


好的和坏的控制#
本笔记本是 Richard McElreath 的 Statistical Rethinking 2023 系列讲座的 PyMC 移植版本的一部分。
# Ignore warnings
import warnings
import arviz as az
import numpy as np
import pandas as pd
import pymc as pm
import statsmodels.formula.api as smf
import utils as utils
import xarray as xr
from matplotlib import pyplot as plt
from matplotlib import style
from scipy import stats as stats
warnings.filterwarnings("ignore")
# Set matplotlib style
STYLE = "statistical-rethinking-2023.mplstyle"
style.use(STYLE)
不惜一切代价避免耍小聪明#
耍小聪明是
不可靠的
不透明的
使用显式因果模型可以让人
使用逻辑推导含义
验证工作和假设
方便同行评审和验证
混杂因素#
回顾#
分叉 \(X \leftarrow Z \rightarrow Y\)
\(X\) 和 \(Y\) 是相关的,除非我们按 \(Z\) 分层
管道 \(X \rightarrow Z \rightarrow Y\)
\(X\) 和 \(Y\) 是相关的,除非我们按 \(Z\) 分层
碰撞 \(X \rightarrow Z \leftarrow Y\)
\(X\) 和 \(Y\) 是不相关的,除非我们按 \(Z\) 分层
后代 \(Z \rightarrow A\)
后代 \(A\) 继承了父代 \(Z\) 的行为
utils.draw_causal_graph(
edge_list=[("U", "X"), ("U", "Y"), ("X", "Y")],
node_props={
"X": {"label": "treatment, X"},
"Y": {"label": "outcome, Y"},
"U": {"label": "confound, U", "style": "dashed"},
"unmeasured": {"style": "dashed"},
},
graph_direction="LR",
)

utils.draw_causal_graph(
edge_list=[("U", "X"), ("U", "Y"), ("X", "Y"), ("R", "X")],
node_props={
"X": {"label": "treatment, X"},
"Y": {"label": "outcome, Y"},
"U": {"label": "confound, U", "style": "dashed"},
"R": {"label": "randomization, R"},
"unmeasured": {"style": "dashed"},
},
edge_props={("U", "X"): {"color": "lightgray"}},
graph_direction="LR",
)

黄金标准是 随机化。然而,随机化通常是不可能的
不可能的
实用主义
伦理考量
未测量的混杂因素
因果思考#
我们想要一个程序 \(do(X)\),它以某种方式干预 \(X\),使其可以“模仿”随机化的效果。
这样的程序将转换混杂图
没有随机化#
utils.draw_causal_graph(
[
("U", "X"),
("U", "Y"),
("X", "Y"),
],
graph_direction="LR",
)

以这样一种方式,所有进入 X 的非因果箭头都已被移除
通过 \(do(X)\) 诱导的“随机化”#
utils.draw_causal_graph(
[
("U", "Y"),
("X", "Y"),
],
edge_props={("X", "Y"): {"label": "do(X) "}},
graph_direction="LR",
)

事实证明,我们可以分析图结构来确定是否存在这样的程序
示例:简单混杂#
utils.draw_causal_graph(
edge_list=[("U", "Y"), ("U", "X"), ("X", "Y")],
node_props={
"U": {"color": "red"},
},
edge_props={("U", "X"): {"color": "red"}, ("U", "Y"): {"color": "red"}},
graph_direction="LR",
)

在分叉示例中,我们已经表明,通过按混杂因素分层,我们通过对 U 进行条件化来“关闭”分叉,从而消除 U 对 X 的任何因果效应,从而使我们能够隔离治疗对 Y 的影响。
此过程是所谓的 Do 演算的一部分。运算符 do(X) 倾向于表示对 X 进行干预(即将其设置为独立于混杂因素的特定值)
即,为我们提供 X 干预的程序等同于 Y 的分布,按治疗 X 和混杂因素 U 分层,并在混杂因素的分布上取平均值。
请注意,当我们对每个 X 使用线性回归估计器时,我们隐含地对我们的治疗和混杂因素进行边缘化和平均(例如,在模型形式 \(Y \sim \mathcal{N}(\alpha + \beta_X X + \beta_Z Z, \sigma^2)\) 中
通常,模型中将 X 与 Y 相关联的不是估计的系数
它是当我们更改 X 时 Y 的分布,在由控制/混杂变量(即 U)定义的分布上取平均值
Do 演算#
应用于 DAG,提供了一组用于识别 \(p(Y | do(X))\) 的规则
在选择函数或分布之前,告知什么是可能的
证明图形分析的合理性
如果 Do 演算声称推理是可能的,则不需要进一步的特殊假设来进行推理
通常,额外的假设可以使推理更强大
后门准则#
使用肉眼以图形方式应用 Do 演算的快捷方式。 用于查找要条件化的变量的最小充分调整集的一般规则。
识别连接治疗 X 和结果 Y 的所有路径,包括进入和退出 X 的路径(关联可以是直接/非直接的,因果关系是直接的)
那些进入 X 的路径中的任何一条都是后门(非因果)路径
找到变量的调整集,一旦条件化,它将“关闭/阻止”在其中识别出的所有后门路径
后门准则示例#
utils.draw_causal_graph(
[("U", "Z"), ("Z", "X"), ("U", "Y"), ("X", "Y")],
node_props={"Z": {"color": "red"}, "U": {"style": "dashed"}},
edge_props={
("U", "Z"): {"color": "red"},
("Z", "X"): {"color": "red"},
("U", "Y"): {"color": "red"},
},
graph_direction="LR",
)

