


贝叶斯向量自回归模型#
import os
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
import statsmodels.api as sm
from pymc.sampling_jax import sample_blackjax_nuts
/Users/nathanielforde/mambaforge/envs/myjlabenv/lib/python3.11/site-packages/pymc/sampling/jax.py:39: UserWarning: This module is experimental.
warnings.warn("This module is experimental.")
RANDOM_SEED = 8927
rng = np.random.default_rng(RANDOM_SEED)
az.style.use("arviz-darkgrid")
%config InlineBackend.figure_format = 'retina'
V(ector)A(uto)R(egression) 模型#
在本笔记本中,我们将概述贝叶斯向量自回归模型的应用。我们将借鉴 PYMC Labs 博客文章 中的工作(参见 Vieira [无日期])。这将是一个分为三个部分系列。在第一部分中,我们想展示如何在 PYMC 中拟合贝叶斯 VAR 模型。在第二部分中,我们将展示如何从拟合模型中提取额外的见解,通过脉冲响应分析,并从拟合的 VAR 模型中进行预测。在第三部分也是最后一部分中,我们将更详细地展示使用贝叶斯 VAR 模型的分层先验的好处。具体来说,我们将概述如何以及为什么实际上存在一系列精心制定的行业标准先验,这些先验适用于贝叶斯 VAR 建模。
在这篇文章中,我们将 (i) 在虚假数据上演示简单 VAR 模型的基本模式,并展示模型如何恢复真实数据生成参数,以及 (ii) 我们将展示一个应用于宏观经济数据的示例,并将结果与使用 statsmodels MLE 拟合在相同数据上实现的结果进行比较,以及 (iii) 展示一个估计多个国家的层次贝叶斯 VAR 模型的示例。
通用自回归模型#
简单自回归模型的思想是捕捉时间序列的过去观测值如何预测当前观测值的方式。因此,按照传统方式,如果我们将此建模为线性现象,我们将得到简单的自回归模型,其中当前值由过去值的加权线性组合和误差项预测。
对于预测当前观测值所需的滞后阶数。
VAR 模型是这种框架的一种泛化,因为它保留了线性组合方法,但允许我们一次对多个时间序列进行建模。因此,具体而言,这意味着 \(\mathbf{y}_{t}\) 是一个向量,其中
其中 As 是系数矩阵,用于与每个单独时间序列的过去值组合。例如,考虑一个经济学示例,其中我们旨在对每个变量对自身和他人的关系和相互影响进行建模。
这种结构是使用矩阵符号的紧凑表示。当我们拟合 VAR 模型时,我们试图估计的是确定最适合我们时间序列数据的线性组合性质的 A 矩阵。这种时间序列模型可以具有自回归或移动平均表示,并且细节对于 VAR 模型拟合的一些含义很重要。
我们将在本系列的下一个笔记本中看到,VAR 的移动平均表示如何使其自身适用于将模型中的协方差结构解释为表示组件时间序列之间的一种脉冲响应关系。
具有两个滞后项的具体规范#
矩阵符号对于建议模型的广泛模式很方便,但查看简单情况下的代数很有用。考虑将爱尔兰的 GDP 和消费描述为
通过这种方式,我们可以看到,如果我们能够估计 \(\beta\) 项,我们就得到了每个变量对另一个变量的双向影响的估计。这是建模的一个有用特征。在接下来的内容中,我应该强调我不是经济学家,我的目标只是展示这些模型的功能,而不是给你关于决定爱尔兰 GDP 数字的经济关系的决定性意见。
创建一些虚假数据#
def simulate_var(
intercepts, coefs_yy, coefs_xy, coefs_xx, coefs_yx, noises=(1, 1), *, warmup=100, steps=200
):
draws_y = np.zeros(warmup + steps)
draws_x = np.zeros(warmup + steps)
draws_y[:2] = intercepts[0]
draws_x[:2] = intercepts[1]
for step in range(2, warmup + steps):
draws_y[step] = (
intercepts[0]
+ coefs_yy[0] * draws_y[step - 1]
+ coefs_yy[1] * draws_y[step - 2]
+ coefs_xy[0] * draws_x[step - 1]
+ coefs_xy[1] * draws_x[step - 2]
+ rng.normal(0, noises[0])
)
draws_x[step] = (
intercepts[1]
+ coefs_xx[0] * draws_x[step - 1]
+ coefs_xx[1] * draws_x[step - 2]
+ coefs_yx[0] * draws_y[step - 1]
+ coefs_yx[1] * draws_y[step - 2]
+ rng.normal(0, noises[1])
)
return draws_y[warmup:], draws_x[warmup:]
首先,我们生成一些具有已知参数的虚假数据。
var_y, var_x = simulate_var(
intercepts=(18, 8),
coefs_yy=(-0.8, 0),
coefs_xy=(0.9, 0),
coefs_xx=(1.3, -0.7),
coefs_yx=(-0.1, 0.3),
)
df = pd.DataFrame({"x": var_x, "y": var_y})
df.head()
| x | y | |
|---|---|---|
| 0 | 34.606613 | 30.117581 |
| 1 | 34.773803 | 23.996700 |
| 2 | 35.455237 | 29.738941 |
| 3 | 33.886706 | 27.193417 |
| 4 | 31.837465 | 26.704728 |
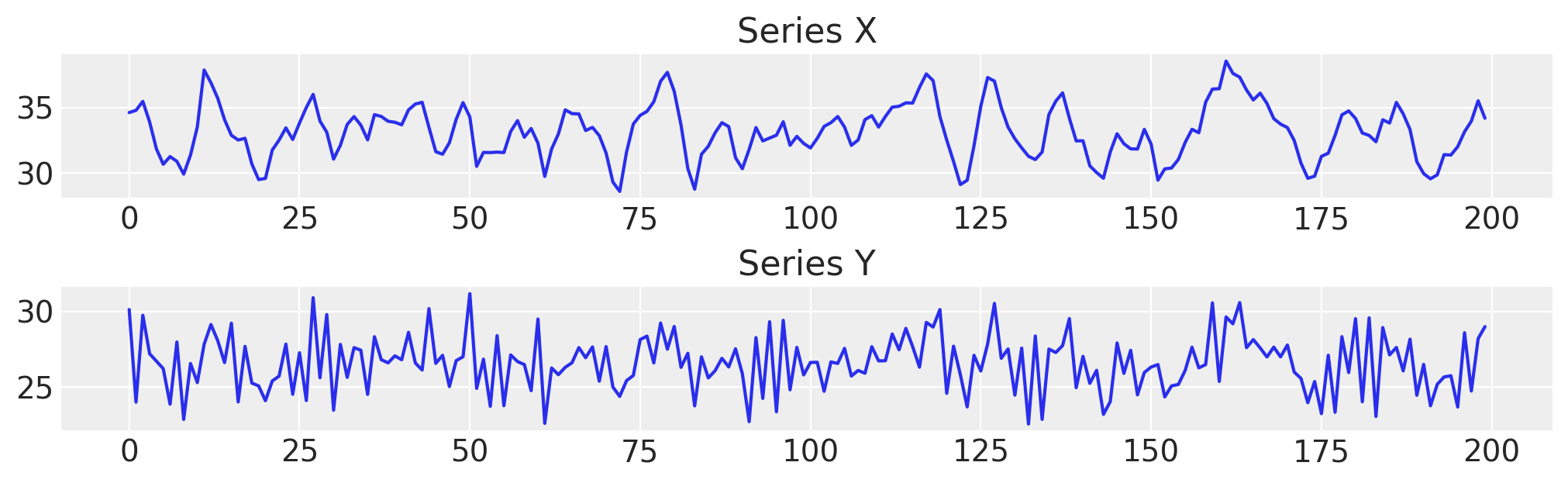
fig, axs = plt.subplots(2, 1, figsize=(10, 3))
axs[0].plot(df["x"], label="x")
axs[0].set_title("Series X")
axs[1].plot(df["y"], label="y")
axs[1].set_title("Series Y");
处理多个滞后和不同维度#
当对多个时间序列进行建模并考虑可能需要在模型中包含的任意数量的滞后时,我们需要将一些模型定义抽象到辅助函数中。一个例子将使这一点更清楚一些。
### Define a helper function that will construct our autoregressive step for the marginal contribution of each lagged
### term in each of the respective time series equations
def calc_ar_step(lag_coefs, n_eqs, n_lags, df):
ars = []
for j in range(n_eqs):
ar = pm.math.sum(
[
pm.math.sum(lag_coefs[j, i] * df.values[n_lags - (i + 1) : -(i + 1)], axis=-1)
for i in range(n_lags)
],
axis=0,
)
ars.append(ar)
beta = pm.math.stack(ars, axis=-1)
return beta
### Make the model in such a way that it can handle different specifications of the likelihood term
### and can be run for simple prior predictive checks. This latter functionality is important for debugging of
### shape handling issues. Building a VAR model involves quite a few moving parts and it is handy to
### inspect the shape implied in the prior predictive checks.
def make_model(n_lags, n_eqs, df, priors, mv_norm=True, prior_checks=True):
coords = {
"lags": np.arange(n_lags) + 1,
"equations": df.columns.tolist(),
"cross_vars": df.columns.tolist(),
"time": [x for x in df.index[n_lags:]],
}
with pm.Model(coords=coords) as model:
lag_coefs = pm.Normal(
"lag_coefs",
mu=priors["lag_coefs"]["mu"],
sigma=priors["lag_coefs"]["sigma"],
dims=["equations", "lags", "cross_vars"],
)
alpha = pm.Normal(
"alpha", mu=priors["alpha"]["mu"], sigma=priors["alpha"]["sigma"], dims=("equations",)
)
data_obs = pm.Data("data_obs", df.values[n_lags:], dims=["time", "equations"], mutable=True)
betaX = calc_ar_step(lag_coefs, n_eqs, n_lags, df)
betaX = pm.Deterministic(
"betaX",
betaX,
dims=[
"time",
],
)
mean = alpha + betaX
if mv_norm:
n = df.shape[1]
## Under the hood the LKJ prior will retain the correlation matrix too.
noise_chol, _, _ = pm.LKJCholeskyCov(
"noise_chol",
eta=priors["noise_chol"]["eta"],
n=n,
sd_dist=pm.HalfNormal.dist(sigma=priors["noise_chol"]["sigma"]),
)
obs = pm.MvNormal(
"obs", mu=mean, chol=noise_chol, observed=data_obs, dims=["time", "equations"]
)
else:
## This is an alternative likelihood that can recover sensible estimates of the coefficients
## But lacks the multivariate correlation between the timeseries.
sigma = pm.HalfNormal("noise", sigma=priors["noise"]["sigma"], dims=["equations"])
obs = pm.Normal(
"obs", mu=mean, sigma=sigma, observed=data_obs, dims=["time", "equations"]
)
if prior_checks:
idata = pm.sample_prior_predictive()
return model, idata
else:
idata = pm.sample_prior_predictive()
idata.extend(pm.sample(draws=2000, random_seed=130))
pm.sample_posterior_predictive(idata, extend_inferencedata=True, random_seed=rng)
return model, idata
该模型在自回归计算中具有确定性成分,这是每个时间步都需要的,但这里的关键点是我们将 VAR 的似然性建模为具有特定协方差关系的多元正态分布。这些协方差关系的估计给出了关于我们的组件时间序列彼此相关的方式的主要见解。
我们将检查具有 2 个滞后和 2 个方程的 VAR 的结构
n_lags = 2
n_eqs = 2
priors = {
"lag_coefs": {"mu": 0.3, "sigma": 1},
"alpha": {"mu": 15, "sigma": 5},
"noise_chol": {"eta": 1, "sigma": 1},
"noise": {"sigma": 1},
}
model, idata = make_model(n_lags, n_eqs, df, priors)
pm.model_to_graphviz(model)
Sampling: [alpha, lag_coefs, noise_chol, obs]

另一个具有 3 个滞后和 2 个方程的 VAR。
n_lags = 3
n_eqs = 2
model, idata = make_model(n_lags, n_eqs, df, priors)
for rv, shape in model.eval_rv_shapes().items():
print(f"{rv:>11}: shape={shape}")
pm.model_to_graphviz(model)
Sampling: [alpha, lag_coefs, noise_chol, obs]
lag_coefs: shape=(2, 3, 2)
alpha: shape=(2,)
noise_chol_cholesky-cov-packed__: shape=(3,)
noise_chol: shape=(3,)

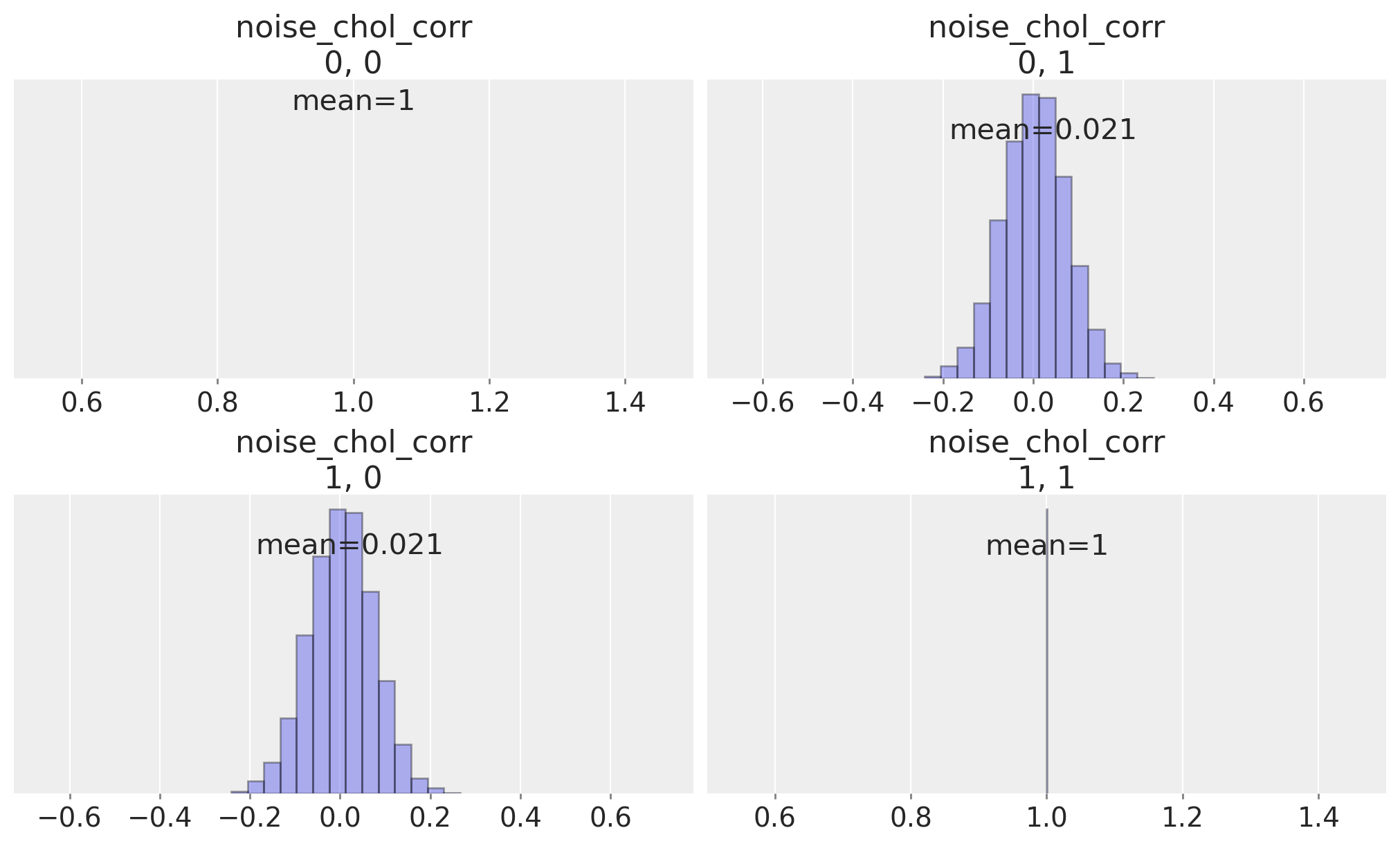
我们可以检查时间序列之间的相关矩阵,该矩阵由先验规范暗示,以查看我们是否允许了它们相关性的平坦均匀先验。
ax = az.plot_posterior(
idata,
var_names="noise_chol_corr",
hdi_prob="hide",
group="prior",
point_estimate="mean",
grid=(2, 2),
kind="hist",
ec="black",
figsize=(10, 4),
)

现在我们将拟合具有 2 个滞后和 2 个方程的 VAR
n_lags = 2
n_eqs = 2
model, idata_fake_data = make_model(n_lags, n_eqs, df, priors, prior_checks=False)
Sampling: [alpha, lag_coefs, noise_chol, obs]
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [lag_coefs, alpha, noise_chol]
Sampling 4 chains for 1_000 tune and 2_000 draw iterations (4_000 + 8_000 draws total) took 360 seconds.
Sampling: [obs]
我们现在将绘制一些结果,以查看参数是否被大致恢复。alpha 参数匹配良好,但各个滞后系数显示出差异。
az.summary(idata_fake_data, var_names=["alpha", "lag_coefs", "noise_chol_corr"])
/Users/nathanielforde/mambaforge/envs/myjlabenv/lib/python3.11/site-packages/arviz/stats/diagnostics.py:584: RuntimeWarning: invalid value encountered in scalar divide
(between_chain_variance / within_chain_variance + num_samples - 1) / (num_samples)
| 均值 | 标准差 | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha[x] | 8.607 | 1.765 | 5.380 | 12.076 | 0.029 | 0.020 | 3823.0 | 4602.0 | 1.0 |
| alpha[y] | 17.094 | 1.778 | 13.750 | 20.431 | 0.027 | 0.019 | 4188.0 | 5182.0 | 1.0 |
| lag_coefs[x, 1, x] | 1.333 | 0.062 | 1.218 | 1.450 | 0.001 | 0.001 | 5564.0 | 4850.0 | 1.0 |
| lag_coefs[x, 1, y] | -0.120 | 0.069 | -0.247 | 0.011 | 0.001 | 0.001 | 3739.0 | 4503.0 | 1.0 |
| lag_coefs[x, 2, x] | -0.711 | 0.097 | -0.890 | -0.527 | 0.002 | 0.001 | 3629.0 | 4312.0 | 1.0 |
| lag_coefs[x, 2, y] | 0.267 | 0.073 | 0.126 | 0.403 | 0.001 | 0.001 | 3408.0 | 4318.0 | 1.0 |
| lag_coefs[y, 1, x] | 0.838 | 0.061 | 0.718 | 0.948 | 0.001 | 0.001 | 5203.0 | 5345.0 | 1.0 |
| lag_coefs[y, 1, y] | -0.800 | 0.069 | -0.932 | -0.673 | 0.001 | 0.001 | 3749.0 | 5131.0 | 1.0 |
| lag_coefs[y, 2, x] | 0.094 | 0.097 | -0.087 | 0.277 | 0.002 | 0.001 | 3573.0 | 4564.0 | 1.0 |
| lag_coefs[y, 2, y] | -0.004 | 0.074 | -0.145 | 0.133 | 0.001 | 0.001 | 3448.0 | 4484.0 | 1.0 |
| noise_chol_corr[0, 0] | 1.000 | 0.000 | 1.000 | 1.000 | 0.000 | 0.000 | 8000.0 | 8000.0 | NaN |
| noise_chol_corr[0, 1] | 0.021 | 0.072 | -0.118 | 0.152 | 0.001 | 0.001 | 6826.0 | 5061.0 | 1.0 |
| noise_chol_corr[1, 0] | 0.021 | 0.072 | -0.118 | 0.152 | 0.001 | 0.001 | 6826.0 | 5061.0 | 1.0 |
| noise_chol_corr[1, 1] | 1.000 | 0.000 | 1.000 | 1.000 | 0.000 | 0.000 | 7813.0 | 7824.0 | 1.0 |
az.plot_posterior(idata_fake_data, var_names=["alpha"], ref_val=[8, 18]);

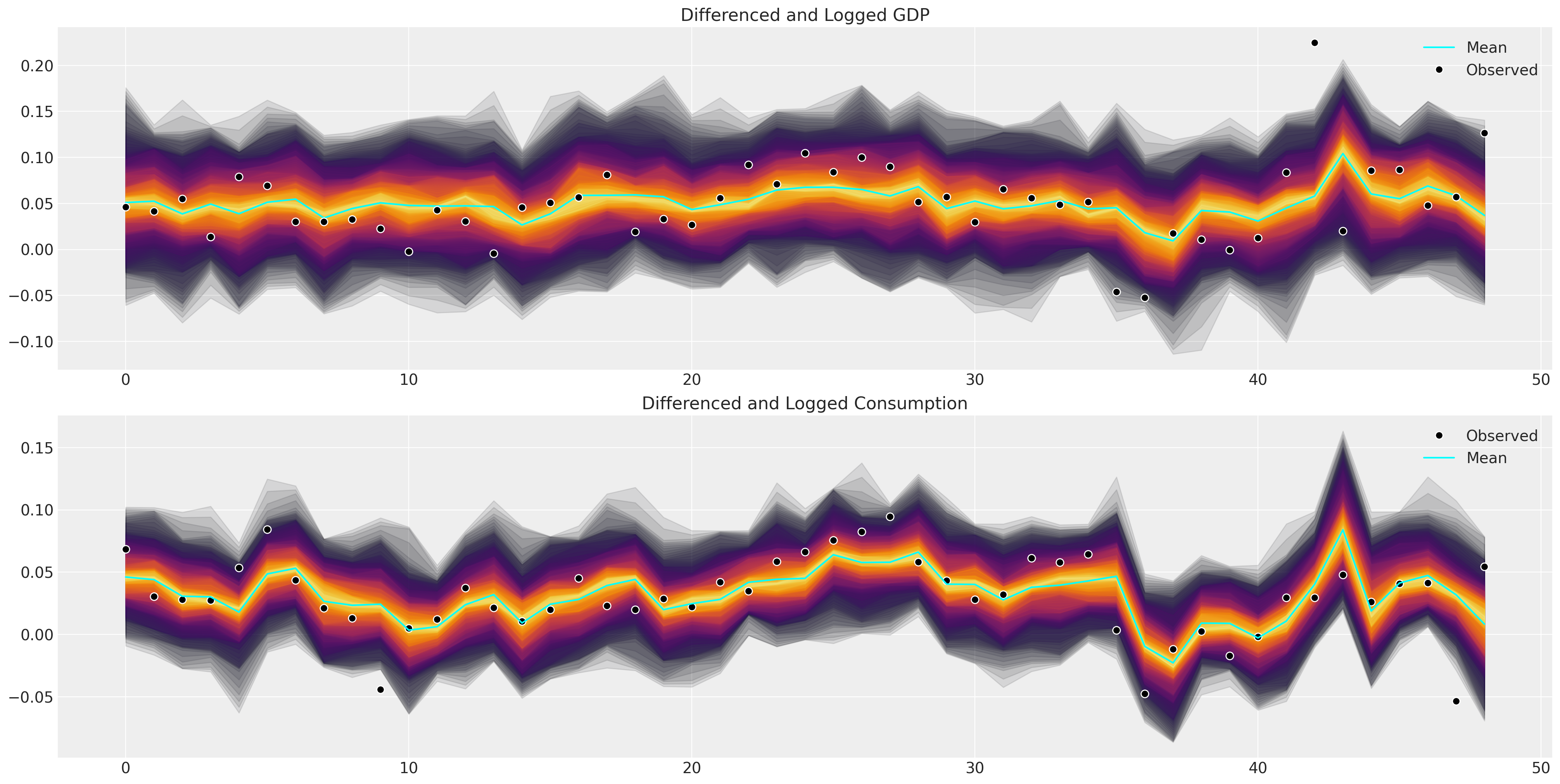
接下来,我们将绘制后验预测分布,以检查拟合模型是否可以捕捉到观测数据中的模式。这是拟合优度的主要测试。
def shade_background(ppc, ax, idx, palette="cividis"):
palette = palette
cmap = plt.get_cmap(palette)
percs = np.linspace(51, 99, 100)
colors = (percs - np.min(percs)) / (np.max(percs) - np.min(percs))
for i, p in enumerate(percs[::-1]):
upper = np.percentile(
ppc[:, idx, :],
p,
axis=1,
)
lower = np.percentile(
ppc[:, idx, :],
100 - p,
axis=1,
)
color_val = colors[i]
ax[idx].fill_between(
x=np.arange(ppc.shape[0]),
y1=upper.flatten(),
y2=lower.flatten(),
color=cmap(color_val),
alpha=0.1,
)
def plot_ppc(idata, df, group="posterior_predictive"):
fig, axs = plt.subplots(2, 1, figsize=(25, 15))
df = pd.DataFrame(idata_fake_data["observed_data"]["obs"].data, columns=["x", "y"])
axs = axs.flatten()
ppc = az.extract(idata, group=group, num_samples=100)["obs"]
# Minus the lagged terms and the constant
shade_background(ppc, axs, 0, "inferno")
axs[0].plot(np.arange(ppc.shape[0]), ppc[:, 0, :].mean(axis=1), color="cyan", label="Mean")
axs[0].plot(df["x"], "o", mfc="black", mec="white", mew=1, markersize=7, label="Observed")
axs[0].set_title("VAR Series 1")
axs[0].legend()
shade_background(ppc, axs, 1, "inferno")
axs[1].plot(df["y"], "o", mfc="black", mec="white", mew=1, markersize=7, label="Observed")
axs[1].plot(np.arange(ppc.shape[0]), ppc[:, 1, :].mean(axis=1), color="cyan", label="Mean")
axs[1].set_title("VAR Series 2")
axs[1].legend()
plot_ppc(idata_fake_data, df)
再次,我们可以检查相关参数的学习后验分布。
ax = az.plot_posterior(
idata_fake_data,
var_names="noise_chol_corr",
hdi_prob="hide",
point_estimate="mean",
grid=(2, 2),
kind="hist",
ec="black",
figsize=(10, 6),
)
应用理论:宏观经济时间序列#
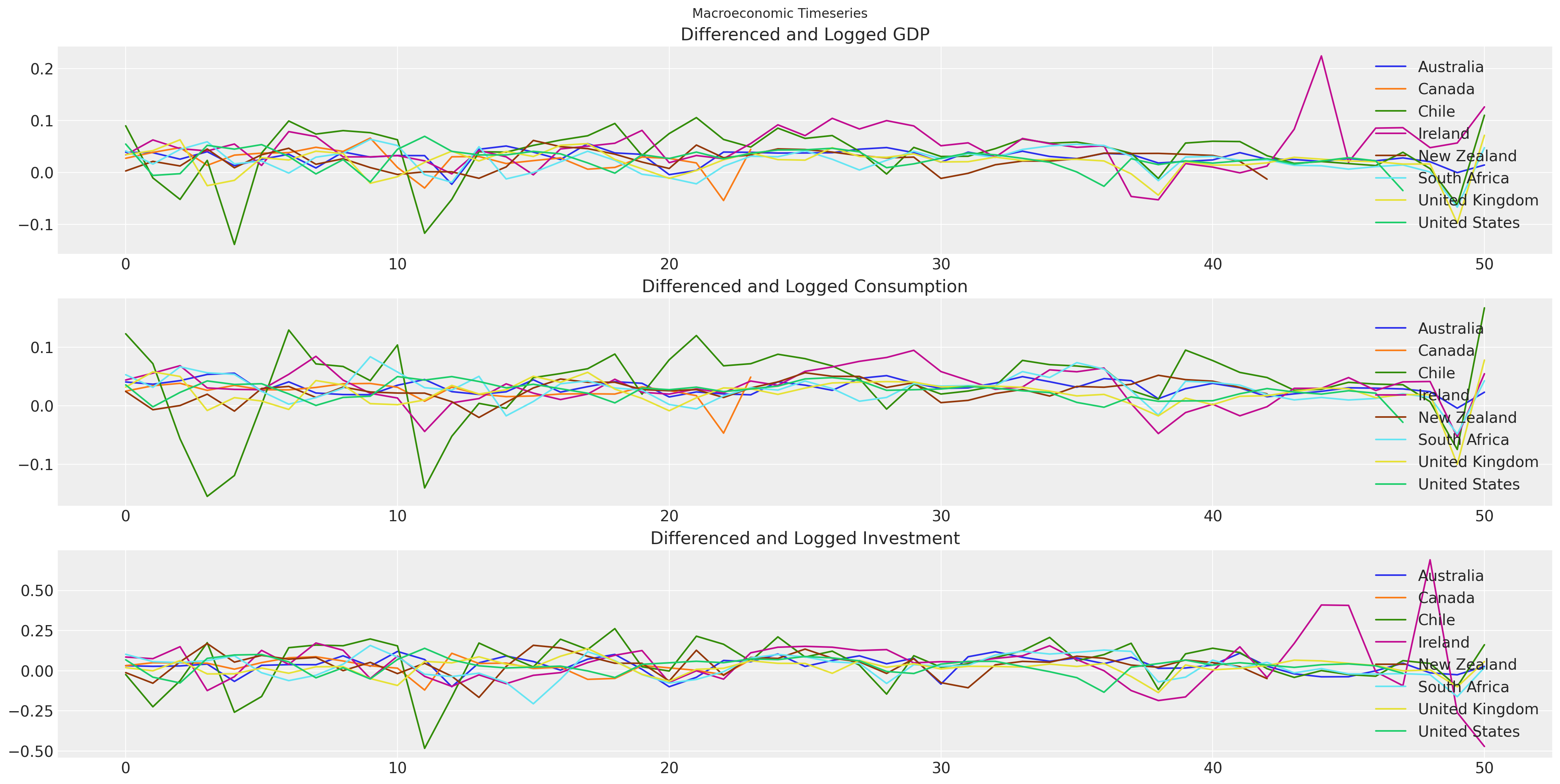
数据来自世界银行的世界发展指标。特别是,我们正在提取 1970 年以来所有国家的 GDP、消费和固定资本形成总额(投资)的年度值。时间序列模型通常在整个序列中具有稳定的均值时效果最佳,因此对于估计过程,我们采用了这些序列的一阶差分和自然对数。
try:
gdp_hierarchical = pd.read_csv(
os.path.join("..", "data", "gdp_data_hierarchical_clean.csv"), index_col=0
)
except FileNotFoundError:
gdp_hierarchical = pd.read_csv(pm.get_data("gdp_data_hierarchical_clean.csv"), ...)
gdp_hierarchical
| 国家 | iso2c | iso3c | 年份 | GDP | CONS | GFCF | dl_gdp | dl_cons | dl_gfcf | more_than_10 | 时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 澳大利亚 | AU | AUS | 1971 | 4.647670e+11 | 3.113170e+11 | 7.985100e+10 | 0.039217 | 0.040606 | 0.031705 | True | 1 |
| 2 | 澳大利亚 | AU | AUS | 1972 | 4.829350e+11 | 3.229650e+11 | 8.209200e+10 | 0.038346 | 0.036732 | 0.027678 | True | 2 |
| 3 | 澳大利亚 | AU | AUS | 1973 | 4.955840e+11 | 3.371070e+11 | 8.460300e+10 | 0.025855 | 0.042856 | 0.030129 | True | 3 |
| 4 | 澳大利亚 | AU | AUS | 1974 | 5.159300e+11 | 3.556010e+11 | 8.821400e+10 | 0.040234 | 0.053409 | 0.041796 | True | 4 |
| 5 | 澳大利亚 | AU | AUS | 1975 | 5.228210e+11 | 3.759000e+11 | 8.255900e+10 | 0.013268 | 0.055514 | -0.066252 | True | 5 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 366 | 美国 | US | USA | 2016 | 1.850960e+13 | 1.522497e+13 | 3.802207e+12 | 0.016537 | 0.023425 | 0.021058 | True | 44 |
| 367 | 美国 | US | USA | 2017 | 1.892712e+13 | 1.553075e+13 | 3.947418e+12 | 0.022306 | 0.019885 | 0.037480 | True | 45 |
| 368 | 美国 | US | USA | 2018 | 1.947957e+13 | 1.593427e+13 | 4.119951e+12 | 0.028771 | 0.025650 | 0.042780 | True | 46 |
| 369 | 美国 | US | USA | 2019 | 1.992544e+13 | 1.627888e+13 | 4.248643e+12 | 0.022631 | 0.021396 | 0.030758 | True | 47 |
| 370 | 美国 | US | USA | 2020 | 1.924706e+13 | 1.582501e+13 | 4.182801e+12 | -0.034639 | -0.028277 | -0.015619 | True | 48 |
370 行 × 12 列
fig, axs = plt.subplots(3, 1, figsize=(20, 10))
for country in gdp_hierarchical["country"].unique():
temp = gdp_hierarchical[gdp_hierarchical["country"] == country].reset_index()
axs[0].plot(temp["dl_gdp"], label=f"{country}")
axs[1].plot(temp["dl_cons"], label=f"{country}")
axs[2].plot(temp["dl_gfcf"], label=f"{country}")
axs[0].set_title("Differenced and Logged GDP")
axs[1].set_title("Differenced and Logged Consumption")
axs[2].set_title("Differenced and Logged Investment")
axs[0].legend()
axs[1].legend()
axs[2].legend()
plt.suptitle("Macroeconomic Timeseries");
爱尔兰的经济状况#
爱尔兰因其 GDP 数字而臭名昭著,这些数字在很大程度上是外国直接投资的产物,并且近年来由于向大型跨国公司提供的投资和税收协议而被夸大超出预期。我们将在此处仅关注 GDP 和消费之间的关系。我们只想展示 VAR 估计的机制,您不应过多解读随后的分析。
ireland_df = gdp_hierarchical[gdp_hierarchical["country"] == "Ireland"]
ireland_df.reset_index(inplace=True, drop=True)
ireland_df.head()
| 国家 | iso2c | iso3c | 年份 | GDP | CONS | GFCF | dl_gdp | dl_cons | dl_gfcf | more_than_10 | 时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 爱尔兰 | IE | IRL | 1971 | 3.314234e+10 | 2.897699e+10 | 8.317518e+09 | 0.034110 | 0.043898 | 0.085452 | True | 1 |
| 1 | 爱尔兰 | IE | IRL | 1972 | 3.529322e+10 | 3.063538e+10 | 8.967782e+09 | 0.062879 | 0.055654 | 0.075274 | True | 2 |
| 2 | 爱尔兰 | IE | IRL | 1973 | 3.695956e+10 | 3.280221e+10 | 1.041728e+10 | 0.046134 | 0.068340 | 0.149828 | True | 3 |
| 3 | 爱尔兰 | IE | IRL | 1974 | 3.853412e+10 | 3.381524e+10 | 9.207243e+09 | 0.041720 | 0.030416 | -0.123476 | True | 4 |
| 4 | 爱尔兰 | IE | IRL | 1975 | 4.071386e+10 | 3.477232e+10 | 8.874887e+09 | 0.055024 | 0.027910 | -0.036765 | True | 5 |
n_lags = 2
n_eqs = 2
priors = {
## Set prior for expected positive relationship between the variables.
"lag_coefs": {"mu": 0.3, "sigma": 1},
"alpha": {"mu": 0, "sigma": 0.1},
"noise_chol": {"eta": 1, "sigma": 1},
"noise": {"sigma": 1},
}
model, idata_ireland = make_model(
n_lags, n_eqs, ireland_df[["dl_gdp", "dl_cons"]], priors, prior_checks=False
)
idata_ireland
Sampling: [alpha, lag_coefs, noise_chol, obs]
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [lag_coefs, alpha, noise_chol]
Sampling 4 chains for 1_000 tune and 2_000 draw iterations (4_000 + 8_000 draws total) took 36 seconds.
Sampling: [obs]
-
- chain: 4
- draw: 2000
- equations: 2
- lags: 2
- cross_vars: 2
- noise_chol_dim_0: 3
- 时间: 49
- betaX_dim_1: 2
- noise_chol_corr_dim_0: 2
- noise_chol_corr_dim_1: 2
- noise_chol_stds_dim_0: 2
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 ... 1996 1997 1998 1999
array([ 0, 1, 2, ..., 1997, 1998, 1999])
- equations(equations)<U7'dl_gdp' 'dl_cons'
array(['dl_gdp', 'dl_cons'], dtype='<U7')
- lags(lags)int641 2
array([1, 2])
- cross_vars(cross_vars)<U7'dl_gdp' 'dl_cons'
array(['dl_gdp', 'dl_cons'], dtype='<U7')
- noise_chol_dim_0(noise_chol_dim_0)int640 1 2
array([0, 1, 2])
- 时间(time)int642 3 4 5 6 7 8 ... 45 46 47 48 49 50
array([ 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50]) - betaX_dim_1(betaX_dim_1)int640 1
array([0, 1])
- noise_chol_corr_dim_0(noise_chol_corr_dim_0)int640 1
array([0, 1])
- noise_chol_corr_dim_1(noise_chol_corr_dim_1)int640 1
array([0, 1])
- noise_chol_stds_dim_0(noise_chol_stds_dim_0)int640 1
array([0, 1])
- lag_coefs(chain, draw, equations, lags, cross_vars)float640.5197 0.07935 ... -0.2045 0.235
array([[[[[ 5.19656576e-01, 7.93542008e-02], [ 2.61607049e-01, -1.72153516e-01]], [[ 3.58280690e-01, 4.69430533e-01], [-1.41598877e-02, 7.07116179e-02]]], [[[-4.16577591e-02, 4.06592634e-01], [ 3.42706574e-01, -5.74590855e-01]], [[ 3.79750238e-01, 3.33743286e-01], [-1.00207466e-01, 1.43191909e-01]]], [[[ 5.15113761e-01, 5.43954306e-02], [ 2.24354001e-01, -1.25071225e-01]], [[ 3.35089469e-01, 3.15187746e-01], [ 8.77271295e-05, 1.81655203e-01]]], ... [[[ 2.78892253e-01, 2.13837349e-01], [ 2.60725950e-01, -1.27187687e-01]], [[ 3.84079652e-01, 9.48802792e-02], [-2.23869617e-02, 2.29483840e-01]]], [[[ 6.31173009e-01, -5.28215508e-01], [-1.55673631e-01, 3.61610751e-02]], [[ 3.27117933e-01, 4.42098735e-01], [-1.36438735e-01, -5.36320280e-03]]], [[[ 4.27130277e-01, -2.91019063e-01], [ 2.63469903e-02, 2.47138008e-01]], [[ 4.50003809e-01, 7.52912358e-02], [-2.04480247e-01, 2.35021007e-01]]]]]) - alpha(chain, draw, equations)float640.01472 -0.001526 ... 0.01042
array([[[ 0.01471676, -0.00152568], [ 0.0441433 , 0.00203566], [ 0.01079889, -0.00421006], ..., [ 0.01721974, 0.00564757], [ 0.04886959, 0.00799192], [ 0.01667415, 0.00371018]], [[ 0.04548506, 0.01127504], [ 0.04432491, -0.00028508], [ 0.03517707, 0.01830341], ..., [ 0.01805819, -0.00392762], [ 0.05267103, 0.02336937], [ 0.04478405, 0.01691428]], [[ 0.03111884, 0.00949071], [ 0.04501899, 0.00520666], [ 0.03759947, 0.00563301], ..., [ 0.02761799, 0.00727374], [ 0.04597957, 0.01626677], [ 0.05225605, 0.01325381]], [[ 0.0365445 , 0.00588842], [ 0.05292467, 0.01589702], [ 0.05850131, 0.00710232], ..., [ 0.03053105, 0.00836573], [ 0.02544402, 0.00399799], [ 0.03312685, 0.01041744]]]) - noise_chol(chain, draw, noise_chol_dim_0)float640.04206 0.01468 ... 0.01262 0.02424
array([[[0.04205913, 0.01467698, 0.02638489], [0.03959323, 0.00462671, 0.02231385], [0.03619061, 0.0115924 , 0.02253414], ..., [0.04634195, 0.01092772, 0.02286984], [0.04250194, 0.01037661, 0.02405165], [0.04079687, 0.00585382, 0.02524456]], [[0.04310706, 0.00775202, 0.02517299], [0.04330754, 0.01079034, 0.02413016], [0.03938486, 0.01259796, 0.02279358], ..., [0.04874519, 0.01286422, 0.02864554], [0.04704716, 0.01101798, 0.02170003], [0.04075767, 0.001405 , 0.02298114]], [[0.04082337, 0.00868785, 0.0205891 ], [0.04190526, 0.0087839 , 0.02398674], [0.0479445 , 0.01780939, 0.0228716 ], ..., [0.04367215, 0.00381667, 0.02414608], [0.04618374, 0.00985851, 0.0241093 ], [0.04771735, 0.01976765, 0.02301084]], [[0.03937039, 0.01452327, 0.02261826], [0.04017701, 0.00773141, 0.01975944], [0.04501176, 0.00872818, 0.01975194], ..., [0.04350486, 0.00854354, 0.02546362], [0.04543641, 0.01214901, 0.023637 ], [0.04664034, 0.01261794, 0.02423548]]]) - betaX(chain, draw, time, betaX_dim_1)float640.03846 0.05127 ... 0.05137 0.02155
array([[[[ 0.03845828, 0.05127494], [ 0.03626535, 0.0516547 ], [ 0.02439747, 0.03340475], ..., [ 0.06606994, 0.05073041], [ 0.04383074, 0.03827857], [ 0.03082664, -0.00237368]], [[ 0.0064756 , 0.04532004], [ 0.01543582, 0.04199548], [-0.0128284 , 0.03115703], ..., [ 0.027321 , 0.04158131], [ 0.02104586, 0.02920793], [-0.03139562, 0.00495901]], [[ 0.03757968, 0.04658869], [ 0.03462795, 0.04711412], [ 0.0249478 , 0.03598497], ..., ... ..., [ 0.05183073, 0.04113899], [ 0.03959469, 0.02977498], [ 0.01174284, 0.02525658]], [[ 0.00656781, 0.04028385], [-0.01475617, 0.03642657], [ 0.00555572, 0.0204332 ], ..., [ 0.02066245, 0.03446825], [-0.00354691, 0.02198112], [ 0.05819251, -0.01170932]], [[ 0.02240881, 0.03582803], [ 0.01522756, 0.02612792], [ 0.0270731 , 0.02769207], ..., [ 0.03377353, 0.03059268], [ 0.0208055 , 0.01661153], [ 0.05137065, 0.02154906]]]]) - noise_chol_corr(chain, draw, noise_chol_corr_dim_0, noise_chol_corr_dim_1)float641.0 0.4861 0.4861 ... 0.4618 1.0
array([[[[1. , 0.48611626], [0.48611626, 1. ]], [[1. , 0.20302855], [0.20302855, 1. ]], [[1. , 0.45745439], [0.45745439, 1. ]], ..., [[1. , 0.43113357], [0.43113357, 1. ]], [[1. , 0.39613595], [0.39613595, 1. ]], [[1. , 0.22589091], [0.22589091, 1. ]]], ... [[[1. , 0.54030892], [0.54030892, 1. ]], [[1. , 0.36437699], [0.36437699, 1. ]], [[1. , 0.40418614], [0.40418614, 1. ]], ..., [[1. , 0.31809258], [0.31809258, 1. ]], [[1. , 0.45713496], [0.45713496, 1. ]], [[1. , 0.46179879], [0.46179879, 1. ]]]]) - noise_chol_stds(chain, draw, noise_chol_stds_dim_0)float640.04206 0.03019 ... 0.04664 0.02732
array([[[0.04205913, 0.03019232], [0.03959323, 0.02278847], [0.03619061, 0.0253411 ], ..., [0.04634195, 0.02534649], [0.04250194, 0.02619458], [0.04079687, 0.02591438]], [[0.04310706, 0.02633958], [0.04330754, 0.02643286], [0.03938486, 0.02604334], ..., [0.04874519, 0.03140152], [0.04704716, 0.02433695], [0.04075767, 0.02302405]], [[0.04082337, 0.02234703], [0.04190526, 0.02554449], [0.0479445 , 0.02898766], ..., [0.04367215, 0.02444586], [0.04618374, 0.02604704], [0.04771735, 0.03033577]], [[0.03937039, 0.02687956], [0.04017701, 0.02121816], [0.04501176, 0.02159444], ..., [0.04350486, 0.02685867], [0.04543641, 0.02657642], [0.04664034, 0.02732345]]])
- chainPandasIndex
PandasIndex(Int64Index([0, 1, 2, 3], dtype='int64', name='chain'))
- drawPandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ... 1990, 1991, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999], dtype='int64', name='draw', length=2000)) - equationsPandasIndex
PandasIndex(Index(['dl_gdp', 'dl_cons'], dtype='object', name='equations'))
- lagsPandasIndex
PandasIndex(Int64Index([1, 2], dtype='int64', name='lags'))
- cross_varsPandasIndex
PandasIndex(Index(['dl_gdp', 'dl_cons'], dtype='object', name='cross_vars'))
- noise_chol_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_dim_0'))
- 时间PandasIndex
PandasIndex(Int64Index([ 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50], dtype='int64', name='time')) - betaX_dim_1PandasIndex
PandasIndex(Int64Index([0, 1], dtype='int64', name='betaX_dim_1'))
- noise_chol_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1], dtype='int64', name='noise_chol_corr_dim_0'))
- noise_chol_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1], dtype='int64', name='noise_chol_corr_dim_1'))
- noise_chol_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1], dtype='int64', name='noise_chol_stds_dim_0'))
- created_at
- 2023-02-21T19:21:22.942792
- arviz_version
- 0.14.0
- inference_library
- pymc
- inference_library_version
- 5.0.1
- sampling_time
- 36.195340156555176
- tuning_steps
- 1000
<xarray.Dataset> Dimensions: (chain: 4, draw: 2000, equations: 2, lags: 2, cross_vars: 2, noise_chol_dim_0: 3, time: 49, betaX_dim_1: 2, noise_chol_corr_dim_0: 2, noise_chol_corr_dim_1: 2, noise_chol_stds_dim_0: 2) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 ... 1995 1996 1997 1998 1999 * equations (equations) <U7 'dl_gdp' 'dl_cons' * lags (lags) int64 1 2 * cross_vars (cross_vars) <U7 'dl_gdp' 'dl_cons' * noise_chol_dim_0 (noise_chol_dim_0) int64 0 1 2 * time (time) int64 2 3 4 5 6 7 8 9 ... 44 45 46 47 48 49 50 * betaX_dim_1 (betaX_dim_1) int64 0 1 * noise_chol_corr_dim_0 (noise_chol_corr_dim_0) int64 0 1 * noise_chol_corr_dim_1 (noise_chol_corr_dim_1) int64 0 1 * noise_chol_stds_dim_0 (noise_chol_stds_dim_0) int64 0 1 Data variables: lag_coefs (chain, draw, equations, lags, cross_vars) float64 ... alpha (chain, draw, equations) float64 0.01472 ... 0.01042 noise_chol (chain, draw, noise_chol_dim_0) float64 0.04206 ..... betaX (chain, draw, time, betaX_dim_1) float64 0.03846 .... noise_chol_corr (chain, draw, noise_chol_corr_dim_0, noise_chol_corr_dim_1) float64 ... noise_chol_stds (chain, draw, noise_chol_stds_dim_0) float64 0.042... Attributes: created_at: 2023-02-21T19:21:22.942792 arviz_version: 0.14.0 inference_library: pymc inference_library_version: 5.0.1 sampling_time: 36.195340156555176 tuning_steps: 1000xarray.Dataset -
- chain: 4
- draw: 2000
- 时间: 49
- equations: 2
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 ... 1996 1997 1998 1999
array([ 0, 1, 2, ..., 1997, 1998, 1999])
- 时间(time)int642 3 4 5 6 7 8 ... 45 46 47 48 49 50
array([ 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50]) - equations(equations)<U7'dl_gdp' 'dl_cons'
array(['dl_gdp', 'dl_cons'], dtype='<U7')
- obs(chain, draw, time, equations)float640.07266 0.05554 ... 0.131 0.05994
array([[[[ 0.07266384, 0.05554043], [-0.03723739, -0.01044936], [ 0.06613757, 0.01211585], ..., [ 0.13244691, 0.06005397], [-0.02656575, 0.02116827], [ 0.07340778, 0.01205019]], [[ 0.08268452, 0.01698459], [ 0.02978633, 0.01275627], [ 0.01878881, 0.04764196], ..., [ 0.12656091, 0.00217327], [ 0.04914098, -0.00649668], [ 0.03080986, 0.05185062]], [[ 0.02621489, 0.00719224], [ 0.01166067, 0.0217407 ], [ 0.06380577, 0.06132611], ..., ... ..., [ 0.13366362, 0.0631761 ], [ 0.08309923, 0.10108214], [ 0.02315299, 0.02944125]], [[ 0.10004432, 0.08094177], [ 0.02037102, 0.08725727], [ 0.00521511, 0.03733144], ..., [ 0.05345503, 0.08313247], [ 0.03175078, 0.01423723], [ 0.16007207, -0.04465602]], [[ 0.05437818, 0.0252325 ], [ 0.08520019, 0.04364142], [ 0.02855142, 0.03297121], ..., [ 0.15104638, 0.08219397], [ 0.1100447 , 0.010313 ], [ 0.13102166, 0.05993663]]]])
- chainPandasIndex
PandasIndex(Int64Index([0, 1, 2, 3], dtype='int64', name='chain'))
- drawPandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ... 1990, 1991, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999], dtype='int64', name='draw', length=2000)) - 时间PandasIndex
PandasIndex(Int64Index([ 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50], dtype='int64', name='time')) - equationsPandasIndex
PandasIndex(Index(['dl_gdp', 'dl_cons'], dtype='object', name='equations'))
- created_at
- 2023-02-21T19:21:57.788979
- arviz_version
- 0.14.0
- inference_library
- pymc
- inference_library_version
- 5.0.1
<xarray.Dataset> Dimensions: (chain: 4, draw: 2000, time: 49, equations: 2) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 6 ... 1993 1994 1995 1996 1997 1998 1999 * time (time) int64 2 3 4 5 6 7 8 9 10 11 ... 42 43 44 45 46 47 48 49 50 * equations (equations) <U7 'dl_gdp' 'dl_cons' Data variables: obs (chain, draw, time, equations) float64 0.07266 ... 0.05994 Attributes: created_at: 2023-02-21T19:21:57.788979 arviz_version: 0.14.0 inference_library: pymc inference_library_version: 5.0.1xarray.Dataset -
- chain: 4
- draw: 2000
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 ... 1996 1997 1998 1999
array([ 0, 1, 2, ..., 1997, 1998, 1999])
- step_size(chain, draw)float640.2559 0.2559 ... 0.2865 0.2865
array([[0.25588962, 0.25588962, 0.25588962, ..., 0.25588962, 0.25588962, 0.25588962], [0.3697469 , 0.3697469 , 0.3697469 , ..., 0.3697469 , 0.3697469 , 0.3697469 ], [0.42101555, 0.42101555, 0.42101555, ..., 0.42101555, 0.42101555, 0.42101555], [0.28653149, 0.28653149, 0.28653149, ..., 0.28653149, 0.28653149, 0.28653149]]) - perf_counter_start(chain, draw)float641.626e+05 1.626e+05 ... 1.626e+05
array([[162631.64961679, 162631.65651296, 162631.66551496, ..., 162648.95160179, 162648.95829438, 162648.96578838], [162631.04184112, 162631.05123112, 162631.0605795 , ..., 162648.36295925, 162648.37161829, 162648.37843467], [162632.29036962, 162632.30043392, 162632.30901504, ..., 162649.81244104, 162649.81932071, 162649.8258015 ], [162631.24282437, 162631.25291775, 162631.26280779, ..., 162648.34229779, 162648.35076021, 162648.35829229]]) - acceptance_rate(chain, draw)float640.452 0.882 ... 0.6842 0.6953
array([[0.45200921, 0.88196032, 0.85477008, ..., 0.96927221, 0.84755787, 0.72968371], [0.98771315, 0.8009883 , 0.80420022, ..., 0.86016188, 0.75991948, 0.20906901], [0.99751756, 0.9866047 , 0.73547533, ..., 0.95386729, 0.73301308, 0.6478722 ], [0.97393312, 0.4316111 , 0.35684925, ..., 0.95519091, 0.6841993 , 0.69534805]]) - largest_eigval(chain, draw)float64nan nan nan nan ... nan nan nan nan
array([[nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan]]) - lp(chain, draw)float64192.2 189.8 192.1 ... 185.6 191.9
array([[192.18966643, 189.81728435, 192.14034097, ..., 192.06668954, 193.42245096, 191.36656983], [190.79957544, 190.83997606, 187.12480105, ..., 185.29102408, 187.45700699, 188.40205797], [192.65934246, 194.23007138, 192.32551615, ..., 192.41982885, 189.68059219, 187.40005344], [193.08342569, 191.03132672, 188.24977915, ..., 191.53209216, 185.60644058, 191.94696886]]) - n_steps(chain, draw)float6415.0 15.0 15.0 ... 15.0 15.0 15.0
array([[15., 15., 15., ..., 15., 15., 15.], [15., 15., 15., ..., 15., 15., 15.], [15., 15., 15., ..., 15., 15., 15.], [15., 15., 15., ..., 15., 15., 15.]]) - perf_counter_diff(chain, draw)float640.006816 0.00892 ... 0.009416
array([[0.00681596, 0.00891987, 0.00853138, ..., 0.00662113, 0.00743258, 0.00674708], [0.00924708, 0.00926471, 0.00896663, ..., 0.00856346, 0.00672742, 0.00760842], [0.00998017, 0.0084875 , 0.00804771, ..., 0.00681546, 0.00641321, 0.00689512], [0.01000392, 0.0098055 , 0.00847175, ..., 0.008375 , 0.00745308, 0.00941558]]) - max_energy_error(chain, draw)float642.216 0.4151 0.2987 ... 1.156 1.252
array([[ 2.21643644, 0.41508426, 0.29868443, ..., -0.09954207, 0.39111492, 0.94939641], [-0.23714436, 0.34132827, 0.66750119, ..., 0.33884617, 1.38906123, 4.3288482 ], [-0.13750741, -0.07262999, 0.49443942, ..., -0.80694987, 0.63095501, 0.99504025], [-0.1666122 , 2.17550408, 3.13785432, ..., -0.33376487, 1.15567682, 1.25234077]]) - tree_depth(chain, draw)int644 4 4 4 4 4 4 4 ... 4 4 4 4 4 4 4 4
array([[4, 4, 4, ..., 4, 4, 4], [4, 4, 4, ..., 4, 4, 4], [4, 4, 4, ..., 4, 4, 4], [4, 4, 4, ..., 4, 4, 4]]) - step_size_bar(chain, draw)float640.2629 0.2629 ... 0.2741 0.2741
array([[0.26288954, 0.26288954, 0.26288954, ..., 0.26288954, 0.26288954, 0.26288954], [0.28887259, 0.28887259, 0.28887259, ..., 0.28887259, 0.28887259, 0.28887259], [0.26055628, 0.26055628, 0.26055628, ..., 0.26055628, 0.26055628, 0.26055628], [0.27413238, 0.27413238, 0.27413238, ..., 0.27413238, 0.27413238, 0.27413238]]) - smallest_eigval(chain, draw)float64nan nan nan nan ... nan nan nan nan
array([[nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan], [nan, nan, nan, ..., nan, nan, nan]]) - energy_error(chain, draw)float640.1063 -0.1922 ... 0.6039 -0.8926
array([[ 0.10633161, -0.19223807, -0.07324313, ..., -0.05689863, 0.11804534, 0.04478887], [-0.11199666, 0.20578808, -0.1399356 , ..., 0.205265 , -0.25117668, 1.01038826], [-0.13750741, -0.03513089, 0.20506484, ..., -0.70430077, -0.01280797, -0.16463478], [-0.1666122 , 0.61632692, -0.48263151, ..., 0.10197503, 0.60388915, -0.89258914]]) - diverging(chain, draw)boolFalse False False ... False False
array([[False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False]]) - index_in_trajectory(chain, draw)int648 -6 -6 -6 10 ... -12 10 10 -10 -6
array([[ 8, -6, -6, ..., 7, -11, -10], [-15, 15, 9, ..., 12, 8, 4], [-14, 6, -12, ..., -13, 7, -6], [ 3, 6, 2, ..., 10, -10, -6]]) - energy(chain, draw)float64-186.7 -183.7 ... -182.6 -182.3
array([[-186.71221527, -183.69718813, -180.80066873, ..., -187.0691717 , -185.80251922, -185.85593343], [-186.62691362, -183.68157888, -180.83446734, ..., -180.21656638, -177.21042455, -175.34992831], [-185.6449068 , -189.74583709, -186.80186591, ..., -176.16387582, -182.34563041, -179.97120628], [-187.09037814, -183.89547442, -175.47726337, ..., -188.01409915, -182.5587388 , -182.28892311]]) - process_time_diff(chain, draw)float640.007787 0.01354 ... 0.01025
array([[0.007787, 0.013544, 0.01156 , ..., 0.00884 , 0.010774, 0.009 ], [0.010579, 0.011096, 0.009645, ..., 0.007559, 0.010655, 0.012674], [0.015694, 0.01198 , 0.01068 , ..., 0.009102, 0.008428, 0.009367], [0.013038, 0.014209, 0.010028, ..., 0.012215, 0.008676, 0.010252]]) - reached_max_treedepth(chain, draw)boolFalse False False ... False False
array([[False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False]])
- chainPandasIndex
PandasIndex(Int64Index([0, 1, 2, 3], dtype='int64', name='chain'))
- drawPandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ... 1990, 1991, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999], dtype='int64', name='draw', length=2000))
- created_at
- 2023-02-21T19:21:22.951462
- arviz_version
- 0.14.0
- inference_library
- pymc
- inference_library_version
- 5.0.1
- sampling_time
- 36.195340156555176
- tuning_steps
- 1000
<xarray.Dataset> Dimensions: (chain: 4, draw: 2000) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 ... 1995 1996 1997 1998 1999 Data variables: (12/17) step_size (chain, draw) float64 0.2559 0.2559 ... 0.2865 0.2865 perf_counter_start (chain, draw) float64 1.626e+05 ... 1.626e+05 acceptance_rate (chain, draw) float64 0.452 0.882 ... 0.6842 0.6953 largest_eigval (chain, draw) float64 nan nan nan nan ... nan nan nan lp (chain, draw) float64 192.2 189.8 ... 185.6 191.9 n_steps (chain, draw) float64 15.0 15.0 15.0 ... 15.0 15.0 ... ... energy_error (chain, draw) float64 0.1063 -0.1922 ... -0.8926 diverging (chain, draw) bool False False False ... False False index_in_trajectory (chain, draw) int64 8 -6 -6 -6 10 ... 10 10 -10 -6 energy (chain, draw) float64 -186.7 -183.7 ... -182.6 -182.3 process_time_diff (chain, draw) float64 0.007787 0.01354 ... 0.01025 reached_max_treedepth (chain, draw) bool False False False ... False False Attributes: created_at: 2023-02-21T19:21:22.951462 arviz_version: 0.14.0 inference_library: pymc inference_library_version: 5.0.1 sampling_time: 36.195340156555176 tuning_steps: 1000xarray.Dataset -
- chain: 1
- draw: 500
- equations: 2
- noise_chol_corr_dim_0: 2
- noise_chol_corr_dim_1: 2
- noise_chol_stds_dim_0: 2
- 时间: 49
- betaX_dim_1: 2
- noise_chol_dim_0: 3
- lags: 2
- cross_vars: 2
- chain(chain)int640
array([0])
- draw(draw)int640 1 2 3 4 5 ... 495 496 497 498 499
array([ 0, 1, 2, ..., 497, 498, 499])
- equations(equations)<U7'dl_gdp' 'dl_cons'
array(['dl_gdp', 'dl_cons'], dtype='<U7')
- noise_chol_corr_dim_0(noise_chol_corr_dim_0)int640 1
array([0, 1])
- noise_chol_corr_dim_1(noise_chol_corr_dim_1)int640 1
array([0, 1])
- noise_chol_stds_dim_0(noise_chol_stds_dim_0)int640 1
array([0, 1])
- 时间(time)int642 3 4 5 6 7 8 ... 45 46 47 48 49 50
array([ 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50]) - betaX_dim_1(betaX_dim_1)int640 1
array([0, 1])
- noise_chol_dim_0(noise_chol_dim_0)int640 1 2
array([0, 1, 2])
- lags(lags)int641 2
array([1, 2])
- cross_vars(cross_vars)<U7'dl_gdp' 'dl_cons'
array(['dl_gdp', 'dl_cons'], dtype='<U7')
- alpha(chain, draw, equations)float64-0.02173 -0.1333 ... 0.04148
array([[[-2.17321208e-02, -1.33334684e-01], [ 5.34931179e-02, 1.59499447e-01], [-9.49314248e-03, 5.64533641e-02], [-2.33126640e-02, -1.02705798e-01], [ 1.26733115e-01, 7.69344011e-02], [-1.80317474e-02, 6.57613825e-02], [-1.13071369e-01, 1.51406968e-01], [-1.54448261e-01, 1.31782276e-01], [-3.17081453e-02, 1.90268718e-02], [-1.18113054e-01, 1.62388440e-01], [ 7.05559903e-02, -1.19139213e-02], [ 1.33057457e-01, -3.39059486e-02], [-2.55956804e-02, -6.54044042e-02], [-8.17956874e-03, 1.98647714e-01], [ 5.57149931e-03, -4.32720912e-02], [ 8.87368333e-02, 1.71219288e-01], [ 2.10682139e-02, -1.24616571e-01], [-1.20201764e-03, -1.17523975e-01], [-9.64406169e-02, 6.16024940e-02], [ 8.76603291e-02, -8.72035128e-02], ... [ 1.37657923e-01, 1.27996799e-01], [ 5.13551369e-02, -1.31544671e-01], [ 1.00260415e-02, -1.07408884e-03], [-5.83019260e-02, -2.54488291e-02], [ 3.70272843e-02, 2.20626431e-01], [ 3.03187875e-02, 2.52427570e-02], [ 7.58630825e-02, -2.94336306e-01], [-2.36982827e-02, -8.84849345e-03], [-1.77442781e-02, -8.50522727e-03], [ 4.80910337e-02, 1.46007292e-02], [ 1.67488753e-01, 2.23774479e-01], [-4.09985360e-02, -1.48536396e-02], [ 4.67375840e-02, -2.03043589e-02], [-1.12377222e-01, -8.82438720e-02], [-9.90900254e-02, 1.36751395e-01], [-2.53327369e-02, -7.34878400e-02], [-4.96505019e-02, 8.64545788e-02], [ 3.48784048e-02, 2.66594474e-01], [ 2.83293109e-02, -7.74836476e-02], [ 7.36847485e-02, 4.14770386e-02]]]) - noise_chol_corr(chain, draw, noise_chol_corr_dim_0, noise_chol_corr_dim_1)float641.0 -0.2284 -0.2284 ... -0.5198 1.0
array([[[[ 1. , -0.22837651], [-0.22837651, 1. ]], [[ 1. , 0.82351754], [ 0.82351754, 1. ]], [[ 1. , 0.34327501], [ 0.34327501, 1. ]], ..., [[ 1. , 0.69452847], [ 0.69452847, 1. ]], [[ 1. , 0.42945802], [ 0.42945802, 1. ]], [[ 1. , -0.5198015 ], [-0.5198015 , 1. ]]]]) - noise_chol_stds(chain, draw, noise_chol_stds_dim_0)float640.4793 1.124 ... 0.01728 0.2597
array([[[4.79284896e-01, 1.12391550e+00], [6.97040739e-01, 9.54652181e-01], [1.59097130e+00, 3.31920295e-01], [1.15243377e+00, 7.82453571e-02], [5.53414777e-01, 2.06989481e-01], [2.14023145e+00, 4.47391867e-02], [2.60874906e-01, 1.49356985e+00], [1.20751677e+00, 5.06368239e-01], [2.93252219e-01, 9.22195628e-02], [5.59250055e-01, 8.46677717e-01], [3.33437205e-01, 5.50176517e-01], [1.67605175e-02, 3.56294802e-01], [2.30751158e-01, 1.10548076e+00], [1.55569836e+00, 9.90290581e-01], [1.41325046e+00, 1.01313301e+00], [7.50295560e-01, 6.17414964e-01], [5.22344641e-01, 7.23205322e-01], [1.41627088e+00, 8.49720046e-01], [1.80338965e+00, 1.65866311e+00], [3.62065401e-02, 3.03571965e+00], ... [1.51141877e+00, 1.44833737e+00], [1.10143071e-01, 4.36921244e-01], [1.53377987e+00, 8.92707864e-01], [7.70254088e-01, 2.15079477e+00], [1.24557997e-01, 1.00007158e+00], [1.26361991e+00, 1.12878392e-01], [2.11441792e-01, 6.76319368e-02], [7.25305848e-01, 2.20809866e+00], [2.95885724e-01, 1.33235181e+00], [9.91874436e-01, 9.99117482e-01], [9.37832970e-01, 8.39861991e-01], [1.54576189e-01, 2.57803495e-01], [1.05339644e+00, 2.84286425e-01], [1.87852079e-01, 6.49825798e-01], [1.41159170e-01, 2.71423310e-01], [1.58019583e+00, 1.23724822e+00], [8.82855209e-01, 2.96738277e+00], [3.47493609e-01, 2.50978228e+00], [1.11940315e+00, 6.25613502e-01], [1.72818848e-02, 2.59731360e-01]]]) - betaX(chain, draw, time, betaX_dim_1)float640.05801 0.1928 ... 0.1824 0.1416
array([[[[ 0.05801452, 0.19282852], [ 0.06136907, 0.19021009], [ 0.06498837, 0.12662961], ..., [ 0.1263401 , 0.22265808], [ 0.09465621, 0.1605613 ], [ 0.12072331, 0.0342081 ]], [[ 0.03458694, 0.04445992], [ 0.077954 , 0.03533871], [ 0.01711512, 0.03041004], ..., [ 0.09682593, 0.02314592], [ 0.09850186, 0.01292326], [-0.03044917, -0.00261849]], [[ 0.03363234, 0.0448288 ], [ 0.0509058 , 0.01335756], [ 0.0114371 , -0.01758728], ..., ... ..., [-0.03846538, 0.06103218], [-0.03609514, 0.01253422], [ 0.11130663, 0.03136471]], [[ 0.15524741, 0.02883929], [ 0.16256085, 0.05265778], [ 0.12545039, -0.00345506], ..., [ 0.14048099, 0.04771948], [ 0.11854582, 0.04748313], [ 0.01834497, -0.07335791]], [[ 0.13089945, -0.05260524], [ 0.15576556, -0.06532189], [ 0.20108248, -0.01115042], ..., [ 0.12102344, 0.0121013 ], [ 0.13921009, -0.00432658], [ 0.18239744, 0.14157838]]]]) - noise_chol(chain, draw, noise_chol_dim_0)float640.4793 -0.2567 ... -0.135 0.2219
array([[[ 0.4792849 , -0.2566759 , 1.09421366], [ 0.69704074, 0.78617282, 0.5415654 ], [ 1.5909713 , 0.11393994, 0.31175114], ..., [ 0.34749361, 1.74311526, 1.80570106], [ 1.11940315, 0.26867474, 0.56498331], [ 0.01728188, -0.13500875, 0.22188514]]]) - lag_coefs(chain, draw, equations, lags, cross_vars)float640.8718 -0.5211 ... 0.5638 -0.01947
array([[[[[ 0.87178822, -0.52109414], [ 0.81192969, 0.10257338]], [[ 1.66388457, 1.39492785], [ 0.2402051 , 0.0541874 ]]], [[[-0.30618212, 0.79757413], [ 1.30337738, -0.79747345]], [[ 0.38143198, 0.35600826], [-0.37832199, 0.309069 ]]], [[[-0.2397557 , 0.95264081], [ 0.11852561, -0.19028039]], [[ 0.88990685, 0.74043063], [-0.60850236, -0.71937965]]], ... [[[-0.33751836, -2.02597956], [ 1.06725697, -0.69540281]], [[ 1.2472135 , 0.17422232], [-0.62668472, -0.00886019]]], [[[ 0.89838374, 1.17917942], [-0.07513856, 0.81314769]], [[-0.23967996, 1.03413277], [ 0.52659114, -0.71997653]]], [[[ 0.5282788 , -0.52010047], [ 0.32594737, 2.63132424]], [[ 0.40303183, -1.73076034], [ 0.56375655, -0.01946577]]]]])
- chainPandasIndex
PandasIndex(Int64Index([0], dtype='int64', name='chain'))
- drawPandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ... 490, 491, 492, 493, 494, 495, 496, 497, 498, 499], dtype='int64', name='draw', length=500)) - equationsPandasIndex
PandasIndex(Index(['dl_gdp', 'dl_cons'], dtype='object', name='equations'))
- noise_chol_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1], dtype='int64', name='noise_chol_corr_dim_0'))
- noise_chol_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1], dtype='int64', name='noise_chol_corr_dim_1'))
- noise_chol_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1], dtype='int64', name='noise_chol_stds_dim_0'))
- 时间PandasIndex
PandasIndex(Int64Index([ 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50], dtype='int64', name='time')) - betaX_dim_1PandasIndex
PandasIndex(Int64Index([0, 1], dtype='int64', name='betaX_dim_1'))
- noise_chol_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_dim_0'))
- lagsPandasIndex
PandasIndex(Int64Index([1, 2], dtype='int64', name='lags'))
- cross_varsPandasIndex
PandasIndex(Index(['dl_gdp', 'dl_cons'], dtype='object', name='cross_vars'))
- created_at
- 2023-02-21T19:20:42.612680
- arviz_version
- 0.14.0
- inference_library
- pymc
- inference_library_version
- 5.0.1
<xarray.Dataset> Dimensions: (chain: 1, draw: 500, equations: 2, noise_chol_corr_dim_0: 2, noise_chol_corr_dim_1: 2, noise_chol_stds_dim_0: 2, time: 49, betaX_dim_1: 2, noise_chol_dim_0: 3, lags: 2, cross_vars: 2) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 5 ... 494 495 496 497 498 499 * equations (equations) <U7 'dl_gdp' 'dl_cons' * noise_chol_corr_dim_0 (noise_chol_corr_dim_0) int64 0 1 * noise_chol_corr_dim_1 (noise_chol_corr_dim_1) int64 0 1 * noise_chol_stds_dim_0 (noise_chol_stds_dim_0) int64 0 1 * time (time) int64 2 3 4 5 6 7 8 9 ... 44 45 46 47 48 49 50 * betaX_dim_1 (betaX_dim_1) int64 0 1 * noise_chol_dim_0 (noise_chol_dim_0) int64 0 1 2 * lags (lags) int64 1 2 * cross_vars (cross_vars) <U7 'dl_gdp' 'dl_cons' Data variables: alpha (chain, draw, equations) float64 -0.02173 ... 0.04148 noise_chol_corr (chain, draw, noise_chol_corr_dim_0, noise_chol_corr_dim_1) float64 ... noise_chol_stds (chain, draw, noise_chol_stds_dim_0) float64 0.479... betaX (chain, draw, time, betaX_dim_1) float64 0.05801 .... noise_chol (chain, draw, noise_chol_dim_0) float64 0.4793 ...... lag_coefs (chain, draw, equations, lags, cross_vars) float64 ... Attributes: created_at: 2023-02-21T19:20:42.612680 arviz_version: 0.14.0 inference_library: pymc inference_library_version: 5.0.1xarray.Dataset -
- chain: 1
- draw: 500
- 时间: 49
- equations: 2
- chain(chain)int640
array([0])
- draw(draw)int640 1 2 3 4 5 ... 495 496 497 498 499
array([ 0, 1, 2, ..., 497, 498, 499])
- 时间(time)int642 3 4 5 6 7 8 ... 45 46 47 48 49 50
array([ 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50]) - equations(equations)<U7'dl_gdp' 'dl_cons'
array(['dl_gdp', 'dl_cons'], dtype='<U7')
- obs(chain, draw, time, equations)float640.4478 -0.1462 ... 0.2672 0.00633
array([[[[ 0.44776047, -0.14616646], [ 0.19862307, -1.56585955], [-0.49237353, 0.10341214], ..., [-0.53594629, 0.0108207 ], [-0.60594248, 1.1033946 ], [-0.29404625, -0.98134169]], [[-0.17508436, -0.39153604], [ 1.38455666, 0.46302004], [ 0.7422721 , 0.89894022], ..., [-0.34396897, 0.32617753], [-0.23282001, -0.28712153], [ 0.44837144, 0.56639172]], [[-2.87839455, -0.232425 ], [ 0.9220839 , -0.62541197], [-0.17169051, -0.02795315], ..., ... ..., [ 0.28226659, 1.30781422], [-0.06117757, -2.03648709], [-0.03451084, -0.82340422]], [[-0.1122591 , -0.0502724 ], [-1.00777064, 0.76872509], [ 1.5855008 , -1.32129034], ..., [-1.79166952, -0.68820344], [ 0.11846899, -0.78256063], [-2.06857488, -0.56486839]], [[ 0.18450661, 0.0350353 ], [ 0.20768096, 0.21245028], [ 0.29240891, 0.13727305], ..., [ 0.20834432, 0.04599256], [ 0.21634715, 0.27336735], [ 0.26716229, 0.00633042]]]])
- chainPandasIndex
PandasIndex(Int64Index([0], dtype='int64', name='chain'))
- drawPandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ... 490, 491, 492, 493, 494, 495, 496, 497, 498, 499], dtype='int64', name='draw', length=500)) - 时间PandasIndex
PandasIndex(Int64Index([ 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50], dtype='int64', name='time')) - equationsPandasIndex
PandasIndex(Index(['dl_gdp', 'dl_cons'], dtype='object', name='equations'))
- created_at
- 2023-02-21T19:20:42.614050
- arviz_version
- 0.14.0
- inference_library
- pymc
- inference_library_version
- 5.0.1
