


审查数据模型#
from copy import copy
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pymc as pm
import seaborn as sns
from numpy.random import default_rng
%config InlineBackend.figure_format = 'retina'
rng = default_rng(1234)
az.style.use("arviz-darkgrid")
关于贝叶斯生存分析的示例笔记本 触及了审查数据的点。审查是缺失数据问题的一种形式,其中大于某个阈值的观测值被裁剪到该阈值,或者小于某个阈值的观测值被裁剪到该阈值,或者两者都进行裁剪。这些分别称为右审查、左审查和区间审查。在本示例笔记本中,我们考虑区间审查。
审查数据出现在许多建模问题中。两个常见的例子是
生存分析: 当研究某种医疗 treatment 对生存时间的影响时,不可能延长研究直到所有受试者都死亡。在研究结束时,为许多患者收集的唯一数据是他们在接受 treatment 后的一段时间 \(T\) 内仍然活着:实际上,他们的真实生存时间大于 \(T\)。
传感器饱和: 传感器可能具有有限的范围,上限和下限将只是传感器可以报告的最高和最低值。例如,许多水银温度计仅报告非常狭窄的温度范围。
本示例笔记本介绍了在 PyMC3 中处理审查数据的两种不同方法
一个插补审查模型,它将审查数据表示为参数,并为所有审查值生成合理的可能值。由于这种插补,该模型能够生成可能的一组人为编造的值,这些值本来会被审查。每个审查元素都引入一个随机变量。
一个未插补审查模型,其中审查数据被积分出来,并且仅通过对数似然来考虑。这种方法更充分地处理大量审查数据,并且收敛速度更快。
为了建立基线,我们将与未审查数据的未审查模型进行比较。
# Produce normally distributed samples
size = 500
true_mu = 13.0
true_sigma = 5.0
samples = rng.normal(true_mu, true_sigma, size)
# Set censoring limits
low = 3.0
high = 16.0
def censor(x, low, high):
x = copy(x)
x[x <= low] = low
x[x >= high] = high
return x
# Censor samples
censored = censor(samples, low, high)
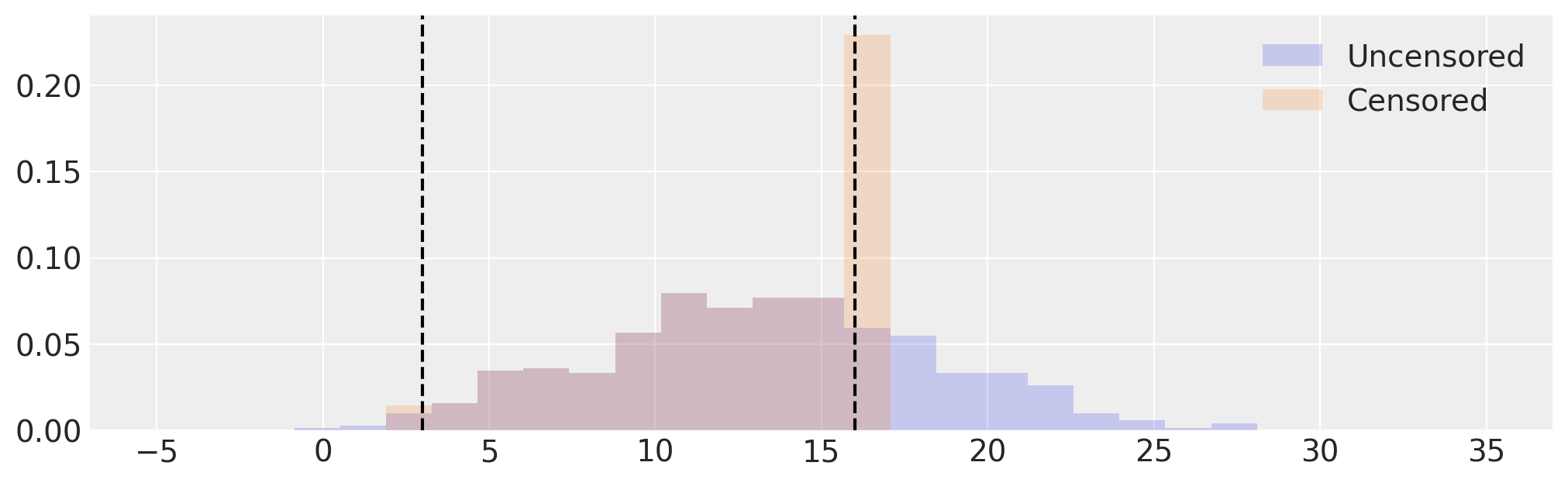
# Visualize uncensored and censored data
_, ax = plt.subplots(figsize=(10, 3))
edges = np.linspace(-5, 35, 30)
