


心理测量学中的验证性因素分析和结构方程模型#
“显然,相关性和依赖性的概念比概率判断的数值更基本地影响着人类的推理……用于表示概率信息的语言应该允许定性、直接和显式地表达关于依赖关系的主张” - Pearl 在智能系统中的概率推理 Pearl [1985]
心理测量学中的测量数据通常来源于针对特定目标现象而战略性构建的调查。一些直觉到的,但尚未测量的概念,可以说在人类行为、动机或情感中起着决定性作用。心理测量学主题的相对“模糊性”对科学中寻求的方法论严谨性产生了催化作用。
调查设计会反复推敲句子结构的正确语气和节奏。测量尺度会进行双重检查,以确保其可靠性和正确性。文献会被查阅,问题会被完善。分析步骤会被证明是合理的,并在大量的建模程序下进行测试。模型架构会被定义和完善,以便更好地表达数据生成过程中假设的结构。我们将看到,如此尽职尽责如何产生强大而富有表现力的模型,使我们能够处理棘手的人类情感问题。
在整个过程中,我们借鉴了 Roy Levy 和 Robert J. Mislevy 出色的贝叶斯心理测量建模。
import warnings
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
import pytensor.tensor as pt
import seaborn as sns
warnings.filterwarnings("ignore", category=RuntimeWarning)
warnings.filterwarnings("ignore", category=UserWarning)
%config InlineBackend.figure_format = 'retina' # high resolution figures
az.style.use("arviz-darkgrid")
rng = np.random.default_rng(42)
潜在结构和测量#
我们的数据借用自 Boris Mayer 和 Andrew Ellis 的工作,可以在这里找到。他们演示了使用 lavaan 进行 CFA 和 SEM 建模。
我们有来自约 300 名个人的调查回复,他们回答了关于他们的成长经历、自我效能感和报告的生活满意度的问题。这个生活满意度数据集中的假设依赖结构假设了与生活满意度、父母和家庭支持以及自我效能感相关的分数之间的调节关系。设计一个能够引出答案的调查并非易事,这些答案可以合理地映射到每个“因素”或主题,更不用说找到一个可以告知我们每个因素对生活满意度结果的相对影响的模型了。
首先,让我们提取数据并检查一些摘要统计信息。
df = pd.read_csv("../data/sem_data.csv")
df.head()
| ID | 地区 | 性别 | 年龄 | se_acad_p1 | se_acad_p2 | se_acad_p3 | se_social_p1 | se_social_p2 | se_social_p3 | sup_friends_p1 | sup_friends_p2 | sup_friends_p3 | sup_parents_p1 | sup_parents_p2 | sup_parents_p3 | ls_p1 | ls_p2 | ls_p3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 西部 | 女性 | 13 | 4.857143 | 5.571429 | 4.500000 | 5.80 | 5.500000 | 5.40 | 6.5 | 6.5 | 7.0 | 7.0 | 7.0 | 6.0 | 5.333333 | 6.75 | 5.50 |
| 1 | 2 | 西部 | 男性 | 14 | 4.571429 | 4.285714 | 4.666667 | 5.00 | 5.500000 | 4.80 | 4.5 | 4.5 | 5.5 | 5.0 | 6.0 | 4.5 | 4.333333 | 5.00 | 4.50 |
| 2 | 10 | 西部 | 女性 | 14 | 4.142857 | 6.142857 | 5.333333 | 5.20 | 4.666667 | 6.00 | 4.0 | 4.5 | 3.5 | 7.0 | 7.0 | 6.5 | 6.333333 | 5.50 | 4.00 |
| 3 | 11 | 西部 | 女性 | 14 | 5.000000 | 5.428571 | 4.833333 | 6.40 | 5.833333 | 6.40 | 7.0 | 7.0 | 7.0 | 7.0 | 7.0 | 7.0 | 4.333333 | 6.50 | 6.25 |
| 4 | 12 | 西部 | 女性 | 14 | 5.166667 | 5.600000 | 4.800000 | 5.25 | 5.400000 | 5.25 | 7.0 | 7.0 | 7.0 | 6.5 | 6.5 | 7.0 | 5.666667 | 6.00 | 5.75 |
fig, ax = plt.subplots(figsize=(20, 10))
drivers = [c for c in df.columns if not c in ["region", "gender", "age", "ID"]]
corr_df = df[drivers].corr()
mask = np.triu(np.ones_like(corr_df, dtype=bool))
sns.heatmap(corr_df, annot=True, cmap="Blues", ax=ax, center=0, mask=mask)
ax.set_title("Sample Correlations between indicator Metrics")
fig, ax = plt.subplots(figsize=(20, 10))
sns.heatmap(df[drivers].cov(), annot=True, cmap="Blues", ax=ax, center=0, mask=mask)
ax.set_title("Sample Covariances between indicator Metrics");

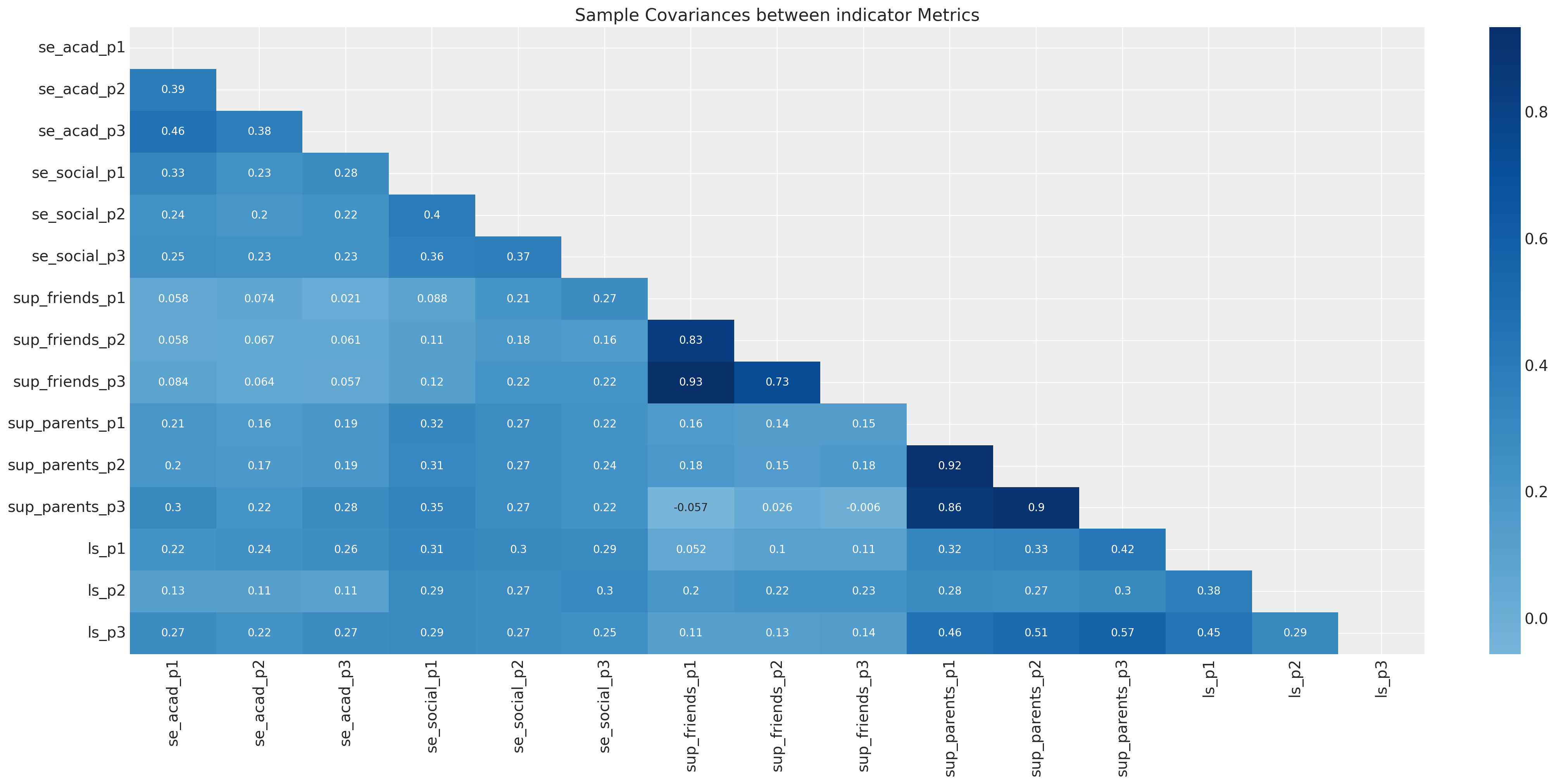
这里的样本协方差矩阵视角在传统的 SEM 建模中很常见。CFA 和 SEM 模型通常通过优化协方差矩阵的参数结构来拟合数据参数进行估计。模型评估程序通常衡量模型恢复样本协方差关系的能力。贝叶斯方法在估计这些模型时采取了略有不同的(约束较少的)方法,该方法侧重于观察到的数据,而不是导出的摘要统计信息。
接下来,我们将绘制配对图以可视化相关性的性质
ax = sns.pairplot(df[drivers], kind="reg", corner=True, diag_kind="kde")
plt.suptitle("Pair Plot of Indicator Metrics with Regression Fits", fontsize=30);

我们试图在 CFA 模型中提炼出这种广泛的关系集。我们如何才能将这种复杂的联合分布结构化为合理且可解释的方式?
测量模型#
测量模型是更一般的结构方程模型中的关键组成部分。测量模型指定了观察变量(通常是调查项目或指标)与其潜在结构(通常称为因子或潜在变量)之间的关系。我们首先更广泛地介绍 SEM 模型,重点关注一种测量模型及其自身的历史——验证性因素模型 (CFA),该模型指定了指标变量和潜在因子之间关系的特定结构。正是这种结构在我们的建模中需要进行验证。
我们将首先在 PyMC 中拟合一个“简单”的 CFA 模型,以演示各个部分如何组合在一起,然后我们将扩展我们的重点。在这里,我们忽略了我们的大部分指标变量,而专注于以下观点:存在两个潜在结构:(1)社会自我效能感和(2)生活满意度。
我们的目标是阐明一种数学结构,其中我们的指标变量 \(x_{ij}\) 由潜在因子 \(\text{Ksi}_{j}\) 通过估计的因子载荷 \(\lambda_{ij}\) 确定。在功能上,我们有一组带有误差项 \(\psi_i\) 的方程,每个个体都有一个误差项。
或更紧凑地表示为
目标是根据这些潜在项之间的协方差来阐明不同因子之间的关系,并估计每个潜在因子与显性指标变量的关系。在高层次上,我们说观察数据的联合分布可以通过以下模式中的条件化来表示。
我们正在论证,来自每个个体 \(q\) 的多元观测 \(\mathbf{x}\) 可以被认为是条件可交换的,并且可以通过德·菲内蒂定理通过贝叶斯条件化来表示。这是估计 CFA 和 SEM 模型的贝叶斯方法。我们正在寻找一种条件化结构,该结构可以根据潜在结构以及结构与观察数据点之间的假设关系来回溯预测观察数据。我们将在下面展示如何将这些结构构建到我们的模型中
# Set up coordinates for appropriate indexing of latent factors
coords = {
"obs": list(range(len(df))),
"indicators": ["se_social_p1", "se_social_p2", "se_social_p3", "ls_p1", "ls_p2", "ls_p3"],
"indicators_1": ["se_social_p1", "se_social_p2", "se_social_p3"],
"indicators_2": ["ls_p1", "ls_p2", "ls_p3"],
"latent": ["SE_SOC", "LS"],
}
obs_idx = list(range(len(df)))
with pm.Model(coords=coords) as model:
# Set up Factor Loadings
lambdas_ = pm.Normal("lambdas_1", 1, 10, dims=("indicators_1"))
# Force a fixed scale on the factor loadings for factor 1
lambdas_1 = pm.Deterministic(
"lambdas1", pt.set_subtensor(lambdas_[0], 1), dims=("indicators_1")
)
lambdas_ = pm.Normal("lambdas_2", 1, 10, dims=("indicators_2"))
# Force a fixed scale on the factor loadings for factor 2
lambdas_2 = pm.Deterministic(
"lambdas2", pt.set_subtensor(lambdas_[0], 1), dims=("indicators_2")
)
# Specify covariance structure between latent factors
kappa = 0
sd_dist = pm.Exponential.dist(1.0, shape=2)
chol, _, _ = pm.LKJCholeskyCov("chol_cov", n=2, eta=2, sd_dist=sd_dist, compute_corr=True)
ksi = pm.MvNormal("ksi", kappa, chol=chol, dims=("obs", "latent"))
# Construct Pseudo Observation matrix based on Factor Loadings
tau = pm.Normal("tau", 3, 10, dims="indicators")
m1 = tau[0] + ksi[obs_idx, 0] * lambdas_1[0]
m2 = tau[1] + ksi[obs_idx, 0] * lambdas_1[1]
m3 = tau[2] + ksi[obs_idx, 0] * lambdas_1[2]
m4 = tau[3] + ksi[obs_idx, 1] * lambdas_2[0]
m5 = tau[4] + ksi[obs_idx, 1] * lambdas_2[1]
m6 = tau[5] + ksi[obs_idx, 1] * lambdas_2[2]
mu = pm.Deterministic("mu", pm.math.stack([m1, m2, m3, m4, m5, m6]).T)
## Error Terms
Psi = pm.InverseGamma("Psi", 5, 10, dims="indicators")
# Likelihood
_ = pm.Normal(
"likelihood",
mu,
Psi,
observed=df[
["se_social_p1", "se_social_p2", "se_social_p3", "ls_p1", "ls_p2", "ls_p3"]
].values,
)
idata = pm.sample(
nuts_sampler="numpyro", target_accept=0.95, idata_kwargs={"log_likelihood": True}
)
idata.extend(pm.sample_posterior_predictive(idata))
pm.model_to_graphviz(model)
Compiling...
Compilation time = 0:00:02.037172
Sampling...
Sampling time = 0:00:04.970539
Transforming variables...
Transformation time = 0:00:00.366997
Computing Log Likelihood...
