


Horoscopes#
此笔记本是 PyMC 对 Richard McElreath 的 Statistical Rethinking 2023 系列讲座的移植。
视频 - 第 20 讲 - Horoscopes# 第 20 讲 - Horoscopes
# Ignore warnings
import warnings
import arviz as az
import numpy as np
import pandas as pd
import pymc as pm
import statsmodels.formula.api as smf
import utils as utils
import xarray as xr
from matplotlib import pyplot as plt
from matplotlib import style
from scipy import stats as stats
warnings.filterwarnings("ignore")
# Set matplotlib style
STYLE = "statistical-rethinking-2023.mplstyle"
style.use(STYLE)
Horoscopes#
本次讲座主要概述了一系列高级启发式方法和工作流程,以提高科学研究的质量。因此,讲座中没有太多要介绍的实现细节。我不会逐个复制幻灯片的内容,但我将在下面介绍一些重点(主要是为了我自己)。
统计学就像算命#
模糊的事实导致模糊的建议
解读茶叶就像遵循统计分析的常用流程图
科学投入很少,因此科学解释也很少
这通常是算命和统计学的特点和缺陷
通过从模糊的输入(例如生日)提供模糊的解释(例如星座预测),他们可以“解释”任意数量的结果
就像模糊的星座运势可以“解释”任意数量的未来事件一样
夸大的重要性
没有人愿意在他们的茶叶中听到邪恶的预兆,就像没有人愿意听到关于 NULL 或负面的统计结果
通常有动机使用统计数据来找到积极的结果
将主观的科学责任推卸给客观的统计程序通常更容易
科学工作流程的三大支柱#
1. 计划
目标设定
估计量
理论构建
假设
4 种理论构建类型,特异性递增
启发式(DAGs)
使我们能够从建立因果结构中推导出很多东西
结构性
通过建立特定形式的因果关系,超越 DAGs
动力学模型
通常在空间/时间网格上工作
倾向于将大量微观状态坍缩为宏观解释
基于 Agent
侧重于个体微观状态
合理的抽样
我们使用哪些数据,其结构是什么
通过模拟验证
合理的分析
哪些 golems?
我们可以从模拟中恢复估计量吗?
文档
它是如何发生的?
帮助他人和您未来的自己
脚本是自我文档化的
注释很重要
不要耍聪明,要明确
避免巧妙的单行代码
我发现 Python PEP 在这里很有用
分享
开源代码和数据格式
专有软件不利于共享,并且是糟糕的科学伦理
这里的讽刺之处在于,MATLAB 在学术界,尤其是工程学领域非常常见 🙄
当您(或其他人)无法再打开专有数据格式时,它们可能会适得其反
预注册不是万能药
对糟糕的分析方法(例如,因果沙拉)预先分配期望并不能修复糟糕的方法
2. 工作
研究工程
将研究更像软件工程一样对待
使软件可靠和可重复的标准化、经过实战检验的程序
版本控制 (git)
测试
单元测试
集成测试
逐步构建测试,在继续下一步之前验证工作流程的每个部分
文档
审查
👀,👀 至少让另一个人审查您的分析代码和文档,并提供反馈
通常会指出错误、优化或文档中的缺点
查看好的例子
例如,McElreath 的咨询项目之一
3. 报告
共享材料
通过遵循基于代码的工作流程,共享几乎为您完成
证明先验的合理性
证明方法的合理性,以及处理审稿人
常见谬误:“良好的科学设计不需要复杂的统计学”
有效的因果建模需要复杂性
不要试图说服审稿人 3 接受你的方法,写信给编辑
将对话从统计建模转移到因果建模
描述数据
结构
缺失值:如有任何插补,请证明其合理性
描述结果
旨在报告对比和边际效应
在区间上使用密度
避免将系数解释为因果效应
做出决策
这通常是目标(尤其是在工业界)
拥抱不确定性
不确定性不是承认弱点
贝叶斯决策理论
使用后验来模拟各种政策干预
可用于提供这些干预措施导致的成本/收益的后验
科学改革#
许多衡量良好科学的标准适得其反
例如,最少被重复的论文继续具有更高的引用次数
元观点:在出版物中,可以使用因果建模和对撞偏差来解释此结果
科学出版物中的对撞偏差#
对撞偏差的因果模型#
utils.draw_causal_graph(
edge_list=[("newsworhiness, N", "published, P"), ("trustworthiness, T", "published, P")],
)

模拟来自对撞因果模型的数据#
np.random.seed(123)
n_samples = 200
# N and T are independent
N = stats.norm.rvs(size=n_samples)
T = stats.norm.rvs(size=n_samples)
# Award criterion; either are large enough to threshold
A = np.where(N + T > 2, 1, 0)
for awarded in [0, 1]:
color = "gray" if not awarded else "C0"
N_A = N[A == awarded]
T_A = T[A == awarded]
utils.plot_scatter(N_A, T_A, color=color)
fit_data = pd.DataFrame({"N": N_A, "T": T_A})
cc = np.corrcoef(fit_data.T, fit_data.N)[0][1]
awarded_model = smf.ols("T ~ N", data=fit_data).fit()
utils.plot_line(
N_A, awarded_model.predict(), color="C0", label=f"Post-selection\nTrend\ncorrelation={cc:0.2}"
)
plt.xlabel("Newsworthiness")
plt.ylabel("Trustworthiness")
plt.axis("square")
plt.legend();
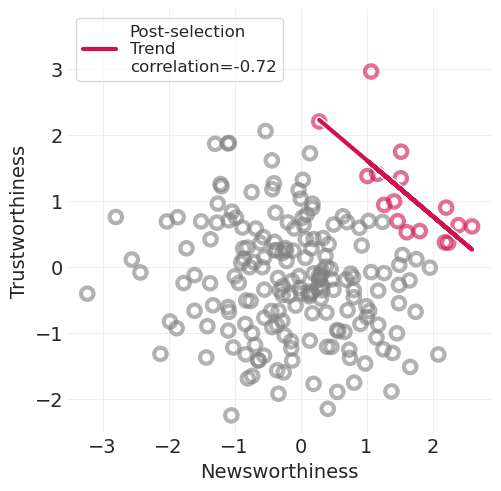
通过根据结合了新闻价值(即“性感的论文”,被大量引用)或可信度(即可重复的无聊论文)的阈值来选择已发表的论文,我们最终得到往往不太可重复的高引用论文。
研究的星座运势#
许多关于科学的“坏”事(例如影响因子)曾经是善意的改革
一些潜在的修复方法可用
在透明沟通的因果模型之前,不进行统计
避免因果沙拉
在您的项目和假设范围内证明您的代码/分析有效
尽可能多地分享
有时数据不可共享
但是您可以创建部分、匿名化或合成数据集
注意研究质量的代理指标(例如,引用次数、影响因子)
许可声明#
本示例库中的所有笔记本均根据 MIT 许可证 提供,该许可证允许修改和再分发用于任何用途,前提是保留版权和许可声明。
引用 PyMC 示例#
要引用此笔记本,请使用 Zenodo 为 pymc-examples 存储库提供的 DOI。
重要提示
许多笔记本改编自其他来源:博客、书籍……在这种情况下,您也应该引用原始来源。
另请记住引用您的代码使用的相关库。
这是一个 bibtex 中的引用模板
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
一旦渲染,它可能看起来像