ax.hist(samples, bins=edges, density=True, histtype="stepfilled", alpha=0.2, label="Uncensored")
ax.hist(censored, bins=edges, density=True, histtype="stepfilled", alpha=0.2, label="Censored")
[ax.axvline(x=x, c="k", ls="--") for x in [low, high]]
ax.legend();
未审查模型#
def uncensored_model(data):
with pm.Model() as model:
mu = pm.Normal("mu", mu=((high - low) / 2) + low, sigma=(high - low))
sigma = pm.HalfNormal("sigma", sigma=(high - low) / 2.0)
observed = pm.Normal("observed", mu=mu, sigma=sigma, observed=data)
return model
我们应该预测,在未审查数据上运行未审查模型,我们将获得均值和方差的合理估计。
uncensored_model_1 = uncensored_model(samples)
with uncensored_model_1:
idata = pm.sample()
az.plot_posterior(idata, ref_val=[true_mu, true_sigma], round_to=3);
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [mu, sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 4 seconds.
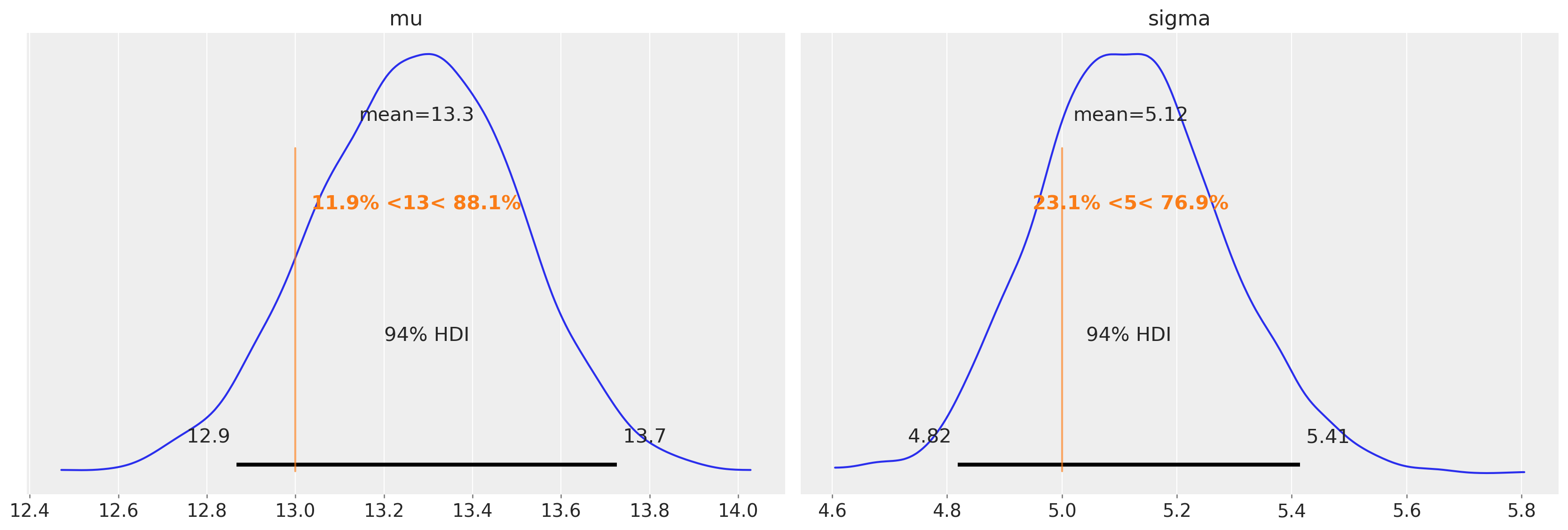
这正是我们发现的。
然而,问题在于,在审查数据上下文中,我们无法访问真实值。如果我们在审查数据上使用相同的未审查模型,我们预计我们的参数估计将会有偏差。如果我们计算均值和标准差的点估计,那么我们可以看到我们可能低估了此特定数据集和审查边界的均值和标准差。
uncensored_model_2 = uncensored_model(censored)
with uncensored_model_2:
idata = pm.sample()
az.plot_posterior(idata, ref_val=[true_mu, true_sigma], round_to=3);
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [mu, sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 4 seconds.