Log Likelihood time = 0:00:00.248048
Sampling: [likelihood]

在这里,模型结构和依赖关系图变得更加清晰。我们的似然项对 283x6 观测值的输出矩阵进行建模,即 6 个问题的调查回复。这些调查回复被建模为来自多元正态分布 \(Ksi\) 的类回归输出,潜在结构之间具有先验相关结构。然后,我们指定每个输出度量如何是其中一个潜在因子的函数,并由适当的因子载荷 lambda 进行修改。
测量模型结构#
我们现在可以看到潜在结构之间的协方差结构是如何成为总体模型设计的组成部分的,该设计被前馈到我们的伪回归组件中,并使用各自的 lambda 项进行加权。
az.summary(idata, var_names=["lambdas1", "lambdas2"])
| 均值 | 标准差 | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| lambdas1[se_social_p1] | 1.000 | 0.000 | 1.000 | 1.000 | 0.000 | 0.000 | 4000.0 | 4000.0 | NaN |
| lambdas1[se_social_p2] | 0.977 | 0.060 | 0.863 | 1.089 | 0.002 | 0.001 | 993.0 | 1688.0 | 1.0 |
| lambdas1[se_social_p3] | 0.947 | 0.074 | 0.810 | 1.091 | 0.002 | 0.002 | 1110.0 | 1965.0 | 1.0 |
| lambdas2[ls_p1] | 1.000 | 0.000 | 1.000 | 1.000 | 0.000 | 0.000 | 4000.0 | 4000.0 | NaN |
| lambdas2[ls_p2] | 0.815 | 0.087 | 0.672 | 0.989 | 0.004 | 0.003 | 524.0 | 792.0 | 1.0 |
| lambdas2[ls_p3] | 0.861 | 0.095 | 0.689 | 1.047 | 0.004 | 0.003 | 713.0 | 1164.0 | 1.0 |
这些因子载荷通常在结构效度方面很重要。由于我们已指定其中一个指标变量固定为 1,因此加载在该因子上的其他指标的载荷系数应与定义结构尺度的固定点指标大致在同一尺度上。我们正在寻找载荷之间的一致性,以评估指标是否是结构的可靠度量,即如果指标载荷偏离单位 1 太远,则可以认为这些指标不属于同一因子结构。
idata
-
<xarray.Dataset> Dimensions: (chain: 4, draw: 1000, indicators_1: 3, indicators_2: 3, obs: 283, latent: 2, indicators: 6, chol_cov_dim_0: 3, chol_cov_corr_dim_0: 2, chol_cov_corr_dim_1: 2, chol_cov_stds_dim_0: 2, mu_dim_0: 283, mu_dim_1: 6) Coordinates: (12/13) * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 6 ... 994 995 996 997 998 999 * indicators_1 (indicators_1) <U12 'se_social_p1' ... 'se_social_p3' * indicators_2 (indicators_2) <U5 'ls_p1' 'ls_p2' 'ls_p3' * obs (obs) int64 0 1 2 3 4 5 6 ... 277 278 279 280 281 282 * latent (latent) <U6 'SE_SOC' 'LS' ... ... * chol_cov_dim_0 (chol_cov_dim_0) int64 0 1 2 * chol_cov_corr_dim_0 (chol_cov_corr_dim_0) int64 0 1 * chol_cov_corr_dim_1 (chol_cov_corr_dim_1) int64 0 1 * chol_cov_stds_dim_0 (chol_cov_stds_dim_0) int64 0 1 * mu_dim_0 (mu_dim_0) int64 0 1 2 3 4 5 ... 278 279 280 281 282 * mu_dim_1 (mu_dim_1) int64 0 1 2 3 4 5 Data variables: lambdas_1 (chain, draw, indicators_1) float64 -1.601 ... 0.962 lambdas_2 (chain, draw, indicators_2) float64 11.47 ... 0.7527 ksi (chain, draw, obs, latent) float64 0.4271 ... 0.9507 tau (chain, draw, indicators) float64 5.301 5.437 ... 5.233 chol_cov (chain, draw, chol_cov_dim_0) float64 0.6359 ... 0.5823 Psi (chain, draw, indicators) float64 0.4654 ... 0.6677 lambdas1 (chain, draw, indicators_1) float64 1.0 ... 0.962 lambdas2 (chain, draw, indicators_2) float64 1.0 ... 0.7527 chol_cov_corr (chain, draw, chol_cov_corr_dim_0, chol_cov_corr_dim_1) float64 ... chol_cov_stds (chain, draw, chol_cov_stds_dim_0) float64 0.6359 ..... mu (chain, draw, mu_dim_0, mu_dim_1) float64 5.728 ... ... Attributes: created_at: 2024-09-25T11:16:42.786789 arviz_version: 0.17.0 -
<xarray.Dataset> Dimensions: (chain: 4, draw: 1000, likelihood_dim_2: 283, likelihood_dim_3: 6) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 6 ... 993 994 995 996 997 998 999 * likelihood_dim_2 (likelihood_dim_2) int64 0 1 2 3 4 ... 278 279 280 281 282 * likelihood_dim_3 (likelihood_dim_3) int64 0 1 2 3 4 5 Data variables: likelihood (chain, draw, likelihood_dim_2, likelihood_dim_3) float64 ... Attributes: created_at: 2024-09-25T11:16:43.032825 arviz_version: 0.17.0 inference_library: pymc inference_library_version: 5.10.3 -
<xarray.Dataset> Dimensions: (chain: 4, draw: 1000, likelihood_dim_0: 283, likelihood_dim_1: 6) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 6 ... 993 994 995 996 997 998 999 * likelihood_dim_0 (likelihood_dim_0) int64 0 1 2 3 4 ... 278 279 280 281 282 * likelihood_dim_1 (likelihood_dim_1) int64 0 1 2 3 4 5 Data variables: likelihood (chain, draw, likelihood_dim_0, likelihood_dim_1) float64 ... Attributes: created_at: 2024-09-25T11:16:42.790979 arviz_version: 0.17.0 -
<xarray.Dataset> Dimensions: (chain: 4, draw: 1000) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 6 ... 993 994 995 996 997 998 999 Data variables: acceptance_rate (chain, draw) float64 0.9026 0.9604 0.9726 ... 0.992 0.9294 step_size (chain, draw) float64 0.1464 0.1464 ... 0.1427 0.1427 diverging (chain, draw) bool False False False ... False False False energy (chain, draw) float64 2.091e+03 2.111e+03 ... 2.072e+03 n_steps (chain, draw) int64 31 31 31 31 31 31 ... 31 31 31 31 31 31 tree_depth (chain, draw) int64 5 5 5 5 5 5 5 5 5 ... 5 5 5 5 5 5 5 5 5 lp (chain, draw) float64 1.803e+03 1.804e+03 ... 1.78e+03 Attributes: created_at: 2024-09-25T11:16:42.789976 arviz_version: 0.17.0 -
<xarray.Dataset> Dimensions: (likelihood_dim_0: 283, likelihood_dim_1: 6) Coordinates: * likelihood_dim_0 (likelihood_dim_0) int64 0 1 2 3 4 ... 278 279 280 281 282 * likelihood_dim_1 (likelihood_dim_1) int64 0 1 2 3 4 5 Data variables: likelihood (likelihood_dim_0, likelihood_dim_1) float64 5.8 ... 5.75 Attributes: created_at: 2024-09-25T11:16:42.791317 arviz_version: 0.17.0 inference_library: numpyro inference_library_version: 0.13.2 sampling_time: 4.970539
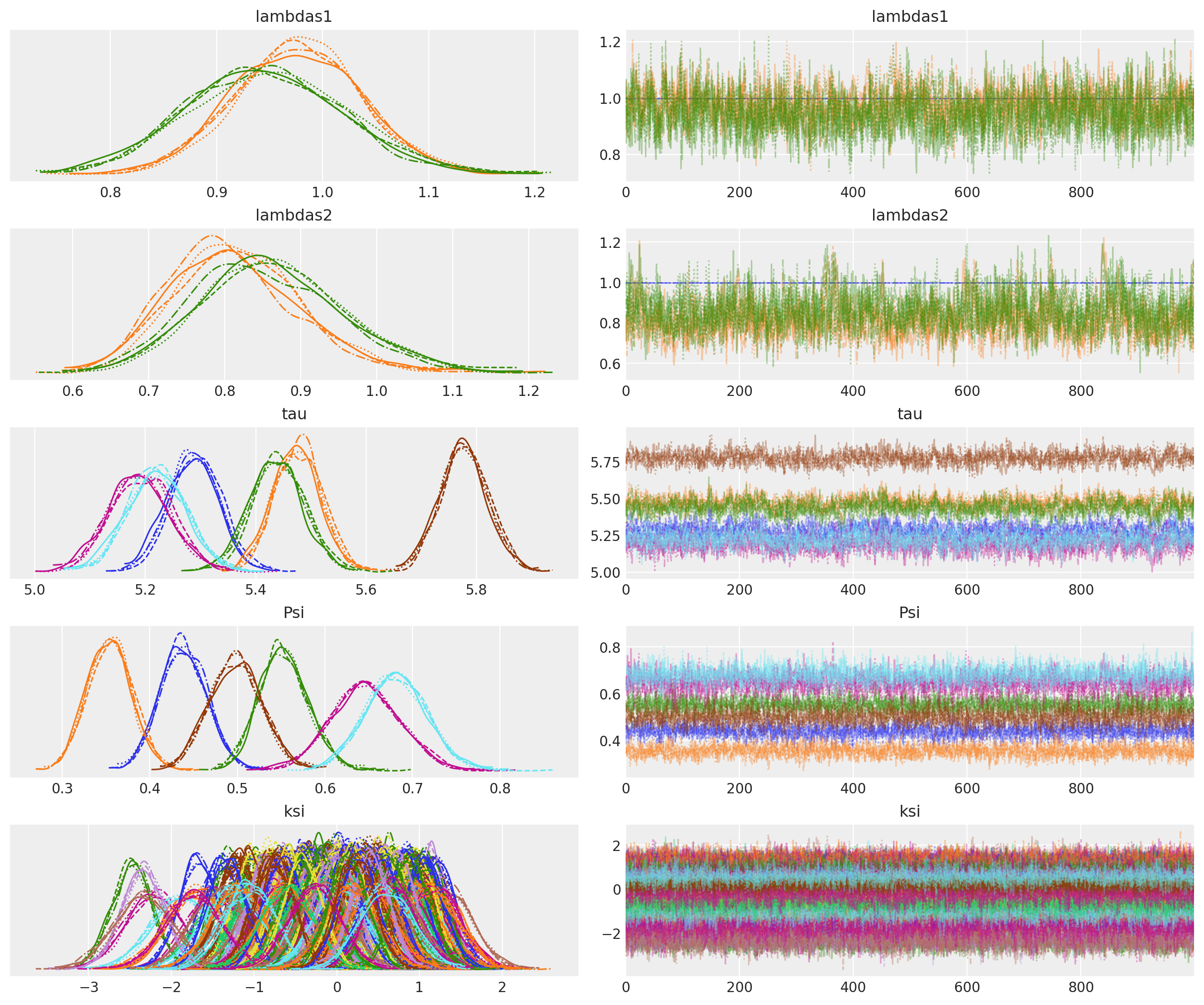
让我们绘制迹线诊断图,以验证采样器是否已很好地收敛到后验分布。
az.plot_trace(idata, var_names=["lambdas1", "lambdas2", "tau", "Psi", "ksi"]);
潜在结构的抽样#
关于拟合 CFA 和 SEM 模型的贝叶斯方式,尤其需要强调的一点是,我们现在可以访问潜在量的后验分布。这些样本可以提供对我们调查中特定个体的见解,而这些见解很难从显性变量的多元表示中收集到。
显示代码单元格源
fig, axs = plt.subplots(1, 2, figsize=(20, 9))
axs = axs.flatten()
ax1 = axs[0]
ax2 = axs[1]
az.plot_forest(
idata,
var_names=["ksi"],
combined=True,
ax=ax1,
colors="forestgreen",
coords={"latent": ["SE_SOC"]},
)
az.plot_forest(
idata, var_names=["ksi"], combined=True, ax=ax2, colors="slateblue", coords={"latent": ["LS"]}
)
ax1.set_yticklabels([])
ax1.set_xlabel("SE_SOCIAL")
ax2.set_yticklabels([])
ax2.set_xlabel("LS")
ax1.axvline(-2, color="red")
ax2.axvline(-2, color="red")
ax1.set_title("Individual Social Self Efficacy \n On Latent Factor SE_SOCIAL")
ax2.set_title("Individual Life Satisfaction Metric \n On Latent Factor LS")
plt.show();
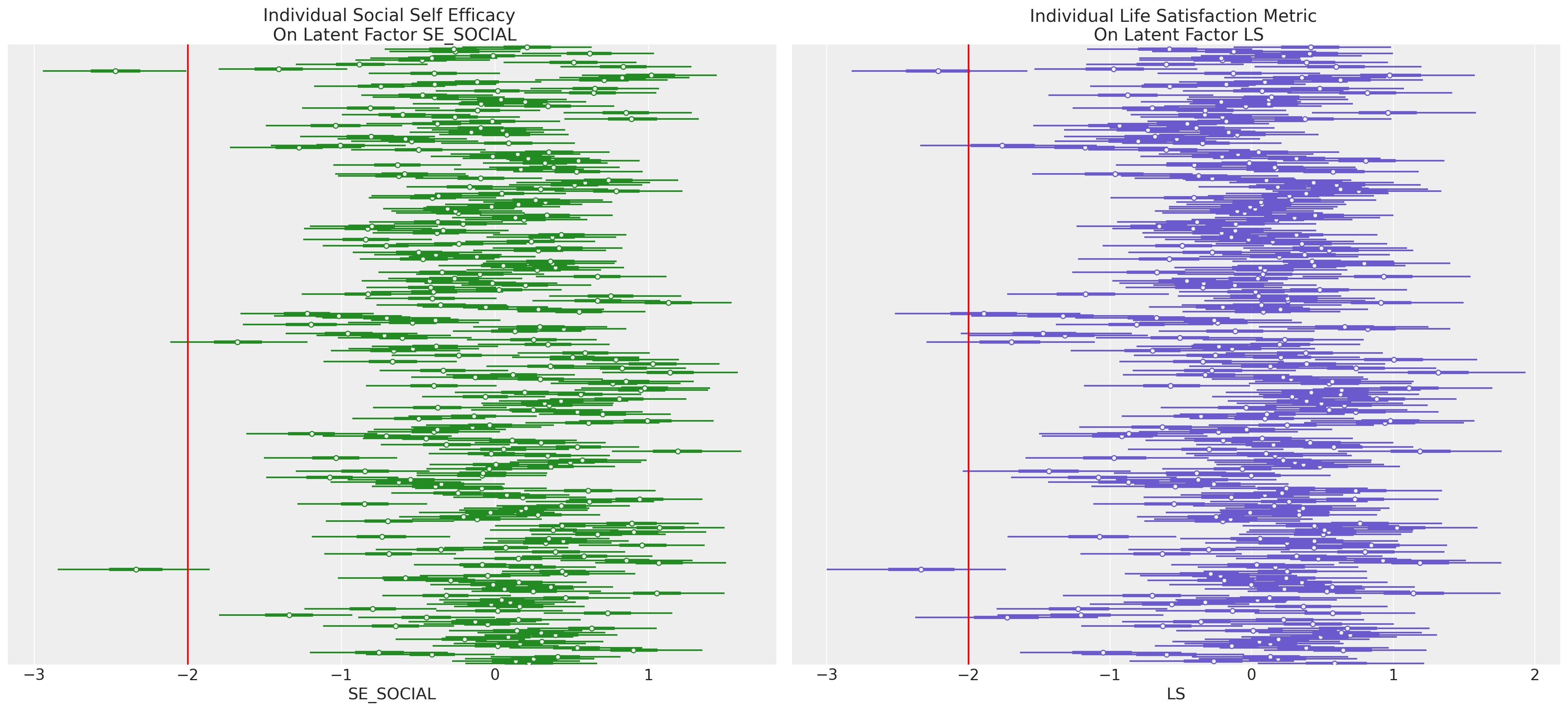
通过这种方式,我们可以识别并集中关注那些在一个或多个潜在结构上似乎是离群值的个体。
后验预测检验#
与更传统的贝叶斯建模一样,模型评估的核心组成部分是对后验预测分布(即隐含结果分布)的评估。在这里,我们也可以针对每个指标变量提取抽取,以评估其连贯性和充分性。
def make_ppc(
idata,
samples=100,
drivers=["se_social_p1", "se_social_p2", "se_social_p3", "ls_p1", "ls_p2", "ls_p3"],
dims=(2, 3),
):
fig, axs = plt.subplots(dims[0], dims[1], figsize=(20, 10))
axs = axs.flatten()
for i in range(len(drivers)):
for j in range(samples):
temp = az.extract(idata["posterior_predictive"].sel({"likelihood_dim_3": i}))[
"likelihood"
].values[:, j]
temp = pd.DataFrame(temp, columns=["likelihood"])
if j == 0:
axs[i].hist(df[drivers[i]], alpha=0.3, ec="black", bins=20, label="Observed Scores")
axs[i].hist(
temp["likelihood"], color="purple", alpha=0.1, bins=20, label="Predicted Scores"
)
else:
axs[i].hist(df[drivers[i]], alpha=0.3, ec="black", bins=20)
axs[i].hist(temp["likelihood"], color="purple", alpha=0.1, bins=20)
axs[i].set_title(f"Posterior Predictive Checks {drivers[i]}")
axs[i].legend()
plt.tight_layout()
plt.show()
make_ppc(idata)
del idata

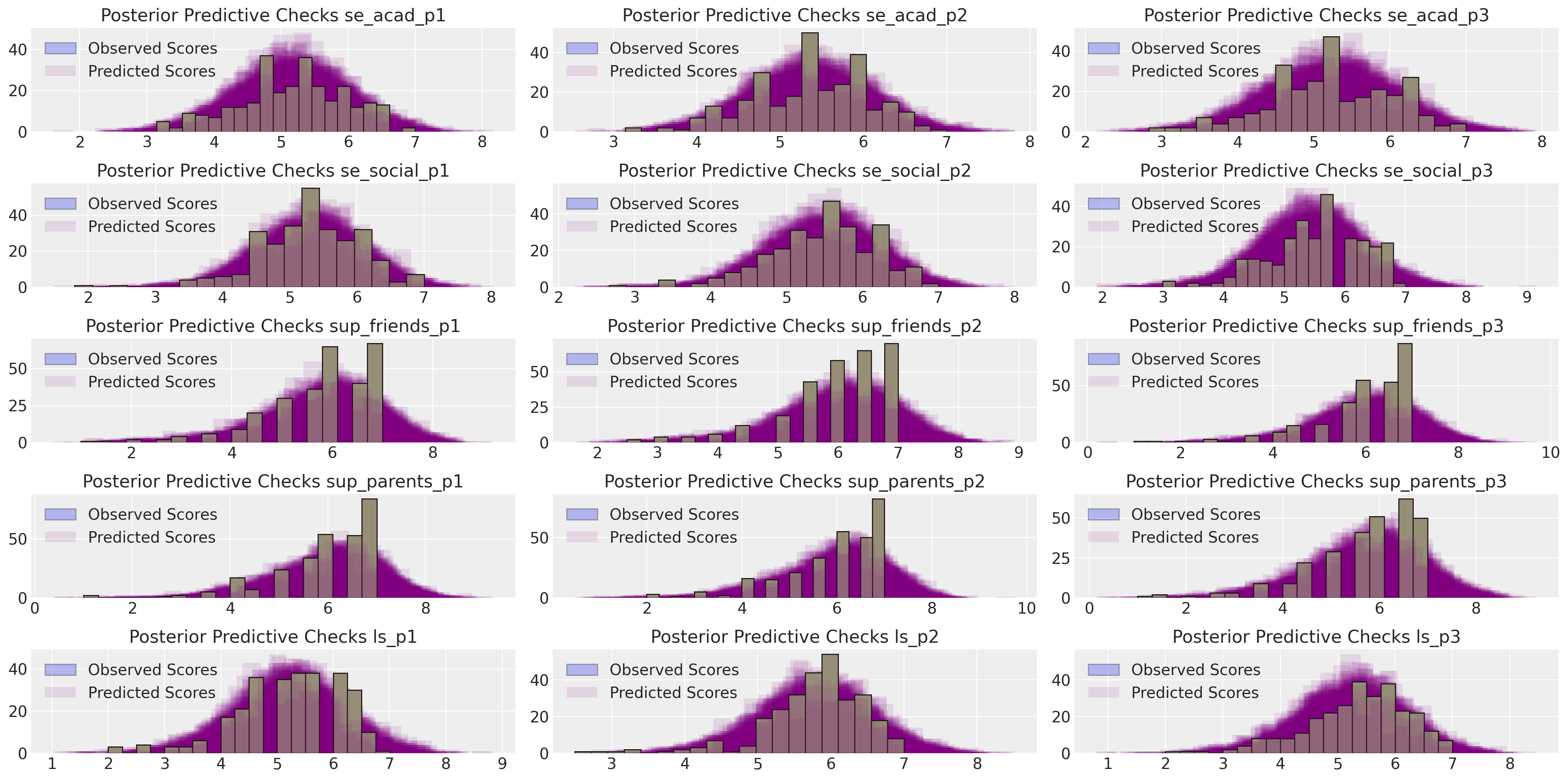
这表明观察数据的恢复相对合理。
中间交叉加载模型#
当我们只看到拟合良好的模型时,测量模型的概念可能有点模糊。相反,我们想简要展示一个不合适的测量模型如何在因子载荷的估计参数中反映出来。在这里,我们指定一个测量模型,该模型试图将 se_social 和 sup_parents 指标耦合起来,并将它们捆绑到同一个因子中。
coords = {
"obs": list(range(len(df))),
"indicators": [
"se_social_p1",
"se_social_p2",
"se_social_p3",
"sup_parents_p1",
