示例:Mauna Loa CO\(_2\) 持续#
此 GP 示例展示了如何:
使用 NUTS 拟合完全贝叶斯 GP
对位置不确定的模型输入进行建模(“x”中的不确定性)
设计半参数高斯过程模型
构建突变点协方差函数/核函数
定义自定义均值和自定义协方差函数

冰芯数据#
我们将要查看的第一个数据集是来自冰芯数据的 CO2 测量值。此数据可追溯到公元 13 年。1958 年之后的数据是冰芯测量值和来自 Mauna Loa 更精确数据的平均值。我非常感谢伯尔尼大学的 Tobias Erhardt 慷慨地分享了关于某些流程实际运作方式的科学见解。 当然,任何错误都是我自己的。
此数据不如 Mauna Loa 大气 CO2 测量值准确。落在南极洲的雪逐渐积累并随着时间推移硬化成冰,这被称为粒雪。在劳德姆冰芯中测量的 CO2 来自冰中捕获的气泡。如果将这些冰快速冷冻,则气泡中包含的 CO2 量将反映冷冻时大气中 CO2 的量和时间。相反,这个过程是逐渐发生的,因此捕获的空气有时间在整个凝固的冰中扩散。粒雪的分层、冻结和凝固过程发生在数年尺度上。对于此处使用的劳德姆数据,数据中列出的 CO2 测量值代表大约 2-4 年的总平均 CO2。
此外,数据点的顺序是固定的。较老的冰层不可能最终位于较新的冰层之上。这强制我们对测量位置设置先验,其顺序受到限制。
冰芯测量值的日期存在一些不确定性。由于冰层每年自身分层,它们在年份级别上可能是准确的,但日期不太可能在进行测量时的季节方面可靠。此外,观察到的 CO2 水平可能是全年总体水平的某种平均值。
正如我们在之前的示例中看到的那样,CO2 水平存在强烈的季节性成分,这在此数据集中是无法观察到的。在 PyMC3 中,我们可以轻松地同时包含 \(y\) 中的误差和 \(x\) 中的误差。为了演示这一点,我们删除了数据的后半部分(这些数据与 Mauna Loa 读数平均),因此我们只有冰芯测量值。我们使用 No-U-Turn MCMC 采样器拟合高斯过程模型。
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc3 as pm
import theano
import theano.tensor as tt
%config InlineBackend.figure_format = 'retina'
RANDOM_SEED = 8927
np.random.seed(RANDOM_SEED)
az.style.use("arviz-darkgrid")
ice = pd.read_csv(pm.get_data("merged_ice_core_yearly.csv"), header=26)
ice.columns = ["year", "CO2"]
ice["CO2"] = ice["CO2"].astype(np.float)
#### DATA AFTER 1958 is an average of ice core and mauna loa data, so remove it
ice = ice[ice["year"] <= 1958]
print("Number of data points:", len(ice))
Number of data points: 111
fig = plt.figure(figsize=(9, 4))
ax = plt.gca()
ax.plot(ice.year.values, ice.CO2.values, ".k")
ax.set_xlabel("Year")
ax.set_ylabel("CO2 (ppm)");
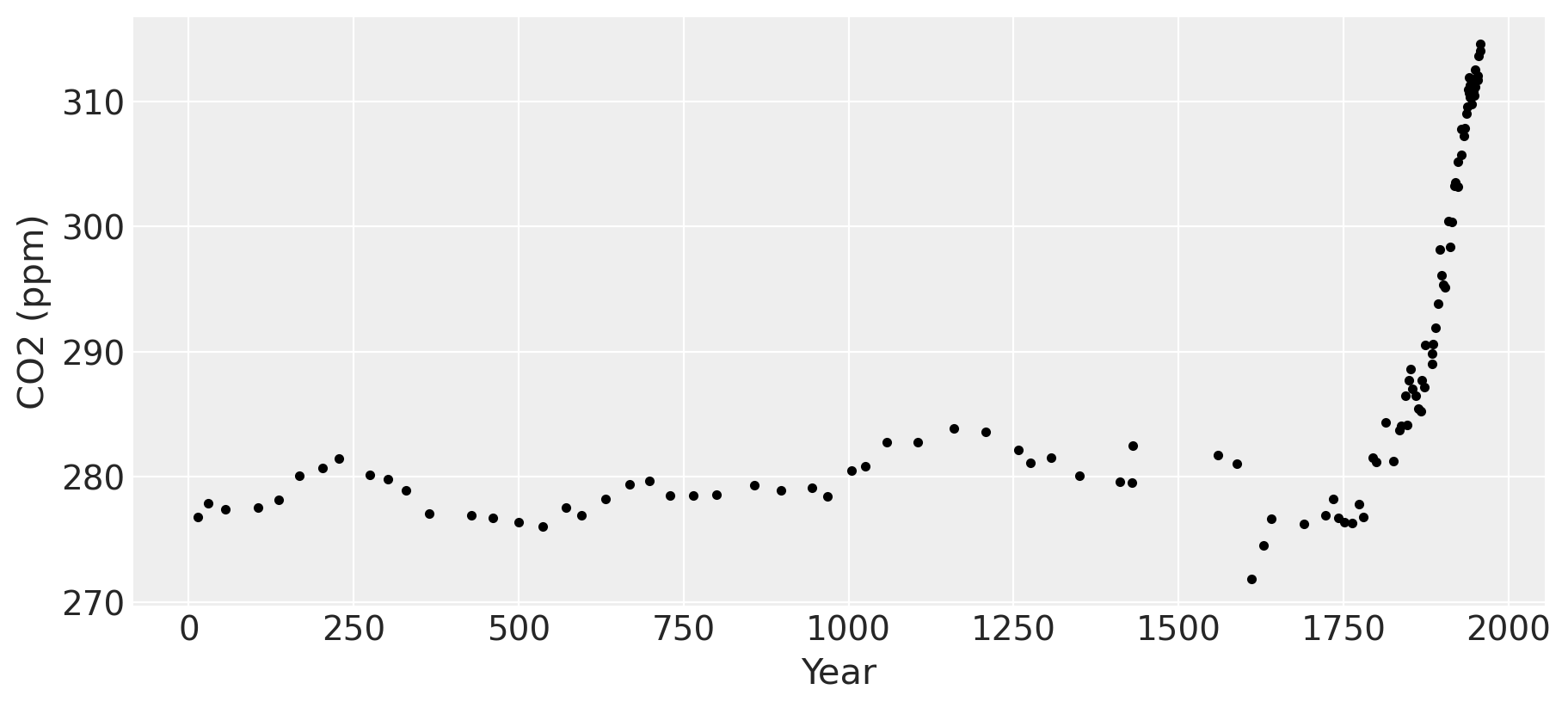
工业革命时代发生在 1760 年至 1840 年左右。这一点在图中清晰可见,CO2 水平在数千年保持在 280 ppm 左右的相当稳定的水平后急剧上升。
“x”中的不确定性#
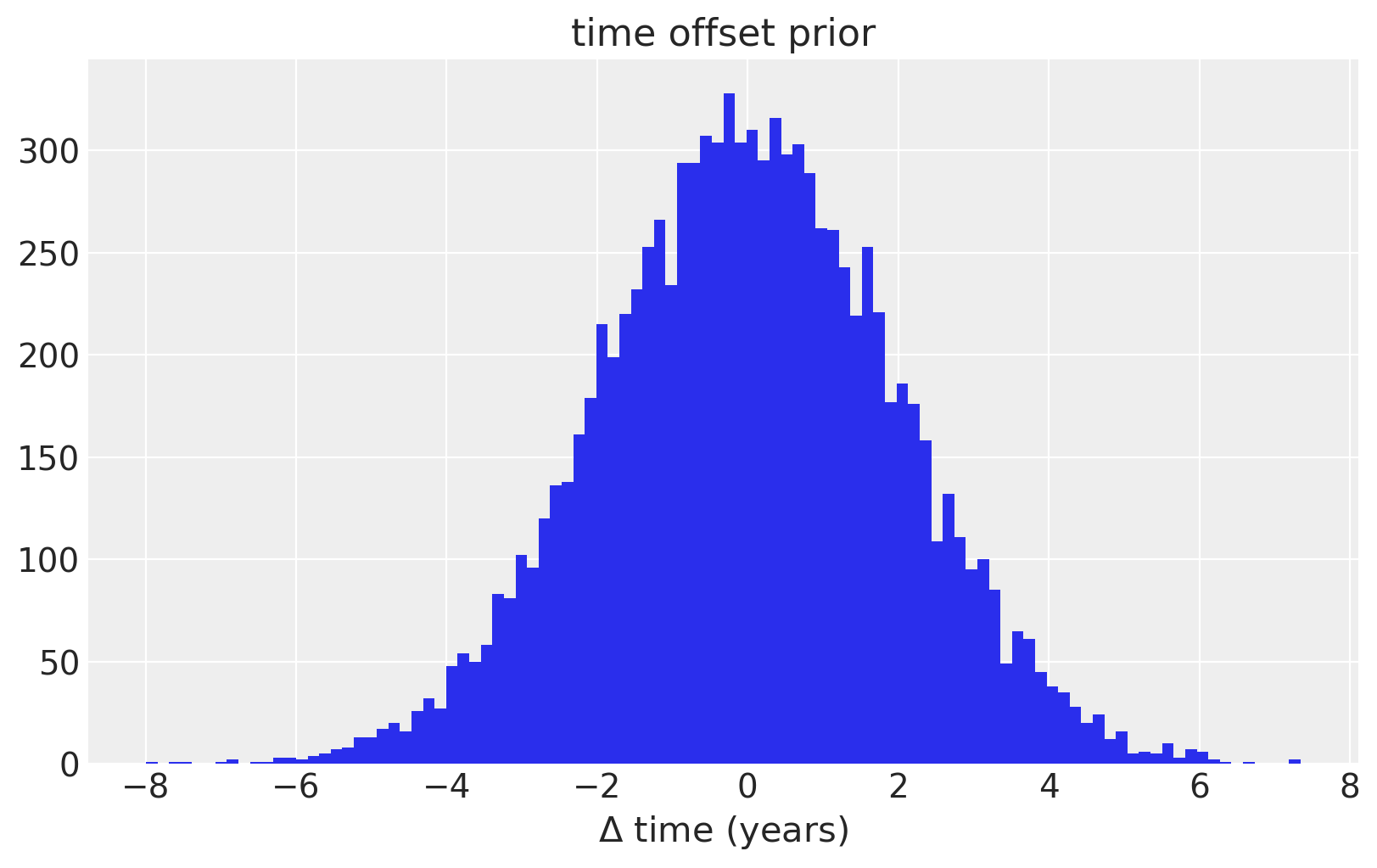
为了对 \(x\) 或时间中的不确定性进行建模,我们对每个观测日期放置先验分布。为了使先验标准化,我们专门使用 PyMC3 随机变量来对数据集中给出的日期与其误差之间的差异进行建模。我们假设这些差异是均值为零,标准差为两年的正态分布。我们还使用 ordered 变换强制观测值在时间上具有严格的顺序。
对于仅冰芯数据,\(x\) 中的不确定性不是很重要。在最后一个示例中,我们将看到它如何在模型中发挥更重要的作用。
fig = plt.figure(figsize=(8, 5))
ax = plt.gca()
ax.hist(100 * pm.Normal.dist(mu=0.0, sigma=0.02).random(size=10000), 100)
ax.set_xlabel(r"$\Delta$ time (years)")
ax.set_title("time offset prior");
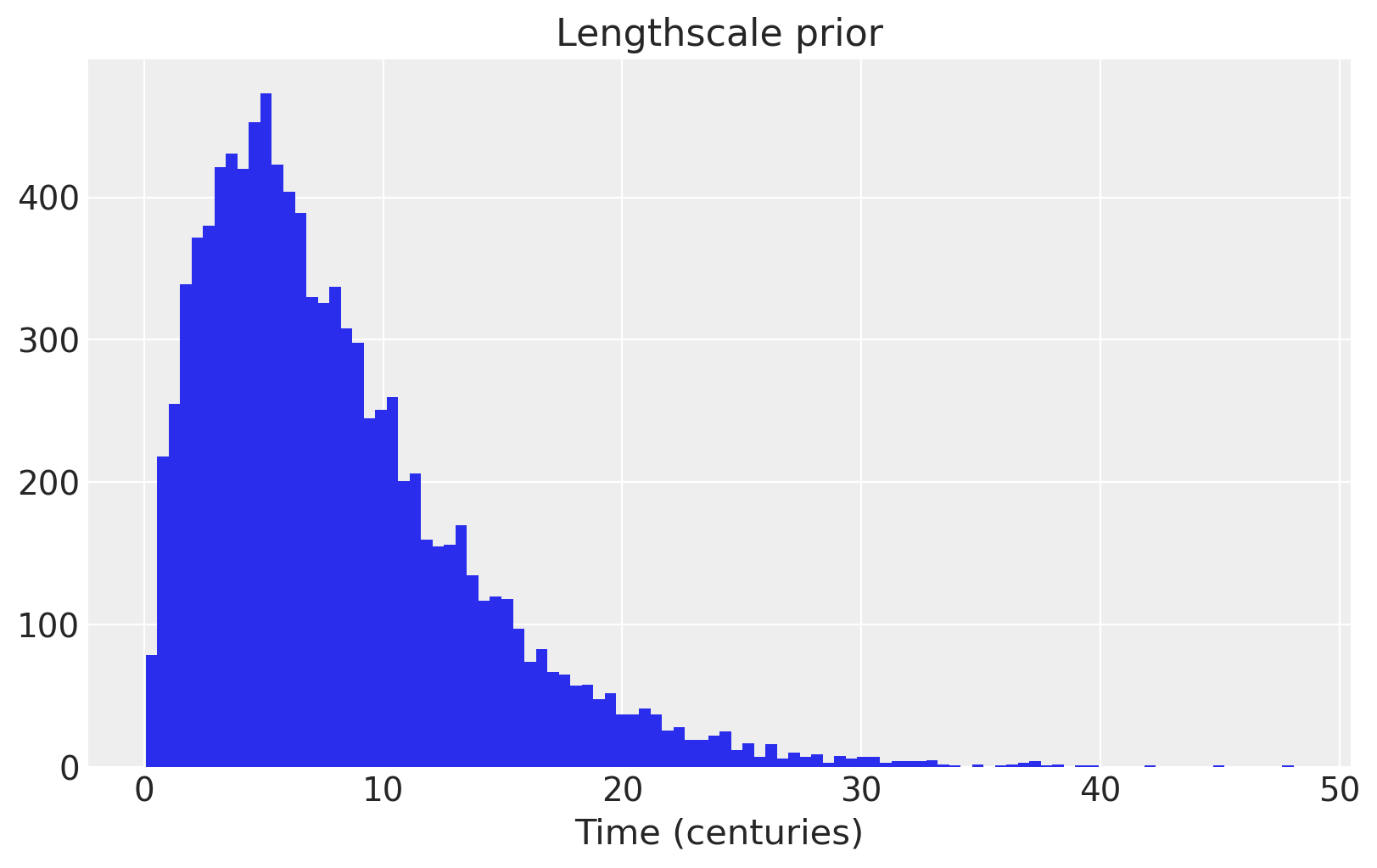
我们在长度尺度上使用信息丰富的先验,将大部分质量放在几个世纪到 20 个世纪之间。
fig = plt.figure(figsize=(8, 5))
ax = plt.gca()
ax.hist(pm.Gamma.dist(alpha=2, beta=0.25).random(size=10000), 100)
ax.set_xlabel("Time (centuries)")
ax.set_title("Lengthscale prior");
with pm.Model() as model:
η = pm.HalfNormal("η", sigma=5)
ℓ = pm.Gamma("ℓ", alpha=4, beta=2)
α = pm.Gamma("α", alpha=3, beta=1)
cov = η**2 * pm.gp.cov.RatQuad(1, α, ℓ)
gp = pm.gp.Marginal(cov_func=cov)
# x location uncertainty
# - sd = 0.02 says the uncertainty on the point is about two years
t_diff = pm.Normal("t_diff", mu=0.0, sigma=0.02, shape=len(t))
t_uncert = t_n - t_diff
# white noise variance
σ = pm.HalfNormal("σ", sigma=5, testval=1)
y_ = gp.marginal_likelihood("y", X=t_uncert[:, None], y=y_n, noise=σ)
/Users/alex_andorra/tptm_alex/pymc3/pymc3/gp/cov.py:93: UserWarning: Only 1 column(s) out of Subtensor{int64}.0 are being used to compute the covariance function. If this is not intended, increase 'input_dim' parameter to the number of columns to use. Ignore otherwise.
