PyMC 4.0 发布公告#
我们,PyMC 核心开发团队,非常激动地宣布 PyMC3(现在简称为 PyMC)的重大重写版本:4.0 发布了。在内部,我们已经几乎完全使用 PyMC 4.0 几个月了,并发现它在各个方面都非常稳定和更好。每个用户都应该升级,因为有很多令人兴奋的新更新,我们将在本篇和即将发布的博客文章中讨论。
图片由 Ravin Kumar 提供#
模型构建的完全 API 兼容性#
为了解决主要问题:是的,您可以继续使用现有的 PyMC 建模代码,而无需更改任何内容(在大多数情况下),并免费获得所有改进。大多数用户唯一需要更改的是将导入语句从 import pymc3 as pm 更改为 import pymc as pm。有关更多信息,请参阅快速迁移指南。如果您使用的 PyMC 的高级功能超出了建模 API,您可能需要更改一些内容。
现在称为 PyMC 而不是 PyMC3#
首先,最大的新闻是:PyMC3 已重命名为 PyMC。PyMC3 3.x 版本将保留当前名称以避免破坏生产系统,但未来版本将在所有地方使用 PyMC 名称。 虽然这有几个原因,但主要原因是 PyMC3 4.0 看起来非常混乱。
Theano → Aesara#
在评估其他张量库(如 TensorFlow 和 PyTorch)作为新的后端时,我们意识到 Theano 实际上是多么出色和独特。它具有成熟且可 hack 的代码库和简单的图表示,可以轻松进行图操作,这对于概率编程语言非常有用。此外,TensorFlow 和 PyTorch 专注于动态图,这对于某些事情很有用,但对于概率编程包来说,静态图实际上要好得多,而 Theano 是唯一提供此功能的库。
因此,我们继续 fork 了 Theano 库,并进行了大规模的代码库清理工作(这项工作由 Brandon Willard 领导),删除了大量旧的和晦涩的代码,并重组了整个库,使其对开发人员更加友好。
这次重写促使我们将软件包重命名为 Aesara(希腊神话中 Theano 的女儿)。很快,一个新的开发团队专注于改进独立于 PyMC 的 aesara。
PyMC 4.0 中的新功能?#
好的,让我们来看看好东西。是什么让 PyMC 4.0 如此出色?

新的 JAX 后端,用于更快的采样#
到目前为止,最引人注目的新功能是新的 JAX 后端以及相关的速度提升。
它是如何工作的? aesara 以各种 aesara Ops(运算符)的形式提供模型 logp 图的表示,这些运算符表示要执行的计算。例如,exp(x + y) 将是一个 Add Op,带有两个输入参数 x 和 y。Add Op 的结果然后输入到 exp Op 中。
此计算图没有说明我们如何实际执行此图,只是我们想要执行哪些操作。从 theano 继承的功能是将此图转换为 C 代码,然后将其编译、作为 C 扩展加载到 Python 中,然后可以非常快速地执行。但是,aesara 现在也可以将图的目标设为 JAX,而不是将图转换为 C。
这非常令人兴奋,因为 JAX(通过 XLA)能够进行大量的底层优化,从而加快模型评估速度,此外还可以在 GPU 上运行您的 PyMC 模型。
更令人兴奋的是,这使我们能够将执行 PyMC 模型的 JAX 代码与也用 JAX 编写的 MCMC 采样器结合起来。这样,模型评估和采样器就变成了一个大的 JAX 图,可以进行优化和执行,而没有任何 Python 调用开销。我们目前支持 numpyro 以及 blackjax 提供的 NUTS 实现。
早期的实验和基准测试显示了令人印象深刻的速度提升。这是一个小例子,说明在相当小且简单的模型上,速度提升了多少:著名的 Radon 示例的分层线性回归。
# Standard imports
import numpy as np
import arviz as az
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
RANDOM_SEED = 8927
rng = np.random.default_rng(RANDOM_SEED)
np.set_printoptions(2)
import os, sys
sys.stderr = open(os.devnull, "w")
为了进行并排比较,让我们导入旧的 PyMC3 和 Theano 以及新的 PyMC 4.0 和 Aesara。对于您自己的用例,您只需要新的 pymc 软件包,当然。
# PyMC3 Imports
import pymc3 as pm3
import theano.tensor as tt
import theano