后门路径以红色突出显示。
如果我们能够测量 \(U\),我们可以只按 \(U\) 分层;但是,它是未观察到的。
但是,尽管无法测量 \(U\),我们仍然可以通过对 \(Z\) 进行条件化来阻止后门路径。
这是可行的,因为 \(Z\) “知道”我们需要了解的关于 \(X\)、\(Y\) 之间关联的所有信息,这些信息是由于未测量的混杂因素 \(U\) 造成的。
按 \(Z\) 分层后的结果图#
\(U \rightarrow Z \rightarrow X\) 管道现在已被打破,将 \(X\) 与混杂因素 \(U\) 解除关联
注意:这不会消除混杂因素对 \(Y\) 的影响
utils.draw_causal_graph(
[("U", "Z"), ("Z", "X"), ("U", "Y"), ("X", "Y")],
node_props={"Z": {"color": "red"}, "U": {"style": "dashed"}},
edge_props={
("U", "Z"): {"color": "red"},
("Z", "X"): {"color": "none"},
("U", "Y"): {"color": "red"},
},
graph_direction="LR",
)

通过模拟验证#
在这里,我们模拟了一种情况,其中 Y 是由 X 和未测量的混杂因素 U 引起的,U 也影响 Z 和 X。(我们也可以用数学方法证明,但模拟也相当有说服力——至少对我来说是这样)
np.random.seed(123)
n_samples = 200
alpha = 0
beta_XY = 0
beta_UY = -1
beta_UZ = -1
beta_ZX = 1
U = stats.bernoulli.rvs(p=0.5, size=n_samples)
Z = stats.norm.rvs(loc=beta_UZ * U)
X = stats.norm.rvs(loc=beta_ZX * Z)
Y = stats.norm.rvs(loc=alpha + beta_XY * X + beta_UY * U)
未分层(混杂)模型#
拟合未分层模型,忽略 Z(和 U)#
with pm.Model() as unstratified_model:
# Priors
alpha_ = pm.Normal("alpha", 0, 1)
beta_XY_ = pm.Normal("beta_XY", 0, 1)
sigma_ = pm.Exponential("sigma", 1)
# Likelihood
mu_ = alpha_ + beta_XY_ * X
Y_ = pm.Normal("Y", mu=mu_, sigma=sigma_, observed=Y)
unstratified_model_inference = pm.sample()
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [alpha, beta_XY, sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
az.summary(unstratified_model_inference)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | -0.381 | 0.084 | -0.535 | -0.219 | 0.001 | 0.001 | 3503.0 | 3034.0 | 1.0 |
| beta_XY | 0.148 | 0.055 | 0.043 | 0.244 | 0.001 | 0.001 | 3763.0 | 3040.0 | 1.0 |
| sigma | 1.114 | 0.058 | 1.015 | 1.227 | 0.001 | 0.001 | 6091.0 | 3259.0 | 1.0 |
按 Z 分层(非混杂)#
# Fit the stratified Model
with pm.Model() as stratified_model:
# Priors
alpha_ = pm.Normal("alpha", 0, 1)
beta_XY_ = pm.Normal("beta_XY", 0, 1)
beta_Z_ = pm.Normal("beta_Z", 0, 1)
sigma_ = pm.Exponential("sigma", 1)
# Likelihood (includes Z)
mu_ = alpha_ + beta_XY_ * X + beta_Z_ * Z
Y_ = pm.Normal("Y", mu=mu_, sigma=sigma_, observed=Y)
stratified_model_inference = pm.sample()
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [alpha, beta_XY, beta_Z, sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 1 seconds.
az.summary(stratified_model_inference)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha | -0.286 | 0.091 | -0.450 | -0.109 | 0.002 | 0.001 | 3570.0 | 2743.0 | 1.0 |
| beta_XY | -0.026 | 0.078 | -0.181 | 0.114 | 0.001 | 0.001 | 2989.0 | 2631.0 | 1.0 |
| beta_Z | 0.318 | 0.106 | 0.118 | 0.515 | 0.002 | 0.001 | 2650.0 | 2469.0 | 1.0 |
| sigma | 1.091 | 0.055 | 0.983 | 1.190 | 0.001 | 0.001 | 3813.0 | 2660.0 | 1.0 |
注意:模型系数 beta_Z 在 \(Z\) 对 \(Y\) 的因果效应方面没有任何意义。为了确定 \(Z\) 对 \(Y\) 的因果效应,您需要一个不同的估计器。一般来说,调整集中的变量是不可解释的。这与“表 2 谬误”有关
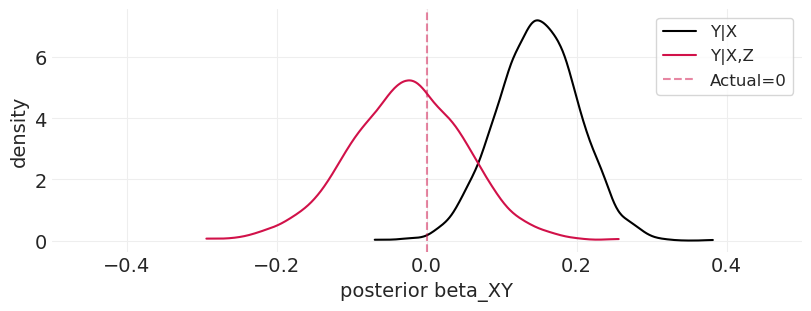
比较分层模型和未分层模型#
_, ax = plt.subplots(figsize=(8, 3))
az.plot_dist(unstratified_model_inference.posterior.beta_XY, color="k", label="Y|X", ax=ax)
az.plot_dist(stratified_model_inference.posterior.beta_XY, color="C0", label="Y|X,Z", ax=ax)
plt.axvline(beta_XY, color="C0", linestyle="--", alpha=0.5, label=f"Actual={beta_XY}")
plt.xlim([-0.5, 0.5])
plt.xlabel("posterior beta_XY")
plt.ylabel("density")
plt.legend();
更复杂的示例#
utils.draw_causal_graph(
edge_list=[
("A", "Z"),
("A", "X"),
("Z", "X"),
("B", "Z"),
("B", "Y"),
("Z", "Y"),
("X", "Y"),
("C", "X"),
("C", "Y"),
],
graph_direction="LR",
)

连接 X 到 Y 的所有路径#
utils.draw_causal_graph(
edge_list=[
("A", "Z"),
("A", "X"),
("Z", "X"),
("B", "Z"),
("B", "Y"),
("Z", "Y"),
("X", "Y"),
("C", "X"),
("C", "Y"),
],
edge_props={
("X", "Y"): {"color": "blue", "label": "Direct Causal Path", "fontcolor": "blue"},
},
graph_direction="LR",
)