"sup_parents_p2",
"sup_parents_p3",
"ls_p1",
"ls_p2",
"ls_p3",
],
## Attempt Cross-Loading of two metric types on one factor
"indicators_1": [
"se_social_p1",
"se_social_p2",
"se_social_p3",
"sup_parents_p1",
"sup_parents_p2",
"sup_parents_p3",
],
"indicators_2": ["ls_p1", "ls_p2", "ls_p3"],
"latent": ["SE_SOC", "LS"],
}
obs_idx = list(range(len(df)))
with pm.Model(coords=coords) as model:
Psi = pm.InverseGamma("Psi", 5, 10, dims="indicators")
lambdas_ = pm.Normal("lambdas_1", 1, 10, dims=("indicators_1"))
# Force a fixed scale on the factor loadings for factor 1
lambdas_1 = pm.Deterministic(
"lambdas1", pt.set_subtensor(lambdas_[0], 1), dims=("indicators_1")
)
lambdas_ = pm.Normal("lambdas_2", 1, 10, dims=("indicators_2"))
# Force a fixed scale on the factor loadings for factor 2
lambdas_2 = pm.Deterministic(
"lambdas2", pt.set_subtensor(lambdas_[0], 1), dims=("indicators_2")
)
tau = pm.Normal("tau", 3, 10, dims="indicators")
# Specify covariance structure between latent factors
kappa = 0
sd_dist = pm.Exponential.dist(1.0, shape=2)
chol, _, _ = pm.LKJCholeskyCov("chol_cov", n=2, eta=2, sd_dist=sd_dist, compute_corr=True)
ksi = pm.MvNormal("ksi", kappa, chol=chol, dims=("obs", "latent"))
# Construct Observation matrix
m1 = tau[0] + ksi[obs_idx, 0] * lambdas_1[0]
m2 = tau[1] + ksi[obs_idx, 0] * lambdas_1[1]
m3 = tau[2] + ksi[obs_idx, 0] * lambdas_1[2]
m4 = tau[3] + ksi[obs_idx, 0] * lambdas_1[3]
m5 = tau[4] + ksi[obs_idx, 0] * lambdas_1[4]
m6 = tau[5] + ksi[obs_idx, 0] * lambdas_1[5]
m7 = tau[3] + ksi[obs_idx, 1] * lambdas_2[0]
m8 = tau[4] + ksi[obs_idx, 1] * lambdas_2[1]
m9 = tau[5] + ksi[obs_idx, 1] * lambdas_2[2]
mu = pm.Deterministic("mu", pm.math.stack([m1, m2, m3, m4, m5, m6, m7, m8, m9]).T)
_ = pm.Normal(
"likelihood",
mu,
Psi,
observed=df[
[
"se_social_p1",
"se_social_p2",
"se_social_p3",
"sup_parents_p1",
"sup_parents_p2",
"sup_parents_p3",
"ls_p1",
"ls_p2",
"ls_p3",
]
].values,
)
idata = pm.sample(
# draws = 4000,
draws=10000,
nuts_sampler="numpyro",
target_accept=0.99,
idata_kwargs={"log_likelihood": True},
random_seed=114,
)
idata.extend(pm.sample_posterior_predictive(idata))
Compiling...
Compilation time = 0:00:01.765569
Sampling...
Sampling time = 0:00:26.201814
Transforming variables...
Transformation time = 0:00:01.184088
Computing Log Likelihood...
Log Likelihood time = 0:00:00.831334
Sampling: [likelihood]
我们的模型再次采样良好,但参数估计表明,我们试图强制两组指标的尺度之间存在一些不一致之处。
az.summary(idata, var_names=["lambdas1", "lambdas2"])
| 均值 | 标准差 | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| lambdas1[se_social_p1] | 1.000 | 0.000 | 1.000 | 1.000 | 0.000 | 0.000 | 40000.0 | 40000.0 | NaN |
| lambdas1[se_social_p2] | 0.928 | 0.128 | 0.694 | 1.172 | 0.002 | 0.002 | 3090.0 | 5423.0 | 1.0 |
| lambdas1[se_social_p3] | 0.854 | 0.139 | 0.598 | 1.121 | 0.002 | 0.002 | 4600.0 | 8366.0 | 1.0 |
| lambdas1[sup_parents_p1] | 2.321 | 0.289 | 1.807 | 2.867 | 0.008 | 0.005 | 1421.0 | 2736.0 | 1.0 |
| lambdas1[sup_parents_p2] | 2.171 | 0.278 | 1.684 | 2.699 | 0.008 | 0.005 | 1333.0 | 2592.0 | 1.0 |
| lambdas1[sup_parents_p3] | 2.334 | 0.290 | 1.832 | 2.898 | 0.008 | 0.005 | 1442.0 | 2795.0 | 1.0 |
| lambdas2[ls_p1] | 1.000 | 0.000 | 1.000 | 1.000 | 0.000 | 0.000 | 40000.0 | 40000.0 | NaN |
| lambdas2[ls_p2] | 0.777 | 0.105 | 0.589 | 0.975 | 0.002 | 0.002 | 2530.0 | 4296.0 | 1.0 |
| lambdas2[ls_p3] | 1.080 | 0.135 | 0.840 | 1.335 | 0.003 | 0.002 | 2271.0 | 3902.0 | 1.0 |
这也同样反映在诊断能量图中。
fig, axs = plt.subplots(1, 2, figsize=(20, 9))
axs = axs.flatten()
az.plot_energy(idata, ax=axs[0])
az.plot_forest(idata, var_names=["lambdas1"], combined=True, ax=axs[1]);
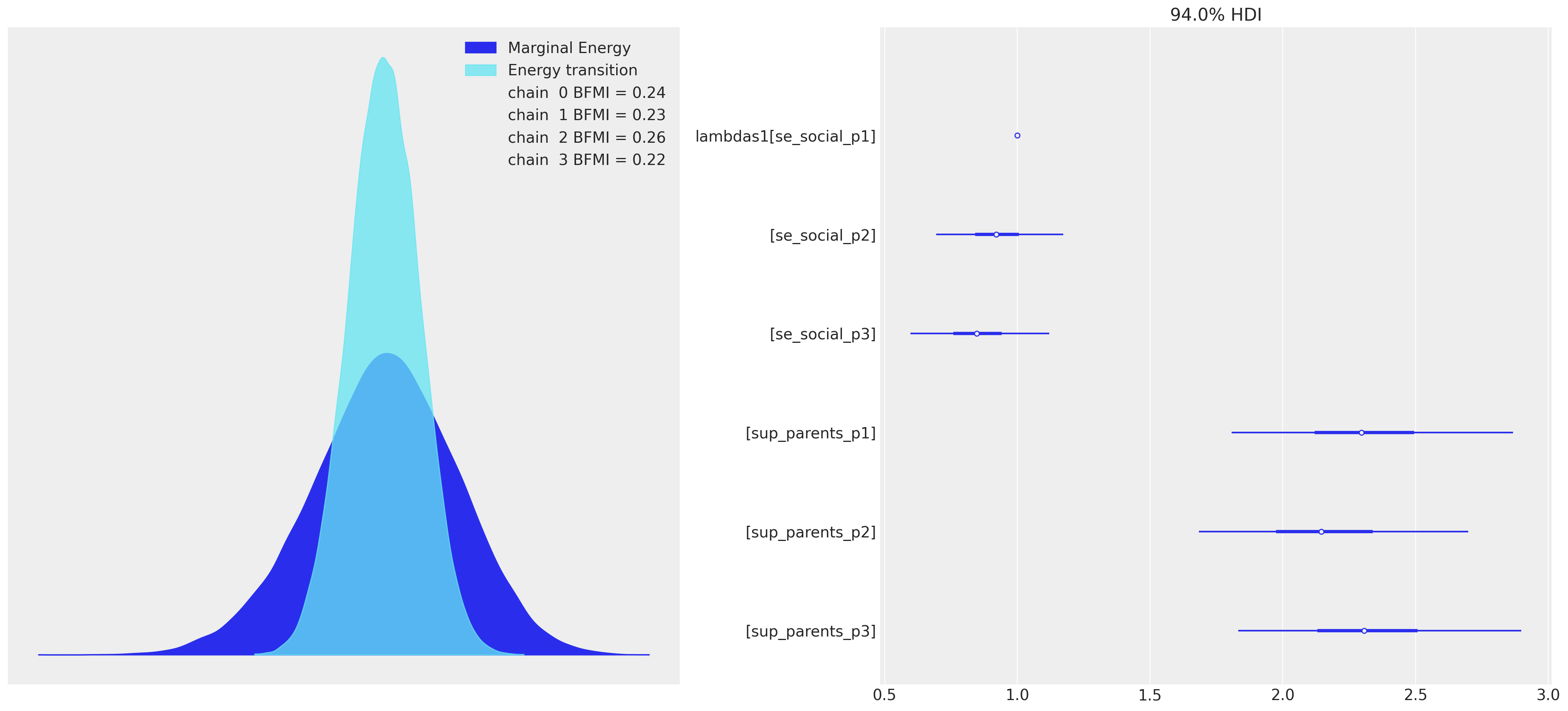
这暗示了各种测量模型误设,应该迫使我们回到绘图板。适当的测量模型将指标变量映射到一致定义的潜在结构,该结构合理地反映了已实现的指标度量的各个方面。
完整测量模型#
考虑到这一点,我们现在将指定一个完整的测量,将每个主题相似的指标度量映射到单独的潜在结构。这要求假设 5 个不同的结构,其中我们只允许三个度量加载到每个结构上。在我们的案例中,哪个度量加载到潜在结构上的选择取决于每个度量旨在测量的结构。在典型的 lavaan 语法中,我们可以将模型写成如下形式
SUP_Parents =~ sup_parents_p1 + sup_parents_p2 + sup_parents_p3
SUP_Friends =~ sup_friends_p1 + sup_friends_p2 + sup_friends_p3
SE_Academic =~ se_acad_p1 + se_acad_p2 + se_acad_p3
SE_Social =~ se_social_p1 + se_social_p2 + se_social_p3
LS =~ ls_p1 + ls_p2 + ls_p3
其中 =~ 语法表示“由...测量”的关系。当我们拟合这种类型的测量模型时,我们试图估计每个指标变量由潜在结构决定的方式。
drivers = [
"se_acad_p1",
"se_acad_p2",
"se_acad_p3",
"se_social_p1",
"se_social_p2",
"se_social_p3",
"sup_friends_p1",
"sup_friends_p2",
"sup_friends_p3",
"sup_parents_p1",
"sup_parents_p2",
"sup_parents_p3",
"ls_p1",
"ls_p2",
"ls_p3",
]
coords = {
"obs": list(range(len(df))),
"indicators": drivers,
"indicators_1": ["se_acad_p1", "se_acad_p2", "se_acad_p3"],
"indicators_2": ["se_social_p1", "se_social_p2", "se_social_p3"],
"indicators_3": ["sup_friends_p1", "sup_friends_p2", "sup_friends_p3"],
"indicators_4": ["sup_parents_p1", "sup_parents_p2", "sup_parents_p3"],
"indicators_5": ["ls_p1", "ls_p2", "ls_p3"],
"latent": ["SE_ACAD", "SE_SOCIAL", "SUP_F", "SUP_P", "LS"],
"latent1": ["SE_ACAD", "SE_SOCIAL", "SUP_F", "SUP_P", "LS"],
}
obs_idx = list(range(len(df)))
with pm.Model(coords=coords) as model:
Psi = pm.InverseGamma("Psi", 5, 10, dims="indicators")
lambdas_ = pm.Normal("lambdas_1", 1, 10, dims=("indicators_1"))
lambdas_1 = pm.Deterministic(
"lambdas1", pt.set_subtensor(lambdas_[0], 1), dims=("indicators_1")
)
lambdas_ = pm.Normal("lambdas_2", 1, 10, dims=("indicators_2"))
lambdas_2 = pm.Deterministic(
"lambdas2", pt.set_subtensor(lambdas_[0], 1), dims=("indicators_2")
)
lambdas_ = pm.Normal("lambdas_3", 1, 10, dims=("indicators_3"))
lambdas_3 = pm.Deterministic(
"lambdas3", pt.set_subtensor(lambdas_[0], 1), dims=("indicators_3")
)
lambdas_ = pm.Normal("lambdas_4", 1, 10, dims=("indicators_4"))
lambdas_4 = pm.Deterministic(
"lambdas4", pt.set_subtensor(lambdas_[0], 1), dims=("indicators_4")
)
lambdas_ = pm.Normal("lambdas_5", 1, 10, dims=("indicators_5"))
lambdas_5 = pm.Deterministic(
"lambdas5", pt.set_subtensor(lambdas_[0], 1), dims=("indicators_5")
)
tau = pm.Normal("tau", 3, 10, dims="indicators")
kappa = 0
sd_dist = pm.Exponential.dist(1.0, shape=5)
chol, _, _ = pm.LKJCholeskyCov("chol_cov", n=5, eta=2, sd_dist=sd_dist, compute_corr=True)
cov = pm.Deterministic("cov", chol.dot(chol.T), dims=("latent", "latent1"))
ksi = pm.MvNormal("ksi", kappa, chol=chol, dims=("obs", "latent"))
m0 = tau[0] + ksi[obs_idx, 0] * lambdas_1[0]
m1 = tau[1] + ksi[obs_idx, 0] * lambdas_1[1]
m2 = tau[2] + ksi[obs_idx, 0] * lambdas_1[2]
m3 = tau[3] + ksi[obs_idx, 1] * lambdas_2[0]
m4 = tau[4] + ksi[obs_idx, 1] * lambdas_2[1]
m5 = tau[5] + ksi[obs_idx, 1] * lambdas_2[2]
m6 = tau[6] + ksi[obs_idx, 2] * lambdas_3[0]
m7 = tau[7] + ksi[obs_idx, 2] * lambdas_3[1]
m8 = tau[8] + ksi[obs_idx, 2] * lambdas_3[2]
m9 = tau[9] + ksi[obs_idx, 3] * lambdas_4[0]
m10 = tau[10] + ksi[obs_idx, 3] * lambdas_4[1]
m11 = tau[11] + ksi[obs_idx, 3] * lambdas_4[2]
m12 = tau[12] + ksi[obs_idx, 4] * lambdas_5[0]
m13 = tau[13] + ksi[obs_idx, 4] * lambdas_5[1]
m14 = tau[14] + ksi[obs_idx, 4] * lambdas_5[2]
mu = pm.Deterministic(
"mu", pm.math.stack([m0, m1, m2, m3, m4, m5, m6, m7, m8, m9, m10, m11, m12, m13, m14]).T
)
_ = pm.Normal("likelihood", mu, Psi, observed=df[drivers].values)
idata_mm = pm.sample(
draws=10000,
nuts_sampler="numpyro",
target_accept=0.98,
tune=1000,
idata_kwargs={"log_likelihood": True},
random_seed=100,
)
idata_mm.extend(pm.sample_posterior_predictive(idata_mm))
Compiling...