" the number of columns to use. Ignore otherwise.", UserWarning)
接下来,我们可以使用 NUTS MCMC 算法进行采样。我们运行两个链,但将核心数设置为 1,因为 Theano 内部使用的线性代数库是多核的。
with model:
tr = pm.sample(target_accept=0.95, return_inferencedata=True)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [σ, t_diff, α, ℓ, η]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 136 seconds.
az.plot_trace(tr, var_names=["t_diff"], compact=True);

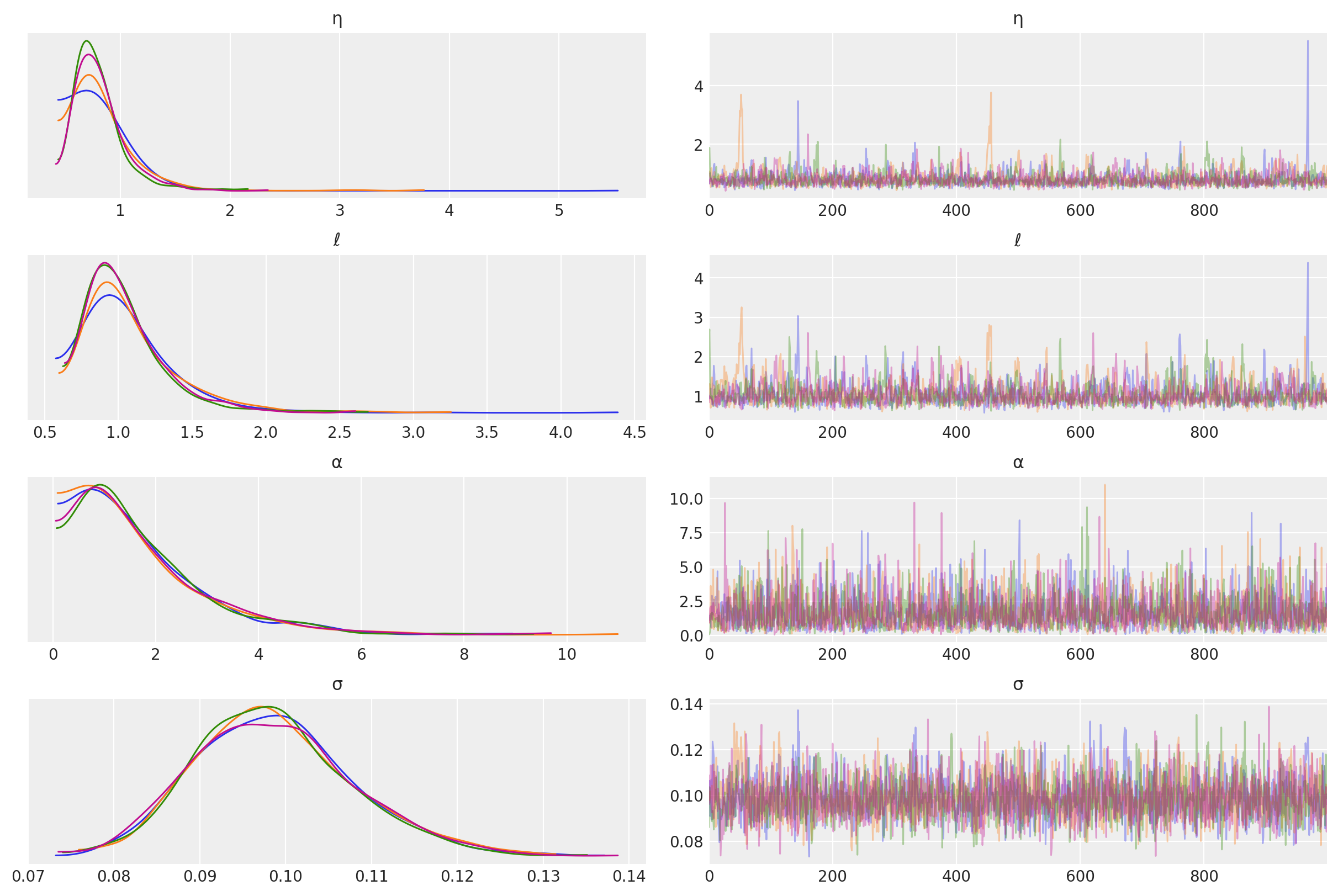
在 t_diff 的迹线图中,我们可以看到不同输入的后验峰值没有移动太多,但位置的不确定性已通过采样得到考虑。
其他未知超参数的后验分布如下。
az.plot_trace(tr, var_names=["η", "ℓ", "α", "σ"]);
预测#
tnew = np.linspace(-100, 2150, 2000) * 0.01
with model:
fnew = gp.conditional("fnew", Xnew=tnew[:, None])
with model:
ppc = pm.sample_posterior_predictive(tr, samples=100, var_names=["fnew"])
/Users/alex_andorra/tptm_alex/pymc3/pymc3/gp/cov.py:93: UserWarning: Only 1 column(s) out of Subtensor{int64}.0 are being used to compute the covariance function. If this is not intended, increase 'input_dim' parameter to the number of columns to use. Ignore otherwise.
" the number of columns to use. Ignore otherwise.", UserWarning)
/Users/alex_andorra/tptm_alex/pymc3/pymc3/sampling.py:1708: UserWarning: samples parameter is smaller than nchains times ndraws, some draws and/or chains may not be represented in the returned posterior predictive sample
"samples parameter is smaller than nchains times ndraws, some draws "
samples = y_sd * ppc["fnew"] + y_mu
fig = plt.figure(figsize=(12, 5))
ax = plt.gca()
pm.gp.util.plot_gp_dist(ax, samples, tnew * 100, plot_samples=True, palette="Blues")
ax.plot(t, y, "k.")
ax.set_xlim([-100, 2200])
ax.set_ylabel("CO2")
ax.set_xlabel("Year");
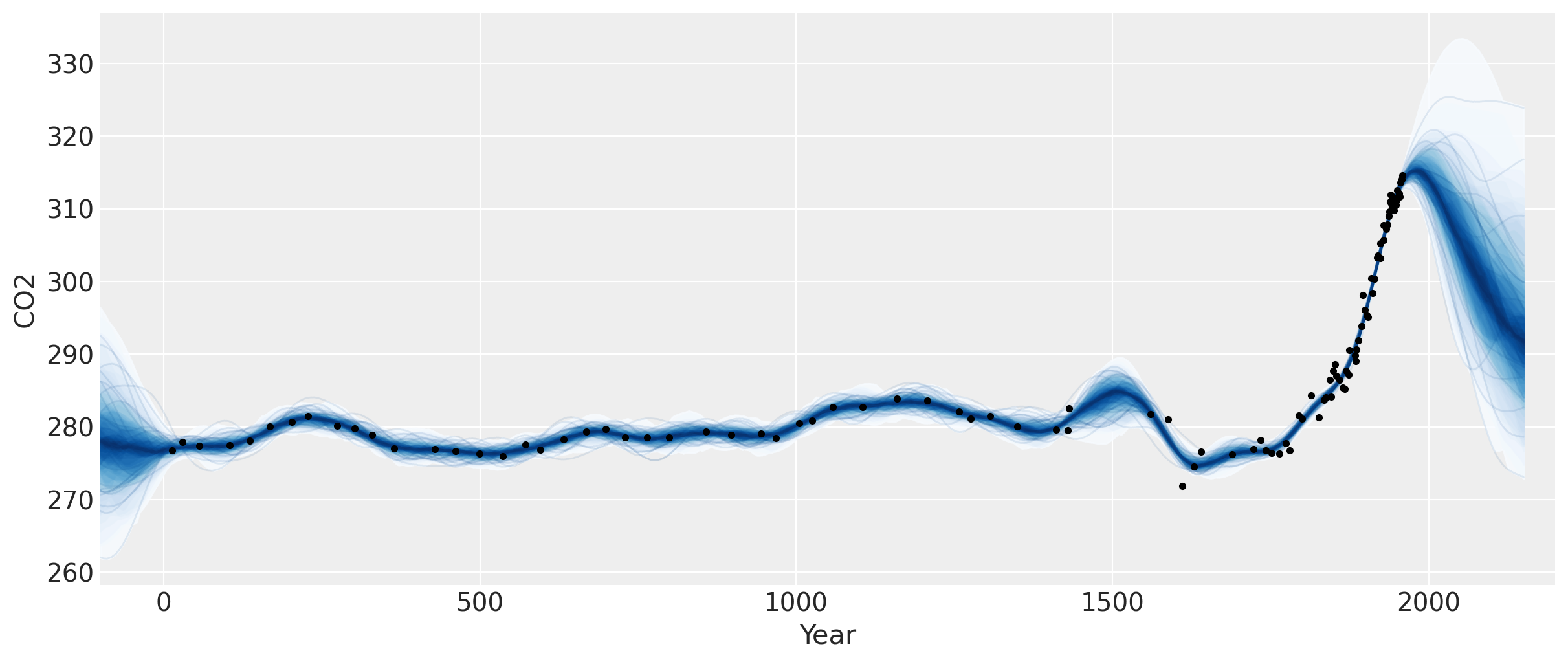
此图中明显有两个特征。一个是小冰河期,其对 CO2 的影响发生在约 1600 年至 1800 年之间。接下来是工业革命,当时人们开始向大气中释放大量 CO2。
半参数高斯过程#
1958 年最新数据点之后的预测上升,然后趋于平缓,然后又向下倾斜。我们应该相信这个预测吗?我们知道它尚未得到证实(参见之前的笔记本),因为 CO2 水平一直在持续上升。
我们在模型中没有指定均值函数,因此我们假设我们的 GP 的均值为零。这意味着当我们预测未来时,该函数最终将返回到零。在这种情况下,这是否合理?没有任何全球性事件表明大气 CO2 不会继续目前的趋势。
用于突变点的线性模型#
我们采用 Facebook 的 prophet 时间序列模型使用的公式。这是一个线性分段函数,其中每个段的端点被限制为彼此连接。下面绘制了一些示例函数。
def dm_changepoints(t, changepoints_t):
A = np.zeros((len(t), len(changepoints_t)))
for i, t_i in enumerate(changepoints_t):
A[t >= t_i, i] = 1
return A
为了以后使用,我们使用符号 Theano 变量重新编程此函数。代码有点难以理解,但它返回的内容与 dm_changepoitns 相同,同时避免了使用循环。
def dm_changepoints_theano(X, changepoints_t):
return 0.5 * (1.0 + tt.sgn(tt.tile(X, (1, len(changepoints_t))) - changepoints_t))
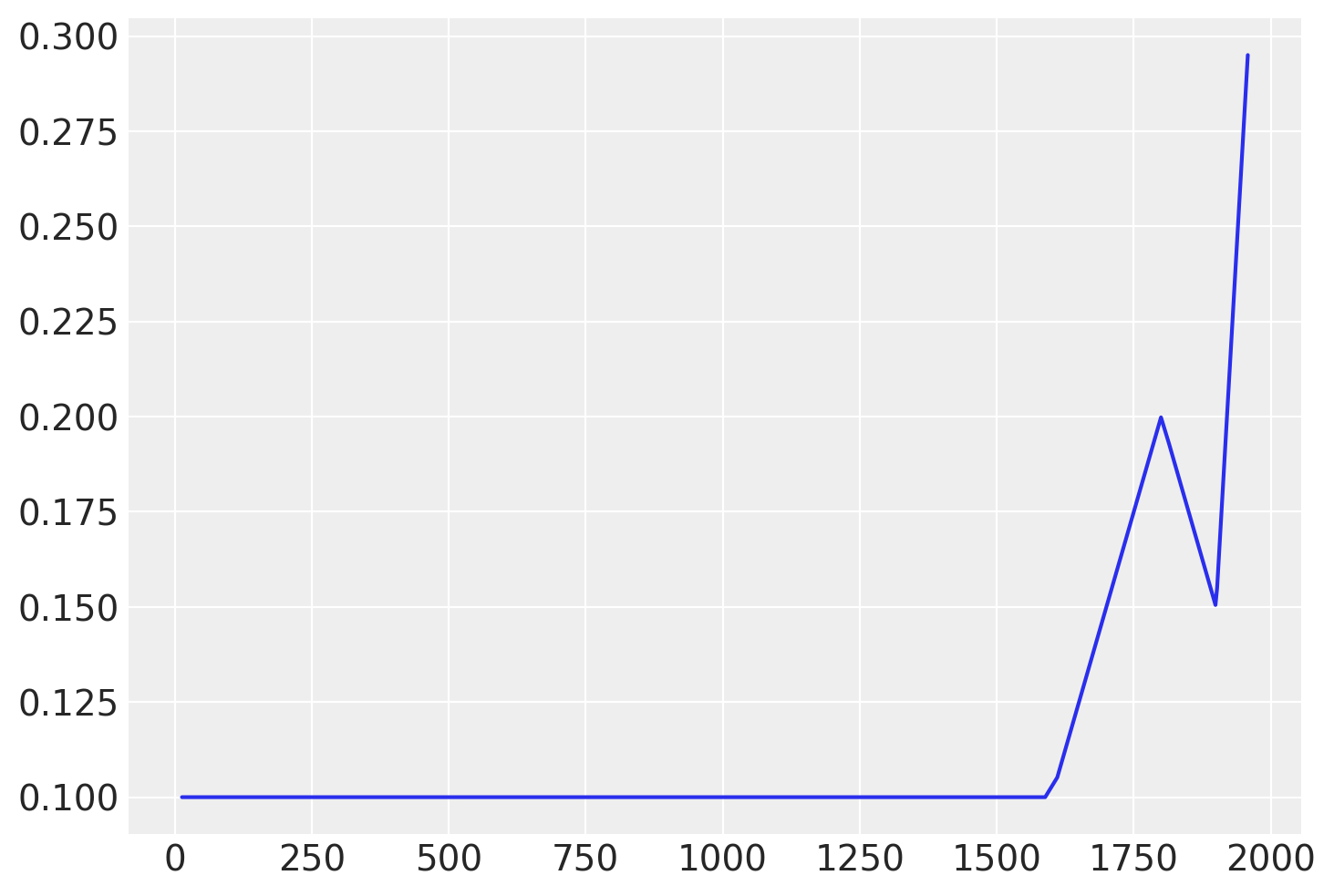
从图中可以看出,突变点的一些可能位置是 1600 年、1800 年,也许还有 1900 年。这些时间点标志着小冰河期、工业革命的开始以及更现代工业实践的开始。
changepoints_t = np.array([16, 18, 19])
A = dm_changepoints(t_n, changepoints_t)
有几个参数(我们将估计),一些测试值,以及生成的函数图如下所示
# base growth rate, or initial slope
k = 0.0
# offset
m = 0.1
# slope parameters
delta = np.array([0.05, -0.1, 0.3])
自定义突变点均值函数#
我们可以直接编码此均值函数,但如果我们将它包装在 Mean 对象中,则更容易使用其他高斯过程功能,例如 .conditional 和 .predict 方法。请参阅此处有关自定义均值和协方差函数的更多信息。我们只需要定义 __init__ 和 __call__ 函数。
class PiecewiseLinear(pm.gp.mean.Mean):
def __init__(self, changepoints, k, m, delta):
self.changepoints = changepoints
self.k = k
self.m = m
self.delta = delta
def __call__(self, X):
# X are the x locations, or time points
A = dm_changepoints_theano(X, self.changepoints)
return (self.k + tt.dot(A, self.delta)) * X.flatten() + (
self.m + tt.dot(A, -self.changepoints * self.delta)
)
每次评估均值函数时都重新创建 A 是低效的,但当进行预测时输入数量发生变化时,我们需要这样做。
半参数突变点模型#
接下来是使用突变点均值函数更新的模型。
with pm.Model() as model:
η = pm.HalfNormal("η", sigma=2)
ℓ = pm.Gamma("ℓ", alpha=4, beta=2)
α = pm.Gamma("α", alpha=3, beta=1)
cov = η**2 * pm.gp.cov.RatQuad(1, α, ℓ)
# piecewise linear mean function
k = pm.Normal("k", mu=0, sigma=1)
m = pm.Normal("m", mu=0, sigma=1)
delta = pm.Normal("delta", mu=0, sigma=5, shape=len(changepoints_t))
mean = PiecewiseLinear(changepoints_t, k, m, delta)
# include mean function in GP constructor
gp = pm.gp.Marginal(cov_func=cov, mean_func=mean)
# x location uncertainty
# - sd = 0.02 says the uncertainty on the point is about two years
t_diff = pm.Normal("t_diff", mu=0.0, sigma=0.02, shape=len(t))
t_uncert = t_n - t_diff
# white noise variance
σ = pm.HalfNormal("σ", sigma=5)
y_ = gp.marginal_likelihood("y", X=t_uncert[:, None], y=y_n, noise=σ)
/Users/alex_andorra/tptm_alex/pymc3/pymc3/gp/cov.py:93: UserWarning: Only 1 column(s) out of Subtensor{int64}.0 are being used to compute the covariance function. If this is not intended, increase 'input_dim' parameter to the number of columns to use. Ignore otherwise.