\(X \rightarrow Y\)#
直接的因果路径,保持开放
utils.draw_causal_graph(
edge_list=[
("A", "Z"),
("A", "X"),
("Z", "X"),
("B", "Z"),
("B", "Y"),
("Z", "Y"),
("X", "Y"),
("C", "X"),
("C", "Y"),
],
edge_props={
("C", "X"): {"color": "red", "label": "XCY", "fontcolor": "red"},
("C", "Y"): {"color": "red"},
},
graph_direction="LR",
)

\(X \leftarrow C \rightarrow Y\)#
后门非因果路径
通过按 \(C\) 分层来阻止
utils.draw_causal_graph(
edge_list=[
("A", "Z"),
("A", "X"),
("Z", "X"),
("B", "Z"),
("B", "Y"),
("Z", "Y"),
("X", "Y"),
("C", "X"),
("C", "Y"),
],
edge_props={
("Z", "X"): {"color": "red", "label": "XZY", "fontcolor": "red"},
("Z", "Y"): {"color": "red"},
},
graph_direction="LR",
)

\(X \leftarrow Z \rightarrow Y\)#
后门非因果路径
通过按 \(Z\) 分层来阻止
utils.draw_causal_graph(
edge_list=[
("A", "Z"),
("A", "X"),
("Z", "X"),
("B", "Z"),
("B", "Y"),
("Z", "Y"),
("X", "Y"),
("C", "X"),
("C", "Y"),
],
edge_props={
("A", "X"): {"color": "red", "label": "XAZBY", "fontcolor": "red"},
("A", "Z"): {"color": "red"},
("B", "Z"): {"color": "red"},
("B", "Y"): {"color": "red"},
},
graph_direction="LR",
)

\(X \leftarrow A \rightarrow Z \leftarrow B \rightarrow Y\)#
后门非因果路径
通过按 \(A\) 或 \(B\) 分层来阻止;按 \(Z\) 分层会打开路径,因为它是一个碰撞变量
我们已经按 \(Z\) 分层,用于 \(X,Z,Y\) 后门路径
utils.draw_causal_graph(
edge_list=[
("A", "Z"),
("A", "X"),
("Z", "X"),
("B", "Z"),
("B", "Y"),
("Z", "Y"),
("X", "Y"),
("C", "X"),
("C", "Y"),
],
edge_props={
("A", "X"): {"color": "red", "label": "XAZY", "fontcolor": "red"},
("A", "Z"): {"color": "red"},
("Z", "Y"): {"color": "red"},
("Z", "Y"): {"color": "red"},
},
graph_direction="LR",
)

\(X \leftarrow A \rightarrow Z \rightarrow Y\)#
后门非因果路径
通过按 \(A\) 分层来阻止;按 \(Z\) 分层会打开路径,因为它是一个碰撞变量
我们已经按 \(Z\) 分层,用于 \(X \leftarrow Z \rightarrow Y\) 后门路径
utils.draw_causal_graph(
edge_list=[
("A", "Z"),
("A", "X"),
("Z", "X"),
("B", "Z"),
("B", "Y"),
("Z", "Y"),
("X", "Y"),
("C", "X"),
("C", "Y"),
],
edge_props={
("Z", "X"): {"color": "red", "label": "XZBY", "fontcolor": "red"},
("B", "Z"): {"color": "red"},
("B", "Y"): {"color": "red"},
},
graph_direction="LR",
)

\(X \leftarrow Z \leftarrow B \rightarrow Y\)#
后门非因果路径
通过按 \(B\) 分层来阻止;按 \(Z\) 分层会打开路径,因为它是一个碰撞变量
我们已经按 \(Z\) 分层,用于 \(X \leftarrow Z \rightarrow Y\) 后门路径
结果最小调整集:Z、C、(A 或 B)#
选择 B 而不是 A 结果在统计上更有效率,尽管在因果关系上与选择 A 没有区别
具有未观察到的混杂因素的示例#
utils.draw_causal_graph(
edge_list=[("G", "P"), ("P", "C"), ("G", "C"), ("u", "P"), ("u", "C")],
node_props={
"G": {"color": "blue"},
"C": {"color": "blue"},
"P": {"color": "red", "label": "collider, P"},
"u": {"style": "dashed"},
"unobserved": {"style": "dashed"},
},
edge_props={("G", "C"): {"color": "blue"}},
graph_direction="LR",
)

\(P\) 是 \(G\) 和 \(C\) 之间的调解变量
\(P\) 也是 \(G, u, C\) 之间的碰撞变量
如果我们想估计 \(G \rightarrow C\) 的直接效应,我们需要按 \(P\) 分层——关闭管道
但是,这将打开通往未观察到的混杂因素的碰撞变量路径。
无法准确估计 G 对 C 的直接因果效应
可以估计总因果效应
好的和坏的控制#
用于选择控制变量的常见不正确启发式方法:#
YOLO 方法 – 电子表格中的任何内容
忽略高度共线性的变量
错误,没有对此的支持
共线性可以通过许多不同的因果过程产生,这些过程可以被准确建模
添加治疗前变量是安全的
错误,治疗前变量,就像治疗后变量一样,可能导致混杂因素。
好的和坏的控制示例#
坏的控制#
utils.draw_causal_graph(
edge_list=[("u", "Z"), ("v", "Z"), ("u", "X"), ("X", "Y"), ("v", "Y")],
node_props={
"u": {"style": "dashed"},
"v": {"style": "dashed"},
"X": {"color": "red"},
"Y": {"color": "red"},
"unobserved": {"style": "dashed"},
},
edge_props={("X", "Y"): {"color": "red"}},
graph_direction="TD",
)