Compilation time = 0:00:02.385203
Sampling...
Sampling time = 0:04:36.313368
Transforming variables...
Transformation time = 0:00:03.402148
Computing Log Likelihood...
Log Likelihood time = 0:00:01.964164
Sampling: [likelihood]
模型评估检查#
我们可以在这里快速看到,这种因子结构似乎采样更好,并保持了尺度的一致性。
fig, axs = plt.subplots(1, 2, figsize=(20, 9))
axs = axs.flatten()
az.plot_energy(idata_mm, ax=axs[0])
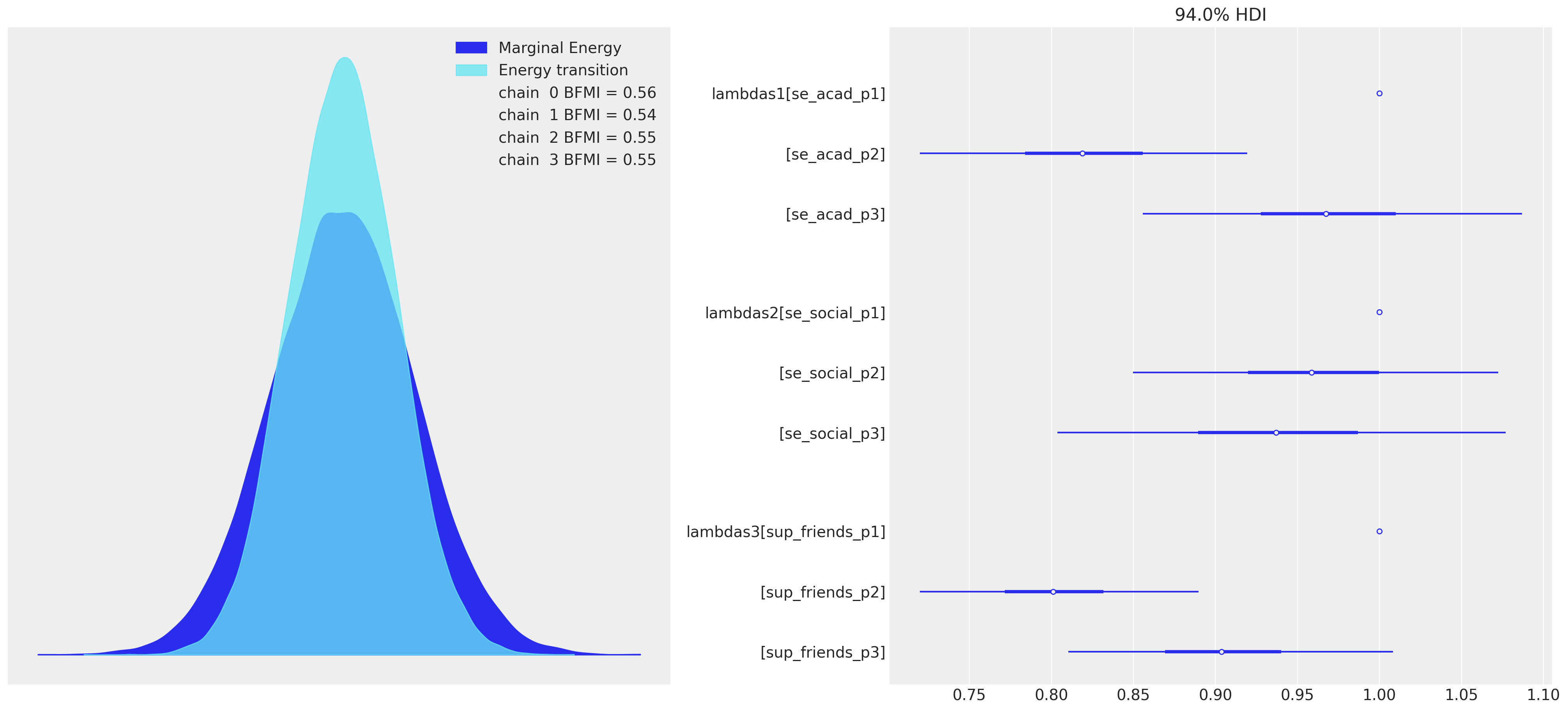
az.plot_forest(idata_mm, var_names=["lambdas1", "lambdas2", "lambdas3"], combined=True, ax=axs[1]);
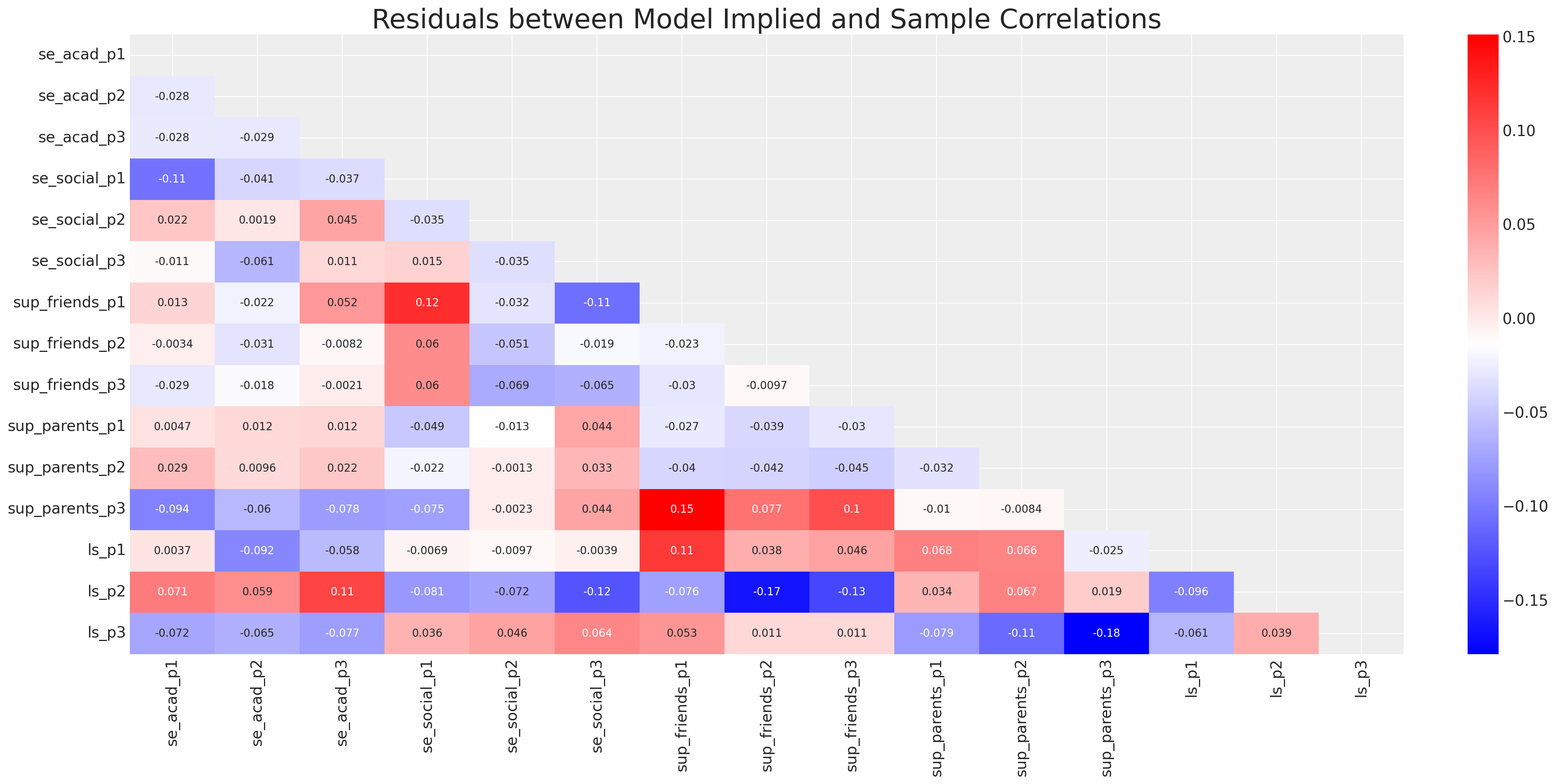
我们还可以通过评估后验预测协方差与样本协方差之间的拟合来提取更典型的模型评估模式。这是一个健全性检查,用于评估局部模型拟合统计量。下面的代码迭代后验预测分布中的抽取,并计算每个抽取上的协方差或相关矩阵,我们计算每个抽取上每个协方差之间的残差,然后对抽取进行平均。
def get_posterior_resids(idata, samples=100, metric="cov"):
resids = []
for i in range(100):
if metric == "cov":
model_cov = pd.DataFrame(
az.extract(idata["posterior_predictive"])["likelihood"][:, :, i]
).cov()
obs_cov = df[drivers].cov()
else:
model_cov = pd.DataFrame(
az.extract(idata["posterior_predictive"])["likelihood"][:, :, i]
).corr()
obs_cov = df[drivers].corr()
model_cov.index = obs_cov.index
model_cov.columns = obs_cov.columns
residuals = model_cov - obs_cov
resids.append(residuals.values.flatten())
residuals_posterior = pd.DataFrame(pd.DataFrame(resids).mean().values.reshape(15, 15))
residuals_posterior.index = obs_cov.index
residuals_posterior.columns = obs_cov.index
return residuals_posterior
residuals_posterior_cov = get_posterior_resids(idata_mm, 2500)
residuals_posterior_corr = get_posterior_resids(idata_mm, 2500, metric="corr")
这些表格可以很好地绘制图表,在图中我们可以突出显示与样本协方差和相关统计量的偏差。
fig, ax = plt.subplots(figsize=(20, 10))
mask = np.triu(np.ones_like(residuals_posterior_corr, dtype=bool))
ax = sns.heatmap(residuals_posterior_corr, annot=True, cmap="bwr", mask=mask)
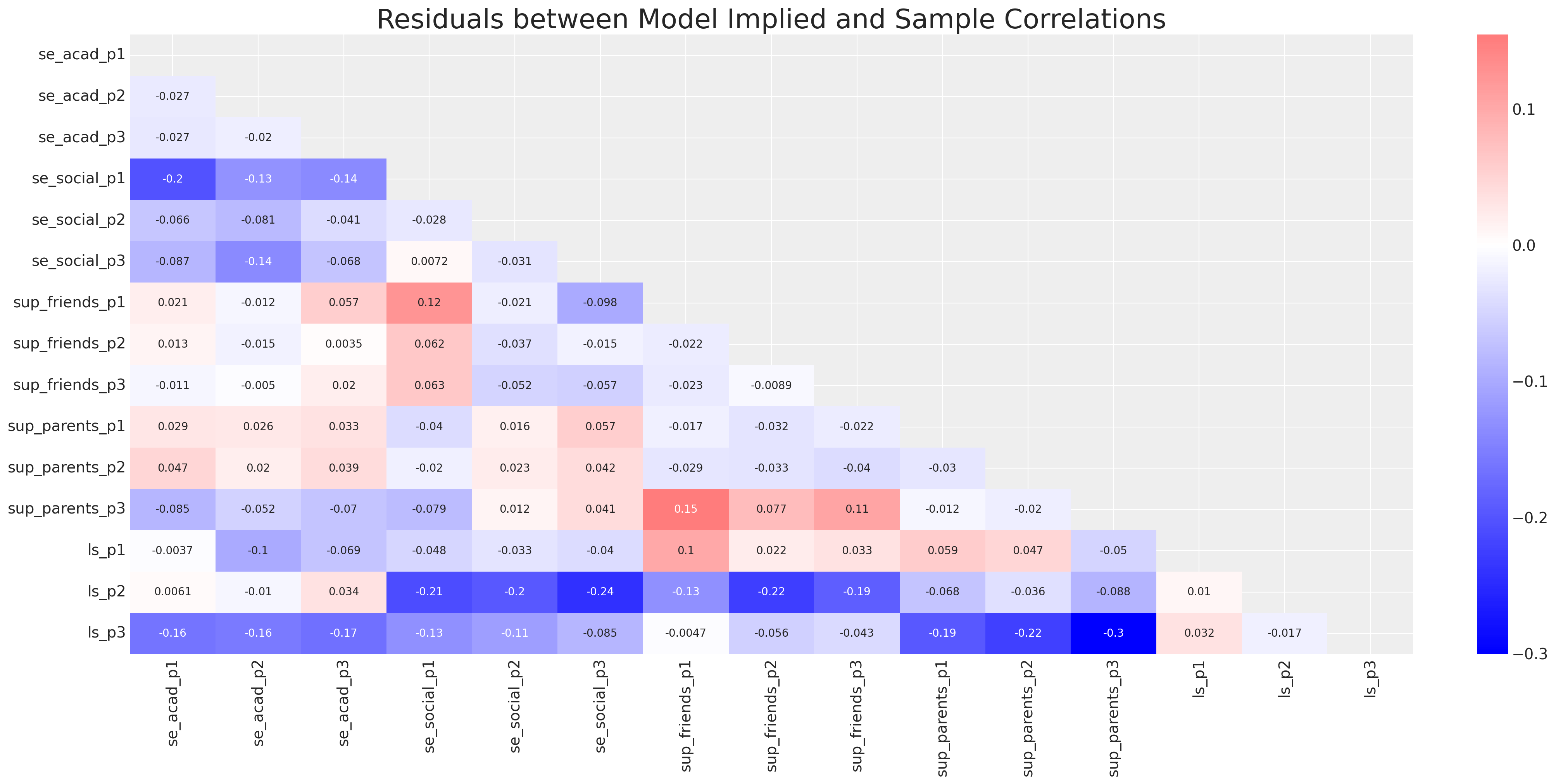
ax.set_title("Residuals between Model Implied and Sample Correlations", fontsize=25);
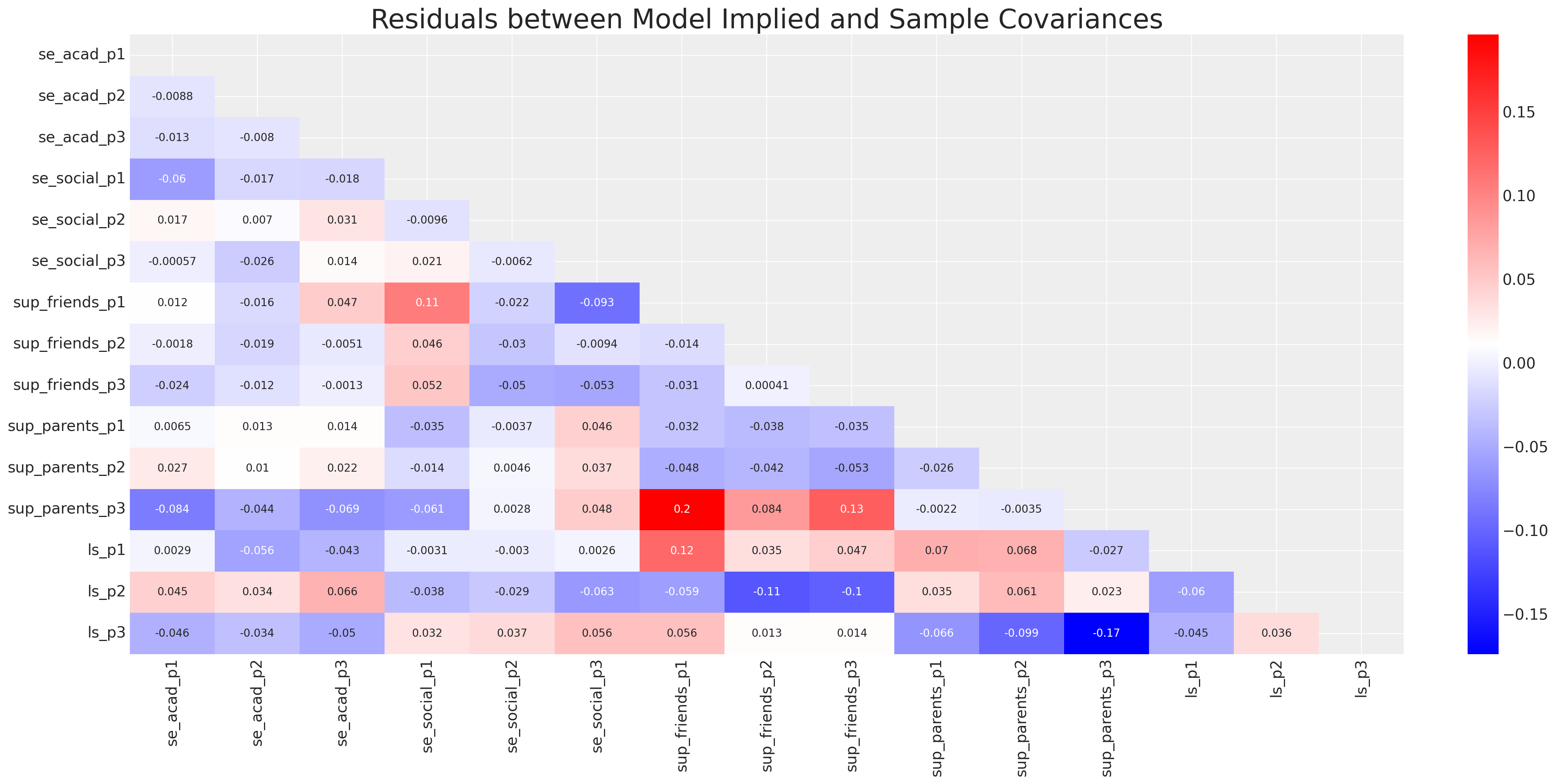
fig, ax = plt.subplots(figsize=(20, 10))
ax = sns.heatmap(residuals_posterior_cov, annot=True, cmap="bwr", mask=mask)
ax.set_title("Residuals between Model Implied and Sample Covariances", fontsize=25);
然而,专注于恢复对这些摘要统计信息的拟合不如恢复观察数据本身那么引人注目和直接。当为每个观察到的指标提取预测后验分布时,我们还可以进行更现代的贝叶斯后验预测检验。
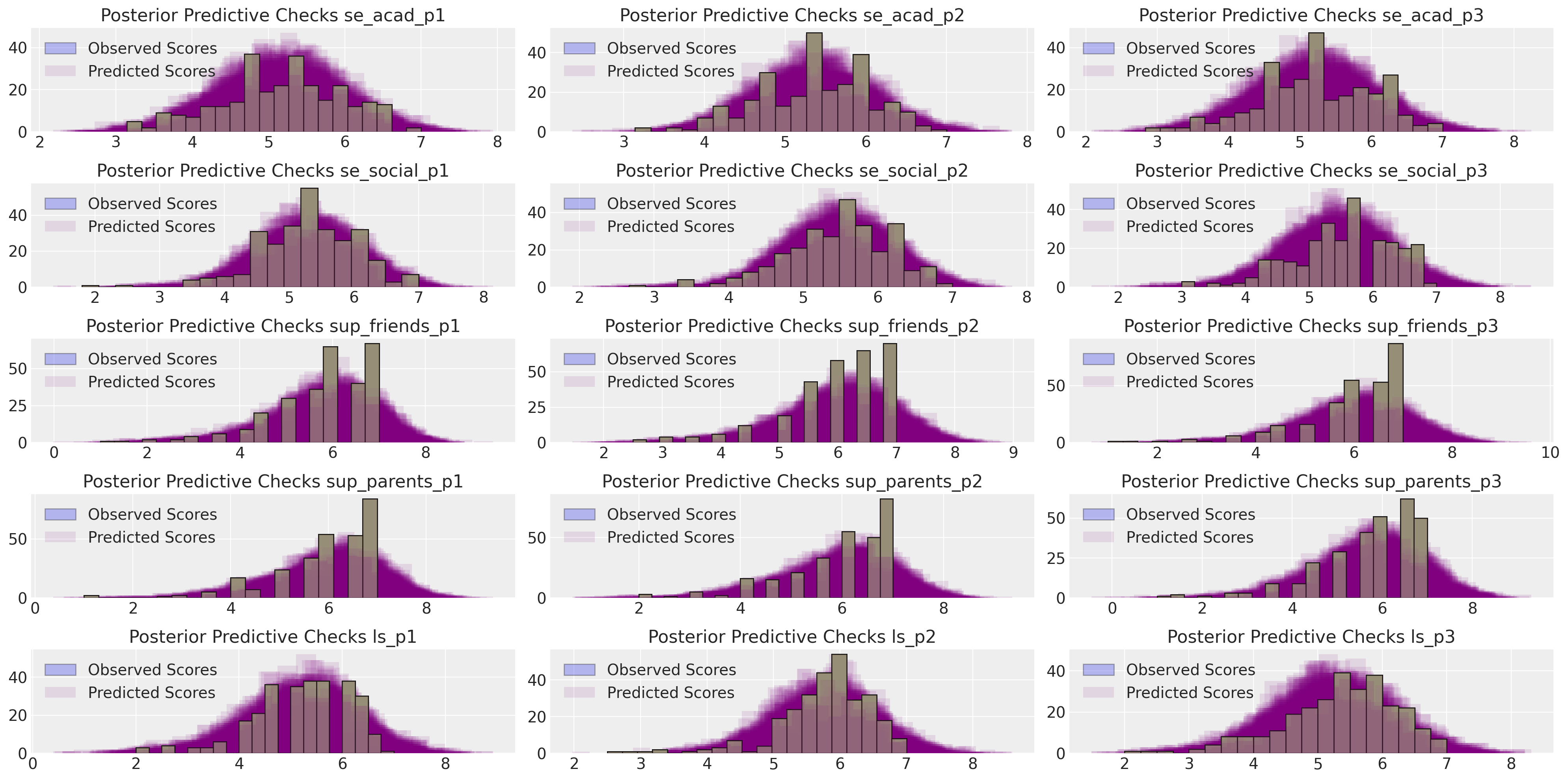
make_ppc(idata_mm, 100, drivers=residuals_posterior_cov.columns, dims=(5, 3));
模型分析#
我们不仅对恢复观察到的数据模式感兴趣,我们还希望有一种方法来提取与潜在结构相关的推论。例如,我们可以提取因子载荷,并计算此因子系统中每个指标变量以及因子本身解释的方差度量。
def make_factor_loadings_df(idata):
factor_loadings = pd.DataFrame(
az.summary(
idata_mm, var_names=["lambdas1", "lambdas2", "lambdas3", "lambdas4", "lambdas5"]
)["mean"]
).reset_index()
factor_loadings["factor"] = factor_loadings["index"].str.split("[", expand=True)[0]
factor_loadings.columns = ["factor_loading", "factor_loading_weight", "factor"]
factor_loadings["factor_loading_weight_sq"] = factor_loadings["factor_loading_weight"] ** 2
factor_loadings["sum_sq_loadings"] = factor_loadings.groupby("factor")[
"factor_loading_weight_sq"
].transform(sum)
factor_loadings["error_variances"] = az.summary(idata_mm, var_names=["Psi"])["mean"].values
factor_loadings["total_indicator_variance"] = (
factor_loadings["factor_loading_weight_sq"] + factor_loadings["error_variances"]
)
factor_loadings["total_variance"] = factor_loadings["total_indicator_variance"].sum()
factor_loadings["indicator_explained_variance"] = (
factor_loadings["factor_loading_weight_sq"] / factor_loadings["total_variance"]
)
factor_loadings["factor_explained_variance"] = (
factor_loadings["sum_sq_loadings"] / factor_loadings["total_variance"]
)
num_cols = [c for c in factor_loadings.columns if not c in ["factor_loading", "factor"]]
return factor_loadings
pd.set_option("display.max_colwidth", 15)
factor_loadings = make_factor_loadings_df(idata_mm)
num_cols = [c for c in factor_loadings.columns if not c in ["factor_loading", "factor"]]
factor_loadings.style.format("{:.2f}", subset=num_cols).background_gradient(
axis=0, subset=["indicator_explained_variance", "factor_explained_variance"]
)
/var/folders/__/ng_3_9pn1f11ftyml_qr69vh0000gn/T/ipykernel_43772/1650813745.py:12: FutureWarning: The provided callable <built-in function sum> is currently using SeriesGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
].transform(sum)
| factor_loading | factor_loading_weight | 因子 | factor_loading_weight_sq | sum_sq_loadings | error_variances | total_indicator_variance | total_variance | indicator_explained_variance | factor_explained_variance | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | lambdas1[se_acad_p1] | 1.00 | lambdas1 | 1.00 | 2.61 | 0.41 | 1.41 | 21.47 | 0.05 | 0.12 |
