


序贯蒙特卡洛#
import arviz as az
import numpy as np
import pymc as pm
import pytensor.tensor as pt
print(f"Running on PyMC v{pm.__version__}")
Running on PyMC v4.0.0b6
az.style.use("arviz-darkgrid")
使用标准 MCMC 方法从具有多个峰值的分布中采样可能很困难,甚至不可能,因为马尔可夫链通常会陷入其中一个最小值。序贯蒙特卡洛采样器 (SMC) 是一种改善此问题的方法。
由于 SMC 有许多变体,在本笔记本中,我们将重点关注 PyMC 中实现的版本。
SMC 结合了几个统计思想,包括重要性采样、退火和 MCMC。退火是指使用辅助温度参数来控制采样过程。要了解退火如何提供帮助,让我们将后验写成
当 \(\beta=0\) 时,我们有 \(p(\theta \mid y)_{\beta=0}\) 是先验分布,当 \(\beta=1\) 时,我们恢复真实后验。我们可以将 \(\beta\) 视为一个旋钮,我们可以用它来逐渐淡入似然性。这可能很有用,因为通常从先验分布中采样比从后验分布中采样更容易。因此,我们可以使用 \(\beta\) 来控制从易于采样的分布到更难采样的分布的过渡。
算法总结如下
将 \(\beta\) 初始化为零,并将阶段设置为零。
从先验分布生成 N 个样本 \(S_{\beta}\)(因为当 \(\beta = 0\) 时,退火后验是先验分布)。
增加 \(\beta\) 以使有效样本大小等于某个预定义值(我们默认使用 \(Nt\),其中 \(t\) 为 0.5)。
计算一组 N 个重要性权重 \(W\)。权重计算为阶段 \(i+1\) 和阶段 \(i\) 样本的似然率。
通过根据 \(W\) 重新采样获得 \(S_{w}\)。
使用 \(W\) 计算提议分布(MVNormal)的均值和协方差。
对于阶段 0 以外的阶段,使用前一阶段的接受率来估计
n_steps。运行 N 个独立的 Metropolis-Hastings (IMH) 链(每个链的长度为
n_steps),每个链从 \(S_{w}\) 中的不同样本开始。样本是 IMH,因为提议均值是前一个后验阶段的均值,而不是参数空间中的当前点。从步骤 3 重复,直到 \(\beta \ge 1\)。
最终结果是来自后验的 \(N\) 个样本的集合