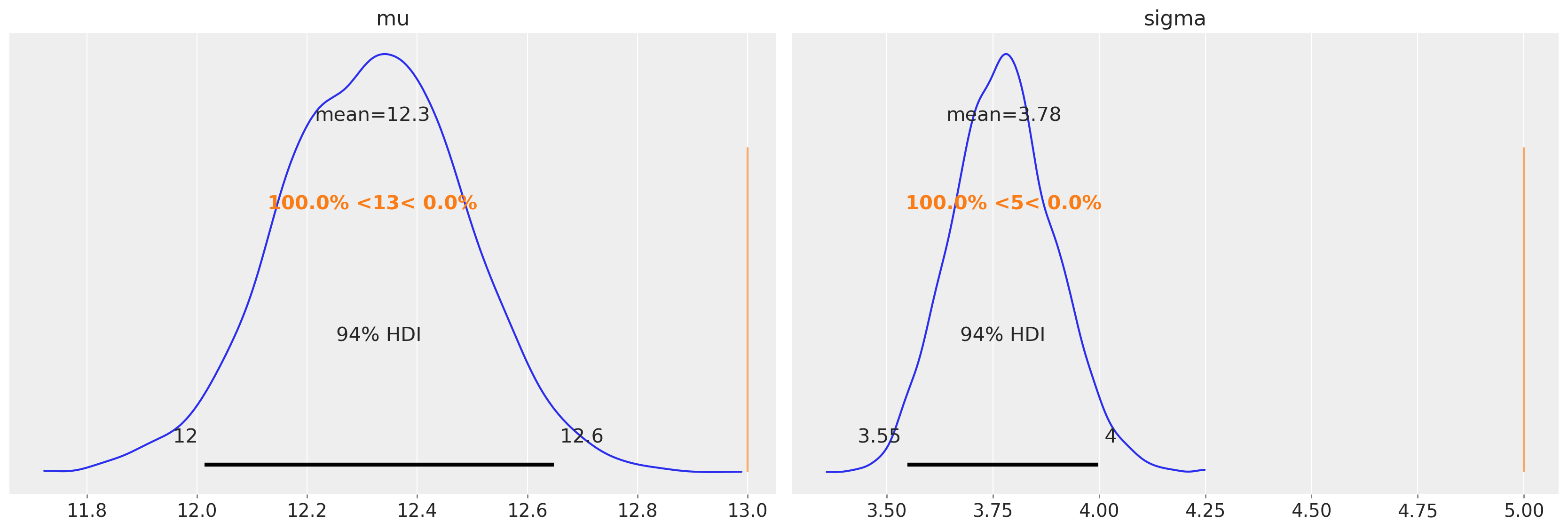
上面的图证实了这一点。
审查数据模型#
以下模型显示了处理审查数据的 2 种方法。首先,我们需要做一些数据预处理来计算左审查或右审查的观测数量。我们还需要提取我们观察到的非审查数据。
模型 1 - 审查数据的插补审查模型#
在此模型中,我们从与未审查数据相同的分布中插补审查值。从后验分布中抽样生成可能的未审查数据集。
n_right_censored = sum(censored >= high)
n_left_censored = sum(censored <= low)
n_observed = len(censored) - n_right_censored - n_left_censored
uncensored = censored[(censored > low) & (censored < high)]
assert len(uncensored) == n_observed
with pm.Model() as imputed_censored_model:
mu = pm.Normal("mu", mu=((high - low) / 2) + low, sigma=(high - low))
sigma = pm.HalfNormal("sigma", sigma=(high - low) / 2.0)
right_censored = pm.Normal(
"right_censored",
mu,
sigma,
transform=pm.distributions.transforms.Interval(high, None),
shape=int(n_right_censored),
initval=np.full(n_right_censored, high + 1),
)
left_censored = pm.Normal(
"left_censored",
mu,
sigma,
transform=pm.distributions.transforms.Interval(None, low),
shape=int(n_left_censored),
initval=np.full(n_left_censored, low - 1),
)
observed = pm.Normal("observed", mu=mu, sigma=sigma, observed=uncensored, shape=int(n_observed))
idata = pm.sample()
az.plot_posterior(idata, var_names=["mu", "sigma"], ref_val=[true_mu, true_sigma], round_to=3);
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [mu, sigma, right_censored, left_censored]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 17 seconds.
