


估计分布的参数,来自笨拙的分箱数据#
问题#
假设我们有兴趣推断人群的属性。这可以是任何事物,从年龄、收入或身体质量指数的分布,到各种不同的可能衡量标准。在完成这项任务时,我们可能经常会遇到这样的情况:我们有多个数据集,每个数据集都可以告知我们对总体人群的看法。
通常,这些数据的形式对于我们这些数据科学家来说,可能并不理想。例如,这些数据可能已被分箱到类别中。这不理想的一个原因是,这种分箱过程实际上丢弃了信息 - 我们失去了关于个体数据位于某个箱子中的哪个位置的任何知识。第二个原因是不理想的是,不同的研究可能会使用不同的分箱方法 - 例如,一项研究可能会以十年为单位记录年龄(例如,某人是 20 多岁、30 多岁、40 多岁等等),但另一项研究可能会通过分配世代标签(例如,Z 世代、千禧一代、X 世代、婴儿潮一代 II、婴儿潮一代 I、战后一代)来(间接地)记录年龄。
因此,我们面临一个问题:我们拥有关于我们感兴趣的度量(无论是年龄、收入、BMI 还是其他任何内容)的计数数据集,但它们是分箱的,并且它们已被不同地分箱。本笔记本介绍了一个针对此问题的解决方案,该解决方案由 PyMC Labs 开发,并由 盖茨基金会 支持。我们可以对人口级别分布的参数进行推断。

解决方案#
更正式地说,我们将问题描述为:如果我们有用于数据分箱的箱子边缘(又名切点)和箱子计数,我们如何估计底层分布的参数?我们将提出一个解决方案以及此解决方案的各种说明性示例,该解决方案做出以下假设
箱子是可排序的(例如,体重不足、正常、超重、肥胖),
底层分布以参数形式指定,并且
划定箱子的切点是已知的,并且可以在分布的支持(也称为概率分布可以返回的有效值)上精确定位。
使用的方法很大程度上基于 序数回归 背后的逻辑。此方法提出,观察到的箱子计数 \(Y = {1, 2, \ldots, K}\) 是由一组箱子边缘(又名切点)\(\theta_1, \ldots, \theta _{K-1}\) 对潜在概率分布(我们可以称之为 \(y^*\))进行操作而生成的。我们可以将观察到箱子 1 中数据的概率描述为
箱子 2 为
箱子 3 为
箱子 4 为
其中 \(\Phi\) 是标准累积正态分布。
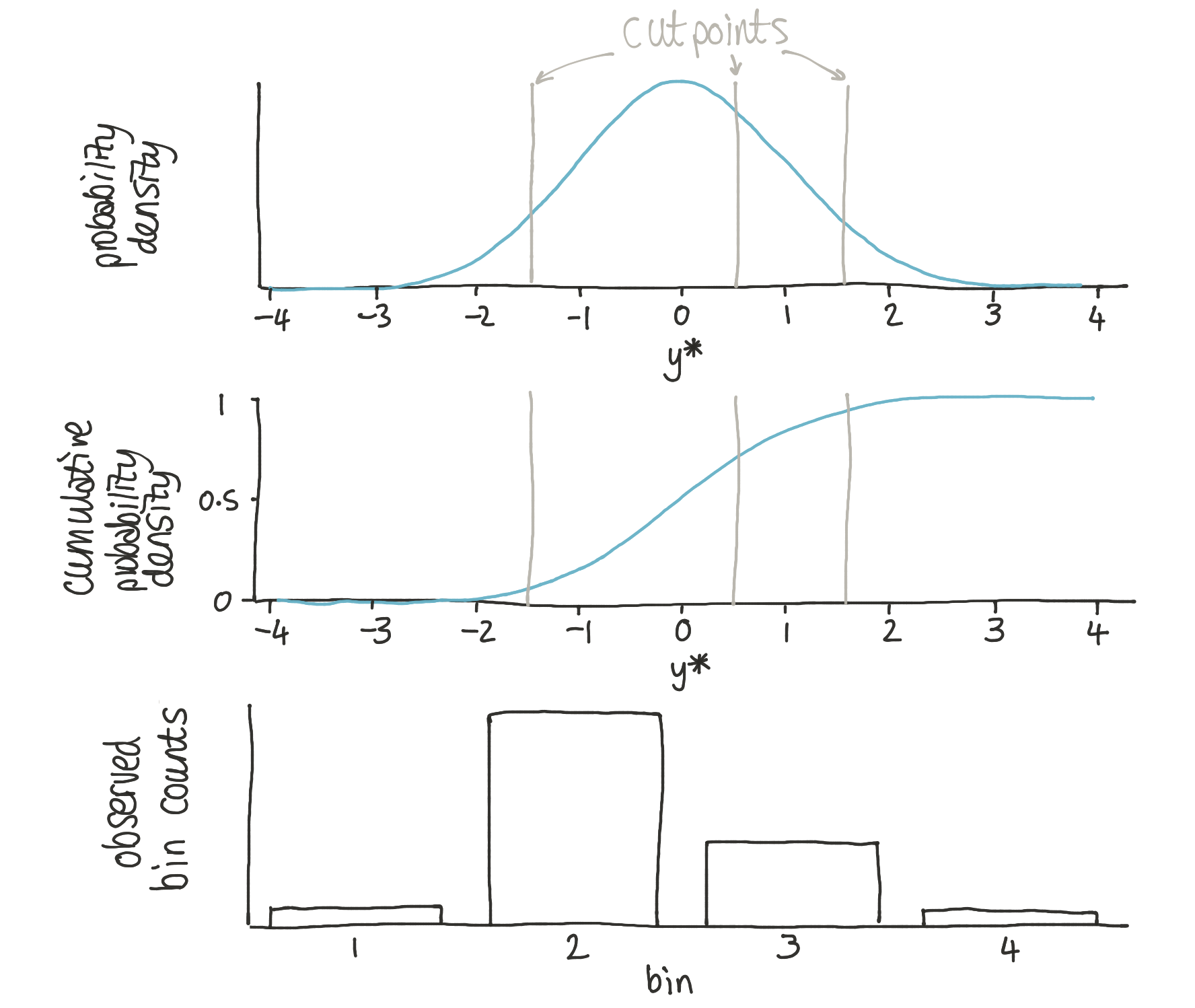
在序数回归中,切点被视为潜在变量,正态分布的参数可以被视为已观察到的(或从其他预测变量派生的)。此问题不同之处在于
高斯分布的参数是未知的,
我们不想局限于高斯分布,
我们观察到了一系列
cutpoints,我们观察到了箱子
counts,
我们现在可以草拟一个生成式 PyMC 模型
import pytensor.tensor as pt
with pm.Model() as model:
# priors
mu = pm.Normal("mu")
sigma = pm.HalfNormal("sigma")
# generative process
probs = pm.math.exp(pm.logcdf(pm.Normal.dist(mu=mu, sigma=sigma), cutpoints))
probs = pm.math.concatenate([[0], probs, [1]])
probs = pt.extra_ops.diff(probs)
# likelihood
pm.Multinomial("counts", p=probs, n=sum(counts), observed=counts)
我们在下面实现模型的确切方式与此略有不同,但让我们分解一下它的工作原理。首先,我们定义了潜在分布的 mu 和 sigma 参数的先验。然后我们有 3 行代码计算任何观察到的数据落入给定箱子的概率。这其中的第一行
probs = pm.math.exp(pm.logcdf(pm.Normal.dist(mu=mu, sigma=sigma), cutpoints))
计算每个切点处的累积密度。第二行
probs = pm.math.concatenate([[0], probs, [1]])
只是将 \(-\infty\) 处的累积密度(为零)和 \(\infty\) 处的累积密度(为 1)连接起来。第三行
probs = pt.extra_ops.diff(probs)
计算连续累积密度之间的差值,以给出数据落入任何给定箱子的实际概率。
最后,我们以多项式似然函数结束,该函数告诉我们观察 counts 的似然性,给定箱子 probs 集和总观察数 sum(counts)。