\(Z\) 是未观察到的变量 \(u\) 和 \(v\) 的碰撞变量,它们独立地影响 \(X\) 和 \(Y\)
列出路径#
\(X \rightarrow Y\)
因果,保持开放
\(X \leftarrow u \rightarrow Z \leftarrow v \rightarrow Y\)
后门,由于碰撞变量而关闭
\(Z\) 是一个坏的控制:按 \(Z\) 分层会打开后门路径
\(Z\) 可能是一个治疗前变量——并非总是适合按治疗前变量分层;绘制您的因果假设
坏的调解变量#
utils.draw_causal_graph(
edge_list=[
("X", "Z"),
("Z", "Y"),
("u", "Z"),
("u", "Y"),
],
node_props={
"X": {"color": "red"},
"Y": {"color": "red"},
"u": {"style": "dashed"},
"unobserved": {"style": "dashed"},
},
edge_props={("X", "Z"): {"color": "red"}, ("Z", "Y"): {"color": "red"}},
graph_direction="LR",
)

列出路径#
\(X \rightarrow Z \rightarrow Y\)
因果,保持开放
\(X \rightarrow Z \leftarrow u \rightarrow Y\)
后门,但仅当按 Z 分层时
没有后门路径,因此无需按 Z 分层
可以测量 \(X\) 对 \(Y\) 的总效应,但不能测量直接效应,因为存在调解变量 \(Z\)
这里没有后门路径,因此无需控制任何混杂因素。事实上,按 Z(坏的调解变量)分层会引入估计偏差,因为它引入了 u 的因果效应,否则将被阻止。
Z 通常是一个治疗后变量,例如,在下面,“幸福感”受到“赢得彩票”治疗的影响
通过模拟验证坏的调解变量:#
utils.draw_causal_graph(
edge_list=[
("X", "Z"),
("Z", "Y"),
("u", "Z"),
("u", "Y"),
],
node_props={
"X": {"color": "red"},
"Y": {"color": "red"},
"u": {"style": "dashed"},
"unobserved": {"style": "dashed"},
},
edge_props={
("X", "Z"): {"color": "red", "label": "1"},
("Z", "Y"): {"color": "red", "label": "1"},
("u", "Z"): {"label": "1"},
("u", "Y"): {"label": "1"},
},
graph_direction="LR",
)

def simulate_bad_mediator(beta_XZ, beta_ZY, n_samples=100):
# independent variables
u = stats.norm.rvs(size=n_samples)
X = stats.norm.rvs(size=n_samples)
# causal effect of X on Z
mu_Z = X * beta_XZ + u
Z = stats.norm.rvs(size=n_samples, loc=mu_Z)
# Causal effect of Z on Y (including confound)
mu_Y = Z * beta_ZY + u
Y = stats.norm.rvs(size=n_samples, loc=mu_Y)
# Put data into format for statsmodels
data = pd.DataFrame(np.vstack([Y, X, Z, u]).T, columns=["Y", "X", "Z", "u"])
unstratified_model = smf.ols("Y ~ X", data=data).fit()
stratified_model = smf.ols("Y ~ X + Z", data=data).fit()
return unstratified_model.params.X, stratified_model.params.X
def run_bad_mediator_simulation(
beta_XZ=1, beta_ZY=1, n_simulations=500, n_samples_per_simualtion=100
):
beta_X = beta_XZ * beta_ZY
simulations = np.array(
[
simulate_bad_mediator(
beta_XZ=beta_XZ, beta_ZY=beta_ZY, n_samples=n_samples_per_simualtion
)
for _ in range(n_simulations)
]
)
_, ax = plt.subplots(figsize=(8, 4))
az.plot_dist(simulations[:, 0], label="Y ~ X\ncorrect", color="black", ax=ax)
az.plot_dist(simulations[:, 1], label="Y ~ X + Z\nwrong", color="C0", ax=ax)
plt.axvline(beta_X, color="k", linestyle="--", label=f"actual={beta_X}")
plt.legend(loc="upper left")
plt.xlabel("posterior mean")
plt.ylabel("density");
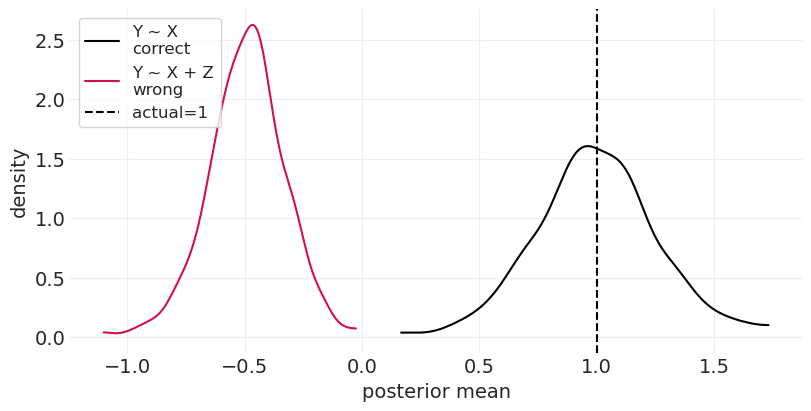
运行模拟,\(\beta_{XZ} = \beta_{ZY} = 1\)#
run_bad_mediator_simulation(beta_XZ=1, beta_ZY=1)
utils.draw_causal_graph(
edge_list=[
("X", "Z"),
("Z", "Y"),
("u", "Z"),
("u", "Y"),
],
node_props={
"X": {"color": "red"},
"Y": {"color": "red"},
"u": {"style": "dashed"},
"unobserved": {"style": "dashed"},
},
edge_props={
("X", "Z"): {"color": "red", "label": "1"},
("Z", "Y"): {"color": "red", "label": "0"},
("u", "Z"): {"label": "1"},
("u", "Y"): {"label": "1"},
},
graph_direction="LR",
)