<xarray.Dataset> Dimensions: (chain: 1, draw: 500, time: 49, equations: 2) Coordinates: * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 5 6 7 ... 492 493 494 495 496 497 498 499 * time (time) int64 2 3 4 5 6 7 8 9 10 11 ... 42 43 44 45 46 47 48 49 50 * equations (equations) <U7 'dl_gdp' 'dl_cons' Data variables: obs (chain, draw, time, equations) float64 0.4478 -0.1462 ... 0.00633 Attributes: created_at: 2023-02-21T19:20:42.614050 arviz_version: 0.14.0 inference_library: pymc inference_library_version: 5.0.1xarray.Dataset -
- 时间: 49
- equations: 2
- 时间(time)int642 3 4 5 6 7 8 ... 45 46 47 48 49 50
array([ 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50]) - equations(equations)<U7'dl_gdp' 'dl_cons'
array(['dl_gdp', 'dl_cons'], dtype='<U7')
- obs(time, equations)float640.04613 0.06834 ... 0.1264 0.05461
array([[ 0.04613358, 0.06834012], [ 0.04171979, 0.03041591], [ 0.05502444, 0.02790996], [ 0.0138517 , 0.02731819], [ 0.07891562, 0.05362182], [ 0.06940226, 0.08433703], [ 0.03026764, 0.04373127], [ 0.03032869, 0.02126963], [ 0.03271127, 0.01319935], [ 0.02257787, -0.04390915], [-0.00244599, 0.00498376], [ 0.04262235, 0.01226503], [ 0.03038967, 0.03741001], [-0.0042925 , 0.02157749], [ 0.04557635, 0.01055227], [ 0.05085863, 0.01996409], [ 0.05651188, 0.04522139], [ 0.08127144, 0.02305265], [ 0.01911258, 0.01992001], [ 0.03288602, 0.02865146], ... [ 0.05728948, 0.04324766], [ 0.02965185, 0.02806114], [ 0.06565545, 0.03202102], [ 0.05577724, 0.06123691], [ 0.04860445, 0.05797527], [ 0.05169516, 0.06437874], [-0.04590363, 0.00356559], [-0.05235144, -0.04743164], [ 0.01739857, -0.01160896], [ 0.01062858, 0.00262455], [-0.00052368, -0.017138 ], [ 0.01259055, -0.00163944], [ 0.08354761, 0.02976708], [ 0.22455252, 0.02970416], [ 0.02021659, 0.04809311], [ 0.0856272 , 0.02608167], [ 0.08645437, 0.04073803], [ 0.04799944, 0.04137956], [ 0.05701317, -0.05335559], [ 0.1264446 , 0.05460824]])
- 时间PandasIndex
PandasIndex(Int64Index([ 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50], dtype='int64', name='time')) - equationsPandasIndex
PandasIndex(Index(['dl_gdp', 'dl_cons'], dtype='object', name='equations'))
- created_at
- 2023-02-21T19:20:42.614347
- arviz_version
- 0.14.0
- inference_library
- pymc
- inference_library_version
- 5.0.1
<xarray.Dataset> Dimensions: (time: 49, equations: 2) Coordinates: * time (time) int64 2 3 4 5 6 7 8 9 10 11 ... 42 43 44 45 46 47 48 49 50 * equations (equations) <U7 'dl_gdp' 'dl_cons' Data variables: obs (time, equations) float64 0.04613 0.06834 ... 0.1264 0.05461 Attributes: created_at: 2023-02-21T19:20:42.614347 arviz_version: 0.14.0 inference_library: pymc inference_library_version: 5.0.1xarray.Dataset -
- 时间: 49
- equations: 2
- 时间(time)int642 3 4 5 6 7 8 ... 45 46 47 48 49 50
array([ 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50]) - equations(equations)<U7'dl_gdp' 'dl_cons'
array(['dl_gdp', 'dl_cons'], dtype='<U7')
- data_obs(time, equations)float640.04613 0.06834 ... 0.1264 0.05461
array([[ 0.04613358, 0.06834012], [ 0.04171979, 0.03041591], [ 0.05502444, 0.02790996], [ 0.0138517 , 0.02731819], [ 0.07891562, 0.05362182], [ 0.06940226, 0.08433703], [ 0.03026764, 0.04373127], [ 0.03032869, 0.02126963], [ 0.03271127, 0.01319935], [ 0.02257787, -0.04390915], [-0.00244599, 0.00498376], [ 0.04262235, 0.01226503], [ 0.03038967, 0.03741001], [-0.0042925 , 0.02157749], [ 0.04557635, 0.01055227], [ 0.05085863, 0.01996409], [ 0.05651188, 0.04522139], [ 0.08127144, 0.02305265], [ 0.01911258, 0.01992001], [ 0.03288602, 0.02865146], ... [ 0.05728948, 0.04324766], [ 0.02965185, 0.02806114], [ 0.06565545, 0.03202102], [ 0.05577724, 0.06123691], [ 0.04860445, 0.05797527], [ 0.05169516, 0.06437874], [-0.04590363, 0.00356559], [-0.05235144, -0.04743164], [ 0.01739857, -0.01160896], [ 0.01062858, 0.00262455], [-0.00052368, -0.017138 ], [ 0.01259055, -0.00163944], [ 0.08354761, 0.02976708], [ 0.22455252, 0.02970416], [ 0.02021659, 0.04809311], [ 0.0856272 , 0.02608167], [ 0.08645437, 0.04073803], [ 0.04799944, 0.04137956], [ 0.05701317, -0.05335559], [ 0.1264446 , 0.05460824]])
- 时间PandasIndex
PandasIndex(Int64Index([ 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50], dtype='int64', name='time')) - equationsPandasIndex
PandasIndex(Index(['dl_gdp', 'dl_cons'], dtype='object', name='equations'))
- created_at
- 2023-02-21T19:20:42.614628
- arviz_version
- 0.14.0
- inference_library
- pymc
- inference_library_version
- 5.0.1
<xarray.Dataset> Dimensions: (time: 49, equations: 2) Coordinates: * time (time) int64 2 3 4 5 6 7 8 9 10 11 ... 42 43 44 45 46 47 48 49 50 * equations (equations) <U7 'dl_gdp' 'dl_cons' Data variables: data_obs (time, equations) float64 0.04613 0.06834 ... 0.1264 0.05461 Attributes: created_at: 2023-02-21T19:20:42.614628 arviz_version: 0.14.0 inference_library: pymc inference_library_version: 5.0.1xarray.Dataset
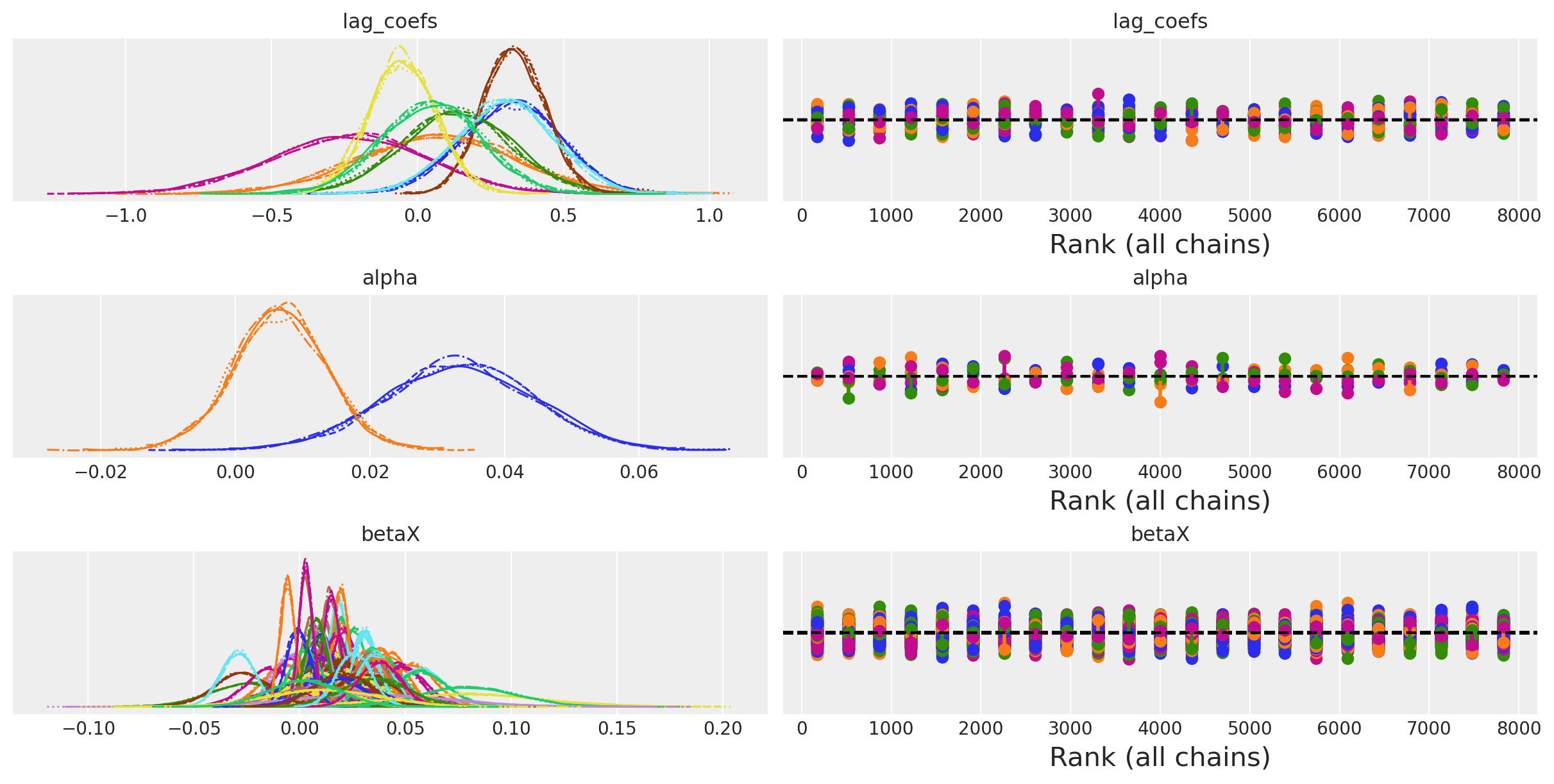
az.plot_trace(idata_ireland, var_names=["lag_coefs", "alpha", "betaX"], kind="rank_vlines");
def plot_ppc_macro(idata, df, group="posterior_predictive"):
df = pd.DataFrame(idata["observed_data"]["obs"].data, columns=["dl_gdp", "dl_cons"])
fig, axs = plt.subplots(2, 1, figsize=(20, 10))
axs = axs.flatten()
ppc = az.extract(idata, group=group, num_samples=100)["obs"]
shade_background(ppc, axs, 0, "inferno")
axs[0].plot(np.arange(ppc.shape[0]), ppc[:, 0, :].mean(axis=1), color="cyan", label="Mean")
axs[0].plot(df["dl_gdp"], "o", mfc="black", mec="white", mew=1, markersize=7, label="Observed")
axs[0].set_title("Differenced and Logged GDP")
axs[0].legend()
shade_background(ppc, axs, 1, "inferno")
axs[1].plot(df["dl_cons"], "o", mfc="black", mec="white", mew=1, markersize=7, label="Observed")
axs[1].plot(np.arange(ppc.shape[0]), ppc[:, 1, :].mean(axis=1), color="cyan", label="Mean")
axs[1].set_title("Differenced and Logged Consumption")
axs[1].legend()
plot_ppc_macro(idata_ireland, ireland_df)
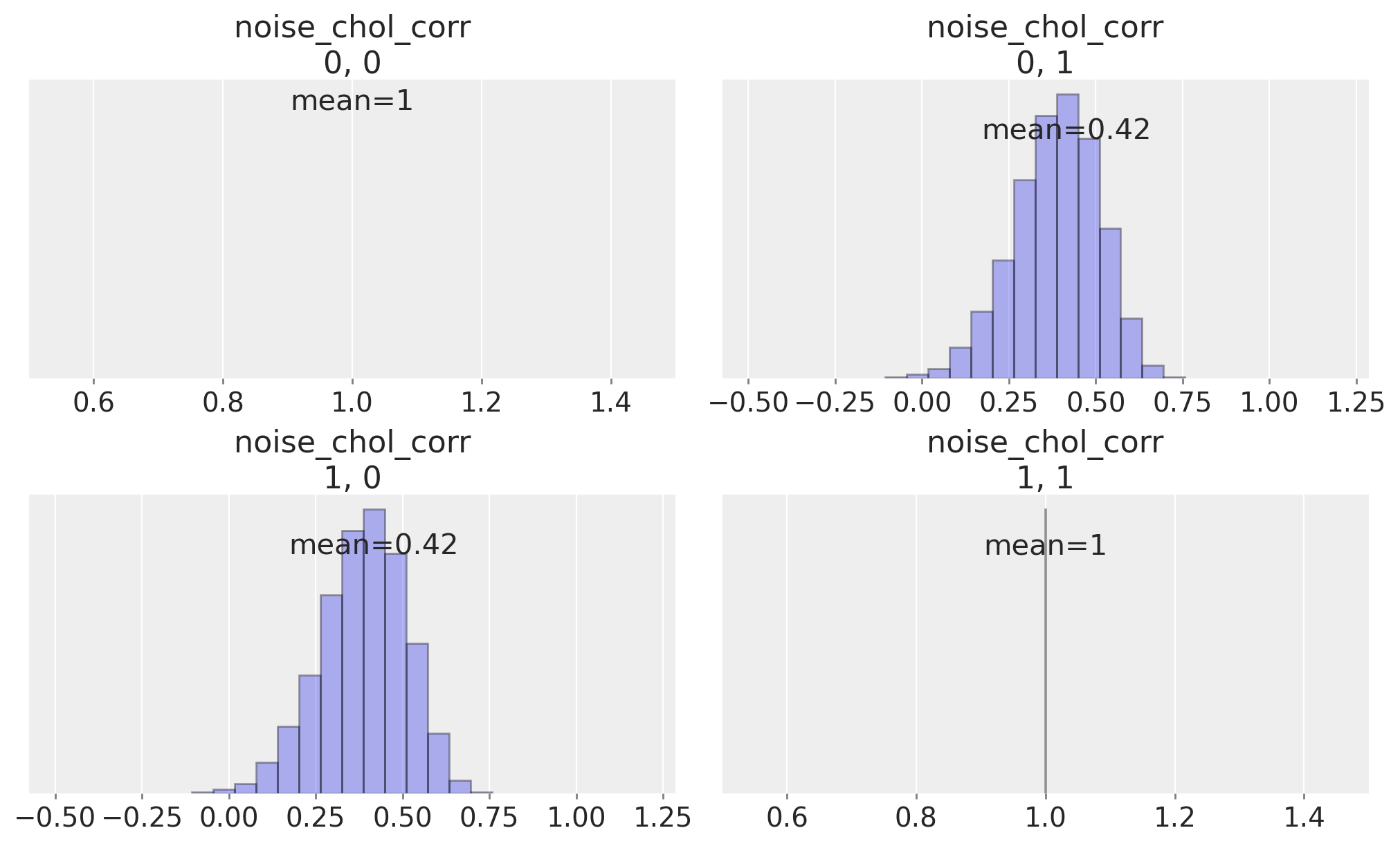
ax = az.plot_posterior(
idata_ireland,
var_names="noise_chol_corr",
hdi_prob="hide",
point_estimate="mean",
grid=(2, 2),
kind="hist",
ec="black",
figsize=(10, 6),
)
与 Statsmodels 的比较#
值得将这些模型拟合与 Statsmodels 实现的模型拟合进行比较,只是为了看看我们是否可以恢复类似的故事。
VAR_model = sm.tsa.VAR(ireland_df[["dl_gdp", "dl_cons"]])
results = VAR_model.fit(2, trend="c")
results.params
| dl_gdp | dl_cons | |
|---|---|---|
| const | 0.034145 | 0.006996 |
| L1.dl_gdp | 0.324904 | 0.330003 |
| L1.dl_cons | 0.076629 | 0.305824 |
| L2.dl_gdp | 0.137721 | -0.053677 |
| L2.dl_cons | -0.278745 | 0.033728 |
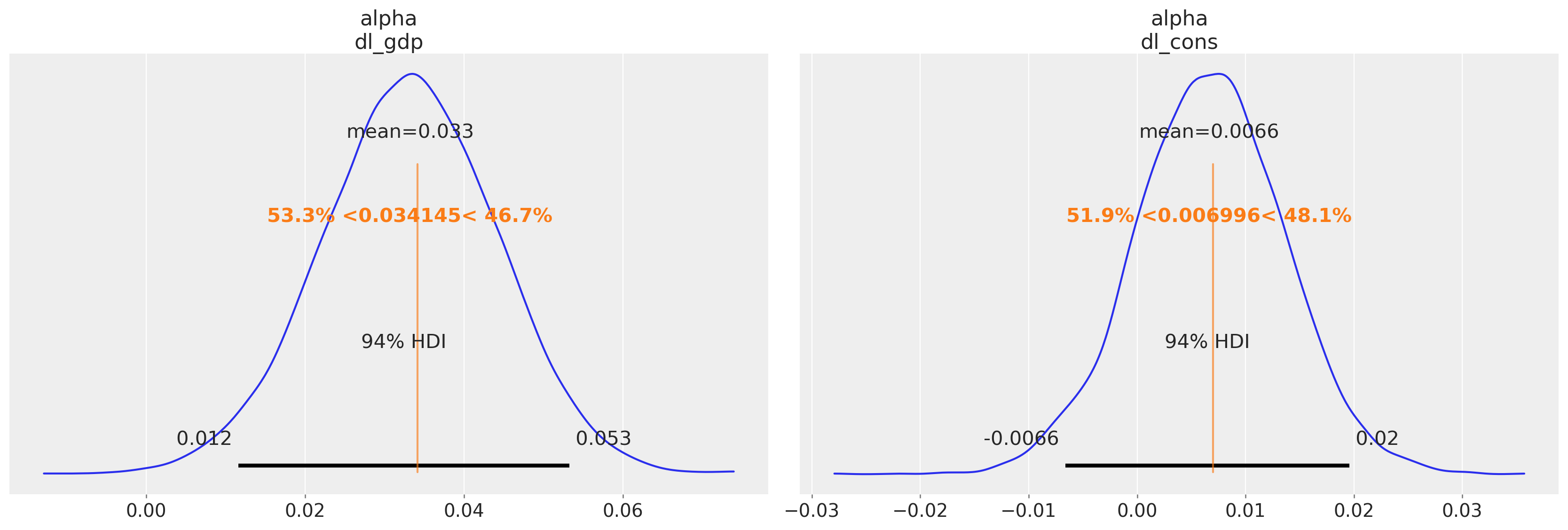
截距参数与我们的贝叶斯模型大致一致,但由滞后项的估计值定义的隐含关系存在一些差异。
corr = pd.DataFrame(results.resid_corr, columns=["dl_gdp", "dl_cons"])
corr.index = ["dl_gdp", "dl_cons"]
corr
| dl_gdp | dl_cons | |
|---|---|---|
| dl_gdp | 1.000000 | 0.435807 |
| dl_cons | 0.435807 | 1.000000 |
statsmodels 报告的残差相关性估计值与我们的贝叶斯模型中变量之间的多元高斯相关性非常吻合。
az.summary(idata_ireland, var_names=["alpha", "lag_coefs", "noise_chol_corr"])
/Users/nathanielforde/mambaforge/envs/myjlabenv/lib/python3.11/site-packages/arviz/stats/diagnostics.py:584: RuntimeWarning: invalid value encountered in scalar divide
(between_chain_variance / within_chain_variance + num_samples - 1) / (num_samples)
| 均值 | 标准差 | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| alpha[dl_gdp] | 0.033 | 0.011 | 0.012 | 0.053 | 0.000 | 0.000 | 6683.0 | 5919.0 | 1.0 |
| alpha[dl_cons] | 0.007 | 0.007 | -0.007 | 0.020 | 0.000 | 0.000 | 7651.0 | 5999.0 | 1.0 |
| lag_coefs[dl_gdp, 1, dl_gdp] | 0.321 | 0.170 | 0.008 | 0.642 | 0.002 | 0.002 | 6984.0 | 6198.0 | 1.0 |
| lag_coefs[dl_gdp, 1, dl_cons] | 0.071 | 0.273 | -0.447 | 0.582 | 0.003 | 0.003 | 7376.0 | 5466.0 | 1.0 |
| lag_coefs[dl_gdp, 2, dl_gdp] | 0.133 | 0.190 | -0.228 | 0.488 | 0.002 | 0.002 | 7471.0 | 6128.0 | 1.0 |
| lag_coefs[dl_gdp, 2, dl_cons] | -0.235 | 0.269 | -0.748 | 0.259 | 0.003 | 0.002 | 8085.0 | 5963.0 | 1.0 |
| lag_coefs[dl_cons, 1, dl_gdp] | 0.331 | 0.106 | 0.133 | 0.528 | 0.001 | 0.001 | 7670.0 | 6360.0 | 1.0 |
| lag_coefs[dl_cons, 1, dl_cons] | 0.302 | 0.170 | -0.012 | 0.616 | 0.002 | 0.001 | 7963.0 | 6150.0 | 1.0 |
| lag_coefs[dl_cons, 2, dl_gdp] | -0.054 | 0.118 | -0.279 | 0.163 | 0.001 | 0.001 | 8427.0 | 6296.0 | 1.0 |
| lag_coefs[dl_cons, 2, dl_cons] | 0.048 | 0.170 | -0.259 | 0.378 | 0.002 | 0.002 | 8669.0 | 6264.0 | 1.0 |
| noise_chol_corr[0, 0] | 1.000 | 0.000 | 1.000 | 1.000 | 0.000 | 0.000 | 8000.0 | 8000.0 | NaN |
| noise_chol_corr[0, 1] | 0.416 | 0.123 | 0.180 | 0.633 | 0.001 | 0.001 | 9155.0 | 6052.0 | 1.0 |
| noise_chol_corr[1, 0] | 0.416 | 0.123 | 0.180 | 0.633 | 0.001 | 0.001 | 9155.0 | 6052.0 | 1.0 |
| noise_chol_corr[1, 1] | 1.000 | 0.000 | 1.000 | 1.000 | 0.000 | 0.000 | 7871.0 | 8000.0 | 1.0 |
我们绘制 alpha 参数估计值与 Statsmodels 估计值的对比图
az.plot_posterior(idata_ireland, var_names=["alpha"], ref_val=[0.034145, 0.006996]);
az.plot_posterior(
idata_ireland,
var_names=["lag_coefs"],
ref_val=[0.330003, -0.053677],
coords={"equations": "dl_cons", "lags": [1, 2], "cross_vars": "dl_gdp"},
);
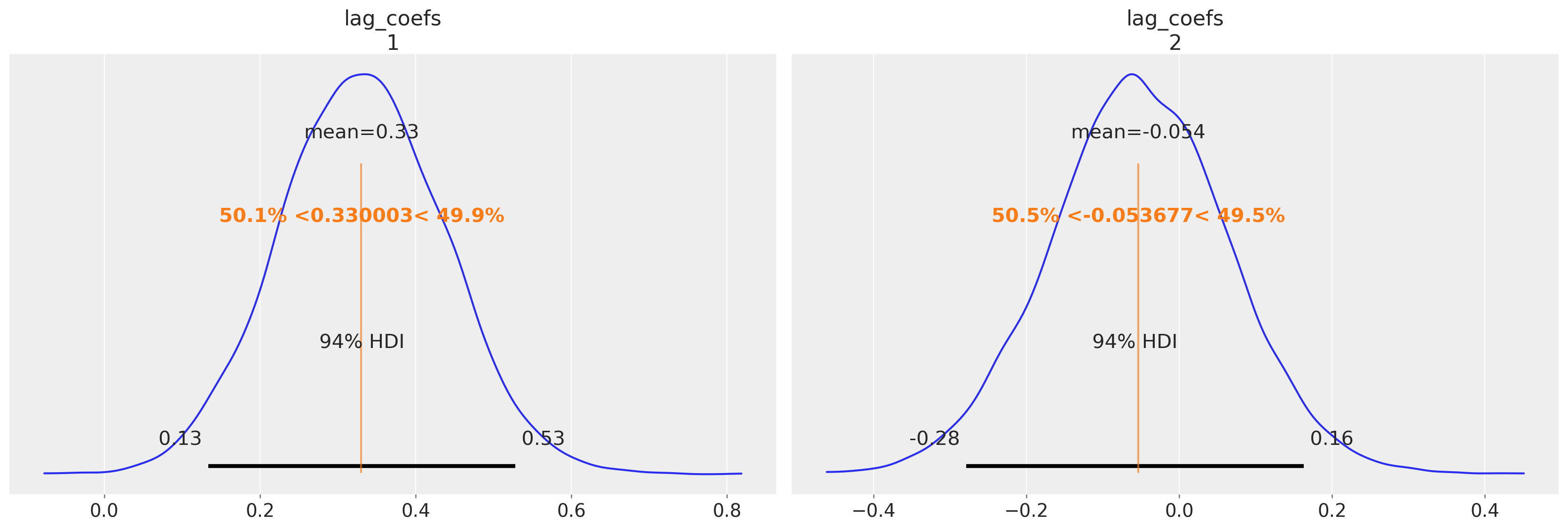
我们再次可以看到贝叶斯 VAR 模型如何恢复许多相同的故事。两个方程的 alpha 项的估计值具有相似的量级,并且第一个滞后的 GDP 数字与消费之间存在明显的关系,以及非常相似的协方差结构。
添加贝叶斯扭曲:分层 VAR#
此外,如果我们想对多个国家以及国家层面这些经济指标之间的关系进行建模,我们可以添加一些分层参数。这在我们的时间序列数据相当短的情况下是一种有用的技术,因为它允许我们“借用”跨国家的信息来告知关键参数的估计。
def make_hierarchical_model(n_lags, n_eqs, df, group_field, prior_checks=True):
cols = [col for col in df.columns if col != group_field]
coords = {"lags": np.arange(n_lags) + 1, "equations": cols, "cross_vars": cols}
groups = df[group_field].unique()
with pm.Model(coords=coords) as model:
## Hierarchical Priors
rho = pm.Beta("rho", alpha=2, beta=2)
alpha_hat_location = pm.Normal("alpha_hat_location", 0, 0.1)
alpha_hat_scale = pm.InverseGamma("alpha_hat_scale", 3, 0.5)
beta_hat_location = pm.Normal("beta_hat_location", 0, 0.1)
beta_hat_scale = pm.InverseGamma("beta_hat_scale", 3, 0.5)
omega_global, _, _ = pm.LKJCholeskyCov(
"omega_global", n=n_eqs, eta=1.0, sd_dist=pm.Exponential.dist(1)
)
for grp in groups:
df_grp = df[df[group_field] == grp][cols]
z_scale_beta = pm.InverseGamma(f"z_scale_beta_{grp}", 3, 0.5)
z_scale_alpha = pm.InverseGamma(f"z_scale_alpha_{grp}", 3, 0.5)
lag_coefs = pm.Normal(
f"lag_coefs_{grp}",
mu=beta_hat_location,
sigma=beta_hat_scale * z_scale_beta,
dims=["equations", "lags", "cross_vars"],
)
alpha = pm.Normal(
f"alpha_{grp}",
mu=alpha_hat_location,
sigma=alpha_hat_scale * z_scale_alpha,
dims=("equations",),
)
betaX = calc_ar_step(lag_coefs, n_eqs, n_lags, df_grp)
betaX = pm.Deterministic(f"betaX_{grp}", betaX)
mean = alpha + betaX
n = df_grp.shape[1]
noise_chol, _, _ = pm.LKJCholeskyCov(
f"noise_chol_{grp}", eta=10, n=n, sd_dist=pm.Exponential.dist(1)
)
omega = pm.Deterministic(f"omega_{grp}", rho * omega_global + (1 - rho) * noise_chol)
obs = pm.MvNormal(f"obs_{grp}", mu=mean, chol=omega, observed=df_grp.values[n_lags:])
if prior_checks:
idata = pm.sample_prior_predictive()
return model, idata
else:
idata = pm.sample_prior_predictive()
idata.extend(sample_blackjax_nuts(2000, random_seed=120))
pm.sample_posterior_predictive(idata, extend_inferencedata=True)
return model, idata
模型设计允许通过允许我们将特定国家的估计值从分层均值移开来非中心化关键似然的参数化,用于每个国家组成部分。这是通过 rho * omega_global + (1 - rho) * noise_chol 行完成的。参数 rho 确定每个国家的数据对经济变量之间协方差关系估计的贡献份额。类似的特定国家调整使用 z_alpha_scale 和 z_beta_scale 参数进行。
df_final = gdp_hierarchical[["country", "dl_gdp", "dl_cons", "dl_gfcf"]]
model_full_test, idata_full_test = make_hierarchical_model(
2,
3,
df_final,
"country",
prior_checks=False,
)
Sampling: [alpha_Australia, alpha_Canada, alpha_Chile, alpha_Ireland, alpha_New Zealand, alpha_South Africa, alpha_United Kingdom, alpha_United States, alpha_hat_location, alpha_hat_scale, beta_hat_location, beta_hat_scale, lag_coefs_Australia, lag_coefs_Canada, lag_coefs_Chile, lag_coefs_Ireland, lag_coefs_New Zealand, lag_coefs_South Africa, lag_coefs_United Kingdom, lag_coefs_United States, noise_chol_Australia, noise_chol_Canada, noise_chol_Chile, noise_chol_Ireland, noise_chol_New Zealand, noise_chol_South Africa, noise_chol_United Kingdom, noise_chol_United States, obs_Australia, obs_Canada, obs_Chile, obs_Ireland, obs_New Zealand, obs_South Africa, obs_United Kingdom, obs_United States, omega_global, rho, z_scale_alpha_Australia, z_scale_alpha_Canada, z_scale_alpha_Chile, z_scale_alpha_Ireland, z_scale_alpha_New Zealand, z_scale_alpha_South Africa, z_scale_alpha_United Kingdom, z_scale_alpha_United States, z_scale_beta_Australia, z_scale_beta_Canada, z_scale_beta_Chile, z_scale_beta_Ireland, z_scale_beta_New Zealand, z_scale_beta_South Africa, z_scale_beta_United Kingdom, z_scale_beta_United States]
Compiling...
Compilation time = 0:00:12.203665
Sampling...
Sampling time = 0:01:13.331452
Transforming variables...
Transformation time = 0:00:13.215405
Sampling: [obs_Australia, obs_Canada, obs_Chile, obs_Ireland, obs_New Zealand, obs_South Africa, obs_United Kingdom, obs_United States]
idata_full_test
-
- chain: 4
- draw: 2000
- equations: 3
- lags: 2
- cross_vars: 3
- omega_global_dim_0: 6
- noise_chol_Australia_dim_0: 6
- noise_chol_Canada_dim_0: 6
- noise_chol_Chile_dim_0: 6
- noise_chol_Ireland_dim_0: 6
- noise_chol_New Zealand_dim_0: 6
- noise_chol_South Africa_dim_0: 6
- noise_chol_United Kingdom_dim_0: 6
- noise_chol_United States_dim_0: 6
- omega_global_corr_dim_0: 3
- omega_global_corr_dim_1: 3
- omega_global_stds_dim_0: 3
- betaX_Australia_dim_0: 49
- betaX_Australia_dim_1: 3
- noise_chol_Australia_corr_dim_0: 3
- noise_chol_Australia_corr_dim_1: 3
- noise_chol_Australia_stds_dim_0: 3
- omega_Australia_dim_0: 3
- omega_Australia_dim_1: 3
- betaX_Canada_dim_0: 22
- betaX_Canada_dim_1: 3
- noise_chol_Canada_corr_dim_0: 3
- noise_chol_Canada_corr_dim_1: 3
- noise_chol_Canada_stds_dim_0: 3
- omega_Canada_dim_0: 3
- omega_Canada_dim_1: 3
- betaX_Chile_dim_0: 49
- betaX_Chile_dim_1: 3
- noise_chol_Chile_corr_dim_0: 3
- noise_chol_Chile_corr_dim_1: 3
- noise_chol_Chile_stds_dim_0: 3
- omega_Chile_dim_0: 3
- omega_Chile_dim_1: 3
- betaX_Ireland_dim_0: 49
- betaX_Ireland_dim_1: 3
- noise_chol_Ireland_corr_dim_0: 3
- noise_chol_Ireland_corr_dim_1: 3
- noise_chol_Ireland_stds_dim_0: 3
- omega_Ireland_dim_0: 3
- omega_Ireland_dim_1: 3
- betaX_New Zealand_dim_0: 41
- betaX_New Zealand_dim_1: 3
- noise_chol_New Zealand_corr_dim_0: 3
- noise_chol_New Zealand_corr_dim_1: 3
- noise_chol_New Zealand_stds_dim_0: 3
- omega_New Zealand_dim_0: 3
- omega_New Zealand_dim_1: 3
- betaX_South Africa_dim_0: 49
- betaX_South Africa_dim_1: 3
- noise_chol_South Africa_corr_dim_0: 3
- noise_chol_South Africa_corr_dim_1: 3
- noise_chol_South Africa_stds_dim_0: 3
- omega_South Africa_dim_0: 3
- omega_South Africa_dim_1: 3
- betaX_United Kingdom_dim_0: 49
- betaX_United Kingdom_dim_1: 3
- noise_chol_United Kingdom_corr_dim_0: 3
- noise_chol_United Kingdom_corr_dim_1: 3
- noise_chol_United Kingdom_stds_dim_0: 3
- omega_United Kingdom_dim_0: 3
- omega_United Kingdom_dim_1: 3
- betaX_United States_dim_0: 46
- betaX_United States_dim_1: 3
- noise_chol_United States_corr_dim_0: 3
- noise_chol_United States_corr_dim_1: 3
- noise_chol_United States_stds_dim_0: 3
- omega_United States_dim_0: 3
- omega_United States_dim_1: 3
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 ... 1996 1997 1998 1999
array([ 0, 1, 2, ..., 1997, 1998, 1999])
- equations(equations)<U7'dl_gdp' 'dl_cons' 'dl_gfcf'
array(['dl_gdp', 'dl_cons', 'dl_gfcf'], dtype='<U7')
- lags(lags)int641 2
array([1, 2])
- cross_vars(cross_vars)<U7'dl_gdp' 'dl_cons' 'dl_gfcf'
array(['dl_gdp', 'dl_cons', 'dl_gfcf'], dtype='<U7')
- omega_global_dim_0(omega_global_dim_0)int640 1 2 3 4 5
array([0, 1, 2, 3, 4, 5])
- noise_chol_Australia_dim_0(noise_chol_Australia_dim_0)int640 1 2 3 4 5
array([0, 1, 2, 3, 4, 5])
- noise_chol_Canada_dim_0(noise_chol_Canada_dim_0)int640 1 2 3 4 5
array([0, 1, 2, 3, 4, 5])
- noise_chol_Chile_dim_0(noise_chol_Chile_dim_0)int640 1 2 3 4 5
array([0, 1, 2, 3, 4, 5])
- noise_chol_Ireland_dim_0(noise_chol_Ireland_dim_0)int640 1 2 3 4 5
array([0, 1, 2, 3, 4, 5])
- noise_chol_New Zealand_dim_0(noise_chol_New Zealand_dim_0)int640 1 2 3 4 5
array([0, 1, 2, 3, 4, 5])
- noise_chol_South Africa_dim_0(noise_chol_South Africa_dim_0)int640 1 2 3 4 5
array([0, 1, 2, 3, 4, 5])
- noise_chol_United Kingdom_dim_0(noise_chol_United Kingdom_dim_0)int640 1 2 3 4 5
array([0, 1, 2, 3, 4, 5])
- noise_chol_United States_dim_0(noise_chol_United States_dim_0)int640 1 2 3 4 5
array([0, 1, 2, 3, 4, 5])
- omega_global_corr_dim_0(omega_global_corr_dim_0)int640 1 2
array([0, 1, 2])
- omega_global_corr_dim_1(omega_global_corr_dim_1)int640 1 2
array([0, 1, 2])
- omega_global_stds_dim_0(omega_global_stds_dim_0)int640 1 2
array([0, 1, 2])
- betaX_Australia_dim_0(betaX_Australia_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - betaX_Australia_dim_1(betaX_Australia_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_Australia_corr_dim_0(noise_chol_Australia_corr_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_Australia_corr_dim_1(noise_chol_Australia_corr_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_Australia_stds_dim_0(noise_chol_Australia_stds_dim_0)int640 1 2
array([0, 1, 2])
- omega_Australia_dim_0(omega_Australia_dim_0)int640 1 2
array([0, 1, 2])
- omega_Australia_dim_1(omega_Australia_dim_1)int640 1 2
array([0, 1, 2])
- betaX_Canada_dim_0(betaX_Canada_dim_0)int640 1 2 3 4 5 6 ... 16 17 18 19 20 21
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21]) - betaX_Canada_dim_1(betaX_Canada_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_Canada_corr_dim_0(noise_chol_Canada_corr_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_Canada_corr_dim_1(noise_chol_Canada_corr_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_Canada_stds_dim_0(noise_chol_Canada_stds_dim_0)int640 1 2
array([0, 1, 2])
- omega_Canada_dim_0(omega_Canada_dim_0)int640 1 2
array([0, 1, 2])
- omega_Canada_dim_1(omega_Canada_dim_1)int640 1 2
array([0, 1, 2])
- betaX_Chile_dim_0(betaX_Chile_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - betaX_Chile_dim_1(betaX_Chile_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_Chile_corr_dim_0(noise_chol_Chile_corr_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_Chile_corr_dim_1(noise_chol_Chile_corr_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_Chile_stds_dim_0(noise_chol_Chile_stds_dim_0)int640 1 2
array([0, 1, 2])
- omega_Chile_dim_0(omega_Chile_dim_0)int640 1 2
array([0, 1, 2])
- omega_Chile_dim_1(omega_Chile_dim_1)int640 1 2
array([0, 1, 2])
- betaX_Ireland_dim_0(betaX_Ireland_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - betaX_Ireland_dim_1(betaX_Ireland_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_Ireland_corr_dim_0(noise_chol_Ireland_corr_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_Ireland_corr_dim_1(noise_chol_Ireland_corr_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_Ireland_stds_dim_0(noise_chol_Ireland_stds_dim_0)int640 1 2
array([0, 1, 2])
- omega_Ireland_dim_0(omega_Ireland_dim_0)int640 1 2
array([0, 1, 2])
- omega_Ireland_dim_1(omega_Ireland_dim_1)int640 1 2
array([0, 1, 2])
- betaX_New Zealand_dim_0(betaX_New Zealand_dim_0)int640 1 2 3 4 5 6 ... 35 36 37 38 39 40
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40]) - betaX_New Zealand_dim_1(betaX_New Zealand_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_New Zealand_corr_dim_0(noise_chol_New Zealand_corr_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_New Zealand_corr_dim_1(noise_chol_New Zealand_corr_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_New Zealand_stds_dim_0(noise_chol_New Zealand_stds_dim_0)int640 1 2
array([0, 1, 2])
- omega_New Zealand_dim_0(omega_New Zealand_dim_0)int640 1 2
array([0, 1, 2])
- omega_New Zealand_dim_1(omega_New Zealand_dim_1)int640 1 2
array([0, 1, 2])
- betaX_South Africa_dim_0(betaX_South Africa_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - betaX_South Africa_dim_1(betaX_South Africa_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_South Africa_corr_dim_0(noise_chol_South Africa_corr_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_South Africa_corr_dim_1(noise_chol_South Africa_corr_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_South Africa_stds_dim_0(noise_chol_South Africa_stds_dim_0)int640 1 2
array([0, 1, 2])
- omega_South Africa_dim_0(omega_South Africa_dim_0)int640 1 2
array([0, 1, 2])
- omega_South Africa_dim_1(omega_South Africa_dim_1)int640 1 2
array([0, 1, 2])
- betaX_United Kingdom_dim_0(betaX_United Kingdom_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - betaX_United Kingdom_dim_1(betaX_United Kingdom_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_United Kingdom_corr_dim_0(noise_chol_United Kingdom_corr_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_United Kingdom_corr_dim_1(noise_chol_United Kingdom_corr_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_United Kingdom_stds_dim_0(noise_chol_United Kingdom_stds_dim_0)int640 1 2
array([0, 1, 2])
- omega_United Kingdom_dim_0(omega_United Kingdom_dim_0)int640 1 2
array([0, 1, 2])
- omega_United Kingdom_dim_1(omega_United Kingdom_dim_1)int640 1 2
array([0, 1, 2])
- betaX_United States_dim_0(betaX_United States_dim_0)int640 1 2 3 4 5 6 ... 40 41 42 43 44 45
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45]) - betaX_United States_dim_1(betaX_United States_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_United States_corr_dim_0(noise_chol_United States_corr_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_United States_corr_dim_1(noise_chol_United States_corr_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_United States_stds_dim_0(noise_chol_United States_stds_dim_0)int640 1 2
array([0, 1, 2])
- omega_United States_dim_0(omega_United States_dim_0)int640 1 2
array([0, 1, 2])
- omega_United States_dim_1(omega_United States_dim_1)int640 1 2
array([0, 1, 2])
- alpha_hat_location(chain, draw)float640.01867 0.02452 ... 0.02525 0.02439
array([[0.0186718 , 0.02451757, 0.02175917, ..., 0.02313991, 0.02264565, 0.02262757], [0.02194229, 0.01975299, 0.01973764, ..., 0.02332028, 0.02396733, 0.02430533], [0.02017885, 0.02004322, 0.01743769, ..., 0.02143034, 0.0220604 , 0.02622348], [0.01845575, 0.02208645, 0.01699277, ..., 0.02487232, 0.02524865, 0.02439422]]) - beta_hat_location(chain, draw)float640.03707 0.03328 ... 0.01597 0.02013
array([[0.03707199, 0.03328202, 0.03327573, ..., 0.02022314, 0.01849649, 0.02157836], [0.02625807, 0.03075176, 0.03222849, ..., 0.02858588, 0.01833262, 0.0215363 ], [0.03578886, 0.03454472, 0.03803878, ..., 0.02762439, 0.0293772 , 0.0225766 ], [0.02942673, 0.03678047, 0.03405673, ..., 0.02473977, 0.01597052, 0.0201329 ]]) - lag_coefs_Australia(chain, draw, equations, lags, cross_vars)float640.03359 0.02897 ... -0.04637
array([[[[[ 3.35876842e-02, 2.89656460e-02, 1.44346827e-02], [ 8.37580972e-02, 3.24134878e-02, -2.82482944e-02]], [[ 7.26090826e-02, -2.13751601e-02, 4.48405788e-02], [-8.62745446e-03, 6.50512197e-02, 3.53772829e-02]], [[ 1.33485138e-01, -1.01438292e-02, -3.84827532e-02], [ 8.71983706e-02, 4.94076769e-02, 1.65164026e-02]]], [[[-1.49945684e-02, 1.26595954e-01, 1.85231803e-02], [ 8.36634775e-02, -2.39762157e-02, -4.01462709e-02]], [[ 4.48792564e-03, 8.64514159e-02, 4.15399598e-02], [ 4.96201513e-02, 4.76304546e-02, -4.78025294e-03]], [[ 3.01187469e-02, 3.96725859e-03, 5.16570055e-02], [ 5.89717588e-02, 1.02783667e-01, -5.68183027e-02]]], ... [[[-6.09370080e-04, -4.28833919e-02, -1.72132262e-02], [ 8.35965353e-03, 4.55781405e-02, -2.42132324e-02]], [[ 4.88764274e-02, 6.16764673e-02, 1.71383871e-02], [ 3.83475664e-02, 6.11454731e-02, 1.19527231e-02]], [[-8.09687797e-02, 8.17902158e-03, -5.25417172e-03], [ 2.41407964e-02, 3.25160033e-03, -2.44207844e-02]]], [[[ 2.05738963e-02, -1.11911043e-02, -2.76806626e-02], [ 3.84035145e-02, 7.34061297e-02, 2.56814253e-02]], [[ 4.87554839e-02, 2.48335988e-02, -7.74723598e-03], [ 5.52062580e-02, 6.27619815e-02, 1.48180294e-03]], [[-8.57767638e-02, -5.80385978e-03, 3.99498228e-02], [ 1.82907424e-02, 5.53130978e-02, -4.63726851e-02]]]]]) - alpha_Australia(chain, draw, equations)float640.02263 0.02195 ... 0.0256 0.04313
array([[[0.02263033, 0.0219483 , 0.02278174], [0.02092655, 0.02117198, 0.01957458], [0.02471809, 0.02338723, 0.02126247], ..., [0.02733054, 0.02529274, 0.02926754], [0.0229278 , 0.02485852, 0.02744026], [0.02545857, 0.024065 , 0.02478534]], [[0.02535366, 0.02349025, 0.0258179 ], [0.02633209, 0.02612907, 0.02978084], [0.02298526, 0.02043026, 0.02110987], ..., [0.02911641, 0.01716411, 0.02245609], [0.02612856, 0.02059014, 0.02068046], [0.0288257 , 0.02033768, 0.02226378]], [[0.02258029, 0.02479371, 0.03093723], [0.0258095 , 0.02523357, 0.02888035], [0.02555444, 0.02835614, 0.02272297], ..., [0.02168698, 0.02232613, 0.02013229], [0.02085286, 0.02223427, 0.02259567], [0.02968412, 0.02811583, 0.03453368]], [[0.02283776, 0.02056642, 0.020418 ], [0.02121562, 0.02447455, 0.01693719], [0.01891216, 0.01366135, 0.01818819], ..., [0.03010412, 0.02400799, 0.03880659], [0.03082631, 0.02208602, 0.0357919 ], [0.02795351, 0.02560223, 0.04313025]]]) - lag_coefs_Canada(chain, draw, equations, lags, cross_vars)float640.07658 0.1244 ... 0.05222
array([[[[[ 7.65771654e-02, 1.24359779e-01, 4.76910322e-02], [ 2.93667122e-02, 3.72310073e-02, 3.49173993e-02]], [[ 4.41347272e-02, 8.81811011e-03, -3.05038254e-04], [ 4.78927391e-02, -4.02214926e-03, 8.59285906e-03]], [[ 5.10979503e-02, 6.56671799e-02, -6.60947485e-02], [-6.07279826e-03, 4.58702563e-03, 7.23134454e-02]]], [[[ 9.58053837e-03, -3.61069775e-02, 6.42945320e-02], [ 3.85629973e-02, 3.81227043e-02, 3.71742576e-02]], [[ 1.99385509e-02, 6.05511924e-02, 4.11373442e-02], [ 4.40550718e-02, 8.55328657e-02, 5.53053572e-02]], [[ 1.73913842e-02, 3.34697407e-02, 1.16211321e-01], [ 6.83408791e-02, 4.04932208e-02, -4.08216894e-03]]], ... [[[ 1.60683243e-02, 2.61087715e-02, 3.92718077e-02], [ 4.01146237e-03, -2.37060312e-02, -4.62161483e-02]], [[ 1.56423894e-02, -4.50955622e-02, 3.51574636e-02], [ 5.25022469e-02, 1.23002896e-01, -8.16030734e-03]], [[ 7.57467809e-02, -2.31002172e-02, 5.49980542e-03], [ 9.01656608e-02, 3.48274765e-02, -2.31388941e-02]]], [[[-3.26630109e-02, 8.19079238e-02, 4.89127987e-02], [ 4.26865954e-02, 7.20299244e-03, 4.26620550e-04]], [[-2.17148943e-02, 1.58301049e-02, 1.81258805e-02], [-9.93058176e-03, 6.71043977e-02, -2.33663183e-02]], [[ 4.33928770e-02, 8.33936906e-02, -3.14980137e-02], [ 2.91290443e-02, -4.29921752e-03, 5.22202592e-02]]]]]) - alpha_Canada(chain, draw, equations)float640.01466 0.0211 ... 0.02472 0.01323
array([[[0.01465676, 0.02109877, 0.01855721], [0.02272014, 0.0171131 , 0.01590168], [0.01971124, 0.02032568, 0.02398538], ..., [0.02450623, 0.02726242, 0.02387 ], [0.01963401, 0.01932964, 0.02593143], [0.02264207, 0.02528133, 0.02215 ]], [[0.01932912, 0.01498189, 0.01999218], [0.01633058, 0.01809994, 0.01882801], [0.02273562, 0.02245996, 0.02561266], ..., [0.02284951, 0.02029153, 0.01529943], [0.02505905, 0.01790449, 0.015711 ], [0.02211575, 0.0200038 , 0.01910552]], [[0.02052051, 0.01468323, 0.01967417], [0.02064814, 0.02049906, 0.01690491], [0.0180907 , 0.01218556, 0.02297644], ..., [0.0162916 , 0.01964002, 0.02564671], [0.01835867, 0.01888253, 0.02585724], [0.02651413, 0.02532478, 0.02536538]], [[0.01227525, 0.00859114, 0.01227358], [0.01348817, 0.02417696, 0.0088522 ], [0.02154709, 0.01892863, 0.01997271], ..., [0.0095156 , 0.01107229, 0.01655292], [0.0125203 , 0.01218851, 0.01862845], [0.02285449, 0.02472482, 0.01322827]]]) - lag_coefs_Chile(chain, draw, equations, lags, cross_vars)float640.02434 0.07542 ... 0.0781 0.01202
array([[[[[ 0.02433804, 0.07542013, 0.02079627], [ 0.02467259, 0.00924671, 0.03645728]], [[ 0.11158481, -0.00292094, -0.00202375], [ 0.04498318, 0.03563335, 0.05439888]], [[-0.01269364, 0.08447966, 0.1345423 ], [ 0.02703151, 0.10369712, 0.03123074]]], [[[ 0.0400249 , 0.00464353, -0.00628709], [ 0.0246438 , -0.00507188, 0.07052514]], [[-0.00183431, 0.09928378, 0.03237165], [-0.01362285, -0.00625419, 0.11892922]], [[ 0.18241235, -0.03177573, -0.07682694], [-0.00521849, 0.05234479, -0.00809534]]], ... [[[-0.01113938, 0.0019725 , 0.03888019], [-0.0062262 , -0.00483893, 0.04046326]], [[ 0.00299654, 0.01747632, 0.03686241], [ 0.02648647, 0.04897884, 0.06965917]], [[-0.0606741 , 0.03266535, 0.03051538], [-0.00779615, -0.04198754, 0.02741326]]], [[[-0.05763529, 0.04684115, 0.05842114], [ 0.06032375, -0.01520761, 0.00817284]], [[ 0.05147328, 0.02202345, 0.03813707], [ 0.03425661, -0.04428136, 0.06632278]], [[-0.03186269, 0.02367396, 0.05876045], [ 0.04699741, 0.07809989, 0.01201971]]]]]) - alpha_Chile(chain, draw, equations)float640.01571 0.02137 ... 0.02319 0.01586
array([[[0.0157132 , 0.02136831, 0.02045335], [0.02351699, 0.02662639, 0.03141462], [0.03286153, 0.02286942, 0.03075199], ..., [0.02658816, 0.03269706, 0.02478334], [0.02555073, 0.01428823, 0.02046823], [0.02267686, 0.03051695, 0.02624876]], [[0.03034501, 0.02961176, 0.03364585], [0.02170808, 0.02056791, 0.01763461], [0.03020966, 0.01999711, 0.02384438], ..., [0.02466762, 0.02259074, 0.02228189], [0.02398052, 0.02372222, 0.02535443], [0.02796878, 0.02258504, 0.03085559]], [[0.01955303, 0.02566435, 0.02335706], [0.02350364, 0.02081194, 0.02000074], [0.02316185, 0.02513018, 0.02467213], ..., [0.02045066, 0.02412166, 0.0248603 ], [0.02073028, 0.02140164, 0.02252704], [0.030537 , 0.03115226, 0.04309932]], [[0.01399888, 0.02231359, 0.01948238], [0.03077856, 0.01536788, 0.03785173], [0.02841149, 0.03715862, 0.04349375], ..., [0.02193738, 0.0220144 , 0.02608079], [0.02520517, 0.01965012, 0.02631976], [0.02767934, 0.02319005, 0.0158585 ]]]) - lag_coefs_Ireland(chain, draw, equations, lags, cross_vars)float64-0.01475 0.0387 ... 0.08891 -0.0483
array([[[[[-1.47458909e-02, 3.87000770e-02, 7.32095142e-02], [ 5.44968014e-02, 6.13786029e-02, 6.07706896e-02]], [[ 7.11516666e-02, 6.17419700e-02, 3.69797323e-02], [-2.28057433e-02, 2.31310597e-02, 7.40369221e-02]], [[ 4.21034377e-02, 8.53380497e-02, 2.10043775e-02], [ 6.44045030e-02, 2.85718044e-02, 4.66844083e-02]]], [[[-3.66079960e-02, -6.99503410e-02, 3.55270626e-02], [ 4.47186220e-02, 5.66331099e-02, 8.58598582e-02]], [[ 1.32912956e-01, 9.57010562e-02, -5.63016658e-02], [-2.51360288e-02, 5.79225409e-02, 6.21822960e-02]], [[ 4.97219669e-02, 1.14537321e-01, 1.07593179e-01], [ 7.35308871e-02, 2.34267153e-02, 2.96861721e-02]]], ... [[[-8.84380474e-02, -8.42599965e-02, 4.61872283e-02], [ 2.79902469e-02, -1.40869522e-02, 8.25633877e-02]], [[ 6.87530181e-02, 1.31929462e-01, -4.16510214e-02], [ 3.93040561e-02, 6.10045570e-02, 6.75494335e-02]], [[ 8.75675887e-02, 4.11261218e-02, -1.24124758e-02], [ 3.07071749e-02, 7.66659495e-02, -5.93595914e-02]]], [[[-1.74323530e-02, -3.22370525e-02, 4.50600308e-02], [-3.68440838e-02, -3.93261936e-02, 1.16347198e-01]], [[ 1.76288211e-01, 8.77909100e-02, -4.35165182e-02], [-8.67491049e-03, 7.67305270e-02, 1.00445039e-01]], [[-1.64839671e-02, -6.10096604e-02, -3.32595903e-03], [-1.71668080e-02, 8.89058437e-02, -4.82995669e-02]]]]]) - alpha_Ireland(chain, draw, equations)float640.02198 0.01418 ... 0.01683 0.02614
array([[[ 0.02198322, 0.01418345, 0.02419023], [ 0.03777364, 0.01957305, 0.007676 ], [ 0.03905588, 0.00898405, 0.02174625], ..., [ 0.03748313, 0.00654185, 0.03192922], [ 0.04685017, 0.01413632, 0.01609315], [ 0.04041201, 0.00862381, 0.04599709]], [[ 0.03520116, 0.00864943, 0.00656473], [ 0.03829489, 0.00718548, 0.03974323], [ 0.02576244, 0.01144094, 0.0282918 ], ..., [ 0.0432292 , 0.01897203, 0.02735446], [ 0.04027758, 0.015737 , 0.02289279], [ 0.03741163, 0.01368131, 0.0235036 ]], [[ 0.03536222, 0.00628412, 0.02729948], [ 0.03195189, 0.00413109, 0.02516136], [ 0.03224617, -0.00497087, 0.01715696], ..., [ 0.0236229 , 0.01416163, 0.0175816 ], [ 0.02379884, 0.01203721, 0.01973875], [ 0.03983179, 0.02813402, 0.01942888]], [[ 0.03169915, 0.01435424, 0.00716936], [ 0.02786021, 0.0175066 , 0.02303785], [ 0.02952215, 0.0132017 , 0.01848463], ..., [ 0.04300775, 0.01253962, 0.04658183], [ 0.0444028 , 0.01022499, 0.04403121], [ 0.04460278, 0.01682959, 0.02614388]]]) - lag_coefs_New Zealand(chain, draw, equations, lags, cross_vars)float640.0048 0.05318 ... 0.04656 -0.0277
array([[[[[ 4.79955216e-03, 5.31766056e-02, 2.48001324e-02], [ 5.58142948e-02, 1.47251580e-02, 1.04404015e-02]], [[ 3.81839725e-02, 7.30885639e-02, 1.76983648e-02], [ 5.93599488e-02, 1.11361964e-01, 4.43170275e-02]], [[ 6.40167465e-02, 1.36748394e-03, 1.17405811e-02], [ 5.95082083e-02, 7.40553746e-02, 3.81552533e-02]]], [[[ 8.78219915e-02, -6.00073761e-03, 4.07609942e-02], [ 2.35031517e-02, 7.66114780e-03, -1.93500127e-02]], [[ 2.80442830e-02, 6.12851857e-02, 3.56544049e-02], [ 5.68764616e-02, 2.83996406e-02, 2.45822496e-02]], [[ 3.56649231e-02, 5.96405911e-02, 8.16509026e-02], [ 2.51308596e-02, 1.76106189e-02, 1.55734961e-02]]], ... [[[ 6.08300123e-02, 5.40027130e-03, 2.18290830e-02], [-1.47997178e-02, -3.39122149e-02, 2.20944587e-03]], [[ 5.50643240e-02, 1.45434541e-02, 1.25605541e-02], [ 4.65713980e-02, 7.46702282e-02, 4.67125897e-02]], [[ 3.57338813e-02, -5.94263736e-03, 4.39900990e-02], [ 3.32299355e-02, 2.50841926e-03, -3.00312747e-02]]], [[[ 1.00552259e-02, 4.50610550e-02, 7.41251774e-03], [ 3.41258860e-02, -5.06182746e-02, -1.04310654e-02]], [[ 5.72570423e-02, -3.84271622e-02, -1.19819215e-02], [ 3.52150287e-02, 9.21245461e-02, 2.60604335e-02]], [[-2.53743801e-02, -1.13646205e-02, 1.13368406e-02], [-2.90074466e-02, 4.65603013e-02, -2.77021942e-02]]]]]) - alpha_New Zealand(chain, draw, equations)float640.01807 0.01578 ... 0.01983 0.03992
array([[[0.01806595, 0.01578354, 0.02132896], [0.01849362, 0.01821667, 0.02721401], [0.02175469, 0.0210865 , 0.03053284], ..., [0.02166377, 0.02133174, 0.02287388], [0.02227288, 0.02121135, 0.04353785], [0.02431044, 0.02571715, 0.03797068]], [[0.01357315, 0.01525364, 0.03253792], [0.02149012, 0.01032409, 0.04364514], [0.01709379, 0.00976669, 0.01623808], ..., [0.01432591, 0.01743779, 0.018122 ], [0.01355899, 0.01595626, 0.0193063 ], [0.01456813, 0.02003352, 0.01938244]], [[0.01530257, 0.01052001, 0.01589447], [0.01779147, 0.01416527, 0.03140318], [0.01520138, 0.02154654, 0.01620615], ..., [0.02688245, 0.02381044, 0.02911095], [0.02494411, 0.02434003, 0.02838573], [0.01827265, 0.01760944, 0.02858284]], [[0.02083092, 0.01857572, 0.03654796], [0.0173904 , 0.01745286, 0.02767121], [0.01518223, 0.01778471, 0.01862866], ..., [0.02430962, 0.02117357, 0.027361 ], [0.02282666, 0.02391651, 0.03463807], [0.0229253 , 0.01982705, 0.03992305]]]) - lag_coefs_South Africa(chain, draw, equations, lags, cross_vars)float640.02541 0.0323 ... 0.03994 0.04386
array([[[[[ 2.54095143e-02, 3.22996821e-02, -3.78097958e-02], [ 3.30784901e-02, 3.32517969e-02, 2.43080368e-02]], [[-9.86439293e-02, 4.45366969e-02, -6.30080609e-05], [ 8.70273005e-02, 5.25125138e-02, 4.04114465e-02]], [[ 9.69363170e-02, 2.63073323e-01, 6.80924159e-02], [ 3.98254154e-02, -5.09993065e-03, 1.62231177e-02]]], [[[ 9.36984734e-03, -2.09374358e-03, 6.01439063e-02], [-7.98620343e-03, -6.73846794e-03, -3.22391351e-02]], [[ 9.86833948e-02, 6.64104290e-02, -2.58380556e-02], [ 9.64834973e-02, 2.63595052e-02, -2.52072028e-03]], [[ 3.62143695e-02, -4.25291141e-02, 7.39053616e-02], [ 1.87797137e-02, 3.77284890e-02, 4.37549702e-03]]], ... [[[ 2.64687906e-02, 3.02834530e-02, -4.36897775e-02], [ 3.48406493e-02, 1.82883799e-02, 2.12566437e-02]], [[ 3.54839360e-03, 5.47190827e-02, -3.93874975e-02], [ 7.21056725e-02, 2.29115900e-02, 1.35507151e-02]], [[ 4.50271670e-02, 5.52450887e-02, 1.01087607e-01], [ 3.18211228e-02, 2.47540401e-02, 5.77444944e-03]]], [[[-2.76738599e-02, 8.16627740e-04, -4.45258332e-02], [ 7.58972502e-02, 1.59472376e-02, 1.02064434e-02]], [[ 4.77160550e-03, 1.77943203e-02, -3.34288369e-02], [ 1.34368769e-02, 1.81799799e-02, 6.96008594e-02]], [[ 1.21946612e-02, 1.53324684e-02, 3.92778531e-03], [-5.05276037e-02, 3.99390702e-02, 4.38554698e-02]]]]]) - alpha_South Africa(chain, draw, equations)float640.01901 0.02268 ... 0.02615 0.01921
array([[[0.01901206, 0.02267808, 0.01252531], [0.02365439, 0.02239854, 0.01985251], [0.01989679, 0.0220024 , 0.02289861], ..., [0.02342958, 0.02782862, 0.0204841 ], [0.01941431, 0.02520382, 0.02561481], [0.01896969, 0.02357623, 0.00824644]], [[0.01886008, 0.01832178, 0.01410036], [0.02367257, 0.02362778, 0.01416356], [0.0225035 , 0.02658002, 0.00968991], ..., [0.02055409, 0.02657549, 0.02245432], [0.02386924, 0.02856589, 0.02115162], [0.02554601, 0.02735204, 0.01862188]], [[0.02579471, 0.02669597, 0.01457212], [0.02038627, 0.02124575, 0.01988502], [0.01889323, 0.02108477, 0.01104016], ..., [0.01864664, 0.02434247, 0.01947247], [0.01867105, 0.02427485, 0.01796539], [0.02647408, 0.02692301, 0.02550011]], [[0.02029671, 0.01952457, 0.01701635], [0.02484205, 0.0302312 , 0.01765515], [0.01887883, 0.01832262, 0.01998897], ..., [0.02211716, 0.0234445 , 0.01737949], [0.02049095, 0.02449048, 0.01372325], [0.01958324, 0.02615177, 0.0192084 ]]]) - lag_coefs_United Kingdom(chain, draw, equations, lags, cross_vars)float640.05761 0.0274 ... -0.001775
array([[[[[ 0.05761089, 0.0274021 , 0.06190151], [ 0.0303106 , 0.02267695, 0.022874 ]], [[ 0.06043142, 0.03478302, 0.04597842], [ 0.07937197, -0.00305529, 0.03926115]], [[ 0.03332199, 0.0388056 , 0.07837689], [ 0.06736559, 0.05133304, 0.01535437]]], [[[ 0.07256452, 0.03193285, 0.02712607], [-0.02385231, -0.00268805, 0.02936621]], [[ 0.02799926, 0.01307594, 0.00886335], [ 0.08689927, 0.05372776, 0.0417348 ]], [[ 0.02188457, 0.07145874, 0.00491692], [-0.01293862, 0.00302327, 0.08443964]]], ... [[[-0.03540654, 0.03918698, -0.0236554 ], [ 0.0313792 , 0.00023517, -0.04371644]], [[-0.02134802, 0.01079886, 0.01746537], [-0.00471261, 0.01925858, 0.01601016]], [[ 0.01603853, 0.05085501, 0.0145626 ], [ 0.02313931, 0.01217526, 0.0396992 ]]], [[[-0.00831721, 0.03572049, 0.00071403], [ 0.05066002, -0.02539158, -0.04745072]], [[-0.02264026, -0.02155469, 0.0228943 ], [ 0.06722884, 0.06794606, 0.0012824 ]], [[ 0.04053666, -0.02507347, 0.00704099], [ 0.04290297, 0.03121881, -0.00177492]]]]]) - alpha_United Kingdom(chain, draw, equations)float640.01761 0.0174 ... 0.02397 0.03081
array([[[0.01761044, 0.0173951 , 0.02129423], [0.0176642 , 0.01433993, 0.01677042], [0.02329868, 0.01875666, 0.02059026], ..., [0.01786654, 0.01739791, 0.01644063], [0.02238243, 0.02049453, 0.02055928], [0.02340852, 0.02267508, 0.02877013]], [[0.02386716, 0.02211543, 0.02609062], [0.02504201, 0.02045074, 0.02446627], [0.02175407, 0.01676955, 0.01927967], ..., [0.01627474, 0.01657221, 0.01809339], [0.01732528, 0.01775757, 0.02601687], [0.01766491, 0.0168034 , 0.02148137]], [[0.01928886, 0.0196265 , 0.02452796], [0.01989401, 0.01935756, 0.02009702], [0.01772464, 0.01579172, 0.01717696], ..., [0.02173498, 0.01841189, 0.01904664], [0.02109208, 0.01908113, 0.01839193], [0.02285666, 0.01746688, 0.0264231 ]], [[0.01553938, 0.01546997, 0.01883268], [0.02013144, 0.01803673, 0.02642818], [0.01576727, 0.0137904 , 0.01420119], ..., [0.02646206, 0.02333062, 0.03159167], [0.02633969, 0.0241074 , 0.03232729], [0.02580901, 0.02397482, 0.03080724]]]) - lag_coefs_United States(chain, draw, equations, lags, cross_vars)float640.05386 0.07003 ... 0.0723 0.004706
array([[[[[ 0.05385766, 0.07003283, -0.01949482], [ 0.00329857, 0.09423554, 0.07803958]], [[ 0.06490934, 0.07647176, 0.05103275], [ 0.08451833, -0.0374088 , 0.04119398]], [[ 0.05504028, -0.02860814, 0.13109432], [-0.00247949, 0.05276195, 0.06957375]]], [[[ 0.01604 , 0.01100934, -0.03315874], [ 0.06344352, 0.01422943, -0.00157213]], [[ 0.00252157, 0.02109809, -0.03896577], [ 0.00764408, 0.09185135, 0.04494501]], [[ 0.03205271, 0.10364687, 0.0513285 ], [ 0.05215269, 0.00552455, -0.00398291]]], ... [[[-0.01745811, 0.00109955, -0.00234785], [ 0.03402061, 0.09196414, 0.02566072]], [[-0.02224305, 0.0419783 , 0.04470546], [ 0.01403128, -0.02350721, 0.03120449]], [[ 0.02172906, 0.1183168 , 0.08603979], [ 0.06071867, 0.06974237, -0.00941608]]], [[[ 0.04054993, 0.00168886, 0.00204798], [ 0.03383608, 0.10752412, 0.00560849]], [[-0.02446238, 0.04611171, 0.06851168], [-0.02977762, 0.05915644, 0.02482298]], [[ 0.02284061, 0.14261998, 0.06283344], [ 0.07870006, 0.0722998 , 0.00470552]]]]]) - alpha_United States(chain, draw, equations)float640.01419 0.01439 ... 0.02238 0.01881
array([[[0.01418759, 0.01438589, 0.01789529], [0.02598225, 0.02316987, 0.02425873], [0.02084087, 0.02086088, 0.02268168], ..., [0.0204412 , 0.0181257 , 0.02361468], [0.02663887, 0.02359841, 0.02279745], [0.02026212, 0.01972341, 0.02921508]], [[0.0175823 , 0.01768812, 0.02307349], [0.01971666, 0.02071566, 0.02032091], [0.02503186, 0.01945537, 0.03680978], ..., [0.02330623, 0.02334296, 0.02966311], [0.02803772, 0.02371988, 0.02919166], [0.02598188, 0.02355839, 0.0276434 ]], [[0.01639968, 0.02059404, 0.02225209], [0.01516595, 0.02000534, 0.02034232], [0.01458103, 0.01572419, 0.01855923], ..., [0.02262127, 0.02314291, 0.02062068], [0.02356728, 0.02304586, 0.01839952], [0.0255272 , 0.02383072, 0.02629042]], [[0.01706889, 0.01811566, 0.01869895], [0.02279406, 0.02093012, 0.02772462], [0.01559355, 0.01706438, 0.01418122], ..., [0.02425718, 0.02578526, 0.02210795], [0.02031301, 0.02141664, 0.02099948], [0.02015476, 0.02238341, 0.01881354]]]) - rho(chain, draw)float640.9738 0.9781 ... 0.9742 0.9753
array([[0.97381057, 0.97811196, 0.97718909, ..., 0.97291982, 0.97309863, 0.97185022], [0.97169609, 0.97574464, 0.98000959, ..., 0.97467665, 0.97241438, 0.97316599], [0.9735359 , 0.97198473, 0.97272403, ..., 0.97850145, 0.97746482, 0.96707703], [0.97773676, 0.98241421, 0.98392793, ..., 0.97368538, 0.97423528, 0.97533662]]) - alpha_hat_scale(chain, draw)float640.03402 0.06921 ... 0.0618 0.05396
array([[0.0340201 , 0.06921044, 0.04641818, ..., 0.05165564, 0.04568199, 0.04795936], [0.04631599, 0.04024177, 0.05337683, ..., 0.05200098, 0.05838578, 0.05937475], [0.03724151, 0.03813012, 0.04173683, ..., 0.02798101, 0.02871392, 0.04856515], [0.04674297, 0.08268964, 0.03778358, ..., 0.06162338, 0.06179729, 0.0539579 ]]) - beta_hat_scale(chain, draw)float640.1702 0.342 ... 0.1799 0.1808
array([[0.17021182, 0.34198411, 0.26618006, ..., 0.06287413, 0.07082787, 0.08768702], [0.3597106 , 0.27083859, 0.30066 , ..., 0.26574803, 0.25635952, 0.22758884], [0.19117243, 0.15246495, 0.14473942, ..., 0.22679552, 0.21358656, 0.18949933], [0.17265149, 0.19386224, 0.19044116, ..., 0.24260553, 0.17989111, 0.18078723]]) - omega_global(chain, draw, omega_global_dim_0)float640.01219 0.01523 ... 0.02162
array([[[ 0.01218822, 0.01522638, 0.00340886, 0.04335285, -0.00217308, 0.01861989], [ 0.01083866, 0.01506469, 0.00349949, 0.0472653 , -0.00810183, 0.018163 ], [ 0.01259793, 0.01506935, 0.00208336, 0.04179166, -0.00406775, 0.01350414], ..., [ 0.01538368, 0.01404695, 0.00268523, 0.04535721, -0.00239042, 0.02258466], [ 0.01742328, 0.01408072, 0.00235776, 0.0409345 , -0.00474418, 0.02801085], [ 0.01750076, 0.01519746, 0.00180543, 0.04712585, -0.00497156, 0.02631976]], [[ 0.0096274 , 0.01478892, 0.00145199, 0.04426993, -0.00713694, 0.01616899], [ 0.00911955, 0.01458634, 0.00192268, 0.04352532, -0.00404308, 0.01334046], [ 0.01766926, 0.01318953, 0.00298321, 0.04399035, -0.00028403, 0.01900471], ... [ 0.01309073, 0.01593698, 0.00427304, 0.04297485, -0.00625585, 0.01492482], [ 0.0131297 , 0.01589519, 0.00361034, 0.04235657, -0.00874078, 0.01485382], [ 0.00700433, 0.01694595, 0.00332786, 0.04951525, -0.00864561, 0.01417389]], [[ 0.01657584, 0.01618365, 0.00121653, 0.0422487 , -0.00536544, 0.02459217], [ 0.01429305, 0.01678552, 0.00287854, 0.04766878, -0.00414733, 0.02612078], [ 0.01566869, 0.01544929, 0.00087778, 0.04375063, -0.00088749, 0.02315615], ..., [ 0.01586844, 0.01328996, 0.00212247, 0.04404664, -0.00792564, 0.01707153], [ 0.01742985, 0.01451352, 0.00181431, 0.04416283, -0.00880546, 0.01853252], [ 0.01696835, 0.01391377, 0.00294613, 0.04265286, -0.00773243, 0.02161597]]]) - z_scale_beta_Australia(chain, draw)float640.2373 0.1376 ... 0.1337 0.3954
array([[0.23733251, 0.13758496, 0.19790107, ..., 0.2683509 , 0.43777321, 0.35490719], [0.16970964, 0.21089276, 0.14752019, ..., 0.20887074, 0.23847507, 0.22740404], [0.18774524, 0.14397091, 0.15803173, ..., 0.1643344 , 0.14389337, 0.17155927], [0.10184759, 0.14977448, 0.3845752 , ..., 0.18333872, 0.13368225, 0.39544404]]) - z_scale_alpha_Australia(chain, draw)float640.1813 0.08512 ... 0.1576 0.1759