" the number of columns to use. Ignore otherwise.", UserWarning)
with model:
tr = pm.sample(chains=2, target_accept=0.95)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 4 jobs)
NUTS: [σ, t_diff, delta, m, k, α, ℓ, η]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 208 seconds.
az.plot_trace(tr, var_names=["η", "ℓ", "α", "σ", "k", "m", "delta"]);
/Users/alex_andorra/opt/anaconda3/envs/dev-pymc/lib/python3.6/site-packages/arviz/data/io_pymc3.py:89: FutureWarning: Using `from_pymc3` without the model will be deprecated in a future release. Not using the model will return less accurate and less useful results. Make sure you use the model argument or call from_pymc3 within a model context.
FutureWarning,
预测#
tnew = np.linspace(-100, 2200, 2000) * 0.01
with model:
fnew = gp.conditional("fnew", Xnew=tnew[:, None])
with model:
ppc = pm.sample_posterior_predictive(tr, samples=100, var_names=["fnew"])
/Users/alex_andorra/tptm_alex/pymc3/pymc3/gp/cov.py:93: UserWarning: Only 1 column(s) out of Subtensor{int64}.0 are being used to compute the covariance function. If this is not intended, increase 'input_dim' parameter to the number of columns to use. Ignore otherwise.
" the number of columns to use. Ignore otherwise.", UserWarning)
/Users/alex_andorra/tptm_alex/pymc3/pymc3/sampling.py:1708: UserWarning: samples parameter is smaller than nchains times ndraws, some draws and/or chains may not be represented in the returned posterior predictive sample
"samples parameter is smaller than nchains times ndraws, some draws "
samples = y_sd * ppc["fnew"] + y_mu
fig = plt.figure(figsize=(12, 5))
ax = plt.gca()
pm.gp.util.plot_gp_dist(ax, samples, tnew * 100, plot_samples=True, palette="Blues")
ax.plot(t, y, "k.")
ax.set_xlim([-100, 2200])
ax.set_ylabel("CO2 (ppm)")
ax.set_xlabel("year");
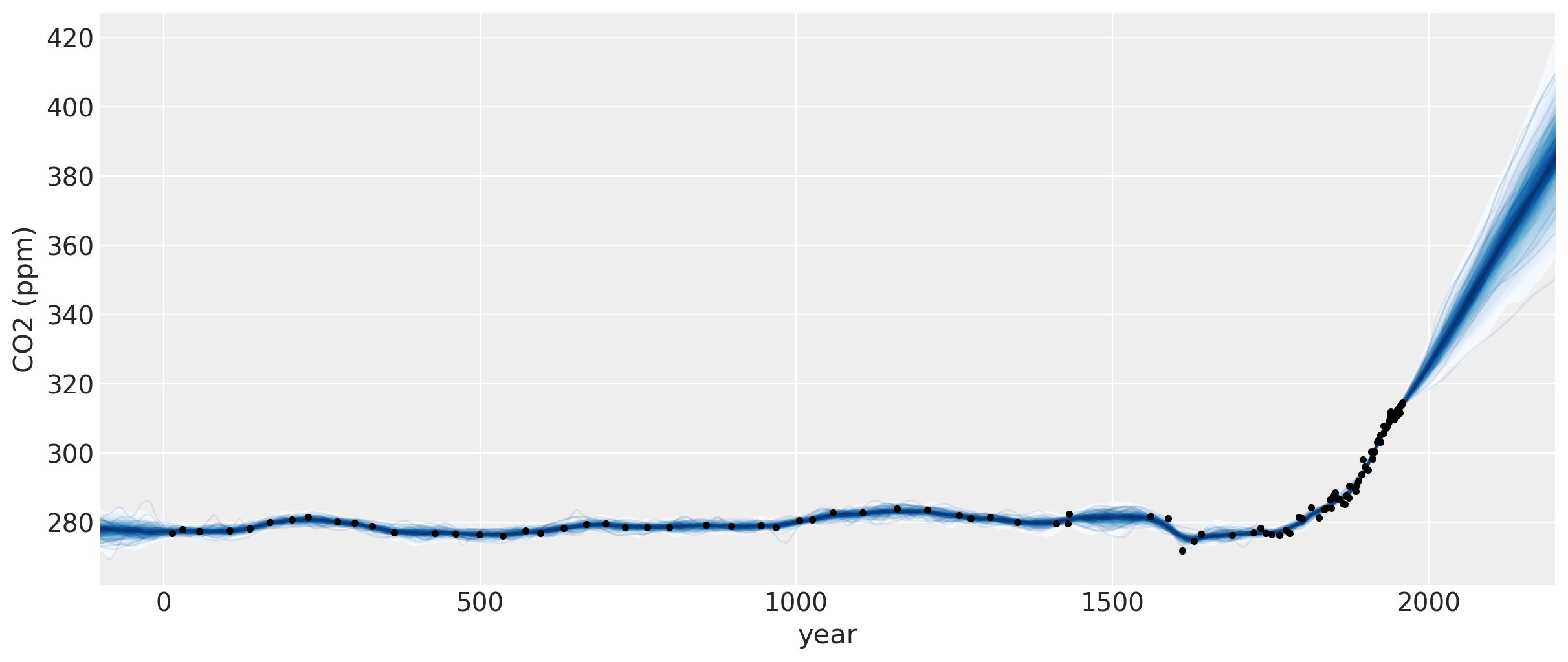
这些结果看起来更好,但我们必须精确地选择突变点的位置。除了在均值函数中使用突变点之外,我们还可以在协方差函数的形式中指定相同的突变点行为。后一种公式的一个好处是,突变点可以是一个更真实的平滑过渡,而不是离散的断点。在下一节中,我们将介绍如何做到这一点。
自定义突变点协方差函数#
更复杂的协方差函数可以通过多种方式组合基本协方差函数来构建。例如,两个最常用的操作是:
两个协方差函数的和是一个协方差函数
两个协方差函数的乘积是一个协方差函数
我们还可以通过按任意函数缩放基本协方差函数 (\(k_b\)) 来构建协方差函数,
Heaviside 阶跃函数#
为了专门构建描述突变点的协方差函数,我们可以提出一个缩放函数 \(s(x)\),它指定基本协方差处于活动状态的区域。最简单的选择是阶跃函数,
它由突变点 \(x_0\) 参数化。协方差函数 \(s(x; x_0) k_b(x, x') s(x'; x_0)\) 仅在区域 \(x > x_0\) 中处于活动状态。
PyMC3 包含 ScaledCov 协方差函数。作为参数,它接受一个基本协方差、一个缩放函数以及基本协方差的参数元组。为了在 PyMC3 中构建它,我们首先定义缩放函数
def step_function(x, x0, greater=True):
if greater:
# s = 1 for x > x_0
return 0.5 * (tt.sgn(x - x0) + 1.0)
else:
return 0.5 * (tt.sgn(x0 - x) + 1.0)
step_function(np.linspace(0, 10, 10), x0=5, greater=True).eval()
array([0., 0., 0., 0., 0., 1., 1., 1., 1., 1.])
step_function(np.linspace(0, 10, 10), x0=5, greater=False).eval()
array([1., 1., 1., 1., 1., 0., 0., 0., 0., 0.])
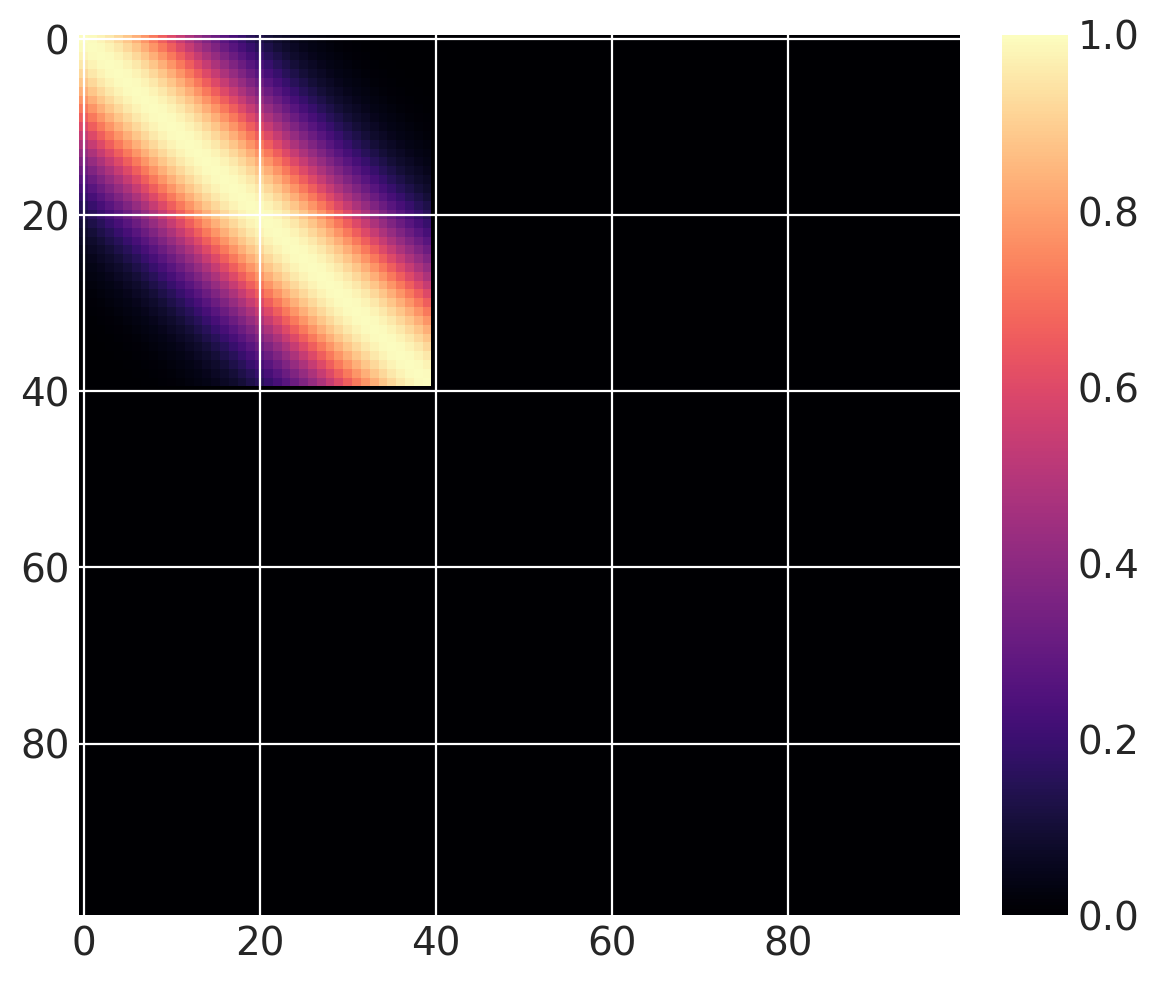
然后我们可以定义以下协方差函数,我们在 \(x \in (0, 100)\) 上计算它。基本协方差的长度尺度为 10,\(x_0 = 40\)。由于我们使用的是阶跃函数,因此当 greater=False 时,它对于 \(x \leq 40\) 是“活动的”,当 greater=True 时,它对于 \(x > 40\) 是“活动的”。
cov = pm.gp.cov.ExpQuad(1, 10)
sc_cov = pm.gp.cov.ScaledCov(1, cov, step_function, (40, False))
x = np.linspace(0, 100, 100)
K = sc_cov(x[:, None]).eval()
m = plt.imshow(K, cmap="magma")
plt.colorbar(m);
/Users/alex_andorra/tptm_alex/pymc3/pymc3/gp/cov.py:93: UserWarning: Only 1 column(s) out of Subtensor{int64}.0 are being used to compute the covariance function. If this is not intended, increase 'input_dim' parameter to the number of columns to use. Ignore otherwise.