# PyMC 4.0 imports
import pymc as pm
import aesara.tensor as at
import aesara
加载 radon 数据集 并对其进行预处理
data = pd.read_csv(pm.get_data("radon.csv"))
county_names = data.county.unique()
data["log_radon"] = data["log_radon"].astype(theano.config.floatX)
county_idx, counties = pd.factorize(data.county)
coords = {"county": counties, "obs_id": np.arange(len(county_idx))}
接下来,让我们在函数内部定义一个分层回归模型(有关此模型的描述,请参见 这篇博文)。请注意,我们在此处提供了 pm,我们的 PyMC 库作为参数。这有点不寻常,但允许我们在 pymc3 或 pymc 4.0 中创建此模型,具体取决于我们传入的模块。在这里您还可以看到,大多数在 pymc3 中工作的模型也可以在 pymc 4.0 中工作,而无需任何代码更改,您只需要更改您的导入语句。
def build_model(pm):
with pm.Model(coords=coords) as hierarchical_model:
# Intercepts, non-centered
mu_a = pm.Normal("mu_a", mu=0.0, sigma=10)
sigma_a = pm.HalfNormal("sigma_a", 1.0)
a = pm.Normal("a", dims="county") * sigma_a + mu_a
# Slopes, non-centered
mu_b = pm.Normal("mu_b", mu=0.0, sigma=2.)
sigma_b = pm.HalfNormal("sigma_b", 1.0)
b = pm.Normal("b", dims="county") * sigma_b + mu_b
eps = pm.HalfNormal("eps", 1.5)
radon_est = a[county_idx] + b[county_idx] * data.floor.values
radon_like = pm.Normal(
"radon_like", mu=radon_est, sigma=eps, observed=data.log_radon,
dims="obs_id"
)
return hierarchical_model
在 pymc3 中创建和采样模型,没什么特别的
model_pymc3 = build_model(pm3)
%%time
with model_pymc3:
idata_pymc3 = pm3.sample(target_accept=0.9, return_inferencedata=True)
CPU times: user 1.8 s, sys: 229 ms, total: 2.03 s
Wall time: 21.5 s
在 pymc 4.0 中创建和采样模型,也没什么特别的(但请注意 pm.sample() 现在默认返回 InferenceData 对象)
model_pymc4 = build_model(pm)
%%time
with model_pymc4:
idata_pymc4 = pm.sample(target_accept=0.9)
CPU times: user 4.08 s, sys: 315 ms, total: 4.39 s
Wall time: 16.9 s
现在,让我们使用 JAX 采样器代替。这里我们使用 numpyro 提供的采样器。这些采样器位于不同的子模块 sampling_jax 中,但计划是将它们集成到 pymc.sample(backend="JAX") 中。
import pymc.sampling_jax
%%time
with model_pymc4:
idata = pm.sampling_jax.sample_numpyro_nuts(target_accept=0.9, progress_bar=False)
Compiling...
Compilation time = 0:00:00.648311
Sampling...
Sampling time = 0:00:04.195409
Transforming variables...