array([[0.18129685, 0.08512272, 0.0825424 , ..., 0.19052937, 0.15158669, 0.06388572], [0.17619474, 0.153651 , 0.06209169, ..., 0.10879725, 0.08143188, 0.06124614], [0.33806892, 0.49434597, 1.13783518, ..., 0.07934544, 0.07641461, 0.12051502], [0.08740891, 0.18904214, 0.05906492, ..., 0.14159646, 0.15764165, 0.17588977]]) - noise_chol_Australia(chain, draw, noise_chol_Australia_dim_0)float640.175 -0.242 ... 0.1645 0.5325
array([[[ 1.75009064e-01, -2.41966458e-01, 3.77166882e-01, 1.56158277e-01, -1.59097525e-01, 7.46226834e-01], [ 3.27286769e-01, -2.06759636e-01, 3.54521164e-01, -8.78404918e-02, 4.12028275e-01, 8.42911934e-01], [ 2.07376788e-01, -2.06733568e-01, 4.11655442e-01, 2.57772407e-02, 1.69097846e-01, 9.34743848e-01], ..., [ 2.45074957e-02, -1.01309189e-01, 3.91599644e-01, -8.20973318e-04, 1.39181640e-02, 5.49412749e-01], [ 8.91305701e-02, -2.30866065e-01, 3.59675857e-01, -2.97897976e-03, 6.01460053e-02, 3.37379791e-01], [ 2.16267881e-02, -1.11576650e-01, 3.04429183e-01, 1.22103651e-01, -5.15246121e-02, 4.76004283e-01]], [[ 1.80956346e-01, -3.70271679e-01, 3.33901352e-01, 8.23575085e-02, 8.00168014e-02, 7.95469864e-01], [ 2.64017511e-01, -2.39610503e-01, 5.50213319e-01, -1.59290032e-01, -1.33132507e-01, 9.18250045e-01], [ 3.78297087e-02, -2.21234165e-01, 4.00785255e-01, 8.51259660e-02, 1.06339001e-01, 7.79466870e-01], ... [ 2.79023071e-01, -1.51039405e-01, 3.01706251e-01, 3.58180855e-01, -2.48669353e-01, 1.10849280e+00], [ 2.38854510e-01, -1.53208579e-01, 3.35600307e-01, 3.42964310e-01, -2.13285861e-01, 1.03457056e+00], [ 2.83983860e-01, -1.71796239e-01, 2.64743634e-01, -1.51092936e-01, 2.46242864e-01, 7.41648021e-01]], [[ 3.88131454e-02, -2.57320192e-01, 4.46016074e-01, 1.77476846e-01, 1.70444198e-01, 1.04851247e+00], [ 5.64098263e-02, -4.67351932e-01, 5.61366262e-01, -1.42738917e-01, 6.95320006e-02, 3.81719892e-01], [ 9.50186978e-02, -3.52880748e-01, 6.78903260e-01, 1.26887043e-01, 1.46595764e-01, 1.12829866e+00], ..., [ 5.44019018e-02, -8.85788728e-02, 3.77625681e-01, 1.10980108e-01, -3.72535830e-02, 5.80429028e-01], [ 1.19395831e-01, -1.42548367e-01, 4.40398013e-01, 1.12601989e-01, 2.26750509e-02, 6.72758290e-01], [ 4.30490930e-02, -1.93142846e-01, 2.47198998e-01, 1.32553510e-01, 1.64468953e-01, 5.32483910e-01]]]) - z_scale_beta_Canada(chain, draw)float640.2736 0.1216 ... 0.2629 0.1972
array([[0.2735902 , 0.12162758, 0.11923719, ..., 0.13616515, 0.14870794, 0.05126063], [0.14145914, 0.12747015, 0.0982708 , ..., 0.17180652, 0.11555273, 0.16727532], [0.2060911 , 0.22955972, 0.26356065, ..., 0.08780278, 0.10534695, 0.22093912], [0.32993518, 0.19789392, 0.39145888, ..., 0.21750251, 0.26293427, 0.19716798]]) - z_scale_alpha_Canada(chain, draw)float640.08111 0.1227 ... 0.1777 0.2688
array([[0.08110592, 0.12272377, 0.05527928, ..., 0.10023458, 0.07230248, 0.12789033], [0.05879722, 0.06700424, 0.11058203, ..., 0.14818562, 0.16656002, 0.14363989], [0.18159317, 0.25359104, 0.07573124, ..., 0.21241997, 0.19597401, 0.04952498], [0.18317507, 0.17453329, 0.13894086, ..., 0.24241797, 0.1777248 , 0.26877818]]) - noise_chol_Canada(chain, draw, noise_chol_Canada_dim_0)float640.6638 0.0403 ... -0.02874 1.181
array([[[ 6.63841785e-01, 4.02967263e-02, 2.04557467e-01, -3.10301667e-01, 1.25588803e-01, 1.01760068e+00], [ 6.72230622e-01, -4.74201546e-02, 3.33468200e-01, -3.04123311e-01, -4.22369969e-02, 8.59109258e-01], [ 4.57499126e-01, -5.57666085e-02, 3.18614921e-01, -1.03435905e-01, 8.60762345e-02, 6.93882000e-01], ..., [ 2.30208350e-01, 2.74176641e-02, 2.56026965e-01, 2.01260051e-02, -6.28187911e-02, 4.99447487e-01], [ 5.83471852e-01, 2.55009302e-02, 2.77491150e-01, -7.29815653e-02, 5.98704180e-03, 5.32175073e-01], [ 1.87097085e-01, -4.50975162e-03, 2.83794397e-01, -2.83188386e-02, -5.74170966e-02, 1.14011854e-01]], [[ 6.89523056e-01, -2.17638947e-02, 3.82243288e-01, -6.11455949e-02, -1.92379821e-02, 8.70274743e-01], [ 5.55481211e-01, -5.85440097e-02, 4.65228228e-01, -1.53032878e-03, -1.32821915e-01, 7.89445881e-01], [ 4.53761398e-01, 1.59819847e-01, 4.83133151e-01, -3.05715714e-01, -1.73863908e-01, 7.85893772e-01], ... [ 4.85396113e-01, -3.85010996e-02, 2.33234358e-01, -5.22581485e-01, 4.28506714e-02, 1.00645794e+00], [ 3.46013361e-01, -1.84679330e-02, 1.96155466e-01, -5.02223862e-01, 6.40270519e-02, 1.10288891e+00], [ 8.72890641e-01, 4.78983043e-03, 2.11053539e-01, 1.98180766e-01, 7.17155397e-02, 5.77998588e-01]], [[ 5.46223094e-01, 8.02505172e-02, 4.28484043e-01, 4.69637940e-02, 9.00672883e-02, 2.69944183e-01], [ 6.57170687e-01, -6.57688587e-02, 4.63001795e-01, -2.95114470e-01, -3.89604532e-01, 1.08588097e+00], [ 2.75631216e-01, -1.73436251e-01, 5.19705110e-01, -2.65749997e-01, -2.14369730e-01, 9.95094373e-01], ..., [ 4.67895105e-01, 5.50273105e-02, 2.99271255e-01, 9.60565736e-02, -3.34911241e-02, 7.01043032e-01], [ 6.05728593e-01, 3.43214520e-02, 2.83898860e-01, 2.63613127e-01, -6.90725341e-02, 4.55452429e-01], [ 3.56213359e-01, 1.20525000e-01, 2.67727139e-01, 2.76738914e-01, -2.87416099e-02, 1.18068692e+00]]]) - z_scale_beta_Chile(chain, draw)float640.229 0.1375 ... 0.1742 0.1706
array([[0.22899545, 0.13745599, 0.26038696, ..., 0.13271286, 0.13996626, 0.15617835], [0.26796844, 0.32397628, 0.24143166, ..., 0.25281944, 0.26285746, 0.16012707], [0.20003227, 0.22413203, 0.30807896, ..., 0.14702232, 0.13655419, 0.1611094 ], [0.12665211, 0.24503321, 0.18145351, ..., 0.16564633, 0.17421741, 0.1706148 ]]) - z_scale_alpha_Chile(chain, draw)float640.07176 0.2501 ... 0.1016 0.1626
array([[0.07175951, 0.25009334, 0.19247747, ..., 0.12144125, 0.14389656, 0.1744608 ], [0.20995505, 0.06798136, 0.16792769, ..., 0.03781415, 0.07560244, 0.09997186], [0.21493768, 0.29495032, 0.14100461, ..., 0.06206609, 0.07443024, 0.14303804], [0.13749515, 0.22017398, 0.6602553 , ..., 0.11386145, 0.10160067, 0.1626074 ]]) - noise_chol_Chile(chain, draw, noise_chol_Chile_dim_0)float641.271 0.9954 1.283 ... 0.5532 2.125
array([[[ 1.2713373 , 0.99536111, 1.28338935, 1.43952188, -0.69684319, 3.22514992], [ 1.40839471, 0.82535996, 1.42734938, 2.09533359, 0.20054094, 2.56586225], [ 1.05662488, 0.98155735, 1.40916792, 2.25338675, -0.04921683, 2.57580404], ..., [ 1.02995934, 0.97970855, 1.26811632, 1.72261509, -0.43159677, 2.03247673], [ 0.76983079, 0.81360878, 1.21848554, 1.2396864 , -0.11252982, 1.81461605], [ 0.99565962, 0.99407386, 1.25909894, 1.71498306, -0.62919271, 1.96900818]], [[ 0.91491713, 0.64726681, 1.17620428, 1.13147863, -0.547197 , 1.88580175], [ 1.54426339, 1.47131482, 1.35847226, 1.30451326, -0.78581922, 2.46155797], [ 1.27900868, 1.54230622, 1.52963902, 1.83131565, 0.5343465 , 2.95908756], ... [ 1.24101022, 0.70036062, 1.73477873, 2.24664284, -0.29344026, 2.921228 ], [ 1.31056705, 0.69116523, 1.67466986, 2.01757443, -0.10579977, 2.69521769], [ 1.07192233, 0.70944004, 1.11569374, 1.23529904, -0.19623784, 2.13655411]], [[ 1.29850511, 1.28588941, 1.64259491, 1.7294742 , 0.0111462 , 2.8531648 ], [ 1.52666923, 0.8594347 , 1.75708998, 2.21872494, -0.79308502, 2.63176654], [ 1.5267606 , 1.79104923, 2.16756641, 1.94223226, 0.36577915, 3.31320725], ..., [ 0.87863276, 0.8645867 , 1.48716868, 0.7839539 , 0.41107075, 2.68110651], [ 1.00752757, 0.84377287, 1.1272519 , 0.996813 , 0.25069931, 2.33427424], [ 0.84373496, 1.00729207, 1.34513209, 1.64363374, 0.55315572, 2.12510581]]]) - z_scale_beta_Ireland(chain, draw)float640.1352 0.1684 ... 0.3071 0.3112
array([[0.13515041, 0.16841739, 0.30566275, ..., 1.48384029, 1.26618831, 0.96436302], [0.3002465 , 0.28440437, 0.33272395, ..., 0.34859503, 0.79417514, 0.92764539], [0.67713418, 0.6029362 , 0.81819988, ..., 0.09783051, 0.08830116, 0.17834987], [0.51930341, 0.40452318, 0.60129802, ..., 0.24895538, 0.30705064, 0.3112266 ]]) - z_scale_alpha_Ireland(chain, draw)float640.1537 0.2775 ... 0.3494 0.1915
array([[0.15365594, 0.27748515, 0.18524841, ..., 0.23729754, 0.277995 , 0.45423572], [0.54173165, 0.39499058, 0.12902482, ..., 0.14727411, 0.19081259, 0.22165099], [0.21476198, 0.35359638, 0.52720217, ..., 0.21613118, 0.23772488, 0.18405737], [0.38242312, 0.17401459, 0.61464315, ..., 0.33708139, 0.34940602, 0.19148278]]) - noise_chol_Ireland(chain, draw, noise_chol_Ireland_dim_0)float641.099 0.02963 ... 1.621 5.085
array([[[ 1.09856315e+00, 2.96345808e-02, 8.88518456e-01, 1.18432112e+00, 7.80034956e-01, 5.25735088e+00], [ 1.07918067e+00, -2.05821137e-01, 7.64516760e-01, -1.16674692e+00, 3.26435914e+00, 5.32583601e+00], [ 1.24444094e+00, -2.02728601e-01, 8.79825094e-01, 1.53841085e-01, 2.59942547e+00, 6.25166488e+00], ..., [ 1.11717345e+00, 5.72925103e-03, 7.30154454e-01, 1.10736309e+00, 9.78603280e-01, 4.12596194e+00], [ 7.93225416e-01, 3.96900413e-02, 7.30948192e-01, 7.10023342e-01, 6.40733857e-01, 4.98412443e+00], [ 7.96916953e-01, -3.01712273e-01, 6.96183628e-01, 5.40954711e-01, 2.35211699e-01, 4.32336375e+00]], [[ 1.20283767e+00, -1.12765130e-01, 5.36040832e-01, -1.27636978e-01, -1.13365143e-01, 4.65049433e+00], [ 1.53763364e+00, -1.42004911e-01, 7.42971220e-01, 1.52130992e+00, 6.66403722e-01, 5.57555202e+00], [ 1.16328075e+00, -2.05732679e-02, 9.36285222e-01, -1.53102862e-01, 6.71542056e-01, 5.95187924e+00], ... [ 1.30702197e+00, -1.76249618e-02, 8.98338946e-01, -3.28047179e-01, 1.67962272e+00, 6.36003612e+00], [ 1.40896661e+00, 7.13161220e-02, 8.78038893e-01, -3.61588797e-01, 1.63284155e+00, 6.57950999e+00], [ 9.00442033e-01, -2.24069083e-01, 6.06522848e-01, 8.79411998e-01, 5.61357327e-01, 4.00038854e+00]], [[ 1.18230319e+00, 4.55079986e-02, 1.19128657e+00, -4.81292673e-01, 2.06992190e+00, 5.61763730e+00], [ 1.60181970e+00, -3.19149032e-01, 1.24078737e+00, 1.92005227e+00, 1.76821775e+00, 7.22578334e+00], [ 1.84183924e+00, 5.61535923e-02, 1.28691485e+00, 8.02460978e-02, 1.53634315e+00, 7.22210371e+00], ..., [ 7.49490956e-01, -1.16600008e-01, 8.05857611e-01, 5.68280518e-01, 1.15574604e+00, 4.22703637e+00], [ 9.77372681e-01, -3.38123856e-02, 8.61020572e-01, 7.34992405e-01, 1.54307067e+00, 4.42657352e+00], [ 8.55023254e-01, -5.75545242e-02, 7.53220868e-01, 4.80298630e-01, 1.62075372e+00, 5.08493460e+00]]]) - z_scale_beta_New Zealand(chain, draw)float640.1568 0.08317 ... 0.1449 0.2407
array([[0.15683385, 0.08317042, 0.13644376, ..., 0.19817681, 0.17730541, 0.22075204], [0.5867957 , 0.40664675, 0.35064204, ..., 0.05166904, 0.10526662, 0.10598518], [0.13731709, 0.14729447, 0.12760717, ..., 0.31413699, 0.23158494, 0.20586101], [0.21346263, 0.10403213, 0.0915345 , ..., 0.11785439, 0.14485999, 0.24066193]]) - z_scale_alpha_New Zealand(chain, draw)float640.06729 0.1558 ... 0.0909 0.1513
array([[0.06728825, 0.15575064, 0.08057372, ..., 0.07220709, 0.45988372, 0.23094846], [0.16929306, 0.32510334, 0.21386455, ..., 0.11509867, 0.17749332, 0.22863279], [0.18692619, 0.23632348, 0.161856 , ..., 0.15370496, 0.1313317 , 0.14631651], [0.2057581 , 0.12671456, 0.08567276, ..., 0.1089957 , 0.09089895, 0.15134683]]) - noise_chol_New Zealand(chain, draw, noise_chol_New Zealand_dim_0)float640.3045 -0.06226 ... 0.2427 0.9673
array([[[ 3.04534370e-01, -6.22634500e-02, 2.30251224e-01, 2.01567722e-01, 2.65176062e-01, 1.06972539e+00], [ 3.82169968e-01, -4.06752918e-02, 4.63471842e-01, 1.48383846e-01, -2.94155889e-01, 1.25174283e+00], [ 2.55826468e-01, -1.03929812e-01, 3.52208684e-01, 1.45533050e-03, -3.15286904e-01, 1.34032233e+00], ..., [ 2.05796473e-01, -5.65038526e-02, 2.72676759e-01, 5.95319409e-02, -3.31483910e-03, 1.01420246e+00], [ 4.82275138e-02, 6.49698870e-03, 3.52252939e-01, 3.08376854e-01, -7.09945453e-02, 8.00374888e-01], [ 9.96422216e-02, -5.69869594e-02, 3.13139052e-01, 1.36687914e-02, 3.74159443e-01, 6.01404006e-01]], [[ 2.96598158e-01, -1.08394671e-01, 2.60064930e-01, 1.00045077e-01, 3.19963468e-01, 1.19235821e+00], [ 3.68460688e-01, -3.49347948e-02, 2.83659682e-01, 3.45677041e-01, 5.39216581e-01, 1.45119058e+00], [ 2.66135207e-02, 9.64662349e-03, 3.33401467e-01, 2.63245444e-01, 6.99199673e-02, 1.46319812e+00], ... [ 3.26785762e-01, -4.75896942e-03, 3.03815676e-01, 3.38326213e-01, 2.46681368e-01, 1.25811353e+00], [ 2.97884495e-01, 1.45474559e-02, 3.52891674e-01, 3.54507591e-01, 2.40356352e-01, 1.30447621e+00], [ 3.22936817e-01, -7.71868518e-02, 3.44787980e-01, 3.25989775e-01, 1.82560741e-01, 9.62272141e-01]], [[ 1.13775785e-01, -1.82756720e-01, 4.41427531e-01, 5.97232948e-03, -2.33164515e-01, 9.26564865e-01], [ 1.42230904e-01, -1.63438802e-01, 4.09825107e-01, 2.92795734e-01, 4.23615387e-01, 8.43114622e-01], [ 7.12239451e-02, -2.82156301e-01, 5.83461936e-01, 8.92206268e-03, -1.95493032e-01, 1.13518904e+00], ..., [ 3.32437466e-03, -1.37439148e-01, 3.00861920e-01, 4.94537599e-01, 3.04668942e-01, 1.37290872e+00], [ 3.17245931e-03, -7.99550666e-02, 3.00059226e-01, 3.14103380e-01, 2.40498251e-01, 1.06737550e+00], [ 1.14414877e-03, -7.99456081e-02, 3.98605313e-01, 3.91641437e-01, 2.42681961e-01, 9.67280276e-01]]]) - z_scale_beta_South Africa(chain, draw)float640.3028 0.1277 ... 0.1921 0.182
array([[0.30279332, 0.12767831, 0.15688923, ..., 0.11106397, 0.07656958, 0.15029139], [0.16064704, 0.23639388, 0.25754659, ..., 0.21746958, 0.10513224, 0.18164775], [0.195663 , 0.35295286, 0.22305478, ..., 0.19855045, 0.19005038, 0.24907922], [0.36338798, 0.18413234, 0.33847675, ..., 0.14802796, 0.19205473, 0.18199475]]) - z_scale_alpha_South Africa(chain, draw)float640.1202 0.1349 ... 0.09006 0.285
array([[0.12015358, 0.13493375, 0.0648358 , ..., 0.0919638 , 0.11024545, 0.15766595], [0.19301864, 0.10122474, 0.17276421, ..., 0.15145001, 0.09511091, 0.10969005], [0.19955557, 0.10092923, 0.10426572, ..., 0.22171558, 0.24340049, 0.05818205], [0.09480666, 0.17856244, 0.08669728, ..., 0.10470687, 0.09005743, 0.28504025]]) - noise_chol_South Africa(chain, draw, noise_chol_South Africa_dim_0)float640.5349 0.1351 ... 0.2843 1.149
array([[[ 0.53491119, 0.13506689, 0.40925099, 0.43060671, -0.04671164, 1.0742078 ], [ 0.45006859, 0.07702614, 0.34843147, -0.02380481, 0.80738061, 1.36785175], [ 0.52911664, 0.13904279, 0.41561976, 0.00761154, 0.44446315, 1.71151233], ..., [ 0.23929478, 0.09108124, 0.29150512, 0.10614043, 0.4239166 , 1.44119576], [ 0.14620517, 0.21860656, 0.39451119, 0.09698263, 0.15418555, 0.74159188], [ 0.28107478, 0.06335196, 0.34141938, 0.14266915, 0.30526329, 1.100891 ]], [[ 0.49119883, 0.15763616, 0.31821425, 0.13000937, 0.3455772 , 1.17951536], [ 0.49160659, 0.07070707, 0.36609474, 0.07224417, 0.22384536, 0.92835412], [ 0.25065236, 0.13493957, 0.48287582, -0.01236825, 0.54147728, 1.49648292], ... [ 0.40043675, 0.12059527, 0.36182001, 0.10638281, 0.6239572 , 1.4541244 ], [ 0.43754413, 0.11387724, 0.36797442, 0.15256836, 0.55618488, 1.36590003], [ 0.50844278, 0.09389214, 0.28417363, 0.05590844, 0.04556554, 1.03091337]], [[ 0.26213754, 0.04139005, 0.42227785, 0.04647854, 0.3332211 , 1.07929115], [ 0.51324612, 0.19302037, 0.48696068, 0.15771725, 0.1630655 , 1.01446079], [ 0.26241434, -0.06503686, 0.65109777, -0.15114364, 0.40048984, 1.62352346], ..., [ 0.30151799, 0.30066605, 0.53213137, 0.15784736, 0.24558049, 0.96060019], [ 0.29867705, 0.2828084 , 0.63986031, 0.14439767, 0.23703673, 0.82412247], [ 0.38222619, 0.30634978, 0.30199813, 0.27346263, 0.28426877, 1.14890924]]]) - z_scale_beta_United Kingdom(chain, draw)float640.1376 0.09737 ... 0.1359 0.1997
array([[0.13760451, 0.09736721, 0.12133271, ..., 0.38925306, 0.31667518, 0.22890316], [0.08038653, 0.12553462, 0.11477293, ..., 0.10769304, 0.10138577, 0.09951663], [0.18279412, 0.15005027, 0.20712825, ..., 0.27319416, 0.28391667, 0.2400759 ], [0.29275696, 0.32307963, 0.20115288, ..., 0.1389538 , 0.13585209, 0.19965343]]) - z_scale_alpha_United Kingdom(chain, draw)float640.1097 0.09583 ... 0.1165 0.1876
array([[0.10966504, 0.09583278, 0.13833385, ..., 0.09903016, 0.27157237, 0.07406357], [0.28040022, 0.29537069, 0.16468849, ..., 0.20401608, 0.14859831, 0.18059844], [0.1275927 , 0.12371497, 0.10679124, ..., 0.11174293, 0.09064222, 0.11041517], [0.16563187, 0.07109435, 0.21548179, ..., 0.08576826, 0.11648584, 0.18761744]]) - noise_chol_United Kingdom(chain, draw, noise_chol_United Kingdom_dim_0)float640.5181 0.1999 ... -0.1428 0.2923
array([[[ 0.51805797, 0.19992544, 0.30611624, -0.03454922, -0.01727734, 0.41038445], [ 0.68063806, 0.17285 , 0.27621605, -0.13650163, 0.02689844, 0.63340957], [ 0.51016555, 0.07968407, 0.35528676, -0.18907501, 0.04373098, 0.57833823], ..., [ 0.49340154, 0.22100705, 0.28635307, -0.06541354, 0.02756904, 0.41131211], [ 0.27505083, 0.1507085 , 0.31188928, -0.02256363, -0.01017282, 0.1454976 ], [ 0.50307347, 0.21146626, 0.35233846, -0.00891876, -0.01109241, 0.08418704]], [[ 0.6697906 , 0.28757484, 0.29081772, 0.06310447, 0.05003137, 0.7282122 ], [ 0.63231443, 0.20961938, 0.35221502, 0.08923737, -0.0575837 , 0.8520046 ], [ 0.33083785, 0.09791569, 0.43926716, -0.2223944 , -0.02075778, 0.89974798], ... [ 0.63094498, 0.20722517, 0.26024145, -0.03947783, 0.06077336, 0.61679501], [ 0.65253291, 0.23846856, 0.26753542, -0.02718829, 0.08001931, 0.68236906], [ 0.55743991, 0.11498019, 0.19110445, -0.17102278, -0.12158564, 0.48314845]], [[ 0.45621561, 0.21430995, 0.43111356, -0.02009445, -0.0292364 , 0.14654888], [ 0.75799236, 0.23109576, 0.45407524, -0.11053904, 0.00506073, 0.41793986], [ 0.73309182, 0.20437958, 0.70501178, -0.0333804 , -0.02803683, 0.2328034 ], ..., [ 0.35197736, 0.19878206, 0.34689516, -0.07355243, 0.14105923, 0.66148832], [ 0.33940493, 0.14350584, 0.35364014, -0.06468686, 0.08147527, 0.49926483], [ 0.49475088, 0.34038341, 0.36892313, -0.03643964, -0.14280008, 0.2922645 ]]]) - z_scale_beta_United States(chain, draw)float640.1896 0.1494 ... 0.2437 0.2543
array([[0.18958107, 0.1494162 , 0.13635679, ..., 0.15827189, 0.15912714, 0.13280968], [0.12184466, 0.21663823, 0.22549997, ..., 0.09356525, 0.10630629, 0.08359141], [0.41350269, 0.50259608, 0.45436826, ..., 0.1459533 , 0.14197894, 0.18436221], [0.10960259, 0.06220923, 0.08655352, ..., 0.21524427, 0.24374299, 0.25433995]]) - z_scale_alpha_United States(chain, draw)float640.2781 0.05996 ... 0.07085 0.1986
array([[0.27805843, 0.05995524, 0.09545307, ..., 0.08129427, 0.13309833, 0.11127608], [0.0663578 , 0.04932191, 0.21701084, ..., 0.077368 , 0.05992179, 0.07399188], [0.10565687, 0.08574053, 0.07569111, ..., 0.11796192, 0.10216897, 0.14909703], [0.08916109, 0.09249728, 0.141727 , ..., 0.10454905, 0.07085149, 0.19861092]]) - noise_chol_United States(chain, draw, noise_chol_United States_dim_0)float640.3961 -0.02142 ... 0.03923
array([[[ 3.96101210e-01, -2.14229339e-02, 1.71805163e-01, 2.88551200e-02, -3.00898234e-02, 1.24734102e-01], [ 5.03002570e-01, -1.43405244e-02, 1.63154102e-01, 5.04905115e-02, -2.63637879e-02, 3.02538415e-01], [ 4.04993670e-01, 3.04129759e-02, 2.90241912e-01, 5.31442601e-02, -1.89588203e-02, 1.61462826e-01], ..., [ 2.53086948e-01, -5.78746877e-02, 2.17718052e-01, -1.25685048e-02, -1.17879993e-02, 4.68672641e-02], [ 1.83608671e-01, 2.04228355e-02, 1.46513849e-01, 1.16691629e-02, 2.42975744e-03, 1.02663465e-01], [ 1.37632782e-01, -1.61296916e-02, 2.69887933e-01, 5.19367162e-02, 2.34998753e-02, 2.43429048e-01]], [[ 3.39014250e-01, -1.43225055e-01, 2.47521763e-01, -8.63219548e-02, 1.72502016e-02, 1.20696676e-01], [ 4.61999281e-01, -1.06880397e-01, 2.19037221e-01, -1.53294265e-01, -1.68548360e-01, 3.12962460e-01], [ 1.82627588e-01, -2.72004972e-02, 2.06479878e-01, 3.62971802e-02, 4.38487019e-02, 1.41787948e-01], ... [ 4.75538859e-01, 1.25698626e-03, 1.60342209e-01, 2.38086815e-01, 1.16724900e-01, 4.99531795e-01], [ 4.79690965e-01, -6.31750907e-03, 1.52214873e-01, 2.48485977e-01, 1.27297589e-01, 3.53743305e-01], [ 5.48080699e-01, -2.28229355e-03, 1.23535355e-01, -1.00901044e-02, 2.00580588e-02, 1.92498698e-01]], [[ 3.58773908e-01, -6.12252628e-02, 2.41452951e-01, 1.47961304e-02, -1.48080351e-02, 7.77483716e-02], [ 5.36307260e-01, -7.16324745e-02, 2.83227906e-01, -4.25654389e-03, 1.64294962e-02, 8.98516510e-02], [ 4.56463393e-01, -4.11304643e-02, 4.90980148e-01, 9.77820024e-03, -1.82103534e-02, 1.15329317e-01], ..., [ 2.48958959e-01, 2.75594740e-02, 3.03903081e-01, 1.03640678e-03, 4.39198702e-03, 5.59877989e-02], [ 1.78786256e-01, -1.96203168e-02, 2.30191909e-01, -1.98062886e-03, -3.28251407e-03, 3.22106727e-02], [ 2.36709720e-01, -1.73959531e-02, 2.35395996e-01, 8.15216826e-03, -1.51576124e-02, 3.92320180e-02]]]) - omega_global_corr(chain, draw, omega_global_corr_dim_0, omega_global_corr_dim_1)float641.0 0.9758 0.9179 ... 0.8284 1.0
array([[[[1. , 0.97584357, 0.91786403], [0.97584357, 1. , 0.88564027], [0.91786403, 0.88564027, 1. ]], [[1. , 0.97406397, 0.92172696], [0.97406397, 1. , 0.86207108], [0.92172696, 0.86207108, 1. ]], [[1. , 0.99057811, 0.94750053], [0.99057811, 1. , 0.92594331], [0.94750053, 0.92594331, 1. ]], ..., [[1. , 0.9822147 , 0.89417307], [0.9822147 , 1. , 0.86942173], [0.89417307, 0.86942173, 1. ]], [[1. , 0.98626896, 0.82152949], [0.98626896, 1. , 0.79452495], ... [0.98561225, 1. , 0.84898728], [0.87442717, 0.84898728, 1. ]], [[1. , 0.99838982, 0.88369556], [0.99838982, 1. , 0.88125579], [0.88369556, 0.88125579, 1. ]], ..., [[1. , 0.98748604, 0.91956421], [0.98748604, 1. , 0.88196208], [0.91956421, 0.88196208, 1. ]], [[1. , 0.99227684, 0.90690012], [0.99227684, 1. , 0.87746611], [0.90690012, 0.87746611, 1. ]], [[1. , 0.97830934, 0.88055348], [0.97830934, 1. , 0.82838574], [0.88055348, 0.82838574, 1. ]]]]) - omega_global_stds(chain, draw, omega_global_stds_dim_0)float640.01219 0.0156 ... 0.01422 0.04844
array([[[0.01218822, 0.0156033 , 0.04723232], [0.01083866, 0.01546581, 0.05127907], [0.01259793, 0.01521268, 0.04410727], ..., [0.01538368, 0.01430131, 0.05072532], [0.01742328, 0.01427676, 0.04982718], [0.01750076, 0.01530433, 0.05420601]], [[0.0096274 , 0.01486003, 0.04766759], [0.00911955, 0.01471251, 0.04570305], [0.01766926, 0.01352269, 0.04792088], ..., [0.01479791, 0.01377459, 0.04464239], [0.01378923, 0.01407682, 0.04411417], [0.01440868, 0.01338876, 0.04470281]], [[0.01858746, 0.01842537, 0.05731224], [0.01665598, 0.01728827, 0.05177552], [0.01536784, 0.01485824, 0.05005355], ..., [0.01309073, 0.01649988, 0.04592084], [0.0131297 , 0.01630005, 0.04572872], [0.00700433, 0.01726962, 0.05222457]], [[0.01657584, 0.0162293 , 0.04917841], [0.01429305, 0.01703056, 0.05451429], [0.01566869, 0.0154742 , 0.04950871], ..., [0.01586844, 0.01345838, 0.04789947], [0.01742985, 0.01462649, 0.04869647], [0.01696835, 0.01422226, 0.04843869]]]) - betaX_Australia(chain, draw, betaX_Australia_dim_0, betaX_Australia_dim_1)float640.006457 0.006665 ... 0.001335
array([[[[ 6.45673426e-03, 6.66495929e-03, 9.63041308e-03], [ 6.16520826e-03, 5.35006929e-03, 7.47274676e-03], [ 6.20528768e-03, 7.28459069e-03, 8.09003561e-03], ..., [ 5.34834939e-03, 5.30224650e-03, 5.12230411e-03], [ 3.17715424e-03, 3.72264068e-03, 7.71014433e-03], [ 2.40968783e-03, -1.10769314e-04, 3.79703453e-03]], [[ 5.62247168e-03, 8.22585752e-03, 7.41526458e-03], [ 6.81212894e-03, 8.59259114e-03, 6.96929263e-03], [ 6.85824713e-03, 9.71421306e-03, 7.80050163e-03], ..., [ 5.27977559e-03, 7.12763087e-03, 7.85077320e-03], [ 2.26854670e-03, 4.17898849e-03, 1.99233690e-03], [ 6.99576361e-04, 8.41475757e-04, 3.12093505e-03]], [[ 6.03583532e-03, 8.91936376e-03, 8.55984040e-03], [ 6.28650722e-03, 9.56265653e-03, 7.12959851e-03], [ 6.99959099e-03, 1.08125186e-02, 8.21668424e-03], ..., ... ..., [ 2.38122422e-04, 7.08644246e-03, -3.15206342e-04], [ 1.90243108e-05, 7.41842090e-03, -8.50312926e-04], [ 2.38167305e-03, 2.04661747e-03, 3.32965871e-04]], [[-6.64125571e-04, 8.97977715e-03, -2.64531910e-03], [-1.04763537e-03, 8.47060066e-03, -1.53199568e-03], [-1.59438755e-03, 9.94896541e-03, -3.01275733e-03], ..., [-4.95738576e-04, 6.66240537e-03, -1.65050538e-03], [-4.20453564e-04, 5.68659459e-03, -1.80702263e-03], [ 2.19041506e-03, 1.42714757e-03, 9.97837296e-04]], [[ 4.91271171e-03, 7.32782997e-03, -9.03573280e-04], [ 4.09813289e-03, 6.55476026e-03, 1.86820033e-04], [ 3.98572968e-03, 7.12591868e-03, -6.45143885e-04], ..., [ 2.01519705e-03, 4.86064939e-03, 1.38575206e-03], [ 4.92548971e-03, 5.14889911e-03, -2.53475447e-03], [ 2.97291555e-03, 2.73004850e-03, 1.33470356e-03]]]]) - noise_chol_Australia_corr(chain, draw, noise_chol_Australia_corr_dim_0, noise_chol_Australia_corr_dim_1)float641.0 -0.54 0.2005 ... 0.08377 1.0
array([[[[ 1. , -0.53997105, 0.20050768], [-0.53997105, 1. , -0.28020889], [ 0.20050768, -0.28020889, 1. ]], [[ 1. , -0.50379035, -0.09321638], [-0.50379035, 1. , 0.42466479], [-0.09321638, 0.42466479, 1. ]], [[ 1. , -0.44878606, 0.02712636], [-0.44878606, 1. , 0.14684738], [ 0.02712636, 0.14684738, 1. ]], ..., [[ 1. , -0.25046026, -0.00149379], [-0.25046026, 1. , 0.02489161], [-0.00149379, 0.02489161, 1. ]], [[ 1. , -0.54017118, -0.00869237], [-0.54017118, 1. , 0.15238841], ... [-0.63981809, 1. , 0.3501592 ], [-0.34526059, 0.3501592 , 1. ]], [[ 1. , -0.4611995 , 0.11083429], [-0.4611995 , 1. , 0.06250126], [ 0.11083429, 0.06250126, 1. ]], ..., [[ 1. , -0.22836937, 0.18742943], [-0.22836937, 1. , -0.1040565 ], [ 0.18742943, -0.1040565 , 1. ]], [[ 1. , -0.30795064, 0.16498622], [-0.30795064, 1. , -0.01919837], [ 0.16498622, -0.01919837, 1. ]], [[ 1. , -0.61568092, 0.23139218], [-0.61568092, 1. , 0.08377404], [ 0.23139218, 0.08377404, 1. ]]]]) - noise_chol_Australia_stds(chain, draw, noise_chol_Australia_stds_dim_0)float640.175 0.4481 ... 0.3137 0.5729
array([[[0.17500906, 0.44811006, 0.77881443], [0.32728677, 0.41040809, 0.94232891], [0.20737679, 0.4606506 , 0.95026555], ..., [0.0245075 , 0.40449207, 0.54958963], [0.08913057, 0.42739427, 0.34271204], [0.02162679, 0.32423213, 0.49410947]], [[0.18095635, 0.49858924, 0.80371497], [0.26401751, 0.60012323, 0.94142484], [0.03782971, 0.45779185, 0.79127935], ..., [0.11119029, 0.4450368 , 1.15437778], [0.08891332, 0.42875352, 1.25429922], [0.10683573, 0.45610541, 1.21426033]], [[0.05160502, 0.46142053, 0.82863923], [0.03275265, 0.40948387, 0.89037715], [0.01766209, 0.42345364, 0.59686582], ..., [0.27902307, 0.33740119, 1.19117012], [0.23885451, 0.36891792, 1.11060868], [0.28398386, 0.31559965, 0.79593116]], [[0.03881315, 0.51492137, 1.07699938], [0.05640983, 0.73044501, 0.41342372], [0.0950187 , 0.76513689, 1.14483558], ..., [0.0544019 , 0.38787546, 0.59211677], [0.11939583, 0.46289356, 0.68249328], [0.04304909, 0.31370608, 0.57285215]]]) - omega_Australia(chain, draw, omega_Australia_dim_0, omega_Australia_dim_1)float640.01645 0.0 ... -0.003485 0.03422
array([[[[ 0.01645241, 0. , 0. ], [ 0.00849064, 0.01319737, 0. ], [ 0.04630716, -0.00628284, 0.0376755 ]], [[ 0.01776509, 0. , 0. ], [ 0.01020939, 0.01118267, 0. ], [ 0.0443081 , 0.00109399, 0.03621514]], [[ 0.01704101, 0. , 0. ], [ 0.01000982, 0.01142607, 0. ], [ 0.04142636, -0.00011768, 0.03451845]], ..., [[ 0.01563076, 0. , 0. ], [ 0.01092309, 0.0132171 , 0. ], [ 0.0441067 , -0.00194878, 0.03685126]], [[ 0.0193523 , 0. , 0. ], [ 0.00749132, 0.01197011, 0. ], ... [ 0.00827159, 0.01269999, 0. ], [ 0.04432031, -0.00285162, 0.03237427]], [[ 0.01694401, 0. , 0. ], [ 0.00952946, 0.01177505, 0. ], [ 0.0450868 , 0.00148287, 0.04091808]], ..., [[ 0.01688243, 0. , 0. ], [ 0.01060932, 0.0120037 , 0. ], [ 0.04580797, -0.00869739, 0.03189607]], [[ 0.02005698, 0. , 0. ], [ 0.01046687, 0.0131143 , 0. ], [ 0.04592615, -0.00799437, 0.03538846]], [[ 0.01761159, 0. , 0. ], [ 0.00880706, 0.00897023, 0. ], [ 0.04487011, -0.00348537, 0.03421569]]]]) - betaX_Canada(chain, draw, betaX_Canada_dim_0, betaX_Canada_dim_1)float640.01247 0.003499 ... -0.004845
array([[[[ 1.24700229e-02, 3.49888035e-03, 3.17631156e-03], [ 1.49572516e-02, 4.59849318e-03, 5.23948172e-03], [ 1.11409290e-02, 3.40311576e-03, 2.78466775e-03], ..., [ 9.42362534e-03, 3.02113378e-03, 4.26624859e-03], [ 6.09631303e-03, 2.33500972e-03, 3.17155501e-03], [-9.81937900e-03, -1.93179353e-03, -4.02832249e-03]], [[ 5.55326597e-03, 1.00136700e-02, 1.04013746e-02], [ 6.92007696e-03, 1.27153046e-02, 1.17002176e-02], [ 7.35928121e-03, 1.19274704e-02, 1.12212105e-02], ..., [ 4.08314668e-03, 8.75353028e-03, 6.65613365e-03], [ 2.43987976e-03, 5.95342126e-03, 4.05159400e-03], [ 1.05279891e-03, -2.47692220e-03, -3.40605712e-03]], [[ 7.65554518e-03, 5.41194263e-03, 9.54488372e-03], [ 9.15665658e-03, 6.88104456e-03, 1.11121618e-02], [ 6.89955222e-03, 7.08948466e-03, 9.77147290e-03], ..., ... ..., [ 2.45715187e-03, 5.19941214e-03, 4.34379533e-03], [ 1.35074050e-03, 4.05808015e-03, 3.73484744e-03], [-1.89123017e-03, 2.17836673e-03, -2.97893739e-04]], [[ 1.53180566e-03, 5.08215787e-03, 5.05360333e-03], [ 7.44626869e-04, 6.60363132e-03, 6.56758081e-03], [-2.40149387e-04, 7.51450347e-03, 5.22763736e-03], ..., [-3.34373481e-04, 5.14172725e-03, 4.62906142e-03], [-4.91254186e-04, 4.10078261e-03, 3.98687062e-03], [-3.50396455e-03, 3.47348333e-03, -9.08573735e-04]], [[ 5.34685825e-03, 1.25850786e-03, 5.32328941e-03], [ 5.91432977e-03, 1.19781114e-03, 7.31923031e-03], [ 6.34408641e-03, 1.90335124e-03, 5.12804004e-03], ..., [ 3.64558827e-03, 1.23370266e-03, 5.24797956e-03], [ 2.29374113e-03, 9.70973007e-04, 3.79256349e-03], [-2.35460757e-03, 8.93351321e-04, -4.84480591e-03]]]]) - noise_chol_Canada_corr(chain, draw, noise_chol_Canada_corr_dim_0, noise_chol_Canada_corr_dim_1)float641.0 0.1933 -0.2897 ... 0.07205 1.0
array([[[[ 1. , 0.19328004, -0.28966389], [ 0.19328004, 1. , 0.05903915], [-0.28966389, 0.05903915, 1. ]], [[ 1. , -0.14078658, -0.3333484 ], [-0.14078658, 1. , 0.00109628], [-0.3333484 , 0.00109628, 1. ]], [[ 1. , -0.17240732, -0.14634189], [-0.17240732, 1. , 0.14518812], [-0.14634189, 0.14518812, 1. ]], ..., [[ 1. , 0.10648015, 0.03994961], [ 0.10648015, 1. , -0.11973097], [ 0.03994961, -0.11973097, 1. ]], [[ 1. , 0.09151256, -0.13585816], [ 0.09151256, 1. , -0.00133437], ... [-0.14063703, 1. , -0.28907142], [-0.24782725, -0.28907142, 1. ]], [[ 1. , -0.31655828, -0.25260422], [-0.31655828, 1. , -0.11332257], [-0.25260422, -0.11332257, 1. ]], ..., [[ 1. , 0.18083947, 0.13559932], [ 0.18083947, 1. , -0.02197691], [ 0.13559932, -0.02197691, 1. ]], [[ 1. , 0.12001937, 0.49667666], [ 0.12001937, 1. , -0.06958886], [ 0.49667666, -0.06958886, 1. ]], [[ 1. , 0.41050003, 0.22813931], [ 0.41050003, 1. , 0.07204544], [ 0.22813931, 0.07204544, 1. ]]]]) - noise_chol_Canada_stds(chain, draw, noise_chol_Canada_stds_dim_0)float640.6638 0.2085 ... 0.2936 1.213
array([[[0.66384179, 0.20848881, 1.07124732], [0.67223062, 0.33682297, 0.91232871], [0.45749913, 0.32345847, 0.70680997], ..., [0.23020835, 0.25749084, 0.50378472], [0.58347185, 0.27866043, 0.53718941], [0.18709708, 0.28383023, 0.13075696]], [[0.68952306, 0.38286238, 0.87263223], [0.55548121, 0.46889733, 0.80054282], [0.4537614 , 0.50888115, 0.86099929], ..., [0.34183028, 0.34435015, 1.81518733], [0.32059482, 0.41286674, 1.11077189], [0.3560867 , 0.40310915, 1.57082235]], [[0.24603132, 0.31396591, 0.69534941], [0.22170782, 0.28096809, 1.12813663], [0.43843064, 0.24032078, 0.673225 ], ..., [0.48539611, 0.23639078, 1.13485029], [0.34601336, 0.19702292, 1.21354531], [0.87289064, 0.21110788, 0.61522443]], [[0.54622309, 0.43593431, 0.28842257], [0.65717069, 0.46764966, 1.19080717], [0.27563122, 0.54788095, 1.05204099], ..., [0.4678951 , 0.30428817, 0.70838538], [0.60572859, 0.28596595, 0.530754 ], [0.35621336, 0.29360534, 1.21302601]]]) - omega_Canada(chain, draw, omega_Canada_dim_0, omega_Canada_dim_1)float640.02925 0.0 ... -0.008251 0.0502
array([[[[ 2.92546585e-02, 0.00000000e+00, 0.00000000e+00], [ 1.58829560e-02, 8.67682572e-03, 0.00000000e+00], [ 3.40908404e-02, 1.17293320e-03, 4.47826285e-02]], [[ 2.53152303e-02, 0.00000000e+00, 0.00000000e+00], [ 1.36970189e-02, 1.07218602e-02, 0.00000000e+00], [ 3.95740937e-02, -8.84898064e-03, 3.65696665e-02]], [[ 2.27465270e-02, 0.00000000e+00, 0.00000000e+00], [ 1.34535147e-02, 9.30373197e-03, 0.00000000e+00], [ 3.84788893e-02, -2.01148218e-03, 2.90241723e-02]], ..., [[ 2.12011736e-02, 0.00000000e+00, 0.00000000e+00], [ 1.44090336e-02, 9.54577122e-03, 0.00000000e+00], [ 4.46739461e-02, -4.02683003e-03, 3.54981952e-02]], [[ 3.26507622e-02, 0.00000000e+00, 0.00000000e+00], [ 1.43879430e-02, 9.75922918e-03, 0.00000000e+00], ... [ 1.53337409e-02, 1.09701702e-02, 0.00000000e+00], [ 4.16406670e-02, -1.09259006e-02, 4.47574983e-02]], [[ 1.98468252e-02, 0.00000000e+00, 0.00000000e+00], [ 1.24135044e-02, 9.21640803e-03, 0.00000000e+00], [ 3.87763130e-02, -4.31859096e-03, 3.87772103e-02]], ..., [[ 2.77633495e-02, 0.00000000e+00, 0.00000000e+00], [ 1.43882668e-02, 9.94183087e-03, 0.00000000e+00], [ 4.54152589e-02, -8.59838307e-03, 3.50699796e-02]], [[ 3.25872062e-02, 0.00000000e+00, 0.00000000e+00], [ 1.50238703e-02, 9.08214401e-03, 0.00000000e+00], [ 4.98169093e-02, -1.03582216e-02, 2.97896361e-02]], [[ 2.53352789e-02, 0.00000000e+00, 0.00000000e+00], [ 1.65431644e-02, 9.47652540e-03, 0.00000000e+00], [ 4.84262120e-02, -8.25059215e-03, 5.02025697e-02]]]]) - betaX_Chile(chain, draw, betaX_Chile_dim_0, betaX_Chile_dim_1)float640.003003 0.006249 ... -0.00412
array([[[[ 3.00269072e-03, 6.24872689e-03, -9.55016990e-03], [-1.45623997e-02, -1.55714871e-02, -1.23016029e-02], [-1.15056639e-02, -4.98474488e-03, 1.00142545e-03], ..., [ 4.40286270e-03, 4.21659692e-03, 1.41303914e-02], [ 5.24313848e-03, 7.20257637e-03, 1.33433018e-02], [-7.25214830e-03, -3.39585308e-03, -1.63731319e-02]], [[ 1.27507817e-03, -4.89803702e-03, 1.92256262e-02], [-1.83711084e-02, -3.44935006e-02, 2.77951318e-03], [-6.24431318e-03, -1.60618990e-02, -6.40851652e-03], ..., [-9.03231703e-04, 1.08382348e-03, 3.30209617e-03], [ 5.27233353e-03, 8.86824000e-03, -1.15353010e-03], [ 1.16659387e-03, -5.20195709e-03, -1.38509917e-03]], [[ 9.89307608e-03, -5.74165359e-03, 7.91040108e-03], [-1.67669462e-02, -2.86250498e-02, 1.03911369e-02], [-1.51037867e-02, -1.20229355e-02, 9.08907897e-04], ..., ... ..., [-3.17410948e-07, 2.70798475e-03, -3.10499155e-03], [ 4.83756910e-03, 8.73702776e-03, -1.32916332e-03], [ 2.82261443e-04, -4.07766714e-03, 2.72946005e-03]], [[-1.05686768e-02, -2.80749013e-04, -1.03762948e-02], [-1.13119168e-02, -1.58087903e-02, -9.68889878e-03], [ 4.31255971e-03, -4.63753719e-03, -7.59437674e-05], ..., [ 4.49659370e-04, 2.87217458e-03, -1.86698162e-03], [ 3.82583331e-03, 8.99343334e-03, 1.06381035e-03], [-1.51498565e-03, -1.39370685e-03, -7.91374858e-04]], [[-5.77579546e-03, -1.14072896e-02, 2.38413016e-03], [-6.83860672e-03, -2.46730317e-02, -9.11421479e-04], [-1.14180209e-03, 1.08306232e-03, -1.70201083e-03], ..., [ 3.07333793e-03, 1.78565109e-03, 6.40907518e-03], [ 4.86858088e-03, 6.20895393e-03, 7.98444814e-03], [-4.94152216e-03, -5.58138556e-03, -4.11992869e-03]]]]) - noise_chol_Chile_corr(chain, draw, noise_chol_Chile_corr_dim_0, noise_chol_Chile_corr_dim_1)float641.0 0.6129 0.3999 ... 0.5206 1.0
array([[[[1. , 0.61285411, 0.39987636], [0.61285411, 1. , 0.09210604], [0.39987636, 0.09210604, 1. ]], [[1. , 0.50058186, 0.63135693], [0.50058186, 1. , 0.36835608], [0.63135693, 0.36835608, 1. ]], [[1. , 0.57156141, 0.65836342], [0.57156141, 1. , 0.3644959 ], [0.65836342, 0.3644959 , 1. ]], ..., [[1. , 0.61136954, 0.63824026], [0.61136954, 1. , 0.26365707], [0.63824026, 0.26365707, 1. ]], [[1. , 0.55530727, 0.56335901], [0.55530727, 1. , 0.27030894], ... [0.43938051, 1. , 0.07429358], [0.62810518, 0.07429358, 1. ]], [[1. , 0.63697676, 0.5034427 ], [0.63697676, 1. , 0.39377102], [0.5034427 , 0.39377102, 1. ]], ..., [[1. , 0.50260036, 0.27765771], [0.50260036, 1. , 0.2654174 ], [0.27765771, 0.2654174 , 1. ]], [[1. , 0.59924247, 0.39082225], [0.59924247, 1. , 0.31288678], [0.39082225, 0.31288678, 1. ]], [[1. , 0.59940686, 0.59922862], [0.59940686, 1. , 0.52060502], [0.59922862, 0.52060502, 1. ]]]]) - noise_chol_Chile_stds(chain, draw, noise_chol_Chile_stds_dim_0)float641.271 1.624 3.6 ... 1.68 2.743
array([[[1.2713373 , 1.62414038, 3.59991746], [1.40839471, 1.64880118, 3.31877818], [1.05662488, 1.71732613, 3.42270954], ..., [1.02995934, 1.60248178, 2.69900726], [0.76983079, 1.4651506 , 2.20052647], [0.99565962, 1.60421725, 2.68589717]], [[0.91491713, 1.34253895, 2.2662561 ], [1.54426339, 2.00255192, 2.8945698 ], [1.27900868, 2.17221178, 3.52071618], ..., [0.80886664, 1.52772598, 2.89590313], [0.82952097, 1.32740011, 2.73284552], [0.79969338, 1.26148752, 2.85823385]], [[0.91773985, 1.56062253, 2.79411 ], [1.00685964, 1.2855223 , 2.78101382], [0.93764767, 1.47389141, 2.23833153], ..., [1.24101022, 1.8708186 , 3.69690198], [1.31056705, 1.81169217, 3.36838218], [1.07192233, 1.32214889, 2.47574968]], [[1.29850511, 2.08605599, 3.33642843], [1.52666923, 1.95601462, 3.53240985], [1.5267606 , 2.81179684, 3.85790135], ..., [0.87863276, 1.72022698, 2.82345444], [1.00752757, 1.40806588, 2.55055337], [0.84373496, 1.68048138, 2.74291593]]]) - omega_Chile(chain, draw, omega_Chile_dim_0, omega_Chile_dim_1)float640.04516 0.0 0.0 ... 0.006101 0.0735
array([[[[ 0.04516462, 0. , 0. ], [ 0.04089555, 0.03693081, 0. ], [ 0.07991772, -0.02036609, 0.10259708]], [[ 0.04142842, 0. , 0. ], [ 0.03280046, 0.03466477, 0. ], [ 0.0920935 , -0.00353505, 0.07392714]], [[ 0.03641313, 0. , 0. ], [ 0.03711581, 0.03418023, 0. ], [ 0.09224015, -0.00509764, 0.07195252]], ..., [[ 0.04285858, 0. , 0. ], [ 0.04019725, 0.03695334, 0. ], [ 0.09077766, -0.01401341, 0.07701291]], [[ 0.03766407, 0. , 0. ], [ 0.03558912, 0.03507327, 0. ], ... [ 0.03160417, 0.03372773, 0. ], [ 0.08584851, -0.01802142, 0.07194311]], [[ 0.03995506, 0. , 0. ], [ 0.04398685, 0.03570095, 0. ], [ 0.07426316, 0.0050056 , 0.07603408]], ..., [[ 0.03857175, 0. , 0. ], [ 0.03569151, 0.0412009 , 0. ], [ 0.06351702, 0.00310009, 0.0871746 ]], [[ 0.04293945, 0. , 0. ], [ 0.03587916, 0.0308109 , 0. ], [ 0.0687076 , -0.00211939, 0.07819696]], [[ 0.03735921, 0. , 0. ], [ 0.03841383, 0.03604897, 0. ], [ 0.08213845, 0.00610096, 0.07349513]]]]) - betaX_Ireland(chain, draw, betaX_Ireland_dim_0, betaX_Ireland_dim_1)float640.01648 0.01726 ... -0.02733
array([[[[ 1.64836620e-02, 1.72578353e-02, 1.64182659e-02], [ 2.43504450e-02, 1.84689416e-02, 2.00754020e-02], [ 7.33619607e-03, 1.19017325e-02, 1.36770851e-02], ..., [-5.87607967e-04, 3.44866967e-03, 1.11521468e-02], [ 5.30266531e-02, 2.36051004e-02, 2.24552156e-02], [ 2.51764667e-02, 4.21411050e-02, 2.89011406e-02]], [[ 7.82774644e-03, 1.64443423e-02, 2.36731975e-02], [ 1.12804312e-02, 1.05602182e-02, 3.44037527e-02], [ 1.07559303e-02, 2.75232881e-02, 1.71403673e-03], ..., [-4.51099742e-03, 1.96146605e-02, 5.70295261e-03], [ 1.80841877e-02, -3.41386122e-02, 8.59956360e-02], [ 5.61955592e-02, 6.12612971e-02, -6.26802772e-03]], [[ 1.74751828e-02, 2.86672623e-02, 1.74833159e-02], [ 1.88330456e-02, 2.82139302e-02, 2.75691533e-02], [ 1.47183887e-02, 3.21766449e-02, -1.83083612e-02], ..., ... ..., [-9.91041283e-03, 1.85968541e-02, 6.60602392e-03], [ 1.13933117e-02, 2.35398549e-03, -1.07360996e-02], [ 4.99000324e-02, 7.04399668e-02, -7.62368101e-02]], [[ 6.18025714e-04, 1.83210873e-02, 6.20114060e-03], [ 4.27276181e-03, 1.68986884e-02, 6.71994714e-03], [ 7.43417339e-04, 2.81270925e-02, 4.19910060e-03], ..., [-1.38228245e-02, 1.97494034e-02, 1.53752579e-02], [ 1.83463571e-02, -2.04016832e-02, 8.62400171e-03], [ 4.52241270e-02, 5.87861112e-02, -3.03262169e-02]], [[ 7.46063846e-03, 2.43506583e-02, -5.49236629e-03], [ 7.99655643e-03, 1.88982657e-02, -5.19542351e-03], [ 5.77313098e-03, 3.52912201e-02, -4.08544848e-03], ..., [-1.18675129e-02, 2.35309218e-02, -2.47016723e-03], [ 1.33567965e-02, -2.49183450e-02, 1.01166132e-03], [ 6.59684494e-02, 8.88266272e-02, -2.73254140e-02]]]]) - noise_chol_Ireland_corr(chain, draw, noise_chol_Ireland_corr_dim_0, noise_chol_Ireland_corr_dim_1)float641.0 0.03333 0.2175 ... 0.2948 1.0
array([[[[ 1.00000000e+00, 3.33342673e-02, 2.17495962e-01], [ 3.33342673e-02, 1.00000000e+00, 1.50420841e-01], [ 2.17495962e-01, 1.50420841e-01, 1.00000000e+00]], [[ 1.00000000e+00, -2.59961345e-01, -1.83604558e-01], [-2.59961345e-01, 1.00000000e+00, 5.43763057e-01], [-1.83604558e-01, 5.43763057e-01, 1.00000000e+00]], [[ 1.00000000e+00, -2.24535655e-01, 2.27162374e-02], [-2.24535655e-01, 1.00000000e+00, 3.68930801e-01], [ 2.27162374e-02, 3.68930801e-01, 1.00000000e+00]], ..., [[ 1.00000000e+00, 7.84638734e-03, 2.52670685e-01], [ 7.84638734e-03, 1.00000000e+00, 2.25266813e-01], [ 2.52670685e-01, 2.25266813e-01, 1.00000000e+00]], [[ 1.00000000e+00, 5.42195183e-02, 1.39904599e-01], [ 5.42195183e-02, 1.00000000e+00, 1.33651491e-01], ... [-2.49106507e-01, 1.00000000e+00, 1.60642213e-01], [ 2.49916275e-01, 1.60642213e-01, 1.00000000e+00]], [[ 1.00000000e+00, 4.35927922e-02, 1.08673539e-02], [ 4.35927922e-02, 1.00000000e+00, 2.08335723e-01], [ 1.08673539e-02, 2.08335723e-01, 1.00000000e+00]], ..., [[ 1.00000000e+00, -1.43199383e-01, 1.28602749e-01], [-1.43199383e-01, 1.00000000e+00, 2.40435719e-01], [ 1.28602749e-01, 2.40435719e-01, 1.00000000e+00]], [[ 1.00000000e+00, -3.92398800e-02, 1.54895511e-01], [-3.92398800e-02, 1.00000000e+00, 3.18864917e-01], [ 1.54895511e-01, 3.18864917e-01, 1.00000000e+00]], [[ 1.00000000e+00, -7.61891204e-02, 8.96321521e-02], [-7.61891204e-02, 1.00000000e+00, 2.94752950e-01], [ 8.96321521e-02, 2.94752950e-01, 1.00000000e+00]]]]) - noise_chol_Ireland_stds(chain, draw, noise_chol_Ireland_stds_dim_0)float641.099 0.889 5.445 ... 0.7554 5.359
array([[[1.09856315, 0.88901252, 5.44525567], [1.07918067, 0.79173747, 6.35467293], [1.24444094, 0.90287933, 6.77229604], ..., [1.11717345, 0.73017693, 4.38263384], [0.79322542, 0.73202497, 5.07505363], [0.79691695, 0.75875025, 4.36341961]], [[1.20283767, 0.54777345, 4.65362658], [1.53763364, 0.75642027, 5.81766776], [1.16328075, 0.93651123, 5.99160043], ..., [1.25065627, 0.71665283, 6.28527513], [1.2169064 , 0.75343536, 5.39141314], [1.17824027, 0.6533815 , 4.65254295]], [[0.75713346, 0.68163394, 4.42842643], [0.70207832, 0.67130676, 5.78454619], [1.0214115 , 0.66706679, 4.34632939], ..., [1.30702197, 0.89851183, 6.58625894], [1.40896661, 0.88093035, 6.78873108], [0.90044203, 0.64658868, 4.13419835]], [[1.18230319, 1.19215547, 6.00616917], [1.6018197 , 1.28117501, 7.68278202], [1.84183924, 1.28813938, 7.38414326], ..., [0.74949096, 0.81424938, 4.41888313], [0.97737268, 0.86168422, 4.74508525], [0.85502325, 0.75541657, 5.35855291]]]) - omega_Ireland(chain, draw, omega_Ireland_dim_0, omega_Ireland_dim_1)float640.04064 0.0 0.0 ... 0.03243 0.1465
array([[[[ 0.04063976, 0. , 0. ], [ 0.01560372, 0.02658937, 0. ], [ 0.07323416, 0.0183125 , 0.15581926]], [[ 0.03422257, 0. , 0. ], [ 0.01022993, 0.02015667, 0. ], [ 0.02069296, 0.06352592, 0.13433755]], [[ 0.04069738, 0. , 0. ], [ 0.01010118, 0.02210544, 0. ], [ 0.04434761, 0.05532029, 0.15580224]], ..., [[ 0.04522035, 0. , 0. ], [ 0.01382171, 0.02238523, 0. ], [ 0.07411653, 0.02417507, 0.13370487]], [[ 0.03829342, 0. , 0. ], [ 0.01476965, 0.02195785, 0. ], ... [ 0.01087785, 0.02464814, 0. ], [ 0.08059611, 0.0270211 , 0.1527325 ]], [[ 0.04501903, 0. , 0. ], [ 0.01610349, 0.02154706, 0. ], [ 0.04433719, 0.02381899, 0.13885813]], ..., [[ 0.03517344, 0. , 0. ], [ 0.00987196, 0.02327246, 0. ], [ 0.05784165, 0.02269594, 0.12785515]], [[ 0.04216251, 0. , 0. ], [ 0.01326842, 0.02395153, 0. ], [ 0.06196187, 0.0311782 , 0.13210447]], [[ 0.03763762, 0. , 0. ], [ 0.01215112, 0.02145044, 0. ], [ 0.05344668, 0.03243153, 0.1464945 ]]]]) - betaX_New Zealand(chain, draw, betaX_New Zealand_dim_0, betaX_New Zealand_dim_1)float64-0.001764 0.001355 ... -0.001023