" the number of columns to use. Ignore otherwise.", UserWarning)
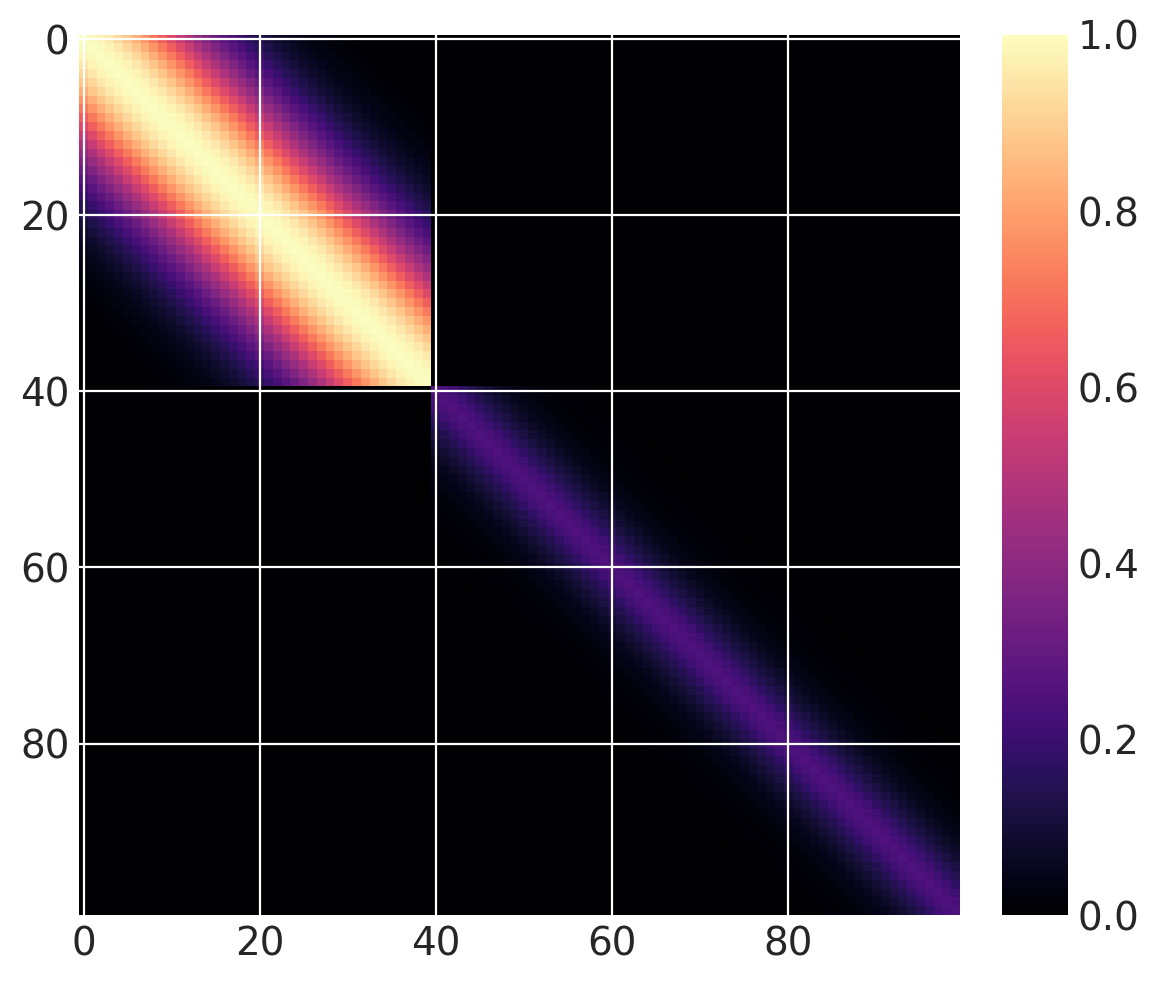
但这还不是突变点协方差函数。我们可以将这两个函数加在一起。对于 \(x > 40\),让我们使用一个基本协方差,它是具有长度尺度 5 和幅度 0.25 的 Matern32
cov1 = pm.gp.cov.ExpQuad(1, 10)
sc_cov1 = pm.gp.cov.ScaledCov(1, cov1, step_function, (40, False))
cov2 = 0.25 * pm.gp.cov.Matern32(1, 5)
sc_cov2 = pm.gp.cov.ScaledCov(1, cov2, step_function, (40, True))
sc_cov = sc_cov1 + sc_cov2
# plot over 0 < x < 100
x = np.linspace(0, 100, 100)
K = sc_cov(x[:, None]).eval()
m = plt.imshow(K, cmap="magma")
plt.colorbar(m);
/Users/alex_andorra/tptm_alex/pymc3/pymc3/gp/cov.py:93: UserWarning: Only 1 column(s) out of Subtensor{int64}.0 are being used to compute the covariance function. If this is not intended, increase 'input_dim' parameter to the number of columns to use. Ignore otherwise.
" the number of columns to use. Ignore otherwise.", UserWarning)
/Users/alex_andorra/tptm_alex/pymc3/pymc3/gp/cov.py:93: UserWarning: Only 1 column(s) out of Subtensor{int64}.0 are being used to compute the covariance function. If this is not intended, increase 'input_dim' parameter to the number of columns to use. Ignore otherwise.
" the number of columns to use. Ignore otherwise.", UserWarning)
具有此协方差的高斯过程先验的样本是什么样的?
prior_samples = np.random.multivariate_normal(np.zeros(100), K, 3).T
plt.plot(x, prior_samples)
plt.axvline(x=40, color="k", alpha=0.5);
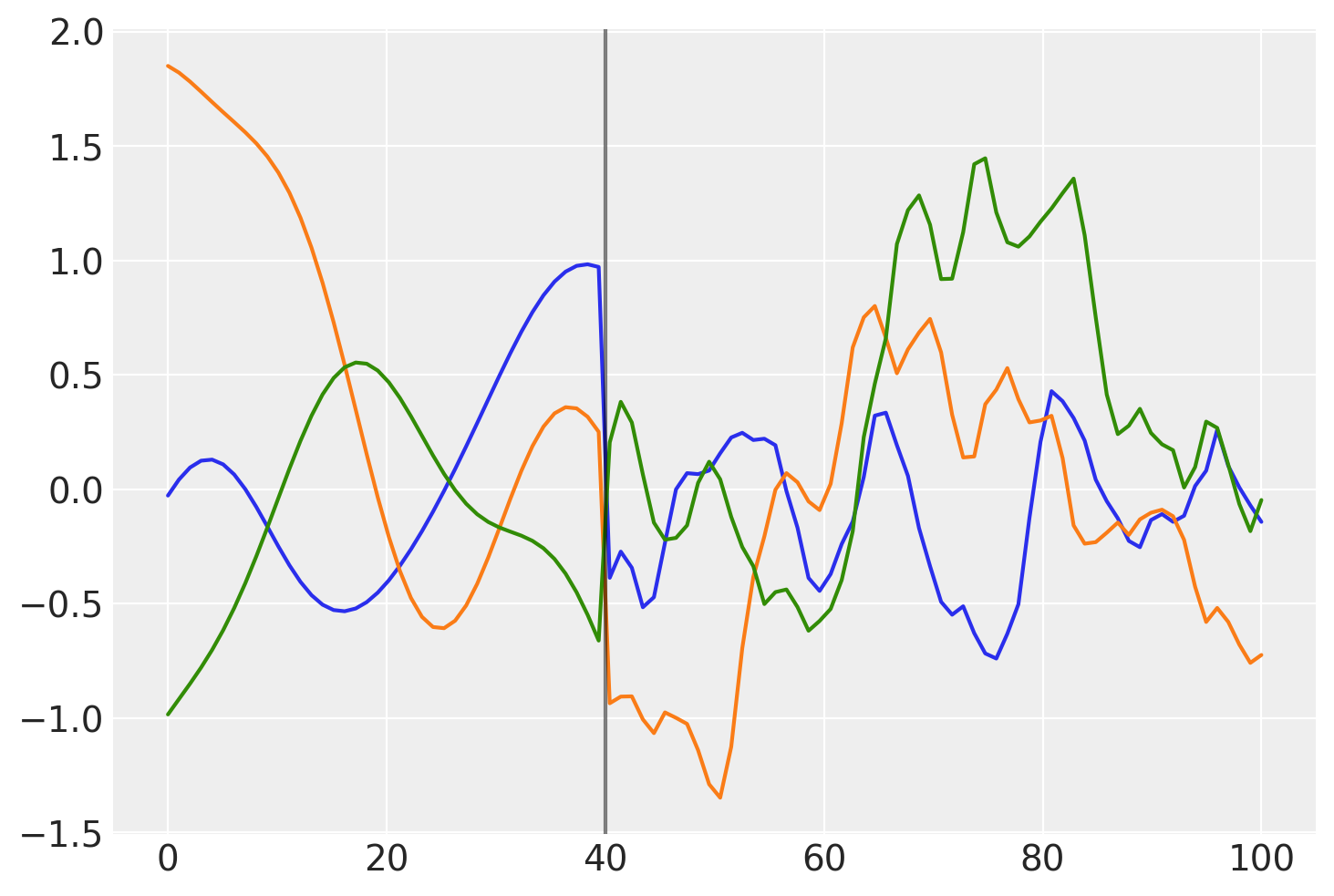
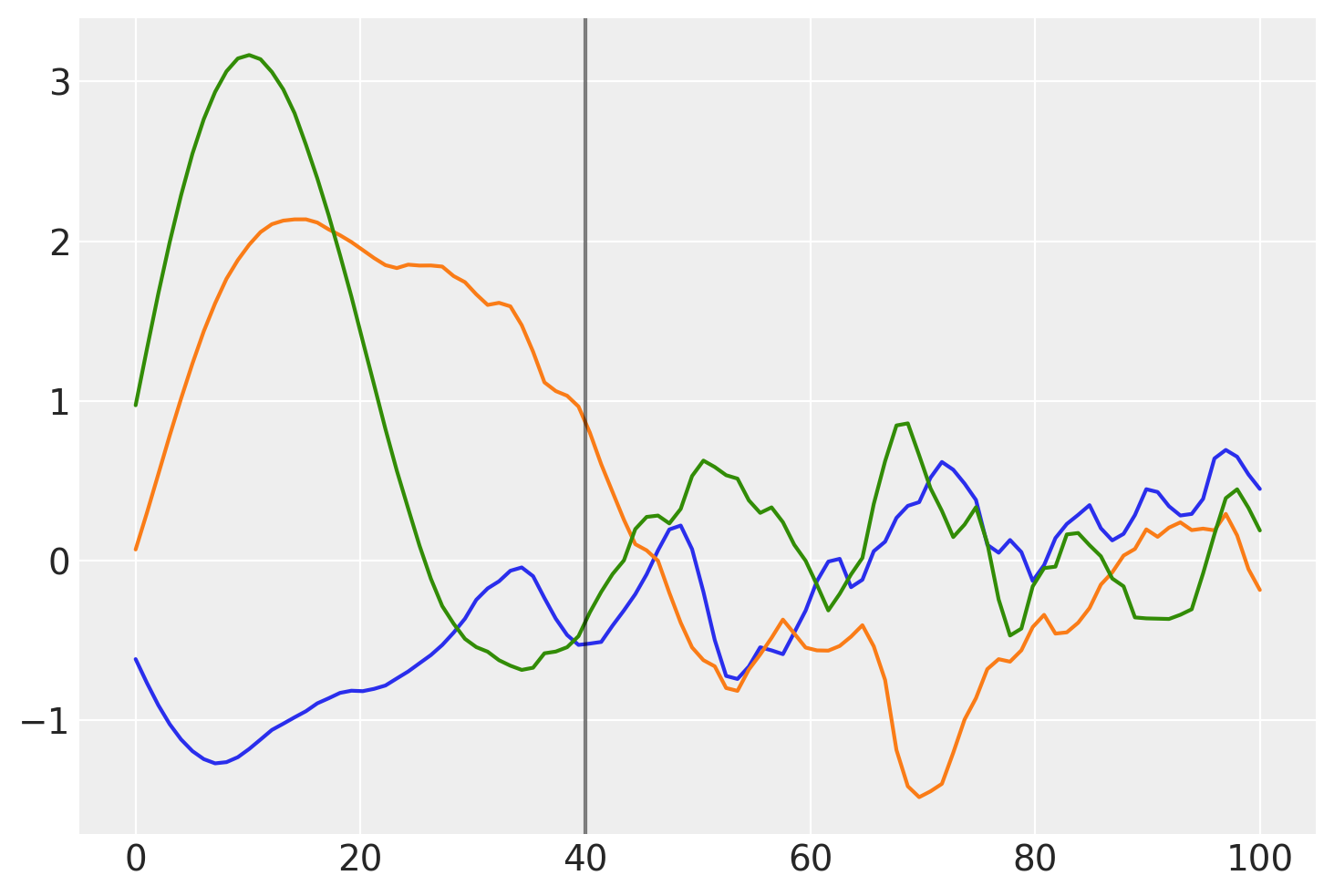
在 \(x = 40\) 之前,该函数是平滑且缓慢变化的。在 \(x = 40\) 之后,样本不太平滑且变化迅速。
使用 sigmoid 函数的逐渐变化#
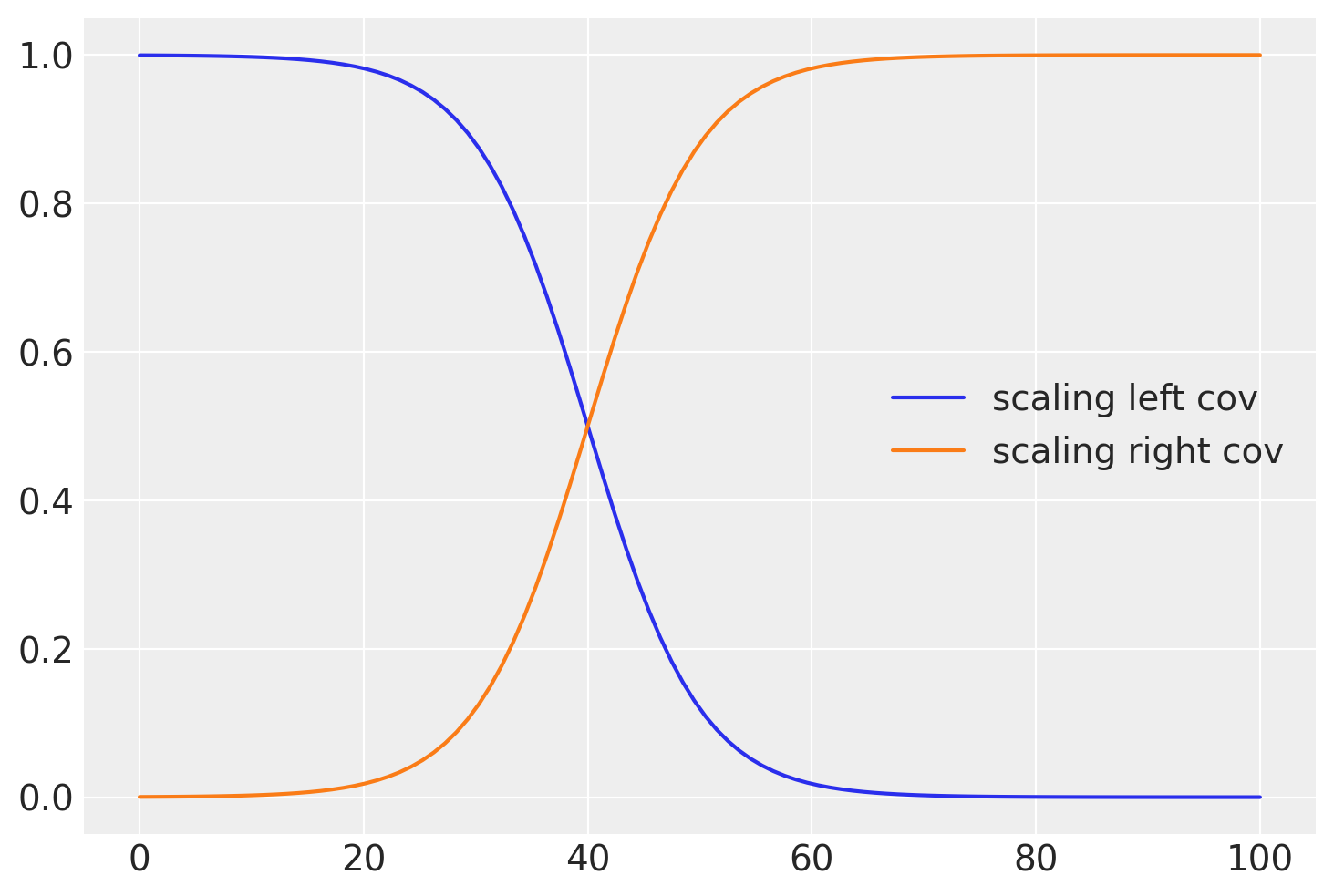
通常,平滑过渡比急剧截止更现实。为此,我们可以使用逻辑函数,如下所示
# b is the slope, a is the location
b = -0.2
a = 40
plt.plot(x, pm.math.invlogit(b * (x - a)).eval(), label="scaling left cov")
b = 0.2
a = 40
plt.plot(x, pm.math.invlogit(b * (x - a)).eval(), label="scaling right cov")
plt.legend();
def logistic(x, b, x0):
# b is the slope, x0 is the location
return pm.math.invlogit(b * (x - x0))
与之前相同的协方差函数,但具有逐渐的突变点,如下所示
cov1 = pm.gp.cov.ExpQuad(1, 10)
sc_cov1 = pm.gp.cov.ScaledCov(1, cov1, logistic, (-0.1, 40))
cov2 = 0.25 * pm.gp.cov.Matern32(1, 5)
sc_cov2 = pm.gp.cov.ScaledCov(1, cov2, logistic, (0.1, 40))
sc_cov = sc_cov1 + sc_cov2
# plot over 0 < x < 100
x = np.linspace(0, 100, 100)
K = sc_cov(x[:, None]).eval()
m = plt.imshow(K, cmap="magma")
plt.colorbar(m);
/Users/alex_andorra/tptm_alex/pymc3/pymc3/gp/cov.py:93: UserWarning: Only 1 column(s) out of Subtensor{int64}.0 are being used to compute the covariance function. If this is not intended, increase 'input_dim' parameter to the number of columns to use. Ignore otherwise.
" the number of columns to use. Ignore otherwise.", UserWarning)
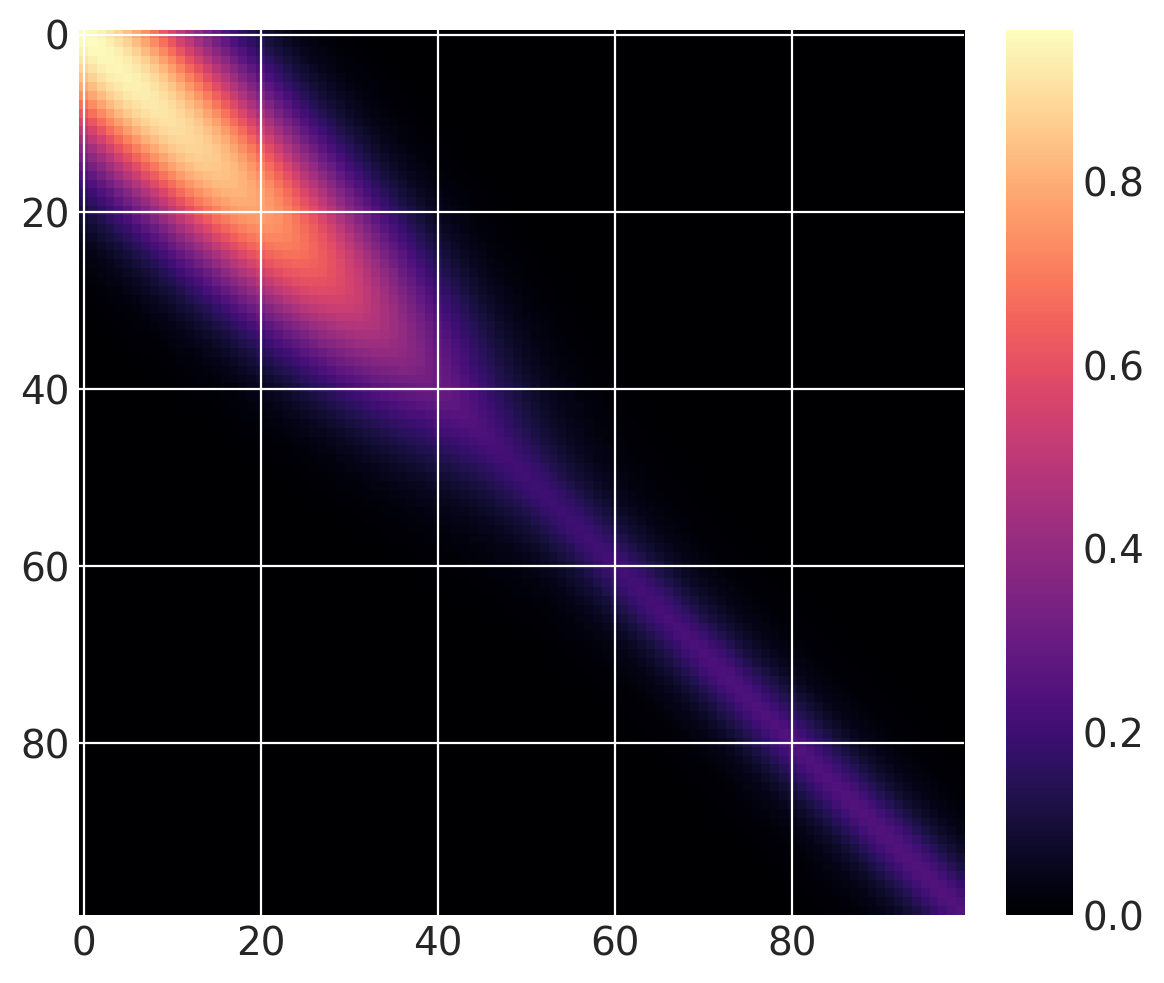
在下面,您可以看到先验函数从一个区域到下一个区域的过渡更加渐进
prior_samples = np.random.multivariate_normal(np.zeros(100), K, 3).T
plt.plot(x, prior_samples)
plt.axvline(x=40, color="k", alpha=0.5);
让我们尝试一下这个模型,而不是半参数突变点版本。
突变点协方差模型#
此模型的特点是:
一个用于所有时间点的短期变化的协方差
参数
x0是工业革命的位置。它被赋予一个先验,其大部分支持在 1760 年到 1840 年之间,中心位于 1800 年。我们可以轻松地将此
x0参数用作 2 次Polynomial(二次)协方差中的shift参数,并用作突变点协方差中突变点的位置。突变点协方差在工业革命之前是
ExpQuad,之后是ExpQuad + Polynomial(degree=2)。我们对突变点协方差中的两个基本协方差使用相同的缩放和长度尺度参数。
仍然像以前一样对
x中的不确定性进行建模。
with pm.Model() as model:
η = pm.HalfNormal("η", sigma=5)
ℓ = pm.Gamma("ℓ", alpha=2, beta=0.1)
# changepoint occurs near the year 1800, sometime between 1760, 1840
x0 = pm.Normal("x0", mu=18, sigma=0.1)
# the change happens gradually
a = pm.HalfNormal("a", sigma=2)
# a constant for the
c = pm.HalfNormal("c", sigma=3)
# quadratic polynomial scale
ηq = pm.HalfNormal("ηq", sigma=5)
cov1 = η**2 * pm.gp.cov.ExpQuad(1, ℓ)
cov2 = η**2 * pm.gp.cov.ExpQuad(1, ℓ) + ηq**2 * pm.gp.cov.Polynomial(1, x0, 2, c)
# construct changepoint cov
sc_cov1 = pm.gp.cov.ScaledCov(1, cov1, logistic, (-a, x0))
sc_cov2 = pm.gp.cov.ScaledCov(1, cov2, logistic, (a, x0))
cov_c = sc_cov1 + sc_cov2
# short term variation
ηs = pm.HalfNormal("ηs", sigma=5)
ℓs = pm.Gamma("ℓs", alpha=2, beta=1)
cov_s = ηs**2 * pm.gp.cov.Matern52(1, ℓs)
gp = pm.gp.Marginal(cov_func=cov_s + cov_c)
t_diff = pm.Normal("t_diff", mu=0.0, sigma=0.02, shape=len(t))
t_uncert = t_n - t_diff
# white noise variance
σ = pm.HalfNormal("σ", sigma=5, testval=1)
y_ = gp.marginal_likelihood("y", X=t_uncert[:, None], y=y_n, noise=σ)
/Users/alex_andorra/tptm_alex/pymc3/pymc3/gp/cov.py:93: UserWarning: Only 1 column(s) out of Subtensor{int64}.0 are being used to compute the covariance function. If this is not intended, increase 'input_dim' parameter to the number of columns to use. Ignore otherwise.
" the number of columns to use. Ignore otherwise.", UserWarning)
/Users/alex_andorra/tptm_alex/pymc3/pymc3/gp/cov.py:93: UserWarning: Only 1 column(s) out of Subtensor{int64}.0 are being used to compute the covariance function. If this is not intended, increase 'input_dim' parameter to the number of columns to use. Ignore otherwise.
" the number of columns to use. Ignore otherwise.", UserWarning)
/Users/alex_andorra/tptm_alex/pymc3/pymc3/gp/cov.py:93: UserWarning: Only 1 column(s) out of Subtensor{int64}.0 are being used to compute the covariance function. If this is not intended, increase 'input_dim' parameter to the number of columns to use. Ignore otherwise.
" the number of columns to use. Ignore otherwise.", UserWarning)
with model:
tr = pm.sample(500, chains=2, target_accept=0.95)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 4 jobs)
NUTS: [σ, t_diff, ℓs, ηs, ηq, c, a, x0, ℓ, η]
Sampling 2 chains for 1_000 tune and 500 draw iterations (2_000 + 1_000 draws total) took 151 seconds.
az.plot_trace(tr, var_names=["η", "ηs", "ℓ", "ℓs", "c", "a", "x0", "σ"]);
/Users/alex_andorra/opt/anaconda3/envs/dev-pymc/lib/python3.6/site-packages/arviz/data/io_pymc3.py:89: FutureWarning: Using `from_pymc3` without the model will be deprecated in a future release. Not using the model will return less accurate and less useful results. Make sure you use the model argument or call from_pymc3 within a model context.
FutureWarning,
预测#
tnew = np.linspace(-100, 2300, 2200) * 0.01
with model:
fnew = gp.conditional("fnew", Xnew=tnew[:, None])
with model:
ppc = pm.sample_posterior_predictive(tr, samples=100, var_names=["fnew"])
/Users/alex_andorra/tptm_alex/pymc3/pymc3/gp/cov.py:93: UserWarning: Only 1 column(s) out of Subtensor{int64}.0 are being used to compute the covariance function. If this is not intended, increase 'input_dim' parameter to the number of columns to use. Ignore otherwise.