Transformation time = 0:00:00.025698
CPU times: user 7.51 s, sys: 108 ms, total: 7.62 s
Wall time: 5.01 s
速度提高了 3 倍——只需进行单行代码更改(尽管我们已经看到速度提升远不止于此,达到 20 倍)!这还只是在 CPU 上运行,我们也可以轻松地在 GPU 上运行它,我们在 GPU 上看到了更令人印象深刻的速度提升(尤其是在我们扩展数据时)。
再次强调,有关更合适的基准测试(也将此与 Stan 进行比较),请参阅 这篇博文。
更好地集成到 aesara 中#
我们感到兴奋的下一个功能是 PyMC 更好地集成到 aesara 中。
在 PyMC3 3.x 中,通过例如调用 x = pm.Normal('x') 创建的随机变量 (RV) 并不是真正的 theano Ops,因此它们与 theano 的其余部分没有很好地集成。这在库中造成了很多问题、限制和复杂性。
Aesara 现在提供了一个合适的 RandomVariable Op,它可以与其他 Ops 完美集成。
这是 4.0 中的一个重大变化,导致 PyMC3 中大量脆弱的代码被删除或大大简化。在许多方面,这种变化比不同的计算后端更令人兴奋,但效果对用户来说不太明显。如果您有兴趣了解 Aesara 和 PyMC 如何更详细地交互,请查看 PyMC 和 Aesara 教程。
但是,在某些情况下,您可以看到好处。
更快的后验预测采样#
%%time
with model_pymc3:
pm3.sample_posterior_predictive(idata_pymc3)
CPU times: user 1min 26s, sys: 2.48 s, total: 1min 28s
Wall time: 1min 29s
%%time
with model_pymc4:
pm.sample_posterior_predictive(idata_pymc4)
CPU times: user 3.88 s, sys: 30.9 ms, total: 3.91 s
Wall time: 3.93 s
在这个模型上,我们获得了 22 倍的速度提升!
原因是预测采样现在作为 aesara 图的一部分发生。之前,我们是在 Python 中遍历随机变量,这不仅速度慢,而且非常容易出错,因此花费了大量的开发时间来修复错误和重写这段复杂的代码。在 PyMC 4.0 中,所有这些复杂性都消失了。
像使用张量一样使用 RV#
在 PyMC3 中,由例如 pm.Normal("x") 返回的 RV 的行为有点像张量变量,但不是完全像。在 PyMC 4.0 中,RV 是第一类张量变量,可以更自由地对其进行操作。
with pm3.Model():
x3 = pm3.Normal("x")
with pm.Model():
x4 = pm.Normal("x")
type(x3)
pymc3.model.FreeRV
type(x4)
aesara.tensor.var.TensorVariable
通过 aeppl(一个新的低级库,它在 aesara 之上为概率编程语言提供核心构建块)的强大功能,PyMC 4.0 允许您直接对 RV 执行更多操作。
例如,我们可以直接在 RV 上调用 aesara.tensor.clip() 以截断某些参数范围。另外,在 RV 上调用 .eval() 会从 RV 中抽取一个随机样本,这也是 PyMC 4.0 中的新功能,使事情更加一致,并允许与 RV 轻松交互。
at.clip(x4, 0, np.inf).eval()
array(1.32)
trunc_norm = [at.clip(x4, 0, np.inf).eval() for _ in range(1000)]
sns.histplot(np.asarray(trunc_norm))
<AxesSubplot:ylabel='Count'>
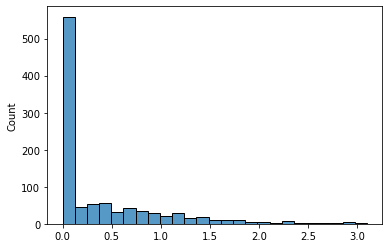
如您所见,负值被裁剪为 0。您可以像使用任何其他变换一样,直接在模型中使用它。
但是您还可以做其他事情,例如 stack() RV,然后使用二进制 RV 对其进行索引。
with pm.Model():
x = pm.Uniform("x", lower=-1, upper=0) # only negtive