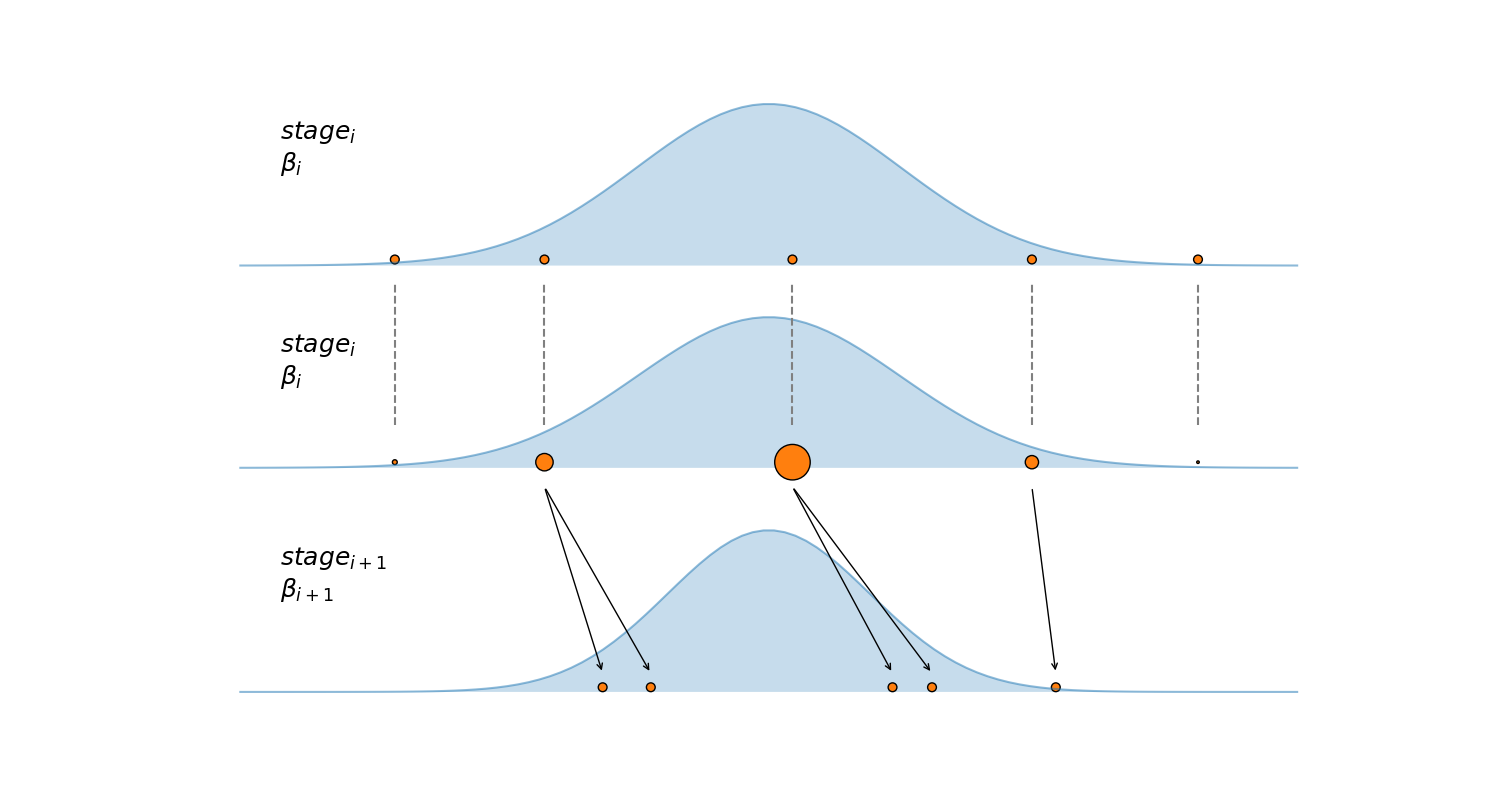
该算法在下图进行总结,第一个子图显示了在某个特定阶段的 5 个样本(橙色点)。第二个子图显示了这些样本如何根据其后验密度(蓝色高斯曲线)重新加权。第三个子图显示了运行一定数量的 IMH 步长的结果,从第二个子图中的重新加权样本 \(S_{w}\) 开始,请注意后验密度较低的两个样本(较小的圆圈)被丢弃,并且不用于播种新的马尔可夫链。
SMC 采样器也可以根据遗传算法进行解释,遗传算法是受生物学启发的算法,可以总结如下
初始化:设置一个个体种群
变异:个体以某种方式被修改或扰动
选择:具有高适应度的个体更有可能产生后代。
迭代:使用步骤 3 中的个体来设置步骤 1 中的种群。
如果每个个体都是问题的特定解决方案,那么遗传算法最终将产生该问题的良好解决方案。一个关键方面是产生足够的多样性(变异步骤)以探索解空间,从而避免陷入局部最小值。然后我们执行选择步骤,以概率性地保留合理的解决方案,同时保持一定的多样性。过于贪婪和目光短浅可能会有问题,在给定时刻的坏解决方案可能会在未来导致好解决方案。
对于 PyMC 中实现的 SMC 版本,我们使用 draws 参数设置并行马尔可夫链的数量 \(N\)。在每个阶段,SMC 将使用独立的马尔可夫链来探索退火后验(图中的黑色箭头)。最终样本,即存储在 trace 中的样本,将完全从最后阶段 (\(\beta = 1\)) 中获取,即真实后验(数学意义上的“真实”)。
\(\beta\) 的连续值是自动确定的(步骤 3)。分布越难采样,\(\beta\) 的两个连续值就越接近。SMC 将花费的阶段数也越多。SMC 通过将两个阶段之间的有效样本大小 (ESS) 保持在恒定的预定义值(抽取数量的一半)来计算下一个 \(\beta\) 值。如果需要,可以通过 threshold 参数(在区间 [0, 1] 内)调整此值——当前默认值 0.5 通常被认为是良好的默认值。此值越大,目标 ESS 越高,并且 \(\beta\) 的两个连续值将越接近。此 ESS 值是从重要性权重(步骤 4)计算得出的,而不是像 ArviZ 中的那些值那样从自相关性计算得出(例如,使用 az.ess 或 az.summary)。
另外两个自动确定的参数是
每个马尔可夫链探索退火后验
n_steps所需的步数。这由前一阶段的接受率确定。MVNormal 提议分布的协方差也会根据每个阶段的接受率自适应地调整。
与其他采样方法一样,多次运行采样器对于计算诊断信息很有用,SMC 也不例外。PyMC 将尝试至少运行两个SMC链(不要与每个 SMC 链内的 \(N\) 马尔可夫链混淆)。