array([[[[-1.76372364e-03, 1.35525819e-03, 2.02611146e-03], [ 1.76226292e-03, -1.40595699e-03, -7.01848911e-04], [ 6.77369237e-03, 9.44922545e-03, 7.84322633e-03], ..., [ 7.25825653e-03, 1.47405243e-02, 9.98505146e-03], [ 6.96508463e-03, 1.52436204e-02, 1.07166853e-02], [ 5.39886989e-03, 1.24515738e-02, 8.74174581e-03]], [[-7.33507167e-04, -1.98169808e-03, -5.63322918e-03], [ 5.34343160e-03, 1.49920196e-03, 4.23808747e-03], [ 1.00199291e-02, 1.06386052e-02, 1.78459333e-02], ..., [ 6.39741247e-03, 1.02239745e-02, 1.15700503e-02], [ 4.58740417e-03, 1.02182004e-02, 1.05329555e-02], [ 2.88523371e-03, 7.76261089e-03, 7.10482735e-03]], [[-3.29875020e-03, -3.50267944e-03, -4.86952563e-04], [ 7.27952619e-03, 7.06963951e-04, -5.50758663e-03], [ 1.58605090e-02, 1.32553477e-02, 7.81357852e-03], ..., ... ..., [ 3.10420929e-03, 7.87559969e-03, 7.96009257e-03], [ 2.86378859e-03, 8.30486587e-03, 6.22048805e-03], [ 1.63544841e-03, 6.62238454e-03, 4.42948689e-03]], [[-1.30996446e-03, 1.55487298e-03, -2.08606111e-03], [ 1.73072691e-03, -1.71345519e-03, 5.93278825e-03], [ 6.49868797e-03, 8.14610668e-03, 7.72636310e-03], ..., [ 1.57982970e-03, 1.00528358e-02, 4.64339627e-03], [ 1.46055332e-03, 1.11614280e-02, 2.42898064e-03], [ 2.51884702e-04, 9.01327227e-03, 1.40423677e-03]], [[-1.66947133e-03, 4.49148200e-03, 7.98465719e-06], [ 2.45136274e-03, -1.83504208e-03, 1.50542664e-03], [ 2.43912078e-03, 1.75038892e-03, -1.34805785e-03], ..., [ 1.25911370e-03, 6.16133924e-03, 1.04761826e-04], [ 8.44121536e-04, 6.76096491e-03, -1.54309646e-03], [ 2.94218980e-04, 6.08009144e-03, -1.02344794e-03]]]]) - noise_chol_New Zealand_corr(chain, draw, noise_chol_New Zealand_corr_dim_0, noise_chol_New Zealand_corr_dim_1)float641.0 -0.261 0.1799 ... 0.1502 1.0
array([[[[ 1. , -0.26103948, 0.1799095 ], [-0.26103948, 1. , 0.18151346], [ 0.1799095 , 0.18151346, 1. ]], [[ 1. , -0.08742612, 0.11463748], [-0.08742612, 1. , -0.2364093 ], [ 0.11463748, -0.2364093 , 1. ]], [[ 1. , -0.28301592, 0.00105696], [-0.28301592, 1. , -0.2199193 ], [ 0.00105696, -0.2199193 , 1. ]], ..., [[ 1. , -0.20290854, 0.05859711], [-0.20290854, 1. , -0.01508477], [ 0.05859711, -0.01508477, 1. ]], [[ 1. , 0.01844096, 0.35830256], [ 0.01844096, 1. , -0.07586697], ... [-0.37043066, 1. , 0.28849878], [ 0.29637054, 0.28849878, 1. ]], [[ 1. , -0.43535589, 0.00774529], [-0.43535589, 1. , -0.15615354], [ 0.00774529, -0.15615354, 1. ]], ..., [[ 1. , -0.41551535, 0.33174242], [-0.41551535, 1. , 0.04805351], [ 0.33174242, 0.04805351, 1. ]], [[ 1. , -0.25748007, 0.27593397], [-0.25748007, 1. , 0.13310236], [ 0.27593397, 0.13310236, 1. ]], [[ 1. , -0.19664719, 0.36554005], [-0.19664719, 1. , 0.150203 ], [ 0.36554005, 0.150203 , 1. ]]]]) - noise_chol_New Zealand_stds(chain, draw, noise_chol_New Zealand_stds_dim_0)float640.3045 0.2385 1.12 ... 0.4065 1.071
array([[[3.04534370e-01, 2.38521201e-01, 1.12038400e+00], [3.82169968e-01, 4.65253294e-01, 1.29437459e+00], [2.55826468e-01, 3.67222498e-01, 1.37690664e+00], ..., [2.05796473e-01, 2.78469568e-01, 1.01595357e+00], [4.82275138e-02, 3.52312849e-01, 8.60660486e-01], [9.96422216e-02, 3.18282233e-01, 7.08427063e-01]], [[2.96598158e-01, 2.81750195e-01, 1.23858942e+00], [3.68460688e-01, 2.85802825e-01, 1.58625384e+00], [2.66135207e-02, 3.33540996e-01, 1.48833319e+00], ..., [2.42703239e-01, 4.22863294e-01, 1.62550222e+00], [1.68752066e-01, 4.14486419e-01, 1.42264760e+00], [2.26454537e-01, 4.29511347e-01, 1.29795254e+00]], [[1.00180477e-01, 4.77008616e-01, 7.48245655e-01], [1.34293327e-01, 3.61395761e-01, 9.26934975e-01], [4.37944414e-02, 4.28662914e-01, 9.59362065e-01], ..., [3.26785762e-01, 3.03852946e-01, 1.32595851e+00], [2.97884495e-01, 3.53191395e-01, 1.37299126e+00], [3.22936817e-01, 3.53322178e-01, 1.03226229e+00]], [[1.13775785e-01, 4.77763837e-01, 9.55470465e-01], [1.42230904e-01, 4.41212942e-01, 9.87938056e-01], [7.12239451e-02, 6.48104937e-01, 1.15193371e+00], ..., [3.32437466e-03, 3.30767916e-01, 1.49072766e+00], [3.17245931e-03, 3.10529148e-01, 1.13832807e+00], [1.14414877e-03, 4.06543350e-01, 1.07140500e+00]]]) - omega_New Zealand(chain, draw, omega_New Zealand_dim_0, omega_New Zealand_dim_1)float640.01984 0.0 ... -0.001556 0.04494
array([[[[ 0.0198446 , 0. , 0. ], [ 0.01319696, 0.00934973, 0. ], [ 0.04749641, 0.00482864, 0.04614774]], [[ 0.01896637, 0. , 0. ], [ 0.01384465, 0.01356738, 0. ], [ 0.04947859, -0.01436299, 0.04516365]], [[ 0.01814619, 0. , 0. ], [ 0.01235487, 0.01007004, 0. ], [ 0.04087155, -0.01116694, 0.04377006]], ..., [[ 0.0205401 , 0. , 0. ], [ 0.01213642, 0.00999665, 0. ], [ 0.04574107, -0.00241545, 0.04943785]], [[ 0.01825196, 0. , 0. ], [ 0.01387671, 0.01177042, 0. ], ... [ 0.01361614, 0.01003502, 0. ], [ 0.05197953, 0.00337521, 0.04048826]], [[ 0.01656158, 0. , 0. ], [ 0.01066615, 0.01024111, 0. ], [ 0.04319086, -0.0040152 , 0.04102882]], ..., [[ 0.01553835, 0. , 0. ], [ 0.00932359, 0.00998369, 0. ], [ 0.05590114, 0.00030017, 0.05274987]], [[ 0.01706251, 0. , 0. ], [ 0.01207957, 0.00949851, 0. ], [ 0.05111778, -0.00238222, 0.04555566]], [[ 0.01657807, 0. , 0. ], [ 0.01159888, 0.01270442, 0. ], [ 0.0512601 , -0.00155637, 0.04493924]]]]) - betaX_South Africa(chain, draw, betaX_South Africa_dim_0, betaX_South Africa_dim_1)float640.004925 0.01035 ... -0.002743
array([[[[ 4.92477337e-03, 1.03488014e-02, 1.67717620e-02], [ 4.32435160e-03, 3.91730303e-03, 2.67024819e-02], [ 5.85941669e-03, 6.08892086e-03, 2.71249215e-02], ..., [ 2.00654636e-03, 2.83766727e-04, 5.68007915e-03], [ 2.14998996e-03, 2.16766524e-03, 2.38793085e-03], [ 2.76682380e-03, 4.27981426e-03, -3.05339838e-02]], [[-4.97662591e-04, 7.41471039e-03, 6.69020614e-03], [ 1.16834788e-03, 9.77819530e-03, 4.29382253e-03], [ 1.79620485e-03, 1.38927964e-02, 8.00042377e-03], ..., [-4.88999869e-04, 4.77078413e-03, -1.05815533e-03], [-1.16997372e-03, 3.69873336e-03, -1.39553035e-03], [-9.53720437e-03, -5.05125885e-03, -1.18212411e-02]], [[ 1.71251393e-03, 7.07095518e-03, 6.18888899e-03], [ 3.40542884e-04, 5.58770770e-03, 7.12103121e-03], [ 8.01976717e-04, 8.98069910e-03, 8.92572794e-03], ..., ... ..., [ 1.15226380e-03, 1.91149281e-03, -4.87228787e-04], [ 1.64967287e-03, 2.09344683e-03, -2.42887920e-03], [ 8.08280694e-03, 4.38379543e-03, -2.61536007e-02]], [[ 3.51350470e-03, 5.16306728e-03, 1.14478061e-02], [ 3.32474240e-03, 4.46254142e-03, 1.24576395e-02], [ 4.36563776e-03, 6.23398176e-03, 1.55351359e-02], ..., [ 1.98228326e-03, 2.71357226e-03, 5.54662649e-04], [ 2.03929097e-03, 3.03869428e-03, -7.55485240e-04], [ 3.60510920e-03, 3.55289045e-03, -2.17092809e-02]], [[ 2.11524685e-03, 7.40829954e-03, 5.40311009e-03], [-1.12407675e-03, 4.43711011e-03, 4.67768445e-03], [ 5.60675386e-04, 4.52186968e-03, 4.46295420e-03], ..., [ 1.26343689e-03, -1.79230279e-05, -5.60797573e-04], [ 2.33385298e-03, 4.07356663e-04, -5.71025786e-04], [ 9.04329474e-03, 2.78928006e-03, -2.74255936e-03]]]]) - noise_chol_South Africa_corr(chain, draw, noise_chol_South Africa_corr_dim_0, noise_chol_South Africa_corr_dim_1)float641.0 0.3134 0.3718 ... 0.3246 1.0
array([[[[ 1. , 0.31340689, 0.37177584], [ 0.31340689, 1. , 0.07821922], [ 0.37177584, 0.07821922, 1. ]], [[ 1. , 0.21585394, -0.01498537], [ 0.21585394, 1. , 0.49303792], [-0.01498537, 0.49303792, 1. ]], [[ 1. , 0.31726026, 0.00430444], [ 0.31726026, 1. , 0.23973121], [ 0.00430444, 0.23973121, 1. ]], ..., [[ 1. , 0.2982329 , 0.07047868], [ 0.2982329 , 1. , 0.28969585], [ 0.07047868, 0.28969585, 1. ]], [[ 1. , 0.48468315, 0.1270014 ], [ 0.48468315, 1. , 0.23816423], ... [ 0.36848594, 1. , 0.20173571], [ 0.15172166, 0.20173571, 1. ]], [[ 1. , -0.09939339, -0.09001966], [-0.09939339, 1. , 0.246294 ], [-0.09001966, 0.246294 , 1. ]], ..., [[ 1. , 0.49192847, 0.15722143], [ 0.49192847, 1. , 0.29030496], [ 0.15722143, 0.29030496, 1. ]], [[ 1. , 0.40425884, 0.16604949], [ 0.40425884, 1. , 0.31644025], [ 0.16604949, 0.31644025, 1. ]], [[ 1. , 0.71214665, 0.22512108], [ 0.71214665, 1. , 0.32460632], [ 0.22512108, 0.32460632, 1. ]]]]) - noise_chol_South Africa_stds(chain, draw, noise_chol_South Africa_stds_dim_0)float640.5349 0.431 1.158 ... 0.4302 1.215
array([[[0.53491119, 0.43096338, 1.15824286], [0.45006859, 0.35684383, 1.5885366 ], [0.52911664, 0.43826098, 1.76829858], ..., [0.23929478, 0.30540305, 1.50599346], [0.14620517, 0.45102983, 0.76363429], [0.28107478, 0.34724727, 1.15130411]], [[0.49119883, 0.35511895, 1.2359541 ], [0.49160659, 0.37286036, 0.95768854], [0.25065236, 0.50137585, 1.59148099], ..., [0.30518656, 0.53886371, 1.78000421], [0.33670211, 0.38883329, 1.66176677], [0.27916421, 0.49112526, 2.23205404]], [[0.18622751, 0.30379024, 1.47280193], [0.2317029 , 0.33054694, 1.06820261], [0.33985707, 0.35578534, 1.58447067], ..., [0.40043675, 0.38138817, 1.58591225], [0.43754413, 0.38519242, 1.48266707], [0.50844278, 0.29928312, 1.03343328]], [[0.26213754, 0.42430145, 1.13051579], [0.51324612, 0.52382017, 1.03951709], [0.26241434, 0.6543379 , 1.67900713], ..., [0.30151799, 0.61119872, 1.00398122], [0.29867705, 0.69957259, 0.8696062 ], [0.38222619, 0.43017794, 1.21473577]]]) - omega_South Africa(chain, draw, omega_South Africa_dim_0, omega_South Africa_dim_1)float640.02588 0.0 ... -0.0005307 0.04942
array([[[[ 0.02587804, 0. , 0. ], [ 0.01836493, 0.01403763, 0. ], [ 0.05349481, -0.00333952, 0.04626514]], [[ 0.02045254, 0. , 0. ], [ 0.0164209 , 0.01104938, 0. ], [ 0.04570972, 0.00974748, 0.04770504]], [[ 0.02438019, 0. , 0. ], [ 0.01789729, 0.0115165 , 0. ], [ 0.04101198, 0.00616365, 0.05223724]], ..., [[ 0.02144724, 0. , 0. ], [ 0.01613305, 0.01050653, 0. ], [ 0.04700323, 0.00915405, 0.06100091]], [[ 0.02088769, 0. , 0. ], [ 0.01958275, 0.01290723, 0. ], ... [ 0.01988475, 0.01139151, 0. ], [ 0.04960407, -0.00120676, 0.04350152]], [[ 0.0196344 , 0. , 0. ], [ 0.01415571, 0.01132816, 0. ], [ 0.04061827, 0.00556347, 0.04887737]], ..., [[ 0.0233852 , 0. , 0. ], [ 0.02085216, 0.01606946, 0. ], [ 0.04704126, -0.00125472, 0.04190013]], [[ 0.02467611, 0. , 0. ], [ 0.02142607, 0.01825339, 0. ], [ 0.04674536, -0.0024714 , 0.03928832]], [[ 0.02597684, 0. , 0. ], [ 0.02112623, 0.01032176, 0. ], [ 0.04834541, -0.0005307 , 0.04941882]]]]) - betaX_United Kingdom(chain, draw, betaX_United Kingdom_dim_0, betaX_United Kingdom_dim_1)float640.006215 0.007962 ... -0.0008488
array([[[[ 6.21527654e-03, 7.96242658e-03, 7.88051157e-03], [ 1.15171077e-02, 1.16361614e-02, 1.48235468e-02], [ 1.60614500e-03, 4.64278585e-03, 5.09645397e-03], ..., [ 3.11837065e-03, 4.52830660e-03, 3.85966222e-03], [ 2.72398143e-03, 3.12844071e-03, 3.78236467e-03], [-1.34696113e-02, -1.24753844e-02, -1.27756146e-02]], [[ 4.57886040e-03, 7.46487033e-03, 6.37450381e-03], [ 6.72372630e-03, 9.75144856e-03, 4.85785417e-03], [-2.40024310e-03, 9.83485240e-03, 3.45607862e-03], ..., [ 2.18882061e-03, 4.62963920e-03, 4.21873249e-03], [ 1.49583464e-03, 3.17624696e-03, 1.53531195e-03], [-1.32462642e-02, -2.22963646e-03, -9.45690105e-03]], [[ 3.05786456e-03, 5.72964323e-03, 1.41988294e-02], [ 3.84512745e-03, 8.16457708e-03, 1.99662356e-02], [ 5.74171450e-03, 7.84849071e-03, 7.32288675e-03], ..., ... ..., [ 2.63601200e-04, 9.58823988e-04, 2.74848285e-03], [ 4.17599347e-04, 8.03252204e-04, 2.32558242e-03], [-9.59425164e-04, -7.43012309e-03, -8.41686030e-03]], [[ 1.00242066e-03, 4.81168942e-04, 5.58231368e-03], [-4.21113612e-04, 1.20499479e-03, 6.14387145e-03], [ 2.62728541e-04, 1.78384078e-03, 3.48250277e-03], ..., [-5.73395517e-04, 5.29181893e-04, 3.16248307e-03], [ 5.72243946e-04, 2.23936860e-04, 1.89344881e-03], [ 2.17874407e-03, -3.72872663e-04, -7.26549941e-03]], [[ 1.71332328e-03, 2.29020264e-03, 2.69870951e-03], [ 1.99736573e-03, 5.71654164e-03, 5.37697455e-03], [-1.16874867e-03, 8.01736567e-03, 3.20344007e-03], ..., [-2.77691368e-04, 1.60241469e-03, 1.46174472e-03], [ 9.20442780e-04, 1.73041839e-03, 1.53158472e-03], [-2.73090553e-03, 4.47796455e-03, -8.48761300e-04]]]]) - noise_chol_United Kingdom_corr(chain, draw, noise_chol_United Kingdom_corr_dim_0, noise_chol_United Kingdom_corr_dim_1)float641.0 0.5468 -0.08382 ... -0.3961 1.0
array([[[[ 1. , 0.54681343, -0.08381696], [ 0.54681343, 1. , -0.08092586], [-0.08381696, -0.08092586, 1. ]], [[ 1. , 0.53047327, -0.21048533], [ 0.53047327, 1. , -0.07649641], [-0.21048533, -0.07649641, 1. ]], [[ 1. , 0.21884439, -0.30994369], [ 0.21884439, 1. , 0.00211945], [-0.30994369, 0.00211945, 1. ]], ..., [[ 1. , 0.61098734, -0.15671942], [ 0.61098734, 1. , -0.04346526], [-0.15671942, -0.04346526, 1. ]], [[ 1. , 0.43507977, -0.15288278], [ 0.43507977, 1. , -0.12857772], ... [ 0.45357421, 1. , -0.10553591], [-0.25567594, -0.10553591, 1. ]], [[ 1. , 0.27843166, -0.14093499], [ 0.27843166, 1. , -0.15293376], [-0.14093499, -0.15293376, 1. ]], ..., [[ 1. , 0.49718739, -0.10810989], [ 0.49718739, 1. , 0.1261408 ], [-0.10810989, 0.1261408 , 1. ]], [[ 1. , 0.37601611, -0.12683991], [ 0.37601611, 1. , 0.10034105], [-0.12683991, 0.10034105, 1. ]], [[ 1. , 0.67810689, -0.11132734], [ 0.67810689, 1. , -0.39613488], [-0.11132734, -0.39613488, 1. ]]]]) - noise_chol_United Kingdom_stds(chain, draw, noise_chol_United Kingdom_stds_dim_0)float640.5181 0.3656 ... 0.502 0.3273
array([[[0.51805797, 0.36561912, 0.41219843], [0.68063806, 0.3258411 , 0.64850899], [0.51016555, 0.36411294, 0.61003021], ..., [0.49340154, 0.36172116, 0.41739266], [0.27505083, 0.34639281, 0.14758779], [0.50307347, 0.41092623, 0.08538175]], [[0.6697906 , 0.40899173, 0.73265156], [0.63231443, 0.40987279, 0.8585983 ], [0.33083785, 0.45004791, 0.92705803], ..., [0.48935691, 0.49467794, 1.01295998], [0.44510797, 0.52991035, 1.08132399], [0.47965262, 0.45470307, 1.13437158]], [[0.34954657, 0.30423 , 0.33940372], [0.3663739 , 0.28138215, 0.46673025], [0.3639808 , 0.35480344, 0.50010027], ..., [0.63094498, 0.33266783, 0.62103783], [0.65253291, 0.35838869, 0.6875826 ], [0.55743991, 0.2230277 , 0.52674879]], [[0.45621561, 0.4814433 , 0.15078173], [0.75799236, 0.50949934, 0.4323404 ], [0.73309182, 0.73403857, 0.23684961], ..., [0.35197736, 0.39981316, 0.68034878], [0.33940493, 0.3816481 , 0.50998822], [0.49475088, 0.50196129, 0.32731979]]]) - omega_United Kingdom(chain, draw, omega_United Kingdom_dim_0, omega_United Kingdom_dim_1)float640.02544 0.0 ... -0.01106 0.02829
array([[[[ 0.02543666, 0. , 0. ], [ 0.02006354, 0.01133659, 0. ], [ 0.04131264, -0.00256865, 0.02887998]], [[ 0.02549925, 0. , 0. ], [ 0.0185183 , 0.00946872, 0. ], [ 0.043243 , -0.00733574, 0.03162954]], [[ 0.0239479 , 0. , 0. ], [ 0.01654327, 0.01014025, 0. ], [ 0.03652538, -0.00297742, 0.02638851]], ..., [[ 0.02832849, 0. , 0. ], [ 0.01965147, 0.01036701, 0. ], [ 0.04235752, -0.00157911, 0.03311147]], [[ 0.02435381, 0. , 0. ], [ 0.0177562 , 0.01068459, 0. ], ... [ 0.02055434, 0.01081319, 0. ], [ 0.04488657, -0.0039854 , 0.03301123]], [[ 0.02719916, 0. , 0. ], [ 0.01848579, 0.01219467, 0. ], [ 0.04251097, -0.00132384, 0.02652562]], ..., [[ 0.02471302, 0. , 0. ], [ 0.01817112, 0.01119504, 0. ], [ 0.04095206, -0.00400516, 0.03402911]], [[ 0.02572545, 0. , 0. ], [ 0.01783698, 0.01087901, 0. ], [ 0.04135835, -0.0064794 , 0.03091845]], [[ 0.02875208, 0. , 0. ], [ 0.02196562, 0.01197236, 0. ], [ 0.04070217, -0.01106366, 0.02829107]]]]) - betaX_United States(chain, draw, betaX_United States_dim_0, betaX_United States_dim_1)float640.009227 0.003603 ... 0.009821
array([[[[ 9.22722045e-03, 3.60275979e-03, 1.03413214e-03], [-3.34614989e-04, -4.28796096e-03, -1.35563330e-02], [ 5.11764460e-04, 6.43801265e-03, 7.73929452e-03], ..., [ 5.76870749e-03, 6.27007420e-03, 8.23227802e-03], [ 7.38431288e-03, 8.69752703e-03, 1.00594222e-02], [ 7.96822737e-03, 7.90918043e-03, 8.92412008e-03]], [[ 5.09639332e-03, 8.26151542e-03, 3.80693518e-04], [ 2.42408780e-03, 1.42977368e-03, -1.72811375e-03], [-9.40735942e-04, -3.31338691e-03, 1.03571680e-02], ..., [ 6.83335339e-04, 2.23986284e-03, 5.60782260e-03], [ 9.64568428e-04, 2.62831868e-03, 6.90049169e-03], [ 1.70169434e-03, 3.80864674e-03, 5.99356634e-03]], [[ 8.69689260e-03, 7.00224941e-03, 9.86526589e-06], [ 2.31349350e-03, 1.78440350e-03, -3.00448101e-03], [-2.42490086e-03, -1.88417718e-03, 1.32421872e-02], ..., ... ..., [ 2.61912113e-03, 1.64929777e-03, 9.36155922e-03], [ 2.74610370e-03, 2.23750225e-03, 1.07090483e-02], [ 4.07038526e-03, 1.67622153e-03, 9.23124744e-03]], [[ 7.08269640e-03, 3.31030736e-04, 1.41251160e-03], [-1.13619758e-03, -3.66125307e-03, -3.95184935e-03], [-9.69577767e-04, 1.13394403e-03, 1.49765738e-02], ..., [ 2.80170646e-03, 2.35261424e-03, 8.50181539e-03], [ 2.97485313e-03, 3.36437811e-03, 9.72913924e-03], [ 3.99169638e-03, 2.90549668e-03, 8.80270684e-03]], [[ 5.76478736e-03, -5.12266740e-04, 4.32993535e-03], [-8.04535286e-04, -5.02750672e-03, -2.30536451e-03], [ 4.31438297e-03, 5.49012222e-03, 1.32219934e-02], ..., [ 4.21131517e-03, 4.35513754e-03, 8.79475388e-03], [ 4.40069853e-03, 4.85238612e-03, 1.03729712e-02], [ 4.98825667e-03, 4.26289486e-03, 9.82111912e-03]]]]) - noise_chol_United States_corr(chain, draw, noise_chol_United States_corr_dim_0, noise_chol_United States_corr_dim_1)float641.0 -0.1237 0.2194 ... -0.3669 1.0
array([[[[ 1. , -0.12373496, 0.2194029 ], [-0.12373496, 1. , -0.25418072], [ 0.2194029 , -0.25418072, 1. ]], [[ 1. , -0.08755801, 0.16400819], [-0.08755801, 1. , -0.09966876], [ 0.16400819, -0.09966876, 1. ]], [[ 1. , 0.10421435, 0.31071612], [ 0.10421435, 1. , -0.07786102], [ 0.31071612, -0.07786102, 1. ]], ..., [[ 1. , -0.25690227, -0.2516993 ], [-0.25690227, 1. , -0.16348354], [-0.2516993 , -0.16348354, 1. ]], [[ 1. , 0.13805707, 0.1129058 ], [ 0.13805707, 1. , 0.03887161], ... [-0.24519414, 1. , 0.18560319], [-0.04654987, 0.18560319, 1. ]], [[ 1. , -0.08347974, 0.08345532], [-0.08347974, 1. , -0.16184667], [ 0.08345532, -0.16184667, 1. ]], ..., [[ 1. , 0.09031447, 0.01845146], [ 0.09031447, 1. , 0.07953875], [ 0.01845146, 0.07953875, 1. ]], [[ 1. , -0.08492667, -0.06105887], [-0.08492667, 1. , -0.09564229], [-0.06105887, -0.09564229, 1. ]], [[ 1. , -0.07369983, 0.19028836], [-0.07369983, 1. , -0.36687185], [ 0.19028836, -0.36687185, 1. ]]]]) - noise_chol_United States_stds(chain, draw, noise_chol_United States_stds_dim_0)float640.3961 0.1731 ... 0.236 0.04284
array([[[0.39610121, 0.17313566, 0.13151658], [0.50300257, 0.16378312, 0.30785359], [0.40499367, 0.29183097, 0.17103799], ..., [0.25308695, 0.225279 , 0.0499346 ], [0.18360867, 0.14793039, 0.10335308], [0.13763278, 0.27036949, 0.25001474]], [[0.33901425, 0.2859728 , 0.14938787], [0.46199928, 0.24372264, 0.38710875], [0.18262759, 0.20826379, 0.15278749], ..., [0.22499492, 0.26278119, 0.64153824], [0.28685874, 0.27750089, 0.57339015], [0.22616996, 0.26611302, 0.81114613]], [[0.26858195, 0.26946796, 0.01240314], [0.19922095, 0.23897807, 0.03079663], [0.23627217, 0.25924429, 0.06318893], ..., [0.47553886, 0.16034714, 0.5655458 ], [0.47969097, 0.15234592, 0.45064874], [0.5480807 , 0.12355644, 0.19380373]], [[0.35877391, 0.24909448, 0.08051716], [0.53630726, 0.29214595, 0.0914405 ], [0.45646339, 0.49269993, 0.1171669 ], ..., [0.24895896, 0.30515014, 0.05616936], [0.17878626, 0.23102656, 0.03243802], [0.23670972, 0.23603791, 0.04284113]]]) - omega_United States(chain, draw, omega_United States_dim_0, omega_United States_dim_1)float640.02224 0.0 ... -0.007916 0.02205
array([[[[ 0.02224269, 0. , 0. ], [ 0.01426655, 0.00781906, 0. ], [ 0.04297316, -0.0029042 , 0.02139896]], [[ 0.02161116, 0. , 0. ], [ 0.01442107, 0.00699402, 0. ], [ 0.04733589, -0.00850155, 0.02438742]], [[ 0.02154883, 0. , 0. ], [ 0.01541935, 0.00865652, 0. ], [ 0.04205062, -0.00440743, 0.01687921]], ..., [[ 0.02182073, 0. , 0. ], [ 0.0120993 , 0.00850836, 0. ], [ 0.04378857, -0.00264491, 0.02324224]], [[ 0.02189389, 0. , 0. ], [ 0.01425134, 0.00623576, 0. ], ... [ 0.01523062, 0.00780871, 0. ], [ 0.04675563, -0.00378547, 0.02724154]], [[ 0.02275317, 0. , 0. ], [ 0.01453993, 0.00875474, 0. ], [ 0.04320462, -0.0011659 , 0.02463757]], ..., [[ 0.02200213, 0. , 0. ], [ 0.01366546, 0.01006372, 0. ], [ 0.04291484, -0.0076015 , 0.0180956 ]], [[ 0.02158716, 0. , 0. ], [ 0.01363408, 0.0076984 , 0. ], [ 0.04297396, -0.00866316, 0.01888493]], [[ 0.02238792, 0. , 0. ], [ 0.01314157, 0.00867913, 0. ], [ 0.04180196, -0.00791556, 0.02205044]]]])
- chainPandasIndex
PandasIndex(Int64Index([0, 1, 2, 3], dtype='int64', name='chain'))
- drawPandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ... 1990, 1991, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999], dtype='int64', name='draw', length=2000)) - equationsPandasIndex
PandasIndex(Index(['dl_gdp', 'dl_cons', 'dl_gfcf'], dtype='object', name='equations'))
- lagsPandasIndex
PandasIndex(Int64Index([1, 2], dtype='int64', name='lags'))
- cross_varsPandasIndex
PandasIndex(Index(['dl_gdp', 'dl_cons', 'dl_gfcf'], dtype='object', name='cross_vars'))
- omega_global_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5], dtype='int64', name='omega_global_dim_0'))
- noise_chol_Australia_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5], dtype='int64', name='noise_chol_Australia_dim_0'))
- noise_chol_Canada_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5], dtype='int64', name='noise_chol_Canada_dim_0'))
- noise_chol_Chile_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5], dtype='int64', name='noise_chol_Chile_dim_0'))
- noise_chol_Ireland_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5], dtype='int64', name='noise_chol_Ireland_dim_0'))
- noise_chol_New Zealand_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5], dtype='int64', name='noise_chol_New Zealand_dim_0'))
- noise_chol_South Africa_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5], dtype='int64', name='noise_chol_South Africa_dim_0'))
- noise_chol_United Kingdom_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5], dtype='int64', name='noise_chol_United Kingdom_dim_0'))
- noise_chol_United States_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5], dtype='int64', name='noise_chol_United States_dim_0'))
- omega_global_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_global_corr_dim_0'))
- omega_global_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_global_corr_dim_1'))
- omega_global_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_global_stds_dim_0'))
- betaX_Australia_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='betaX_Australia_dim_0')) - betaX_Australia_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='betaX_Australia_dim_1'))
- noise_chol_Australia_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Australia_corr_dim_0'))
- noise_chol_Australia_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Australia_corr_dim_1'))
- noise_chol_Australia_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Australia_stds_dim_0'))
- omega_Australia_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_Australia_dim_0'))
- omega_Australia_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_Australia_dim_1'))
- betaX_Canada_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21], dtype='int64', name='betaX_Canada_dim_0')) - betaX_Canada_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='betaX_Canada_dim_1'))
- noise_chol_Canada_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Canada_corr_dim_0'))
- noise_chol_Canada_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Canada_corr_dim_1'))
- noise_chol_Canada_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Canada_stds_dim_0'))
- omega_Canada_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_Canada_dim_0'))
- omega_Canada_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_Canada_dim_1'))
- betaX_Chile_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='betaX_Chile_dim_0')) - betaX_Chile_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='betaX_Chile_dim_1'))
- noise_chol_Chile_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Chile_corr_dim_0'))
- noise_chol_Chile_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Chile_corr_dim_1'))
- noise_chol_Chile_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Chile_stds_dim_0'))
- omega_Chile_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_Chile_dim_0'))
- omega_Chile_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_Chile_dim_1'))
- betaX_Ireland_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='betaX_Ireland_dim_0')) - betaX_Ireland_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='betaX_Ireland_dim_1'))
- noise_chol_Ireland_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Ireland_corr_dim_0'))
- noise_chol_Ireland_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Ireland_corr_dim_1'))
- noise_chol_Ireland_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Ireland_stds_dim_0'))
- omega_Ireland_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_Ireland_dim_0'))
- omega_Ireland_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_Ireland_dim_1'))
- betaX_New Zealand_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40], dtype='int64', name='betaX_New Zealand_dim_0')) - betaX_New Zealand_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='betaX_New Zealand_dim_1'))
- noise_chol_New Zealand_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_New Zealand_corr_dim_0'))
- noise_chol_New Zealand_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_New Zealand_corr_dim_1'))
- noise_chol_New Zealand_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_New Zealand_stds_dim_0'))
- omega_New Zealand_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_New Zealand_dim_0'))
- omega_New Zealand_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_New Zealand_dim_1'))
- betaX_South Africa_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='betaX_South Africa_dim_0')) - betaX_South Africa_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='betaX_South Africa_dim_1'))
- noise_chol_South Africa_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_South Africa_corr_dim_0'))
- noise_chol_South Africa_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_South Africa_corr_dim_1'))
- noise_chol_South Africa_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_South Africa_stds_dim_0'))
- omega_South Africa_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_South Africa_dim_0'))
- omega_South Africa_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_South Africa_dim_1'))
- betaX_United Kingdom_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='betaX_United Kingdom_dim_0')) - betaX_United Kingdom_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='betaX_United Kingdom_dim_1'))
- noise_chol_United Kingdom_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_United Kingdom_corr_dim_0'))
- noise_chol_United Kingdom_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_United Kingdom_corr_dim_1'))
- noise_chol_United Kingdom_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_United Kingdom_stds_dim_0'))
- omega_United Kingdom_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_United Kingdom_dim_0'))
- omega_United Kingdom_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_United Kingdom_dim_1'))
- betaX_United States_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45], dtype='int64', name='betaX_United States_dim_0')) - betaX_United States_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='betaX_United States_dim_1'))
- noise_chol_United States_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_United States_corr_dim_0'))
- noise_chol_United States_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_United States_corr_dim_1'))
- noise_chol_United States_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_United States_stds_dim_0'))
- omega_United States_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_United States_dim_0'))
- omega_United States_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_United States_dim_1'))
- created_at
- 2023-02-21T19:24:14.259388
- arviz_version
- 0.14.0
<xarray.Dataset> Dimensions: (chain: 4, draw: 2000, equations: 3, lags: 2, cross_vars: 3, omega_global_dim_0: 6, noise_chol_Australia_dim_0: 6, noise_chol_Canada_dim_0: 6, noise_chol_Chile_dim_0: 6, ... betaX_United States_dim_1: 3, noise_chol_United States_corr_dim_0: 3, noise_chol_United States_corr_dim_1: 3, noise_chol_United States_stds_dim_0: 3, omega_United States_dim_0: 3, omega_United States_dim_1: 3) Coordinates: (12/73) * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 ... 1997 1998 1999 * equations (equations) <U7 'dl_gdp' ... 'dl_gfcf' * lags (lags) int64 1 2 * cross_vars (cross_vars) <U7 'dl_gdp' ... 'dl_g... * omega_global_dim_0 (omega_global_dim_0) int64 0 1 2 3 4 5 ... ... * betaX_United States_dim_1 (betaX_United States_dim_1) int64 0... * noise_chol_United States_corr_dim_0 (noise_chol_United States_corr_dim_0) int64 ... * noise_chol_United States_corr_dim_1 (noise_chol_United States_corr_dim_1) int64 ... * noise_chol_United States_stds_dim_0 (noise_chol_United States_stds_dim_0) int64 ... * omega_United States_dim_0 (omega_United States_dim_0) int64 0... * omega_United States_dim_1 (omega_United States_dim_1) int64 0... Data variables: (12/80) alpha_hat_location (chain, draw) float64 0.01867 ... 0... beta_hat_location (chain, draw) float64 0.03707 ... 0... lag_coefs_Australia (chain, draw, equations, lags, cross_vars) float64 ... alpha_Australia (chain, draw, equations) float64 0.... lag_coefs_Canada (chain, draw, equations, lags, cross_vars) float64 ... alpha_Canada (chain, draw, equations) float64 0.... ... ... noise_chol_United Kingdom_stds (chain, draw, noise_chol_United Kingdom_stds_dim_0) float64 ... omega_United Kingdom (chain, draw, omega_United Kingdom_dim_0, omega_United Kingdom_dim_1) float64 ... betaX_United States (chain, draw, betaX_United States_dim_0, betaX_United States_dim_1) float64 ... noise_chol_United States_corr (chain, draw, noise_chol_United States_corr_dim_0, noise_chol_United States_corr_dim_1) float64 ... noise_chol_United States_stds (chain, draw, noise_chol_United States_stds_dim_0) float64 ... omega_United States (chain, draw, omega_United States_dim_0, omega_United States_dim_1) float64 ... Attributes: created_at: 2023-02-21T19:24:14.259388 arviz_version: 0.14.0xarray.Dataset -
- chain: 4
- draw: 2000
- obs_Australia_dim_2: 49
- obs_Australia_dim_3: 3
- obs_Canada_dim_2: 22
- obs_Canada_dim_3: 3
- obs_Chile_dim_2: 49
- obs_Chile_dim_3: 3
- obs_Ireland_dim_2: 49
- obs_Ireland_dim_3: 3
- obs_New Zealand_dim_2: 41
- obs_New Zealand_dim_3: 3
- obs_South Africa_dim_2: 49
- obs_South Africa_dim_3: 3
- obs_United Kingdom_dim_2: 49
- obs_United Kingdom_dim_3: 3
- obs_United States_dim_2: 46
- obs_United States_dim_3: 3
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 ... 1996 1997 1998 1999
array([ 0, 1, 2, ..., 1997, 1998, 1999])
- obs_Australia_dim_2(obs_Australia_dim_2)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - obs_Australia_dim_3(obs_Australia_dim_3)int640 1 2
array([0, 1, 2])
- obs_Canada_dim_2(obs_Canada_dim_2)int640 1 2 3 4 5 6 ... 16 17 18 19 20 21
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21]) - obs_Canada_dim_3(obs_Canada_dim_3)int640 1 2
array([0, 1, 2])
- obs_Chile_dim_2(obs_Chile_dim_2)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - obs_Chile_dim_3(obs_Chile_dim_3)int640 1 2
array([0, 1, 2])
- obs_Ireland_dim_2(obs_Ireland_dim_2)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - obs_Ireland_dim_3(obs_Ireland_dim_3)int640 1 2
array([0, 1, 2])
- obs_New Zealand_dim_2(obs_New Zealand_dim_2)int640 1 2 3 4 5 6 ... 35 36 37 38 39 40
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40]) - obs_New Zealand_dim_3(obs_New Zealand_dim_3)int640 1 2
array([0, 1, 2])
- obs_South Africa_dim_2(obs_South Africa_dim_2)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - obs_South Africa_dim_3(obs_South Africa_dim_3)int640 1 2
array([0, 1, 2])
- obs_United Kingdom_dim_2(obs_United Kingdom_dim_2)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - obs_United Kingdom_dim_3(obs_United Kingdom_dim_3)int640 1 2
array([0, 1, 2])
- obs_United States_dim_2(obs_United States_dim_2)int640 1 2 3 4 5 6 ... 40 41 42 43 44 45
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45]) - obs_United States_dim_3(obs_United States_dim_3)int640 1 2
array([0, 1, 2])
- obs_Australia(chain, draw, obs_Australia_dim_2, obs_Australia_dim_3)float640.01718 0.03863 ... 0.01568 0.02849
array([[[[ 1.71814304e-02, 3.86304132e-02, 8.62497633e-03], [ 3.72827017e-02, 2.32908100e-02, 4.65201150e-02], [ 1.56932521e-02, 1.75517726e-02, 4.09380858e-02], ..., [ 4.10301093e-02, 4.62873493e-02, 1.15345906e-01], [ 3.95068453e-03, 1.66705131e-02, -1.22055946e-02], [ 1.61741262e-02, 2.00958780e-02, 4.75676040e-02]], [[ 1.16765646e-02, 4.34190246e-02, 1.17997888e-02], [ 3.70198818e-02, 4.49392262e-02, 6.63994229e-02], [ 2.29244731e-03, 3.70708820e-02, -8.81318993e-02], ..., [ 4.06237200e-02, 3.38910413e-02, 5.24163359e-02], [ 2.45360155e-02, 3.27939557e-02, 9.95139123e-02], [ 1.18874430e-02, 1.24712580e-03, -3.16569114e-02]], [[ 3.78454998e-02, 5.97333817e-02, 6.57289700e-02], [ 3.42922279e-02, 1.98606073e-02, 5.86488810e-02], [ 2.97512375e-02, 5.08368977e-02, 1.44429184e-02], ..., ... ..., [-7.82775100e-03, -1.11524239e-02, 1.33931778e-02], [ 1.04920189e-02, 2.95794905e-02, -4.20372757e-02], [ 1.25868172e-02, 8.26226518e-03, 2.32814476e-02]], [[ 4.22496563e-02, 3.93804556e-02, 6.17123928e-02], [ 5.75016873e-02, 2.83514497e-02, 1.29165220e-01], [ 9.63236659e-03, 2.90319014e-02, 3.65130736e-02], ..., [ 2.54372236e-02, 1.22418583e-02, 3.11397189e-02], [ 3.37716207e-02, 2.88003128e-02, 6.13473952e-02], [ 4.59080412e-02, 4.35640830e-02, 1.02486032e-01]], [[ 2.69865820e-02, 2.75567929e-02, 5.12639080e-02], [ 1.63093433e-02, 2.40403089e-02, 1.11878254e-02], [ 3.20637964e-02, 3.06880118e-02, 3.32248612e-02], ..., [ 1.52853345e-02, 2.57307871e-02, -1.14341035e-02], [ 1.15251256e-02, 3.50691462e-02, -5.55453149e-02], [ 1.15289667e-02, 1.56763222e-02, 2.84865123e-02]]]]) - obs_Canada(chain, draw, obs_Canada_dim_2, obs_Canada_dim_3)float64-0.004644 0.000541 ... 0.01186
array([[[[-4.64408169e-03, 5.41022474e-04, 2.77090992e-02], [ 7.65108310e-02, 4.20272316e-02, 4.29074280e-02], [ 7.63487440e-02, 5.93399341e-02, 2.21993532e-02], ..., [-4.88784351e-03, 1.89402137e-02, 5.13358215e-02], [ 3.09359293e-02, 2.63088702e-02, 3.34784431e-02], [-1.62071430e-02, 2.95699755e-03, -1.96588288e-02]], [[ 1.69427739e-02, 3.14504425e-02, -2.45921194e-02], [ 4.78292980e-02, 4.17053081e-02, 1.16101106e-01], [ 2.21984842e-02, 1.30568362e-02, 2.49782856e-02], ..., [-1.36514051e-02, 2.28260141e-02, -4.90129985e-02], [ 4.23434785e-02, 1.39910394e-02, -9.14378186e-03], [ 1.41931876e-03, 2.56539088e-03, -2.01969582e-02]], [[ 9.35860132e-03, 2.05013115e-02, -7.53635328e-02], [ 5.08839915e-02, 4.06375683e-02, 6.38489237e-02], [ 3.78814501e-02, 3.35364632e-02, 4.77189677e-02], ..., ... ..., [-2.43404641e-02, 1.05330236e-02, -7.31521306e-02], [-7.40980621e-03, -8.55092575e-03, 1.99562626e-02], [ 8.46992483e-03, 1.95258363e-02, -3.71379069e-04]], [[-3.32481115e-02, -5.09555042e-03, -6.69249055e-02], [ 2.86525876e-02, 2.61265843e-02, 7.45085394e-02], [ 2.94601432e-02, 3.67928245e-02, 6.20563008e-02], ..., [-2.53938240e-04, 1.58998304e-02, -1.97567736e-02], [-3.30727502e-02, -1.95918626e-02, -2.19663825e-02], [ 3.07192812e-02, 1.44959030e-02, 6.38936482e-03]], [[-5.55669235e-03, 1.34096637e-02, -2.80229050e-03], [ 4.48636450e-02, 4.32087685e-02, 1.64682437e-02], [ 4.45741963e-02, 5.19414321e-02, -7.16768194e-02], ..., [ 7.20579040e-04, 1.90249533e-02, 4.08664008e-02], [-3.45389840e-03, 9.57581651e-03, 1.34331022e-02], [ 1.33797090e-02, 4.79016262e-02, 1.18614703e-02]]]]) - obs_Chile(chain, draw, obs_Chile_dim_2, obs_Chile_dim_3)float640.06127 0.03212 ... 0.08228
array([[[[ 6.12721183e-02, 3.21234017e-02, -4.03472510e-03], [ 9.81831038e-02, 7.56367935e-02, 3.00220526e-01], [-3.68627357e-02, -2.69241465e-02, 8.85175587e-02], ..., [ 6.65175085e-02, -3.07421617e-02, 1.67618155e-01], [ 7.17788445e-02, 9.60941741e-02, 1.12337786e-02], [ 4.37529878e-02, 4.24993573e-03, 1.38548876e-01]], [[ 8.62422526e-02, 7.59547740e-02, 2.11013291e-01], [-4.18916708e-02, 2.26006525e-02, -4.03739272e-02], [ 4.36567379e-02, 2.03844443e-02, 1.25405233e-01], ..., [ 2.46903978e-02, 3.19814849e-02, 9.10853274e-02], [-6.69388915e-02, -4.47635493e-02, -1.14852887e-01], [-1.12864431e-02, -8.30831365e-02, 3.79573314e-02]], [[ 8.11728592e-02, 3.46064296e-02, 1.38006803e-01], [ 8.66492371e-02, 1.54124190e-01, 9.23997087e-02], [ 8.72837690e-02, 8.65410217e-02, 9.36000724e-02], ..., ... ..., [ 5.79495015e-02, 1.32505013e-02, 6.20323360e-02], [ 3.59242864e-02, 8.75189010e-02, 1.26132245e-01], [ 1.51691936e-02, 3.39243983e-02, 1.85009169e-02]], [[-2.27000865e-02, 2.03228260e-03, -4.95550764e-02], [ 4.93748178e-02, 5.23312019e-02, 1.21542326e-01], [-1.79720053e-03, -5.77901061e-02, 4.97585606e-02], ..., [ 7.51790930e-02, -6.82322742e-03, 1.38309046e-01], [ 1.47121927e-02, 1.32441539e-02, -1.41932657e-01], [-6.58490525e-03, -2.03698972e-02, -5.22053183e-02]], [[ 8.65731987e-02, 8.21620479e-02, 5.84672407e-02], [-1.91285361e-02, -7.43787048e-02, -7.11719043e-02], [ 6.22570647e-02, 5.84276412e-02, 1.84151634e-01], ..., [ 3.89607458e-02, 2.18309257e-02, 1.11930753e-01], [ 1.28759433e-01, 7.40660544e-02, 3.00524095e-01], [ 1.78603328e-02, 7.96127549e-03, 8.22820066e-02]]]]) - obs_Ireland(chain, draw, obs_Ireland_dim_2, obs_Ireland_dim_3)float640.1557 0.08176 ... 0.1287 -0.1345
array([[[[ 1.55690315e-01, 8.17612051e-02, 2.54884944e-01], [ 8.30537113e-02, 1.96665946e-02, 1.91948672e-01], [ 5.18063002e-02, 5.37948610e-02, 2.01020695e-02], ..., [-4.17005132e-02, 8.62801058e-03, -2.50714188e-02], [ 2.34376745e-02, -2.86949863e-02, 4.73413071e-02], [ 4.12567885e-02, 2.97175467e-02, 1.09204836e-02]], [[ 7.12140536e-02, 5.72404917e-02, 1.40261014e-01], [ 5.01194556e-02, 5.21749690e-02, -6.98677346e-02], [ 3.60390422e-03, 4.14117641e-02, -6.59201620e-02], ..., [ 8.32956157e-02, 4.80447074e-02, 2.77882427e-01], [ 3.15432944e-02, -5.43268717e-03, 2.16518669e-01], [ 7.67925538e-02, 9.95581466e-02, 3.24362526e-01]], [[ 1.02130912e-01, 7.24110686e-02, 2.33259953e-01], [ 8.76638592e-02, 2.77026372e-02, -1.28836810e-01], [ 3.81034380e-02, 2.48540029e-02, -2.91263272e-01], ..., ... ..., [ 4.69004828e-02, 7.92535331e-02, 1.62716290e-01], [ 4.44298900e-02, -2.36389271e-02, 3.84840773e-02], [ 6.47962921e-02, 7.12658913e-02, 1.09032776e-01]], [[ 1.45692181e-01, 9.76994510e-02, 1.16284048e-01], [ 9.98886023e-03, 2.38721537e-02, 1.37205085e-01], [ 1.13475116e-01, 9.52640604e-02, 5.53537026e-01], ..., [ 1.98637109e-03, -1.44739613e-02, -4.04618619e-03], [ 2.07201815e-02, -9.89853531e-03, 4.83800414e-02], [ 6.30169392e-02, 5.31426338e-02, 7.65845437e-02]], [[ 4.12936563e-03, 3.55472206e-02, 1.96776728e-01], [ 3.03932892e-02, 8.51055142e-03, -2.50454449e-01], [ 5.73927769e-02, 5.66884598e-02, 2.93782574e-01], ..., [-2.56240493e-02, 1.43019866e-02, -9.83973799e-02], [ 6.46347175e-02, -1.25078103e-02, -4.73941676e-02], [ 1.42690626e-01, 1.28735853e-01, -1.34536179e-01]]]]) - obs_New Zealand(chain, draw, obs_New Zealand_dim_2, obs_New Zealand_dim_3)float640.03207 0.02997 ... 0.03527 0.05695
array([[[[ 3.20690633e-02, 2.99727795e-02, 6.17409380e-02], [-2.62744148e-02, -1.74185454e-02, 5.74588695e-02], [ 6.14617585e-03, 6.67343005e-03, -2.34943617e-02], ..., [ 3.01151769e-02, 3.01847683e-02, 7.40915874e-02], [ 4.60903541e-02, 4.94159825e-02, 8.83121067e-02], [ 4.52213957e-02, 3.48933527e-02, 1.19125066e-01]], [[ 4.02898888e-02, 2.22407120e-02, 7.61584903e-02], [ 2.87672463e-02, 2.62409068e-02, -1.34640321e-02], [ 4.44452188e-02, 5.58481770e-02, 8.33098440e-02], ..., [ 4.32440904e-02, 4.30665619e-02, 1.74801352e-01], [ 6.65765975e-03, 2.01150519e-03, -1.15729457e-02], [ 5.09384596e-02, 4.91561580e-02, 1.07038226e-01]], [[ 2.15312405e-02, 1.19202069e-02, 7.14022593e-02], [ 3.82029616e-02, 3.03344257e-02, 7.46014123e-02], [ 4.86917765e-02, 3.76701870e-02, 7.68651184e-02], ..., ... ..., [ 3.69542256e-02, 4.80030477e-03, -3.94413090e-02], [ 3.21254844e-02, 2.89474315e-02, 2.37307277e-02], [ 3.65098794e-02, 4.35925092e-02, 1.25754074e-01]], [[ 2.40271958e-02, 3.69412637e-02, -3.30688007e-02], [ 5.32477411e-02, 4.43699163e-02, 1.01855370e-01], [ 3.02279921e-02, 5.15357782e-02, 3.36666242e-02], ..., [ 2.32986286e-02, 2.17719747e-02, 4.38569710e-02], [ 9.90753293e-03, 2.49266878e-02, -1.53327898e-02], [ 1.61506414e-02, 3.21587798e-02, -5.85673173e-02]], [[ 2.53196637e-02, 4.13067995e-02, 6.94431362e-02], [ 5.02102734e-02, 2.53355885e-02, 1.97033240e-01], [ 3.47888163e-02, 4.30719282e-02, 6.21989311e-02], ..., [ 3.66163423e-02, 2.37704316e-02, -1.16997417e-02], [ 1.55158215e-02, 2.99695145e-02, 4.99092419e-02], [ 3.74461661e-02, 3.52667102e-02, 5.69489057e-02]]]]) - obs_South Africa(chain, draw, obs_South Africa_dim_2, obs_South Africa_dim_3)float640.03308 0.04329 ... -0.007726
array([[[[ 3.30780556e-02, 4.32893911e-02, 6.05011744e-02], [-1.51739626e-04, -1.13314322e-02, -6.98970591e-02], [ 5.06024438e-02, 5.17561504e-02, 9.42083761e-02], ..., [ 5.54624849e-03, -3.15079810e-03, -1.47314096e-02], [ 2.08204734e-02, 2.75899818e-02, -1.83820743e-02], [-4.73507799e-03, 2.18914557e-02, -4.96872468e-02]], [[ 4.81253439e-02, 4.89427662e-02, 4.42420433e-02], [ 2.49053249e-02, 3.43137915e-02, 4.90914050e-02], [ 1.46720422e-02, 3.49305129e-02, 3.71172461e-02], ..., [-4.48067052e-03, -1.40509654e-02, -1.14008983e-01], [ 1.63492220e-02, 2.43939630e-02, -1.44261140e-02], [ 2.91068131e-02, 2.07542405e-02, 2.58933316e-02]], [[ 7.73081474e-02, 7.66319051e-02, 6.97183640e-02], [ 1.31293018e-02, 1.13030226e-02, -1.19635530e-01], [-2.73258731e-02, -6.94899442e-03, -4.09784834e-02], ..., ... ..., [ 5.04232684e-02, 5.28574979e-02, 1.24196528e-01], [ 1.63034069e-02, 2.85918028e-02, 4.63768417e-02], [ 2.28468022e-02, 8.97429649e-03, 1.21741339e-02]], [[ 1.21447075e-02, -2.23071080e-03, 2.54235225e-02], [ 2.48943153e-03, -3.75262990e-03, -2.55812651e-04], [ 3.38794359e-02, 1.90850623e-02, 7.09915282e-02], ..., [ 2.14291154e-02, 2.95327945e-02, -9.95109508e-03], [ 9.76334126e-03, 2.74741835e-02, -9.84441835e-02], [-2.84738787e-03, 2.82455574e-02, -8.46302365e-02]], [[ 1.76455902e-02, 3.48699330e-02, -1.12066834e-02], [ 2.56519386e-02, 3.03284960e-02, 2.70031257e-02], [ 8.51457640e-03, 1.04369079e-02, 3.20902969e-02], ..., [ 1.44325853e-02, 9.60955260e-03, -3.49045275e-02], [ 2.94730987e-02, 3.92554503e-02, -1.61254730e-02], [ 2.21664043e-02, 3.03301943e-02, -7.72575903e-03]]]]) - obs_United Kingdom(chain, draw, obs_United Kingdom_dim_2, obs_United Kingdom_dim_3)float640.0448 0.04243 ... 0.02593 0.05417
array([[[[ 4.47963612e-02, 4.24337553e-02, 5.30809163e-02], [ 1.98628679e-02, 3.62871294e-02, -2.13912012e-02], [ 6.66614065e-03, 2.15867609e-02, -1.32673374e-02], ..., [ 4.31005695e-02, 3.91699840e-02, 6.53844859e-02], [ 4.41643424e-02, 2.77469541e-02, 7.85013753e-02], [ 3.93853453e-02, 3.28562568e-02, 8.88386060e-02]], [[-5.90061000e-03, -3.68935945e-03, -4.58361479e-03], [ 1.25872647e-03, 6.90687176e-03, 2.50108349e-02], [ 4.08323717e-02, 3.37580392e-02, 1.54248560e-01], ..., [ 4.08601546e-02, 2.69133667e-02, 1.37595011e-01], [ 3.98290375e-02, 2.03067542e-02, 4.83012601e-02], [ 1.56694518e-02, 1.62809715e-02, 4.68512624e-02]], [[ 3.01925836e-02, 1.73296171e-02, 7.20531325e-03], [ 1.73253627e-02, 2.25736782e-02, 5.78747659e-02], [-1.02540683e-02, 9.73991571e-04, -4.85102028e-02], ..., ... ..., [ 2.12890584e-03, 6.05849284e-03, 2.34878655e-02], [ 1.25287356e-02, 6.89032917e-03, 6.88012797e-02], [ 4.40254150e-03, 1.75809138e-03, 6.40606607e-03]], [[-1.73004397e-02, -7.43669461e-03, -2.15385541e-02], [-2.15727640e-03, 4.04738662e-03, -4.19487099e-02], [ 4.29180817e-02, 3.82009101e-02, 6.67301387e-02], ..., [-4.68188628e-03, 1.33528184e-02, -4.39221050e-02], [ 4.68646792e-02, 3.31468558e-02, 5.82560257e-02], [ 7.75585379e-03, 7.89267910e-03, -3.41566846e-02]], [[ 5.82243193e-02, 5.36666285e-02, 6.65792342e-02], [ 5.36896564e-02, 4.72045409e-02, 4.98576751e-02], [ 5.21386240e-02, 5.64919290e-02, 1.12981453e-01], ..., [ 3.53548206e-02, 2.98210067e-02, 1.94859678e-02], [ 2.80990148e-02, 3.17759443e-02, -9.36937590e-03], [ 2.15120699e-02, 2.59287536e-02, 5.41668008e-02]]]]) - obs_United States(chain, draw, obs_United States_dim_2, obs_United States_dim_3)float640.008293 0.0005756 ... 0.02601
array([[[[ 0.00829273, 0.00057562, 0.00587833], [ 0.01323049, 0.00472613, -0.02500458], [ 0.01578798, 0.02120087, 0.01372787], ..., [ 0.00020075, 0.00101262, -0.0349095 ], [ 0.00136731, 0.00649784, -0.03638963], [ 0.04477031, 0.03937194, 0.05329405]], [[ 0.05196033, 0.03276444, 0.06056884], [ 0.02986291, 0.00465566, 0.10946823], [ 0.01320663, 0.01860797, 0.01033147], ..., [ 0.00389877, 0.00691071, -0.03040151], [ 0.00421392, 0.015716 , 0.02244968], [ 0.01750093, 0.02115849, 0.01491858]], [[ 0.03202804, 0.0409238 , 0.01360283], [-0.00775588, 0.01125095, -0.03788069], [ 0.01289303, 0.00459615, 0.01594723], ..., ... ..., [-0.00605736, 0.00638832, -0.01777219], [-0.0015468 , 0.02003112, -0.03676623], [-0.01219943, 0.01533257, -0.04725824]], [[ 0.03360024, 0.03446592, 0.03699262], [-0.0141114 , -0.00257232, -0.06878331], [ 0.03911067, 0.04103395, 0.06795756], ..., [ 0.06179876, 0.04901743, 0.07049406], [ 0.00814458, 0.00760273, 0.00171805], [-0.03116158, -0.01415311, -0.11120307]], [[ 0.03732969, 0.02478824, 0.05976468], [ 0.01944701, 0.01566222, 0.04757722], [ 0.02900474, 0.04581697, 0.04853083], ..., [ 0.0171826 , 0.01891361, 0.01726273], [ 0.01433668, 0.01098619, 0.04256221], [ 0.02656965, 0.02604265, 0.02600868]]]])