通过将 \(\beta_{ZY}\) 更改为 0 来关闭因果效应#
run_bad_mediator_simulation(beta_XZ=1, beta_ZY=0)
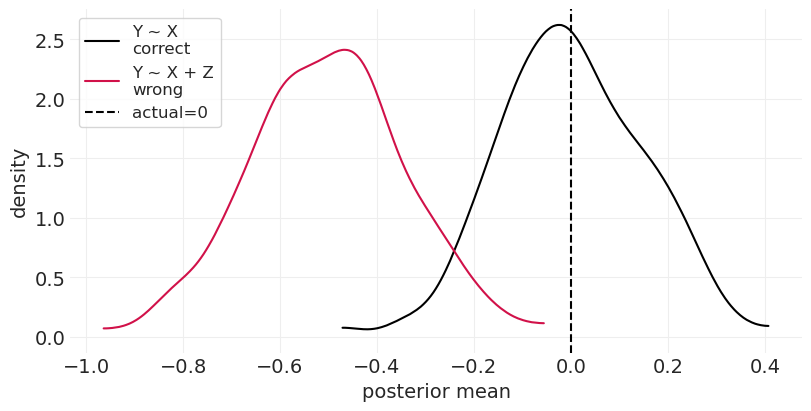
尽管没有因果效应,但您最终得出了 X 对 Y 的负面效应的结论
碰撞变量和后代#
一般来说,避免碰撞变量!
添加目标变量的后代几乎总是一个糟糕的主意,因为您正在根据结果选择组。这被称为 病例对照偏差(根据结果选择)
utils.draw_causal_graph(
edge_list=[("X", "Y"), ("X", "Z"), ("Y", "Z")],
node_props={"X": {"color": "red"}, "Y": {"color": "red"}},
edge_props={("X", "Y"): {"color": "red"}},
)

碰撞变量并不总是那么明显
utils.draw_causal_graph(
edge_list=[
("X", "Y"),
("X", "Z"),
("u", "Y"),
("u", "Z"),
],
node_props={
"X": {"color": "red"},
"Y": {"color": "red"},
"u": {"style": "dashed"},
"unobserved": {"style": "dashed"},
},
edge_props={("X", "Y"): {"color": "red"}},
)

碰撞变量由未观察到的变量 u 形成
坏的后代:根据结果选择(病例对照偏差)#
在受结果影响的变量上分层是一种非常糟糕的做法。
减少了 \(Y\) 中可能由 \(X\) 解释的变异
utils.draw_causal_graph(
edge_list=[
("X", "Y"),
("Y", "Z"),
],
node_props={
"X": {"color": "red", "label": "education, X"},
"Y": {"color": "red", "label": "occupation, Y"},
"Z": {"label": "income, Z"},
},
edge_props={("X", "Y"): {"color": "red"}},
graph_direction="LR",
)

通过模拟验证:#
utils.draw_causal_graph(
edge_list=[
("X", "Y"),
("Y", "Z"),
],
node_props={
"X": {"color": "red"},
"Y": {"color": "red"},
},
edge_props={("X", "Y"): {"color": "red", "label": "1"}, ("Y", "Z"): {"label": "1"}},
graph_direction="LR",
)

def simulate_case_control_bias(beta_XY=1, beta_YZ=1, n_samples=100):
# independent variables
X = stats.norm.rvs(size=n_samples)
# Causal effect of Z on Y (including confound)
mu_Y = X * beta_XY
Y = stats.norm.rvs(size=n_samples, loc=mu_Y)
# causal effect of X on Z
mu_Z = Y * beta_YZ
Z = stats.norm.rvs(size=n_samples, loc=mu_Z)
# Put data into format for statsmodels
data = pd.DataFrame(np.vstack([Y, X, Z]).T, columns=["Y", "X", "Z"])
unstratified_model = smf.ols("Y ~ X", data=data).fit()
stratified_model = smf.ols("Y ~ X + Z", data=data).fit()
return unstratified_model.params.X, stratified_model.params.X
def run_case_control_simulation(
beta_XY=1, beta_YZ=1, n_simulations=500, n_samples_per_simualtion=100
):
beta_X = beta_XY
simulations = np.array(
[
simulate_case_control_bias(
beta_XY=beta_XY, beta_YZ=beta_YZ, n_samples=n_samples_per_simualtion
)
for _ in range(n_simulations)
]
)
_, ax = plt.subplots(figsize=(8, 4))
az.plot_dist(simulations[:, 0], label="Y ~ X\ncorrect", color="black", ax=ax)
az.plot_dist(simulations[:, 1], label="Y ~ X + Z\nwrong", color="C0", ax=ax)
plt.axvline(beta_X, color="k", linestyle="--", label=f"actual={beta_X}")
plt.legend(loc="upper left")
plt.xlabel("posterior mean")
plt.ylabel("density");
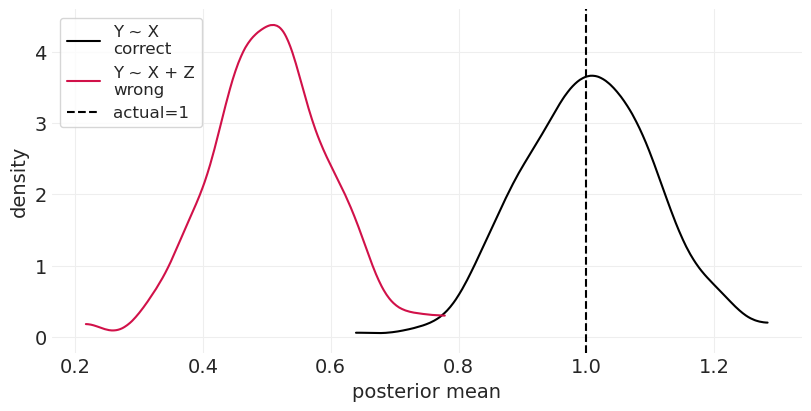
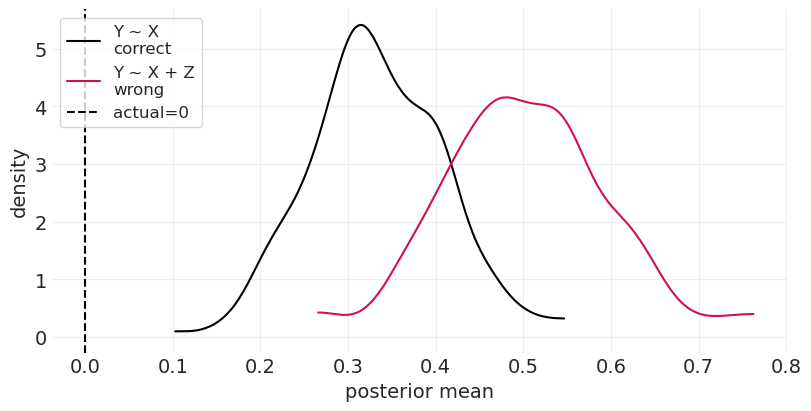
后代解释了 \(X\) 对 \(Y\) 的部分因果效应#
估计的因果效应已经减少,因为后代减少了 \(Y\) 中可以由 \(X\) 解释的变异
run_case_control_simulation(beta_XY=1, beta_YZ=1)
通过设置 \(\beta_{YZ}=0\) 来消除后代效应#
后代在这里不再有任何影响,因此我们应该为分层模型和未分层模型恢复相同的(正确的)推理
run_case_control_simulation(beta_XY=1, beta_YZ=0)
坏的祖先(又名精度寄生虫)#
现在 \(Z\) 是 \(X\) 的父代
没有后门路径,\(X\) 直接连接到 \(Y\)
当按 \(Z\) 分层时,您正在解释 \(X\) 中的变异,从而减少 \(X\) 和 \(Y\) 之间可以以其他方式解释的因果信息的量。
不会使您的估计产生偏差, 但它降低了精度,因此估计将具有更多不确定性
utils.draw_causal_graph(
edge_list=[
("X", "Y"),
("Z", "X"),
],
node_props={
"X": {"color": "red"},
"Y": {"color": "red"},
},
edge_props={("X", "Y"): {"color": "red", "label": "1"}, ("Z", "X"): {"label": "1"}},
graph_direction="LR",
)