即使 SMC 在底层使用了 Metropolis-Hasting 算法,它也比它具有几个优势
它可以从具有多个峰值的分布中采样。
它没有老化期,它首先直接从先验分布中采样,然后在每个阶段,起始点已经近似根据退火后验分布(由于重新加权步骤)。
它是固有的并行性。
使用 SMC 求解 PyMC 模型#
为了查看如何在 PyMC 中使用 SMC 的示例,让我们定义一个维度为 \(n\) 的多元高斯分布,其中包含两个模式、每个模式的权重和协方差矩阵。
n = 4
mu1 = np.ones(n) * (1.0 / 2)
mu2 = -mu1
stdev = 0.1
sigma = np.power(stdev, 2) * np.eye(n)
isigma = np.linalg.inv(sigma)
dsigma = np.linalg.det(sigma)
w1 = 0.1 # one mode with 0.1 of the mass
w2 = 1 - w1 # the other mode with 0.9 of the mass
def two_gaussians(x):
log_like1 = (
-0.5 * n * pt.log(2 * np.pi)
- 0.5 * pt.log(dsigma)
- 0.5 * (x - mu1).T.dot(isigma).dot(x - mu1)
)
log_like2 = (
-0.5 * n * pt.log(2 * np.pi)
- 0.5 * pt.log(dsigma)
- 0.5 * (x - mu2).T.dot(isigma).dot(x - mu2)
)
return pm.math.logsumexp([pt.log(w1) + log_like1, pt.log(w2) + log_like2])
with pm.Model() as model:
X = pm.Uniform(
"X",
shape=n,
lower=-2.0 * np.ones_like(mu1),
upper=2.0 * np.ones_like(mu1),
initval=-1.0 * np.ones_like(mu1),
)
llk = pm.Potential("llk", two_gaussians(X))
idata_04 = pm.sample_smc(2000)
Initializing SMC sampler...