- chainPandasIndex
PandasIndex(Int64Index([0, 1, 2, 3], dtype='int64', name='chain'))
- drawPandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ... 1990, 1991, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999], dtype='int64', name='draw', length=2000)) - obs_Australia_dim_2PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='obs_Australia_dim_2')) - obs_Australia_dim_3PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_Australia_dim_3'))
- obs_Canada_dim_2PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21], dtype='int64', name='obs_Canada_dim_2')) - obs_Canada_dim_3PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_Canada_dim_3'))
- obs_Chile_dim_2PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='obs_Chile_dim_2')) - obs_Chile_dim_3PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_Chile_dim_3'))
- obs_Ireland_dim_2PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='obs_Ireland_dim_2')) - obs_Ireland_dim_3PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_Ireland_dim_3'))
- obs_New Zealand_dim_2PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40], dtype='int64', name='obs_New Zealand_dim_2')) - obs_New Zealand_dim_3PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_New Zealand_dim_3'))
- obs_South Africa_dim_2PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='obs_South Africa_dim_2')) - obs_South Africa_dim_3PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_South Africa_dim_3'))
- obs_United Kingdom_dim_2PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='obs_United Kingdom_dim_2')) - obs_United Kingdom_dim_3PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_United Kingdom_dim_3'))
- obs_United States_dim_2PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45], dtype='int64', name='obs_United States_dim_2')) - obs_United States_dim_3PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_United States_dim_3'))
- created_at
- 2023-02-21T19:31:34.868405
- arviz_version
- 0.14.0
- inference_library
- pymc
- inference_library_version
- 5.0.1
<xarray.Dataset> Dimensions: (chain: 4, draw: 2000, obs_Australia_dim_2: 49, obs_Australia_dim_3: 3, obs_Canada_dim_2: 22, obs_Canada_dim_3: 3, obs_Chile_dim_2: 49, obs_Chile_dim_3: 3, obs_Ireland_dim_2: 49, obs_Ireland_dim_3: 3, obs_New Zealand_dim_2: 41, obs_New Zealand_dim_3: 3, obs_South Africa_dim_2: 49, obs_South Africa_dim_3: 3, obs_United Kingdom_dim_2: 49, obs_United Kingdom_dim_3: 3, obs_United States_dim_2: 46, obs_United States_dim_3: 3) Coordinates: (12/18) * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 ... 1996 1997 1998 1999 * obs_Australia_dim_2 (obs_Australia_dim_2) int64 0 1 2 3 ... 46 47 48 * obs_Australia_dim_3 (obs_Australia_dim_3) int64 0 1 2 * obs_Canada_dim_2 (obs_Canada_dim_2) int64 0 1 2 3 4 ... 18 19 20 21 * obs_Canada_dim_3 (obs_Canada_dim_3) int64 0 1 2 ... ... * obs_South Africa_dim_2 (obs_South Africa_dim_2) int64 0 1 2 ... 46 47 48 * obs_South Africa_dim_3 (obs_South Africa_dim_3) int64 0 1 2 * obs_United Kingdom_dim_2 (obs_United Kingdom_dim_2) int64 0 1 2 ... 47 48 * obs_United Kingdom_dim_3 (obs_United Kingdom_dim_3) int64 0 1 2 * obs_United States_dim_2 (obs_United States_dim_2) int64 0 1 2 ... 43 44 45 * obs_United States_dim_3 (obs_United States_dim_3) int64 0 1 2 Data variables: obs_Australia (chain, draw, obs_Australia_dim_2, obs_Australia_dim_3) float64 ... obs_Canada (chain, draw, obs_Canada_dim_2, obs_Canada_dim_3) float64 ... obs_Chile (chain, draw, obs_Chile_dim_2, obs_Chile_dim_3) float64 ... obs_Ireland (chain, draw, obs_Ireland_dim_2, obs_Ireland_dim_3) float64 ... obs_New Zealand (chain, draw, obs_New Zealand_dim_2, obs_New Zealand_dim_3) float64 ... obs_South Africa (chain, draw, obs_South Africa_dim_2, obs_South Africa_dim_3) float64 ... obs_United Kingdom (chain, draw, obs_United Kingdom_dim_2, obs_United Kingdom_dim_3) float64 ... obs_United States (chain, draw, obs_United States_dim_2, obs_United States_dim_3) float64 ... Attributes: created_at: 2023-02-21T19:31:34.868405 arviz_version: 0.14.0 inference_library: pymc inference_library_version: 5.0.1xarray.Dataset -
- chain: 4
- draw: 2000
- chain(chain)int640 1 2 3
array([0, 1, 2, 3])
- draw(draw)int640 1 2 3 4 ... 1996 1997 1998 1999
array([ 0, 1, 2, ..., 1997, 1998, 1999])
- lp(chain, draw)float64-2.64e+03 -2.628e+03 ... -2.604e+03
array([[-2639.89115833, -2627.55770592, -2634.71443207, ..., -2765.56713392, -2748.95428527, -2735.7959319 ], [-2561.93945366, -2572.71071931, -2564.66514406, ..., -2616.41390537, -2618.61317438, -2623.36681425], [-2618.62600932, -2634.94074369, -2642.66539056, ..., -2653.05805478, -2656.48474006, -2651.63628297], [-2643.62426065, -2633.29142627, -2611.0879038 , ..., -2634.38375437, -2629.36058901, -2603.85800117]]) - diverging(chain, draw)boolFalse False False ... False False
array([[False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False], [False, False, False, ..., False, False, False]]) - energy(chain, draw)float64-2.532e+03 ... -2.494e+03
array([[-2531.58065155, -2521.32883239, -2514.6890569 , ..., -2630.50082991, -2637.8246221 , -2628.53079807], [-2441.12079867, -2432.56725591, -2440.74362316, ..., -2522.43066788, -2496.14911007, -2504.88809094], [-2492.78271971, -2519.36678959, -2519.07385537, ..., -2533.16366468, -2536.07235735, -2540.30849264], [-2521.35037416, -2507.4984581 , -2497.56736915, ..., -2527.36637866, -2511.02585969, -2493.66140801]]) - tree_depth(chain, draw)int646 6 6 6 6 6 7 7 ... 6 6 5 6 6 6 6 6
array([[6, 6, 6, ..., 6, 6, 6], [7, 7, 7, ..., 6, 7, 6], [6, 6, 6, ..., 6, 6, 6], [6, 6, 6, ..., 6, 6, 6]]) - n_steps(chain, draw)int6463 63 63 63 63 ... 63 63 63 63 63
array([[ 63, 63, 63, ..., 63, 63, 63], [127, 127, 127, ..., 63, 127, 63], [ 63, 63, 63, ..., 63, 63, 63], [ 63, 63, 63, ..., 63, 63, 63]]) - acceptance_rate(chain, draw)float640.8533 0.9783 ... 0.9693 0.9407
array([[0.85333103, 0.97828366, 0.96105869, ..., 0.98549555, 0.97487632, 0.67458368], [0.95142328, 0.99429708, 0.81421262, ..., 0.97399939, 0.81520905, 0.97292531], [0.92793643, 0.25595475, 0.9103398 , ..., 0.95571164, 0.74282113, 0.99596529], [0.99370679, 0.92069916, 0.8585449 , ..., 0.46255423, 0.96933128, 0.94071658]])
- chainPandasIndex
PandasIndex(Int64Index([0, 1, 2, 3], dtype='int64', name='chain'))
- drawPandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ... 1990, 1991, 1992, 1993, 1994, 1995, 1996, 1997, 1998, 1999], dtype='int64', name='draw', length=2000))
- created_at
- 2023-02-21T19:24:14.274886
- arviz_version
- 0.14.0
<xarray.Dataset> Dimensions: (chain: 4, draw: 2000) Coordinates: * chain (chain) int64 0 1 2 3 * draw (draw) int64 0 1 2 3 4 5 ... 1994 1995 1996 1997 1998 1999 Data variables: lp (chain, draw) float64 -2.64e+03 -2.628e+03 ... -2.604e+03 diverging (chain, draw) bool False False False ... False False False energy (chain, draw) float64 -2.532e+03 -2.521e+03 ... -2.494e+03 tree_depth (chain, draw) int64 6 6 6 6 6 6 7 7 7 ... 6 6 6 5 6 6 6 6 6 n_steps (chain, draw) int64 63 63 63 63 63 63 ... 31 63 63 63 63 63 acceptance_rate (chain, draw) float64 0.8533 0.9783 ... 0.9693 0.9407 Attributes: created_at: 2023-02-21T19:24:14.274886 arviz_version: 0.14.0xarray.Dataset -
- chain: 1
- draw: 500
- omega_global_dim_0: 6
- betaX_Canada_dim_0: 22
- betaX_Canada_dim_1: 3
- noise_chol_South Africa_dim_0: 6
- omega_New Zealand_dim_0: 3
- omega_New Zealand_dim_1: 3
- equations: 3
- lags: 2
- cross_vars: 3
- betaX_United States_dim_0: 46
- betaX_United States_dim_1: 3
- noise_chol_United Kingdom_stds_dim_0: 3
- noise_chol_New Zealand_stds_dim_0: 3
- omega_United Kingdom_dim_0: 3
- omega_United Kingdom_dim_1: 3
- omega_Australia_dim_0: 3
- omega_Australia_dim_1: 3
- noise_chol_South Africa_stds_dim_0: 3
- omega_Ireland_dim_0: 3
- omega_Ireland_dim_1: 3
- noise_chol_Chile_corr_dim_0: 3
- noise_chol_Chile_corr_dim_1: 3
- noise_chol_United States_stds_dim_0: 3
- omega_United States_dim_0: 3
- omega_United States_dim_1: 3
- noise_chol_New Zealand_dim_0: 6
- omega_Chile_dim_0: 3
- omega_Chile_dim_1: 3
- noise_chol_United States_dim_0: 6
- noise_chol_United Kingdom_corr_dim_0: 3
- noise_chol_United Kingdom_corr_dim_1: 3
- betaX_United Kingdom_dim_0: 49
- betaX_United Kingdom_dim_1: 3
- betaX_Ireland_dim_0: 49
- betaX_Ireland_dim_1: 3
- omega_South Africa_dim_0: 3
- omega_South Africa_dim_1: 3
- noise_chol_Canada_dim_0: 6
- omega_global_corr_dim_0: 3
- omega_global_corr_dim_1: 3
- betaX_Australia_dim_0: 49
- betaX_Australia_dim_1: 3
- noise_chol_Canada_corr_dim_0: 3
- noise_chol_Canada_corr_dim_1: 3
- noise_chol_Chile_stds_dim_0: 3
- noise_chol_United Kingdom_dim_0: 6
- noise_chol_Australia_dim_0: 6
- betaX_New Zealand_dim_0: 41
- betaX_New Zealand_dim_1: 3
- noise_chol_Australia_corr_dim_0: 3
- noise_chol_Australia_corr_dim_1: 3
- omega_Canada_dim_0: 3
- omega_Canada_dim_1: 3
- noise_chol_Australia_stds_dim_0: 3
- noise_chol_South Africa_corr_dim_0: 3
- noise_chol_South Africa_corr_dim_1: 3
- noise_chol_Ireland_dim_0: 6
- noise_chol_Ireland_corr_dim_0: 3
- noise_chol_Ireland_corr_dim_1: 3
- betaX_Chile_dim_0: 49
- betaX_Chile_dim_1: 3
- omega_global_stds_dim_0: 3
- betaX_South Africa_dim_0: 49
- betaX_South Africa_dim_1: 3
- noise_chol_Canada_stds_dim_0: 3
- noise_chol_New Zealand_corr_dim_0: 3
- noise_chol_New Zealand_corr_dim_1: 3
- noise_chol_United States_corr_dim_0: 3
- noise_chol_United States_corr_dim_1: 3
- noise_chol_Chile_dim_0: 6
- noise_chol_Ireland_stds_dim_0: 3
- chain(chain)int640
array([0])
- draw(draw)int640 1 2 3 4 5 ... 495 496 497 498 499
array([ 0, 1, 2, ..., 497, 498, 499])
- omega_global_dim_0(omega_global_dim_0)int640 1 2 3 4 5
array([0, 1, 2, 3, 4, 5])
- betaX_Canada_dim_0(betaX_Canada_dim_0)int640 1 2 3 4 5 6 ... 16 17 18 19 20 21
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21]) - betaX_Canada_dim_1(betaX_Canada_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_South Africa_dim_0(noise_chol_South Africa_dim_0)int640 1 2 3 4 5
array([0, 1, 2, 3, 4, 5])
- omega_New Zealand_dim_0(omega_New Zealand_dim_0)int640 1 2
array([0, 1, 2])
- omega_New Zealand_dim_1(omega_New Zealand_dim_1)int640 1 2
array([0, 1, 2])
- equations(equations)<U7'dl_gdp' 'dl_cons' 'dl_gfcf'
array(['dl_gdp', 'dl_cons', 'dl_gfcf'], dtype='<U7')
- lags(lags)int641 2
array([1, 2])
- cross_vars(cross_vars)<U7'dl_gdp' 'dl_cons' 'dl_gfcf'
array(['dl_gdp', 'dl_cons', 'dl_gfcf'], dtype='<U7')
- betaX_United States_dim_0(betaX_United States_dim_0)int640 1 2 3 4 5 6 ... 40 41 42 43 44 45
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45]) - betaX_United States_dim_1(betaX_United States_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_United Kingdom_stds_dim_0(noise_chol_United Kingdom_stds_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_New Zealand_stds_dim_0(noise_chol_New Zealand_stds_dim_0)int640 1 2
array([0, 1, 2])
- omega_United Kingdom_dim_0(omega_United Kingdom_dim_0)int640 1 2
array([0, 1, 2])
- omega_United Kingdom_dim_1(omega_United Kingdom_dim_1)int640 1 2
array([0, 1, 2])
- omega_Australia_dim_0(omega_Australia_dim_0)int640 1 2
array([0, 1, 2])
- omega_Australia_dim_1(omega_Australia_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_South Africa_stds_dim_0(noise_chol_South Africa_stds_dim_0)int640 1 2
array([0, 1, 2])
- omega_Ireland_dim_0(omega_Ireland_dim_0)int640 1 2
array([0, 1, 2])
- omega_Ireland_dim_1(omega_Ireland_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_Chile_corr_dim_0(noise_chol_Chile_corr_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_Chile_corr_dim_1(noise_chol_Chile_corr_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_United States_stds_dim_0(noise_chol_United States_stds_dim_0)int640 1 2
array([0, 1, 2])
- omega_United States_dim_0(omega_United States_dim_0)int640 1 2
array([0, 1, 2])
- omega_United States_dim_1(omega_United States_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_New Zealand_dim_0(noise_chol_New Zealand_dim_0)int640 1 2 3 4 5
array([0, 1, 2, 3, 4, 5])
- omega_Chile_dim_0(omega_Chile_dim_0)int640 1 2
array([0, 1, 2])
- omega_Chile_dim_1(omega_Chile_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_United States_dim_0(noise_chol_United States_dim_0)int640 1 2 3 4 5
array([0, 1, 2, 3, 4, 5])
- noise_chol_United Kingdom_corr_dim_0(noise_chol_United Kingdom_corr_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_United Kingdom_corr_dim_1(noise_chol_United Kingdom_corr_dim_1)int640 1 2
array([0, 1, 2])
- betaX_United Kingdom_dim_0(betaX_United Kingdom_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - betaX_United Kingdom_dim_1(betaX_United Kingdom_dim_1)int640 1 2
array([0, 1, 2])
- betaX_Ireland_dim_0(betaX_Ireland_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - betaX_Ireland_dim_1(betaX_Ireland_dim_1)int640 1 2
array([0, 1, 2])
- omega_South Africa_dim_0(omega_South Africa_dim_0)int640 1 2
array([0, 1, 2])
- omega_South Africa_dim_1(omega_South Africa_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_Canada_dim_0(noise_chol_Canada_dim_0)int640 1 2 3 4 5
array([0, 1, 2, 3, 4, 5])
- omega_global_corr_dim_0(omega_global_corr_dim_0)int640 1 2
array([0, 1, 2])
- omega_global_corr_dim_1(omega_global_corr_dim_1)int640 1 2
array([0, 1, 2])
- betaX_Australia_dim_0(betaX_Australia_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - betaX_Australia_dim_1(betaX_Australia_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_Canada_corr_dim_0(noise_chol_Canada_corr_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_Canada_corr_dim_1(noise_chol_Canada_corr_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_Chile_stds_dim_0(noise_chol_Chile_stds_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_United Kingdom_dim_0(noise_chol_United Kingdom_dim_0)int640 1 2 3 4 5
array([0, 1, 2, 3, 4, 5])
- noise_chol_Australia_dim_0(noise_chol_Australia_dim_0)int640 1 2 3 4 5
array([0, 1, 2, 3, 4, 5])
- betaX_New Zealand_dim_0(betaX_New Zealand_dim_0)int640 1 2 3 4 5 6 ... 35 36 37 38 39 40
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40]) - betaX_New Zealand_dim_1(betaX_New Zealand_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_Australia_corr_dim_0(noise_chol_Australia_corr_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_Australia_corr_dim_1(noise_chol_Australia_corr_dim_1)int640 1 2
array([0, 1, 2])
- omega_Canada_dim_0(omega_Canada_dim_0)int640 1 2
array([0, 1, 2])
- omega_Canada_dim_1(omega_Canada_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_Australia_stds_dim_0(noise_chol_Australia_stds_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_South Africa_corr_dim_0(noise_chol_South Africa_corr_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_South Africa_corr_dim_1(noise_chol_South Africa_corr_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_Ireland_dim_0(noise_chol_Ireland_dim_0)int640 1 2 3 4 5
array([0, 1, 2, 3, 4, 5])
- noise_chol_Ireland_corr_dim_0(noise_chol_Ireland_corr_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_Ireland_corr_dim_1(noise_chol_Ireland_corr_dim_1)int640 1 2
array([0, 1, 2])
- betaX_Chile_dim_0(betaX_Chile_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - betaX_Chile_dim_1(betaX_Chile_dim_1)int640 1 2
array([0, 1, 2])
- omega_global_stds_dim_0(omega_global_stds_dim_0)int640 1 2
array([0, 1, 2])
- betaX_South Africa_dim_0(betaX_South Africa_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - betaX_South Africa_dim_1(betaX_South Africa_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_Canada_stds_dim_0(noise_chol_Canada_stds_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_New Zealand_corr_dim_0(noise_chol_New Zealand_corr_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_New Zealand_corr_dim_1(noise_chol_New Zealand_corr_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_United States_corr_dim_0(noise_chol_United States_corr_dim_0)int640 1 2
array([0, 1, 2])
- noise_chol_United States_corr_dim_1(noise_chol_United States_corr_dim_1)int640 1 2
array([0, 1, 2])
- noise_chol_Chile_dim_0(noise_chol_Chile_dim_0)int640 1 2 3 4 5
array([0, 1, 2, 3, 4, 5])
- noise_chol_Ireland_stds_dim_0(noise_chol_Ireland_stds_dim_0)int640 1 2
array([0, 1, 2])
- omega_global(chain, draw, omega_global_dim_0)float642.027 0.1165 ... -0.05625 1.081
array([[[ 2.02687573, 0.11647196, 0.37456589, -0.05392265, 0.04851504, 0.19494854], [ 1.42338109, -0.7031298 , 1.20526889, -1.10723708, -0.56268989, 0.16130681], [ 0.17172083, 0.13656726, 0.37594241, 0.03902472, -0.33701542, 0.3199291 ], ..., [ 0.49741775, -0.06073033, 0.21288268, 0.04606727, -0.26836034, 0.32224374], [ 4.03165864, -1.5451338 , 1.51594275, -0.09386334, -0.09212436, 0.06404812], [ 2.50023366, 2.99005488, 0.38783897, 0.54857007, -0.05625022, 1.08114627]]]) - betaX_Canada(chain, draw, betaX_Canada_dim_0, betaX_Canada_dim_1)float64-0.02959 -0.03111 ... -0.004869
array([[[[-0.02958802, -0.03111391, -0.02964134], [-0.03755296, -0.04026266, -0.03852361], [-0.03670091, -0.03886219, -0.03409941], ..., [-0.0257217 , -0.02779475, -0.02744646], [-0.01794688, -0.0182232 , -0.02087961], [ 0.00436016, 0.00622635, 0.00900255]], [[-0.0425969 , -0.04366728, -0.04615484], [-0.05258459, -0.05409159, -0.05866094], [-0.04568509, -0.04411511, -0.05134403], ..., [-0.03367277, -0.03391679, -0.03839855], [-0.02211253, -0.02176753, -0.02595201], [ 0.01687551, 0.02297411, 0.01621278]], [[ 0.03378103, 0.0338103 , 0.03402627], [ 0.04220881, 0.04225048, 0.04234694], [ 0.03633951, 0.03654703, 0.03637642], ..., ... ..., [-0.03480167, -0.03707513, -0.03885839], [-0.02075958, -0.02547082, -0.02567666], [ 0.01950194, 0.01199164, 0.01058504]], [[-0.00426948, 0.00734552, -0.00132585], [-0.00391059, 0.00958301, -0.00163274], [-0.00091696, 0.0074017 , 0.00137115], ..., [-0.00132751, 0.00584341, -0.00113681], [-0.00041472, 0.00370545, -0.00094243], [ 0.00809292, -0.00379171, 0.00419078]], [[ 0.01158302, 0.01273005, 0.01295267], [ 0.01457555, 0.01590839, 0.01613327], [ 0.01244839, 0.01370919, 0.01421059], ..., [ 0.00943236, 0.01019738, 0.01032848], [ 0.00635713, 0.00661155, 0.00668655], [-0.004658 , -0.00547512, -0.00486891]]]]) - noise_chol_South Africa(chain, draw, noise_chol_South Africa_dim_0)float641.581 0.2351 ... -0.06042 0.1807
array([[[ 1.58122840e+00, 2.35063162e-01, 1.81065326e+00, 6.69361180e-03, -2.60958004e-03, 3.70879685e-02], [ 3.29713432e+00, 3.28705752e-02, 3.23124184e-01, 3.28256261e-01, -5.83091202e-01, 2.81468551e+00], [ 8.70964317e-01, -1.50781168e-01, 6.64077957e-01, -7.27371344e-02, -1.63955244e-03, 1.80082914e+00], ..., [ 6.62529343e-01, -2.23523154e-01, 1.85091748e+00, 6.98613335e-01, -2.89741836e-02, 2.05858881e+00], [ 2.86182017e-01, 9.22905260e-02, 7.41981134e-01, 4.80310851e-04, 1.42592625e-01, 5.47812994e-01], [ 1.61046635e-01, 8.23376815e-02, 3.18195594e-01, 2.28347316e-02, -6.04202178e-02, 1.80685825e-01]]]) - omega_New Zealand(chain, draw, omega_New Zealand_dim_0, omega_New Zealand_dim_1)float641.235 0.0 0.0 ... -0.05175 0.8164
array([[[[ 1.23475989, 0. , 0. ], [ 0.05707809, 0.18012104, 0. ], [ 0.12814648, -0.14911574, 0.62815169]], [[ 1.12848127, 0. , 0. ], [-0.4626681 , 1.00359328, 0. ], [-0.78412303, -0.38860358, 0.12772782]], [[ 0.3386176 , 0. , 0. ], [ 0.11565954, 1.97196896, 0. ], [ 0.05263391, -0.35786357, 0.85787868]], ..., [[ 0.38447676, 0. , 0. ], [-0.14655631, 0.63812057, 0. ], [-0.351443 , -0.05787807, 1.01881844]], [[ 1.62221937, 0. , 0. ], [-0.22344884, 0.8221504 , 0. ], [ 0.44877203, -0.3211205 , 1.60225819]], [[ 1.65910263, 0. , 0. ], [ 1.69784562, 0.43286907, 0. ], [ 0.32013471, -0.05175294, 0.81644111]]]]) - lag_coefs_United States(chain, draw, equations, lags, cross_vars)float64-0.1935 -0.2252 ... 0.06284 0.05233
array([[[[[-0.19351 , -0.22521912, -0.1517748 ], [-0.24910903, 0.00387421, -0.07808006]], [[-0.21532541, -0.2332341 , -0.36174169], [-0.15914035, -0.19475919, -0.07084988]], [[-0.08980639, -0.12722645, -0.1085578 ], [-0.30059753, -0.20408448, -0.1545564 ]]], [[[-0.18886062, -0.17840099, -0.21103498], [-0.21810999, -0.20734971, -0.20962268]], [[-0.18253502, -0.20026692, -0.20777754], [-0.20243412, -0.21968197, -0.18696931]], [[-0.15498564, -0.19470107, -0.20251693], [-0.19547364, -0.17793239, -0.21758384]]], ... [[[ 0.04566002, 0.04279759, 0.01117736], [-0.02671817, 0.04126656, -0.01548748]], [[ 0.04193849, 0.02128232, -0.19083049], [ 0.00676198, 0.02390407, -0.02639729]], [[ 0.13080941, 0.02435788, -0.00379633], [ 0.12300067, 0.04885043, 0.05568541]]], [[[ 0.05033085, 0.06261057, 0.05781419], [ 0.06337439, 0.05412811, 0.06496625]], [[ 0.0511598 , 0.06752266, 0.07029739], [ 0.06096998, 0.05747771, 0.05488061]], [[ 0.067718 , 0.07093895, 0.05849658], [ 0.05365325, 0.06284001, 0.05232967]]]]]) - betaX_United States(chain, draw, betaX_United States_dim_0, betaX_United States_dim_1)float64-0.01138 -0.004519 ... 0.01024
array([[[[-0.01137667, -0.00451903, -0.02929914], [ 0.01122024, 0.02658823, 0.01367127], [-0.02489871, -0.04786618, -0.01080599], ..., [-0.02015653, -0.03168506, -0.02160832], [-0.02624333, -0.03773096, -0.02704752], [-0.02427429, -0.03359497, -0.02858871]], [[-0.02393938, -0.0220922 , -0.02268617], [ 0.02222772, 0.02050507, 0.02128093], [-0.02215843, -0.02453128, -0.01918522], ..., [-0.02854824, -0.02827249, -0.02690168], [-0.0358828 , -0.03516884, -0.03417038], [-0.03514358, -0.0342643 , -0.03339847]], [[ 0.01788564, 0.01799546, 0.02211616], [-0.01804569, -0.01675939, -0.01407074], [ 0.02058391, 0.02098643, 0.01705385], ..., ... ..., [-0.02512259, -0.03356722, -0.02451416], [-0.03030195, -0.04144246, -0.02974323], [-0.02848949, -0.03989498, -0.02828534]], [[-0.00182867, 0.00674854, 0.01169921], [ 0.00072007, 0.01583485, -0.00239951], [ 0.00724176, -0.00910908, 0.00424258], ..., [ 0.00248719, -0.00567769, 0.00761097], [ 0.00253376, -0.00677438, 0.01002803], [ 0.00192006, -0.00478675, 0.01053876]], [[ 0.00715985, 0.00594686, 0.00593528], [-0.00608821, -0.00651577, -0.00544604], [ 0.00593823, 0.008 , 0.00843259], ..., [ 0.00821864, 0.008629 , 0.00857489], [ 0.01045224, 0.01077109, 0.01067808], [ 0.01024788, 0.01034098, 0.01024373]]]]) - z_scale_alpha_Ireland(chain, draw)float640.5116 0.1397 ... 0.1342 0.2306
array([[0.51158645, 0.13970817, 0.09375044, 0.22546456, 0.11690336, 0.18071698, 0.13085104, 0.12613609, 0.11071867, 0.11863399, 1.01966015, 0.08379751, 0.35997548, 0.09879424, 0.14538562, 0.24479192, 0.32613972, 0.34103393, 0.09204398, 0.15258833, 0.0846486 , 0.16851581, 0.22037281, 0.43876369, 0.27917013, 0.28890463, 0.36907312, 0.06880731, 0.32653339, 0.16650296, 0.67233228, 0.17520708, 0.73168596, 0.17943095, 0.04339154, 0.87860528, 0.0902929 , 0.12554086, 0.05205397, 0.13163887, 0.18812767, 0.28784634, 0.12096629, 0.28414731, 0.30588849, 0.08410933, 0.16007233, 0.07836366, 0.25604716, 0.22755973, 0.08053769, 0.10195325, 0.15135842, 0.23905198, 0.17683231, 0.20688851, 0.16360327, 0.16471266, 0.60683626, 0.41665465, 0.20856958, 0.09474701, 0.17649755, 0.26976955, 0.13058694, 0.22029265, 0.23742807, 0.57035641, 0.1317696 , 0.19482831, 0.19729133, 0.33593179, 0.11966043, 0.13913473, 0.08842925, 0.16272767, 0.09280604, 3.47688008, 0.1381783 , 0.12320211, 0.30030345, 0.31766401, 0.69338639, 0.20337742, 0.2342212 , 0.18209416, 0.7522726 , 0.19758033, 0.76945964, 0.31365889, 0.12344788, 0.76560755, 0.24752784, 0.25957989, 0.09198846, 0.34464921, 0.37336806, 0.10254146, 0.16931808, 0.10916805, ... 0.15973534, 1.17441072, 0.19365826, 0.08147133, 0.16842842, 0.35135656, 0.09271101, 0.14803967, 0.21271489, 0.17090407, 1.31439143, 0.19568287, 0.1324949 , 0.7336209 , 0.08684975, 0.30756519, 0.28528399, 0.61887749, 0.37268476, 0.08006531, 0.26596824, 0.10191996, 0.23494502, 0.73125934, 0.16135043, 0.31041881, 0.24232558, 0.23723761, 0.29023683, 0.27058875, 0.12401297, 0.11695787, 0.13830657, 0.16463358, 0.20700472, 0.14013282, 0.16698267, 0.26857147, 0.18290139, 0.18879111, 0.14139622, 0.20556509, 0.11803317, 0.13828638, 0.10692438, 0.07661694, 0.61984467, 0.22950678, 0.52285373, 0.26827668, 0.27439876, 0.2871008 , 0.0865294 , 0.16514618, 0.11516385, 0.19218968, 0.14700579, 0.58597846, 0.17383473, 0.09574533, 0.35871119, 0.1845075 , 0.14243374, 0.19698913, 0.24377526, 0.41340451, 0.23316587, 0.13564413, 0.2755567 , 0.62852515, 0.26603256, 0.07591389, 0.14888167, 0.5318431 , 0.15210543, 0.13585047, 0.41461438, 0.31654239, 0.18930941, 0.5823387 , 0.13762684, 0.16860118, 0.10612805, 0.18198135, 0.15497983, 0.14827952, 0.08008737, 0.07503787, 0.16820413, 0.06952973, 0.43373073, 0.1333964 , 0.20756783, 0.23637012, 0.11010225, 0.22196761, 0.2610846 , 0.65380877, 0.13424296, 0.23055266]]) - z_scale_beta_United States(chain, draw)float640.2073 0.07694 ... 0.242 0.1381
array([[0.20734036, 0.07693513, 0.18672826, 0.19813901, 0.22038334, 0.16681774, 0.22328428, 0.26010326, 0.2193448 , 1.88297581, 0.11857573, 0.19167814, 0.17406328, 0.2120837 , 0.29897147, 0.1438986 , 0.5631577 , 0.10040927, 0.14017919, 0.14549112, 0.17853873, 0.47852713, 0.15319318, 0.28302628, 0.17486913, 0.29753298, 0.67343941, 0.30223281, 0.20796031, 0.32657908, 0.15982154, 0.07102473, 0.11100181, 0.19291736, 0.11073926, 0.26723373, 0.12051404, 0.17071922, 0.08569388, 0.1487173 , 0.68398926, 1.44224934, 0.07962882, 0.13715676, 0.20909543, 0.41409616, 0.29805412, 0.07817491, 0.55319383, 0.2176259 , 0.09704971, 0.49317679, 0.06315766, 0.08790942, 0.1501398 , 0.21665696, 0.23579709, 0.29819007, 0.3497411 , 0.18464204, 0.1578776 , 0.42834809, 0.09655194, 0.10765619, 0.19653686, 0.23628055, 0.16701936, 0.29582332, 0.08325537, 0.23609906, 0.10505704, 0.23114092, 0.14968839, 0.2302336 , 0.2105364 , 0.67058982, 0.47292089, 0.24122525, 0.19631579, 0.17362513, 0.31328028, 0.2562648 , 0.12718644, 0.46851371, 0.24181609, 0.14474166, 0.30420576, 0.13418311, 0.21842447, 0.2507538 , 0.13666702, 0.23586703, 0.58408083, 0.34207287, 0.11223281, 0.10982336, 0.31975457, 0.22282189, 0.17944722, 0.21874003, ... 0.20688043, 0.47403467, 0.25717756, 0.19066508, 0.12625064, 0.44768237, 0.16660089, 0.0706952 , 0.16784098, 0.36421198, 1.46345517, 0.50179268, 0.1523372 , 0.1956238 , 0.14694697, 0.24004588, 0.11692893, 0.10727995, 1.66596053, 0.18589723, 0.13322186, 0.13850513, 0.09790181, 0.15698714, 0.16617059, 0.09406059, 0.10885364, 0.21139588, 0.16196186, 0.16195316, 0.07182767, 0.31162329, 0.30275279, 0.24104304, 0.12604417, 0.26921645, 0.27088864, 0.15102642, 0.17063538, 0.41558565, 0.10870371, 0.16531107, 0.15824463, 0.32388857, 0.14568043, 0.26336275, 0.13224454, 0.2083225 , 0.04507302, 0.2587414 , 0.26198809, 0.07615262, 0.08256953, 0.21247356, 0.21920917, 0.76939755, 0.20889981, 0.27236234, 0.52139234, 0.14835252, 0.37085224, 0.3050953 , 0.12233382, 0.11905191, 0.33253917, 0.14611272, 0.35574692, 0.11257593, 0.18050403, 0.34533744, 0.22266884, 0.48356926, 0.21836733, 0.1846639 , 0.13248554, 0.26967546, 0.12959754, 0.25059262, 0.17419057, 0.13497309, 0.0906121 , 0.12921711, 0.21698366, 0.20942048, 0.04668369, 0.24006113, 0.064138 , 0.05198891, 0.23646192, 0.53840494, 0.15887142, 0.12730902, 0.52102642, 0.24299043, 0.14601515, 0.10681178, 0.18504517, 0.1231525 , 0.24204206, 0.13810632]]) - z_scale_alpha_New Zealand(chain, draw)float640.1626 0.2047 ... 0.1554 0.1919
array([[0.16257979, 0.20473353, 0.1660467 , 0.07499469, 0.36006641, 0.27578616, 0.33046821, 0.15915183, 0.12910625, 0.13831407, 0.38751857, 0.0874059 , 0.09957618, 0.48866631, 0.19392543, 0.16874209, 0.33632883, 0.71572109, 0.13533204, 0.13084356, 0.17533974, 0.1627762 , 0.41064477, 0.09139926, 0.42826298, 0.24550348, 0.54457365, 0.109875 , 0.13222741, 0.1482109 , 0.15881414, 0.30962614, 0.25116188, 1.26561043, 0.33560544, 0.33325531, 0.40790865, 0.08030093, 0.44762566, 0.2142664 , 0.18684605, 0.15369943, 0.2504877 , 0.15317435, 0.22186467, 0.09589369, 0.12158797, 0.17326896, 0.04194884, 0.1814088 , 0.13621317, 0.30596159, 0.342959 , 0.0943213 , 0.24865241, 0.10509923, 0.08364646, 0.14001044, 0.10834617, 0.40030199, 0.09234299, 0.24991498, 0.13387583, 0.21161424, 0.29525061, 0.78664943, 0.12887164, 0.64957614, 0.19592254, 0.13840067, 0.13675668, 0.30774641, 0.45503469, 0.72828347, 0.08071809, 0.27950943, 0.32301921, 0.26599902, 0.15022287, 0.24510993, 0.27177268, 0.12823048, 0.3827117 , 1.90113199, 0.07435057, 0.33548514, 0.09668177, 0.18994735, 0.17390371, 0.13445681, 0.44980731, 0.20885992, 0.20527302, 0.2798389 , 0.44963417, 0.21717974, 0.09733105, 0.19918713, 0.07762868, 0.13818783, ... 0.25566491, 0.30947523, 0.24619062, 1.89050063, 0.13979159, 0.11169646, 0.13075423, 0.4799055 , 0.1438906 , 0.10359371, 0.23691968, 0.20487274, 0.1360907 , 0.19665027, 0.14693158, 0.45196561, 0.19480535, 0.10585268, 0.32039815, 0.11680072, 0.43485763, 0.13889767, 0.11705017, 0.08644812, 0.08329165, 0.18170034, 0.13523083, 0.39954947, 0.22274435, 0.19364089, 0.22599914, 0.15006166, 0.14756247, 0.28986554, 0.08765432, 0.08399995, 0.11124613, 0.16629054, 0.27270246, 0.12558614, 0.08695939, 0.22951728, 0.19615921, 0.11669168, 0.11381599, 0.71645648, 0.29388051, 0.21441234, 0.18118576, 0.06118888, 0.2243009 , 0.38444353, 0.16246841, 0.15515467, 0.23542627, 0.18778183, 0.22342853, 0.35938595, 0.25569006, 0.32454787, 0.56908536, 0.33990059, 0.11888528, 0.23752101, 0.17677255, 0.37918781, 0.33519036, 0.09408516, 0.1167565 , 0.10384138, 0.28937624, 0.14690894, 0.10925158, 0.25924562, 0.09139761, 0.10794599, 0.15254773, 0.13925995, 0.09375719, 0.15574462, 0.56007416, 0.64587154, 0.1143188 , 0.32715885, 0.21143106, 0.1363281 , 0.09308427, 0.09047241, 0.32805184, 0.16646588, 0.24756532, 0.36085691, 0.14129387, 0.1061752 , 0.12475895, 0.21138747, 0.24721275, 0.15752091, 0.1553929 , 0.19194603]]) - noise_chol_United Kingdom_stds(chain, draw, noise_chol_United Kingdom_stds_dim_0)float640.03717 2.628 ... 0.4055 0.9324
array([[[3.71684705e-02, 2.62803616e+00, 1.89761851e-03], [5.13831503e-01, 9.58806618e-01, 8.79435090e-01], [4.04689556e-01, 2.48416636e-01, 2.04990466e-01], ..., [1.62342154e+00, 9.95776379e-01, 1.13714189e-01], [2.92163436e-01, 2.45445126e-01, 5.07074668e-01], [2.76772440e+00, 4.05453310e-01, 9.32391346e-01]]]) - noise_chol_New Zealand_stds(chain, draw, noise_chol_New Zealand_stds_dim_0)float640.5759 0.01992 ... 0.4947 0.4636
array([[[0.57589167, 0.01992298, 1.07403478], [0.46120014, 0.55327983, 0.07426313], [0.42868234, 2.83517613, 1.20754258], ..., [0.30040541, 0.97758018, 1.67099333], [1.10737718, 0.67647755, 2.04557369], [0.53009693, 0.49466781, 0.46359907]]]) - alpha_United States(chain, draw, equations)float64-0.1123 -0.1273 ... -0.1899 -0.2605
array([[[-0.1122754 , -0.12734704, -0.11031494], [ 0.10359595, 0.12226043, 0.0931555 ], [ 0.23832381, 0.10872559, 0.21367728], ..., [ 0.06169654, 0.04741402, 0.12548373], [-0.18185839, -0.15345144, 0.44086299], [-0.2822267 , -0.18992889, -0.26050735]]]) - omega_United Kingdom(chain, draw, omega_United Kingdom_dim_0, omega_United Kingdom_dim_1)float640.9407 0.0 0.0 ... 0.01623 0.9991
array([[[[ 0.94066212, 0. , 0. ], [ 0.52129994, 1.52615182, 0. ], [-0.02478948, 0.02157187, 0.08940098]], [[ 1.14461231, 0. , 0. ], [-0.41585808, 1.1208319 , 0. ], [-0.80488536, -0.21964174, 0.31724845]], [[ 0.32303426, 0. , 0. ], [-0.02630292, 0.27505622, 0. ], [-0.02302956, -0.13349563, 0.23918957]], ..., [[ 1.1429204 , 0. , 0. ], [-0.0091967 , 0.6614462 , 0. ], [ 0.02132631, -0.11638239, 0.20265227]], [[ 0.95053025, 0. , 0. ], [-0.35868561, 0.44962075, 0. ], [-0.02624491, -0.0391682 , 0.42833245]], [[ 2.61443627, 0. , 0. ], [ 1.65874467, 0.38647794, 0. ], [ 0.20439408, 0.01622911, 0.99906375]]]]) - omega_Australia(chain, draw, omega_Australia_dim_0, omega_Australia_dim_1)float642.798 0.0 0.0 ... -0.01649 0.6657
array([[[[ 2.79849438, 0. , 0. ], [ 0.05129535, 0.33119208, 0. ], [-0.00809379, 0.18551762, 0.38975745]], [[ 2.19888565, 0. , 0. ], [-0.2283893 , 1.44020266, 0. ], [-0.74426769, -0.49472631, 0.45332848]], [[ 0.17032368, 0. , 0. ], [ 0.05269687, 0.78212657, 0. ], [ 0.04829656, -0.12379496, 0.29457698]], ..., [[ 0.51430996, 0. , 0. ], [-0.02749578, 0.10576037, 0. ], [ 0.01963391, -0.10862464, 0.156789 ]], [[ 1.94167524, 0. , 0. ], [-0.25907015, 0.36416895, 0. ], [-0.00998854, 0.13205535, 1.79311081]], [[ 1.92090981, 0. , 0. ], [ 1.64235627, 0.50585178, 0. ], [ 0.31495163, -0.016493 , 0.66569132]]]]) - lag_coefs_Australia(chain, draw, equations, lags, cross_vars)float64-0.1962 -0.04238 ... 0.05701 0.0538
array([[[[[-0.1961536 , -0.04238493, -0.02241971], [-0.15077542, -0.21313777, -0.09135567]], [[-0.19894081, -0.23320756, -0.27911626], [ 0.0578797 , -0.30527527, -0.22313689]], [[-0.22023162, 0.03049929, -0.00585038], [-0.1296688 , -0.12040214, -0.09948174]]], [[[-0.22891816, -0.1967858 , -0.21468313], [-0.2100601 , -0.24386615, -0.17782713]], [[-0.25126413, -0.20889774, -0.18437045], [-0.20418875, -0.20383443, -0.19456342]], [[-0.22720345, -0.18963524, -0.2048201 ], [-0.2082145 , -0.18245376, -0.1971739 ]]], ... [[[ 0.04336268, 0.03602578, 0.03023212], [ 0.04924396, -0.01320222, 0.00612381]], [[ 0.00549566, 0.01761463, -0.01967821], [ 0.03505736, 0.01685139, -0.00436121]], [[ 0.01222543, 0.02852398, 0.03352444], [ 0.01152931, -0.0016901 , -0.01869344]]], [[[ 0.07208268, 0.04829299, 0.07349987], [ 0.06538528, 0.05084192, 0.06645425]], [[ 0.07066286, 0.06578292, 0.06102497], [ 0.0391673 , 0.053377 , 0.04046732]], [[ 0.0664287 , 0.06745102, 0.05934131], [ 0.05570972, 0.0570131 , 0.05380317]]]]]) - z_scale_beta_New Zealand(chain, draw)float640.1596 0.3191 ... 0.09559 0.1677
array([[0.1595764 , 0.31909431, 0.14984458, 0.473567 , 0.30314647, 0.41680411, 0.14055266, 0.21443999, 0.28680193, 0.207827 , 0.12470213, 0.27358584, 0.15877701, 0.1766966 , 0.31672804, 0.34511963, 0.20636382, 0.17567789, 0.37350301, 0.16425487, 0.44202529, 0.17671469, 1.0025769 , 0.17129725, 0.11397575, 0.36668509, 0.12703921, 0.31440648, 0.65616426, 0.27927965, 0.07146724, 0.29072444, 0.30097163, 0.42272131, 0.50763782, 0.11535842, 0.19219011, 0.08155474, 0.14333571, 0.10171381, 0.16189723, 0.09084773, 0.18996573, 0.28882752, 0.5236453 , 0.6868979 , 0.26741783, 0.08599283, 0.13714952, 0.32331594, 0.85861371, 0.13800996, 0.56831276, 0.15072784, 0.14006245, 0.18924386, 0.16490975, 0.2730547 , 1.81338977, 0.21590061, 0.13114485, 0.19547382, 0.30880499, 0.11408552, 0.18137243, 0.48850668, 0.35926686, 0.11678598, 0.18221083, 0.0764939 , 0.59665507, 0.16989122, 0.10456052, 0.28523524, 0.52829938, 0.63250685, 0.11275178, 0.47830736, 0.20330458, 0.05676593, 0.22213268, 0.37820405, 0.11673709, 0.15349803, 0.13847562, 0.45858207, 0.28596827, 0.09620013, 0.09036497, 0.06405045, 0.20398546, 0.19810778, 0.09165543, 0.15941918, 0.28383069, 0.16264909, 0.24714102, 0.41887418, 0.11412962, 0.22608534, ... 0.09466267, 0.32698251, 0.24179005, 0.17866664, 0.14031657, 0.14328991, 0.18572951, 0.18990388, 0.23515911, 0.45604518, 0.05824148, 0.16369792, 0.0536564 , 0.14770094, 0.49495615, 0.10217579, 0.11772349, 0.07809962, 0.14428259, 0.17064257, 0.13764948, 0.18450781, 0.17910942, 0.24048955, 0.13946675, 0.21332236, 0.08934233, 0.12498345, 0.08966867, 0.24637675, 0.1822877 , 0.19826166, 0.11381018, 0.25234185, 0.1336435 , 0.09102639, 0.92209292, 0.27710708, 0.24156467, 0.13801857, 0.36776389, 0.15985224, 0.44076973, 0.14350409, 0.19963751, 0.70209226, 0.18562798, 0.19088137, 0.10218107, 0.19664039, 0.10636086, 0.24755424, 0.25374839, 0.06738148, 0.21254131, 0.56908049, 0.34745447, 0.44286962, 0.21850306, 0.21384828, 0.1672484 , 0.34116064, 0.16123007, 0.10147714, 0.61500581, 0.17133974, 0.60976176, 0.12176558, 0.16685053, 0.06602818, 0.18366747, 0.14912495, 0.14119082, 0.22471715, 0.25352004, 0.63217796, 0.38316989, 0.77526843, 0.14541542, 0.12339019, 0.0495911 , 0.28415788, 0.184606 , 0.59120927, 0.13984808, 0.42151482, 0.54217349, 0.1484539 , 0.11815923, 0.11127211, 0.29087105, 0.13832078, 0.2819072 , 0.13687175, 0.49502223, 0.18897839, 0.07491648, 0.06200944, 0.09559076, 0.16772793]]) - alpha_New Zealand(chain, draw, equations)float64-0.1341 -0.1184 ... -0.309 -0.2621
array([[[-0.13411454, -0.11837157, -0.09823672], [ 0.06188021, 0.03255268, 0.06646392], [ 0.20641065, 0.1379772 , 0.19274663], ..., [ 0.09546404, 0.06121229, 0.03803407], [ 0.05411883, 0.02830194, 0.05475787], [-0.26640311, -0.30904358, -0.26214372]]]) - lag_coefs_Ireland(chain, draw, equations, lags, cross_vars)float64-0.1868 -0.1527 ... 0.06407 0.05551
array([[[[[-0.18678705, -0.15265051, -0.14907884], [-0.18391385, -0.18808559, -0.12134384]], [[-0.19569234, -0.24607583, -0.17957038], [-0.16946666, -0.14072849, -0.21832593]], [[-0.17528042, -0.21988379, -0.17378612], [-0.19794297, -0.15543846, -0.12668154]]], [[[-0.20297659, -0.19835389, -0.22150673], [-0.21533709, -0.21462178, -0.21762576]], [[-0.22332784, -0.20240641, -0.21523745], [-0.1852436 , -0.21375762, -0.19681 ]], [[-0.20094811, -0.201738 , -0.2196669 ], [-0.18584382, -0.19476701, -0.19170025]]], ... [[[ 0.17158737, 0.17518965, 0.05365764], [-0.01095842, 0.06114475, 0.02548319]], [[-0.0470689 , 0.08979091, 0.04993573], [ 0.05302195, -0.01399206, 0.05093116]], [[-0.07491731, 0.07711348, 0.02723354], [ 0.07700294, -0.00584274, 0.07558744]]], [[[ 0.06073059, 0.05678287, 0.0623281 ], [ 0.05840248, 0.05519933, 0.06312752]], [[ 0.05587671, 0.06360262, 0.05175008], [ 0.06448157, 0.04623022, 0.06312355]], [[ 0.05817472, 0.06320071, 0.04800966], [ 0.06643841, 0.06407291, 0.05550688]]]]]) - noise_chol_South Africa_stds(chain, draw, noise_chol_South Africa_stds_dim_0)float641.581 1.826 ... 0.3287 0.1919
array([[[1.5812284 , 1.82584772, 0.0377774 ], [3.29713432, 0.3247918 , 2.89313015], [0.87096432, 0.68098054, 1.80229825], ..., [0.66252934, 1.86436534, 2.17409475], [0.28618202, 0.74769883, 0.5660671 ], [0.16104663, 0.32867603, 0.19188381]]]) - alpha_South Africa(chain, draw, equations)float64-0.1202 -0.1137 ... -0.2432 -0.2544
array([[[-0.12022232, -0.11367182, -0.10794469], [ 0.07282995, 0.04322713, 0.06724012], [ 0.06996945, 0.14752209, 0.16313593], ..., [ 0.11707275, 0.05555555, -0.16032398], [ 0.04373721, 0.09431552, 0.04430106], [-0.26879254, -0.24317041, -0.25442029]]]) - omega_Ireland(chain, draw, omega_Ireland_dim_0, omega_Ireland_dim_1)float642.586 0.0 0.0 ... 0.0008263 0.8505
array([[[[ 2.58639628e+00, 0.00000000e+00, 0.00000000e+00], [ 4.09927426e-01, 1.35269659e+00, 0.00000000e+00], [-5.37619633e-02, 2.44418105e-02, 1.83495101e-01]], [[ 1.18559436e+00, 0.00000000e+00, 0.00000000e+00], [-4.93503902e-01, 1.07422866e+00, 0.00000000e+00], [-7.72675644e-01, -3.98223351e-01, 1.55929365e-01]], [[ 5.19799071e-01, 0.00000000e+00, 0.00000000e+00], [ 3.33304174e-02, 1.56625045e+00, 0.00000000e+00], [-8.12668016e-02, -7.65072574e-02, 4.02325125e-01]], ..., [[ 9.03289140e-01, 0.00000000e+00, 0.00000000e+00], [-8.16329007e-02, 7.61894507e-01, 0.00000000e+00], [ 2.95952632e-01, -3.81254889e-01, 1.64034000e+00]], [[ 1.99897232e+00, 0.00000000e+00, 0.00000000e+00], [-2.06124180e-01, 7.66606308e-01, 0.00000000e+00], [-1.73635520e-02, 1.48188438e-01, 8.50744813e-01]], [[ 1.95106390e+00, 0.00000000e+00, 0.00000000e+00], [ 1.74963152e+00, 4.01199909e-01, 0.00000000e+00], [ 3.53497383e-01, 8.26304021e-04, 8.50474997e-01]]]]) - lag_coefs_United Kingdom(chain, draw, equations, lags, cross_vars)float64-0.3605 -0.1986 ... 0.06297 0.06245
array([[[[[-0.36052092, -0.19860953, 0.02177938], [-0.03464429, -0.09187011, -0.43320885]], [[ 0.03266122, 0.05491349, -0.33003956], [-0.24663718, -0.32606953, -0.15747561]], [[-0.0260827 , -0.12671588, -0.25819839], [ 0.00386647, 0.06725576, -0.38870329]]], [[[-0.26505344, -0.20221769, -0.2292391 ], [-0.19091368, -0.24630777, -0.16210045]], [[-0.15381381, -0.24810409, -0.16861722], [-0.14581489, -0.19537078, -0.19954608]], [[-0.22349155, -0.19670298, -0.18637268], [-0.14958251, -0.14433438, -0.2048611 ]]], ... [[[ 0.0037063 , 0.07384256, 0.0575044 ], [-0.04287917, 0.07976311, -0.00292942]], [[ 0.04505964, -0.00613842, 0.08048952], [-0.01867705, 0.01364884, -0.078449 ]], [[-0.0179588 , 0.02668368, -0.02074897], [ 0.04733557, -0.04998428, -0.04249807]]], [[[ 0.06611016, 0.04871902, 0.05118372], [ 0.0757195 , 0.05552676, 0.06288292]], [[ 0.0604792 , 0.06258736, 0.05946574], [ 0.06521125, 0.0639017 , 0.06616612]], [[ 0.04742713, 0.07416921, 0.04645026], [ 0.05075313, 0.06297496, 0.06244988]]]]]) - alpha_Canada(chain, draw, equations)float64-0.1172 -0.1188 ... -0.2555 -0.2642
array([[[-0.11724578, -0.11883244, -0.11291433], [ 0.05042853, 0.05767736, 0.10802469], [ 0.21811029, 0.23366782, 0.20019744], ..., [ 0.13969839, 0.04808045, 0.10640985], [ 0.06852303, 0.07106682, 0.06308139], [-0.23532934, -0.25552875, -0.26415459]]]) - z_scale_beta_Ireland(chain, draw)float640.07163 0.08413 ... 0.3716 0.1233
array([[0.07163329, 0.08413478, 0.08755404, 0.23453179, 0.30542108, 0.43203706, 0.11621525, 0.22725081, 0.14066017, 0.06447647, 0.18195441, 0.2979855 , 0.25577131, 0.07385324, 0.14376264, 0.12304787, 0.83388509, 0.11786395, 0.17542277, 0.13408145, 0.27892992, 0.11153842, 0.13897429, 0.14334591, 0.13401484, 0.14252127, 0.39030187, 0.15815744, 0.07312245, 0.13120768, 0.22964085, 0.19894006, 0.10616301, 0.15233651, 0.45655982, 0.1301663 , 0.972213 , 0.24668618, 0.22498558, 0.22384238, 0.19722808, 0.21387158, 0.34359696, 0.07736254, 0.14463155, 1.0583714 , 0.12364719, 0.16719231, 0.10613701, 0.13767955, 0.23892066, 0.17893978, 0.33054068, 0.12373109, 0.18793181, 0.82859709, 0.45311229, 0.18805356, 0.1728399 , 0.15028426, 0.25672119, 0.18429149, 0.24616073, 0.19184509, 0.11043875, 0.21774424, 0.18178512, 0.17160492, 0.14600922, 0.32059958, 0.19876657, 0.4457766 , 1.14460319, 0.31732579, 0.29761875, 0.05390961, 0.12838263, 0.26261061, 1.29202241, 0.13479564, 0.18347114, 0.14445945, 0.11380765, 0.23588144, 0.28325807, 0.06268906, 0.24010887, 0.08551197, 0.14933643, 0.31853377, 0.28051309, 0.13742563, 0.17363697, 0.17822277, 0.12570658, 0.22254829, 0.11654764, 0.31638426, 0.1752214 , 0.06424156, ... 0.18017406, 0.25107532, 0.14125656, 0.1340293 , 0.15143401, 0.17979784, 0.10230655, 0.09610106, 0.23308408, 0.16685291, 0.35500314, 0.11487525, 0.14464978, 0.42393198, 0.91474375, 0.11772092, 0.51607064, 0.13537261, 0.11358025, 0.11583106, 0.19417048, 0.13565478, 0.23522559, 0.0905361 , 0.10013519, 0.19108106, 0.16220839, 0.32430115, 0.07865016, 0.28852676, 0.18530219, 0.26364345, 0.05486286, 0.29282799, 0.10392355, 0.49220611, 0.15431847, 0.08114926, 0.46771052, 0.27909326, 0.21189142, 0.11080887, 0.49201439, 0.20806369, 0.3919624 , 0.29717214, 0.08647545, 0.1629127 , 0.11928048, 0.10979854, 0.1155407 , 0.29554581, 0.16796259, 0.77389029, 0.16345719, 0.35637281, 0.09542406, 0.39445065, 0.23896037, 0.13337993, 0.13671295, 0.06786871, 0.15321679, 0.64859899, 0.1688205 , 0.16550456, 0.28892148, 1.02925402, 0.12911254, 0.44169065, 1.09725051, 0.12139197, 0.15877436, 0.53522059, 0.25541761, 2.50454558, 0.16618171, 0.54993892, 0.29564516, 0.12609919, 0.1834574 , 0.61799822, 0.10576515, 0.53324708, 1.50356317, 0.26191044, 0.41923726, 0.08723944, 0.30142969, 0.06410624, 0.20717064, 0.08829394, 0.10641084, 0.65765017, 0.42985316, 0.08507945, 0.24317143, 0.16548908, 0.37164655, 0.12326749]]) - noise_chol_Chile_corr(chain, draw, noise_chol_Chile_corr_dim_0, noise_chol_Chile_corr_dim_1)float641.0 -0.1709 0.1487 ... -0.3751 1.0
array([[[[ 1. , -0.17090528, 0.14869546], [-0.17090528, 1. , 0.21319977], [ 0.14869546, 0.21319977, 1. ]], [[ 1. , -0.39296326, 0.24200419], [-0.39296326, 1. , -0.07165122], [ 0.24200419, -0.07165122, 1. ]], [[ 1. , -0.03235085, 0.37344916], [-0.03235085, 1. , 0.03250628], [ 0.37344916, 0.03250628, 1. ]], ..., [[ 1. , -0.25233108, -0.34355138], [-0.25233108, 1. , 0.07825342], [-0.34355138, 0.07825342, 1. ]], [[ 1. , 0.30324589, 0.23548559], [ 0.30324589, 1. , 0.29728758], [ 0.23548559, 0.29728758, 1. ]], [[ 1. , -0.27067426, 0.05400277], [-0.27067426, 1. , -0.37509298], [ 0.05400277, -0.37509298, 1. ]]]]) - noise_chol_United States_stds(chain, draw, noise_chol_United States_stds_dim_0)float641.025 2.018 0.5789 ... 0.619 0.2143