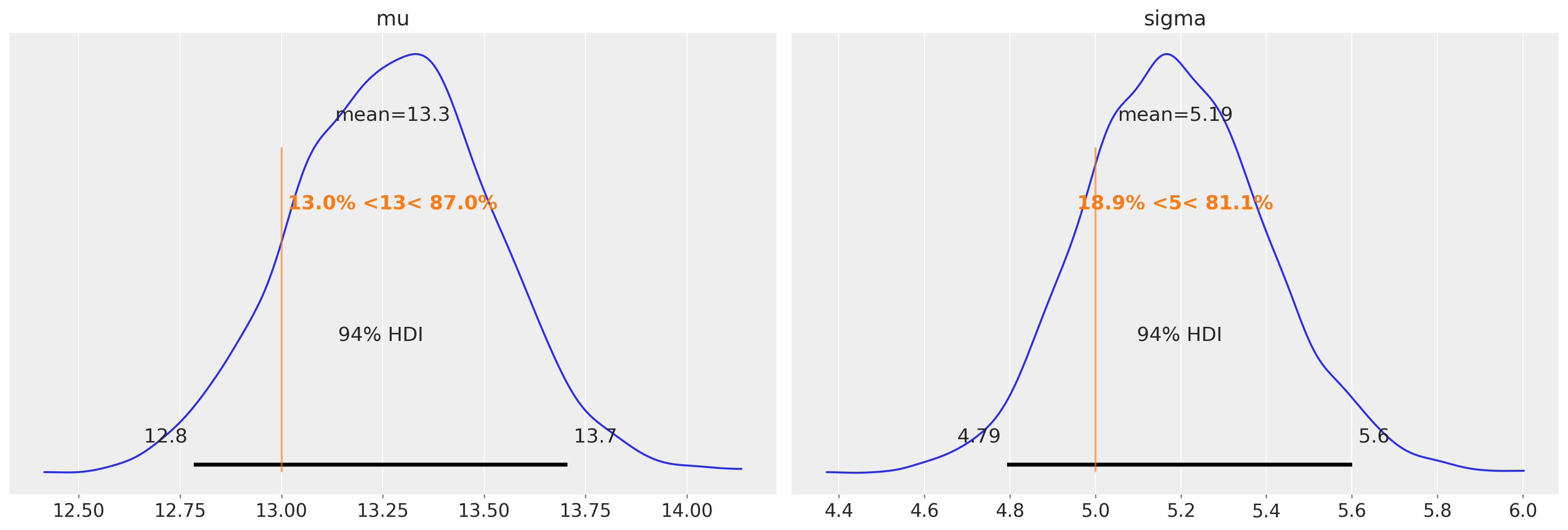
我们可以看到,均值和方差估计中的偏差(存在于未审查模型中)已在很大程度上消除。
模型 2 - 审查数据的未插补审查模型#
在这里,我们可以使用 pm.Censored。
with pm.Model() as unimputed_censored_model:
mu = pm.Normal("mu", mu=0.0, sigma=(high - low) / 2.0)
sigma = pm.HalfNormal("sigma", sigma=(high - low) / 2.0)
y_latent = pm.Normal.dist(mu=mu, sigma=sigma)
obs = pm.Censored("obs", y_latent, lower=low, upper=high, observed=censored)
抽样
with unimputed_censored_model:
idata = pm.sample()
az.plot_posterior(idata, var_names=["mu", "sigma"], ref_val=[true_mu, true_sigma], round_to=3);
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [mu, sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 5 seconds.