| 1 | lambdas1[se_acad_p2] | 0.82 | lambdas1 | 0.67 | 2.61 | 0.41 | 1.09 | 21.47 | 0.03 | 0.12 |
| 2 | lambdas1[se_acad_p3] | 0.97 | lambdas1 | 0.94 | 2.61 | 0.47 | 1.41 | 21.47 | 0.04 | 0.12 |
| 3 | lambdas2[se_social_p1] | 1.00 | lambdas2 | 1.00 | 2.81 | 0.43 | 1.43 | 21.47 | 0.05 | 0.13 |
| 4 | lambdas2[se_social_p2] | 0.96 | lambdas2 | 0.92 | 2.81 | 0.36 | 1.29 | 21.47 | 0.04 | 0.13 |
| 5 | lambdas2[se_social_p3] | 0.94 | lambdas2 | 0.88 | 2.81 | 0.55 | 1.43 | 21.47 | 0.04 | 0.13 |
| 6 | lambdas3[sup_friends_p1] | 1.00 | lambdas3 | 1.00 | 2.46 | 0.52 | 1.52 | 21.47 | 0.05 | 0.11 |
| 7 | lambdas3[sup_friends_p2] | 0.80 | lambdas3 | 0.64 | 2.46 | 0.51 | 1.15 | 21.47 | 0.03 | 0.11 |
| 8 | lambdas3[sup_friends_p3] | 0.91 | lambdas3 | 0.82 | 2.46 | 0.62 | 1.44 | 21.47 | 0.04 | 0.11 |
| 9 | lambdas4[sup_parents_p1] | 1.00 | lambdas4 | 1.00 | 3.11 | 0.55 | 1.55 | 21.47 | 0.05 | 0.14 |
| 10 | lambdas4[sup_parents_p2] | 1.04 | lambdas4 | 1.08 | 3.11 | 0.54 | 1.62 | 21.47 | 0.05 | 0.14 |
| 11 | lambdas4[sup_parents_p3] | 1.01 | lambdas4 | 1.02 | 3.11 | 0.68 | 1.70 | 21.47 | 0.05 | 0.14 |
| 12 | lambdas5[ls_p1] | 1.00 | lambdas5 | 1.00 | 2.61 | 0.67 | 1.67 | 21.47 | 0.05 | 0.12 |
| 13 | lambdas5[ls_p2] | 0.79 | lambdas5 | 0.63 | 2.61 | 0.53 | 1.16 | 21.47 | 0.03 | 0.12 |
| 14 | lambdas5[ls_p3] | 0.99 | lambdas5 | 0.98 | 2.61 | 0.62 | 1.61 | 21.47 | 0.05 | 0.12 |
我们可以提取并绘制有序的权重,作为一种特征重要性图。
fig, ax = plt.subplots(figsize=(15, 8))
temp = factor_loadings[["factor_loading", "indicator_explained_variance"]].sort_values(
by="indicator_explained_variance"
)
ax.barh(
temp["factor_loading"], temp["indicator_explained_variance"], align="center", color="slateblue"
)
ax.set_title("Explained Variance");
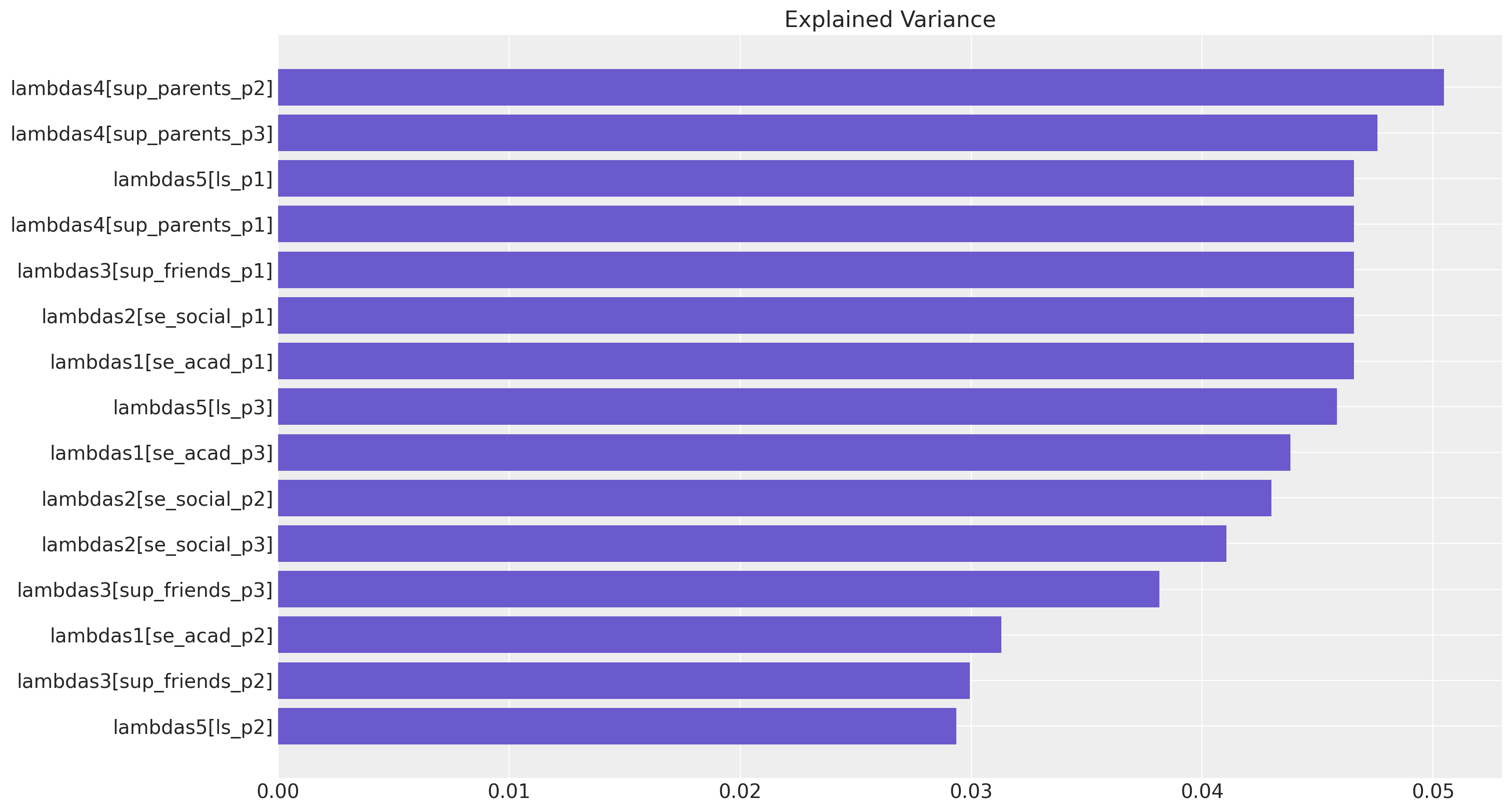
这种观点的目标不一定是像在机器学习环境中那样找到有用的特征,而是帮助理解我们系统中变异的性质。我们还可以提取潜在因子之间的协方差和相关性
显示代码单元格源
cov_df = pd.DataFrame(az.extract(idata_mm["posterior"])["cov"].mean(axis=2))
cov_df.index = ["SE_ACAD", "SE_SOCIAL", "SUP_F", "SUP_P", "LS"]
cov_df.columns = ["SE_ACAD", "SE_SOCIAL", "SUP_F", "SUP_P", "LS"]
correlation_df = pd.DataFrame(az.extract(idata_mm["posterior"])["chol_cov_corr"].mean(axis=2))
correlation_df.index = ["SE_ACAD", "SE_SOCIAL", "SUP_F", "SUP_P", "LS"]
correlation_df.columns = ["SE_ACAD", "SE_SOCIAL", "SUP_F", "SUP_P", "LS"]
fig, axs = plt.subplots(1, 2, figsize=(20, 10))
axs = axs.flatten()
mask = np.triu(np.ones_like(cov_df, dtype=bool))
sns.heatmap(cov_df, annot=True, cmap="Blues", ax=axs[0], mask=mask)
axs[0].set_title("Covariance of Latent Constructs")
axs[1].set_title("Correlation of Latent Constructs")
sns.heatmap(correlation_df, annot=True, cmap="Blues", ax=axs[1], mask=mask);

这突出了生活满意度 LS 结构、父母支持 SUP_P 和社会自我效能感 SE_SOCIAL 之间的强关系。我们也可以在潜在结构的抽取中观察到这些模式
显示代码单元格源
fig, axs = plt.subplots(1, 3, figsize=(15, 10))
axs = axs.flatten()
ax = axs[0]
ax1 = axs[1]
ax2 = axs[2]
az.plot_forest(idata_mm, var_names=["ksi"], combined=True, ax=ax, coords={"latent": ["SUP_P"]})
az.plot_forest(
idata_mm,
var_names=["ksi"],
combined=True,
ax=ax1,
colors="forestgreen",
coords={"latent": ["SE_SOCIAL"]},
)
az.plot_forest(
idata_mm,
var_names=["ksi"],
combined=True,
ax=ax2,
colors="slateblue",
coords={"latent": ["LS"]},
)
ax.set_yticklabels([])
ax.set_xlabel("SUP_P")
ax1.set_yticklabels([])
ax1.set_xlabel("SE_SOCIAL")
ax2.set_yticklabels([])
ax2.set_xlabel("LS")
ax.axvline(-2, color="red")
ax1.axvline(-2, color="red")
ax2.axvline(-2, color="red")
ax.set_title("Individual Parental Support Metric \n On Latent Factor SUP_P")
ax1.set_title("Individual Social Self Efficacy \n On Latent Factor SE_SOCIAL")
ax2.set_title("Individual Life Satisfaction Metric \n On Latent Factor LS")
plt.show();
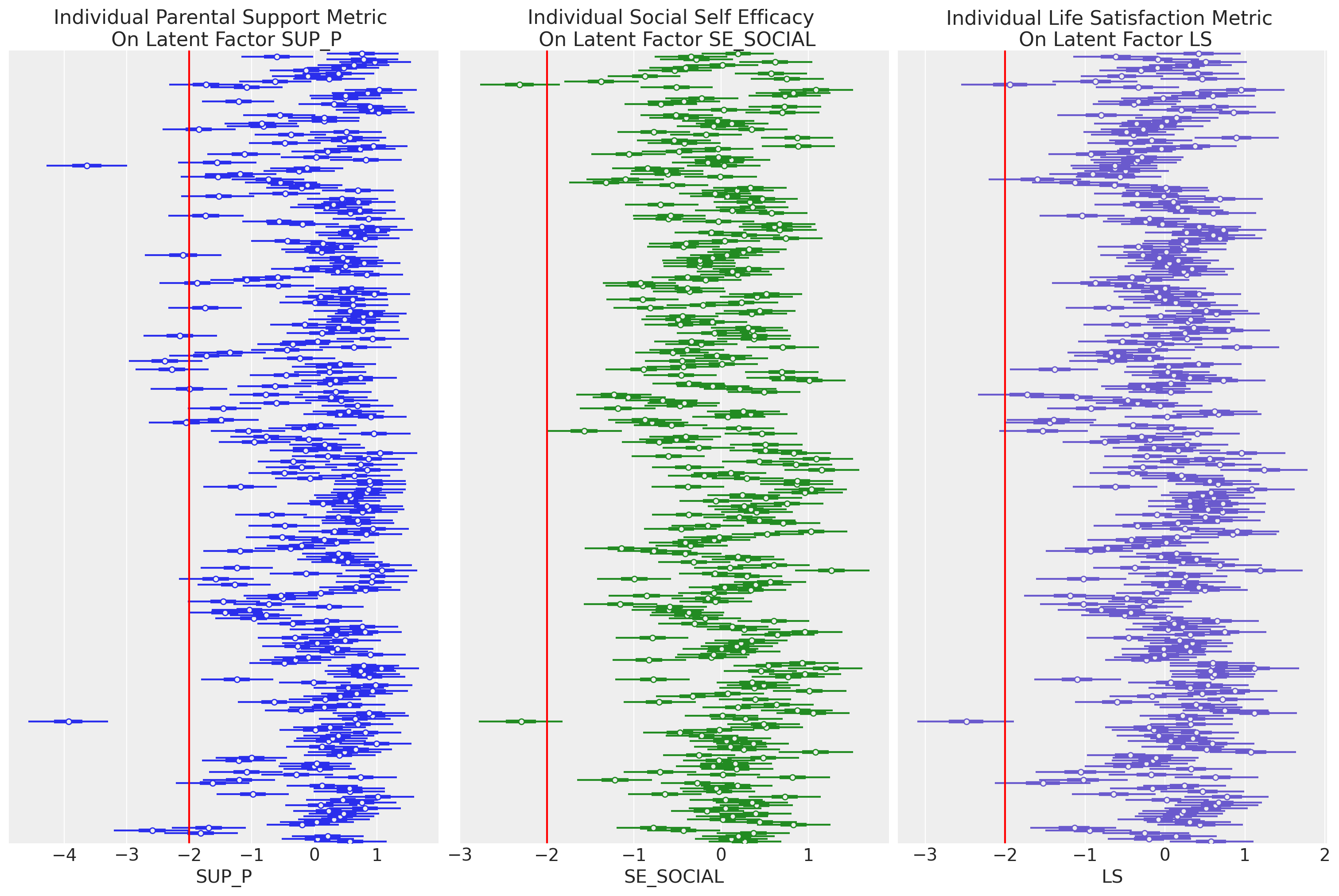
值得在这里强调的是 SUP_P 图左上角的队列,他们的父母支持分数较低,似乎 SE_SOCIAL 分数也较低。这种组合似乎导致了相当标准的 LS 分数,这表明存在某种调节关系。
贝叶斯结构方程模型#
我们现在已经了解了测量模型如何以一种粗略的方式帮助我们理解不同指标变量之间的关系。我们假设了一个潜在因子系统,并推导了这些因子之间的相关性,以帮助我们理解更广泛的感兴趣结构之间的关系强度。这是一种结构方程模型的特例。在 SEM 传统中,我们有兴趣找出变量之间结构关系的各个方面,这意味着希望假设依赖关系和独立关系,以探究我们对系统中影响流动的信念。
对于我们的数据集,我们可以假设以下依赖链
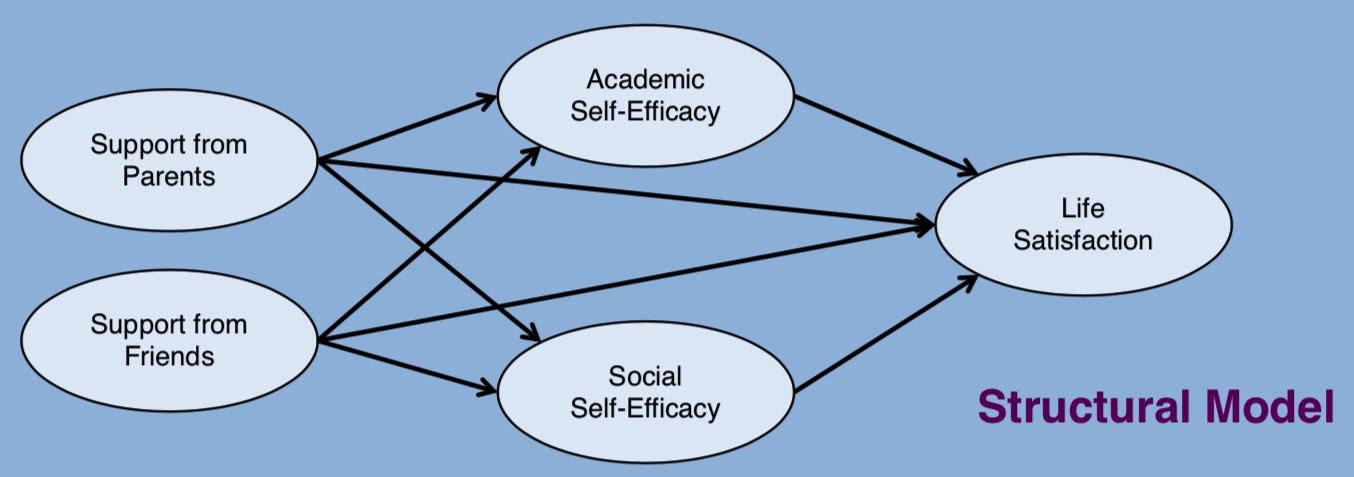
这张图片引入了对依赖性的具体主张,然后问题就变成了如何对这些模式进行建模?在下一节中,我们将以基本测量模型的结构为基础,阐明这些依赖链作为“根”结构的功能方程。这允许评估与以前相同的模型充分性问题,但此外,我们现在可以提出关于潜在结构之间直接和间接关系的问题。特别是,由于我们的重点是是什么驱动生活满意度,我们可以向我们的模型询问父母和同伴支持的中介效应。
模型复杂性和贝叶斯敏感性分析#
这些模型已经很复杂了,现在我们正在向模型添加大量新参数和结构。每个参数都配备了一个先验,该先验塑造了模型规范的含义。这是一个极具表现力的框架,我们可以在其中编码各种各样的依赖关系和相关性。有了这种构建推理模型的自由,我们需要小心评估我们的推论的稳健性。因此,我们将在此处执行快速敏感性分析,以展示此模型的中心含义如何在不同的先验设置下变化。
drivers = [
"se_acad_p1",
"se_acad_p2",
"se_acad_p3",
"se_social_p1",
"se_social_p2",
"se_social_p3",
"sup_friends_p1",
"sup_friends_p2",
"sup_friends_p3",
"sup_parents_p1",
"sup_parents_p2",
