


使用自定义步长方法从局部共轭后验分布中采样#
简介#
马尔可夫链蒙特卡洛 (MCMC) 抽样方法是现代贝叶斯推断的基础。PyMC 利用哈密顿蒙特卡洛 (HMC),这是一种强大的抽样算法,可以有效地探索高维后验分布。与更简单的 MCMC 方法不同,HMC 利用对数后验密度的梯度进行智能提议,使其能够有效地对具有数百或数千个参数的复杂后验进行抽样。HMC 的一个关键优势是其通用性——它可以与任意先验分布和似然函数一起使用,而无需共轭对或闭式解。这至关重要,因为大多数现实世界的模型都涉及先验和似然,它们的乘积无法进行解析积分以获得后验分布。HMC 的梯度引导提议使其比早期依赖随机游走或简单提议分布的 MCMC 方法效率更高。
然而,对于变量和观测数据之间具有特别复杂的功能依赖关系的模型,这些梯度计算通常可能非常昂贵。在这种情况下,我们可能希望通过利用模型某些部分中的额外结构来找到更快的抽样方案。当模型中的许多变量是共轭的时,条件后验——即,保持所有其他模型变量固定的后验分布——通常可以非常容易地从中采样。这表明使用 HMC 内吉布斯步,我们在可能的情况下交替使用廉价的共轭抽样来处理变量,并对剩余部分使用更昂贵的 HMC。
通常,不建议选择任何替代抽样方法并用它来替换 HMC。即使单个样本的抽取速度更快,这种组合通常也会在有效抽样率方面产生更差的性能。在本笔记本中,我们将展示如何在 PyMC 中实现共轭抽样方案,并将其与完全 HMC(或者,在本例中为 NUTS)方法进行比较。对于这种情况,我们发现使用共轭抽样可以显着加快 Dirichlet-multinomial 模型的计算速度。
概率模型#
为了使本笔记本保持简单,我们将考虑一个相对简单的分层模型,该模型为跨 \(J\) 个结果的计数向量的 \(N\) 个观测值定义:
索引 \(i\in\{1,...,N\}\) 表示观测值,而 \(j\in \{1...,J\}\) 索引结果。变量 \(\tau\) 是标量浓度,而 \(\mathbf{p}_i\) 是从狄利克雷先验中抽取的 \(J\) 维概率向量,条目为 \((\tau, \tau, ..., \tau)\)。对于固定的 \(\tau\) 和观测数据 \(x\),我们知道 \(\mathbf{p}\) 具有 闭式后验分布,这意味着我们可以轻松地从中采样。我们的抽样方案将在 \(\tau\) 上使用无转弯采样器 (NUTS) 和从 \(\mathbf{p}_i\) 的已知条件后验分布中抽取之间交替。我们将假设 \(\lambda\) 的固定值。
实现自定义步长方法#
将共轭采样器添加到我们的复合抽样方法中非常简单:我们定义一个新的步长方法,该方法检查马尔可夫链近似的当前状态,并通过添加从共轭后验中抽取的样本来修改它。
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pymc as pm
from pymc.distributions.transforms import simplex as stick_breaking
from pymc.step_methods.arraystep import BlockedStep
RANDOM_SEED = 8927
np.random.seed(RANDOM_SEED)
az.style.use("arviz-darkgrid")
首先,我们需要一种从狄利克雷分布中采样的方法。内置的 numpy.random.dirichlet 只能处理 2D 输入数组,并且我们将来可能希望将其推广到此范围之外。因此,我创建了一个函数,用于通过将狄利克雷分布表示为 Gamma 随机变量的归一化和,来从具有参数数组 c 的狄利克雷分布中采样。有关此的更多详细信息,请参见 此处。
def sample_dirichlet(c):
"""
Samples Dirichlet random variables which sum to 1 along their last axis.