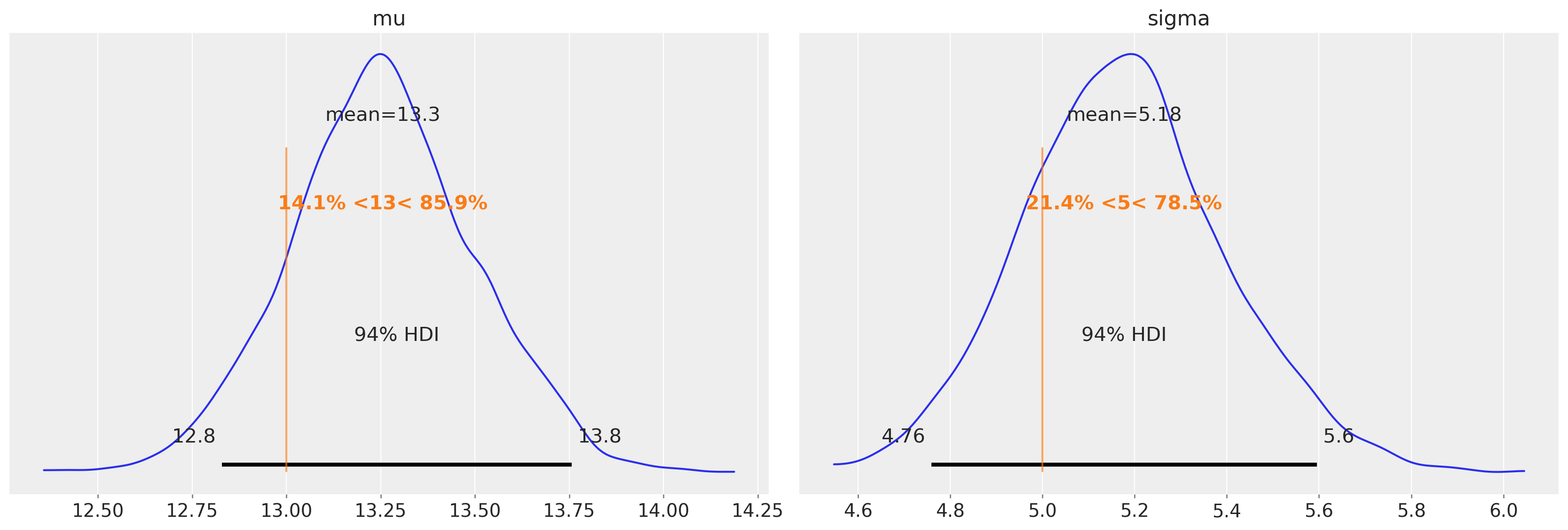
同样,均值和方差估计中的偏差(存在于未审查模型中)已在很大程度上消除。
讨论#
正如我们所看到的,两种审查模型似乎都能像未审查模型一样捕获底层分布的均值和方差!此外,插补审查模型能够生成审查值的数据集(从 left_censored 和 right_censored 的后验分布中抽样以生成它们),而未插补审查模型在处理更多审查数据时扩展性更好,并且收敛速度更快。
水印#
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor,aeppl
Last updated: Tue Jan 17 2023
Python implementation: CPython
Python version : 3.11.0
IPython version : 8.8.0
pytensor: 2.9.1
aeppl : not installed
seaborn : 0.12.2
pymc : 5.0.1+42.g99dd7158
arviz : 0.14.0
matplotlib: 3.6.2
sys : 3.11.0 | packaged by conda-forge | (main, Oct 25 2022, 06:24:40) [GCC 10.4.0]
numpy : 1.24.1
Watermark: 2.3.1
许可证声明#
本示例库中的所有笔记本均根据 MIT 许可证 提供,该许可证允许修改和再分发以用于任何用途,前提是保留版权和许可证声明。
引用 PyMC 示例#
要引用此笔记本,请使用 Zenodo 为 pymc-examples 存储库提供的 DOI。
重要提示
许多笔记本改编自其他来源:博客、书籍…… 在这种情况下,您也应该引用原始来源。
另请记住引用您的代码使用的相关库。
这是一个 bibtex 中的引用模板
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
一旦渲染,它可能看起来像