Sampling 4 chains in 4 jobs
我们可以从消息中看到 PyMC 正在并行运行四个SMC 链。如前所述,这对于诊断很有用。与其他采样器一样,一个有用的诊断是 plot_trace,这里我们使用 kind="rank_vlines",因为秩图通常比经典的“trace”更有用
ax = az.plot_trace(idata_04, compact=True, kind="rank_vlines")
ax[0, 0].axvline(-0.5, 0, 0.9, color="k")
ax[0, 0].axvline(0.5, 0, 0.1, color="k")
f'Estimated w1 = {np.mean(idata_04.posterior["X"] < 0).item():.3f}'
'Estimated w1 = 0.907'

从 KDE 中我们可以看到,我们恢复了模式,甚至相对权重看起来也相当不错。右侧的秩图看起来也不错。一个 SMC 链以蓝色表示,另一个以橙色表示。垂直线表示与理想期望值的偏差,理想期望值用黑色虚线表示。如果垂直线高于参考黑色虚线,则我们获得的样本多于预期,如果垂直线低于参考黑色虚线,则采样器获得的样本少于预期。像上图中的偏差是可以接受的,而不是引起关注的原因。
如前所述,SMC 在内部计算 ESS 的估计值(来自重要性权重)。这些 ESS 值对于诊断没有用处,因为它们是固定的目标值。我们可以从 sample_smc 返回的跟踪中计算 ESS 值,但这也不是非常有用的诊断,因为此 ESS 值的计算考虑了自相关性,并且每个 SMC 运行/链在构造上都具有低自相关性,对于大多数问题,ESS 值将非常接近总样本数(即抽取数 x 链)。通常,只有当每个 SMC 链探索不同的模式时,它才会是一个低数字,在这种情况下,ESS 的值将接近模式的数量。
杀死你的宠儿#
SMC 并非没有问题,随着问题维度的增加,采样可能会恶化,特别是对于多模态后验或奇怪的几何形状(如分层模型)。在某种程度上,增加抽取数量可能会有所帮助。增加参数 p_acc_rate 的值也是一个好主意。此参数控制每个阶段步数的计算方式。要访问每个阶段的步数,您可以检查 trace.report.nsteps。理想情况下,SMC 将采用小于 n_steps 的步数。但是,如果每个阶段的实际步数为 n_steps,对于几个阶段,这可能表明我们也应该增加 n_steps。
让我们看看当我们在运行与之前相同的模型时,将维度从 4 增加到 80 时,SMC 的性能如何。
n = 80
mu1 = np.ones(n) * (1.0 / 2)
mu2 = -mu1
stdev = 0.1
sigma = np.power(stdev, 2) * np.eye(n)
isigma = np.linalg.inv(sigma)
dsigma = np.linalg.det(sigma)
w1 = 0.1 # one mode with 0.1 of the mass
w2 = 1 - w1 # the other mode with 0.9 of the mass
def two_gaussians(x):
log_like1 = (
-0.5 * n * pt.log(2 * np.pi)
- 0.5 * pt.log(dsigma)
- 0.5 * (x - mu1).T.dot(isigma).dot(x - mu1)
)
log_like2 = (
-0.5 * n * pt.log(2 * np.pi)
- 0.5 * pt.log(dsigma)
- 0.5 * (x - mu2).T.dot(isigma).dot(x - mu2)
)
return pm.math.logsumexp([pt.log(w1) + log_like1, pt.log(w2) + log_like2])
with pm.Model() as model:
X = pm.Uniform(
"X",
shape=n,
lower=-2.0 * np.ones_like(mu1),
upper=2.0 * np.ones_like(mu1),
initval=-1.0 * np.ones_like(mu1),
)
llk = pm.Potential("llk", two_gaussians(X))
idata_80 = pm.sample_smc(2000)
Initializing SMC sampler...
Sampling 4 chains in 4 jobs
我们看到 SMC 认识到这是一个更难的问题,并增加了阶段数。我们可以看到 SMC 仍然从两种模式中采样,但现在权重较高的模型被过度采样(我们获得的相对权重为 0.99 而不是 0.9)。请注意,秩图看起来比 n=4 时更差。
ax = az.plot_trace(idata_80, compact=True, kind="rank_vlines")
ax[0, 0].axvline(-0.5, 0, 0.9, color="k")
ax[0, 0].axvline(0.5, 0, 0.1, color="k")
f'Estimated w1 = {np.mean(idata_80.posterior["X"] < 0).item():.3f}'
'Estimated w1 = 0.991'

您可能想要重复 n=80 的 SMC 采样,并更改一个或多个默认参数,以查看是否可以改进采样以及采样器计算后验所需的时间。
%load_ext watermark
%watermark -n -u -v -iv -w -p xarray
Last updated: Tue May 31 2022
Python implementation: CPython
Python version : 3.9.7
IPython version : 8.3.0
xarray: 2022.3.0
sys : 3.9.7 (default, Sep 16 2021, 13:09:58)
[GCC 7.5.0]
arviz : 0.12.0
numpy : 1.21.5
pytensor: 2.6.2
pymc : 4.0.0b6
Watermark: 2.3.0