array([[[1.02485906, 2.01769132, 0.57885858], [0.12223676, 0.34959891, 0.81983802], [1.81531772, 1.2366803 , 2.8199029 ], ..., [0.63896902, 0.23374696, 3.08903391], [0.93403749, 1.1745727 , 0.23355354], [0.91164171, 0.61897674, 0.21429496]]]) - omega_United States(chain, draw, omega_United States_dim_0, omega_United States_dim_1)float641.48 0.0 0.0 ... -0.002397 0.7022
array([[[[ 1.4798585 , 0. , 0. ], [ 0.07280083, 1.27139482, 0. ], [-0.0490548 , 0.15088609, 0.3760185 ]], [[ 1.02459204, 0. , 0. ], [-0.49268994, 0.94289404, 0. ], [-0.73130831, -0.31803447, 0.34975097]], [[ 1.23923872, 0. , 0. ], [-0.10186104, 0.92091395, 0. ], [ 0.07675077, 0.7677725 , 1.71391872]], ..., [[ 0.57856465, 0. , 0. ], [-0.02838119, 0.22482083, 0. ], [-0.66458456, -0.06387396, 1.77003816]], [[ 1.47939746, 0. , 0. ], [-0.32124116, 1.23342166, 0. ], [-0.02755179, -0.00738831, 0.20319158]], [[ 1.82199953, 0. , 0. ], [ 1.80787964, 0.46908523, 0. ], [ 0.28886718, -0.00239748, 0.70220697]]]]) - lag_coefs_New Zealand(chain, draw, equations, lags, cross_vars)float64-0.2065 -0.1456 ... 0.06747 0.05084
array([[[[[-0.20654316, -0.14562934, -0.26288777], [-0.16641344, -0.15950696, -0.11481519]], [[-0.25234332, -0.10828001, -0.192556 ], [-0.13940197, -0.2283368 , -0.12041435]], [[-0.1208677 , -0.23817163, -0.19558745], [-0.13492058, -0.06619099, -0.21045424]]], [[[-0.32770078, -0.10647709, -0.2173961 ], [-0.11299811, -0.09182672, -0.25010002]], [[-0.15915056, -0.28384819, -0.15889862], [-0.10944911, -0.20428178, -0.22873497]], [[-0.18243547, -0.21476259, -0.08634329], [-0.19036886, -0.1796177 , -0.19128967]]], ... [[[ 0.02159585, 0.03169854, 0.02494288], [ 0.01473301, 0.02966987, -0.01652773]], [[ 0.01446537, -0.00331149, 0.00869062], [ 0.00396315, -0.01732477, 0.01578873]], [[ 0.03041103, 0.01238237, 0.01386057], [ 0.00996718, 0.07574674, 0.02485907]]], [[[ 0.04620779, 0.05968816, 0.06256686], [ 0.04269093, 0.059605 , 0.05580936]], [[ 0.05003254, 0.06448281, 0.06014105], [ 0.06150055, 0.05707461, 0.06059594]], [[ 0.05997411, 0.0561341 , 0.05838696], [ 0.06310736, 0.06746523, 0.05083574]]]]]) - z_scale_beta_Australia(chain, draw)float640.2788 0.1047 ... 0.08373 0.2213
array([[0.27881565, 0.10469813, 0.1211257 , 0.25124204, 0.16018028, 0.23515602, 0.16096252, 0.29431363, 0.98003321, 0.15331914, 0.09585257, 0.09113346, 0.0837121 , 0.1312792 , 0.88342217, 0.164084 , 0.44128772, 0.37055024, 0.07643875, 0.24940322, 0.2673004 , 0.18368429, 0.33493299, 0.1157403 , 0.1971344 , 0.60712343, 0.1726061 , 0.16856774, 0.09592041, 0.12013222, 0.1370233 , 0.2426129 , 0.30202182, 0.28234465, 0.71192041, 0.05518795, 0.21404515, 0.14405558, 0.155575 , 0.26943012, 0.28554819, 0.09805847, 0.09992052, 0.19794793, 0.31936183, 0.10023596, 0.07385885, 0.26026719, 0.25966287, 0.15740078, 0.28298877, 0.23618574, 0.10719332, 0.18815603, 0.19847085, 0.09465452, 0.13741752, 0.14836489, 0.25264099, 0.41073982, 0.08606129, 0.12396397, 0.31378118, 0.12070497, 0.51071 , 0.23677943, 0.18116091, 0.20819466, 0.17827292, 0.17258466, 0.15612765, 0.12282135, 0.18750847, 0.14498828, 0.10212388, 0.19377678, 0.31166066, 0.10249523, 0.27172758, 0.42374111, 1.27183713, 0.21220824, 0.18636243, 0.31130914, 0.10902415, 0.10676085, 0.12933155, 0.35427775, 0.25906178, 0.53339082, 0.22363702, 0.34051648, 0.15133265, 0.13279198, 0.14951954, 0.14884373, 0.44572052, 0.20747406, 0.24888566, 0.1628897 , ... 0.10074804, 0.24566984, 0.14527515, 0.21195912, 0.29674904, 0.39399415, 0.24526314, 0.16635332, 0.12266914, 0.11014299, 0.11756377, 0.19903654, 0.13099525, 0.20033183, 0.1225756 , 0.15833845, 0.07301871, 0.10099471, 0.26370506, 0.09525833, 0.25715513, 0.22447191, 0.7251473 , 0.24861478, 0.06885664, 0.11701662, 0.4595473 , 0.8219404 , 0.19257692, 0.34735225, 0.18519346, 0.1219051 , 0.28037848, 0.23374819, 0.18555476, 0.20611156, 0.20997989, 0.13054928, 0.41153894, 0.29190641, 0.32473762, 0.09319944, 0.22788271, 0.11747517, 0.08590645, 0.35781655, 0.10869864, 0.26159247, 0.205304 , 0.32638852, 0.15692531, 0.3650207 , 0.16708497, 0.1859105 , 0.09055496, 0.18565301, 0.28684467, 0.12816474, 0.2203393 , 0.28199904, 0.26975798, 0.15679835, 0.07407453, 0.16824704, 0.3836013 , 0.05707429, 0.20832219, 0.10882047, 0.94681812, 0.10141334, 0.17883141, 0.42572401, 0.15002428, 0.2590692 , 0.125405 , 0.1197349 , 0.41379128, 0.47283222, 0.22757644, 0.2949491 , 0.17909723, 0.34026183, 0.17221909, 0.11406275, 0.17099736, 0.32597273, 0.16747589, 0.09508129, 0.65332027, 0.13359989, 0.47814597, 0.07304196, 0.08927572, 0.15589993, 0.23143155, 0.28141908, 0.19219578, 0.11351882, 0.08373141, 0.22127545]]) - noise_chol_New Zealand(chain, draw, noise_chol_New Zealand_dim_0)float640.5759 0.007675 ... -0.04572 0.4611
array([[[ 0.57589167, 0.0076753 , 0.01838518, 0.27958843, -0.31350159, 0.98848256], [ 0.46120014, 0.08143382, 0.54725415, -0.05300044, 0.00530818, 0.05174736], [ 0.42868234, 0.10437683, 2.83325416, 0.05997802, -0.36911415, 1.14817963], ..., [ 0.30040541, -0.2104437 , 0.95466039, -0.64734286, 0.09880133, 1.53733673], [ 1.10737718, 0.05896507, 0.67390281, 0.56472082, -0.37005175, 1.93093858], [ 0.53009693, -0.03661856, 0.49331058, 0.01351801, -0.04571649, 0.46114137]]]) - omega_Chile(chain, draw, omega_Chile_dim_0, omega_Chile_dim_1)float640.936 0.0 0.0 ... -0.09397 0.7722
array([[[[ 9.36020417e-01, 0.00000000e+00, 0.00000000e+00], [ 1.52401959e-02, 3.87128043e-01, 0.00000000e+00], [ 4.37408784e-02, 1.33147881e-01, 5.28437735e-01]], [[ 1.04733738e+00, 0.00000000e+00, 0.00000000e+00], [-5.38931203e-01, 9.55919656e-01, 0.00000000e+00], [-7.35513836e-01, -3.86820347e-01, 2.41585067e-01]], [[ 3.26869831e+00, 0.00000000e+00, 0.00000000e+00], [ 3.30205840e-02, 5.90436206e-01, 0.00000000e+00], [ 5.97951794e-01, -4.83281138e-02, 1.56179601e+00]], ..., [[ 2.14014411e-01, 0.00000000e+00, 0.00000000e+00], [-5.36481580e-01, 2.04876587e+00, 0.00000000e+00], [-2.37240883e-02, -1.15618572e-01, 2.56096869e-01]], [[ 8.57876950e-01, 0.00000000e+00, 0.00000000e+00], [ 8.80571205e-04, 1.12448908e+00, 0.00000000e+00], [ 2.98983373e-01, 3.01371030e-01, 1.27409569e+00]], [[ 1.56441016e+00, 0.00000000e+00, 0.00000000e+00], [ 1.52603411e+00, 8.88917038e-01, 0.00000000e+00], [ 3.23267111e-01, -9.39733478e-02, 7.72182687e-01]]]]) - z_scale_alpha_Australia(chain, draw)float640.2135 0.558 ... 0.1505 0.283
array([[0.21349685, 0.55798781, 0.89276486, 0.0929538 , 0.16229627, 0.12217945, 0.19102479, 0.12181753, 0.26815972, 0.12455234, 0.14814762, 0.13467901, 0.31316463, 0.38224019, 0.09268671, 0.28875773, 0.17290106, 0.08494782, 0.16675921, 0.18716972, 0.0906609 , 0.39631931, 0.13631636, 0.12975208, 0.18477318, 0.13932279, 0.10940528, 1.07689583, 0.11714862, 0.35288666, 0.46205462, 0.17280418, 0.15916952, 0.08627822, 0.39790241, 0.16470455, 0.34617587, 0.29920837, 0.45214034, 0.25277276, 0.31529658, 0.0796127 , 0.12027817, 0.2970992 , 0.18230463, 0.30367395, 0.10165875, 0.25707323, 0.34925061, 0.13220736, 0.13025155, 0.17074058, 0.09000912, 0.32023614, 0.0934971 , 0.15784082, 0.25430052, 0.32815974, 0.16281204, 0.16189498, 0.0796007 , 0.20408872, 0.15960882, 0.19821208, 0.10822714, 0.31919547, 0.4725085 , 0.1297642 , 0.13783116, 0.16311501, 0.07950005, 0.16803838, 0.22591461, 0.1850961 , 0.41528212, 0.23679564, 0.27401552, 0.13444167, 0.22487896, 0.10652259, 0.12493599, 0.21251467, 0.15683186, 0.11963954, 0.24229907, 0.18876937, 0.19871174, 0.1161395 , 0.16222612, 0.17238744, 0.25550942, 0.23321398, 0.11471119, 0.15866093, 0.18912152, 0.268599 , 0.20141053, 0.23590482, 0.11265815, 0.16831428, ... 0.32098438, 0.33982917, 0.15818539, 0.1181535 , 0.13422332, 0.10383103, 0.15148347, 0.27367008, 0.37663366, 0.65801811, 0.22779821, 0.12107004, 0.14691564, 0.1583824 , 0.13815032, 0.29145257, 0.1324747 , 0.71650209, 0.08977658, 0.25536085, 0.23384534, 0.24988145, 0.11220109, 0.51525044, 0.16830479, 0.1459533 , 0.25387926, 0.61865403, 2.39769012, 0.14074619, 0.38246219, 0.19007745, 0.10237864, 0.08020918, 0.2269304 , 0.15385598, 0.1881944 , 0.12722658, 0.68554785, 0.29884224, 0.26259276, 0.29588416, 0.08275737, 0.4399304 , 0.21779385, 0.66440144, 0.08841264, 0.21978646, 0.18137905, 0.11109064, 0.53287206, 0.07603271, 0.24072975, 0.35999341, 0.23792117, 0.22200911, 0.12065137, 0.13772612, 0.21153311, 0.38971295, 0.07261891, 0.2049971 , 0.25216086, 0.32072983, 0.29977723, 0.46945961, 0.22070712, 0.49405479, 0.21245975, 0.8270608 , 0.09507272, 0.13288111, 0.16609586, 0.1783188 , 0.20623537, 0.23260991, 0.26462791, 0.71120718, 0.12302289, 0.19987558, 0.12040077, 0.15655036, 0.1692955 , 0.11366119, 0.07819533, 0.09425215, 0.16759718, 0.30319109, 0.2926074 , 0.09344479, 0.16946023, 0.24534464, 0.17671518, 0.26588803, 0.26731759, 0.06168833, 0.11848901, 0.12463534, 0.15053058, 0.28295018]]) - noise_chol_United States(chain, draw, noise_chol_United States_dim_0)float641.025 0.03648 ... 0.06989 0.1936
array([[[ 1.02485906, 0.03647595, 2.01736158, -0.0450058 , 0.23603656, 0.52662935], [ 0.12223676, -0.01651957, 0.3492084 , 0.11932015, 0.23555674, 0.77615083], [ 1.81531772, -0.2305273 , 1.21500425, 0.09710938, 1.36396402, 2.46617604], ..., [ 0.63896902, -0.00430105, 0.23370739, -1.19358163, 0.08834221, 2.84775158], [ 0.93403749, -0.05972324, 1.17305335, -0.01338253, 0.01071785, 0.23292336], [ 0.91164171, 0.22110833, 0.5781378 , -0.05971827, 0.06988621, 0.19357679]]]) - lag_coefs_South Africa(chain, draw, equations, lags, cross_vars)float64-0.2365 -0.1754 ... 0.05666 0.05853
array([[[[[-0.23653396, -0.17535764, -0.19259883], [-0.23701861, -0.10574879, -0.19480722]], [[-0.19592983, -0.12407823, -0.17365097], [-0.15210075, -0.07545554, -0.21088623]], [[-0.25404572, -0.21689502, -0.16918229], [-0.12288923, -0.14146429, -0.19812718]]], [[[-0.25672551, -0.22618817, -0.18411549], [-0.24591878, -0.27018902, -0.27187515]], [[-0.22940812, -0.1967032 , -0.19118466], [-0.23785843, -0.18149571, -0.20791851]], [[-0.18135597, -0.17611271, -0.28292983], [-0.20437799, -0.1659736 , -0.24030227]]], ... [[[ 0.00319377, 0.03971881, 0.04003112], [ 0.07366218, -0.03378931, 0.14260651]], [[-0.03996608, -0.00224961, -0.03843742], [ 0.01421821, -0.01586986, -0.05962431]], [[ 0.00375386, 0.1397171 , 0.09193438], [-0.06978229, -0.10550759, -0.09893312]]], [[[ 0.03846222, 0.06165028, 0.0582391 ], [ 0.04459164, 0.05316985, 0.05482073]], [[ 0.0377817 , 0.06268424, 0.08046469], [ 0.04958416, 0.05165488, 0.06246147]], [[ 0.03785436, 0.05958385, 0.05252461], [ 0.05541533, 0.05665948, 0.05853228]]]]]) - z_scale_beta_Canada(chain, draw)float640.206 0.1572 0.062 ... 0.2 0.1907
array([[0.20597835, 0.15715561, 0.062 , 0.21010669, 0.28258379, 0.11517814, 0.30118359, 0.48763144, 0.37490842, 0.08627406, 0.08519334, 0.11332028, 0.27016606, 0.1155351 , 0.12088698, 0.43648722, 0.24707822, 0.12911647, 0.18902934, 0.15183204, 0.32300672, 0.2541712 , 0.15232288, 0.20628871, 0.32135944, 0.21188144, 0.10275504, 0.20189652, 0.11160093, 0.16513119, 0.27321642, 0.17276446, 0.590317 , 0.21623107, 0.16032405, 0.1484018 , 0.23818659, 0.15288073, 0.16149012, 0.12235722, 0.09850244, 0.12354564, 0.13699863, 0.35075085, 0.67227034, 0.31109322, 0.06269607, 0.26313699, 0.44222567, 0.31281536, 0.64379277, 0.09593582, 0.16328929, 0.6698961 , 0.12044611, 0.26743635, 0.22373021, 0.67184493, 0.07137944, 0.48541162, 0.31137895, 0.13695403, 0.19946058, 0.21471459, 0.2345619 , 0.19579824, 0.12624404, 0.18195879, 0.2321122 , 0.18688321, 0.17116901, 0.42275027, 0.22626851, 0.08654082, 0.21525921, 0.06693556, 0.20763649, 0.18333726, 0.5773455 , 0.08616333, 0.37190231, 0.20615889, 0.52651009, 0.19026844, 0.08872785, 0.12709443, 0.13739737, 0.29774602, 0.19083827, 0.08953584, 0.24023509, 0.18150133, 0.1622077 , 0.10278121, 0.28490485, 0.79936355, 0.10746417, 0.72094253, 0.13005678, 0.1692404 , ... 0.12591114, 0.09727694, 0.12564752, 0.13456127, 0.14667568, 0.37183583, 0.11748543, 0.15256233, 0.45761602, 0.19443811, 0.42583561, 0.50855639, 0.53799702, 0.18945073, 0.94775416, 0.22755719, 0.15736608, 0.19850553, 0.20375117, 0.29020824, 0.24507071, 0.13249971, 0.68559728, 0.12291209, 0.14090839, 0.0674714 , 0.62049209, 0.42207586, 0.1717535 , 0.13568536, 0.09318577, 0.08745766, 0.18766408, 0.25468481, 0.1937421 , 0.1074329 , 0.39462298, 0.17551673, 0.14620555, 0.09398065, 0.21262622, 0.32647654, 0.13420811, 0.18585891, 0.49753251, 0.15809565, 0.05227775, 0.1335445 , 0.13660069, 0.27004503, 0.15732034, 0.36840803, 0.15603986, 0.34394718, 0.08431872, 0.27838542, 0.71138281, 0.5397544 , 0.23548402, 0.22775199, 0.14072805, 0.85468932, 0.08632006, 0.13319566, 0.16904253, 0.16330327, 0.11303598, 0.14150272, 0.19259192, 0.39271348, 0.20441471, 0.20754252, 0.21929124, 0.8280654 , 0.17102702, 0.10245022, 0.16402004, 0.17161117, 0.33091494, 0.16519594, 0.60766513, 0.06786667, 0.16778956, 0.39310014, 0.21843639, 0.10776247, 0.09070453, 0.65914102, 0.11487672, 0.19322548, 0.12971926, 0.11234246, 0.75772232, 0.24139028, 0.08129723, 0.09606349, 0.24675547, 0.1075058 , 0.20003389, 0.19066278]]) - noise_chol_United Kingdom_corr(chain, draw, noise_chol_United Kingdom_corr_dim_0, noise_chol_United Kingdom_corr_dim_1)float641.0 0.3265 -0.2935 ... 0.2028 1.0
array([[[[ 1. , 0.3264905 , -0.29353167], [ 0.3264905 , 1. , -0.51373321], [-0.29353167, -0.51373321, 1. ]], [[ 1. , 0.24422305, -0.13729554], [ 0.24422305, 1. , 0.58019564], [-0.13729554, 0.58019564, 1. ]], [[ 1. , -0.45969038, -0.27570427], [-0.45969038, 1. , 0.02420394], [-0.27570427, 0.02420394, 1. ]], ..., [[ 1. , 0.02928775, 0.02558654], [ 0.02928775, 1. , -0.02784166], [ 0.02558654, -0.02784166, 1. ]], [[ 1. , -0.42848156, -0.02326362], [-0.42848156, 1. , -0.03966232], [-0.02326362, -0.03966232, 1. ]], [[ 1. , -0.31619581, -0.27625219], [-0.31619581, 1. , 0.20284884], [-0.27625219, 0.20284884, 1. ]]]]) - betaX_United Kingdom(chain, draw, betaX_United Kingdom_dim_0, betaX_United Kingdom_dim_1)float64-0.03942 -0.0173 ... -0.01429
array([[[[-3.94200727e-02, -1.72960150e-02, -1.37328921e-02], [-3.79317591e-02, -4.53373613e-02, -2.01338350e-02], [-2.39758091e-02, -3.66182392e-02, -1.42564510e-02], ..., [-2.57352036e-02, -1.30193541e-02, -1.42700677e-02], [-1.16573145e-02, -1.03436958e-02, -2.65486491e-03], [ 4.80652990e-02, 1.31812110e-02, 4.02105108e-02]], [[-4.04344934e-02, -3.59703964e-02, -3.45494651e-02], [-6.36351531e-02, -5.01866228e-02, -5.03541000e-02], [-2.18118174e-02, -2.24104271e-02, -1.87514300e-02], ..., [-2.07125734e-02, -1.93613847e-02, -1.90652796e-02], [-1.71725392e-02, -1.41379985e-02, -1.35063678e-02], [ 6.01759801e-02, 4.93910828e-02, 5.36831375e-02]], [[ 2.86682966e-02, 3.20268398e-02, 2.95692942e-02], [ 4.34325441e-02, 4.73849063e-02, 4.35284843e-02], [ 1.99255126e-02, 1.57083928e-02, 1.93408830e-02], ..., ... ..., [-2.69771117e-03, -3.64429604e-02, -3.27062402e-02], [-7.03103807e-04, -9.22475180e-03, -2.57338713e-02], [ 1.53851564e-01, 1.53041658e-01, -7.31188951e-03]], [[ 5.40793655e-03, -2.38576597e-04, -8.11218187e-06], [ 1.03659910e-02, 7.67184162e-03, -1.98821601e-03], [-7.38141253e-04, -8.13952392e-03, -1.55442008e-03], ..., [ 1.52258812e-03, -2.18115754e-03, -8.41467136e-04], [ 2.58704937e-03, 1.07263009e-03, -5.18633926e-05], [-1.26991250e-02, -1.22900297e-02, 7.60138700e-04]], [[ 1.12116387e-02, 1.17415215e-02, 1.12632551e-02], [ 1.62448204e-02, 1.71448738e-02, 1.54098057e-02], [ 8.47609120e-03, 8.30410186e-03, 7.59920840e-03], ..., [ 6.37787667e-03, 6.54341701e-03, 6.11904745e-03], [ 4.55178811e-03, 4.75105435e-03, 4.43108902e-03], [-1.37622991e-02, -1.54251835e-02, -1.42899188e-02]]]]) - alpha_United Kingdom(chain, draw, equations)float64-0.105 -0.1099 ... -0.2986 -0.2771
array([[[-0.10504847, -0.10987787, -0.11568448], [ 0.05049984, 0.06462595, 0.07323632], [ 0.20993419, 0.19883819, 0.19144551], ..., [ 0.04368448, 0.12319567, 0.05689683], [ 0.05776521, 0.01628855, 0.02436099], [-0.30739603, -0.2986272 , -0.27708257]]]) - betaX_Ireland(chain, draw, betaX_Ireland_dim_0, betaX_Ireland_dim_1)float64-0.05636 -0.07013 ... 0.03163
array([[[[-5.63613585e-02, -7.01316530e-02, -6.07409557e-02], [-7.25515457e-02, -8.76718177e-02, -7.97842750e-02], [-3.35471778e-02, -4.36230850e-02, -3.12771740e-02], ..., [-2.84617300e-02, -2.71654585e-02, -2.82291463e-02], [-1.30542441e-01, -1.43708806e-01, -1.49224861e-01], [-6.41395282e-02, -1.16062421e-01, -5.64768311e-02]], [[-7.58390921e-02, -7.40291967e-02, -7.16683955e-02], [-9.79737904e-02, -9.47430625e-02, -9.29247926e-02], [-4.43584884e-02, -4.15387463e-02, -3.80020949e-02], ..., [-2.78143551e-02, -2.78437093e-02, -2.50561363e-02], [-1.78090695e-01, -1.74201825e-01, -1.75912371e-01], [-1.12888189e-01, -9.96055527e-02, -9.29263820e-02]], [[ 5.83024323e-02, 5.87612745e-02, 5.83082381e-02], [ 7.41351914e-02, 7.57836883e-02, 7.48976492e-02], [ 3.80233060e-02, 3.32594997e-02, 3.44645598e-02], ..., ... ..., [ 6.82319001e-03, -6.97506458e-03, -1.45017860e-02], [-3.27922716e-01, -1.86692288e-01, -1.46732649e-01], [-2.23884865e-02, -1.32983562e-01, -9.27375381e-02]], [[ 2.90661497e-02, 1.13429741e-02, 1.04601173e-02], [ 3.25599336e-02, 1.78357114e-02, 1.61005972e-02], [ 1.33529018e-02, 3.72229383e-03, 1.03354929e-02], ..., [ 1.74939468e-02, -1.17313520e-03, 1.33576926e-04], [ 5.17234887e-02, 3.52299281e-02, 1.78026406e-02], [ 6.07970992e-03, 1.66774566e-02, 4.01917905e-02]], [[ 2.14802003e-02, 2.05715801e-02, 2.06112919e-02], [ 2.75169822e-02, 2.60570226e-02, 2.61178648e-02], [ 1.24896653e-02, 1.34676256e-02, 1.41815825e-02], ..., [ 7.84468179e-03, 8.97218835e-03, 1.01794491e-02], [ 4.97487964e-02, 4.26521968e-02, 4.17659545e-02], [ 3.29057445e-02, 3.49353835e-02, 3.16323974e-02]]]]) - z_scale_alpha_South Africa(chain, draw)float640.1016 0.1248 ... 0.1378 0.07456
array([[0.10158372, 0.12483101, 0.51288006, 0.15688106, 0.36685966, 0.1977919 , 0.15267253, 0.19591569, 0.59390305, 0.85488895, 0.10587033, 0.21915306, 0.1623386 , 0.5986583 , 0.16613045, 0.67263342, 0.11661068, 0.32518286, 1.5361486 , 1.45709589, 0.1294471 , 0.47819553, 0.15264436, 0.44517857, 0.10923452, 0.16646303, 0.10647573, 0.0892792 , 0.14177543, 0.27333858, 0.13350324, 0.08810627, 0.26110173, 0.0919285 , 0.09816649, 0.26209278, 0.0764066 , 0.04830488, 0.40724656, 0.12750582, 0.31631358, 0.14794213, 0.37235809, 0.25241872, 0.12788007, 0.13404573, 0.17880159, 0.36286645, 0.51347296, 0.15289694, 0.21073588, 0.23397541, 0.43315221, 0.10431045, 0.5654643 , 0.41999103, 0.40271515, 0.15731881, 0.14442823, 0.12233247, 0.54836549, 0.59848302, 0.2114371 , 0.26221595, 0.47246925, 0.3137886 , 0.10494884, 0.12912805, 0.18391246, 0.12884373, 0.15274523, 0.3725999 , 0.12177836, 0.24943004, 0.17295438, 0.1309844 , 1.8084263 , 0.186108 , 0.15504212, 0.27137544, 0.42143829, 0.19261572, 0.39520666, 0.22817145, 0.11095781, 0.15273024, 0.50592954, 0.09639036, 0.06401957, 0.21317518, 0.07973296, 0.17947608, 0.09611679, 0.29737776, 0.06023055, 0.14621088, 0.16808568, 0.15571004, 0.12821163, 0.40133051, ... 0.08203337, 0.45353632, 0.12209597, 0.16200809, 0.31780427, 0.22325601, 0.11873745, 0.08931568, 0.14336465, 0.23646683, 0.10727013, 0.09932834, 0.18313903, 0.10980764, 0.21582747, 0.10017599, 0.09735297, 0.23616385, 0.14951644, 0.06934906, 0.21301649, 0.11839936, 0.1319655 , 0.10892052, 0.22106444, 0.47243188, 0.34067691, 0.11456418, 0.08852128, 0.15495958, 0.22919555, 0.18288511, 0.34971504, 0.25516174, 0.1457496 , 0.39572965, 0.6039811 , 0.12686073, 0.17295965, 0.15575192, 0.0565876 , 0.10520198, 0.21569628, 0.25940171, 0.63693879, 0.18781137, 0.09305883, 0.25714287, 0.15878983, 0.44034101, 0.11823393, 0.13136161, 0.20973821, 1.42332463, 0.21302649, 0.2226954 , 0.27316585, 0.14044902, 0.53966122, 0.1195044 , 0.150667 , 0.23497026, 0.11131538, 0.20400561, 0.11954057, 0.18559815, 0.30009964, 0.17376405, 0.16068921, 0.09253434, 0.60062737, 0.2703372 , 0.07692366, 0.09411692, 0.26417048, 0.09748224, 0.11672049, 0.13086781, 0.20560368, 0.20239755, 0.08500308, 0.22931061, 0.11815733, 0.32180559, 0.2216965 , 0.72182278, 0.12920471, 0.34160552, 0.48694934, 0.31786736, 0.18793372, 0.15005929, 0.20836772, 0.42221041, 0.12569971, 0.16010514, 0.13736873, 0.30613186, 0.13783877, 0.07455761]]) - omega_South Africa(chain, draw, omega_South Africa_dim_0, omega_South Africa_dim_1)float641.784 0.0 0.0 ... -0.05803 0.6967
array([[[[ 1.78358959, 0. , 0. ], [ 0.18121283, 1.15854938, 0. ], [-0.02083124, 0.02060528, 0.10876988]], [[ 1.99766962, 0. , 0. ], [-0.4775523 , 0.93489946, 0. ], [-0.66727127, -0.56894271, 0.97454354]], [[ 0.6258802 , 0. , 0. ], [-0.05006584, 0.56308675, 0. ], [-0.03356472, -0.11918844, 1.28177522]], ..., [[ 0.59207105, 0. , 0. ], [-0.15405435, 1.15191665, 0. ], [ 0.42015146, -0.13112777, 1.3176359 ]], [[ 0.94560191, 0. , 0. ], [-0.19599059, 0.87824301, 0. ], [-0.01612961, 0.1012689 , 0.46264248]], [[ 1.50154014, 0. , 0. ], [ 1.74863285, 0.3581054 , 0. ], [ 0.3241124 , -0.05803056, 0.6967033 ]]]]) - z_scale_beta_United Kingdom(chain, draw)float640.3233 0.1573 ... 0.1529 0.2527
array([[0.32329421, 0.1573022 , 0.18395888, 0.31115335, 0.08793985, 0.64458887, 0.08426981, 0.1739706 , 0.25291676, 0.40157056, 0.1272336 , 0.2048703 , 0.82405807, 1.0602077 , 0.30134718, 0.27591026, 0.11990954, 0.22748406, 0.1296425 , 0.03586132, 0.18854633, 0.13555937, 0.15987621, 0.20211453, 0.96087343, 0.13200587, 0.35302074, 0.16344653, 0.27828552, 0.0784578 , 0.20021474, 0.1040394 , 0.26592825, 0.15760564, 0.25392231, 0.4902283 , 0.21793767, 0.48491566, 0.18729284, 0.30805642, 0.32554183, 0.1028073 , 0.1974544 , 0.36962696, 0.12917224, 0.11429995, 0.23014723, 0.12717217, 0.17021359, 0.42686837, 0.51873028, 0.14007854, 0.1921737 , 0.138695 , 0.16323093, 0.37369897, 0.28539739, 0.26873964, 0.16324976, 0.46518 , 0.15825429, 0.15334833, 0.11715296, 0.56726684, 0.3316949 , 0.22294716, 0.08289984, 0.20016843, 0.08728106, 0.36024453, 0.4137913 , 0.21460476, 0.08989952, 0.62251973, 0.09447217, 1.09391803, 0.18945414, 0.28841037, 0.13869962, 0.16524337, 0.10166989, 0.05820755, 0.37717556, 0.16057303, 0.26310522, 0.21005783, 0.34844353, 0.15838789, 0.15406413, 0.29755489, 0.32437052, 0.41087799, 0.1377247 , 0.08347871, 0.50160563, 0.113767 , 0.13644536, 0.09342668, 0.27791361, 0.17950133, ... 0.11099167, 0.23969892, 0.12262426, 0.1755397 , 0.24322786, 0.11843434, 0.38237235, 0.21831319, 0.05396117, 0.23099262, 0.20061547, 0.19406781, 0.17941891, 0.08188348, 0.1880668 , 0.51481259, 0.20328566, 0.70005929, 0.15409202, 0.3034517 , 0.37492744, 0.12686545, 0.12791117, 0.67418773, 0.32532571, 0.07088648, 0.32204798, 0.16968474, 0.17607128, 0.19494038, 0.11102617, 0.18283606, 0.20243548, 0.35749114, 0.16571656, 0.14121779, 0.34345642, 0.1701505 , 0.07026001, 0.44226981, 0.17050301, 0.22328302, 0.22484323, 0.09580508, 0.33943649, 0.32584451, 0.14876404, 0.56129836, 0.50985411, 0.20187562, 0.27118215, 0.14051975, 0.15176628, 0.51159659, 0.19814433, 0.32667369, 0.05378582, 0.07843321, 0.11752381, 0.10458065, 0.11609248, 0.06791563, 0.29600561, 0.45469787, 0.11424575, 0.18505702, 0.08807271, 0.19533745, 0.12638563, 0.10660988, 0.09380297, 0.14078204, 0.05021521, 0.11993517, 0.30265546, 0.24492029, 0.23754694, 0.12969476, 0.37838559, 0.26103451, 0.57541725, 0.11774033, 0.90168756, 0.12440032, 0.12350289, 0.18303855, 0.49137428, 0.17835225, 0.21784502, 0.14457128, 0.08277858, 0.25047164, 0.14644423, 0.11178635, 0.08588925, 0.18190685, 0.75139059, 0.51204172, 0.15293603, 0.25272013]]) - noise_chol_Canada(chain, draw, noise_chol_Canada_dim_0)float641.104 -0.06141 ... 0.3915 0.9881
array([[[ 1.10440523e+00, -6.14109927e-02, 8.22749881e-01, 1.02356729e-01, -3.51431230e-02, 1.75236206e+00], [ 1.58393068e-01, -2.09363094e-01, 1.81394898e+00, -1.47916702e-02, 1.84719694e-03, 1.02419234e-01], [ 1.08584398e-01, -3.50908298e-01, 2.43234781e+00, -2.89296391e-02, -1.37607379e-01, 1.16846656e+00], ..., [ 6.75563536e-01, -2.71357075e-01, 3.83127860e+00, 5.39568575e-01, 7.32348991e-02, 1.76801481e+00], [ 3.21172324e+00, 1.80240754e-02, 1.19982287e+00, 8.23736425e-02, 2.21532656e-01, 1.48254113e+00], [ 9.42435758e-01, -2.09670521e-01, 5.32329692e-01, -3.01572098e-01, 3.91459628e-01, 9.88126253e-01]]]) - beta_hat_scale(chain, draw)float640.445 0.253 ... 0.2568 0.04878
array([[0.44503705, 0.25302872, 0.09734064, 0.08140516, 0.09403591, 0.53281248, 0.28569491, 0.06927693, 0.23716861, 0.48898782, 0.12018069, 0.32561429, 0.11594634, 0.11938186, 0.18987112, 0.05024414, 0.31705729, 0.36470701, 0.23925633, 0.13041001, 0.82218282, 0.08605663, 0.43065183, 0.43511532, 0.42329363, 0.23868226, 0.14223661, 0.18942365, 0.11064443, 0.17979744, 0.08929333, 0.08621157, 0.22297356, 0.32616151, 0.42752162, 0.33973567, 0.26361747, 0.33651065, 0.30514592, 0.6040292 , 0.30559007, 0.2764355 , 0.1030149 , 0.2478419 , 0.1149303 , 0.17284634, 0.12390858, 0.11802487, 0.12523576, 0.08518932, 0.24107197, 0.20765158, 0.17661285, 0.27904944, 0.23839197, 0.48257666, 0.09528768, 0.11454373, 0.29407864, 0.26232946, 0.75598757, 0.16745614, 0.11830287, 0.10899471, 0.27860523, 0.20970053, 0.19249533, 0.13234794, 0.10192466, 0.05061725, 0.09358496, 0.16118725, 0.09068751, 0.16353462, 0.14521383, 0.1080347 , 0.20866713, 0.24090732, 0.43486484, 0.18934286, 0.23082179, 0.24133749, 0.1685625 , 0.06079055, 0.23491592, 0.21468027, 0.12939244, 0.32378068, 0.21257374, 0.17706071, 0.14395569, 0.3012523 , 0.08673807, 0.20119311, 0.24151278, 1.02288321, 0.21913009, 0.11876808, 0.13561561, 0.22144594, ... 0.38661143, 0.49959209, 0.33899083, 0.28879166, 0.16437471, 0.25944415, 0.26070646, 0.14659932, 0.2987469 , 0.16546793, 0.54347232, 0.15610741, 0.32850537, 0.14202903, 0.46403254, 0.20134906, 0.14092558, 0.31915747, 0.1083041 , 0.06595824, 0.12607071, 0.32347699, 0.18128918, 0.20217098, 0.15515703, 0.07901812, 0.0957816 , 0.69466819, 0.17602688, 0.14354201, 0.15914825, 0.27937793, 0.35717692, 0.25445324, 0.06645117, 0.52638452, 0.28862398, 0.182403 , 0.10244508, 0.28279983, 0.20290727, 0.67652985, 0.19440047, 0.07835929, 0.25447417, 0.09081237, 0.13050397, 0.12495608, 0.89505844, 0.2964415 , 0.12699845, 0.31185433, 0.21496858, 0.13297115, 0.0998401 , 0.17609794, 0.24341781, 0.49670671, 0.38368282, 0.11393543, 0.08738413, 0.14064452, 0.14818658, 0.21655171, 0.26690996, 0.28877758, 0.12789248, 0.17698881, 0.06163298, 0.21681181, 0.10022167, 0.6127 , 0.18760715, 0.16731792, 0.14341602, 0.1900311 , 0.12648602, 0.0819759 , 0.18701306, 0.53192278, 0.08351364, 0.17312503, 0.19946883, 0.21985174, 0.07079137, 0.28623224, 0.15362624, 0.18702488, 0.61049313, 0.36899625, 0.10071906, 0.07739268, 0.24766829, 0.11793443, 0.13010391, 0.17038084, 0.07135453, 1.03649588, 0.25679807, 0.04878009]]) - omega_global_corr(chain, draw, omega_global_corr_dim_0, omega_global_corr_dim_1)float641.0 0.2969 -0.2592 ... 0.4423 1.0
array([[[[ 1. , 0.29692789, -0.25923662], [ 0.29692789, 1. , 0.14574549], [-0.25923662, 0.14574549, 1. ]], [[ 1. , -0.50390112, -0.88406178], [-0.50390112, 1. , 0.05741437], [-0.88406178, 0.05741437, 1. ]], [[ 1. , 0.34143595, 0.08368607], [ 0.34143595, 1. , -0.65070387], [ 0.08368607, -0.65070387, 1. ]], ..., [[ 1. , -0.27433149, 0.10919589], [-0.27433149, 1. , -0.6416615 ], [ 0.10919589, -0.6416615 , 1. ]], [[ 1. , -0.71381744, -0.6416458 ], [-0.71381744, 1. , 0.01697827], [-0.6416458 , 0.01697827, 1. ]], [[ 1. , 0.99169239, 0.45199652], [ 0.99169239, 1. , 0.44227972], [ 0.45199652, 0.44227972, 1. ]]]]) - z_scale_beta_Chile(chain, draw)float640.3099 0.319 ... 0.1535 0.249
array([[0.30990536, 0.31898127, 0.46805575, 1.46775288, 0.31189055, 0.29670148, 0.12160982, 0.21345929, 0.28993789, 0.07594419, 0.17217328, 0.14362066, 0.42858227, 0.18093675, 0.31762323, 0.08629456, 0.08945899, 0.12837699, 0.30115755, 0.24399574, 0.17697334, 0.0704102 , 0.19864746, 0.37872674, 0.18952204, 0.17068355, 0.06265502, 0.35056743, 0.16200572, 0.16669569, 0.12729406, 0.17905708, 0.12424471, 0.19146932, 0.32778996, 0.22980471, 0.2034019 , 0.14299723, 0.07957804, 0.12835942, 0.13764474, 0.11565458, 0.26232806, 0.14814521, 0.06457627, 0.12113411, 0.142652 , 0.14084364, 0.21478267, 0.32992681, 0.2477339 , 0.21158255, 0.5724395 , 0.25254504, 0.4214072 , 0.1466429 , 0.43787646, 0.07259178, 0.56152386, 0.27947568, 1.55597931, 0.12504306, 0.11720669, 0.28814203, 0.23095757, 0.59749398, 0.19761514, 0.10450226, 0.25204799, 0.23369357, 0.59321525, 0.11224511, 0.14313231, 0.1937793 , 0.72057527, 0.12585264, 0.09828015, 0.1590817 , 0.33499431, 0.15217841, 0.92295021, 0.51095889, 0.27241345, 0.25733832, 0.06198806, 0.1485592 , 0.20171744, 0.36242288, 0.18339561, 0.15778783, 0.40656022, 0.13442682, 0.35546348, 0.53646324, 0.22447086, 0.22082826, 0.35280804, 0.28602613, 0.25661764, 0.18910331, ... 0.17809947, 0.36406137, 0.10420537, 0.08386398, 0.13171774, 0.1779471 , 0.25193476, 0.07719311, 0.25698288, 0.07146643, 0.19145748, 0.07357926, 0.18635246, 0.30343246, 0.152774 , 0.18638894, 0.46796965, 0.50509979, 0.10939796, 0.35368413, 0.10356129, 0.18410041, 0.16715199, 0.19867206, 0.34242053, 0.15595651, 0.34579875, 0.13957914, 0.13643082, 0.32962603, 0.44742806, 0.12325874, 0.24707 , 0.20842144, 0.15227183, 0.18973992, 0.08675561, 0.40103028, 0.15597983, 0.0843263 , 0.39750353, 0.11267465, 0.13539262, 0.60783435, 0.13182377, 0.40304187, 0.09901869, 0.21478436, 1.25552176, 0.15233609, 0.20822934, 0.26070483, 0.18185246, 0.14669762, 0.08624216, 0.07059232, 0.28667757, 0.1052545 , 0.27464558, 0.95117541, 0.48424707, 0.15908758, 0.46374762, 0.19377645, 0.07026614, 0.47954379, 0.27252315, 0.09018434, 0.09685043, 0.74444211, 0.14658351, 0.20068838, 0.17096532, 0.1126428 , 0.63954626, 0.53113693, 0.38469789, 0.221623 , 0.18916632, 0.06957461, 0.09160466, 0.05415353, 0.20477535, 0.19636591, 0.21163338, 0.04727546, 0.42889752, 1.94669786, 0.47964026, 0.26143897, 0.08786324, 0.12047803, 0.15553462, 0.17466272, 0.65884565, 0.14780694, 0.14465865, 0.2293884 , 0.15349672, 0.24900105]]) - betaX_Australia(chain, draw, betaX_Australia_dim_0, betaX_Australia_dim_1)float64-0.02716 -0.04112 ... 7.089e-05
array([[[[-2.71631337e-02, -4.11209056e-02, -2.06149307e-02], [-2.37026713e-02, -3.87175835e-02, -1.67115989e-02], [-2.68779372e-02, -5.04349934e-02, -1.89863050e-02], ..., [-1.76051608e-02, -3.32686837e-02, -1.21494546e-02], [-1.95325150e-02, -2.38321889e-02, -1.56259155e-02], [-6.34610944e-03, 4.72511321e-03, -4.29248487e-03]], [[-4.57268446e-02, -4.48644831e-02, -4.31727789e-02], [-4.27550145e-02, -4.17061760e-02, -4.03159647e-02], [-4.99334261e-02, -4.88492687e-02, -4.69735667e-02], ..., [-3.42849440e-02, -3.24920082e-02, -3.16742955e-02], [-2.80948391e-02, -2.87194875e-02, -2.71145462e-02], [-1.75129213e-03, -1.15958062e-03, -2.66442705e-04]], [[ 3.66348357e-02, 3.60079149e-02, 3.46216391e-02], [ 3.45002324e-02, 3.39491167e-02, 3.26298453e-02], [ 3.98914082e-02, 3.92686230e-02, 3.78749625e-02], ..., ... ..., [-3.93991174e-02, -3.25176960e-02, -1.39060936e-02], [-1.84757090e-02, -3.13568524e-02, -1.07089047e-02], [-1.91136119e-03, -1.30694417e-03, 1.82679994e-03]], [[ 5.41213322e-03, 2.23393602e-03, 2.23527329e-03], [ 5.14878836e-03, 2.14668584e-03, 2.41120458e-03], [ 5.82424046e-03, 1.83661445e-03, 3.07894010e-03], ..., [ 4.40988044e-03, 1.03347356e-03, 2.96765783e-03], [ 2.68659013e-03, 2.06077366e-03, -9.73468885e-05], [-2.74763707e-04, 1.61254037e-03, -5.17438623e-04]], [[ 1.33079716e-02, 1.18015094e-02, 1.28730283e-02], [ 1.23619639e-02, 1.10674498e-02, 1.21157449e-02], [ 1.44231024e-02, 1.34265145e-02, 1.42602060e-02], ..., [ 9.88310291e-03, 9.24608458e-03, 9.57381238e-03], [ 8.17092213e-03, 6.82380882e-03, 7.99997718e-03], [-3.12477776e-04, -2.25905479e-04, 7.08883444e-05]]]]) - noise_chol_Canada_corr(chain, draw, noise_chol_Canada_corr_dim_0, noise_chol_Canada_corr_dim_1)float641.0 -0.07443 0.0583 ... 0.4297 1.0
array([[[[ 1. , -0.07443409, 0.05829965], [-0.07443409, 1. , -0.02430053], [ 0.05829965, -0.02430053, 1. ]], [[ 1. , -0.11465723, -0.14291699], [-0.11465723, 1. , 0.03411636], [-0.14291699, 0.03411636, 1. ]], [[ 1. , -0.14278903, -0.02458128], [-0.14278903, 1. , -0.11221584], [-0.02458128, -0.11221584, 1. ]], ..., [[ 1. , -0.07064978, 0.29166406], [-0.07064978, 1. , 0.01888224], [ 0.29166406, 0.01888224, 1. ]], [[ 1. , 0.01502059, 0.05486956], [ 0.01502059, 1. , 0.14837172], [ 0.05486956, 0.14837172, 1. ]], [[ 1. , -0.36647139, -0.27296569], [-0.36647139, 1. , 0.42971006], [-0.27296569, 0.42971006, 1. ]]]]) - alpha_hat_location(chain, draw)float64-0.1142 0.06737 ... 0.06274 -0.2666
array([[-1.14215881e-01, 6.73702220e-02, 1.91390197e-01, -1.16041416e-02, -1.24930644e-02, 1.73151022e-01, 1.62079891e-02, -9.84983370e-02, -1.83338972e-01, 2.73037779e-02, 8.03824509e-02, -7.74581290e-02, -2.33151633e-01, 2.11686594e-01, -1.26425955e-01, 1.92428012e-01, 3.05683152e-02, -5.16687825e-02, 3.15888205e-01, -1.57532143e-01, 1.22378583e-01, -1.08112679e-01, 5.23449912e-02, 4.31351949e-02, -1.42511344e-02, 5.19508807e-02, 1.92124314e-02, 1.28942591e-02, -7.49653882e-03, 1.90296410e-01, -7.17142579e-02, -6.71235689e-02, -7.51747078e-02, 1.11586049e-01, 7.90522444e-02, -1.18764713e-01, 1.19181240e-01, 9.75056361e-02, -5.54103362e-02, -1.33069569e-01, 1.36178519e-01, 4.87806046e-02, 3.33680523e-02, -5.04320820e-02, -1.11918471e-01, 1.56954740e-02, -6.11651521e-02, -3.15021225e-02, 1.10610591e-01, 1.81375319e-03, 1.09281481e-01, -4.78632564e-02, 1.81503756e-01, 1.02128533e-01, -1.08703136e-01, -1.19687776e-01, 2.21152009e-01, 2.57520351e-02, 2.38293206e-01, 1.39071621e-01, ... 8.16216513e-02, -3.45893522e-02, -1.10124812e-01, 7.01522725e-02, -1.21726161e-01, -1.47423865e-01, -1.23039680e-01, -1.23374131e-02, -1.19147263e-02, 1.07446992e-01, -9.88817692e-02, -1.45182600e-01, 1.93775170e-01, -1.27346943e-01, 1.86633137e-02, 1.30837905e-01, -4.27720196e-02, -4.25461514e-02, -2.19099141e-03, 1.54280390e-01, 1.13050168e-01, -7.06144502e-02, 2.57282628e-01, -3.94247200e-02, 2.39564231e-02, -7.92104464e-02, -4.87981362e-02, -7.78851583e-03, -2.28206362e-01, -1.18388960e-02, -1.91268194e-02, 9.57533367e-02, -1.09828713e-02, -4.72533983e-02, -4.23669224e-03, -2.92308657e-01, 1.61615890e-01, 1.61840033e-01, -1.32490938e-01, -5.74908350e-02, 1.19546422e-02, -9.28351294e-02, -2.93992019e-02, 1.14365769e-01, -1.27576497e-01, 9.93977785e-02, -5.33986035e-02, 7.83101625e-02, 8.45049729e-02, -3.99923331e-03, 1.85768987e-02, -4.76808205e-02, -1.72594705e-03, -1.78767313e-01, -3.48304267e-02, 1.45269570e-01, 5.70227246e-02, 6.27400545e-02, -2.66605418e-01]]) - noise_chol_Chile_stds(chain, draw, noise_chol_Chile_stds_dim_0)float640.02867 0.4035 ... 1.622 0.3862
array([[[2.86658712e-02, 4.03513734e-01, 8.40480985e-01], [1.96448849e-01, 4.25975528e-01, 4.36350422e-01], [4.93996180e+00, 7.06556201e-01, 2.40882351e+00], ..., [3.05380895e-03, 3.52957975e+00, 2.20274432e-01], [1.79712235e-01, 1.09227714e+00, 1.62611114e+00], [3.08303752e-01, 1.62203664e+00, 3.86181427e-01]]]) - noise_chol_United Kingdom(chain, draw, noise_chol_United Kingdom_dim_0)float640.03717 0.858 ... 0.1135 0.8889
array([[[ 3.71684705e-02, 8.58028852e-01, 2.48402104e+00, -5.57011125e-04, -8.38986884e-04, 1.60835183e-03], [ 5.13831503e-01, 2.34162679e-01, 9.29773075e-01, -1.20742517e-01, 5.56586464e-01, 6.70103597e-01], [ 4.04689556e-01, -1.14194737e-01, 2.20613660e-01, -5.65167465e-02, -2.36675135e-02, 1.95619011e-01], ..., [ 1.62342154e+00, 2.91640489e-02, 9.95349212e-01, 2.90955246e-03, -3.25260129e-03, 1.13630417e-01], [ 2.92163436e-01, -1.05168710e-01, 2.21772073e-01, -1.17963943e-02, -2.78526733e-02, 5.06171702e-01], [ 2.76772440e+00, -1.28202638e-01, 3.84651102e-01, -2.57575151e-01, 1.13514286e-01, 8.88888728e-01]]]) - noise_chol_Australia(chain, draw, noise_chol_Australia_dim_0)float643.44 -0.002917 ... 0.03687 0.108
array([[[ 3.44031341e+00, -2.91742222e-03, 2.95114501e-01, 3.00258616e-02, 2.99474003e-01, 5.51796129e-01], [ 3.95364961e+00, 8.45824247e-01, 1.97179631e+00, 7.70370867e-02, -3.40942505e-01, 1.11409713e+00], [ 1.69569723e-01, 7.43677258e-03, 1.00132117e+00, 5.33000539e-02, -8.73193794e-03, 2.80895870e-01], ..., [ 5.26884235e-01, -2.75655607e-03, 2.60203450e-02, -4.26425806e-05, 1.02798877e-02, 3.36273249e-02], [ 1.49509349e+00, 1.57323061e-02, 1.18061170e-01, 7.93359128e-03, 1.79957435e-01, 2.16257204e+00], [ 1.14331405e+00, -1.66588331e-01, 6.64254119e-01, 1.37794637e-03, 3.68710103e-02, 1.08048111e-01]]]) - betaX_New Zealand(chain, draw, betaX_New Zealand_dim_0, betaX_New Zealand_dim_1)float640.0138 0.005566 ... 0.01215 0.01206
array([[[[ 0.01379526, 0.00556591, 0.01453189], [-0.01093608, -0.00610566, 0.00132908], [-0.0654455 , -0.05485527, -0.05683577], ..., [-0.04833221, -0.04626699, -0.04100381], [-0.04691773, -0.04578927, -0.0457036 ], [-0.03383016, -0.03411925, -0.03302587]], [[ 0.01074248, 0.00809032, 0.00140507], [ 0.00125393, 0.00577161, 0.00471226], [-0.06928569, -0.0540019 , -0.04032888], ..., [-0.04526051, -0.04856437, -0.04233282], [-0.05114788, -0.05350525, -0.0469331 ], [-0.0363158 , -0.04021684, -0.03642858]], [[-0.00549983, -0.00797334, -0.00876304], [-0.000499 , -0.00053982, 0.00104204], [ 0.04512627, 0.04957843, 0.05111695], ..., ... ..., [-0.05104744, -0.04843079, -0.04806802], [-0.05096372, -0.05555819, -0.04730662], [-0.03881188, -0.04276146, -0.03506456]], [[-0.00072227, -0.00092834, 0.00109428], [ 0.00307515, -0.00035414, -0.00106262], [ 0.00512026, 0.00298923, 0.00551994], ..., [ 0.00556997, 0.00053438, 0.00740147], [ 0.0040398 , 0.00120579, 0.00761817], [ 0.00299686, 0.0006392 , 0.00617203]], [[-0.00330571, -0.00312396, -0.00234554], [ 0.00028601, 0.00025555, 0.00100261], [ 0.01756795, 0.01793027, 0.01740211], ..., [ 0.01437661, 0.0152307 , 0.01547717], [ 0.01510083, 0.01617478, 0.01592912], [ 0.01122486, 0.01215329, 0.01205646]]]]) - lag_coefs_Chile(chain, draw, equations, lags, cross_vars)float64-0.1921 -0.1453 ... 0.04501 0.05681
array([[[[[-0.19213101, -0.14533614, -0.06473391], [-0.10356245, -0.36552089, -0.43861718]], [[ 0.11692234, -0.50634091, -0.25130411], [-0.10260963, 0.03150801, -0.12869279]], [[-0.00281497, -0.19004161, -0.25181706], [-0.02282547, -0.17534982, -0.06769479]]], [[[-0.13170617, -0.16964863, -0.36087602], [-0.13553971, -0.3571018 , -0.23857882]], [[-0.2724737 , -0.32146061, -0.18594359], [-0.24326934, -0.27428855, -0.16527453]], [[-0.33820013, -0.12477845, -0.25843155], [-0.1160043 , -0.2363186 , -0.11849807]]], ... [[[ 0.06922752, 0.00624961, -0.01264068], [ 0.0254135 , 0.09469037, -0.02588675]], [[-0.00340065, 0.01196188, 0.05139274], [-0.00997527, 0.03844669, -0.02156547]], [[ 0.08087667, 0.05921484, -0.0042421 ], [ 0.07486357, 0.04012774, -0.01098364]]], [[[ 0.0683015 , 0.06817381, 0.06101953], [ 0.05036844, 0.0645917 , 0.07088023]], [[ 0.09482449, 0.05084338, 0.0451617 ], [ 0.05136685, 0.07126498, 0.08353124]], [[ 0.05112117, 0.07426872, 0.05209611], [ 0.06962942, 0.0450149 , 0.05680818]]]]]) - noise_chol_Australia_corr(chain, draw, noise_chol_Australia_corr_dim_0, noise_chol_Australia_corr_dim_1)float641.0 -0.009885 ... 0.3103 1.0
array([[[[ 1. , -0.00988525, 0.04777064], [-0.00988525, 1. , 0.47596262], [ 0.04777064, 0.47596262, 1. ]], [[ 1. , 0.39422195, 0.06597661], [ 0.39422195, 1. , -0.24233587], [ 0.06597661, -0.24233587, 1. ]], [[ 1. , 0.00742676, 0.18633691], [ 0.00742676, 1. , -0.02914212], [ 0.18633691, -0.02914212, 1. ]], ..., [[ 1. , -0.10534898, -0.00121269], [-0.10534898, 1. , 0.29084598], [-0.00121269, 0.29084598, 1. ]], [[ 1. , 0.13208796, 0.00365593], [ 0.13208796, 1. , 0.08268365], [ 0.00365593, 0.08268365, 1. ]], [[ 1. , -0.24325681, 0.0120688 ], [-0.24325681, 1. , 0.31030004], [ 0.0120688 , 0.31030004, 1. ]]]]) - omega_Canada(chain, draw, omega_Canada_dim_0, omega_Canada_dim_1)float641.523 0.0 0.0 ... 0.1349 1.041
array([[[[ 1.52328406e+00, 0.00000000e+00, 0.00000000e+00], [ 1.93627565e-02, 6.19236831e-01, 0.00000000e+00], [ 3.13928098e-02, 2.84468516e-03, 1.04516595e+00]], [[ 1.03567362e+00, 0.00000000e+00, 0.00000000e+00], [-5.51794742e-01, 1.39182387e+00, 0.00000000e+00], [-7.72412381e-01, -3.89664344e-01, 1.43258294e-01]], [[ 1.30713651e-01, 0.00000000e+00, 0.00000000e+00], [-1.80048623e-01, 1.71157986e+00, 0.00000000e+00], [-5.11170658e-03, -2.07499688e-01, 8.71055067e-01]], ..., [[ 5.99543140e-01, 0.00000000e+00, 0.00000000e+00], [-1.81476036e-01, 2.28719555e+00, 0.00000000e+00], [ 3.28976088e-01, -7.25345051e-02, 1.15105894e+00]], [[ 3.35607916e+00, 0.00000000e+00, 0.00000000e+00], [-2.57181861e-01, 1.25547820e+00, 0.00000000e+00], [ 5.13457700e-02, 1.66310933e-01, 1.23280455e+00]], [[ 1.83514675e+00, 0.00000000e+00, 0.00000000e+00], [ 1.62396274e+00, 4.49527903e-01, 0.00000000e+00], [ 1.85610003e-01, 1.34895216e-01, 1.04143226e+00]]]]) - lag_coefs_Canada(chain, draw, equations, lags, cross_vars)float64-0.04739 -0.1423 ... 0.06879
array([[[[[-0.04738794, -0.14234143, -0.13853129], [-0.21672458, -0.22407083, -0.13756053]], [[-0.01232171, -0.20316328, -0.12326586], [-0.09032331, -0.26726072, -0.26274655]], [[-0.16732872, -0.17919546, -0.02832849], [-0.31048545, -0.1777181 , -0.08124112]]], [[[-0.19777672, -0.18399189, -0.23498679], [-0.18921315, -0.2419562 , -0.175745 ]], [[-0.2598466 , -0.21769632, -0.21247609], [-0.1577351 , -0.16856828, -0.21739963]], [[-0.23133308, -0.18661768, -0.19154727], [-0.27220409, -0.2292755 , -0.24996292]]], ... [[[-0.056478 , -0.06623036, -0.04319848], [ 0.0013269 , 0.04519498, 0.03744916]], [[ 0.06816514, 0.00815985, 0.02599815], [ 0.0353851 , 0.00424746, 0.06376147]], [[-0.08474669, 0.00093978, 0.02174443], [ 0.0326497 , -0.02543293, 0.01845534]]], [[[ 0.06552367, 0.04694831, 0.05054006], [ 0.06591855, 0.05434666, 0.05416537]], [[ 0.05667259, 0.06613503, 0.06163121], [ 0.05148675, 0.0603007 , 0.07082295]], [[ 0.05292572, 0.0572092 , 0.07033403], [ 0.05395109, 0.06972252, 0.06879022]]]]]) - alpha_Australia(chain, draw, equations)float64-0.1104 -0.1173 ... -0.3236 -0.2169
array([[[-0.11040217, -0.11730994, -0.11892907], [ 0.07011581, 0.01573795, 0.04269177], [ 0.14804868, 0.37001871, 0.34760741], ..., [ 0.06043768, 0.03483796, 0.07371805], [ 0.12422274, 0.07173644, 0.06389303], [-0.18801587, -0.32364038, -0.21688848]]]) - alpha_Ireland(chain, draw, equations)float64-0.1087 -0.1638 ... -0.1815 -0.2331
array([[[-0.10869618, -0.163818 , -0.08208925], [ 0.07940262, 0.06773777, 0.09363815], [ 0.15238541, 0.16961705, 0.19856246], ..., [ 0.06369923, -0.01606961, 0.43712469], [ 0.04537984, 0.06825317, 0.03096073], [-0.19148377, -0.1815312 , -0.23313313]]]) - noise_chol_Australia_stds(chain, draw, noise_chol_Australia_stds_dim_0)float643.44 0.2951 ... 0.6848 0.1142
array([[[3.44031341, 0.29512892, 0.62854212], [3.95364961, 2.14555339, 1.16764246], [0.16956972, 1.00134879, 0.28604131], ..., [0.52688423, 0.02616595, 0.03516354], [1.49509349, 0.11910477, 2.17006116], [1.14331405, 0.68482495, 0.11417427]]]) - noise_chol_South Africa_corr(chain, draw, noise_chol_South Africa_corr_dim_0, noise_chol_South Africa_corr_dim_1)float641.0 0.1287 0.1772 ... -0.275 1.0
array([[[[ 1.00000000e+00, 1.28741931e-01, 1.77185626e-01], [ 1.28741931e-01, 1.00000000e+00, -4.56917382e-02], [ 1.77185626e-01, -4.56917382e-02, 1.00000000e+00]], [[ 1.00000000e+00, 1.01205065e-01, 1.13460593e-01], [ 1.01205065e-01, 1.00000000e+00, -1.89025777e-01], [ 1.13460593e-01, -1.89025777e-01, 1.00000000e+00]], [[ 1.00000000e+00, -2.21417734e-01, -4.03579898e-02], [-2.21417734e-01, 1.00000000e+00, 8.04885336e-03], [-4.03579898e-02, 8.04885336e-03, 1.00000000e+00]], ..., [[ 1.00000000e+00, -1.19892356e-01, 3.21335276e-01], [-1.19892356e-01, 1.00000000e+00, -5.17565248e-02], [ 3.21335276e-01, -5.17565248e-02, 1.00000000e+00]], [[ 1.00000000e+00, 1.23432754e-01, 8.48505149e-04], [ 1.23432754e-01, 1.00000000e+00, 2.50079003e-01], [ 8.48505149e-04, 2.50079003e-01, 1.00000000e+00]], [[ 1.00000000e+00, 2.50513196e-01, 1.19002911e-01], [ 2.50513196e-01, 1.00000000e+00, -2.75026897e-01], [ 1.19002911e-01, -2.75026897e-01, 1.00000000e+00]]]]) - noise_chol_Ireland(chain, draw, noise_chol_Ireland_dim_0)float643.052 0.654 ... 0.07744 0.5409