"sup_parents_p3",
"ls_p1",
"ls_p2",
"ls_p3",
]
def make_indirect_sem(priors):
coords = {
"obs": list(range(len(df))),
"indicators": drivers,
"indicators_1": ["se_acad_p1", "se_acad_p2", "se_acad_p3"],
"indicators_2": ["se_social_p1", "se_social_p2", "se_social_p3"],
"indicators_3": ["sup_friends_p1", "sup_friends_p2", "sup_friends_p3"],
"indicators_4": ["sup_parents_p1", "sup_parents_p2", "sup_parents_p3"],
"indicators_5": ["ls_p1", "ls_p2", "ls_p3"],
"latent": ["SUP_F", "SUP_P"],
"latent1": ["SUP_F", "SUP_P"],
"latent_regression": ["SUP_F->SE_ACAD", "SUP_P->SE_ACAD", "SUP_F->SE_SOC", "SUP_P->SE_SOC"],
"regression": ["SE_ACAD", "SE_SOCIAL", "SUP_F", "SUP_P"],
}
obs_idx = list(range(len(df)))
with pm.Model(coords=coords) as model:
Psi = pm.InverseGamma("Psi", 5, 10, dims="indicators")
lambdas_ = pm.Normal(
"lambdas_1", priors["lambda"][0], priors["lambda"][1], dims=("indicators_1")
)
lambdas_1 = pm.Deterministic(
"lambdas1", pt.set_subtensor(lambdas_[0], 1), dims=("indicators_1")
)
lambdas_ = pm.Normal(
"lambdas_2", priors["lambda"][0], priors["lambda"][1], dims=("indicators_2")
)
lambdas_2 = pm.Deterministic(
"lambdas2", pt.set_subtensor(lambdas_[0], 1), dims=("indicators_2")
)
lambdas_ = pm.Normal(
"lambdas_3", priors["lambda"][0], priors["lambda"][1], dims=("indicators_3")
)
lambdas_3 = pm.Deterministic(
"lambdas3", pt.set_subtensor(lambdas_[0], 1), dims=("indicators_3")
)
lambdas_ = pm.Normal(
"lambdas_4", priors["lambda"][0], priors["lambda"][1], dims=("indicators_4")
)
lambdas_4 = pm.Deterministic(
"lambdas4", pt.set_subtensor(lambdas_[0], 1), dims=("indicators_4")
)
lambdas_ = pm.Normal(
"lambdas_5", priors["lambda"][0], priors["lambda"][1], dims=("indicators_5")
)
lambdas_5 = pm.Deterministic(
"lambdas5", pt.set_subtensor(lambdas_[0], 1), dims=("indicators_5")
)
tau = pm.Normal("tau", 3, 0.5, dims="indicators")
kappa = 0
sd_dist = pm.Exponential.dist(1.0, shape=2)
chol, _, _ = pm.LKJCholeskyCov(
"chol_cov", n=2, eta=priors["eta"], sd_dist=sd_dist, compute_corr=True
)
cov = pm.Deterministic("cov", chol.dot(chol.T), dims=("latent", "latent1"))
ksi = pm.MvNormal("ksi", kappa, chol=chol, dims=("obs", "latent"))
# Regression Components
beta_r = pm.Normal("beta_r", 0, priors["beta_r"], dims="latent_regression")
beta_r2 = pm.Normal("beta_r2", 0, priors["beta_r2"], dims="regression")
sd_dist1 = pm.Exponential.dist(1.0, shape=2)
resid_chol, _, _ = pm.LKJCholeskyCov(
"resid_chol", n=2, eta=3, sd_dist=sd_dist1, compute_corr=True
)
_ = pm.Deterministic("resid_cov", chol.dot(chol.T))
sigmas_resid = pm.MvNormal("sigmas_resid", kappa, chol=resid_chol)
# SE_ACAD ~ SUP_FRIENDS + SUP_PARENTS
regression_se_acad = pm.Normal(
"regr_se_acad",
beta_r[0] * ksi[obs_idx, 0] + beta_r[1] * ksi[obs_idx, 1],
sigmas_resid[0],
)
# SE_SOCIAL ~ SUP_FRIENDS + SUP_PARENTS
regression_se_social = pm.Normal(
"regr_se_social",
beta_r[2] * ksi[obs_idx, 0] + beta_r[3] * ksi[obs_idx, 1],
sigmas_resid[1],
)
# LS ~ SE_ACAD + SE_SOCIAL + SUP_FRIEND + SUP_PARENTS
regression = pm.Normal(
"regr",
beta_r2[0] * regression_se_acad
+ beta_r2[1] * regression_se_social
+ beta_r2[2] * ksi[obs_idx, 0]
+ beta_r2[3] * ksi[obs_idx, 1],
1,
)
m0 = tau[0] + regression_se_acad * lambdas_1[0]
m1 = tau[1] + regression_se_acad * lambdas_1[1]
m2 = tau[2] + regression_se_acad * lambdas_1[2]
m3 = tau[3] + regression_se_social * lambdas_2[0]
m4 = tau[4] + regression_se_social * lambdas_2[1]
m5 = tau[5] + regression_se_social * lambdas_2[2]
m6 = tau[6] + ksi[obs_idx, 0] * lambdas_3[0]
m7 = tau[7] + ksi[obs_idx, 0] * lambdas_3[1]
m8 = tau[8] + ksi[obs_idx, 0] * lambdas_3[2]
m9 = tau[9] + ksi[obs_idx, 1] * lambdas_4[0]
m10 = tau[10] + ksi[obs_idx, 1] * lambdas_4[1]
m11 = tau[11] + ksi[obs_idx, 1] * lambdas_4[2]
m12 = tau[12] + regression * lambdas_5[0]
m13 = tau[13] + regression * lambdas_5[1]
m14 = tau[14] + regression * lambdas_5[2]
mu = pm.Deterministic(
"mu", pm.math.stack([m0, m1, m2, m3, m4, m5, m6, m7, m8, m9, m10, m11, m12, m13, m14]).T
)
_ = pm.Normal("likelihood", mu, Psi, observed=df[drivers].values)
idata = pm.sample(
10_000,
chains=4,
nuts_sampler="numpyro",
target_accept=0.99,
tune=2000,
idata_kwargs={"log_likelihood": True},
random_seed=110,
)
idata.extend(pm.sample_posterior_predictive(idata))
return model, idata
model_sem0, idata_sem0 = make_indirect_sem(
priors={"eta": 2, "lambda": [1, 1], "beta_r": 0.1, "beta_r2": 0.1}
)
model_sem1, idata_sem1 = make_indirect_sem(
priors={"eta": 2, "lambda": [1, 1], "beta_r": 0.2, "beta_r2": 0.2}
)
model_sem2, idata_sem2 = make_indirect_sem(
priors={"eta": 2, "lambda": [1, 1], "beta_r": 0.5, "beta_r2": 0.5}
)
Compiling...