"""
gamma = np.random.gamma(c)
p = gamma / gamma.sum(axis=-1, keepdims=True)
return p
接下来,我们定义用于替换部分计算的 NUTS 的步长对象。它必须具有一个 step 方法,该方法接收一个名为 point 的字典,其中包含马尔可夫链的当前状态。我们将在适当的位置修改它。
这里有一个额外的复杂性,因为 PyMC 不会以 \(\mathbf{p}=(p_1, p_2 ,..., p_J)\) 的形式跟踪狄利克雷随机变量的状态,并带有约束 \(\sum_j p_j = 1\)。相反,它使用变量的逆棒断裂变换,这更易于与 NUTS 一起使用。此变换消除了所有条目必须总和为 1 且为正的约束。
class ConjugateStep(BlockedStep):
def __init__(self, var, counts: np.ndarray, concentration):
self.vars = [var]
self.counts = counts
self.name = var.name
self.conc_prior = concentration
self.shared = {}
def step(self, point: dict):
# Since our concentration parameter is going to be log-transformed
# in point, we invert that transformation so that we
# can get conc_posterior = conc_prior + counts
conc_posterior = np.exp(point[self.conc_prior.name + "_log__"]) + self.counts
draw = sample_dirichlet(conc_posterior)
# Since our new_p is not in the transformed / unconstrained space,
# we apply the transformation so that our new value
# is consistent with PyMC's internal representation of p
point[self.name] = stick_breaking.forward(draw).eval()
return point, [] # Return empty stats list as second element
此处 point 的用法及其索引变量可能会令人困惑。此表达式是必要的,因为当调用 step 时,它会传递一个字典 point,其中字符串变量名称作为键。
但是,先验参数的名称不会直接存储在 point 的键中,因为 PyMC 存储的是变换后的变量。因此,我们需要使用变换后的名称(因此,_log__ 后缀)查询 point,然后撤消该变换。
为了识别要查询到 point 中的正确变量,我们需要在初始化期间采用一个参数,该参数告诉抽样步骤在哪里找到先验参数。因此,我们将 var 传递到 ConjugateStep 中,以便采样器稍后可以找到变换后变量的名称 (var.transformed.name)。
模拟数据#
我们将在一些模拟数据上尝试采样器。固定 \(\tau=0.5\),我们将抽取 500 个 10 维狄利克雷分布的观测值。
J = 10
N = 500
ncounts = 20
tau_true = 0.5
alpha = tau_true * np.ones([N, J])
p_true = sample_dirichlet(alpha)
counts = np.zeros([N, J])
for i in range(N):
counts[i] = np.random.multinomial(ncounts, p_true[i])
print(counts.shape)
(500, 10)
比较部分共轭抽样与完全 NUTS 抽样#
我们没有 \(\tau\) 后验分布的任何闭式表达式,因此我们将在其上使用 NUTS。在下面的代码单元格中,我们使用 1) 对概率向量进行共轭抽样,并在 \(\tau\) 上使用 NUTS,以及 2) 对所有内容使用 NUTS 来拟合相同的模型。
traces = []
models = []
names = ["Partial conjugate sampling", "Full NUTS"]
for use_conjugate in [True, False]:
with pm.Model() as model:
tau = pm.Exponential("tau", lam=1, initval=1.0)
alpha = pm.Deterministic("alpha", tau * np.ones([N, J]))
p = pm.Dirichlet("p", a=alpha)
if use_conjugate:
# If we use the conjugate sampling, we don't need to define the likelihood
# as it's already taken into account in our custom step method
step = [ConjugateStep(model.rvs_to_values[p], counts, tau)]
else:
x = pm.Multinomial("x", n=ncounts, p=p, observed=counts)
step = []
trace = pm.sample(step=step, chains=1, random_seed=RANDOM_SEED)
traces.append(trace)
# assert all(az.summary(trace)["r_hat"] < 1.1)
models.append(model)
Sequential sampling (1 chains in 1 job)
CompoundStep
>ConjugateStep: [p]
>NUTS: [tau]
Sampling 1 chain for 1_000 tune and 1_000 draw iterations (1_000 + 1_000 draws total) took 26527 seconds.