array([[[ 3.05179578e+00, 6.54018601e-01, 2.16628875e+00, -5.36283083e-02, 4.41811696e-03, 1.73968325e-01], [ 6.47545198e-01, -1.91753318e-02, 7.77718888e-01, -1.56506280e-02, -2.60786049e-02, 1.43761624e-01], [ 7.07637200e-01, -2.23806635e-02, 2.20859235e+00, -1.46181329e-01, 6.40742541e-02, 4.46789597e-01], ..., [ 1.20541287e+00, -9.71924165e-02, 1.17056953e+00, 4.81963023e-01, -4.65291663e-01, 2.62150833e+00], [ 1.56463364e+00, 7.99916182e-02, 6.06490213e-01, -1.01729349e-03, 1.99537798e-01, 1.01884394e+00], [ 1.21394237e+00, 8.46768355e-02, 4.19133586e-01, 9.16616344e-02, 7.74371047e-02, 5.40857144e-01]]]) - noise_chol_Ireland_corr(chain, draw, noise_chol_Ireland_corr_dim_0, noise_chol_Ireland_corr_dim_1)float641.0 0.289 -0.2945 ... 0.1698 1.0
array([[[[ 1.00000000e+00, 2.89022671e-01, -2.94498852e-01], [ 2.89022671e-01, 1.00000000e+00, -6.18902857e-02], [-2.94498852e-01, -6.18902857e-02, 1.00000000e+00]], [[ 1.00000000e+00, -2.46483740e-02, -1.06507675e-01], [-2.46483740e-02, 1.00000000e+00, -1.74794330e-01], [-1.06507675e-01, -1.74794330e-01, 1.00000000e+00]], [[ 1.00000000e+00, -1.01329313e-02, -3.08111964e-01], [-1.01329313e-02, 1.00000000e+00, 1.38166893e-01], [-3.08111964e-01, 1.38166893e-01, 1.00000000e+00]], ..., [[ 1.00000000e+00, -8.27452920e-02, 1.78125390e-01], [-8.27452920e-02, 1.00000000e+00, -1.86113264e-01], [ 1.78125390e-01, -1.86113264e-01, 1.00000000e+00]], [[ 1.00000000e+00, 1.30760250e-01, -9.79862682e-04], [ 1.30760250e-01, 1.00000000e+00, 1.90417587e-01], [-9.79862682e-04, 1.90417587e-01, 1.00000000e+00]], [[ 1.00000000e+00, 1.98027405e-01, 1.65451839e-01], [ 1.98027405e-01, 1.00000000e+00, 1.69772100e-01], [ 1.65451839e-01, 1.69772100e-01, 1.00000000e+00]]]]) - betaX_Chile(chain, draw, betaX_Chile_dim_0, betaX_Chile_dim_1)float64-0.03785 0.01646 ... -0.01037
array([[[[-0.03785033, 0.01645857, 0.02087206], [ 0.09531856, 0.07028343, 0.02932705], [ 0.05980812, 0.04857091, 0.00052036], ..., [-0.01685545, -0.02523695, -0.02725142], [-0.05015806, -0.02501123, -0.02422215], [ 0.00575774, 0.04877649, 0.03458518]], [[ 0.01966734, -0.03028052, 0.01579705], [ 0.06804103, 0.06359205, 0.05134099], [ 0.00193208, 0.0490178 , -0.00721928], ..., [-0.04087721, -0.04169082, -0.04024195], [-0.05170266, -0.04250768, -0.03567257], [ 0.04181574, 0.04772947, 0.04759498]], [[ 0.00658565, 0.00798913, 0.03706616], [-0.04220304, -0.06184718, -0.05100309], [-0.01072383, -0.02186942, -0.0499245 ], ..., ... ..., [-0.04834585, -0.01974106, -0.00777098], [-0.0127852 , -0.03802169, -0.03700922], [ 0.0598804 , 0.02581887, 0.00509231]], [[ 0.01709368, -0.00630599, 0.01629886], [ 0.00920585, 0.00400731, -0.00266765], [-0.00658293, 0.0067501 , -0.01343034], ..., [ 0.00685193, 0.0055429 , 0.00788099], [ 0.00275637, 0.00202491, 0.00451132], [-0.00382311, -0.00651726, -0.00863301]], [[ 0.00131005, 0.00396284, 0.00358667], [-0.02293317, -0.02470869, -0.02028217], [-0.00889773, -0.00958227, -0.01082166], ..., [ 0.00961991, 0.0088714 , 0.00861739], [ 0.01251388, 0.0129503 , 0.0111852 ], [-0.01122307, -0.00938066, -0.01037044]]]]) - omega_global_stds(chain, draw, omega_global_stds_dim_0)float642.027 0.3923 0.208 ... 3.015 1.214
array([[[2.02687573, 0.3922567 , 0.20800552], [1.42338109, 1.39537257, 1.25244312], [0.17172083, 0.39997914, 0.46632279], ..., [0.49741775, 0.22137572, 0.42187734], [4.03165864, 2.1646064 , 0.14628529], [2.50023366, 3.0151032 , 1.21365994]]]) - alpha_Chile(chain, draw, equations)float64-0.1192 -0.1203 ... -0.2583 -0.2283
array([[[-0.11924555, -0.12032095, -0.10467121], [ 0.09605114, 0.04042802, 0.0695121 ], [ 0.19930289, 0.20740156, 0.2040223 ], ..., [ 0.16471413, 0.20172513, 0.06137248], [ 0.01225394, 0.08455854, 0.02188007], [-0.26668872, -0.25826539, -0.22825017]]]) - betaX_South Africa(chain, draw, betaX_South Africa_dim_0, betaX_South Africa_dim_1)float64-0.05584 -0.04898 ... -0.01442
array([[[[-0.0558436 , -0.04898187, -0.05355381], [-0.05030295, -0.04268354, -0.05209047], [-0.06362075, -0.05213718, -0.06295628], ..., [-0.00370569, -0.00070618, -0.00429591], [-0.00026378, 0.00221167, -0.00043544], [ 0.05821865, 0.05091112, 0.05731178]], [[-0.07427694, -0.06170692, -0.06658133], [-0.0638319 , -0.05446519, -0.05642085], [-0.0823938 , -0.07004981, -0.07096411], ..., [-0.00576356, -0.00474655, -0.00073715], [-0.00335177, -0.00192779, 0.00204938], [ 0.06017439, 0.05778677, 0.06944154]], [[ 0.04658698, 0.04616185, 0.04584471], [ 0.04232194, 0.04217134, 0.04243651], [ 0.05361996, 0.05414532, 0.05408819], ..., ... ..., [ 0.01480562, -0.00324349, 0.00864162], [ 0.02060229, -0.01014975, 0.00712865], [ 0.11584537, 0.01655988, 0.05265053]], [[ 0.01950713, -0.0092738 , -0.00900151], [ 0.0130672 , -0.00754261, 0.00406379], [ 0.01326231, -0.00838295, -0.00127099], ..., [-0.00235201, 0.00123899, 0.0012021 ], [-0.00255293, 0.00180714, -0.00168518], [-0.01246222, 0.01020893, -0.02097644]], [[ 0.01618206, 0.01837856, 0.01680204], [ 0.01429436, 0.01593231, 0.01433676], [ 0.01775231, 0.01968737, 0.01814331], ..., [ 0.0008452 , 0.00034234, 0.00098735], [ 0.00027306, -0.00034906, 0.00054784], [-0.0154514 , -0.01924211, -0.01441864]]]]) - noise_chol_Canada_stds(chain, draw, noise_chol_Canada_stds_dim_0)float641.104 0.825 1.756 ... 0.5721 1.105
array([[[1.10440523, 0.82503859, 1.75570064], [0.15839307, 1.82599118, 0.10349833], [0.1085844 , 2.45752976, 1.17689712], ..., [0.67556354, 3.84087625, 1.84996594], [3.21172324, 1.19995824, 1.50126291], [0.94243576, 0.5721334 , 1.10479856]]]) - z_scale_beta_South Africa(chain, draw)float640.1073 0.1805 ... 0.2544 0.2265
array([[0.10725401, 0.18053172, 0.15312198, 0.13222558, 0.24763501, 0.13829208, 0.13942574, 0.22536165, 0.0804554 , 0.16919095, 0.09650668, 0.43661526, 0.11085958, 0.19899226, 0.08281941, 0.07041651, 0.13845667, 0.23730792, 0.1101118 , 0.13838181, 0.38630228, 0.1075834 , 0.17936368, 0.10454221, 0.09760238, 0.19306042, 0.14542157, 0.15596088, 0.20652342, 0.51818893, 0.09761156, 0.30728218, 0.0837425 , 0.35364186, 0.10977368, 0.18523932, 0.32144508, 0.36644665, 0.33300565, 0.24270826, 0.10655736, 0.21650779, 1.10851693, 0.19038574, 0.09248167, 0.42827783, 0.25155635, 0.13940242, 0.21130247, 0.17644408, 0.08264195, 0.28730601, 0.12524715, 0.54499077, 0.35556992, 0.78320452, 0.36482641, 0.14980467, 0.19185827, 0.10402998, 0.10465709, 0.13258314, 0.51721945, 0.12322392, 0.12148108, 0.14556979, 0.10882881, 0.20944164, 0.07319728, 0.10113682, 0.48365335, 0.28372294, 0.20965392, 0.14507687, 0.33385838, 0.09031964, 0.35193183, 0.0726045 , 0.21016792, 0.13165753, 0.62025143, 0.14487309, 0.18718442, 0.16994823, 0.10752624, 0.20953533, 0.29508935, 0.15935652, 0.08113116, 0.36304941, 0.17457381, 0.09257469, 0.20229817, 0.27807935, 0.25228236, 0.47765986, 0.04043506, 0.17068503, 0.23606871, 0.21949982, ... 0.25812428, 0.25584492, 0.12000788, 0.18615161, 0.30618276, 0.55531509, 0.3798937 , 0.58517722, 1.33472023, 0.08258648, 0.17049598, 0.13462352, 0.13251328, 0.3574387 , 0.16609369, 0.17063956, 0.22181368, 0.31298038, 0.10275053, 0.05074391, 0.14210875, 0.10690855, 0.23991028, 0.10684294, 0.34441436, 0.29376056, 0.13149677, 0.18759748, 0.10411764, 0.36140611, 0.08693992, 0.19647584, 0.20251634, 0.18216841, 0.15343795, 0.09189746, 0.14098726, 0.40627829, 0.14786393, 0.38931897, 0.17453446, 0.14334555, 0.10576873, 0.15494502, 0.1223162 , 0.44686162, 0.19276915, 0.22505745, 0.44672386, 0.06326841, 0.15580757, 0.26850481, 0.1358556 , 0.13065448, 0.35651341, 0.45386905, 0.1353396 , 0.23605247, 0.49807726, 0.1012356 , 0.22667477, 0.29198482, 0.3749364 , 1.06615042, 0.12785009, 0.11832592, 0.12795421, 0.67197296, 0.1005462 , 0.23591892, 0.1126967 , 1.15764445, 0.12701876, 0.27796705, 0.07589608, 0.23126463, 0.10319304, 0.10209158, 0.13637707, 0.18236102, 0.10418193, 0.2118901 , 0.16719501, 0.12298671, 0.29827216, 0.27316018, 0.11454635, 0.43375971, 0.14775724, 0.16408741, 0.23225362, 0.18957495, 0.15405318, 0.25925591, 0.10530855, 0.08787894, 0.11283592, 0.27737801, 0.25435022, 0.22653212]]) - alpha_hat_scale(chain, draw)float640.0727 0.1192 ... 0.2113 0.1635
array([[0.07269615, 0.11921829, 0.23143252, 0.84861949, 0.16966103, 0.5075582 , 0.67664624, 0.20809928, 0.30311923, 0.64344922, 1.01196531, 0.07163681, 0.14849358, 0.70496493, 0.71984082, 0.09816693, 0.30453596, 0.16022729, 0.34023738, 0.18437594, 0.08933639, 0.12849086, 0.10990283, 0.10864449, 0.39733202, 0.22996314, 0.74297684, 0.09706945, 0.13139282, 0.11102822, 0.14630976, 0.15336906, 0.56344578, 0.41766301, 0.52541364, 0.26019061, 0.33760547, 0.19281295, 0.35854335, 0.07862992, 0.1358479 , 0.43859383, 0.20273686, 0.13698435, 0.55731002, 0.20756932, 0.3602051 , 0.06894599, 0.16491305, 0.24257593, 0.09313312, 0.32056066, 0.19396391, 0.10980309, 0.24942448, 0.10673777, 0.1348833 , 0.22183752, 0.19270976, 0.13682576, 0.06966482, 0.24358429, 0.16095191, 0.27298288, 0.19911166, 0.20125226, 0.16671434, 0.09073042, 0.2481739 , 0.10550495, 0.04841081, 4.4755525 , 0.10680349, 0.37361509, 0.08602964, 0.06953387, 0.13064071, 0.32415379, 0.39946363, 0.15933561, 0.31391744, 0.11403867, 0.11453116, 0.31961843, 0.22937366, 0.38438506, 0.12169275, 0.16522245, 0.45366146, 0.4183631 , 0.28288921, 0.11183029, 0.0706044 , 0.09158592, 0.35316383, 0.21230669, 0.18942057, 0.10234242, 0.23640088, 0.34122672, ... 0.11510218, 0.28715445, 0.06325536, 0.2182641 , 0.05826435, 0.23779747, 0.12024905, 0.20812626, 0.08283591, 0.12346339, 0.12013893, 0.14929195, 0.20226776, 0.07193751, 0.21939499, 0.10643118, 0.16011808, 0.2110086 , 0.14463812, 0.14317078, 0.64361059, 0.1397251 , 0.46588068, 0.12380565, 0.11512193, 0.0764919 , 0.16231359, 0.07582565, 0.12714337, 0.13839952, 0.19057452, 0.19415788, 0.05211183, 0.19719842, 0.24943753, 0.19734745, 0.29850262, 0.34822184, 0.51842222, 0.07572321, 0.16820925, 0.20390044, 0.28380267, 0.07146765, 0.06384731, 0.28055985, 0.09380778, 0.4739377 , 0.3139601 , 0.12539639, 0.1713179 , 0.15938139, 0.14701943, 0.1486747 , 0.33452924, 0.31705784, 0.42520577, 0.19829761, 0.16739522, 0.17925151, 0.25676685, 0.33851669, 1.13426024, 0.2406065 , 0.15675693, 0.11306248, 0.24601556, 0.14152391, 0.16138818, 0.1007528 , 0.21083613, 0.21538297, 0.23693717, 0.34581154, 0.46284469, 0.20132751, 0.62907934, 0.67779712, 0.89761045, 0.30522743, 0.35975874, 0.27838732, 0.29728314, 0.10639236, 0.09146294, 0.36255709, 0.32174608, 0.07658706, 0.17405355, 0.09338064, 0.62281929, 0.2122815 , 0.23269755, 0.15123917, 0.37040656, 0.21158872, 0.31484035, 0.28298487, 0.21128568, 0.16345312]]) - z_scale_alpha_Chile(chain, draw)float640.1228 0.1802 ... 0.1581 0.1447
array([[0.12280496, 0.1801886 , 0.06214498, 0.9396314 , 0.29532813, 0.14485331, 0.25391981, 0.09722508, 0.84281462, 0.1754833 , 0.14833856, 0.16231669, 0.25938678, 0.80888171, 1.90351011, 0.36425559, 0.18082723, 0.14113397, 0.76681855, 0.28962159, 0.33811589, 0.20426871, 0.15037805, 0.11512526, 0.3217111 , 0.42380128, 0.13099404, 0.66522252, 0.10802987, 0.12609351, 0.08573739, 0.25037987, 0.15922931, 0.30542747, 0.19328752, 0.1186681 , 0.16841963, 0.14580037, 0.57867261, 1.36610174, 0.09644918, 0.07780445, 0.17635274, 0.06792031, 0.60318196, 0.26870654, 0.20632756, 0.22098476, 0.30685076, 0.1174546 , 0.10842272, 0.63121043, 0.13528979, 0.12295001, 0.21622103, 0.32004973, 0.20743825, 0.12341796, 0.16046552, 0.12204894, 0.15700979, 0.47426836, 0.59871361, 0.130174 , 0.17841922, 0.05130847, 0.24402754, 0.26311468, 0.3673745 , 0.21245848, 0.15455659, 0.16135878, 0.22060327, 0.08259884, 0.20288021, 0.19934387, 0.4310693 , 0.15725011, 0.11558767, 0.18058161, 0.40076971, 1.59883351, 0.13512574, 0.07111749, 0.2259875 , 0.11708975, 0.17962592, 0.20554337, 0.10674949, 0.38846715, 0.24648182, 0.26746079, 0.21472927, 0.58726211, 0.2480894 , 0.22786661, 0.07168677, 0.15040255, 0.31669026, 0.81533274, ... 0.10732727, 0.25540907, 0.18845381, 0.18159762, 0.84641552, 0.95657691, 0.29089986, 0.10297957, 2.18222589, 0.18367526, 0.13414844, 0.27980592, 0.16258218, 0.22178631, 0.24193235, 0.33693783, 0.15629178, 0.13617769, 0.15148151, 0.17607153, 0.13714411, 0.11630865, 0.50907849, 0.18781747, 0.25961083, 0.17828212, 0.30363962, 0.24837124, 0.28097205, 0.1212715 , 0.15934898, 0.17463097, 0.36715658, 0.1965841 , 0.15911579, 0.18945764, 0.53008639, 1.60310381, 0.29878552, 0.31898287, 0.2580223 , 0.16231215, 0.25781832, 0.12833553, 0.22224723, 0.11660717, 0.11259463, 0.70996616, 0.26725195, 0.27916963, 0.0648474 , 0.13238682, 0.14569057, 0.08504128, 0.34093376, 0.0886281 , 0.41900118, 0.14394318, 0.06623067, 0.07323047, 0.1616256 , 0.1730078 , 0.29926958, 0.41316745, 0.48462346, 0.06349766, 1.03391098, 0.09250841, 0.35071748, 0.11720248, 0.22021422, 0.25051871, 0.07971699, 0.11641528, 0.15521057, 0.44110744, 0.19682487, 0.18227832, 0.16280956, 0.16616888, 0.25973939, 0.12016903, 0.20314555, 0.14937808, 0.44411365, 0.35396291, 0.30764843, 0.41954436, 0.29483912, 0.20793049, 0.5363871 , 0.08154625, 0.31168436, 0.15164051, 0.20415209, 0.14594542, 0.26251029, 0.31846204, 0.15811698, 0.1447256 ]]) - z_scale_alpha_United Kingdom(chain, draw)float640.1462 0.2181 ... 0.1132 0.1805
array([[0.14615347, 0.21814529, 0.08921965, 0.15732618, 0.10877408, 0.26838932, 0.23372908, 0.10478102, 0.30007749, 0.20797412, 0.24297004, 0.14059216, 0.50656317, 0.04252637, 0.42111484, 0.16856053, 0.1426295 , 0.13709904, 0.44633171, 0.92469999, 0.27874396, 0.96112713, 0.55251534, 0.15682131, 0.58532478, 0.0775758 , 0.31647196, 0.10230881, 0.09274098, 0.17951364, 0.10385349, 0.34649954, 0.1111455 , 0.15686222, 0.10405297, 0.14926344, 0.1219439 , 0.1299249 , 0.70901532, 0.1017012 , 0.09479976, 0.30732467, 0.22215443, 0.25663154, 0.09132576, 0.11221097, 0.20059669, 0.08295577, 0.619365 , 0.17270199, 0.11771648, 0.1574121 , 0.1192092 , 0.19272859, 0.59577432, 0.25757943, 0.30501459, 0.10930594, 0.32325162, 0.08842916, 0.4478156 , 0.17351546, 0.47777777, 0.18264043, 0.18286935, 0.14669802, 0.18226189, 0.18756594, 0.8562476 , 0.12543233, 0.17217142, 0.06201229, 0.18986327, 0.15523575, 0.26112021, 0.85582229, 0.29504765, 0.08046924, 0.14008726, 0.14362572, 0.11293334, 0.14019856, 0.20855488, 0.33438951, 0.33480502, 0.20368539, 0.19183289, 0.07625658, 0.3757983 , 0.13890529, 0.3200278 , 0.13286024, 0.08474757, 0.06918901, 0.82314137, 0.13584292, 0.19353441, 0.44884621, 0.20077177, 0.31292323, ... 0.27453994, 0.2341724 , 0.05568105, 0.18127981, 0.17273249, 0.73311412, 1.24177591, 0.11517602, 0.20825295, 0.22007299, 0.1253171 , 0.49008584, 0.08482854, 0.37319298, 0.3061145 , 0.18899357, 0.20976727, 0.2296741 , 0.09501514, 0.24112746, 0.09570809, 0.18475431, 0.16895616, 0.15710433, 0.52212712, 0.47383848, 0.13838211, 0.21483669, 0.07641952, 0.28699865, 0.26494069, 0.07559187, 0.09959629, 0.23535023, 0.23532044, 0.09781274, 0.30847832, 0.06363466, 0.18676587, 0.16781683, 0.18327309, 0.06711008, 0.48003086, 0.09125349, 0.23476454, 0.10241234, 0.78334824, 0.06992242, 0.27470254, 0.13828056, 0.17578395, 0.15507622, 0.1191825 , 0.11911828, 0.17926634, 0.24485954, 0.11456693, 0.43582202, 0.14602728, 0.46181792, 0.14520694, 0.42904162, 0.06024894, 0.24232622, 0.13150011, 0.09110117, 0.12624898, 0.21179786, 0.5072583 , 0.30542341, 0.15424995, 0.26049769, 0.35399283, 0.14698489, 0.25859346, 0.15470331, 0.20398941, 0.13981706, 0.32678196, 0.12441435, 0.46566708, 0.0994699 , 0.36349282, 0.19693197, 0.05707575, 0.1943626 , 0.24143071, 0.29668235, 0.22333971, 0.13946168, 0.20708734, 0.19571303, 0.2096319 , 0.08398149, 0.09573948, 0.1769644 , 0.46251936, 0.19525321, 0.1131867 , 0.18048441]]) - noise_chol_New Zealand_corr(chain, draw, noise_chol_New Zealand_corr_dim_0, noise_chol_New Zealand_corr_dim_1)float641.0 0.3852 0.2603 ... -0.1005 1.0
array([[[[ 1. , 0.38524886, 0.26031599], [ 0.38524886, 1. , -0.16907472], [ 0.26031599, -0.16907472, 1. ]], [[ 1. , 0.14718378, -0.71368448], [ 0.14718378, 1. , -0.03434326], [-0.71368448, -0.03434326, 1. ]], [[ 1. , 0.03681494, 0.04966948], [ 0.03681494, 1. , -0.30363802], [ 0.04966948, -0.30363802, 1. ]], ..., [[ 1. , -0.21527001, -0.38740003], [-0.21527001, 1. , 0.14113665], [-0.38740003, 0.14113665, 1. ]], [[ 1. , 0.08716486, 0.27606965], [ 0.08716486, 1. , -0.15615154], [ 0.27606965, -0.15615154, 1. ]], [[ 1. , -0.07402657, 0.02915884], [-0.07402657, 1. , -0.10050008], [ 0.02915884, -0.10050008, 1. ]]]]) - noise_chol_United States_corr(chain, draw, noise_chol_United States_corr_dim_0, noise_chol_United States_corr_dim_1)float641.0 0.01808 -0.07775 ... 0.2051 1.0
array([[[[ 1. , 0.01807806, -0.07774922], [ 0.01807806, 1. , 0.40628986], [-0.07774922, 0.40628986, 1. ]], [[ 1. , -0.04725293, 0.14554113], [-0.04725293, 1. , 0.28012288], [ 0.14554113, 0.28012288, 1. ]], [[ 1. , -0.18640816, 0.03443714], [-0.18640816, 1. , 0.46879452], [ 0.03443714, 0.46879452, 1. ]], ..., [[ 1. , -0.01840045, -0.38639318], [-0.01840045, 1. , 0.03570362], [-0.38639318, 0.03570362, 1. ]], [[ 1. , -0.05084678, -0.05729962], [-0.05084678, 1. , 0.04874449], [-0.05729962, 0.04874449, 1. ]], [[ 1. , 0.35721589, -0.27867325], [ 0.35721589, 1. , 0.20505815], [-0.27867325, 0.20505815, 1. ]]]]) - noise_chol_Chile(chain, draw, noise_chol_Chile_dim_0)float640.02867 -0.06896 ... -0.1446 0.3575
array([[[ 2.86658712e-02, -6.89626277e-02, 3.97577024e-01, 1.24975708e-01, 2.03544014e-01, 8.05828265e-01], [ 1.96448849e-01, -1.67392731e-01, 3.91707574e-01, 1.05598630e-01, 1.11264155e-02, 4.23233769e-01], [ 4.93996180e+00, -2.28576964e-02, 7.06186371e-01, 8.99573106e-01, 1.07460087e-01, 2.23196130e+00], ..., [ 3.05380895e-03, -8.90622680e-01, 3.41536594e+00, -7.56755854e-02, -1.92021092e-03, 2.06858270e-01], [ 1.79712235e-01, 3.31228560e-01, 1.04084437e+00, 3.82925750e-01, 3.85452013e-01, 1.53265523e+00], [ 3.08303752e-01, -4.39043564e-01, 1.56148763e+00, 2.08548661e-02, -1.44607107e-01, 3.57477207e-01]]]) - z_scale_alpha_United States(chain, draw)float640.2131 0.2173 ... 0.9523 0.2111
array([[0.213131 , 0.21725718, 0.22404577, 0.25395186, 1.25995739, 0.05129905, 0.28177037, 0.49832128, 0.55824947, 0.27270416, 0.54184521, 0.23547635, 0.1661448 , 0.1095501 , 0.09859127, 0.38130638, 0.13448592, 0.19701676, 0.28648084, 0.17895608, 0.12634376, 0.43515596, 0.13119484, 0.93350449, 0.20318491, 0.27020998, 0.12537416, 0.06455312, 0.25969604, 0.19505406, 0.13752629, 0.11508442, 0.69842961, 0.63597102, 0.08573165, 0.15040056, 0.07971116, 0.27761443, 0.29080742, 0.10751002, 0.16730017, 0.22935299, 0.18744526, 0.16046437, 0.09227502, 0.08299103, 0.14732107, 0.18676536, 1.44512843, 0.09468049, 0.36356497, 0.47477523, 0.10161336, 0.2142195 , 0.2393077 , 0.21300733, 0.06310802, 0.17393768, 0.12666332, 0.11760015, 0.26429748, 0.33236386, 0.39800096, 0.08165497, 0.1144731 , 0.08405083, 0.12684565, 0.16087119, 0.1557723 , 0.27829468, 0.10828135, 0.30089728, 0.1192222 , 0.08841513, 0.17681336, 0.2129509 , 0.08544167, 0.09566903, 0.4035193 , 0.65962495, 0.24762694, 0.17419881, 0.39933495, 0.48364864, 0.24012817, 0.20604128, 0.3841842 , 0.15346105, 0.1078102 , 0.23174745, 0.74321902, 0.16599125, 0.49158993, 0.10894033, 0.29102026, 0.15326786, 0.10167379, 0.14005689, 0.23751325, 0.78210725, ... 0.14312609, 0.14504121, 0.12848571, 0.09837204, 0.15276736, 0.63350922, 0.07001615, 0.16307457, 0.23126341, 0.19017895, 0.18095649, 0.31685085, 0.36320904, 0.20086189, 0.09804208, 0.11229264, 0.15529835, 0.10684901, 0.16513884, 1.00334368, 0.90216595, 0.25810317, 1.45173001, 0.83503671, 0.10299706, 0.20407598, 0.04759074, 0.10313566, 0.3615443 , 0.40750234, 0.12881712, 0.29223599, 0.39753163, 0.6605557 , 0.50994988, 0.14554548, 0.13850693, 0.67496332, 0.23446763, 0.1438275 , 0.10050025, 0.22235178, 0.35316296, 0.11539015, 0.08959966, 0.19899996, 0.07770607, 0.12859195, 0.11907838, 0.19230079, 0.15656008, 0.12932708, 0.29257899, 0.21465011, 0.39832942, 0.04844192, 0.07065745, 0.15464813, 0.16818291, 0.13314731, 0.06698879, 0.37597655, 0.15014681, 0.10834985, 0.32433376, 0.12216928, 0.50987548, 1.23717434, 0.09642178, 0.37018357, 0.18213376, 0.05193194, 0.1497674 , 0.22702825, 0.24786638, 0.05947143, 0.17178903, 0.29558854, 0.25410012, 0.30833692, 0.15885424, 0.11080126, 0.24733362, 0.2618624 , 0.10312871, 0.20318639, 0.12534367, 0.2954155 , 0.1974756 , 0.13267557, 0.26437944, 0.26765847, 0.09003416, 0.28084225, 0.6000107 , 0.15638529, 0.1348397 , 0.114784 , 0.95225872, 0.2111357 ]]) - noise_chol_Ireland_stds(chain, draw, noise_chol_Ireland_stds_dim_0)float643.052 2.263 0.1821 ... 0.4276 0.554
array([[[3.05179578, 2.26286263, 0.18210023], [0.6475452 , 0.77795524, 0.14694366], [0.7076372 , 2.20870574, 0.47444224], ..., [1.20541287, 1.17459754, 2.70575139], [1.56463364, 0.61174262, 1.03820005], [1.21394237, 0.4276016 , 0.55400795]]]) - beta_hat_location(chain, draw)float64-0.1648 -0.2081 ... 0.0113 0.05914
array([[-0.16481175, -0.20809496, 0.16284455, -0.06670417, 0.20153212, 0.00238363, 0.06199665, -0.03543655, -0.03926312, 0.13693163, 0.13141081, 0.10801654, 0.11110207, -0.10641381, -0.04353907, 0.1056492 , 0.06787589, -0.10119827, -0.04913159, 0.0462559 , -0.23254297, 0.07203862, -0.1765229 , 0.09002237, -0.08303859, 0.05352949, 0.11311501, 0.11669136, 0.07052244, -0.0111081 , -0.20942819, 0.13809954, -0.01091662, 0.01813257, 0.02249916, 0.17290654, 0.00451771, -0.04546065, 0.1887338 , 0.15981393, -0.12068138, 0.12706804, -0.10485724, 0.05808422, 0.1083918 , 0.11740385, -0.23974765, 0.01047011, -0.07072351, 0.02013301, -0.03522476, -0.09390172, -0.08729993, -0.02633896, -0.17301583, -0.16426084, 0.05181323, 0.02842454, -0.00801742, -0.09094017, 0.05193375, -0.12707409, 0.01230593, -0.00335992, -0.07555674, -0.10280913, -0.16115713, 0.18664087, 0.31247593, 0.1037974 , -0.02645771, 0.07510285, 0.01774999, -0.03879357, -0.18341457, -0.01466648, 0.03587112, -0.07496613, 0.292636 , -0.28021826, 0.13067678, 0.02094223, -0.11146711, -0.08585967, -0.12881305, 0.02642538, 0.15162453, -0.12306617, -0.02078033, -0.05134788, -0.02570612, 0.09287529, 0.14307387, 0.07750462, -0.08578185, -0.00848868, 0.02153072, 0.09048901, -0.09708856, 0.16906214, ... 0.15142473, -0.32155753, 0.03281664, -0.12321917, -0.05759783, 0.19264854, 0.0715562 , -0.02225798, 0.00513071, 0.01819049, 0.08043267, -0.10933417, 0.01239515, 0.00716248, -0.02060367, -0.14038532, 0.17588652, 0.04889748, -0.04151308, -0.0464201 , -0.09352181, 0.06807259, 0.00763478, -0.08002759, -0.04640006, -0.11200583, 0.09651522, 0.17205287, 0.07632241, 0.05538552, -0.04992605, -0.03717167, -0.10774248, 0.07257829, -0.16353298, 0.02617405, 0.10574109, 0.07088435, -0.16879805, -0.08567799, 0.03575711, 0.20419767, -0.02997488, -0.09988271, -0.06459231, -0.22554068, 0.04772152, -0.19766586, 0.080018 , -0.09377091, -0.05714076, -0.01117028, -0.12294586, -0.1362682 , -0.06380633, 0.04973399, -0.12680432, 0.04301216, -0.03454063, 0.19510736, -0.25272959, -0.00048978, -0.0808569 , -0.16610265, -0.01780281, -0.10247105, 0.05562454, 0.01445049, -0.20653719, 0.14408886, -0.03978285, 0.02297927, -0.18641727, -0.01959715, -0.15556193, -0.0172424 , -0.00495404, 0.05588277, 0.17457213, -0.01759205, -0.053386 , 0.1278743 , -0.00732395, 0.09852238, -0.00235284, 0.00120081, 0.116359 , 0.00593622, -0.11993341, -0.06500739, 0.15256744, 0.01469552, -0.08728158, 0.12287521, -0.10911156, 0.01910623, -0.16061979, -0.18130079, 0.01129778, 0.05913939]]) - rho(chain, draw)float640.4541 0.6935 ... 0.1761 0.5731
array([[0.45408371, 0.69350899, 0.35049896, 0.23006247, 0.76242918, 0.70501677, 0.05367603, 0.67104457, 0.27539228, 0.7166245 , 0.45334409, 0.84363359, 0.35948475, 0.03437022, 0.19584551, 0.42114371, 0.4940945 , 0.67276139, 0.84154138, 0.2502528 , 0.79031196, 0.48646038, 0.76934743, 0.91227126, 0.67111831, 0.2401683 , 0.52495365, 0.51705828, 0.14105183, 0.73161832, 0.8221039 , 0.20932337, 0.28994766, 0.24748005, 0.53707395, 0.33366829, 0.69892448, 0.50569658, 0.83425951, 0.34720364, 0.57428598, 0.17666474, 0.8467154 , 0.87396205, 0.29832267, 0.3786298 , 0.50826547, 0.37942305, 0.62288707, 0.50273959, 0.49671072, 0.32090275, 0.51230094, 0.43734976, 0.51710441, 0.62698532, 0.55284996, 0.54306173, 0.46399675, 0.73824307, 0.35566467, 0.1523995 , 0.26756316, 0.70418041, 0.52058539, 0.39748723, 0.93960598, 0.58849021, 0.87406193, 0.88156013, 0.62846781, 0.29445907, 0.06498372, 0.67313392, 0.79593263, 0.96395349, 0.17048755, 0.35716337, 0.51502277, 0.43679723, 0.12226093, 0.46175202, 0.3580057 , 0.19219847, 0.57047203, 0.52972452, 0.07763128, 0.29154291, 0.23669705, 0.19362827, 0.66743246, 0.42616666, 0.2766233 , 0.60863324, 0.26673162, 0.85178987, 0.75493282, 0.52312087, 0.15625225, 0.86869569, ... 0.5916496 , 0.95019525, 0.66363723, 0.60389902, 0.42312456, 0.65388926, 0.41973304, 0.78954301, 0.67610768, 0.49357635, 0.94811528, 0.1627281 , 0.81540546, 0.71591941, 0.15847906, 0.42608947, 0.59020144, 0.60466001, 0.16386533, 0.6563939 , 0.72368189, 0.71268739, 0.08435803, 0.16813328, 0.71776272, 0.47468738, 0.33987693, 0.51241451, 0.53359411, 0.7615783 , 0.22030355, 0.69281104, 0.41457362, 0.31889544, 0.59163158, 0.41498785, 0.50451057, 0.47400243, 0.69923042, 0.27328454, 0.73617488, 0.59073884, 0.67845796, 0.236538 , 0.19893683, 0.19526877, 0.86770475, 0.70382729, 0.58445592, 0.6208028 , 0.7915242 , 0.82593155, 0.4962333 , 0.70547759, 0.80282085, 0.11878151, 0.19505328, 0.64237388, 0.68187787, 0.61570776, 0.93888417, 0.22076176, 0.43904963, 0.47437682, 0.47768572, 0.73397547, 0.64809938, 0.28300901, 0.41784012, 0.39098325, 0.49852955, 0.66886414, 0.71536127, 0.18841023, 0.2009872 , 0.50540092, 0.43635371, 0.32098071, 0.26902961, 0.38409436, 0.1486014 , 0.75615635, 0.51535178, 0.43578111, 0.32947848, 0.19946403, 0.1354591 , 0.74983673, 0.91626011, 0.24296797, 0.14304216, 0.21893295, 0.47244829, 0.20654953, 0.55832374, 0.64679508, 0.33490577, 0.42673137, 0.17605767, 0.57305957]]) - z_scale_alpha_Canada(chain, draw)float640.06378 0.2621 ... 0.06267 0.2395
array([[0.06378199, 0.26213638, 0.10562488, 0.41412078, 0.22852257, 0.97315592, 0.1018424 , 0.28849668, 0.31188091, 0.16670602, 0.19405259, 0.15868021, 0.14469301, 0.34340057, 0.23637804, 0.11256724, 0.63783365, 0.0999994 , 0.1261458 , 0.34533882, 0.06299829, 0.10649731, 0.31179513, 0.13521697, 0.15208259, 0.16434184, 0.13069923, 0.15646203, 0.25548276, 0.17661368, 0.23370614, 0.25636507, 0.13942621, 0.39854945, 0.13636833, 0.10310414, 0.39128064, 0.12635791, 0.22949415, 0.23036678, 0.12051084, 0.10650911, 0.12005857, 0.46443176, 3.7093797 , 0.12245853, 0.10306819, 1.55604689, 0.06856524, 0.08798214, 0.13534854, 0.14941395, 0.15001066, 0.1209059 , 0.10413524, 0.1032491 , 0.20396899, 0.31495513, 0.11535401, 0.35148579, 0.18075366, 0.19389029, 0.08548038, 0.15217848, 0.19976525, 0.20243536, 0.25413403, 0.72784895, 0.20917203, 0.13343318, 0.08898976, 0.23062395, 0.27564811, 0.34233545, 0.18439108, 0.26244743, 0.07358966, 0.07545393, 0.58289477, 0.32524163, 0.07374368, 0.18442543, 0.12958636, 0.2696356 , 0.18756169, 0.11827149, 0.33316798, 0.15683388, 0.05593736, 0.1856784 , 0.19879242, 0.22442752, 0.23856679, 0.22624447, 0.11213538, 0.12026965, 0.25985264, 0.50055825, 0.13438282, 0.20595772, ... 0.08248672, 0.72677529, 0.80857457, 0.20586513, 0.47596947, 0.15769514, 0.08850205, 0.16083444, 0.07485606, 0.07304545, 0.18594709, 0.0954647 , 2.51901922, 0.1055115 , 0.10995192, 0.54821221, 0.3098678 , 0.84624647, 0.16265487, 0.19637961, 0.10971489, 0.15174734, 0.20759024, 0.13325213, 0.49380788, 0.13177068, 0.18697702, 0.16572793, 0.49853711, 0.24387162, 0.23964506, 0.19749614, 0.70791164, 0.15848289, 0.27759852, 0.19001998, 0.26131136, 0.21886743, 0.10997396, 0.24131981, 0.11431693, 0.11110756, 0.6115091 , 0.08767059, 0.23483956, 0.19086222, 0.10834805, 0.10833937, 0.13314133, 0.27010614, 0.08072827, 0.1878972 , 0.2072152 , 0.19607113, 0.31546982, 0.29895169, 0.21528694, 0.07094348, 0.16626419, 0.23719245, 0.1359794 , 0.13518073, 0.30263685, 0.06922079, 0.57380417, 0.46551093, 0.23889615, 0.364586 , 0.23034022, 0.10063996, 0.12269451, 0.25981145, 0.3079617 , 0.37582332, 0.13643984, 0.31780538, 0.29426745, 0.14108259, 0.10929791, 0.57187571, 0.23080312, 0.12899524, 0.21813754, 0.25141642, 0.07688701, 0.14417158, 0.12121741, 0.33565333, 0.14715947, 0.10673218, 0.09397568, 0.14081268, 0.44149728, 0.06293998, 0.10423666, 0.14709606, 0.18111538, 0.17217239, 0.0626725 , 0.2394876 ]])
- chainPandasIndex
PandasIndex(Int64Index([0], dtype='int64', name='chain'))
- drawPandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ... 490, 491, 492, 493, 494, 495, 496, 497, 498, 499], dtype='int64', name='draw', length=500)) - omega_global_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5], dtype='int64', name='omega_global_dim_0'))
- betaX_Canada_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21], dtype='int64', name='betaX_Canada_dim_0')) - betaX_Canada_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='betaX_Canada_dim_1'))
- noise_chol_South Africa_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5], dtype='int64', name='noise_chol_South Africa_dim_0'))
- omega_New Zealand_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_New Zealand_dim_0'))
- omega_New Zealand_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_New Zealand_dim_1'))
- equationsPandasIndex
PandasIndex(Index(['dl_gdp', 'dl_cons', 'dl_gfcf'], dtype='object', name='equations'))
- lagsPandasIndex
PandasIndex(Int64Index([1, 2], dtype='int64', name='lags'))
- cross_varsPandasIndex
PandasIndex(Index(['dl_gdp', 'dl_cons', 'dl_gfcf'], dtype='object', name='cross_vars'))
- betaX_United States_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45], dtype='int64', name='betaX_United States_dim_0')) - betaX_United States_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='betaX_United States_dim_1'))
- noise_chol_United Kingdom_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_United Kingdom_stds_dim_0'))
- noise_chol_New Zealand_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_New Zealand_stds_dim_0'))
- omega_United Kingdom_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_United Kingdom_dim_0'))
- omega_United Kingdom_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_United Kingdom_dim_1'))
- omega_Australia_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_Australia_dim_0'))
- omega_Australia_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_Australia_dim_1'))
- noise_chol_South Africa_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_South Africa_stds_dim_0'))
- omega_Ireland_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_Ireland_dim_0'))
- omega_Ireland_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_Ireland_dim_1'))
- noise_chol_Chile_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Chile_corr_dim_0'))
- noise_chol_Chile_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Chile_corr_dim_1'))
- noise_chol_United States_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_United States_stds_dim_0'))
- omega_United States_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_United States_dim_0'))
- omega_United States_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_United States_dim_1'))
- noise_chol_New Zealand_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5], dtype='int64', name='noise_chol_New Zealand_dim_0'))
- omega_Chile_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_Chile_dim_0'))
- omega_Chile_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_Chile_dim_1'))
- noise_chol_United States_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5], dtype='int64', name='noise_chol_United States_dim_0'))
- noise_chol_United Kingdom_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_United Kingdom_corr_dim_0'))
- noise_chol_United Kingdom_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_United Kingdom_corr_dim_1'))
- betaX_United Kingdom_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='betaX_United Kingdom_dim_0')) - betaX_United Kingdom_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='betaX_United Kingdom_dim_1'))
- betaX_Ireland_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='betaX_Ireland_dim_0')) - betaX_Ireland_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='betaX_Ireland_dim_1'))
- omega_South Africa_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_South Africa_dim_0'))
- omega_South Africa_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_South Africa_dim_1'))
- noise_chol_Canada_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5], dtype='int64', name='noise_chol_Canada_dim_0'))
- omega_global_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_global_corr_dim_0'))
- omega_global_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_global_corr_dim_1'))
- betaX_Australia_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='betaX_Australia_dim_0')) - betaX_Australia_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='betaX_Australia_dim_1'))
- noise_chol_Canada_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Canada_corr_dim_0'))
- noise_chol_Canada_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Canada_corr_dim_1'))
- noise_chol_Chile_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Chile_stds_dim_0'))
- noise_chol_United Kingdom_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5], dtype='int64', name='noise_chol_United Kingdom_dim_0'))
- noise_chol_Australia_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5], dtype='int64', name='noise_chol_Australia_dim_0'))
- betaX_New Zealand_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40], dtype='int64', name='betaX_New Zealand_dim_0')) - betaX_New Zealand_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='betaX_New Zealand_dim_1'))
- noise_chol_Australia_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Australia_corr_dim_0'))
- noise_chol_Australia_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Australia_corr_dim_1'))
- omega_Canada_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_Canada_dim_0'))
- omega_Canada_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_Canada_dim_1'))
- noise_chol_Australia_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Australia_stds_dim_0'))
- noise_chol_South Africa_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_South Africa_corr_dim_0'))
- noise_chol_South Africa_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_South Africa_corr_dim_1'))
- noise_chol_Ireland_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5], dtype='int64', name='noise_chol_Ireland_dim_0'))
- noise_chol_Ireland_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Ireland_corr_dim_0'))
- noise_chol_Ireland_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Ireland_corr_dim_1'))
- betaX_Chile_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='betaX_Chile_dim_0')) - betaX_Chile_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='betaX_Chile_dim_1'))
- omega_global_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='omega_global_stds_dim_0'))
- betaX_South Africa_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='betaX_South Africa_dim_0')) - betaX_South Africa_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='betaX_South Africa_dim_1'))
- noise_chol_Canada_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Canada_stds_dim_0'))
- noise_chol_New Zealand_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_New Zealand_corr_dim_0'))
- noise_chol_New Zealand_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_New Zealand_corr_dim_1'))
- noise_chol_United States_corr_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_United States_corr_dim_0'))
- noise_chol_United States_corr_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_United States_corr_dim_1'))
- noise_chol_Chile_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5], dtype='int64', name='noise_chol_Chile_dim_0'))
- noise_chol_Ireland_stds_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='noise_chol_Ireland_stds_dim_0'))
- created_at
- 2023-02-21T19:22:35.383920
- arviz_version
- 0.14.0
- inference_library
- pymc
- inference_library_version
- 5.0.1
<xarray.Dataset> Dimensions: (chain: 1, draw: 500, omega_global_dim_0: 6, betaX_Canada_dim_0: 22, betaX_Canada_dim_1: 3, noise_chol_South Africa_dim_0: 6, omega_New Zealand_dim_0: 3, ... noise_chol_New Zealand_corr_dim_0: 3, noise_chol_New Zealand_corr_dim_1: 3, noise_chol_United States_corr_dim_0: 3, noise_chol_United States_corr_dim_1: 3, noise_chol_Chile_dim_0: 6, noise_chol_Ireland_stds_dim_0: 3) Coordinates: (12/73) * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 ... 497 498 499 * omega_global_dim_0 (omega_global_dim_0) int64 0 1 2 3 4 5 * betaX_Canada_dim_0 (betaX_Canada_dim_0) int64 0 1 ... 21 * betaX_Canada_dim_1 (betaX_Canada_dim_1) int64 0 1 2 * noise_chol_South Africa_dim_0 (noise_chol_South Africa_dim_0) int64 ... ... ... * noise_chol_New Zealand_corr_dim_0 (noise_chol_New Zealand_corr_dim_0) int64 ... * noise_chol_New Zealand_corr_dim_1 (noise_chol_New Zealand_corr_dim_1) int64 ... * noise_chol_United States_corr_dim_0 (noise_chol_United States_corr_dim_0) int64 ... * noise_chol_United States_corr_dim_1 (noise_chol_United States_corr_dim_1) int64 ... * noise_chol_Chile_dim_0 (noise_chol_Chile_dim_0) int64 0 ... 5 * noise_chol_Ireland_stds_dim_0 (noise_chol_Ireland_stds_dim_0) int64 ... Data variables: (12/80) omega_global (chain, draw, omega_global_dim_0) float64 ... betaX_Canada (chain, draw, betaX_Canada_dim_0, betaX_Canada_dim_1) float64 ... noise_chol_South Africa (chain, draw, noise_chol_South Africa_dim_0) float64 ... omega_New Zealand (chain, draw, omega_New Zealand_dim_0, omega_New Zealand_dim_1) float64 ... lag_coefs_United States (chain, draw, equations, lags, cross_vars) float64 ... betaX_United States (chain, draw, betaX_United States_dim_0, betaX_United States_dim_1) float64 ... ... ... noise_chol_Chile (chain, draw, noise_chol_Chile_dim_0) float64 ... z_scale_alpha_United States (chain, draw) float64 0.2131 ... 0.... noise_chol_Ireland_stds (chain, draw, noise_chol_Ireland_stds_dim_0) float64 ... beta_hat_location (chain, draw) float64 -0.1648 ... 0... rho (chain, draw) float64 0.4541 ... 0.... z_scale_alpha_Canada (chain, draw) float64 0.06378 ... 0... Attributes: created_at: 2023-02-21T19:22:35.383920 arviz_version: 0.14.0 inference_library: pymc inference_library_version: 5.0.1xarray.Dataset -
- chain: 1
- draw: 500
- obs_Ireland_dim_0: 49
- obs_Ireland_dim_1: 3
- obs_South Africa_dim_0: 49
- obs_South Africa_dim_1: 3
- obs_United States_dim_0: 46
- obs_United States_dim_1: 3
- obs_Chile_dim_0: 49
- obs_Chile_dim_1: 3
- obs_Canada_dim_0: 22
- obs_Canada_dim_1: 3
- obs_New Zealand_dim_0: 41
- obs_New Zealand_dim_1: 3
- obs_United Kingdom_dim_0: 49
- obs_United Kingdom_dim_1: 3
- obs_Australia_dim_0: 49
- obs_Australia_dim_1: 3
- chain(chain)int640
array([0])
- draw(draw)int640 1 2 3 4 5 ... 495 496 497 498 499
array([ 0, 1, 2, ..., 497, 498, 499])
- obs_Ireland_dim_0(obs_Ireland_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - obs_Ireland_dim_1(obs_Ireland_dim_1)int640 1 2
array([0, 1, 2])
- obs_South Africa_dim_0(obs_South Africa_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - obs_South Africa_dim_1(obs_South Africa_dim_1)int640 1 2
array([0, 1, 2])
- obs_United States_dim_0(obs_United States_dim_0)int640 1 2 3 4 5 6 ... 40 41 42 43 44 45
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45]) - obs_United States_dim_1(obs_United States_dim_1)int640 1 2
array([0, 1, 2])
- obs_Chile_dim_0(obs_Chile_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - obs_Chile_dim_1(obs_Chile_dim_1)int640 1 2
array([0, 1, 2])
- obs_Canada_dim_0(obs_Canada_dim_0)int640 1 2 3 4 5 6 ... 16 17 18 19 20 21
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21]) - obs_Canada_dim_1(obs_Canada_dim_1)int640 1 2
array([0, 1, 2])
- obs_New Zealand_dim_0(obs_New Zealand_dim_0)int640 1 2 3 4 5 6 ... 35 36 37 38 39 40
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40]) - obs_New Zealand_dim_1(obs_New Zealand_dim_1)int640 1 2
array([0, 1, 2])
- obs_United Kingdom_dim_0(obs_United Kingdom_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - obs_United Kingdom_dim_1(obs_United Kingdom_dim_1)int640 1 2
array([0, 1, 2])
- obs_Australia_dim_0(obs_Australia_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - obs_Australia_dim_1(obs_Australia_dim_1)int640 1 2
array([0, 1, 2])
- obs_Ireland(chain, draw, obs_Ireland_dim_0, obs_Ireland_dim_1)float641.442 1.214 ... -1.998 -0.2268
array([[[[ 1.44216392, 1.21433603, -0.24620373], [-0.29216679, -2.39120885, -0.22496641], [-1.20296202, -2.54566872, -0.22978156], ..., [ 5.4151822 , -0.20693587, 0.24666736], [ 1.72677909, 0.93029297, -0.45735838], [-1.82894206, -2.75633625, -0.14823089]], [[ 1.86050196, 0.3829668 , -1.76367683], [ 1.34522644, 0.89586816, -1.46318557], [-1.83455167, -1.14518294, 1.74751655], ..., [ 0.67964042, -2.60436758, 0.47356766], [-0.30570083, 1.05962613, -0.32873821], [-0.41864025, -0.98748916, 0.65666947]], [[ 0.09244337, -0.96028434, -0.05410173], [ 0.3888446 , -1.45914636, 0.65642348], [ 0.35328146, 0.57956438, 0.48289132], ..., ... ..., [-0.65047194, 0.20260695, 0.48688026], [ 1.06195943, 0.93297824, 0.58146274], [-1.04956009, 0.17975547, -0.87755078]], [[-0.05558822, 0.64847547, 0.87191278], [ 1.53149986, -0.87046858, 1.462854 ], [-0.78521177, 0.36727654, 0.30958242], ..., [ 1.36300562, 0.33760491, 0.85538822], [ 2.0075936 , -0.53134895, -0.10552448], [ 1.06922899, -0.772015 , -0.22834952]], [[ 1.22562894, 1.1954118 , -1.77726454], [ 1.32047634, 0.26520605, -0.18302668], [ 2.92656349, 3.24812927, 0.34441356], ..., [ 2.83626309, 2.9921436 , -0.40669417], [-0.61613114, -0.41848802, -1.38183079], [-2.20019105, -1.99845853, -0.22684925]]]]) - obs_South Africa(chain, draw, obs_South Africa_dim_0, obs_South Africa_dim_1)float64-1.08 -1.475 ... -3.026 -0.4278
array([[[[-1.08042815, -1.47486374, -0.18998885], [-2.22090256, -0.52845789, 0.14413059], [ 0.18061971, 0.13006436, -0.25252454], ..., [ 0.83959636, -0.62210856, -0.34175715], [-0.18503247, 1.01256311, 0.01452391], [-0.94098186, 0.48988045, -0.19091588]], [[-0.96874486, 0.67375781, 1.19963497], [-1.68355957, 0.8223419 , 0.86117177], [ 3.29639347, -1.39216596, -2.36671704], ..., [-1.1907885 , -1.08244153, 0.53956029], [ 1.02026952, -0.45850167, 0.26503035], [-0.57281338, 0.41690366, -0.31898268]], [[ 0.90392978, 0.12189939, -0.89010113], [ 0.23838208, -0.07178184, 0.31858745], [ 0.65777894, 0.94456795, 0.6605204 ], ..., ... ..., [ 1.20299772, 0.63924542, 0.76281646], [ 1.14701949, 0.01895048, -1.16792918], [ 1.07097969, -0.10581595, -0.92965169]], [[ 0.404994 , 0.17072219, -0.25864754], [ 0.91183848, 1.87827984, 0.2626324 ], [-0.62801688, -0.96702257, -0.17971642], ..., [-0.61541632, -0.38355841, -0.73965677], [-0.37693426, 1.51279364, 0.51928169], [-0.76537358, -0.98890974, 0.02919827]], [[ 1.06355078, 1.35670492, -0.43499497], [-0.49787069, -0.89534819, -0.59284817], [-0.39022683, -0.01694431, -1.06289771], ..., [-0.3023473 , -0.23479384, -0.74991632], [ 2.45133219, 3.44020825, -0.8500616 ], [-2.67742504, -3.0255616 , -0.42784937]]]]) - obs_United States(chain, draw, obs_United States_dim_0, obs_United States_dim_1)float642.089 -2.226 ... -2.025 -0.3652
array([[[[ 2.08853197, -2.22588785, -0.58962537], [-0.10969838, 1.34801774, -0.52620355], [-0.90904737, 0.38794311, -0.01206754], ..., [ 1.24994634, 0.70346244, 0.28820293], [ 0.18712305, -2.0775857 , -0.26144148], [ 0.36701772, 0.42406919, -0.20399696]], [[ 0.43927676, 0.05106411, -0.39859406], [-0.12982463, 1.12329005, 0.0893416 ], [ 0.0298152 , 1.28654773, -0.27773953], ..., [-0.71448065, -0.1567184 , 0.606019 ], [-0.99729536, 3.2019223 , -0.25898444], [ 0.05618898, -0.29531048, 0.24716793]], [[ 0.1088473 , 0.46556288, 2.20590056], [-1.93142753, 0.38205921, 2.50283913], [-0.48950337, -1.06061476, -0.06973738], ..., ... ..., [ 0.50105365, -0.16590621, -4.01649351], [ 0.24845363, 0.05301149, 1.30080469], [-0.35403633, 0.26474948, 0.19587305]], [[ 0.36636661, -0.48933288, 0.5562534 ], [ 0.83096629, 0.4422902 , 0.53408087], [ 1.32701595, -2.33520178, 0.33690979], ..., [-0.01116044, 0.19162144, 0.43105356], [ 1.07767062, -1.90503447, -0.1494513 ], [ 2.16704744, -1.31648337, -0.04139058]], [[-0.56202632, -0.43752455, -0.27313303], [-2.48768493, -3.07775194, -0.65138619], [-0.81996858, -0.76701832, 0.25229919], ..., [-0.05610424, 0.1457594 , -1.22410613], [-4.3172488 , -4.36695607, -1.04569734], [-2.24153764, -2.02481296, -0.36521949]]]]) - obs_Chile(chain, draw, obs_Chile_dim_0, obs_Chile_dim_1)float64-0.2398 -0.555 ... -0.5953 -0.1403