Compilation time = 0:00:11.696197
Sampling...
Sampling time = 0:01:08.103534
Transforming variables...
Transformation time = 0:00:03.042150
Computing Log Likelihood...
Log Likelihood time = 0:00:01.889064
Sampling: [likelihood]
Compiling...
Compilation time = 0:00:11.975201
Sampling...
Sampling time = 0:01:08.567877
Transforming variables...
Transformation time = 0:00:03.029417
Computing Log Likelihood...
Log Likelihood time = 0:00:02.128598
Sampling: [likelihood]
Compiling...
Compilation time = 0:00:12.106062
Sampling...
Sampling time = 0:01:07.131131
Transforming variables...
Transformation time = 0:00:03.069262
Computing Log Likelihood...
Log Likelihood time = 0:00:01.810234
Sampling: [likelihood]
要观察的主要结构特征是,我们现在向模型添加了大量回归,使得我们在测量模型中视为给定的某些结构现在被导出为其他结构的线性组合。由于我们删除了 SE_SOCIAL 和 SE_ACAD 之间的相关效应,因此我们通过向其回归方程添加相关的误差项来重新引入它们相关的可能性。在 lavaan 语法中,我们的目标是类似
Measurement model
SUP_Parents =~ sup_parents_p1 + sup_parents_p2 + sup_parents_p3
SUP_Friends =~ sup_friends_p1 + sup_friends_p2 + sup_friends_p3
SE_Academic =~ se_acad_p1 + se_acad_p2 + se_acad_p3
SE_Social =~ se_social_p1 + se_social_p2 + se_social_p3
LS =~ ls_p1 + ls_p2 + ls_p3
Regressions
SE_Academic ~ SUP_Parents + SUP_Friends
SE_Social ~ SUP_Parents + SUP_Friends
LS ~ SE_Academic + SE_Social + SUP_Parents + SUP_Friends
Residual covariances
SE_Academic ~~ SE_Social
pm.model_to_graphviz(model_sem0)

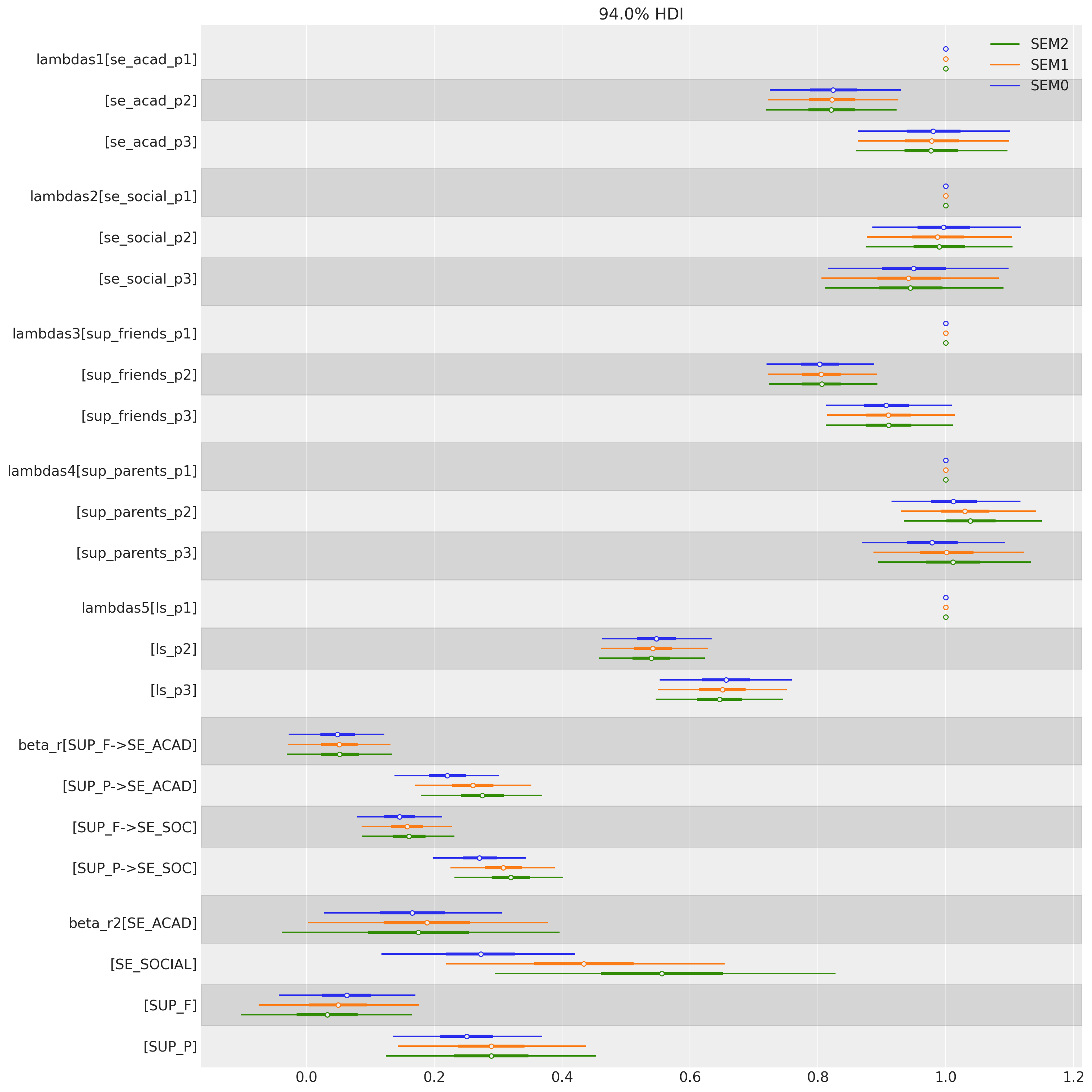
值得暂停一下来检查此图中草绘的依赖关系的性质。我们可以在这里看到我们如何替换了更简单的测量模型结构,并添加了三个回归函数,这些函数替换了来自多元正态分布 \(Ksi\) 的抽取。换句话说,我们将依赖关系表示为一系列回归,所有回归都在一个模型中。接下来,我们将看到参数估计如何在模型先验规范中发生变化。请注意,与回归系数相比,因子载荷的相对稳定性。
fig, ax = plt.subplots(figsize=(15, 15))
az.plot_forest(
[idata_sem0, idata_sem1, idata_sem2],
model_names=["SEM0", "SEM1", "SEM2"],
var_names=["lambdas1", "lambdas2", "lambdas3", "lambdas4", "lambdas5", "beta_r", "beta_r2"],
combined=True,
ax=ax,
);
模型评估检查#
对模型性能的快速评估表明,在恢复样本协方差结构方面,我们不如使用更简单的测量模型做得好。
residuals_posterior_cov = get_posterior_resids(idata_sem0, 2500)
residuals_posterior_corr = get_posterior_resids(idata_sem0, 2500, metric="corr")
fig, ax = plt.subplots(figsize=(20, 10))
mask = np.triu(np.ones_like(residuals_posterior_corr, dtype=bool))
ax = sns.heatmap(residuals_posterior_corr, annot=True, cmap="bwr", center=0, mask=mask)
ax.set_title("Residuals between Model Implied and Sample Correlations", fontsize=25);
但后验预测检验看起来仍然合理。我们关注的生活满意度量似乎得到了很好的恢复。
make_ppc(idata_sem0, 100, drivers=drivers, dims=(5, 3))
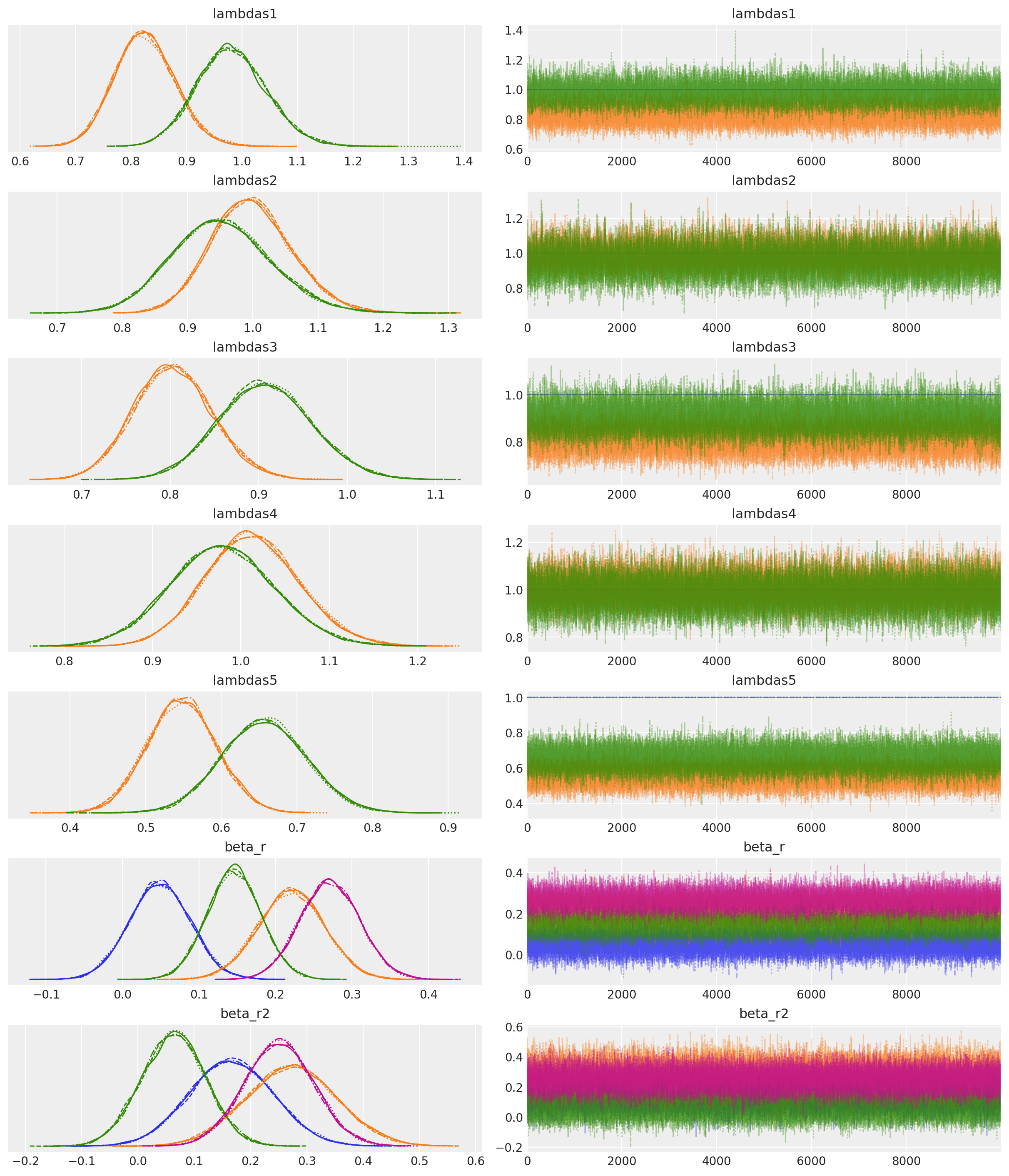
模型诊断显示总体上看起来健康的迹线图,有一些发散,但有效样本量和 r-hat 度量都很好,因此我们应该普遍感到满意,模型已很好地收敛到后验分布。
az.plot_trace(
idata_sem0,
var_names=["lambdas1", "lambdas2", "lambdas3", "lambdas4", "lambdas5", "beta_r", "beta_r2"],
);
az.summary(
idata_sem0,
var_names=[
"lambdas1",
"lambdas2",
"lambdas3",
"lambdas4",
"lambdas5",
"beta_r",
"beta_r2",
"Psi",
"tau",
],
)
| 均值 | 标准差 | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| lambdas1[se_acad_p1] | 1.000 | 0.000 | 1.000 | 1.000 | 0.000 | 0.000 | 40000.0 | 40000.0 | NaN |
| lambdas1[se_acad_p2] | 0.825 | 0.055 | 0.725 | 0.930 | 0.001 | 0.000 | 9636.0 | 15616.0 | 1.0 |
| lambdas1[se_acad_p3] | 0.982 | 0.063 | 0.863 | 1.101 | 0.001 | 0.000 | 8860.0 | 14667.0 | 1.0 |
| lambdas2[se_social_p1] | 1.000 | 0.000 | 1.000 | 1.000 | 0.000 | 0.000 | 40000.0 | 40000.0 | NaN |
| lambdas2[se_social_p2] | 0.999 | 0.062 | 0.885 | 1.118 | 0.001 | 0.001 | 5688.0 | 9867.0 | 1.0 |
| lambdas2[se_social_p3] | 0.952 | 0.075 | 0.816 | 1.098 | 0.001 | 0.001 | 9841.0 | 16162.0 | 1.0 |
| lambdas3[sup_friends_p1] | 1.000 | 0.000 | 1.000 | 1.000 | 0.000 | 0.000 | 40000.0 | 40000.0 | NaN |
| lambdas3[sup_friends_p2] | 0.804 | 0.045 | 0.720 | 0.888 | 0.000 | 0.000 | 10940.0 | 18878.0 | 1.0 |
| lambdas3[sup_friends_p3] | 0.908 | 0.052 | 0.813 | 1.010 | 0.000 | 0.000 | 12075.0 | 20292.0 | 1.0 |
| lambdas4[sup_parents_p1] | 1.000 | 0.000 | 1.000 | 1.000 | 0.000 | 0.000 | 40000.0 | 40000.0 | NaN |
| lambdas4[sup_parents_p2] | 1.013 | 0.054 | 0.915 | 1.117 | 0.001 | 0.000 | 8953.0 | 15516.0 | 1.0 |
| lambdas4[sup_parents_p3] | 0.979 | 0.059 | 0.869 | 1.093 | 0.001 | 0.000 | 12016.0 | 19450.0 | 1.0 |
| lambdas5[ls_p1] | 1.000 | 0.000 | 1.000 | 1.000 | 0.000 | 0.000 | 40000.0 | 40000.0 | NaN |
| lambdas5[ls_p2] | 0.547 | 0.046 | 0.463 | 0.634 | 0.000 | 0.000 | 23600.0 | 28513.0 | 1.0 |
| lambdas5[ls_p3] | 0.656 | 0.056 | 0.552 | 0.759 | 0.000 | 0.000 | 21916.0 | 27988.0 | 1.0 |
| beta_r[SUP_F->SE_ACAD] | 0.049 | 0.040 | -0.028 | 0.122 | 0.000 | 0.000 | 33619.0 | 30265.0 | 1.0 |
| beta_r[SUP_P->SE_ACAD] | 0.220 | 0.043 | 0.138 | 0.301 | 0.000 | 0.000 | 26087.0 | 27608.0 | 1.0 |
| beta_r[SUP_F->SE_SOC] | 0.146 | 0.035 | 0.080 | 0.213 | 0.000 | 0.000 | 26552.0 | 29710.0 | 1.0 |
| beta_r[SUP_P->SE_SOC] | 0.271 | 0.039 | 0.198 | 0.344 | 0.000 | 0.000 | 18597.0 | 25964.0 | 1.0 |
| beta_r2[SE_ACAD] | 0.166 | 0.074 | 0.028 | 0.305 | 0.000 | 0.000 | 41792.0 | 31794.0 | 1.0 |
| beta_r2[SE_SOCIAL] | 0.272 | 0.080 | 0.118 | 0.420 | 0.000 | 0.000 | 42014.0 | 31550.0 | 1.0 |
| beta_r2[SUP_F] | 0.063 | 0.057 | -0.043 | 0.171 | 0.000 | 0.000 | 34544.0 | 27449.0 | 1.0 |
| beta_r2[SUP_P] | 0.251 | 0.062 | 0.136 | 0.369 | 0.000 | 0.000 | 29584.0 | 30999.0 | 1.0 |
| Psi[se_acad_p1] | 0.417 | 0.029 | 0.362 | 0.471 | 0.000 | 0.000 | 11409.0 | 16465.0 | 1.0 |
| Psi[se_acad_p2] | 0.413 | 0.024 | 0.366 | 0.457 | 0.000 | 0.000 | 19369.0 | 24906.0 | 1.0 |
| Psi[se_acad_p3] | 0.462 | 0.028 | 0.408 | 0.516 | 0.000 | 0.000 | 17531.0 | 22823.0 | 1.0 |
| Psi[se_social_p1] | 0.444 | 0.027 | 0.394 | 0.494 | 0.000 | 0.000 | 14886.0 | 22035.0 | 1.0 |
| Psi[se_social_p2] | 0.338 | 0.026 | 0.291 | 0.389 | 0.000 | 0.000 | 10327.0 | 17290.0 | 1.0 |
| Psi[se_social_p3] | 0.557 | 0.029 | 0.503 | 0.610 | 0.000 | 0.000 | 29639.0 | 29036.0 | 1.0 |
| Psi[sup_friends_p1] | 0.517 | 0.039 | 0.444 | 0.591 | 0.000 | 0.000 | 10615.0 | 15242.0 | 1.0 |
| Psi[sup_friends_p2] | 0.508 | 0.031 | 0.450 | 0.566 | 0.000 | 0.000 | 18625.0 | 24298.0 | 1.0 |
| Psi[sup_friends_p3] | 0.624 | 0.036 | 0.556 | 0.691 | 0.000 | 0.000 | 21581.0 | 25635.0 | 1.0 |
| Psi[sup_parents_p1] | 0.541 | 0.035 | 0.477 | 0.609 | 0.000 | 0.000 | 14766.0 | 22528.0 | 1.0 |
| Psi[sup_parents_p2] | 0.537 | 0.037 | 0.468 | 0.605 | 0.000 | 0.000 | 13008.0 | 18715.0 | 1.0 |
| Psi[sup_parents_p3] | 0.684 | 0.038 | 0.612 | 0.754 | 0.000 | 0.000 | 21999.0 | 26864.0 | 1.0 |
| Psi[ls_p1] | 0.537 | 0.051 | 0.442 | 0.633 | 0.001 | 0.000 | 6824.0 | 10978.0 | 1.0 |
| Psi[ls_p2] | 0.552 | 0.030 | 0.496 | 0.608 | 0.000 | 0.000 | 21921.0 | 25170.0 | 1.0 |
| Psi[ls_p3] | 0.670 | 0.036 | 0.603 | 0.740 | 0.000 | 0.000 | 19160.0 | 24500.0 | 1.0 |