y = pm.Uniform("y", lower=0, upper=1) # only positive
xy = at.stack([x, y]) # combined
index = pm.Bernoulli("index", p=0.5) # index 0 or 1
indexed_RV = xy[index] # binary index into stacked variable
for _ in range(5):
print("Sampled value = {:.2f}".format(indexed_RV.eval()))
Sampled value = 0.82
Sampled value = 0.15
Sampled value = 0.31
Sampled value = -0.71
Sampled value = 0.00
如您所见,根据 index 是 0 还是 1,我们要么从负均匀分布中采样,要么从正均匀分布中采样。这也支持花式索引,因此您可以像这样使用 Categorical 手动创建复杂的混合分布
with pm.Model():
x = pm.Uniform("x", lower=-1, upper=0)
y = pm.Uniform("y", lower=0, upper=1)
z = pm.Uniform("z", lower=1, upper=2)
xyz = at.stack([x, y, z])
index = pm.Categorical("index", [.3, .3], shape=3)
index_RV = xyz[index]
for _ in range(5):
print("Sampled value = {}".format(index_RV.eval()))
Sampled value = [ 0.79 -0.28 0.79]
Sampled value = [0.37 0.37 0.37]
Sampled value = [-0.76 0.76 0.76]
Sampled value = [ 0.91 -0.2 0.91]
Sampled value = [0.78 0.78 0.78]
更好(和动态)的形状支持#
PyMC 4.0 中的另一个重大改进是内部处理形状的方式。以前,还有一堆复杂且脆弱的 Python 代码来处理形状。在内部,我们有一个笑话,我们计算了距离我们发现新的形状错误已经过去了多少天。但现在没有了!现在,所有形状处理都完全卸载到 aesara,后者可以正确处理此问题。作为副作用,这种更好的形状支持还允许动态 RV 形状,其中形状取决于另一个 RV
with pm.Model() as m:
x = pm.Poisson('x', 2)
z = pm.Normal('z', shape=x)
for _ in range(5):
print("Value of z = {}".format(z.eval()))
Value of z = [-0.54 -0.24]
Value of z = [0.33]
Value of z = [-0.22 -0.67]
Value of z = []
Value of z = [ 2.01 -0.48]
如您所见,z 的形状随着 x 采样的整数而每次绘制都发生变化。
但是请注意,这尚不适用于后验推断(即采样)。原因是跟踪后端 (arviz.InferenceData) 以及这种情况下的采样器也必须支持更改维度(如可逆跳跃 MCMC)。有计划添加此功能。
更好的 NUTS 初始化#
我们还修复了默认 NUTS 预热的问题,该问题有时会导致采样器卡住一段时间。在修复此问题的同时,Adrian Seyboldt 还提出了一种新的初始化方法,该方法使用梯度来估计更好的质量矩阵。您可以通过调用 pm.sample(init="jitter+adapt_diag_grad") 来使用此(仍然是实验性的)功能。
让我们在上面的分层回归模型上尝试一下
with model_pymc4:
idata_pymc4_grad = pm.sample(init="jitter+adapt_diag_grad", target_accept=0.9)
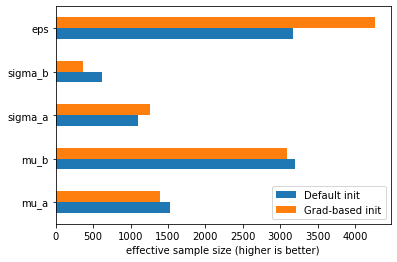
首先要观察到的是,这次我们没有任何偏差。比较默认初始化和基于梯度的初始化的有效样本量,我们还可以看到,对于某些参数,它导致了更好的采样