array([[[[-0.23983271, -0.55496307, -0.32546261], [ 2.65740345, 0.27049439, 1.4947758 ], [-0.46034862, 0.47972309, -0.18367752], ..., [-0.95509841, -0.14319467, -0.2346776 ], [-0.7353475 , -0.56112571, -0.17695423], [ 0.69757888, -0.2706058 , -0.09177315]], [[ 1.50715309, 0.45717434, -1.48379218], [-0.7717147 , 2.7121891 , 0.07460517], [ 0.7450025 , 0.69279186, -0.68221752], ..., [-1.88908705, 1.36096753, 0.98561717], [-0.05317145, 1.00672431, -0.2189253 ], [ 1.88091604, -0.35806087, -1.30143482]], [[ 5.38281052, -0.60435078, 3.84112732], [ 1.38303577, 0.41621645, 1.08785577], [ 0.64042152, -0.11685234, -1.46692512], ..., ... ..., [-0.01658554, 1.45378278, -0.12856442], [ 0.20198539, 2.90396268, 0.25314398], [-0.22151684, -1.1588733 , 0.40549707]], [[ 0.94490597, 1.7444274 , 0.92247364], [ 0.26286682, -0.84164471, 0.52252032], [-0.47989137, 2.09021485, 1.27009669], ..., [ 0.7860727 , 0.30765822, -1.3157127 ], [-0.46221212, 1.88805901, -0.97950823], [-0.32482327, 0.27650055, 1.32142354]], [[-1.90786146, -2.28417557, -0.5581007 ], [-0.64835244, -1.90706006, 0.14107129], [ 2.35462028, 1.47455725, 0.37631502], ..., [-0.16268285, 1.58034517, -1.64781457], [-1.79508319, -2.65565003, 0.42062359], [-1.14180525, -0.59525268, -0.14033109]]]]) - obs_Canada(chain, draw, obs_Canada_dim_0, obs_Canada_dim_1)float642.987 -1.596 ... 0.9749 0.4238
array([[[[ 2.98660411, -1.59648976, 0.02776848], [ 2.30760763, -0.90014747, -1.37311418], [-1.34691522, -0.51156209, -0.91005974], ..., [-0.26104631, 0.4777054 , -0.13301976], [ 1.97676618, -0.15473958, 1.36435682], [ 1.33046223, -0.17425685, 0.6712027 ]], [[-0.80795108, -0.64994571, 0.99029705], [ 0.53232811, 0.07427657, -0.42027595], [-0.67383398, 0.72604355, 0.50428044], ..., [-0.56489111, 2.43644893, -0.04659438], [ 0.22243535, -2.58961294, 0.81879761], [-1.17388754, 0.70958432, 1.00067421]], [[ 0.32959532, -0.56568257, -0.41270325], [ 0.33805488, 1.55197966, 0.38555987], [ 0.40486586, -1.44468415, 1.79171157], ..., ... ..., [ 0.45944104, -0.12098934, -1.62095287], [-0.30234169, 0.91677438, -0.77668383], [ 0.40048151, 1.21934097, 0.1267496 ]], [[ 0.47931881, -0.64326409, 2.6489885 ], [ 0.67076413, -0.62735388, 0.33671592], [ 4.16374303, -0.48509279, 1.87181408], ..., [ 1.92751611, -1.02713286, 0.51161177], [ 2.24039588, 2.5608276 , 3.3617624 ], [ 4.46036862, -1.56867684, 1.78854956]], [[-0.74379176, -0.13221482, -0.97135126], [-1.12372226, -1.04658563, -1.19400086], [ 1.68300538, 1.53496957, -0.64640167], ..., [-2.2878875 , -1.25458378, -1.04748576], [ 2.32948378, 1.53639997, -1.66119426], [ 1.2399767 , 0.97493392, 0.42379137]]]]) - obs_New Zealand(chain, draw, obs_New Zealand_dim_0, obs_New Zealand_dim_1)float641.055 -0.1359 ... -1.389 0.5238
array([[[[ 1.05523252, -0.13593232, 0.34285394], [ 1.10724659, -0.22494669, 0.38763203], [ 1.10306878, 0.13183832, 0.28809004], ..., [ 0.63228329, -0.14917731, -0.86728425], [ 1.48214696, -0.106533 , -0.01250324], [-0.19633409, 0.06782761, -0.72674219]], [[-1.45176185, 0.86840139, 0.85946383], [-0.93452266, 0.80516561, 0.48220917], [-2.45383128, 2.5491863 , 1.10627156], ..., [ 0.11443249, -1.17622893, 0.36837752], [-3.3279085 , 1.93894 , 2.30954749], [-1.6718716 , 0.49667556, 1.25951951]], [[ 0.04847526, -2.17173998, -0.59243999], [ 1.02471664, -1.73180326, 1.5968373 ], [-0.34959728, 1.94235375, -1.03645308], ..., ... ..., [ 0.31642202, 0.53061372, 0.75828846], [-0.01783574, -0.1485634 , -0.3748505 ], [ 0.26475625, 0.49328303, -0.63879072]], [[ 0.41255484, 0.33032059, -0.60283073], [-1.94941087, -0.87270202, -1.20654958], [-2.46339777, 0.22859426, -1.38589276], ..., [ 0.63739327, 0.26510252, 1.22511094], [-1.152238 , 0.57430785, 1.73773102], [ 1.85377782, -0.57949193, 1.67061952]], [[ 0.56362365, 0.29930631, -1.52660782], [-2.37537378, -3.19383251, 2.00526821], [-0.10600629, 0.73408653, -0.23659082], ..., [ 2.07984589, 2.2624388 , 0.99146509], [-1.87705982, -2.67770578, -1.0458133 ], [-1.31605037, -1.38868301, 0.52380847]]]]) - obs_United Kingdom(chain, draw, obs_United Kingdom_dim_0, obs_United Kingdom_dim_1)float641.107 -2.117 ... -0.7776 -0.8262
array([[[[ 1.10738845, -2.11722522, -0.35746766], [ 1.55223399, 2.62762349, -0.16935803], [-0.44632279, -2.35956383, -0.01947456], ..., [ 0.18994703, 1.66294906, -0.25094526], [ 0.3716922 , -0.3117239 , -0.02782261], [ 0.7887149 , -0.66596306, -0.2303511 ]], [[-0.71891412, -1.46268714, 1.23698941], [-0.93229571, 1.22427462, 0.0601163 ], [ 0.56910366, 0.48965776, -0.67313399], ..., [-1.29604265, 2.8609556 , 1.05316722], [ 0.03062841, 1.7680467 , -0.27597323], [ 1.88690148, -1.52340342, -0.49127921]], [[ 0.31584015, -0.12397509, 0.75474332], [-0.24685663, 0.13060596, 0.3601289 ], [ 0.13992027, -0.03836627, 0.45646398], ..., ... ..., [ 0.57405796, 0.09665485, 0.03985287], [-2.51254281, 0.67780332, 0.27077475], [ 1.33433029, -0.04570146, 0.17439368]], [[ 0.09309161, 0.55771717, 0.57979781], [ 3.18335899, -0.35302318, -0.73893789], [-1.1142341 , 0.17748681, 0.63689114], ..., [-0.45750183, 0.28319619, 0.53701605], [ 0.26386199, 0.26702223, -0.1595756 ], [ 0.52050313, 0.33525292, -0.75879134]], [[-3.57813703, -2.23288716, -2.70898962], [ 2.17291994, 1.40198545, 0.85217644], [-3.28761705, -2.31308783, 0.59479336], ..., [ 0.35926463, -0.04177487, -2.39238352], [ 2.68620149, 2.01590833, -0.99310651], [-2.05764241, -0.7776359 , -0.82616616]]]]) - obs_Australia(chain, draw, obs_Australia_dim_0, obs_Australia_dim_1)float64-5.604 -0.2084 ... -0.9151 -0.07599
array([[[[-5.60393572e+00, -2.08367889e-01, -5.34531446e-01], [-1.50689758e+00, -5.77504918e-01, -6.70400497e-01], [ 1.59242235e+00, 1.12682024e-02, 1.84156820e-01], ..., [ 1.14049351e+00, -2.20449941e-01, -3.63655669e-01], [ 7.36214659e-01, 1.17890333e-01, 3.28919007e-01], [-1.61922809e+00, 3.29915836e-01, 1.44851794e-01]], [[ 2.63927117e+00, -1.53513527e+00, -1.09620961e-01], [ 3.58209032e-01, 4.64295322e-02, 2.47855405e-01], [-2.20697192e+00, 1.55617999e-01, 9.23830722e-01], ..., [-9.26518306e-01, 2.72831592e+00, -9.81586410e-01], [ 1.48436501e+00, 8.39778239e-01, -1.10045548e+00], [-1.75706361e-01, 1.67216355e+00, -8.29995090e-02]], [[ 3.90776771e-01, 8.08349220e-01, 9.65900633e-02], [ 3.36658728e-01, 3.14831015e-01, -1.62908539e-01], [ 2.36358106e-01, 1.33925410e+00, -8.62401016e-02], ..., ... ..., [-3.48177967e-01, 7.69201252e-02, -4.36393500e-01], [ 2.40615919e-01, -1.39237716e-01, 2.23500298e-01], [ 4.94323748e-01, 4.57505097e-02, -3.20458296e-06]], [[-2.48806518e+00, 9.12924257e-01, 1.32764793e-01], [-1.64769461e+00, 6.10682508e-02, -1.13931263e+00], [-1.16813627e+00, 8.23503325e-02, -2.64580168e+00], ..., [ 5.11267528e-01, 2.39102062e-01, 6.47469253e-01], [ 2.90856041e+00, -2.22564814e-01, 1.33412563e+00], [-3.85778035e-01, 2.87312627e-01, -3.41999226e-01]], [[ 9.37939769e-01, 1.02722270e+00, 1.58903612e-01], [ 1.92159493e-01, -1.33098265e-01, -4.73658285e-01], [-3.85149807e+00, -2.39606350e+00, -7.20505580e-01], ..., [-2.54402056e-01, -4.37774476e-01, 8.59884653e-01], [-1.53794252e+00, -9.67771004e-01, 4.47421046e-01], [ 3.87364370e-01, -9.15064981e-01, -7.59942798e-02]]]])
- chainPandasIndex
PandasIndex(Int64Index([0], dtype='int64', name='chain'))
- drawPandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ... 490, 491, 492, 493, 494, 495, 496, 497, 498, 499], dtype='int64', name='draw', length=500)) - obs_Ireland_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='obs_Ireland_dim_0')) - obs_Ireland_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_Ireland_dim_1'))
- obs_South Africa_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='obs_South Africa_dim_0')) - obs_South Africa_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_South Africa_dim_1'))
- obs_United States_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45], dtype='int64', name='obs_United States_dim_0')) - obs_United States_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_United States_dim_1'))
- obs_Chile_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='obs_Chile_dim_0')) - obs_Chile_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_Chile_dim_1'))
- obs_Canada_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21], dtype='int64', name='obs_Canada_dim_0')) - obs_Canada_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_Canada_dim_1'))
- obs_New Zealand_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40], dtype='int64', name='obs_New Zealand_dim_0')) - obs_New Zealand_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_New Zealand_dim_1'))
- obs_United Kingdom_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='obs_United Kingdom_dim_0')) - obs_United Kingdom_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_United Kingdom_dim_1'))
- obs_Australia_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='obs_Australia_dim_0')) - obs_Australia_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_Australia_dim_1'))
- created_at
- 2023-02-21T19:22:35.399482
- arviz_version
- 0.14.0
- inference_library
- pymc
- inference_library_version
- 5.0.1
<xarray.Dataset> Dimensions: (chain: 1, draw: 500, obs_Ireland_dim_0: 49, obs_Ireland_dim_1: 3, obs_South Africa_dim_0: 49, obs_South Africa_dim_1: 3, obs_United States_dim_0: 46, obs_United States_dim_1: 3, obs_Chile_dim_0: 49, obs_Chile_dim_1: 3, obs_Canada_dim_0: 22, obs_Canada_dim_1: 3, obs_New Zealand_dim_0: 41, obs_New Zealand_dim_1: 3, obs_United Kingdom_dim_0: 49, obs_United Kingdom_dim_1: 3, obs_Australia_dim_0: 49, obs_Australia_dim_1: 3) Coordinates: (12/18) * chain (chain) int64 0 * draw (draw) int64 0 1 2 3 4 5 ... 495 496 497 498 499 * obs_Ireland_dim_0 (obs_Ireland_dim_0) int64 0 1 2 3 ... 45 46 47 48 * obs_Ireland_dim_1 (obs_Ireland_dim_1) int64 0 1 2 * obs_South Africa_dim_0 (obs_South Africa_dim_0) int64 0 1 2 ... 46 47 48 * obs_South Africa_dim_1 (obs_South Africa_dim_1) int64 0 1 2 ... ... * obs_New Zealand_dim_0 (obs_New Zealand_dim_0) int64 0 1 2 3 ... 38 39 40 * obs_New Zealand_dim_1 (obs_New Zealand_dim_1) int64 0 1 2 * obs_United Kingdom_dim_0 (obs_United Kingdom_dim_0) int64 0 1 2 ... 47 48 * obs_United Kingdom_dim_1 (obs_United Kingdom_dim_1) int64 0 1 2 * obs_Australia_dim_0 (obs_Australia_dim_0) int64 0 1 2 3 ... 46 47 48 * obs_Australia_dim_1 (obs_Australia_dim_1) int64 0 1 2 Data variables: obs_Ireland (chain, draw, obs_Ireland_dim_0, obs_Ireland_dim_1) float64 ... obs_South Africa (chain, draw, obs_South Africa_dim_0, obs_South Africa_dim_1) float64 ... obs_United States (chain, draw, obs_United States_dim_0, obs_United States_dim_1) float64 ... obs_Chile (chain, draw, obs_Chile_dim_0, obs_Chile_dim_1) float64 ... obs_Canada (chain, draw, obs_Canada_dim_0, obs_Canada_dim_1) float64 ... obs_New Zealand (chain, draw, obs_New Zealand_dim_0, obs_New Zealand_dim_1) float64 ... obs_United Kingdom (chain, draw, obs_United Kingdom_dim_0, obs_United Kingdom_dim_1) float64 ... obs_Australia (chain, draw, obs_Australia_dim_0, obs_Australia_dim_1) float64 ... Attributes: created_at: 2023-02-21T19:22:35.399482 arviz_version: 0.14.0 inference_library: pymc inference_library_version: 5.0.1xarray.Dataset -
- obs_Australia_dim_0: 49
- obs_Australia_dim_1: 3
- obs_Canada_dim_0: 22
- obs_Canada_dim_1: 3
- obs_Chile_dim_0: 49
- obs_Chile_dim_1: 3
- obs_Ireland_dim_0: 49
- obs_Ireland_dim_1: 3
- obs_New Zealand_dim_0: 41
- obs_New Zealand_dim_1: 3
- obs_South Africa_dim_0: 49
- obs_South Africa_dim_1: 3
- obs_United Kingdom_dim_0: 49
- obs_United Kingdom_dim_1: 3
- obs_United States_dim_0: 46
- obs_United States_dim_1: 3
- obs_Australia_dim_0(obs_Australia_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - obs_Australia_dim_1(obs_Australia_dim_1)int640 1 2
array([0, 1, 2])
- obs_Canada_dim_0(obs_Canada_dim_0)int640 1 2 3 4 5 6 ... 16 17 18 19 20 21
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21]) - obs_Canada_dim_1(obs_Canada_dim_1)int640 1 2
array([0, 1, 2])
- obs_Chile_dim_0(obs_Chile_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - obs_Chile_dim_1(obs_Chile_dim_1)int640 1 2
array([0, 1, 2])
- obs_Ireland_dim_0(obs_Ireland_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - obs_Ireland_dim_1(obs_Ireland_dim_1)int640 1 2
array([0, 1, 2])
- obs_New Zealand_dim_0(obs_New Zealand_dim_0)int640 1 2 3 4 5 6 ... 35 36 37 38 39 40
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40]) - obs_New Zealand_dim_1(obs_New Zealand_dim_1)int640 1 2
array([0, 1, 2])
- obs_South Africa_dim_0(obs_South Africa_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - obs_South Africa_dim_1(obs_South Africa_dim_1)int640 1 2
array([0, 1, 2])
- obs_United Kingdom_dim_0(obs_United Kingdom_dim_0)int640 1 2 3 4 5 6 ... 43 44 45 46 47 48
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48]) - obs_United Kingdom_dim_1(obs_United Kingdom_dim_1)int640 1 2
array([0, 1, 2])
- obs_United States_dim_0(obs_United States_dim_0)int640 1 2 3 4 5 6 ... 40 41 42 43 44 45
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45]) - obs_United States_dim_1(obs_United States_dim_1)int640 1 2
array([0, 1, 2])
- obs_Australia(obs_Australia_dim_0, obs_Australia_dim_1)float640.02585 0.04286 ... 0.02312 0.02713
array([[ 2.58547961e-02, 4.28564292e-02, 3.01291574e-02], [ 4.02342322e-02, 5.34089284e-02, 4.17959536e-02], [ 1.32680519e-02, 5.55138348e-02, -6.62524913e-02], [ 2.55832078e-02, 2.47380310e-02, 3.37743618e-02], [ 3.52982455e-02, 4.08175306e-02, 3.81639772e-02], [ 8.90130652e-03, 2.17807603e-02, 3.76296913e-02], [ 3.97088688e-02, 1.91113918e-02, 9.32662671e-02], [ 2.99024255e-02, 1.88280936e-02, 2.83222198e-02], [ 3.28427956e-02, 3.49877208e-02, 1.20346340e-01], [ 3.26885389e-02, 4.47891940e-02, 7.00031593e-02], [-2.24702705e-02, 2.40914115e-02, -9.94876459e-02], [ 4.49343999e-02, 1.93523407e-02, 4.95572988e-02], [ 5.11883837e-02, 2.38045459e-02, 9.17559621e-02], [ 3.95184383e-02, 4.42945925e-02, 5.76147242e-02], [ 2.51601327e-02, 2.32608503e-02, 3.85592131e-03], [ 5.58478462e-02, 3.26020154e-02, 7.22331578e-02], [ 3.79164057e-02, 4.11176562e-02, 1.01848719e-01], [ 3.51113862e-02, 3.83006373e-02, 9.02173419e-03], [-3.95869708e-03, 1.50128092e-02, -9.95998900e-02], [ 4.12926667e-03, 2.35802217e-02, -4.07912299e-02], ... [ 3.93603828e-02, 3.05145425e-02, 8.73148213e-02], [ 3.06293466e-02, 3.86425685e-02, 1.18382423e-01], [ 4.11942154e-02, 4.96800641e-02, 8.37471749e-02], [ 3.11142746e-02, 4.10141391e-02, 5.91564733e-02], [ 2.69037608e-02, 3.16772386e-02, 7.94902106e-02], [ 3.69921502e-02, 4.62949959e-02, 4.42069118e-02], [ 3.51452551e-02, 4.28133874e-02, 8.39925571e-02], [ 1.84962064e-02, 1.19790989e-02, 1.51249834e-02], [ 2.14907809e-02, 2.91778938e-02, 1.73281695e-02], [ 2.43974109e-02, 3.82530099e-02, 3.53663916e-02], [ 3.84258056e-02, 3.06389144e-02, 1.09774809e-01], [ 2.56698119e-02, 1.53975077e-02, 2.85034459e-02], [ 2.53063902e-02, 2.03530897e-02, -1.90696114e-02], [ 2.14894856e-02, 2.45858631e-02, -3.76203585e-02], [ 2.70473314e-02, 3.06920086e-02, -3.71083141e-02], [ 2.26996714e-02, 2.99812162e-02, -3.91306699e-04], [ 2.83053226e-02, 2.86940855e-02, 4.72726441e-02], [ 2.09113206e-02, 2.40001483e-02, -1.28781610e-02], [-3.83663216e-05, -4.17408601e-03, -2.50317561e-02], [ 1.46438819e-02, 2.31248682e-02, 2.71311126e-02]]) - obs_Canada(obs_Canada_dim_0, obs_Canada_dim_1)float640.04801 0.03828 ... 0.04888 0.06909
array([[ 0.04800665, 0.0382813 , 0.04941686], [ 0.01395742, 0.02626848, 0.04706986], [ 0.03364893, 0.03478331, 0.00991683], [ 0.03740262, 0.02741445, 0.05085894], [ 0.03839372, 0.02711028, 0.08098272], [ 0.04875074, 0.03124278, 0.08731537], [ 0.04081384, 0.03747819, 0.06090471], [ 0.06642994, 0.03802772, 0.03118513], [ 0.0100258 , 0.03149776, 0.0161345 ], [-0.02972134, 0.00777432, -0.12006804], [ 0.0304273 , 0.03166653, 0.10895903], [ 0.03098382, 0.01992693, 0.04532905], [ 0.01746875, 0.01554452, 0.04770492], [ 0.02302412, 0.01671947, 0.01438519], [ 0.02829622, 0.02010709, 0.02225279], [ 0.00657014, 0.02045177, -0.05350516], [ 0.00996414, 0.01997434, -0.04765361], [ 0.02994591, 0.03212583, 0.03291847], [ 0.0273918 , 0.02606687, 0.01802123], [ 0.01862146, 0.01724382, 0.00255267], [-0.0537492 , -0.04666877, -0.02469412], [ 0.04461856, 0.04887529, 0.06908599]]) - obs_Chile(obs_Chile_dim_0, obs_Chile_dim_1)float64-0.0516 -0.05632 ... 0.1669 0.162
array([[-0.05160122, -0.05632364, -0.06215139], [ 0.02354219, -0.15455255, 0.17491378], [-0.13825224, -0.11897169, -0.25839899], [ 0.03760965, 0.0018707 , -0.16035492], [ 0.09934463, 0.12915606, 0.14364864], [ 0.07418965, 0.07139739, 0.16021225], [ 0.08082675, 0.06701527, 0.15572056], [ 0.07683715, 0.04286705, 0.19806412], [ 0.06321299, 0.10368039, 0.15493248], [-0.11669456, -0.14008232, -0.48290291], [-0.05147669, -0.05200956, -0.16292912], [ 0.04021717, 0.00408348, 0.17264662], [ 0.03931606, -0.00438434, 0.09508209], [ 0.05238078, 0.04793333, 0.02389143], [ 0.06260354, 0.05494253, 0.19649118], [ 0.07087879, 0.06314511, 0.13236687], [ 0.09461342, 0.08821887, 0.26234943], [ 0.03279207, 0.0198484 , 0.02485722], [ 0.07514822, 0.07836482, -0.00177746], [ 0.10586076, 0.11977667, 0.21531643], ... [ 0.03152579, 0.02513677, 0.04334088], [ 0.04615093, 0.03353653, 0.08202795], [ 0.06460965, 0.07738999, 0.12455842], [ 0.05673042, 0.07012815, 0.20768463], [ 0.05874041, 0.06780596, 0.06252882], [ 0.05039108, 0.06323181, 0.1004948 ], [ 0.03719359, 0.02603368, 0.17122012], [-0.01124334, 0.01110709, -0.11718115], [ 0.05686841, 0.09495075, 0.10532089], [ 0.06037891, 0.07707863, 0.14033521], [ 0.05973331, 0.05686997, 0.11341797], [ 0.03254955, 0.04815577, 0.01312942], [ 0.01776771, 0.02642016, -0.04138332], [ 0.02129115, 0.02810647, 0.00106907], [ 0.0173785 , 0.03995643, -0.02388277], [ 0.01348561, 0.03692704, -0.03381831], [ 0.03912484, 0.03581437, 0.06290846], [ 0.00767586, 0.00689587, 0.04550277], [-0.06164377, -0.074563 , -0.09811202], [ 0.11036201, 0.16693706, 0.16198002]]) - obs_Ireland(obs_Ireland_dim_0, obs_Ireland_dim_1)float640.04613 0.06834 ... 0.05461 -0.4713
array([[ 4.61335791e-02, 6.83401168e-02, 1.49827877e-01], [ 4.17197937e-02, 3.04159061e-02, -1.23475797e-01], [ 5.50244419e-02, 2.79099604e-02, -3.67648540e-02], [ 1.38516968e-02, 2.73181945e-02, 1.27133693e-01], [ 7.89156239e-02, 5.36218161e-02, 3.97563116e-02], [ 6.94022552e-02, 8.43370255e-02, 1.72927194e-01], [ 3.02676413e-02, 4.37312685e-02, 1.27614771e-01], [ 3.03286863e-02, 2.12696323e-02, -4.83238754e-02], [ 3.27112701e-02, 1.31993486e-02, 9.10272102e-02], [ 2.25778666e-02, -4.39091504e-02, -3.47189705e-02], [-2.44598876e-03, 4.98375959e-03, -9.74500134e-02], [ 4.26223474e-02, 1.22650316e-02, -2.54792846e-02], [ 3.03896656e-02, 3.74100113e-02, -8.02856927e-02], [-4.29250459e-03, 2.15774944e-02, -2.83320698e-02], [ 4.55763509e-02, 1.05522680e-02, -1.14438996e-02], [ 5.08586344e-02, 1.99640927e-02, 5.10270372e-02], [ 5.65118802e-02, 4.52213918e-02, 9.65358392e-02], [ 8.12714443e-02, 2.30526508e-02, 1.25768983e-01], [ 1.91125787e-02, 1.99200071e-02, -7.23979883e-02], [ 3.28860205e-02, 2.86514636e-02, -2.66017423e-04], ... [ 5.72894826e-02, 4.32476634e-02, 5.40679052e-02], [ 2.96518496e-02, 2.80611431e-02, 7.67303647e-02], [ 6.56554548e-02, 3.20210217e-02, 9.31065883e-02], [ 5.57772353e-02, 6.12369062e-02, 1.55613972e-01], [ 4.86044518e-02, 5.79752697e-02, 6.96325136e-02], [ 5.16951629e-02, 6.43787433e-02, 3.09831703e-04], [-4.59036270e-02, 3.56558699e-03, -1.23095127e-01], [-5.23514448e-02, -4.74316447e-02, -1.85459413e-01], [ 1.73985707e-02, -1.16089566e-02, -1.62875961e-01], [ 1.06285825e-02, 2.62454869e-03, -1.38828831e-03], [-5.23684952e-04, -1.71380002e-02, 1.49189678e-01], [ 1.25905519e-02, -1.63944405e-03, -4.22632230e-02], [ 8.35476150e-02, 2.97670828e-02, 1.70091250e-01], [ 2.24552520e-01, 2.97041623e-02, 4.09453854e-01], [ 2.02165860e-02, 4.80931056e-02, 4.07069746e-01], [ 8.56272032e-02, 2.60816736e-02, -5.84910067e-03], [ 8.64543653e-02, 4.07380268e-02, -9.28996410e-02], [ 4.79994419e-02, 4.13795569e-02, 6.90712155e-01], [ 5.70131720e-02, -5.33555938e-02, -2.60193601e-01], [ 1.26444598e-01, 5.46082354e-02, -4.71301047e-01]]) - obs_New Zealand(obs_New Zealand_dim_0, obs_New Zealand_dim_1)float640.01276 0.0003994 ... -0.04888
array([[ 0.01275757, 0.00039945, 0.05562552], [ 0.04550785, 0.01973033, 0.16965206], [ 0.00925395, -0.00913711, 0.05374564], [ 0.03432179, 0.02948118, 0.09586059], [ 0.04681983, 0.03295578, 0.07206984], [ 0.01602514, 0.0141673 , 0.08313887], [ 0.02669465, 0.03190073, 0.00063869], [ 0.00965985, 0.02347439, 0.05223172], [-0.00354805, 0.02166055, -0.01767435], [ 0.00161108, 0.02154704, 0.04673256], [ 0.00152856, 0.0069469 , -0.03406895], [-0.01096479, -0.01994773, -0.16585547], [ 0.01088486, 0.00573841, 0.02677066], [ 0.06195639, 0.03040616, 0.15858095], [ 0.0499192 , 0.04561174, 0.14225122], [ 0.04614348, 0.04011437, 0.08992779], [ 0.03551665, 0.04009712, 0.04693239], [ 0.02029111, 0.02765009, 0.04662608], [ 0.00794279, 0.02562678, -0.06359527], [ 0.05307744, 0.02760857, 0.12767563], ... [ 0.0340567 , 0.03040034, 0.08290577], [ 0.04568639, 0.04065663, 0.07679202], [ 0.04449519, 0.05630502, 0.1349896 ], [ 0.03949282, 0.05023121, 0.07825136], [ 0.03266772, 0.05004526, 0.05561569], [ 0.0284034 , 0.03121604, -0.01671832], [ 0.02983217, 0.03945121, 0.07489517], [-0.01117747, 0.005312 , -0.07399979], [-0.00135262, 0.00921378, -0.10590376], [ 0.01512383, 0.02096096, 0.03688958], [ 0.02226781, 0.0277072 , 0.05837884], [ 0.02220467, 0.01657869, 0.05313663], [ 0.0265973 , 0.03295962, 0.09054234], [ 0.0374444 , 0.03158895, 0.07775609], [ 0.03675934, 0.0366383 , 0.03531498], [ 0.03698213, 0.05200807, 0.02186305], [ 0.03515745, 0.04454498, 0.06703786], [ 0.0330403 , 0.04194925, 0.05071202], [ 0.02168788, 0.03128527, 0.02580023], [-0.01260577, 0.02029054, -0.04887683]]) - obs_South Africa(obs_South Africa_dim_0, obs_South Africa_dim_1)float640.04471 0.06648 ... 0.04268 0.02013
array([[ 4.47051150e-02, 6.64754513e-02, 5.09040274e-02], [ 5.93166808e-02, 5.62608597e-02, 6.32529762e-02], [ 1.68122171e-02, 5.35913552e-02, 9.31032193e-02], [ 2.22492430e-02, 2.46847875e-02, -1.24324541e-02], [-9.40233042e-04, 2.68428795e-03, -6.14687390e-02], [ 2.96993727e-02, 1.38764596e-02, -2.81211227e-02], [ 3.72044440e-02, 3.00933311e-02, 4.08383585e-02], [ 6.41063974e-02, 8.36294473e-02, 1.57666347e-01], [ 5.22203796e-02, 5.76052512e-02, 8.57594849e-02], [-3.84156044e-03, 3.08210094e-02, -2.17288418e-02], [-1.86381945e-02, 2.66908702e-02, -3.60537389e-02], [ 4.97340198e-02, 5.01916489e-02, -1.50071858e-02], [-1.21893986e-02, -1.72244869e-02, -7.28525477e-02], [ 1.78476474e-04, 7.25430820e-03, -2.05487765e-01], [ 2.07896794e-02, 3.75301356e-02, -5.25230432e-02], [ 4.11429956e-02, 4.23097973e-02, 1.18525664e-01], [ 2.36656964e-02, 3.03063946e-02, 6.30169602e-02], [-3.18266357e-03, 2.67459923e-02, -2.36844273e-02], [-1.02346454e-02, 2.19137613e-03, -7.67546375e-02], [-2.16019802e-02, -5.34858092e-03, -5.40315019e-02], ... [ 3.63355397e-02, 3.43620535e-02, 3.43300225e-02], [ 2.90642670e-02, 3.43103698e-02, 9.74625263e-02], [ 4.45388535e-02, 5.82814840e-02, 1.21128375e-01], [ 5.14252794e-02, 4.81903464e-02, 1.04213487e-01], [ 5.45242306e-02, 7.35687362e-02, 1.14619392e-01], [ 5.22173708e-02, 6.24956095e-02, 1.28909455e-01], [ 3.14118792e-02, 2.59384473e-02, 1.20645751e-01], [-1.55004043e-02, -1.60128132e-02, -6.91009142e-02], [ 2.99444840e-02, 4.17842195e-02, -3.99083704e-02], [ 3.11939334e-02, 3.98013850e-02, 6.61950516e-02], [ 2.36797328e-02, 3.51947516e-02, 1.74217409e-02], [ 2.45508270e-02, 1.90371107e-02, 5.21926438e-02], [ 1.40392514e-02, 9.96208252e-03, -1.32604270e-02], [ 1.31320187e-02, 1.41410543e-02, 1.34055579e-02], [ 6.62353893e-03, 9.84260750e-03, -1.95087200e-02], [ 1.15129405e-02, 1.24423566e-02, -2.05408909e-02], [ 1.47666087e-02, 2.05234972e-02, -1.78043515e-02], [ 1.12989839e-03, 1.42409638e-02, -2.44166814e-02], [-6.64814723e-02, -4.82250860e-02, -1.61237297e-01], [ 4.79765253e-02, 4.26787540e-02, 2.01288685e-02]]) - obs_United Kingdom(obs_United Kingdom_dim_0, obs_United Kingdom_dim_1)float640.0632 0.04994 ... 0.07793 0.05719
array([[ 0.0631987 , 0.04994497, 0.06337169], [-0.02515786, -0.00812863, -0.01970066], [-0.01484616, 0.01383284, -0.01909747], [ 0.02868722, 0.00806818, 0.01712351], [ 0.02428034, -0.00627614, -0.01543497], [ 0.04118283, 0.04299063, 0.0248173 ], [ 0.03680449, 0.03551332, 0.02585783], [-0.02052284, 0.00363682, -0.04865774], [-0.00790863, 0.00178865, -0.0913653 ], [ 0.01975254, 0.00986482, 0.05837711], [ 0.04135167, 0.03471082, 0.04922731], [ 0.02243744, 0.0200251 , 0.08704313], [ 0.04063716, 0.0272396 , 0.04084613], [ 0.03101735, 0.05030823, 0.02170983], [ 0.05252355, 0.04003375, 0.0905554 ], [ 0.05574132, 0.05698841, 0.13841338], [ 0.02544943, 0.02841384, 0.05919042], [ 0.00731077, 0.01256388, -0.02235462], [-0.01109251, -0.00849372, -0.06537815], [ 0.0040028 , 0.01360378, 0.00895118], ... [ 0.02100996, 0.03285221, 0.02787326], [ 0.02984895, 0.03346377, 0.02706516], [ 0.02328313, 0.03152612, 0.02325109], [ 0.02560225, 0.02491369, 0.04169183], [ 0.02551281, 0.01679235, 0.0267212 ], [ 0.02244117, 0.01937612, 0.04536821], [-0.00239926, 0.00310638, -0.03581101], [-0.04340195, -0.01724746, -0.13593041], [ 0.02109041, 0.01300281, 0.03628414], [ 0.01447043, 0.00184942, 0.00570219], [ 0.01459189, 0.01615877, 0.01511258], [ 0.01872379, 0.01716657, 0.03228887], [ 0.02947302, 0.02440921, 0.06598913], [ 0.02588796, 0.03009682, 0.06147314], [ 0.02238227, 0.02906562, 0.04613987], [ 0.02111993, 0.01376355, 0.03244003], [ 0.01637446, 0.01897499, -0.00063386], [ 0.01658121, 0.01894308, 0.00545265], [-0.09728665, -0.09991479, -0.09989816], [ 0.07177422, 0.07792672, 0.05718545]]) - obs_United States(obs_United States_dim_0, obs_United States_dim_1)float64-0.002057 0.0228 ... -0.01562
array([[-0.00205667, 0.02279784, -0.07580306], [ 0.05247991, 0.0423446 , 0.07725835], [ 0.04520425, 0.0363257 , 0.09829596], [ 0.05387536, 0.03756695, 0.10123019], [ 0.03117056, 0.02023809, 0.05542428], [-0.0025708 , 0.00055427, -0.04387308], [ 0.02506054, 0.01420906, 0.01889814], [-0.01819337, 0.01631303, -0.05093106], [ 0.04481956, 0.04978586, 0.07007873], [ 0.06986773, 0.04381145, 0.139842 ], [ 0.04085069, 0.04976591, 0.06770261], [ 0.03404045, 0.04134896, 0.03097407], [ 0.03400765, 0.03055211, 0.01752661], [ 0.04092178, 0.03667373, 0.02285645], [ 0.03606814, 0.02904549, 0.02888397], [ 0.01868401, 0.02135529, -0.00104886], [-0.00108323, 0.00492023, -0.04193738], [ 0.03461822, 0.03016452, 0.04018221], [ 0.027146 , 0.02738892, 0.04969453], [ 0.03949753, 0.03169813, 0.05925663], ... [ 0.00949814, 0.02632002, -0.00424008], [ 0.01681722, 0.02737844, -0.01710235], [ 0.02757829, 0.02855487, 0.04149606], [ 0.03780194, 0.03301059, 0.05820109], [ 0.03423929, 0.0299518 , 0.058829 ], [ 0.02744794, 0.02555851, 0.02639172], [ 0.01990564, 0.02252906, -0.00580617], [ 0.00122114, 0.00574324, -0.04296584], [-0.02634283, -0.00251815, -0.1337838 ], [ 0.02672817, 0.01518253, 0.02207697], [ 0.01538007, 0.00758364, 0.0447487 ], [ 0.02255069, 0.00827521, 0.06644212], [ 0.01825118, 0.00854824, 0.03506226], [ 0.02261999, 0.02050827, 0.05006005], [ 0.02670395, 0.02934843, 0.03586364], [ 0.01653722, 0.02342548, 0.02105755], [ 0.02230616, 0.01988538, 0.03747989], [ 0.02877069, 0.02565042, 0.04277978], [ 0.02263068, 0.02139597, 0.03075832], [-0.03463896, -0.028277 , -0.01561854]])
- obs_Australia_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='obs_Australia_dim_0')) - obs_Australia_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_Australia_dim_1'))
- obs_Canada_dim_0PandasIndex
PandasIndex(Int64Index([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21], dtype='int64', name='obs_Canada_dim_0')) - obs_Canada_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_Canada_dim_1'))
- obs_Chile_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='obs_Chile_dim_0')) - obs_Chile_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_Chile_dim_1'))
- obs_Ireland_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='obs_Ireland_dim_0')) - obs_Ireland_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_Ireland_dim_1'))
- obs_New Zealand_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40], dtype='int64', name='obs_New Zealand_dim_0')) - obs_New Zealand_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_New Zealand_dim_1'))
- obs_South Africa_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='obs_South Africa_dim_0')) - obs_South Africa_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_South Africa_dim_1'))
- obs_United Kingdom_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48], dtype='int64', name='obs_United Kingdom_dim_0')) - obs_United Kingdom_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_United Kingdom_dim_1'))
- obs_United States_dim_0PandasIndex
PandasIndex(Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45], dtype='int64', name='obs_United States_dim_0')) - obs_United States_dim_1PandasIndex
PandasIndex(Int64Index([0, 1, 2], dtype='int64', name='obs_United States_dim_1'))
- created_at
- 2023-02-21T19:22:35.401625
- arviz_version
- 0.14.0
- inference_library
- pymc
- inference_library_version
- 5.0.1
<xarray.Dataset> Dimensions: (obs_Australia_dim_0: 49, obs_Australia_dim_1: 3, obs_Canada_dim_0: 22, obs_Canada_dim_1: 3, obs_Chile_dim_0: 49, obs_Chile_dim_1: 3, obs_Ireland_dim_0: 49, obs_Ireland_dim_1: 3, obs_New Zealand_dim_0: 41, obs_New Zealand_dim_1: 3, obs_South Africa_dim_0: 49, obs_South Africa_dim_1: 3, obs_United Kingdom_dim_0: 49, obs_United Kingdom_dim_1: 3, obs_United States_dim_0: 46, obs_United States_dim_1: 3) Coordinates: (12/16) * obs_Australia_dim_0 (obs_Australia_dim_0) int64 0 1 2 3 ... 46 47 48 * obs_Australia_dim_1 (obs_Australia_dim_1) int64 0 1 2 * obs_Canada_dim_0 (obs_Canada_dim_0) int64 0 1 2 3 4 ... 18 19 20 21 * obs_Canada_dim_1 (obs_Canada_dim_1) int64 0 1 2 * obs_Chile_dim_0 (obs_Chile_dim_0) int64 0 1 2 3 4 ... 45 46 47 48 * obs_Chile_dim_1 (obs_Chile_dim_1) int64 0 1 2 ... ... * obs_South Africa_dim_0 (obs_South Africa_dim_0) int64 0 1 2 ... 46 47 48 * obs_South Africa_dim_1 (obs_South Africa_dim_1) int64 0 1 2 * obs_United Kingdom_dim_0 (obs_United Kingdom_dim_0) int64 0 1 2 ... 47 48 * obs_United Kingdom_dim_1 (obs_United Kingdom_dim_1) int64 0 1 2 * obs_United States_dim_0 (obs_United States_dim_0) int64 0 1 2 ... 43 44 45 * obs_United States_dim_1 (obs_United States_dim_1) int64 0 1 2 Data variables: obs_Australia (obs_Australia_dim_0, obs_Australia_dim_1) float64 ... obs_Canada (obs_Canada_dim_0, obs_Canada_dim_1) float64 0.... obs_Chile (obs_Chile_dim_0, obs_Chile_dim_1) float64 -0.0... obs_Ireland (obs_Ireland_dim_0, obs_Ireland_dim_1) float64 ... obs_New Zealand (obs_New Zealand_dim_0, obs_New Zealand_dim_1) float64 ... obs_South Africa (obs_South Africa_dim_0, obs_South Africa_dim_1) float64 ... obs_United Kingdom (obs_United Kingdom_dim_0, obs_United Kingdom_dim_1) float64 ... obs_United States (obs_United States_dim_0, obs_United States_dim_1) float64 ... Attributes: created_at: 2023-02-21T19:22:35.401625 arviz_version: 0.14.0 inference_library: pymc inference_library_version: 5.0.1xarray.Dataset
az.plot_trace(
idata_full_test,
var_names=["rho", "alpha_hat_location", "beta_hat_location", "omega_global"],
kind="rank_vlines",
);
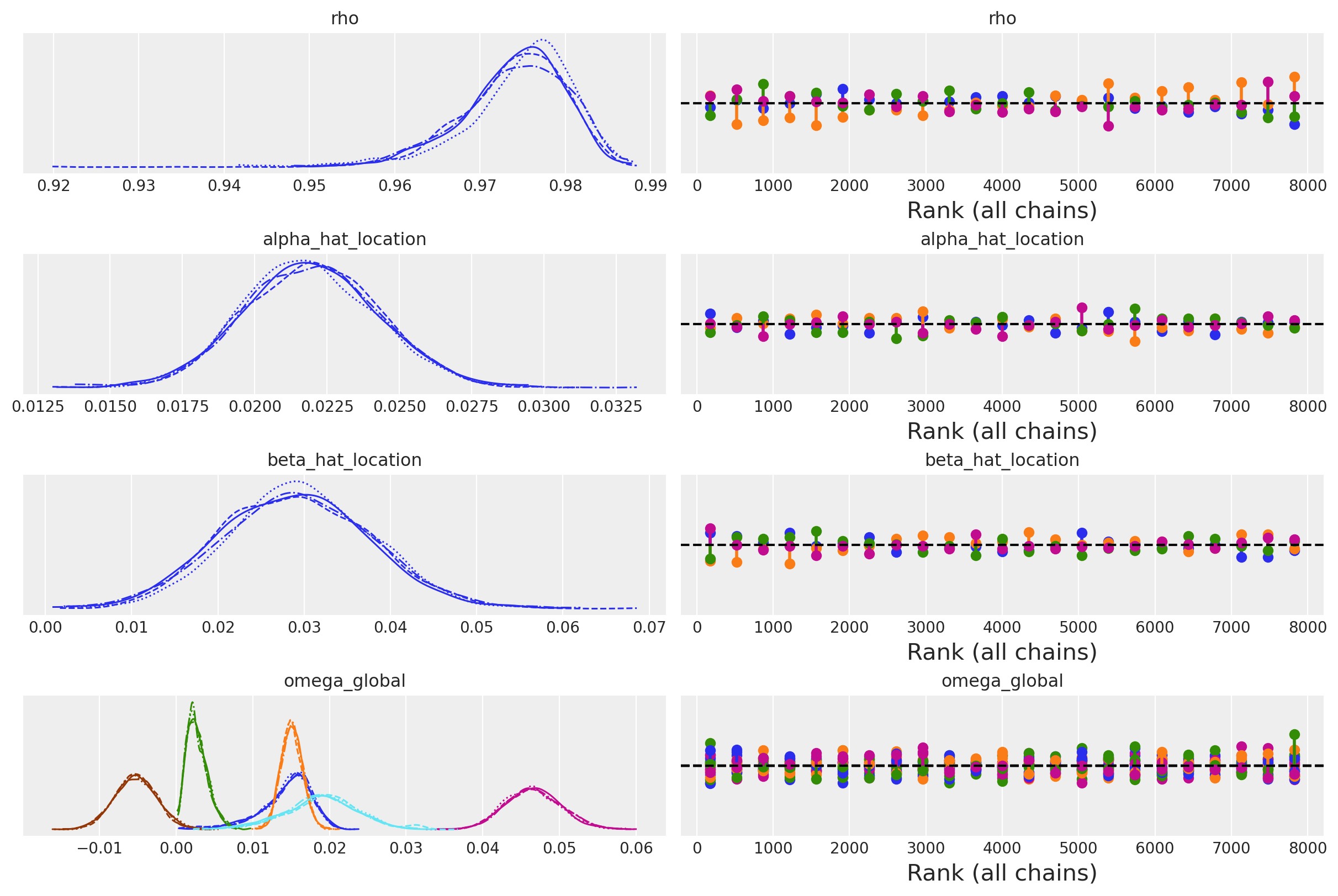
接下来我们将看看一些汇总统计量,以及它们在不同国家之间的变化情况。
az.summary(
idata_full_test,
var_names=[
"rho",
"alpha_hat_location",
"alpha_hat_scale",
"beta_hat_location",
"beta_hat_scale",
"z_scale_alpha_Ireland",
"z_scale_alpha_United States",
"z_scale_beta_Ireland",
"z_scale_beta_United States",
"alpha_Ireland",
"alpha_United States",
"omega_global_corr",
"lag_coefs_Ireland",
"lag_coefs_United States",
],
)
/Users/nathanielforde/mambaforge/envs/myjlabenv/lib/python3.11/site-packages/arviz/stats/diagnostics.py:584: RuntimeWarning: invalid value encountered in scalar divide
(between_chain_variance / within_chain_variance + num_samples - 1) / (num_samples)
| 均值 | 标准差 | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| rho | 0.974 | 0.006 | 0.962 | 0.984 | 0.000 | 0.000 | 749.0 | 1354.0 | 1.00 |
| alpha_hat_location | 0.022 | 0.002 | 0.018 | 0.026 | 0.000 | 0.000 | 1642.0 | 3651.0 | 1.00 |
| alpha_hat_scale | 0.047 | 0.012 | 0.027 | 0.069 | 0.000 | 0.000 | 2933.0 | 1097.0 | 1.00 |
| beta_hat_location | 0.029 | 0.009 | 0.014 | 0.046 | 0.000 | 0.000 | 855.0 | 2218.0 | 1.00 |
| beta_hat_scale | 0.186 | 0.064 | 0.077 | 0.305 | 0.003 | 0.002 | 312.0 | 647.0 | 1.01 |
| z_scale_alpha_Ireland | 0.264 | 0.147 | 0.070 | 0.508 | 0.002 | 0.002 | 2074.0 | 854.0 | 1.00 |
| z_scale_alpha_United States | 0.132 | 0.066 | 0.045 | 0.245 | 0.001 | 0.001 | 8457.0 | 5680.0 | 1.00 |
| z_scale_beta_Ireland | 0.508 | 0.326 | 0.096 | 1.067 | 0.014 | 0.010 | 592.0 | 1294.0 | 1.00 |
| z_scale_beta_United States | 0.213 | 0.125 | 0.050 | 0.445 | 0.005 | 0.003 | 646.0 | 1423.0 | 1.00 |
| alpha_Ireland[dl_gdp] | 0.035 | 0.008 | 0.020 | 0.048 | 0.000 | 0.000 | 3446.0 | 4001.0 | 1.00 |
| alpha_Ireland[dl_cons] | 0.014 | 0.006 | 0.003 | 0.024 | 0.000 | 0.000 | 1597.0 | 4464.0 | 1.00 |
| alpha_Ireland[dl_gfcf] | 0.024 | 0.011 | 0.002 | 0.046 | 0.000 | 0.000 | 6768.0 | 5217.0 | 1.00 |
| alpha_United States[dl_gdp] | 0.021 | 0.003 | 0.015 | 0.026 | 0.000 | 0.000 | 2322.0 | 3773.0 | 1.00 |
| alpha_United States[dl_cons] | 0.020 | 0.003 | 0.015 | 0.025 | 0.000 | 0.000 | 2164.0 | 3321.0 | 1.00 |
| alpha_United States[dl_gfcf] | 0.024 | 0.005 | 0.015 | 0.034 | 0.000 | 0.000 | 4455.0 | 5176.0 | 1.00 |
| omega_global_corr[0, 0] | 1.000 | 0.000 | 1.000 | 1.000 | 0.000 | 0.000 | 8000.0 | 8000.0 | NaN |
| omega_global_corr[0, 1] | 0.980 | 0.019 | 0.944 | 1.000 | 0.000 | 0.000 | 2393.0 | 2273.0 | 1.00 |
| omega_global_corr[0, 2] | 0.916 | 0.033 | 0.854 | 0.977 | 0.001 | 0.001 | 915.0 | 763.0 | 1.00 |
| omega_global_corr[1, 0] | 0.980 | 0.019 | 0.944 | 1.000 | 0.000 | 0.000 | 2393.0 | 2273.0 | 1.00 |
| omega_global_corr[1, 1] | 1.000 | 0.000 | 1.000 | 1.000 | 0.000 | 0.000 | 7937.0 | 7898.0 | 1.00 |
| omega_global_corr[1, 2] | 0.879 | 0.045 | 0.794 | 0.960 | 0.001 | 0.001 | 1345.0 | 3018.0 | 1.00 |
| omega_global_corr[2, 0] | 0.916 | 0.033 | 0.854 | 0.977 | 0.001 | 0.001 | 915.0 | 763.0 | 1.00 |
| omega_global_corr[2, 1] | 0.879 | 0.045 | 0.794 | 0.960 | 0.001 | 0.001 | 1345.0 | 3018.0 | 1.00 |
| omega_global_corr[2, 2] | 1.000 | 0.000 | 1.000 | 1.000 | 0.000 | 0.000 | 8042.0 | 7890.0 | 1.00 |
| lag_coefs_Ireland[dl_gdp, 1, dl_gdp] | 0.012 | 0.080 | -0.151 | 0.160 | 0.001 | 0.001 | 5559.0 | 3646.0 | 1.00 |
| lag_coefs_Ireland[dl_gdp, 1, dl_cons] | 0.007 | 0.086 | -0.161 | 0.174 | 0.001 | 0.002 | 4661.0 | 3294.0 | 1.00 |
| lag_coefs_Ireland[dl_gdp, 1, dl_gfcf] | 0.057 | 0.037 | -0.009 | 0.128 | 0.001 | 0.000 | 4699.0 | 4249.0 | 1.00 |
| lag_coefs_Ireland[dl_gdp, 2, dl_gdp] | -0.005 | 0.087 | -0.176 | 0.152 | 0.002 | 0.002 | 3099.0 | 2447.0 | 1.00 |
| lag_coefs_Ireland[dl_gdp, 2, dl_cons] | 0.003 | 0.088 | -0.171 | 0.171 | 0.001 | 0.001 | 4239.0 | 2997.0 | 1.00 |
| lag_coefs_Ireland[dl_gdp, 2, dl_gfcf] | 0.104 | 0.041 | 0.027 | 0.180 | 0.001 | 0.001 | 1785.0 | 4172.0 | 1.00 |
| lag_coefs_Ireland[dl_cons, 1, dl_gdp] | 0.132 | 0.081 | -0.000 | 0.287 | 0.002 | 0.002 | 1109.0 | 1022.0 | 1.00 |
| lag_coefs_Ireland[dl_cons, 1, dl_cons] | 0.158 | 0.110 | -0.004 | 0.376 | 0.003 | 0.002 | 1227.0 | 2390.0 | 1.00 |
| lag_coefs_Ireland[dl_cons, 1, dl_gfcf] | -0.031 | 0.028 | -0.082 | 0.023 | 0.001 | 0.000 | 1756.0 | 4031.0 | 1.00 |
| lag_coefs_Ireland[dl_cons, 2, dl_gdp] | 0.018 | 0.069 | -0.120 | 0.147 | 0.001 | 0.001 | 5040.0 | 3039.0 | 1.00 |
| lag_coefs_Ireland[dl_cons, 2, dl_cons] | 0.048 | 0.073 | -0.095 | 0.189 | 0.001 | 0.001 | 5765.0 | 3448.0 | 1.00 |
| lag_coefs_Ireland[dl_cons, 2, dl_gfcf] | 0.071 | 0.025 | 0.021 | 0.116 | 0.000 | 0.000 | 5169.0 | 5742.0 | 1.00 |
| lag_coefs_Ireland[dl_gfcf, 1, dl_gdp] | 0.091 | 0.118 | -0.094 | 0.332 | 0.003 | 0.002 | 2232.0 | 1385.0 | 1.00 |
| lag_coefs_Ireland[dl_gfcf, 1, dl_cons] | 0.058 | 0.099 | -0.136 | 0.254 | 0.002 | 0.002 | 5377.0 | 2440.0 | 1.00 |
| lag_coefs_Ireland[dl_gfcf, 1, dl_gfcf] | 0.064 | 0.076 | -0.076 | 0.216 | 0.001 | 0.001 | 4693.0 | 3703.0 | 1.00 |
| lag_coefs_Ireland[dl_gfcf, 2, dl_gdp] | 0.050 | 0.092 | -0.121 | 0.232 | 0.001 | 0.001 | 6475.0 | 3196.0 | 1.00 |
| lag_coefs_Ireland[dl_gfcf, 2, dl_cons] | 0.024 | 0.096 | -0.154 | 0.221 | 0.001 | 0.002 | 5052.0 | 3012.0 | 1.00 |
| lag_coefs_Ireland[dl_gfcf, 2, dl_gfcf] | -0.048 | 0.093 | -0.239 | 0.102 | 0.002 | 0.002 | 1904.0 | 2237.0 | 1.00 |
| lag_coefs_United States[dl_gdp, 1, dl_gdp] | 0.033 | 0.044 | -0.043 | 0.122 | 0.001 | 0.001 | 2364.0 | 1396.0 | 1.00 |
| lag_coefs_United States[dl_gdp, 1, dl_cons] | 0.031 | 0.042 | -0.044 | 0.119 | 0.001 | 0.001 | 3946.0 | 2353.0 | 1.00 |
| lag_coefs_United States[dl_gdp, 1, dl_gfcf] | -0.008 | 0.031 | -0.072 | 0.043 | 0.001 | 0.001 | 1330.0 | 2254.0 | 1.00 |
| lag_coefs_United States[dl_gdp, 2, dl_gdp] | 0.036 | 0.042 | -0.037 | 0.121 | 0.001 | 0.001 | 3903.0 | 2216.0 | 1.00 |
| lag_coefs_United States[dl_gdp, 2, dl_cons] | 0.048 | 0.047 | -0.033 | 0.141 | 0.001 | 0.001 | 1335.0 | 1481.0 | 1.00 |
| lag_coefs_United States[dl_gdp, 2, dl_gfcf] | 0.027 | 0.028 | -0.027 | 0.076 | 0.000 | 0.000 | 3760.0 | 1877.0 | 1.00 |
| lag_coefs_United States[dl_cons, 1, dl_gdp] | 0.024 | 0.041 | -0.060 | 0.102 | 0.001 | 0.001 | 5468.0 | 2430.0 | 1.00 |
| lag_coefs_United States[dl_cons, 1, dl_cons] | 0.044 | 0.047 | -0.031 | 0.141 | 0.001 | 0.001 | 1768.0 | 1738.0 | 1.00 |
| lag_coefs_United States[dl_cons, 1, dl_gfcf] | 0.007 | 0.031 | -0.053 | 0.060 | 0.001 | 0.001 | 1909.0 | 2312.0 | 1.00 |
| lag_coefs_United States[dl_cons, 2, dl_gdp] | 0.039 | 0.044 | -0.033 | 0.131 | 0.001 | 0.001 | 2644.0 | 1843.0 | 1.00 |
| lag_coefs_United States[dl_cons, 2, dl_cons] | 0.036 | 0.042 | -0.040 | 0.116 | 0.001 | 0.001 | 4171.0 | 1978.0 | 1.00 |
| lag_coefs_United States[dl_cons, 2, dl_gfcf] | 0.031 | 0.027 | -0.018 | 0.084 | 0.000 | 0.000 | 4192.0 | 2149.0 | 1.00 |
| lag_coefs_United States[dl_gfcf, 1, dl_gdp] | 0.039 | 0.045 | -0.045 | 0.129 | 0.001 | 0.001 | 3809.0 | 1798.0 | 1.00 |
| lag_coefs_United States[dl_gfcf, 1, dl_cons] | 0.034 | 0.045 | -0.046 | 0.125 | 0.001 | 0.001 | 4896.0 | 2476.0 | 1.00 |
| lag_coefs_United States[dl_gfcf, 1, dl_gfcf] | 0.075 | 0.057 | -0.005 | 0.189 | 0.002 | 0.002 | 746.0 | 1317.0 | 1.00 |
| lag_coefs_United States[dl_gfcf, 2, dl_gdp] | 0.016 | 0.047 | -0.078 | 0.102 | 0.001 | 0.001 | 4171.0 | 1975.0 | 1.00 |
| lag_coefs_United States[dl_gfcf, 2, dl_cons] | 0.018 | 0.047 | -0.078 | 0.104 | 0.001 | 0.001 | 4508.0 | 1892.0 | 1.00 |
| lag_coefs_United States[dl_gfcf, 2, dl_gfcf] | 0.015 | 0.043 | -0.072 | 0.091 | 0.001 | 0.001 | 2937.0 | 2034.0 | 1.00 |
ax = az.plot_forest(
idata_full_test,
var_names=[
"alpha_Ireland",
"alpha_United States",
"alpha_Australia",
"alpha_Chile",
"alpha_New Zealand",
"alpha_South Africa",
"alpha_Canada",
"alpha_United Kingdom",
],
kind="ridgeplot",
combined=True,
ridgeplot_truncate=False,
ridgeplot_quantiles=[0.25, 0.5, 0.75],
ridgeplot_overlap=0.7,
figsize=(10, 10),
)
ax[0].axvline(0, color="red")
ax[0].set_title("Intercept Parameters for each country \n and Economic Measure");
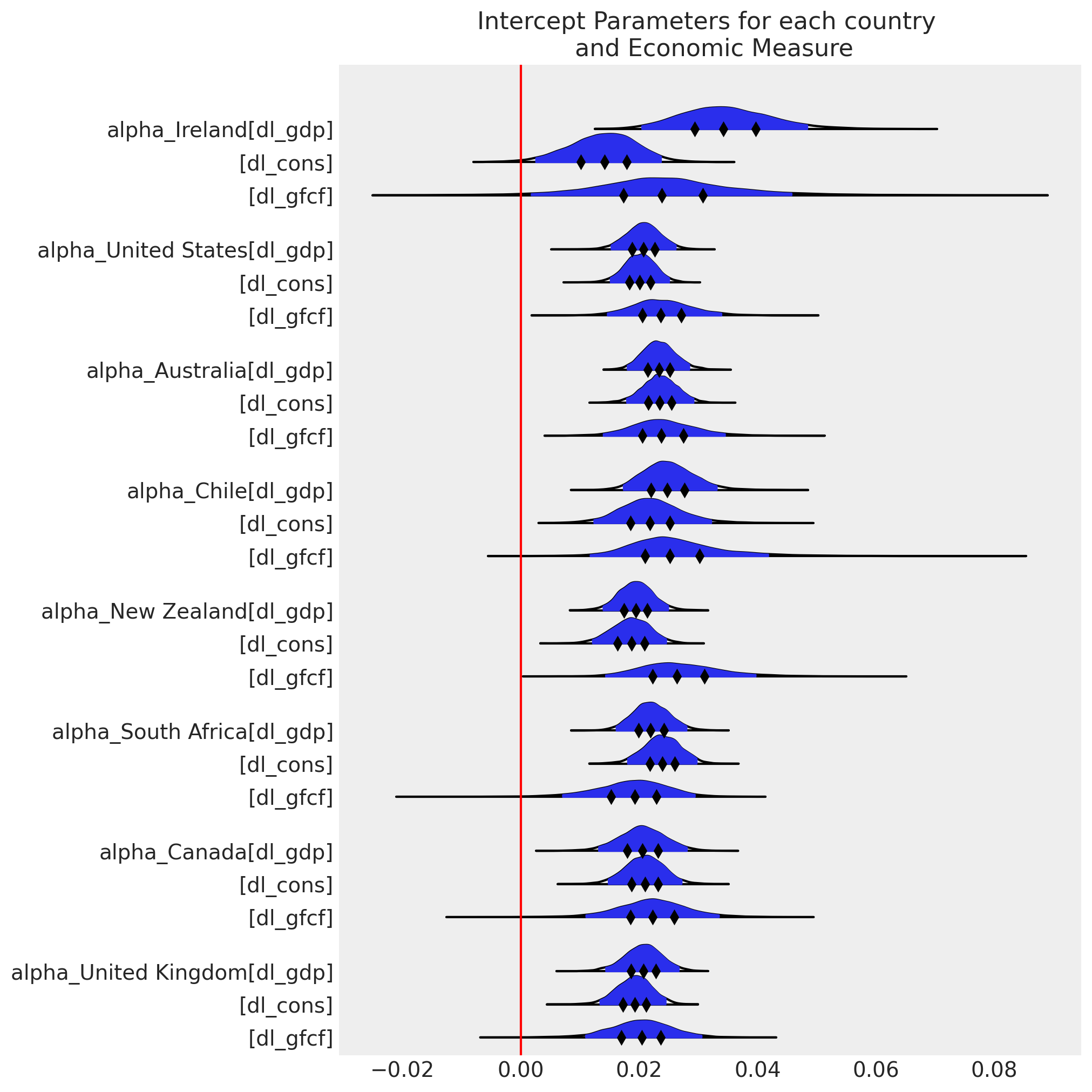
ax = az.plot_forest(
idata_full_test,
var_names=[
"lag_coefs_Ireland",
"lag_coefs_United States",
"lag_coefs_Australia",
"lag_coefs_Chile",
"lag_coefs_New Zealand",
"lag_coefs_South Africa",
"lag_coefs_Canada",
"lag_coefs_United Kingdom",
],
kind="ridgeplot",
ridgeplot_truncate=False,
figsize=(10, 10),
coords={"equations": "dl_cons", "lags": 1, "cross_vars": "dl_gdp"},
)
ax[0].axvline(0, color="red")
ax[0].set_title("Lag Coefficient for the first lag of GDP on Consumption \n by Country");
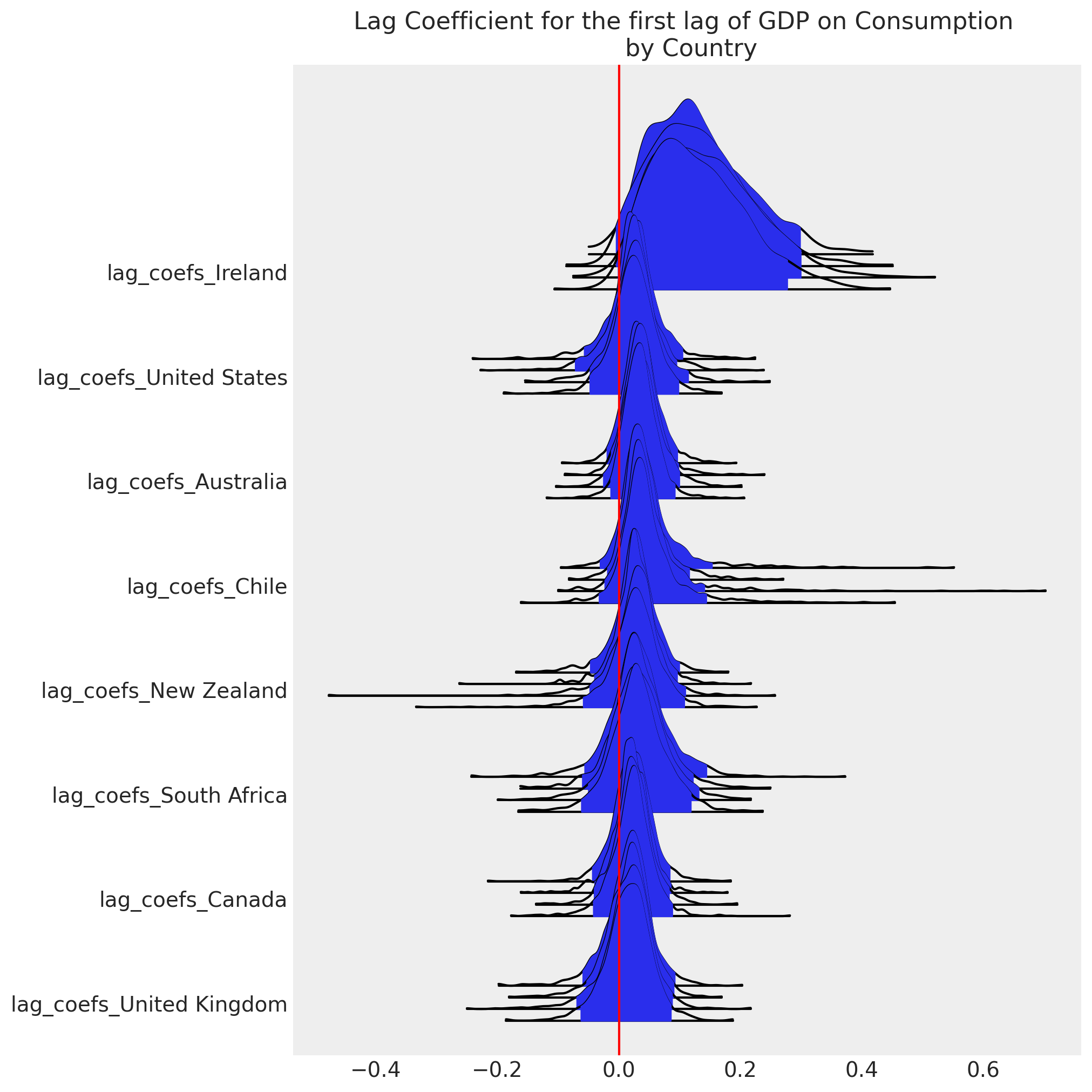
接下来我们将检查三个变量之间的相关性,看看通过包含分层结构我们学到了什么。
corr = pd.DataFrame(
az.summary(idata_full_test, var_names=["omega_global_corr"])["mean"].values.reshape(3, 3),
columns=["GDP", "CONS", "GFCF"],
)
corr.index = ["GDP", "CONS", "GFCF"]
corr
/Users/nathanielforde/mambaforge/envs/myjlabenv/lib/python3.11/site-packages/arviz/stats/diagnostics.py:584: RuntimeWarning: invalid value encountered in scalar divide
(between_chain_variance / within_chain_variance + num_samples - 1) / (num_samples)
| GDP | CONS | GFCF | |
|---|---|---|---|
| GDP | 1.000 | 0.980 | 0.916 |
| CONS | 0.980 | 1.000 | 0.879 |
| GFCF | 0.916 | 0.879 | 1.000 |
ax = az.plot_posterior(
idata_full_test,
var_names="omega_global_corr",
hdi_prob="hide",
point_estimate="mean",
grid=(3, 3),
kind="hist",
ec="black",
figsize=(10, 7),
)
titles = [
"GDP/GDP",
"GDP/CONS",
"GDP/GFCF",
"CONS/GDP",
"CONS/CONS",
"CONS/GFCF",
"GFCF/GDP",
"GFCF/CONS",
"GFCF/GFCF",
]
for ax, t in zip(ax.ravel(), titles):
ax.set_xlim(0.6, 1)
ax.set_title(t, fontsize=10)
plt.suptitle("The Posterior Correlation Estimates", fontsize=20);
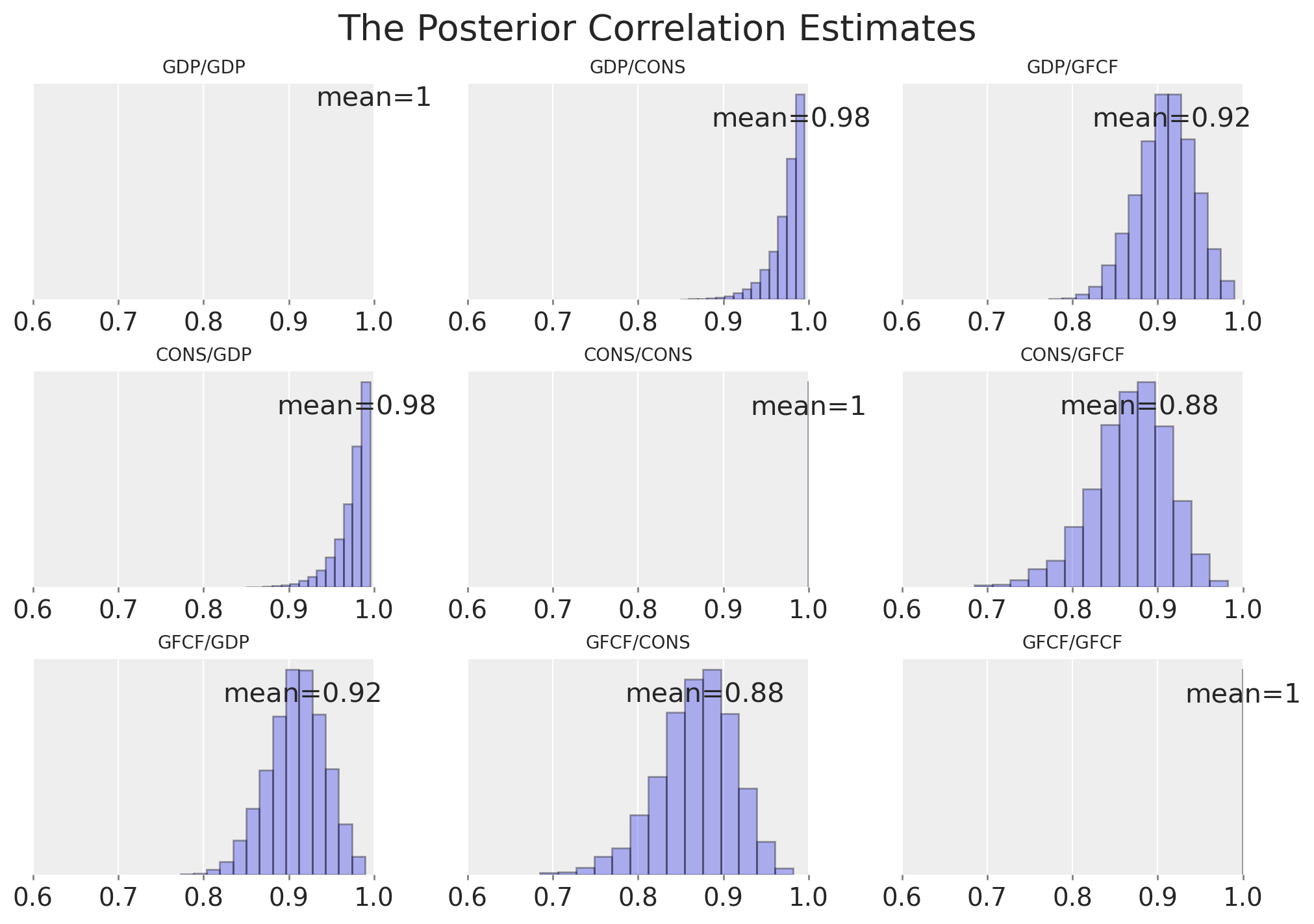
我们可以看到,这三个经济变量之间相关性的估计值与我们单独研究爱尔兰的简单情况有显著差异。特别是,我们可以看到 GDF 和 CONS 之间的相关性现在更高了。这表明我们已经了解了这些变量之间关系的一些信息,而这些信息在单独研究爱尔兰案例时并不明显。
接下来我们将绘制每个国家的模型拟合图,以确保预测分布能够恢复观测数据。对于模型充分性的问题,重要的是我们既能恢复爱尔兰的异常值情况,也能恢复澳大利亚和美国等更常规国家的情况。
az.plot_ppc(idata_full_test);
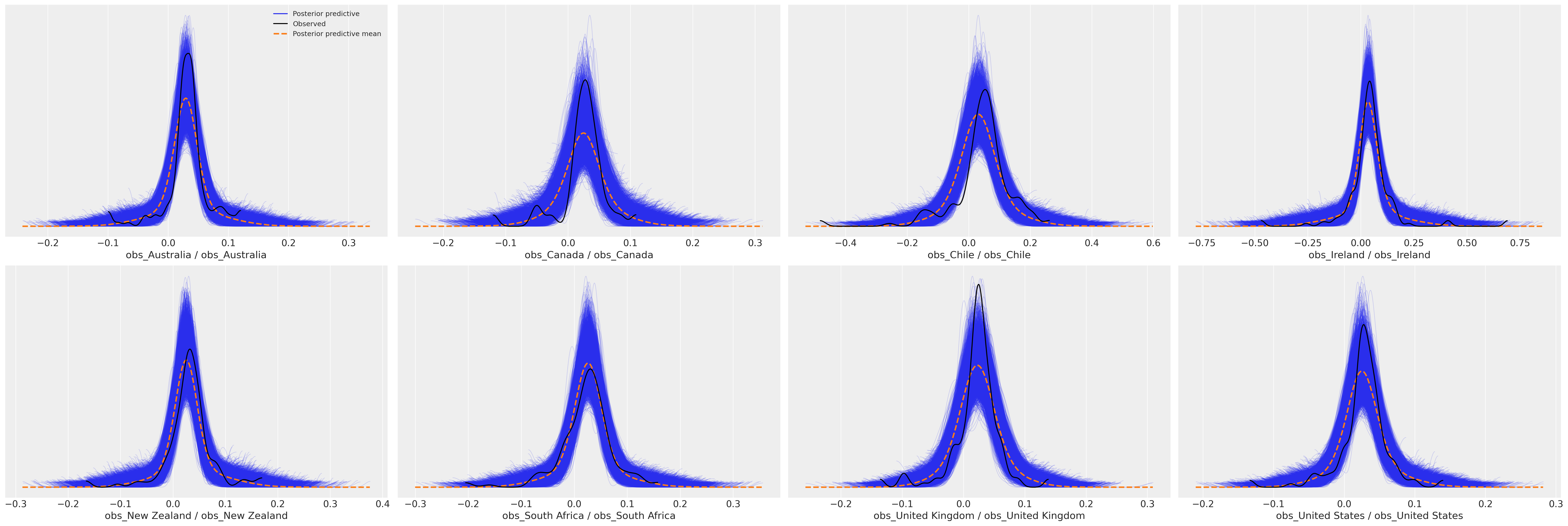
为了查看这些模型拟合随时间的演变
countries = gdp_hierarchical["country"].unique()
fig, axs = plt.subplots(8, 3, figsize=(20, 40))
for ax, country in zip(axs, countries):
temp = pd.DataFrame(
idata_full_test["observed_data"][f"obs_{country}"].data,
columns=["dl_gdp", "dl_cons", "dl_gfcf"],
)
ppc = az.extract(idata_full_test, group="posterior_predictive", num_samples=100)[
f"obs_{country}"
]
if country == "Ireland":
color = "viridis"
else:
color = "inferno"
for i in range(3):
shade_background(ppc, ax, i, color)
ax[0].plot(np.arange(ppc.shape[0]), ppc[:, 0, :].mean(axis=1), color="cyan", label="Mean")
ax[0].plot(temp["dl_gdp"], "o", mfc="black", mec="white", mew=1, markersize=7, label="Observed")
ax[0].set_title(f"Posterior Predictive GDP: {country}")
ax[0].legend(loc="lower left")
ax[1].plot(
temp["dl_cons"], "o", mfc="black", mec="white", mew=1, markersize=7, label="Observed"
)
ax[1].plot(np.arange(ppc.shape[0]), ppc[:, 1, :].mean(axis=1), color="cyan", label="Mean")
ax[1].set_title(f"Posterior Predictive Consumption: {country}")
ax[1].legend(loc="lower left")
ax[2].plot(
temp["dl_gfcf"], "o", mfc="black", mec="white", mew=1, markersize=7, label="Observed"
)
ax[2].plot(np.arange(ppc.shape[0]), ppc[:, 2, :].mean(axis=1), color="cyan", label="Mean")
ax[2].set_title(f"Posterior Predictive Investment: {country}")
ax[2].legend(loc="lower left")
plt.suptitle("Posterior Predictive Checks on Hierarchical VAR", fontsize=20);

在这里我们可以看到,该模型似乎已经恢复了观测数据的合理后验预测,并且与其他国家相比,爱尔兰 GDP 数据的波动性非常明显。这是否是关于数据质量还是指标被破坏的警示故事,我们留给经济学家来弄清楚。
结论#
VAR 模型构建是经济学中一个丰富而有趣的研究领域,在这些模型的解释和理解方面存在一系列挑战和陷阱。我们希望这个例子能够鼓励您继续探索贝叶斯框架中此类 VAR 模型构建的潜力。无论您是对宏观经济理论之间的关系感兴趣,还是对不良应用程序性能对客户反馈的影响等更简单的问题感兴趣,VAR 模型都为您提供了一个强大的工具,用于随着时间的推移探究这些关系。正如我们所看到的,分层 VAR 进一步实现了对同类群组中异常值的精确量化,并且不会因为国际资本主义产生的奇怪会计实务而丢弃信息。
在本系列的下一篇文章中,我们将花一些时间深入研究拟合 VAR 模型后得到的时间序列之间隐含的关系。
参考文献#
Ricardo Vieira。PyMC 中的贝叶斯向量自回归。URL: https://www.pymc-labs.io/blog-posts/bayesian-vector-autoregression/ (访问于 2022-12-09)。
作者#
改编自 PYMC labs 博客文章 和 Jim Savage 的讨论 这里,由 Nathaniel Forde 于 2022 年 11 月完成 (pymc-examples#456)
由 Nathaniel Forde 于 2023 年 2 月重新执行 (pymc_examples#523)
水印#
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor,aeppl,xarray
Last updated: Tue Feb 21 2023
Python implementation: CPython
Python version : 3.11.0
IPython version : 8.9.0
pytensor: 2.8.11
aeppl : not installed
xarray : 2023.1.0
pymc : 5.0.1
statsmodels: 0.13.5
pandas : 1.5.3
numpy : 1.24.1
matplotlib : 3.6.3
arviz : 0.14.0
Watermark: 2.3.1
许可声明#
本示例库中的所有笔记本均根据 MIT 许可证 提供,该许可证允许修改和再分发以用于任何用途,前提是版权和许可声明得到保留。
引用 PyMC 示例#
要引用此笔记本,请使用 Zenodo 为 pymc-examples 存储库提供的 DOI。
重要
许多笔记本改编自其他来源:博客、书籍…… 在这种情况下,您也应该引用原始来源。
另请记住引用代码中使用的相关库。
这是一个 bibtex 中的引用模板
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
渲染后可能看起来像