通过模拟验证#
utils.draw_causal_graph(
edge_list=[
("X", "Y"),
("Z", "X"),
],
node_props={
"X": {"color": "red"},
"Y": {"color": "red"},
},
edge_props={
("X", "Y"): {"color": "red", "label": "1"},
("Y", "Z"): {"color": "red", "label": "1"},
},
graph_direction="LR",
)

np.random.seed(123)
def simulate_bad_ancestor(beta_ZX=1, beta_XY=1, unobserved_variance=None, n_samples=100):
Z = stats.norm.rvs(size=n_samples)
mu_X = Z * beta_ZX
if unobserved_variance is not None:
u = stats.norm.rvs(size=n_samples) * unobserved_variance
mu_X += u
X = stats.norm.rvs(size=n_samples, loc=mu_X)
mu_Y = X * beta_XY
if unobserved_variance is not None:
mu_Y += u
Y = stats.norm.rvs(size=n_samples, loc=mu_Y)
data = pd.DataFrame(np.vstack([X, Y, Z]).T, columns=["X", "Y", "Z"])
non_stratified_model = smf.ols("Y ~ X", data=data).fit()
stratified_model = smf.ols("Y ~ X + Z", data=data).fit()
return non_stratified_model.params.X, stratified_model.params.X
def run_bad_ancestor_simulation(
beta_ZX=1, beta_XY=1, n_simulations=500, unobserved_variance=None, n_samples_per_simualtion=100
):
beta_X = beta_XY
simulations = np.array(
[
simulate_bad_ancestor(
beta_ZX=beta_ZX,
beta_XY=beta_XY,
unobserved_variance=unobserved_variance,
n_samples=n_samples_per_simualtion,
)
for _ in range(n_simulations)
]
)
_, ax = plt.subplots(figsize=(8, 4))
az.plot_dist(simulations[:, 0], label="Y ~ X\ncorrect", color="black", ax=ax)
az.plot_dist(simulations[:, 1], label="Y ~ X + Z\nwrong", color="C0", ax=ax)
plt.axvline(beta_X, color="k", linestyle="--", label=f"actual={beta_X}")
plt.legend(loc="upper left")
plt.xlabel("posterior mean")
plt.ylabel("density");
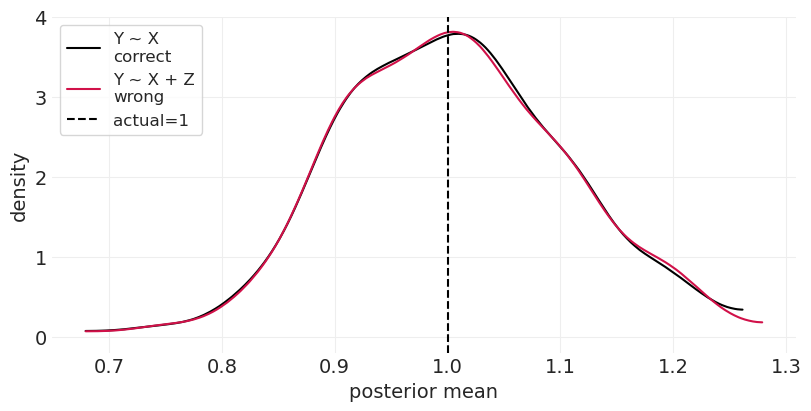
run_bad_ancestor_simulation()
按 Z 分层不会增加偏差(它以正确的值为中心),但它确实会增加估计器中的方差。这种精度降低与 Z 和 X 之间因果关系的大小成正比
增加 Z 和 X 之间的关系会进一步降低精度#
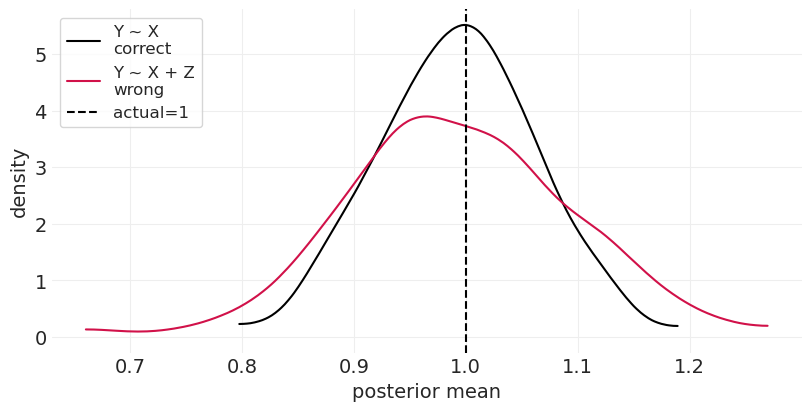
run_bad_ancestor_simulation(beta_ZX=3)
偏差放大#
当存在其他混杂因素(尤其是未观察到的分叉)时,在祖先上分层。 这就像偏差寄生虫场景,但它也增加了偏差。
utils.draw_causal_graph(
edge_list=[("X", "Y"), ("Z", "X"), ("u", "X"), ("u", "Y")],
node_props={
"X": {"color": "red"},
"Y": {"color": "red"},
"u": {"style": "dashed"},
"unobserved": {"style": "dashed"},
},
edge_props={("X", "Y"): {"color": "red"}, ("Y", "Z"): {"color": "red"}},
graph_direction="LR",
)