pd.DataFrame({"Default init": az.summary(idata_pymc4, var_names=["~a", "~b"])["ess_bulk"],
"Grad-based init": az.summary(idata_pymc4_grad, var_names=["~a", "~b"])["ess_bulk"]}).plot.barh()
plt.xlabel("effective sample size (higher is better)");
浏览器中的 PyMC#
您知道您现在也可以在浏览器中运行 PyMC 吗?这可以通过 PyScript 实现。查看 这篇博文,其中有一个小型演示。
安装#
迫不及待想试用它了吗?太棒了!conda install -c conda-forge "pymc>=4" 应该可以开始了。有关详细说明,请参见此处。
新网站#
我们还完全修改了我们的网站,您可以在 https://pymc.cn 上查看。它尚未完全完成,因此预计将来会有更多改进。这项工作由 Oriol Abril 领导。
展望未来#
用 Aesara 编写的采样器#
上面我们描述了如何使用新的 JAX 后端,我们可以将模型和采样器作为一个大的 JAX 图运行,而没有任何 Python 调用开销。虽然这已经非常令人兴奋,但我们可以更进一步。我们上面展示的设置获取模型 logp 图(以 aesara 表示)并将其编译为 JAX。然后可以从直接用 JAX(即 numpyro 或 blackjax)编写的采样器中调用生成的 JAX 函数。
虽然速度极快,但这对于两个原因来说是次优的
对于新的后端,例如
numba,我们将需要也用numba编写新的采样器实现。虽然我们从 logp+sampler JAX 图上的
JAX获得底层优化,但我们没有获得任何高级优化,而这正是aesara的优势,因为aesara看不到采样器。
借助 aehmc 和 aemcmc,aesara 开发人员正在开发一个用 aesara 编写的采样器库。这样,我们的模型 logp(由 aesara Ops 组成)可以与采样器逻辑(现在也由 aesara Ops 组成)结合起来,并形成一个大的 aesara 图。
在包含模型和采样器的大图上,aesara 可以进行高级优化,以获得更有效的图表示。在下一步中,它可以将其编译为我们想要的任何后端:JAX、numba、C 或未来我们添加的任何其他后端。
如果您认为这很有趣,请务必查看这些软件包并考虑贡献,这是下一轮创新的来源!
自动模型重新参数化#
正如开头提到的,aesara 是 PyData 生态系统中独特的库,因为它是唯一一个提供静态、可变计算图的库。直接访问此计算图允许许多有趣的功能
图优化,例如
log(exp(x)) -> x符号重写,例如
N(0, 1) + a->N(a, 1)
并且 aesara 已经实现了许多这些。虽然我们没有合适的基准测试,但我们注意到,即使没有 JAX 后端,将模型从 PyMC3 移植到 4.0 也大大提高了速度。
但是这些图重写可以变得更加复杂。例如,可以通过利用共轭性直接将二项式似然的 beta 先验替换为其解析解。
或者,以中心参数化编写的分层模型可以自动转换为其 非中心化模拟,后者通常采样效率更高。这些模型重新参数化可以极大地改变模型的采样效果。不幸的是,这些重新参数化仍然需要对数学有深入的了解,并且对后验几何形状有深刻的理解,这不是一个普通的 PyMC 用户会熟悉的。因此,通过这些图重写,我们将能够为您自动重新参数化 PyMC 模型,并找到采样效率最高的配置。
总而言之,我们相信 PyMC 4.0 是迄今为止最好的版本,并将概率编程的最新技术向前推进了一步。但它也是通往更多创新的垫脚石。感谢您成为其中的一部分。
行动号召#
想帮助我们构建概率编程的未来吗?现在是参与其中的最佳时机。如果您对以下内容感兴趣
用户友好的 API → PyMC
文档和示例 → PyMC 文档
前沿 PyMC 功能(BART 等)→ PyMC-experimental
低级图框架 → aesara
此外,请在 Twitter 上关注我们,以保持最新状态,并加入我们的 MeetUp 群组 以获取即将到来的活动。如果您正在寻找咨询服务,以使用 PyMC 解决您最具挑战性的数据科学问题,请查看 PyMC Labs – 贝叶斯咨询公司。
赞誉#
虽然很多人为此付出了努力,但我们要特别强调 Brandon Willard、Ricardo Vieira 和 Kaustubh Chaudhari 的杰出贡献,他们领导了这项巨大的工作。