" the number of columns to use. Ignore otherwise.", UserWarning)
/Users/alex_andorra/tptm_alex/pymc3/pymc3/sampling.py:1708: UserWarning: samples parameter is smaller than nchains times ndraws, some draws and/or chains may not be represented in the returned posterior predictive sample
"samples parameter is smaller than nchains times ndraws, some draws "
samples = y_sd * ppc["fnew"] + y_mu
fig = plt.figure(figsize=(12, 5))
ax = plt.gca()
pm.gp.util.plot_gp_dist(ax, samples, tnew, plot_samples=True, palette="Blues")
ax.plot(t / 100, y, "k.")
ax.set_xticks(np.arange(0, 23))
ax.set_xlim([-1, 23])
ax.set_ylim([250, 450])
ax.set_xlabel("time (in centuries)")
ax.set_ylabel("CO2 (ppm)");
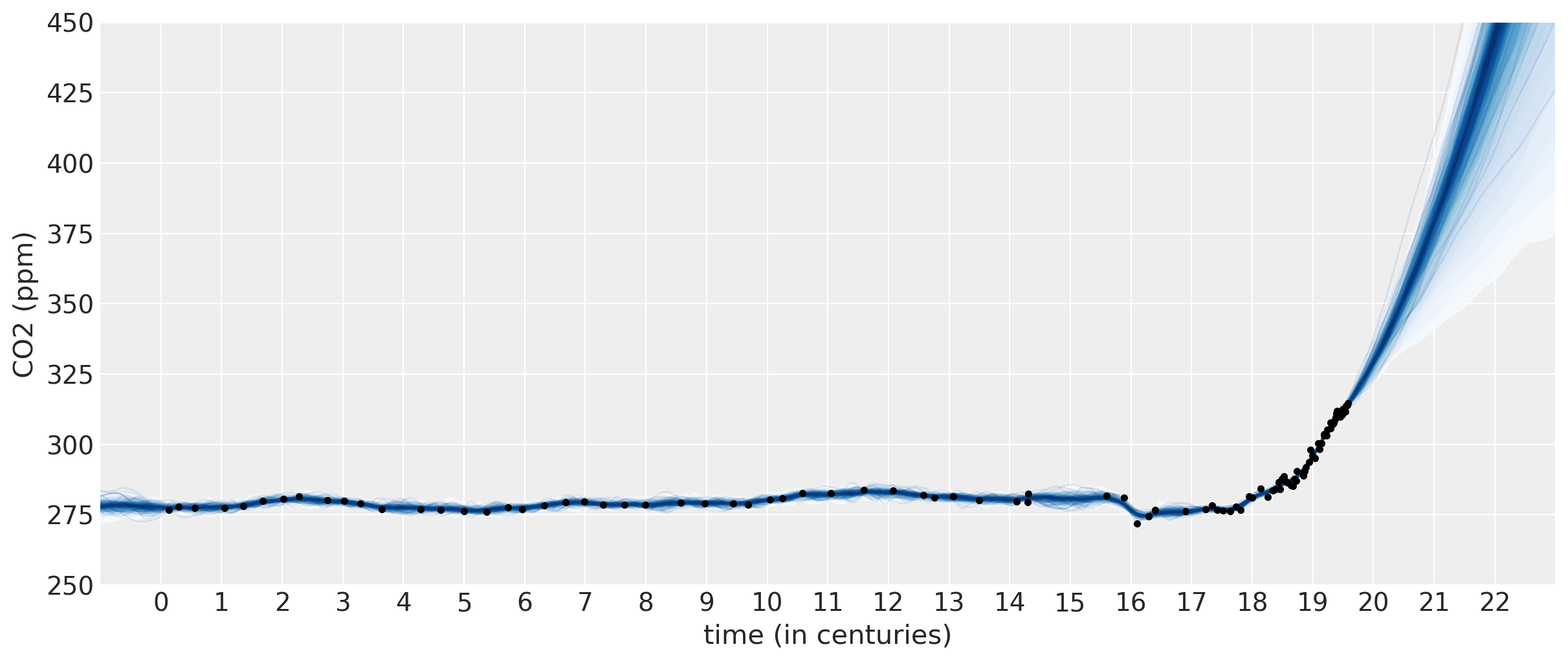
此模型的预测看起来更真实。2 次多项式与 ExpQuad 的总和看起来是一个很好的预测模型。它允许 CO2 量以非完全线性的方式增加。我们可以从预测中看到:
CO2 量可能会以更快的速度增加
CO2 量应该或多或少线性增加
CO2 有可能开始减少
结合大气 CO2 测量值#
接下来,我们结合来自 Mauna Loa 天文台的 CO2 测量值。这些数据点是每月从大气水平采集的。与冰芯数据不同,这些测量值没有不确定性。在将这两个数据集一起建模时,包含冰芯测量时间的不确定性的价值将更加明显。使用冰芯数据反向预测 Mauna Loa 季节性没有太多意义,因为南极的季节性模式与夏威夷北半球的季节性模式不同。尽管如此,我们还是会展示它,因为它有可能,并且在其他上下文中可能很有用。
首先,让我们加载数据,然后将其与冰芯数据一起绘制。
import time
from datetime import datetime as dt
def toYearFraction(date):
date = pd.to_datetime(date)
def sinceEpoch(date): # returns seconds since epoch
return time.mktime(date.timetuple())
s = sinceEpoch
year = date.year
startOfThisYear = dt(year=year, month=1, day=1)
startOfNextYear = dt(year=year + 1, month=1, day=1)
yearElapsed = s(date) - s(startOfThisYear)
yearDuration = s(startOfNextYear) - s(startOfThisYear)
fraction = yearElapsed / yearDuration
return date.year + fraction
airdata = pd.read_csv(pm.get_data("monthly_in_situ_co2_mlo.csv"), header=56)
# - replace -99.99 with NaN
airdata.replace(to_replace=-99.99, value=np.nan, inplace=True)
# fix column names
cols = [
"year",
"month",
"--",
"--",
"CO2",
"seasonaly_adjusted",
"fit",
"seasonally_adjusted_fit",
"CO2_filled",
"seasonally_adjusted_filled",
]
airdata.columns = cols
cols.remove("--")
cols.remove("--")
airdata = airdata[cols]
# drop rows with nan
airdata.dropna(inplace=True)
# fix time index
airdata["day"] = 15
airdata.index = pd.to_datetime(airdata[["year", "month", "day"]])
airdata["year"] = [toYearFraction(date) for date in airdata.index.values]
cols.remove("month")
airdata = airdata[cols]
air = airdata[["year", "CO2"]]
air.head(5)
| 年份 | CO2 | |
|---|---|---|
| 1958-03-15 | 1958.200000 | 315.69 |
| 1958-04-15 | 1958.284932 | 317.46 |
| 1958-05-15 | 1958.367123 | 317.50 |
| 1958-07-15 | 1958.534247 | 315.86 |
| 1958-08-15 | 1958.619178 | 314.93 |
就像第一个笔记本中所做的那样,我们保留了 2004 年至今的数据作为测试集。
sep_idx = air.index.searchsorted(pd.to_datetime("2003-12-15"))
air_test = air.iloc[sep_idx:, :]
air = air.iloc[: sep_idx + 1, :]
plt.plot(air.year.values, air.CO2.values, ".b", label="atmospheric CO2")
plt.plot(ice.year.values, ice.CO2.values, ".", color="c", label="ice core CO2")
plt.legend()
plt.xlabel("year")
plt.ylabel("CO2 (ppm)");
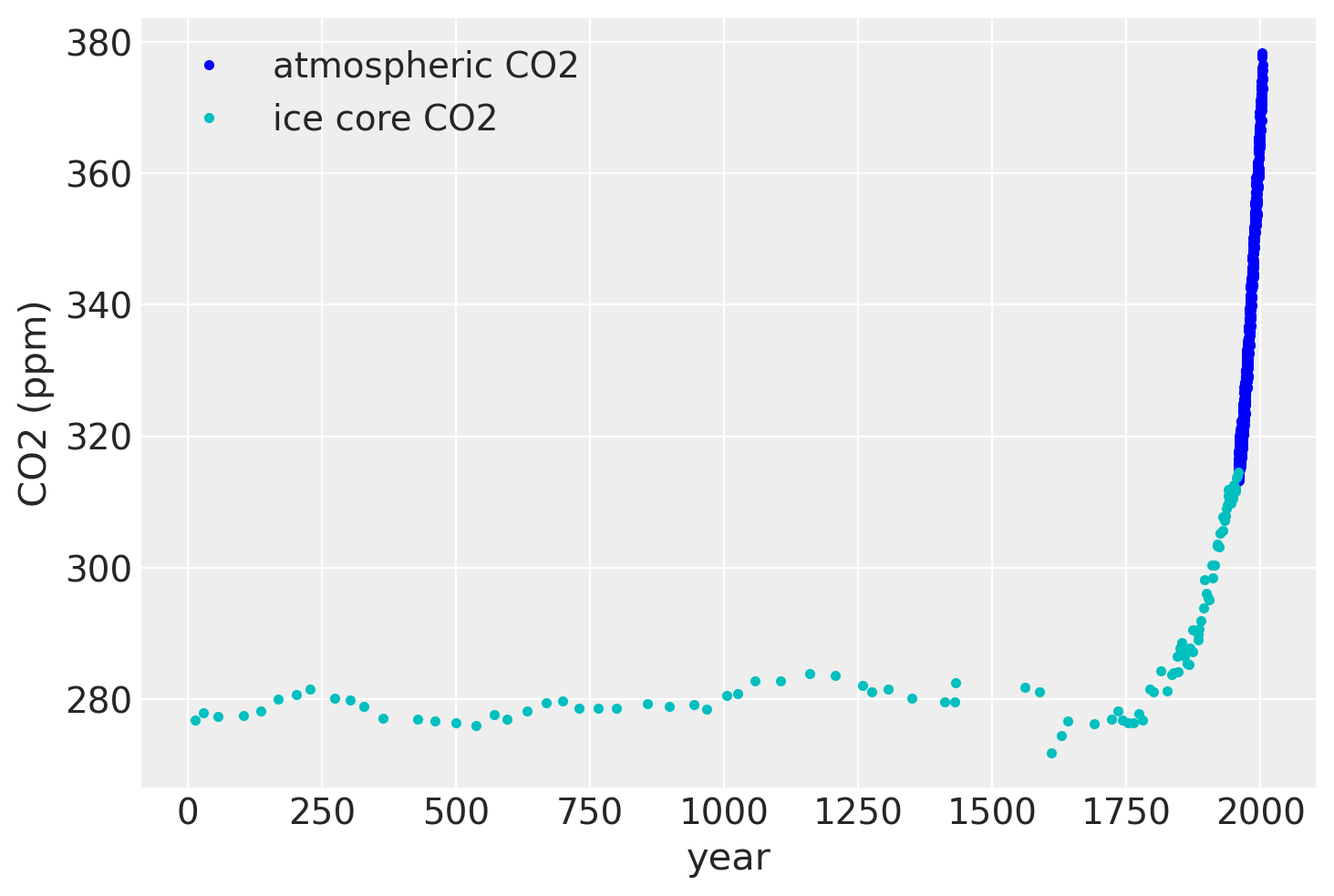
如果我们放大 1950 年代后期,我们可以看到大气数据具有季节性成分,而冰芯数据则没有。
plt.plot(air.year.values, air.CO2.values, ".b", label="atmospheric CO2")
plt.plot(ice.year.values, ice.CO2.values, ".", color="c", label="ice core CO2")
plt.xlim([1949, 1965])
plt.ylim([305, 325])
plt.legend()
plt.xlabel("year")
plt.ylabel("CO2 (ppm)");
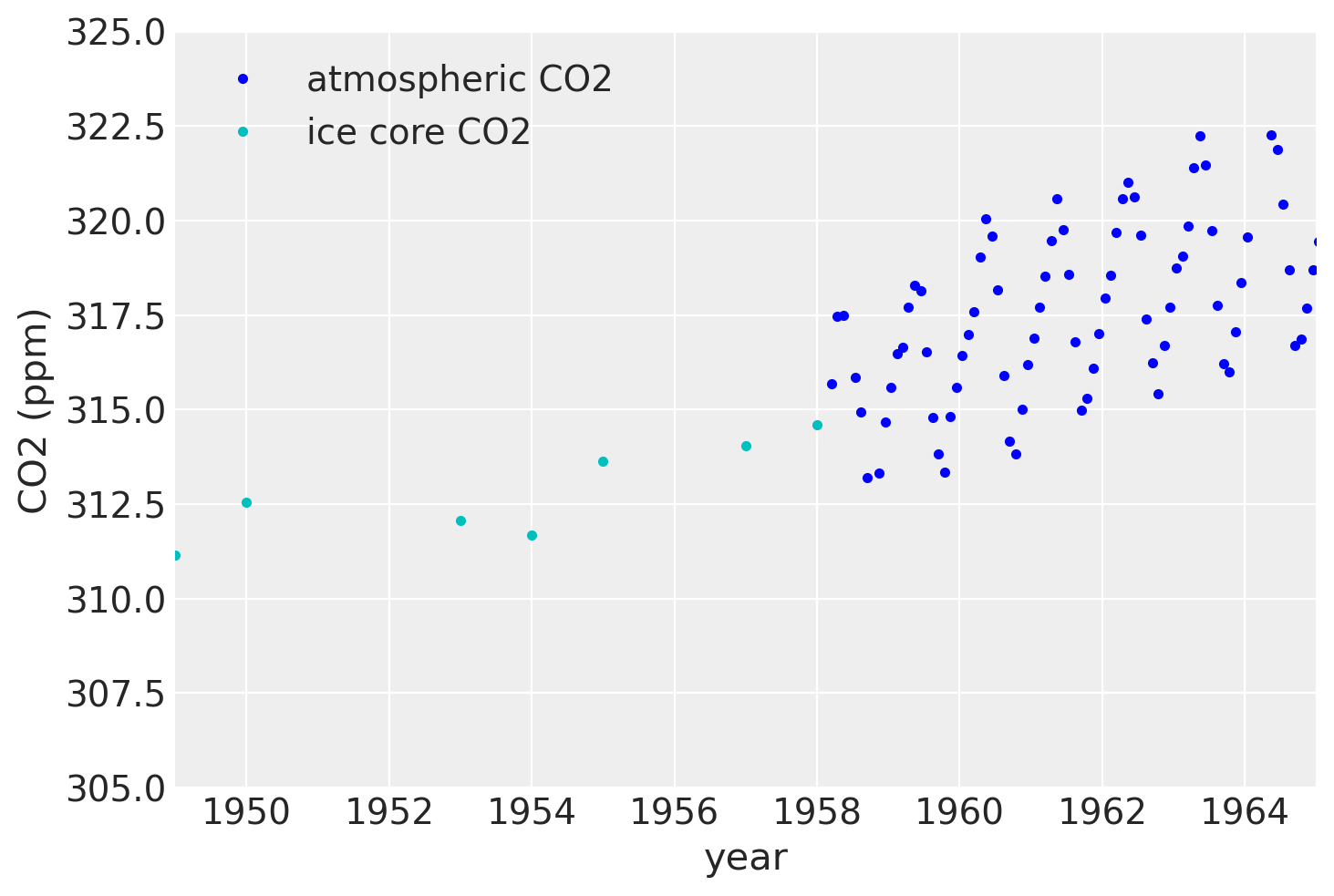
由于冰芯数据的测量不准确,因此除非我们对 x 中的不确定性进行建模,否则不可能反向预测季节性成分,除非我们对 x 中的不确定性进行建模。
为了将这两个数据一起建模,我们将结合我们使用冰芯数据构建的模型,并将其与之前关于 Mauna Loa 数据的笔记本中的元素结合起来。从之前的笔记本中,我们将额外包括:
Periodic,季节性成分RatQuad协方差,用于短程、年度规模的变化
此外,由于我们正在使用两个不同的数据集,因此应该有两个不同的 y 方向不确定性,一个用于冰芯数据,一个用于大气数据。为了实现这一点,我们制作了一个自定义的 WhiteNoise 协方差函数,它有两个 σ 参数。
所有自定义协方差函数都需要定义相同的三个方法:__init__、diag 和 full。full 返回完整的协方差,给定 X 或 X 和不同的 Xs。diag 仅返回对角线,__init__ 保存输入参数。
class CustomWhiteNoise(pm.gp.cov.Covariance):
"""Custom White Noise covariance
- sigma1 is applied to the first n1 points in the data
- sigma2 is applied to the next n2 points in the data
The total number of data points n = n1 + n2
"""
def __init__(self, sigma1, sigma2, n1, n2):
super().__init__(1, None)
self.sigma1 = sigma1
self.sigma2 = sigma2
self.n1 = n1
self.n2 = n2
def diag(self, X):
d1 = tt.alloc(tt.square(self.sigma1), self.n1)
d2 = tt.alloc(tt.square(self.sigma2), self.n2)
return tt.concatenate((d1, d2), 0)
def full(self, X, Xs=None):
if Xs is None:
return tt.diag(self.diag(X))
else:
return tt.alloc(0.0, X.shape[0], Xs.shape[0])
接下来,我们需要组织和合并这两个数据集。请记住,x 轴上的单位是世纪,而不是年。
# form dataset, stack t and co2 measurements
t = np.concatenate((ice.year.values, air.year.values), 0)
y = np.concatenate((ice.CO2.values, air.CO2.values), 0)
y_mu, y_sd = np.mean(ice.CO2.values[0:50]), np.std(y)
y_n = (y - y_mu) / y_sd
t_n = t * 0.01
模型的规范如下。数据集现在更大了,因此 MCMC 现在需要更长的时间。但是您会看到,估计整个后验是绝对值得等待的!