Only one chain was sampled, this makes it impossible to run some convergence checks
Initializing NUTS using jitter+adapt_diag...
Sequential sampling (1 chains in 1 job)
NUTS: [tau, p]
Sampling 1 chain for 1_000 tune and 1_000 draw iterations (1_000 + 1_000 draws total) took 104 seconds.
Only one chain was sampled, this makes it impossible to run some convergence checks
我们看到部分共轭抽样的运行时间要低得多,但如果样本具有高自相关性或链混合非常缓慢,这可能会产生误导。我们还看到仅 NUTS 跟踪中存在一些发散。
我们想确保两个采样器收敛到相同的估计值。下面的后验直方图和迹图表明,两者基本上都在合理的后验不确定性可信区间内收敛到 \(\tau\)。我们还可以看到,迹图缺少任何明显的自相关性,因为它们与白噪声几乎没有区别。
for name, trace in zip(names, traces):
ax = az.plot_trace(trace, var_names="tau")
ax[0, 0].axvline(0.5, label="True value", color="k")
ax[0, 0].legend()
plt.suptitle(name)


我们希望避免以每秒原始样本数来比较采样器有效性。如果采样器每个样本的工作速度很快,但生成高度相关的样本,则有效样本大小 (ESS) 会减小。由于我们的后验分析严重依赖于有效样本大小,因此我们应该检查后一个量。
此模型包括 \(500\times 10=5000\) 个概率值,用于 500 个狄利克雷随机变量。让我们计算这 5000 个条目中每个条目的有效样本大小,并为每种抽样方法生成一个直方图
summaries_p = []
for trace, model in zip(traces, models):
with model:
summaries_p.append(az.summary(trace, var_names="p"))
[plt.hist(s["ess_bulk"], bins=50, alpha=0.4, label=names[i]) for i, s in enumerate(summaries_p)]
plt.legend(), plt.xlabel("Effective sample size");
arviz - WARNING - Shape validation failed: input_shape: (1, 1000), minimum_shape: (chains=2, draws=4)
arviz - WARNING - Shape validation failed: input_shape: (1, 1000), minimum_shape: (chains=2, draws=4)
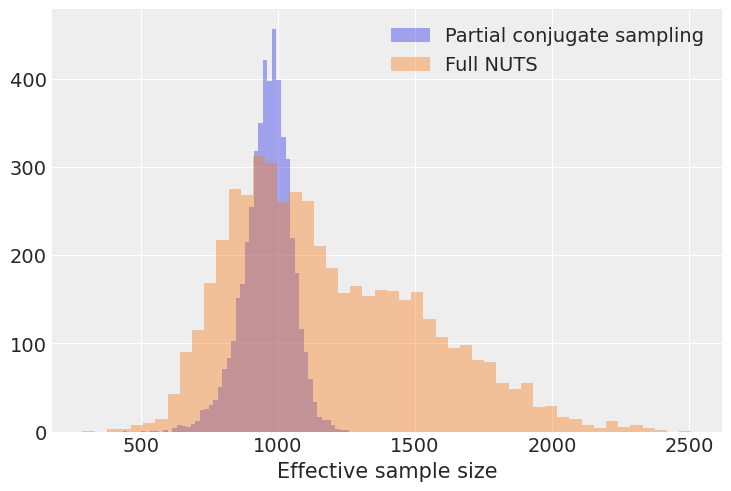
有趣的是,我们看到虽然完全 NUTS 运行的 ESS 直方图的众数较大,但最小 ESS 似乎较低。由于我们的推断通常受到马尔可夫链中表现最差的部分的约束,因此最小 ESS 值得关注。
print("Minimum effective sample sizes across all entries of p:")
print({names[i]: s["ess_bulk"].min() for i, s in enumerate(summaries_p)})
Minimum effective sample sizes across all entries of p:
{'Partial conjugate sampling': 435.0, 'Full NUTS': 288.0}
在这里,我们可以看到共轭抽样方案在最坏的情况下获得了相似数量的有效样本。但是,当我们考虑有效抽样率时,存在巨大的差异。
print("Minimum ESS/second across all entries of p:")
print(
{
names[i]: s["ess_bulk"].min() / traces[i].posterior.sampling_time
for i, s in enumerate(summaries_p)
}
)
Minimum ESS/second across all entries of p:
{'Partial conjugate sampling': 0.016398236944603167, 'Full NUTS': 2.757810535058409}
在最坏情况下的 ESS 率方面,部分共轭抽样方案的速度快了 10 倍以上!