通过模拟验证#
utils.draw_causal_graph(
edge_list=[("X", "Y"), ("Z", "X"), ("u", "X"), ("u", "Y")],
node_props={
"X": {"color": "red"},
"Y": {"color": "red"},
"u": {"style": "dashed"},
"unobserved": {"style": "dashed"},
},
edge_props={
("X", "Y"): {"color": "red", "label": "0"},
("Z", "X"): {"color": "red", "label": "1"},
},
graph_direction="LR",
)

运行模拟,没有实际的因果效应,\(\beta_{XY} = 0\)#
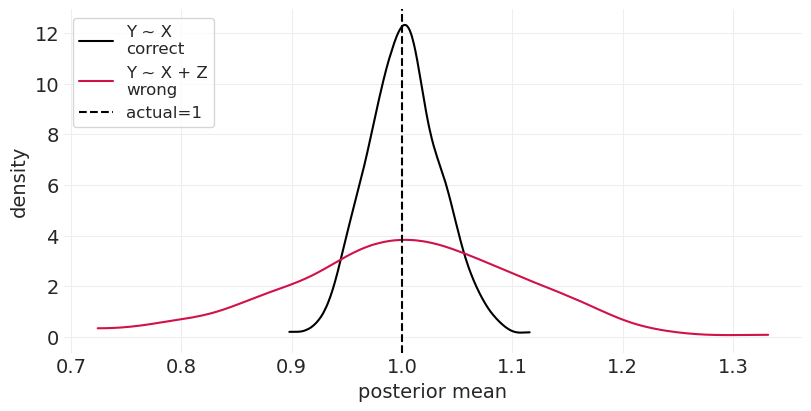
run_bad_ancestor_simulation(beta_ZX=1, beta_XY=0, unobserved_variance=1)
在上面我们看到,即使在最好的情况下,两个估计器都是有偏差的——我们无法观察到,因此也无法控制混杂因素 \(u\)。但是当按祖先分层时,情况会更糟。
粗略的解释
为了使 \(X\) 和 \(Y\) 相关联,它们的起因需要相关联
通过按 \(Z\) 分层,我们消除了 \(X\) 中由 \(Z\) 引起的变异量
这种 \(X\) 变异的减少使得混杂因素 \(u\) 相对而言更重要
偏差放大的离散示例#
def simulate_discrete_bias_amplifications(beta_ZX=1, beta_XY=1, n_samples=1000):
Z = stats.bernoulli.rvs(p=0.5, size=n_samples)
u = stats.norm.rvs(size=n_samples)
mu_X = beta_ZX * Z + u
X = stats.norm.rvs(loc=mu_X, size=n_samples)
mu_Y = X * beta_XY + u
Y = stats.norm.rvs(loc=mu_Y, size=n_samples)
data = pd.DataFrame(np.vstack([u, Z, X, Y]).T, columns=["u", "Z", "X", "Y"])
models = {}
models["unstratified"] = smf.ols("Y ~ X", data=data).fit()
models["z=0"] = smf.ols("Y ~ X", data=data[data.Z == 0]).fit()
models["z=1"] = smf.ols("Y ~ X", data=data[data.Z == 1]).fit()
return models, data
beta_ZX = 7
beta_ZY = 0
models, data = simulate_discrete_bias_amplifications(beta_ZX=beta_ZX, beta_XY=beta_XY)
fig, axs = plt.subplots(figsize=(5, 5))
def plot_linear_model(model, color, label):
params = model.params
xs = np.linspace(data.X.min(), data.X.max(), 10)
ys = params.Intercept + params.X * xs
utils.plot_line(xs, ys, color=color, label=label)
for z in [0, 1]:
color = f"C{z}"
utils.plot_scatter(data.X[data.Z == z], data.Y[data.Z == z], color=color)
model = models[f"z={z}"]
plot_linear_model(model, color=color, label=f"Z={z}")
model = models["unstratified"]
plot_linear_model(model, color="k", label=f"total sample")
plt.xlim([-5, 12])
plt.ylim([-5, 5])
plt.legend();
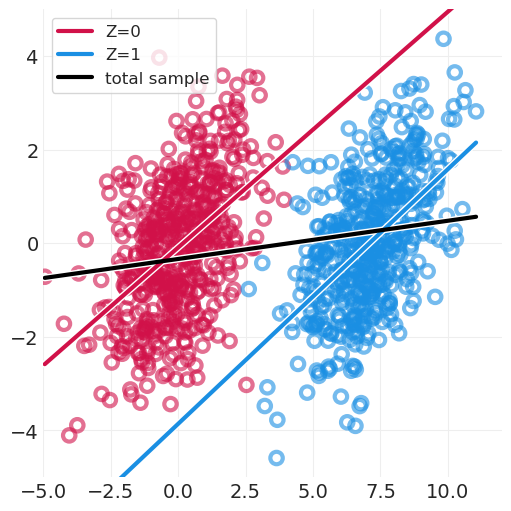
当忽略 Z(祖先)时,估计仍然有些偏差(即,黑色斜率不是平坦的,因为它应该对于 \(\beta_{XY}=0\) 是平坦的)
但它远没有按 Z 分层时的各个斜率(蓝色/红色)那么糟糕。
回顾:好的和坏的控制#
混杂因素:使我们的因果估计“混淆”或“困惑”的估计器设计或样本
控制:添加到分析中的变量,以便因果估计成为可能
添加控制通常比省略它们更糟糕
使假设明确,并使用后门准则来验证这些假设
您必须进行科学建模才能进行科学分析
奖励:表 2 谬误#
并非所有系数都代表因果效应,特别是调整集中的系数
那些是因果效应的往往是部分效应,而不是总因果效应。
表 2 积极鼓励误解
如多次提到的:需要不同的估计器来解决不同的因果效应。
示例:吸烟、年龄、HIV 和中风#
utils.draw_causal_graph(
edge_list=[
("X", "Y"),
("S", "Y"),
("S", "X"),
("A", "Y"),
("A", "X"),
("A", "S"),
],
node_props={
"X": {"label": "X, HIV", "color": "red"},
"Y": {"label": "Y, Stroke", "color": "red"},
"S": {"label": "S, Smoking"},
"A": {"label": "A, Age"},
},
edge_props={("X", "Y"): {"color": "red"}},
graph_direction="LR",
)