我们还更仔细地选择了超参数的先验。对于突变点协方差,我们使用 ExpQuad 协方差对后工业革命数据进行建模,该协方差具有与工业革命前相同的更长长度尺度。这个想法是,无论之前是什么过程在起作用,之后仍然存在。但随后我们添加了 Polynomial(degree=2) 和 Matern52 的乘积。我们将 Matern52 的长度尺度固定为 2。由于工业革命至今只有大约两个世纪,因此我们强制多项式分量在该时间尺度上衰减。这迫使不确定性在该时间尺度上上升。
2 次多项式和 Matern52 乘积表达了我们的先验信念,即 CO2 水平可能会半二次方地增加,或半二次方地减少,因为此乘积的缩放参数也可能最终为零。
with pm.Model() as model:
ηc = pm.Gamma("ηc", alpha=3, beta=2)
ℓc = pm.Gamma("ℓc", alpha=10, beta=1)
# changepoint occurs near the year 1800, sometime between 1760, 1840
x0 = pm.Normal("x0", mu=18, sigma=0.1)
# the change happens gradually
a = pm.Gamma("a", alpha=3, beta=1)
# constant offset
c = pm.HalfNormal("c", sigma=2)
# quadratic polynomial scale
ηq = pm.HalfNormal("ηq", sigma=1)
ℓq = 2.0 # 2 century impact, since we only have 2 C of post IR data
cov1 = ηc**2 * pm.gp.cov.ExpQuad(1, ℓc)
cov2 = ηc**2 * pm.gp.cov.ExpQuad(1, ℓc) + ηq**2 * pm.gp.cov.Polynomial(
1, x0, 2, c
) * pm.gp.cov.Matern52(
1, ℓq
) # ~2 century impact
# construct changepoint cov
sc_cov1 = pm.gp.cov.ScaledCov(1, cov1, logistic, (-a, x0))
sc_cov2 = pm.gp.cov.ScaledCov(1, cov2, logistic, (a, x0))
gp_c = pm.gp.Marginal(cov_func=sc_cov1 + sc_cov2)
# short term variation
ηs = pm.HalfNormal("ηs", sigma=3)
ℓs = pm.Gamma("ℓs", alpha=5, beta=100)
α = pm.Gamma("α", alpha=4, beta=1)
cov_s = ηs**2 * pm.gp.cov.RatQuad(1, α, ℓs)
gp_s = pm.gp.Marginal(cov_func=cov_s)
# medium term variation
ηm = pm.HalfNormal("ηm", sigma=5)
ℓm = pm.Gamma("ℓm", alpha=2, beta=3)
cov_m = ηm**2 * pm.gp.cov.ExpQuad(1, ℓm)
gp_m = pm.gp.Marginal(cov_func=cov_m)
## periodic
ηp = pm.HalfNormal("ηp", sigma=2)
ℓp_decay = pm.Gamma("ℓp_decay", alpha=40, beta=0.1)
ℓp_smooth = pm.Normal("ℓp_smooth ", mu=1.0, sigma=0.05)
period = 1 * 0.01 # we know the period is annual
cov_p = ηp**2 * pm.gp.cov.Periodic(1, period, ℓp_smooth) * pm.gp.cov.ExpQuad(1, ℓp_decay)
gp_p = pm.gp.Marginal(cov_func=cov_p)
gp = gp_c + gp_m + gp_s + gp_p
# - x location uncertainty (sd = 0.01 is a standard deviation of one year)
# - only the first 111 points are the ice core data
t_mu = t_n[:111]
t_diff = pm.Normal("t_diff", mu=0.0, sigma=0.02, shape=len(t_mu))
t_uncert = t_mu - t_diff
t_combined = tt.concatenate((t_uncert, t_n[111:]), 0)
# Noise covariance, using boundary avoiding priors for MAP estimation
σ1 = pm.Gamma("σ1", alpha=3, beta=50)
σ2 = pm.Gamma("σ2", alpha=3, beta=50)
η_noise = pm.HalfNormal("η_noise", sigma=1)
ℓ_noise = pm.Gamma("ℓ_noise", alpha=2, beta=200)
cov_noise = η_noise**2 * pm.gp.cov.Matern32(1, ℓ_noise) + CustomWhiteNoise(σ1, σ2, 111, 545)
y_ = gp.marginal_likelihood("y", X=t_combined[:, None], y=y_n, noise=cov_noise)
/Users/alex_andorra/tptm_alex/pymc3/pymc3/gp/cov.py:93: UserWarning: Only 1 column(s) out of Subtensor{int64}.0 are being used to compute the covariance function. If this is not intended, increase 'input_dim' parameter to the number of columns to use. Ignore otherwise.
" the number of columns to use. Ignore otherwise.", UserWarning)
/Users/alex_andorra/tptm_alex/pymc3/pymc3/gp/cov.py:93: UserWarning: Only 1 column(s) out of Subtensor{int64}.0 are being used to compute the covariance function. If this is not intended, increase 'input_dim' parameter to the number of columns to use. Ignore otherwise.
" the number of columns to use. Ignore otherwise.", UserWarning)
/Users/alex_andorra/tptm_alex/pymc3/pymc3/gp/cov.py:93: UserWarning: Only 1 column(s) out of Subtensor{int64}.0 are being used to compute the covariance function. If this is not intended, increase 'input_dim' parameter to the number of columns to use. Ignore otherwise.
" the number of columns to use. Ignore otherwise.", UserWarning)
with model:
tr = pm.sample(500, tune=1000, chains=2, cores=16, return_inferencedata=True)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 16 jobs)
NUTS: [ℓ_noise, η_noise, σ2, σ1, t_diff, ℓp_smooth , ℓp_decay, ηp, ℓm, ηm, α, ℓs, ηs, ηq, c, a, x0, ℓc, ηc]
Sampling 2 chains for 1_000 tune and 500 draw iterations (2_000 + 1_000 draws total) took 79100 seconds.
There were 17 divergences after tuning. Increase `target_accept` or reparameterize.
The rhat statistic is larger than 1.4 for some parameters. The sampler did not converge.
The estimated number of effective samples is smaller than 200 for some parameters.
az.plot_trace(tr, compact=True);
/Users/alex_andorra/opt/anaconda3/envs/dev-pymc/lib/python3.6/site-packages/arviz/data/io_pymc3.py:89: FutureWarning: Using `from_pymc3` without the model will be deprecated in a future release. Not using the model will return less accurate and less useful results. Make sure you use the model argument or call from_pymc3 within a model context.
FutureWarning,
tnew = np.linspace(1700, 2040, 3000) * 0.01
with model:
fnew = gp.conditional("fnew", Xnew=tnew[:, None])
/Users/alex_andorra/tptm_alex/pymc3/pymc3/gp/cov.py:93: UserWarning: Only 1 column(s) out of Subtensor{int64}.0 are being used to compute the covariance function. If this is not intended, increase 'input_dim' parameter to the number of columns to use. Ignore otherwise.
" the number of columns to use. Ignore otherwise.", UserWarning)
with model:
ppc = pm.sample_posterior_predictive(tr, samples=200, var_names=["fnew"])
/Users/alex_andorra/tptm_alex/pymc3/pymc3/sampling.py:1708: UserWarning: samples parameter is smaller than nchains times ndraws, some draws and/or chains may not be represented in the returned posterior predictive sample
"samples parameter is smaller than nchains times ndraws, some draws "
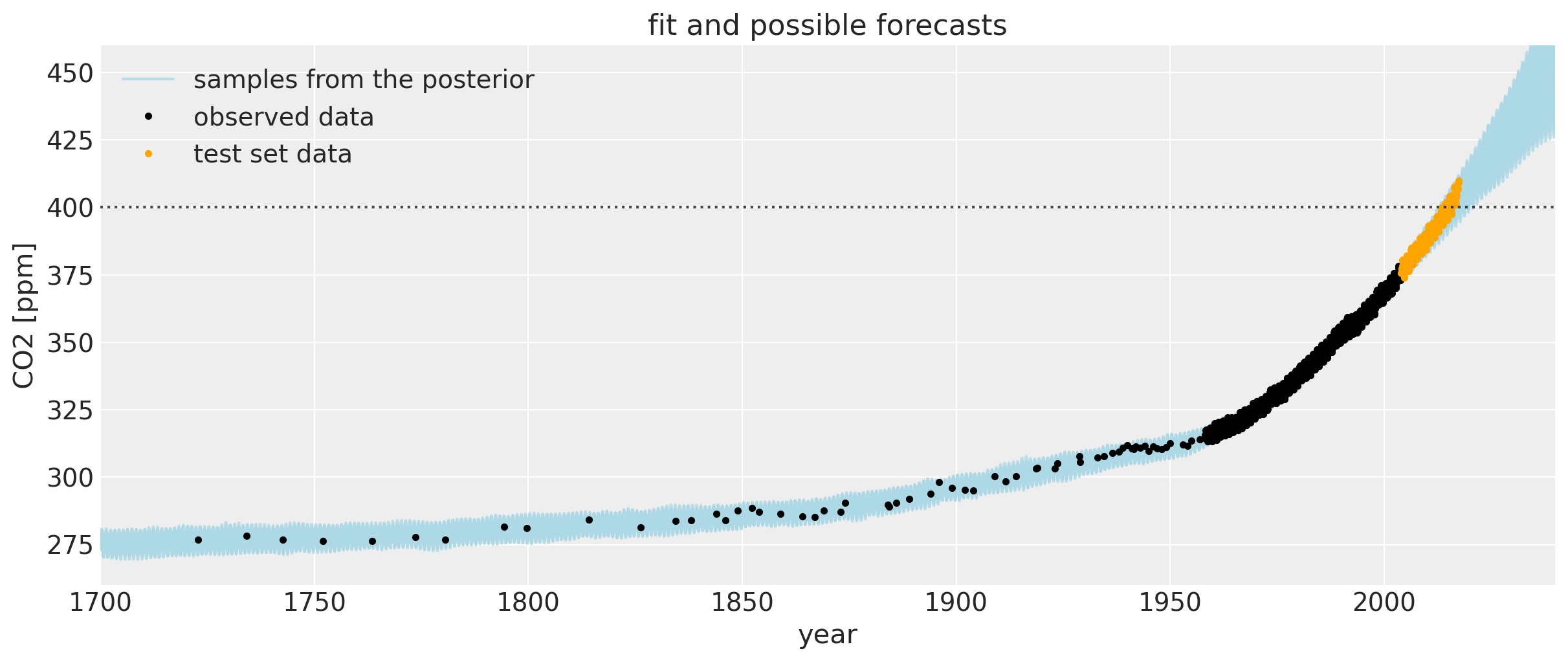
下面是从 18 世纪至今(Mauna Loa 和 Law Dome 冰芯数据)用于拟合模型的数据图。浅蓝色线条在此缩放级别下有点难以辨认,但它们是来自高斯过程后验的样本。它们既插值了观测数据,又代表了未来预测的合理轨迹。这些样本也可以替代地用于定义可信区间。
plt.figure(figsize=(12, 5))
plt.plot(tnew * 100, y_sd * ppc["fnew"][0:200:5, :].T + y_mu, color="lightblue", alpha=0.8)
plt.plot(
[-1000, -1001],
[-1000, -1001],
color="lightblue",
alpha=0.8,
label="samples from the posterior",
)
plt.plot(t, y, "k.", label="observed data")
plt.plot(
air_test.year.values,
air_test.CO2.values,
".",
color="orange",
label="test set data",
)
plt.axhline(y=400, color="k", alpha=0.7, linestyle=":")
plt.ylabel("CO2 [ppm]")
plt.xlabel("year")
plt.title("fit and possible forecasts")
plt.legend()
plt.xlim([1700, 2040])
plt.ylim([260, 460]);
让我们放大一下,更仔细地看一下 CO2 水平首次超过 400 ppm 区域附近的不确定性区间。我们可以看到,后验样本给出了未来可能轨迹的范围。请注意,橙色绘制的数据未用于拟合模型。
plt.figure(figsize=(12, 5))
plt.plot(tnew * 100, y_sd * ppc["fnew"][0:200:5, :].T + y_mu, color="lightblue", alpha=0.8)
plt.plot(
[-1000, -1001],
[-1000, -1001],
color="lightblue",
alpha=0.8,
label="samples from the posterior",
)
plt.plot(
air_test.year.values,
air_test.CO2.values,
".",
color="orange",
label="test set data",
)
plt.axhline(y=400, color="k", alpha=0.7, linestyle=":")
plt.ylabel("CO2 [ppm]")
plt.xlabel("year")
plt.title("fit and possible forecasts")
plt.legend()
plt.xlim([2004, 2040])
plt.ylim([360, 460]);
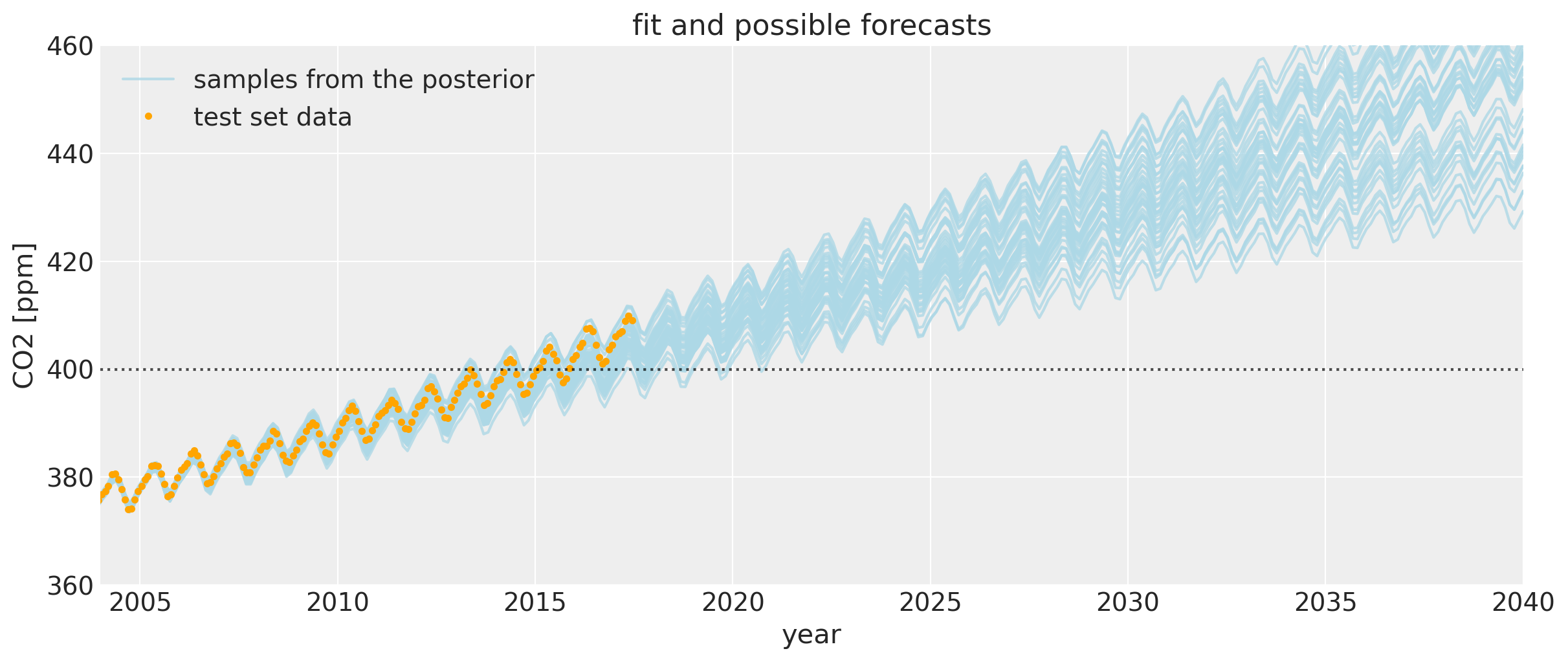
如果将其与第一个 Mauna Loa 示例笔记本进行比较,预测会好得多。CO2 水平首次达到 400 的日期预测得更加准确。偏差的这种改进是由于包括了 Polynomial * Matern52 项和突变点模型。
我们还可以查看模型对过去 CO2 水平的说法。由于我们允许 x 测量值具有不确定性,因此我们能够及时回溯季节性成分。可以肯定的是,从科学的角度来看,使用冰芯数据反向预测 Mauna Loa CO2 测量值实际上没有意义,因为由于季节性变化,CO2 水平因您在地球上的位置而异。Mauna Loa 将具有更明显的周期性模式,因为北半球的植被更多。植被量在很大程度上驱动了夏季和冬季植物生长和死亡引起的季节性。但这只是因为很酷,所以让我们无论如何看看这里模型的拟合情况
tnew = np.linspace(11, 32, 500) * 0.01
with model:
fnew2 = gp.conditional("fnew2", Xnew=tnew[:, None])
/Users/alex_andorra/tptm_alex/pymc3/pymc3/gp/cov.py:93: UserWarning: Only 1 column(s) out of Subtensor{int64}.0 are being used to compute the covariance function. If this is not intended, increase 'input_dim' parameter to the number of columns to use. Ignore otherwise.