| tau[se_acad_p1] | 5.058 | 0.048 | 4.966 | 5.148 | 0.001 | 0.001 | 4545.0 | 10287.0 | 1.0 |
| tau[se_acad_p2] | 5.266 | 0.042 | 5.186 | 5.345 | 0.001 | 0.000 | 5105.0 | 12105.0 | 1.0 |
| tau[se_acad_p3] | 5.115 | 0.049 | 5.022 | 5.208 | 0.001 | 0.000 | 4915.0 | 12071.0 | 1.0 |
| tau[se_social_p1] | 5.175 | 0.046 | 5.087 | 5.262 | 0.001 | 0.001 | 3954.0 | 9674.0 | 1.0 |
| tau[se_social_p2] | 5.364 | 0.043 | 5.283 | 5.444 | 0.001 | 0.001 | 3632.0 | 8857.0 | 1.0 |
| tau[se_social_p3] | 5.327 | 0.049 | 5.236 | 5.421 | 0.001 | 0.000 | 5021.0 | 11942.0 | 1.0 |
| tau[sup_friends_p1] | 5.607 | 0.070 | 5.473 | 5.735 | 0.001 | 0.001 | 3545.0 | 7220.0 | 1.0 |
| tau[sup_friends_p2] | 5.864 | 0.059 | 5.754 | 5.979 | 0.001 | 0.001 | 3903.0 | 8593.0 | 1.0 |
| tau[sup_friends_p3] | 5.822 | 0.068 | 5.696 | 5.954 | 0.001 | 0.001 | 4102.0 | 8858.0 | 1.0 |
| tau[sup_parents_p1] | 5.769 | 0.068 | 5.641 | 5.895 | 0.001 | 0.001 | 3000.0 | 7066.0 | 1.0 |
| tau[sup_parents_p2] | 5.719 | 0.068 | 5.587 | 5.843 | 0.001 | 0.001 | 3132.0 | 7931.0 | 1.0 |
| tau[sup_parents_p3] | 5.512 | 0.071 | 5.378 | 5.644 | 0.001 | 0.001 | 3647.0 | 9103.0 | 1.0 |
| tau[ls_p1] | 5.010 | 0.073 | 4.873 | 5.149 | 0.001 | 0.001 | 4056.0 | 9242.0 | 1.0 |
| tau[ls_p2] | 5.671 | 0.050 | 5.578 | 5.765 | 0.001 | 0.000 | 5777.0 | 13336.0 | 1.0 |
| tau[ls_p3] | 5.096 | 0.060 | 4.984 | 5.210 | 0.001 | 0.001 | 5766.0 | 12740.0 | 1.0 |
其他模型也具有类似的诊断结果。我们现在继续评估直接和间接效应的问题,这些问题在更简单的测量模型中是模糊不清的。我的意思是,我们追踪影响生活满意度的总路径,并评估父母和同伴支持的相对影响强度。
间接和直接效应#
我们现在转向已编码到模型图中的其他回归结构。首先,我们提取回归系数
fig, axs = plt.subplots(1, 2, figsize=(20, 8))
az.plot_energy(idata_sem0, ax=axs[0])
az.plot_forest(idata_sem0, var_names=["beta_r", "beta_r2"], combined=True, ax=axs[1])
axs[1].axvline(0, color="red", label="zero-effect")
axs[1].legend();
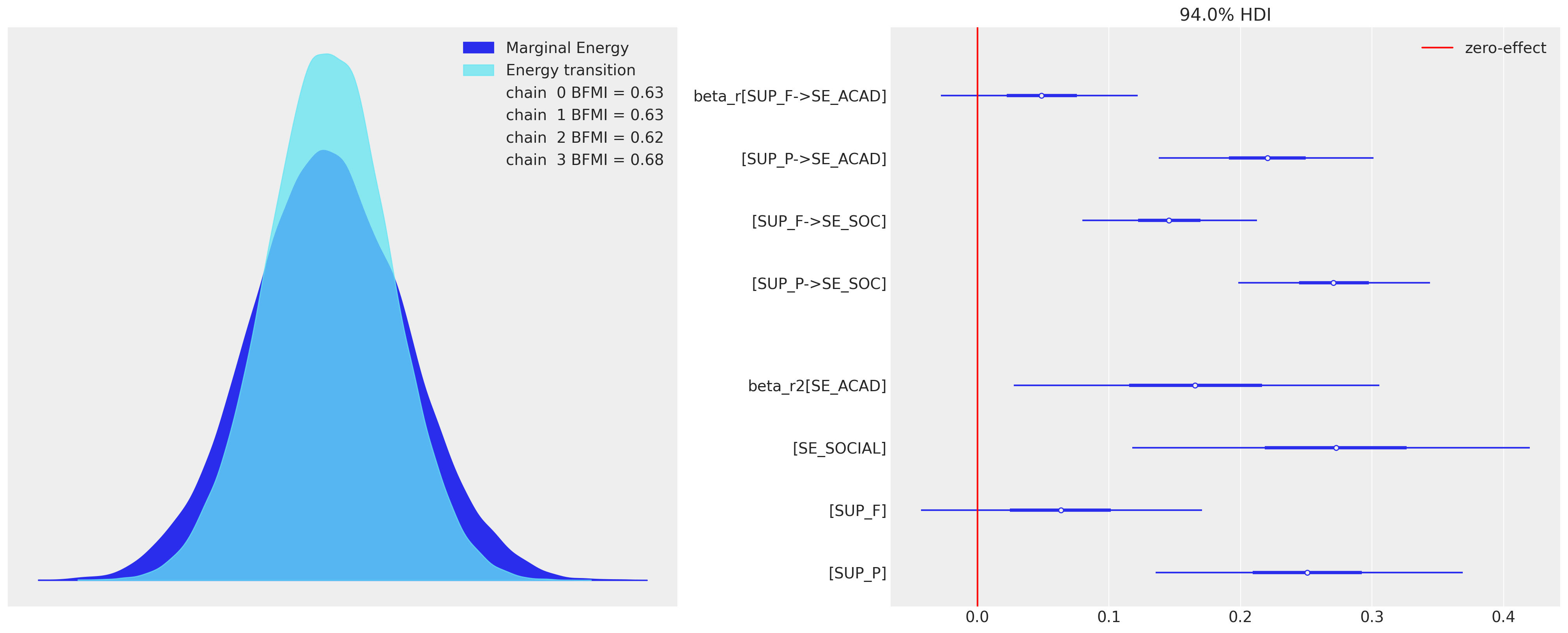
这些系数表明,与我们看到的父母支持相比,同伴支持的影响的相对权重较小。当我们通过 DAG 或回归系数链追踪累积因果效应(直接和间接)时,这一点得到了证实。
def calculate_effects(idata, var="SUP_P"):
summary_df = az.summary(idata, var_names=["beta_r", "beta_r2"])
# Indirect Paths
## VAR -> SE_SOC ->LS
indirect_parent_soc = (
summary_df.loc[f"beta_r[{var}->SE_SOC]"]["mean"]
* summary_df.loc["beta_r2[SE_SOCIAL]"]["mean"]
)
## VAR -> SE_SOC ->LS
indirect_parent_acad = (
summary_df.loc[f"beta_r[{var}->SE_ACAD]"]["mean"]
* summary_df.loc["beta_r2[SE_ACAD]"]["mean"]
)
## Total Indirect Effects
total_indirect = indirect_parent_soc + indirect_parent_acad
## Total Effects
total_effect = total_indirect + summary_df.loc[f"beta_r2[{var}]"]["mean"]
return pd.DataFrame(
[[indirect_parent_soc, indirect_parent_acad, total_indirect, total_effect]],
columns=[
f"{var} -> SE_SOC ->LS",
f"{var} -> SE_ACAD ->LS",
f"Total Indirect Effects {var}",
f"Total Effects {var}",
],
)
重要的是,我们在这里看到了先验对隐含关系的影响。当我们使先验更接近 0 时,父母支持的总效应会从 0.5 向下移动,而同伴支持则保持相对稳定,约为 0.10。然而,仍然清楚的是,父母支持的影响使同伴支持的影响相形见绌。
summary_p = pd.concat(
[calculate_effects(idata_sem0), calculate_effects(idata_sem1), calculate_effects(idata_sem2)]
)
summary_p.index = ["SEM0", "SEM1", "SEM2"]
summary_p
| SUP_P -> SE_SOC ->LS | SUP_P -> SE_ACAD ->LS | SUP_P 的总间接效应 | SUP_P 的总效应 | |
|---|---|---|---|---|
| SEM0 | 0.073712 | 0.03652 | 0.110232 | 0.361232 |
| SEM1 | 0.133672 | 0.04914 | 0.182812 | 0.471812 |
| SEM2 | 0.177920 | 0.04840 | 0.226320 | 0.515320 |
由于父母支持的估计影响的敏感性随着我们对方差的先验而强烈变化。这是一个模型设计中理论选择作用的实质性例子。我们应该在多大程度上相信父母和同伴效应不会对生活满意度产生影响?我倾向于认为,如果我们试图将效应缩小到零,那么我们就太保守了,应该更喜欢不那么保守的模型。然而,这里的例子不是为了争论这个问题,而是为了证明敏感性检查的重要性。
summary_f = pd.concat(
[
calculate_effects(idata_sem0, "SUP_F"),
calculate_effects(idata_sem1, "SUP_F"),
calculate_effects(idata_sem2, "SUP_F"),
]
)
summary_f.index = ["SEM0", "SEM1", "SEM2"]
summary_f
| SUP_F -> SE_SOC ->LS | SUP_F -> SE_ACAD ->LS | SUP_F 的总间接效应 | 总效应 SUP_F | |
|---|---|---|---|---|
| SEM0 | 0.039712 | 0.008134 | 0.047846 | 0.110846 |
| SEM1 | 0.068572 | 0.009828 | 0.078400 | 0.127400 |
| SEM2 | 0.089516 | 0.009152 | 0.098668 | 0.130668 |
计算全局模型拟合度#
我们还可以计算全局模型拟合度的度量。在这里,我们有些不公平地比较了测量模型和我们 SEM 模型的各种形式。SEM 模型试图阐明更复杂的结构,并且在针对相对简单模型的全局拟合度的简单度量中可能会受到影响。这种复杂性并非任意的,您需要就表达能力与全局模型拟合度相对于观察到的数据点之间的权衡做出决定。
compare_df = az.compare(
{"SEM0": idata_sem0, "SEM1": idata_sem1, "SEM2": idata_sem2, "MM": idata_mm}
)
compare_df
/Users/nathanielforde/mambaforge/envs/pymc_causal/lib/python3.11/site-packages/arviz/stats/stats.py:309: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas. Value 'True' has dtype incompatible with float64, please explicitly cast to a compatible dtype first.
df_comp.loc[val] = (
/Users/nathanielforde/mambaforge/envs/pymc_causal/lib/python3.11/site-packages/arviz/stats/stats.py:309: FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas. Value 'log' has dtype incompatible with float64, please explicitly cast to a compatible dtype first.
df_comp.loc[val] = (
| 秩 | elpd_loo | p_loo | elpd_diff | 权重 | se | dse | 警告 | 尺度 | |
|---|---|---|---|---|---|---|---|---|---|
| MM | 0 | -3728.300062 | 994.604514 | 0.000000 | 8.023087e-01 | 65.332293 | 0.000000 | 真 | log |
| SEM0 | 1 | -3778.256742 | 1109.385888 | 49.956680 | 1.976913e-01 | 64.764420 | 13.618924 | 真 | log |
| SEM1 | 2 | -3781.419677 | 1104.681730 | 53.119615 | 3.276563e-15 | 64.853007 | 13.459803 | 真 | log |
| SEM2 | 3 | -3782.787099 | 1102.006963 | 54.487037 | 0.000000e+00 | 64.871911 | 13.330740 | 真 | log |
结论#
我们刚刚了解了如何从思考抽象心理测量结构的测量,到评估这些潜在结构之间复杂的相关性和协方差模式,再到评估潜在因素之间的假设因果结构。这是一次关于心理测量模型以及 SEM 和 CFA 模型的表达能力的旋风式巡览,我们最终将其与因果推断领域联系起来!这不是偶然,而是因果关系问题位于大多数建模努力核心的证据。当我们对变量的任何类型的复杂联合分布感兴趣时,我们可能对系统的因果结构感兴趣——一些观察到的指标的实现值如何依赖于或与其他指标相关?重要的是,我们需要了解这些观察结果是如何实现的,而不会通过幼稚或混淆的推断将简单的相关性与因果关系混淆。
Mislevy 和 Levy 通过关注德菲内蒂定理在通过贝叶斯推断恢复可交换性中的作用,突出了这种联系。根据德菲内蒂定理,可交换变量序列的分布可以表示为条件独立变量的混合。
这种表示形式允许对系统提出实质性声明。因此,如果我们正确指定条件分布,我们就可以恢复使用精心设计的模型进行推断的条件,因为受试者的结果被认为在我们模型的条件下是可交换的。混合分布只是我们模型条件化的参数向量。这在 SEM 和 CFA 模型中表现得很好,因为我们明确地构建了系统的交互作用,以消除偏差依赖结构并允许清晰的推断。保持潜在结构的固定水平,我们期望能够得出关于指标度量的预期实现的通用声明。
[条]件独立性不是我们可以被动等待的自然恩赐,而是一种心理上的必然性,我们通过以特定的方式组织我们的知识来满足这种必然性。在这种组织中,一个重要的工具是识别在可观察变量之间引起条件独立性的中间变量;如果我们的词汇表中没有这样的变量,我们就创造它们。例如,在医学诊断中,当某些症状直接相互影响时,医学界会为这种相互作用发明一个名称(例如“综合征”、“并发症”、“病理状态”),并将其视为一种新的辅助变量,从而引起条件独立性。” - Pearl 引用于 Levy 和 Mislevy [2020] 第 61 页
正是这种对条件化结构的刻意而谨慎的关注,将看似不同的心理测量学和因果推断学科结合在一起。这两个学科都培养了对数据生成过程结构的仔细思考,更重要的是,它们提出了条件化策略,以更好地针对一些感兴趣的估计量。两者都很好地用概率编程语言(如 PyMC)的富有表现力的词汇表达出来。我们鼓励您自行探索丰富的可能性!
参考文献#
水印#
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor
Last updated: Wed Sep 25 2024
Python implementation: CPython
Python version : 3.11.7
IPython version : 8.20.0
pytensor: 2.18.6
pandas : 2.2.0
pymc : 5.10.3
arviz : 0.17.0
matplotlib: 3.8.2
pytensor : 2.18.6
numpy : 1.24.4
seaborn : 0.13.2
Watermark: 2.4.3