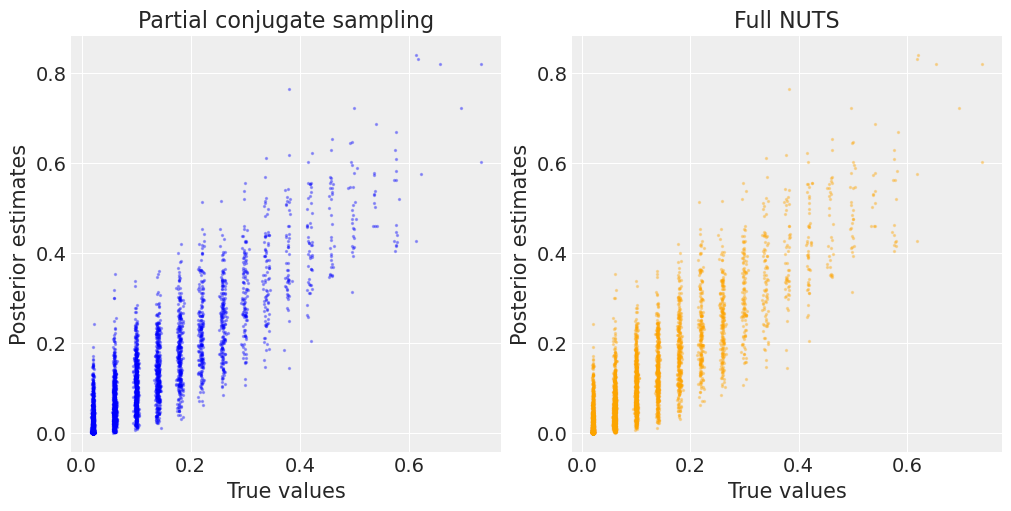
作为最后的检查,我们还想确保两个采样器的概率估计值相同。在下图中,我们可以看到来自部分共轭抽样和完全 NUTS 抽样的估计值与真实值非常密切相关。
fig, axes = plt.subplots(1, 2, figsize=(10, 5))
axes[0].scatter(
summaries_p[0]["mean"],
p_true.ravel(),
s=2,
label="Partial conjugate sampling",
zorder=2,
alpha=0.3,
color="b",
)
axes[0].set_ylabel("Posterior estimates"), axes[0].set_xlabel("True values")
axes[1].scatter(
summaries_p[1]["mean"],
p_true.ravel(),
s=2,
alpha=0.3,
color="orange",
)
axes[1].set_ylabel("Posterior estimates"), axes[1].set_xlabel("True values")
[axes[i].set_title(n) for i, n in enumerate(names)];
许可声明#
本示例库中的所有笔记本均根据 MIT 许可证 提供,该许可证允许修改和再分发以用于任何用途,前提是保留版权和许可证声明。
引用 PyMC 示例#
要引用本笔记本,请使用 Zenodo 为 pymc-examples 存储库提供的 DOI。
重要提示
许多笔记本都改编自其他来源:博客、书籍…… 在这种情况下,您也应该引用原始来源。
另请记住引用您的代码使用的相关库。
这是一个 bibtex 中的引用模板
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
渲染后可能如下所示