通过后门准则识别路径#
\(X \rightarrow Y\) (前门)
\(X \leftarrow S \rightarrow Y\) (后门,分叉)
\(X \leftarrow A \rightarrow Y\) (后门,分叉)
\(X \leftarrow A \rightarrow S \rightarrow Y\) (后门,分叉和管道)
调整集是 \(\{S, A\}\)
条件统计模型#
“从各种变量的角度”看待模型#
从 X 的角度#
对 \(A\) 和 \(S\) 进行条件化实际上消除了进入 \(X\) 的箭头,\(\beta_X\) 给了我们 \(X\) 对 \(Y\) 的直接效应
我们通过按 \(S\) 和 \(A\) 分层,通过系数 \(\beta_S, \beta_A\) 消除了所有后门路径
utils.draw_causal_graph(
edge_list=[
("X", "Y"),
("S", "Y"),
("S", "X"),
("A", "Y"),
("A", "X"),
("A", "S"),
],
node_props={"X": {"color": "red"}, "Y": {"color": "red"}},
edge_props={
("X", "Y"): {"color": "red"},
("A", "X"): {"color": "none"},
("S", "X"): {"color": "none"},
},
graph_direction="LR",
)

从 S 的角度#
utils.draw_causal_graph(
edge_list=[
("X", "Y"),
("S", "Y"),
("S", "X"),
("A", "Y"),
("A", "X"),
("A", "S"),
],
node_props={"Y": {"color": "red"}, "S": {"color": "red"}},
edge_props={
("X", "Y"): {"color": "red"},
("S", "X"): {"color": "red"},
("S", "Y"): {"color": "red"},
},
graph_direction="LR",
)

使用完整模型的调整图#
utils.draw_causal_graph(
edge_list=[
("X", "Y"),
("S", "Y"),
("S", "X"),
("A", "Y"),
("A", "X"),
("A", "S"),
],
node_props={"Y": {"color": "red"}, "S": {"color": "red"}},
edge_props={
("S", "X"): {"color": "none"},
("A", "S"): {"color": "none"},
("S", "Y"): {"color": "red"},
},
graph_direction="LR",
)

在无条件模型中,\(S\) 对 \(Y\) 的影响受到 \(A\) 的混淆,因为它是 \(S\) 和 \(Y\)(以及 \(X\))的共同原因
对 \(A\) 和 \(X\) 进行条件化(通过上面的相同统计模型),\(\beta_{S}\) 给出了 \(S\) 对 \(Y\)/的直接效应
由于我们在线性回归中阻止了沿 \(X\) 的路径,因此我们不再获得总效应。
从 A 的角度#
在无条件模型中,\(A\) 对 \(Y\) 的总因果效应流经所有路径
utils.draw_causal_graph(
edge_list=[
("X", "Y"),
("S", "Y"),
("S", "X"),
("A", "Y"),
("A", "X"),
("A", "S"),
],
node_props={"Y": {"color": "red"}, "A": {"color": "red"}},
edge_props={
("X", "Y"): {"color": "red"},
("A", "X"): {"color": "red"},
("A", "Y"): {"color": "red"},
("A", "S"): {"color": "red"},
("S", "X"): {"color": "red"},
("S", "Y"): {"color": "red"},
},
graph_direction="LR",
)

对 \(S\) 和 \(X\) 进行条件化(通过上面的相同统计模型),\(\beta_{A}\) 给出了 \(A\) 对 \(Y\)/的直接效应
由于我们在线性回归中阻止了沿 \(X\) 的路径,因此我们不再获得总效应。
utils.draw_causal_graph(
edge_list=[
("X", "Y"),
("S", "Y"),
("S", "X"),
("A", "Y"),
("A", "X"),
("A", "S"),
],
node_props={"Y": {"color": "red"}, "A": {"color": "red"}},
edge_props={
("A", "X"): {"color": "none"},
("A", "S"): {"color": "none"},
("A", "Y"): {"color": "red"},
},
graph_direction="LR",
)

如果我们考虑变量上未观察到的混杂因素,这将变得更加棘手!
总结:表 2 谬误#
并非所有系数都具有相同的解释
不同的估计量需要不同的模型
不要将系数呈现为它们是相等的(即在表 2 中)
……或者,根本不要呈现系数,而是推出预测。
为每个提供明确的解释
许可声明#
本示例画廊中的所有笔记本均根据 MIT 许可证 提供,该许可证允许修改和再分发以用于任何用途,前提是保留版权和许可证声明。
引用 PyMC 示例#
要引用此笔记本,请使用 Zenodo 为 pymc-examples 存储库提供的 DOI。
重要
许多笔记本都是从其他来源改编而来的:博客、书籍…… 在这种情况下,您也应该引用原始来源。
另请记住引用您的代码使用的相关库。
这是一个 bibtex 中的引用模板
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
渲染后可能看起来像这样