" the number of columns to use. Ignore otherwise.", UserWarning)
with model:
ppc = pm.sample_posterior_predictive(tr, samples=200, var_names=["fnew2"])
/Users/alex_andorra/tptm_alex/pymc3/pymc3/sampling.py:1708: UserWarning: samples parameter is smaller than nchains times ndraws, some draws and/or chains may not be represented in the returned posterior predictive sample
"samples parameter is smaller than nchains times ndraws, some draws "
plt.figure(figsize=(12, 5))
plt.plot(tnew * 100, y_sd * ppc["fnew2"][0:200:10, :].T + y_mu, color="lightblue", alpha=0.8)
plt.plot(
[-1000, -1001],
[-1000, -1001],
color="lightblue",
alpha=0.8,
label="samples from the GP posterior",
)
plt.plot(100 * (t_n[:111][:, None] - tr["t_diff"].T), y[:111], "oy", alpha=0.01)
plt.plot(
[100, 200],
[100, 200],
"oy",
alpha=0.3,
label="data location posterior samples reflecting ice core time measurement uncertainty",
)
plt.plot(t, y, "k.", label="observed data")
plt.plot(air_test.year.values, air_test.CO2.values, ".", color="orange")
plt.legend(loc="upper left")
plt.ylabel("CO2 [ppm]")
plt.xlabel("year")
plt.xlim([12, 31])
plt.xticks(np.arange(12, 32))
plt.ylim([272, 283]);
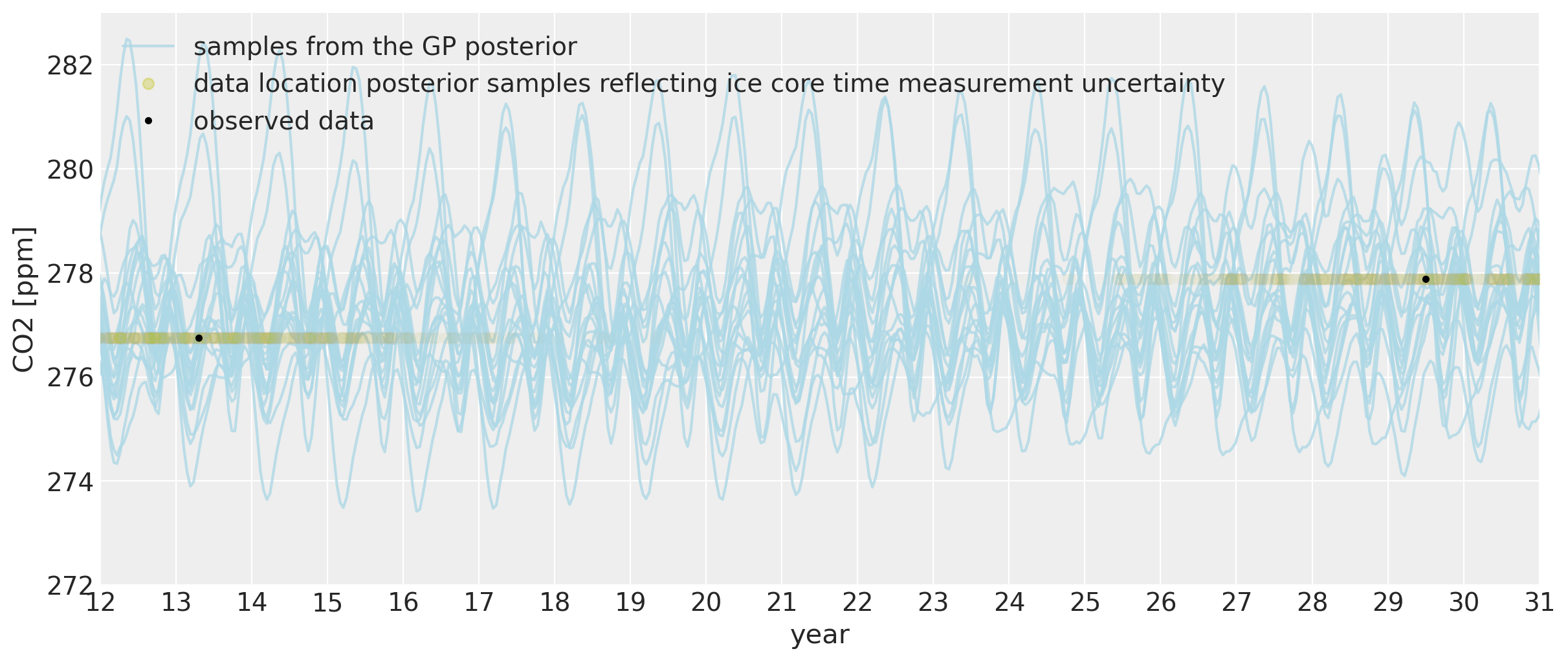
我们可以看到,在很久以前,我们甚至可以在一定程度上反向预测季节性行为。 x 位置中约 2 年的不确定性允许它们移至该年份季节性振荡的最近部分。振荡的幅度与现代相同。虽然每个后验样本中的周期仍然具有年度周期,但由于我们远离 Mauna Loa 数据收集的日期,因此其确切形态不太确定。
tnew = np.linspace(-20, 0, 300) * 0.01
with model:
fnew3 = gp.conditional("fnew3", Xnew=tnew[:, None])
/Users/alex_andorra/tptm_alex/pymc3/pymc3/gp/cov.py:93: UserWarning: Only 1 column(s) out of Subtensor{int64}.0 are being used to compute the covariance function. If this is not intended, increase 'input_dim' parameter to the number of columns to use. Ignore otherwise.
" the number of columns to use. Ignore otherwise.", UserWarning)
with model:
ppc = pm.sample_posterior_predictive(tr, samples=200, var_names=["fnew3"])
/Users/alex_andorra/tptm_alex/pymc3/pymc3/sampling.py:1708: UserWarning: samples parameter is smaller than nchains times ndraws, some draws and/or chains may not be represented in the returned posterior predictive sample
"samples parameter is smaller than nchains times ndraws, some draws "
plt.figure(figsize=(12, 5))
plt.plot(tnew * 100, y_sd * ppc["fnew3"][0:200:10, :].T + y_mu, color="lightblue", alpha=0.8)
plt.plot(
[-1000, -1001],
[-1000, -1001],
color="lightblue",
alpha=0.8,
label="samples from the GP posterior",
)
plt.legend(loc="upper left")
plt.ylabel("CO2 [ppm]")
plt.xlabel("year")
plt.xlim([-20, 0])
plt.ylim([272, 283]);
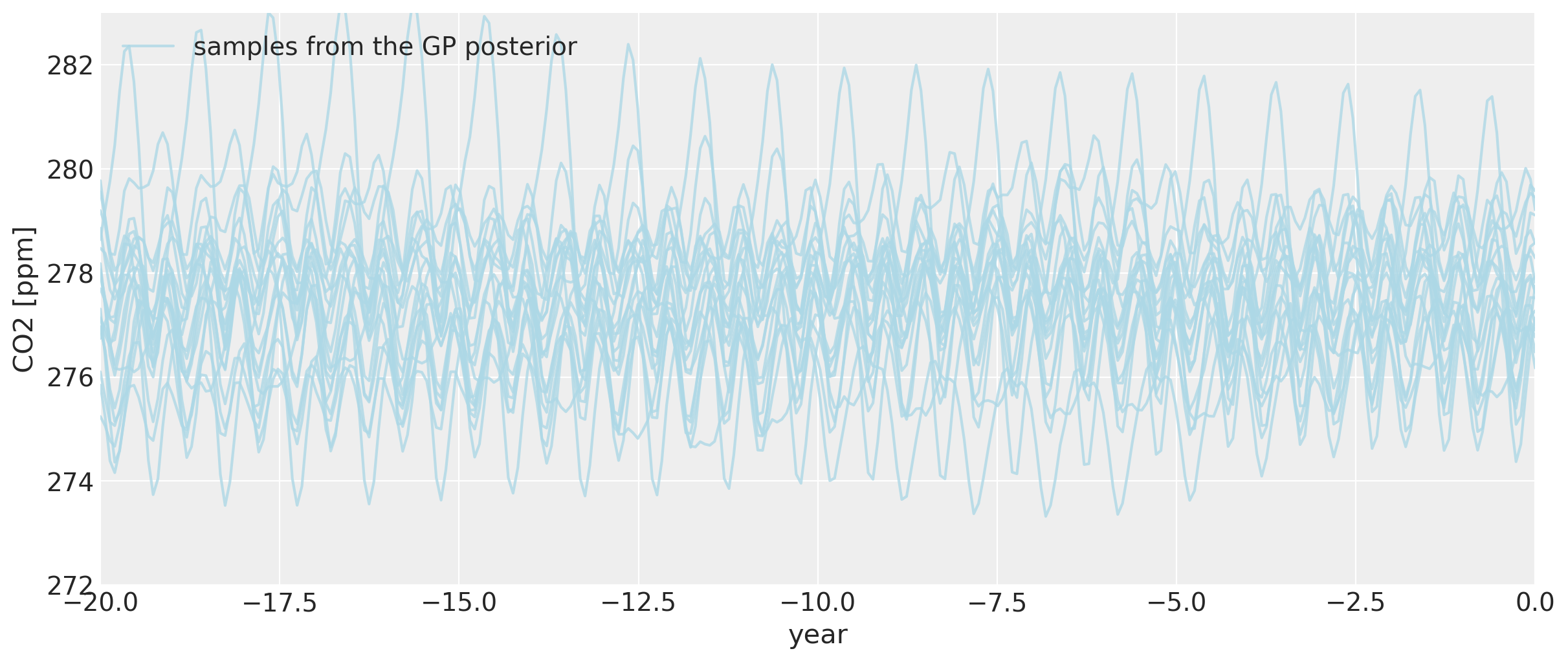
即使我们回到公元前零年之前,一般反向预测的季节性模式仍然完好无损,尽管它确实开始更加剧烈地变化。
结论#
此笔记本的目标是帮助提供一些关于如何利用 PyMC3 GP 建模功能的灵活性的想法。数据很少来自单一来源的整齐、均匀采样的间隔,这对于一般的 GP 模型来说不是问题。为了实现有趣的行为建模,可以轻松定义自定义协方差和均值函数。无需担心计算梯度,因为这由 Theano 的自动微分功能处理。能够在 PyMC3 中将极高质量的 NUTS 采样器与 GP 模型一起使用意味着可以使用来自后验分布的样本作为可能的预测,这些预测考虑了均值和协方差函数超参数的不确定性。
%load_ext watermark
%watermark -n -u -v -iv -w
theano 1.0.5
pandas 1.1.0
numpy 1.19.1
pymc3 3.9.3
arviz 0.9.0
last updated: Sun Aug 09 2020
CPython 3.6.11
IPython 7.16.1
watermark 2.0.2