假设我们可以使用基本 python 或 numpy 来描述生成过程。然而,这样做的问题是梯度信息丢失,因此使用保留梯度信息的数值库完成这些操作允许 MCMC 采样算法使用它。
该方法用高斯分布进行了说明,下面我们展示了许多使用高斯分布的工作示例。然而,该方法是通用的,在本笔记本的末尾,我们提供了一个演示,证明该方法确实扩展到了非高斯分布。
import warnings
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
import pytensor.tensor as pt
import seaborn as sns
warnings.filterwarnings(action="ignore", category=UserWarning)
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
plt.rcParams.update({"font.size": 14})
az.style.use("arviz-darkgrid")
rng = np.random.default_rng(1234)
具有高斯分布的模拟数据#
前几个示例将基于 2 项假设研究,这些研究测量高斯分布的变量。每项研究都有自己的样本量,我们的任务是学习人口级别高斯分布的参数。挫折 1 是数据已被分箱。挫折 2 是每项研究都使用了不同的类别,即此数据分箱过程中的不同切点。
在此模拟方法中,我们将真实人口级别参数定义为
true_mu: -2.0true_sigma: 2.0
我们的目标是仅根据箱子计数和切点来恢复 mu 和 sigma 值。
# Generate two different sets of random samples from the same Gaussian.
true_mu, true_sigma = -2, 2
x1 = rng.normal(loc=true_mu, scale=true_sigma, size=1500)
x2 = rng.normal(loc=true_mu, scale=true_sigma, size=2000)
这些研究在其数据分箱过程中使用了以下不同的切点。
def data_to_bincounts(data, cutpoints):
# categorise each datum into correct bin
bins = np.digitize(data, bins=cutpoints)
# bin counts
counts = pd.DataFrame({"bins": bins}).groupby(by="bins")["bins"].agg("count")
return counts
c1 = data_to_bincounts(x1, d1)
c2 = data_to_bincounts(x2, d2)
让我们在一个方便的图中可视化它。左侧列显示了两个研究的底层数据和切点。右侧列显示了生成的箱子计数。
fig, ax = plt.subplots(2, 2, figsize=(12, 8))
# First set of measurements
ax[0, 0].hist(x1, 50, alpha=0.5)
for cut in d1:
ax[0, 0].axvline(cut, color="k", ls=":")
# Plot observed bin counts
c1.plot(kind="bar", ax=ax[0, 1], alpha=0.5)
ax[0, 1].set_xticklabels([f"bin {n}" for n in range(len(c1))])
ax[0, 1].set(title="Study 1", xlabel="c1", ylabel="bin count")
# Second set of measuremsnts
ax[1, 0].hist(x2, 50, alpha=0.5)
for cut in d2:
ax[1, 0].axvline(cut, color="k", ls=":")
# Plot observed bin counts
c2.plot(kind="bar", ax=ax[1, 1], alpha=0.5)
ax[1, 1].set_xticklabels([f"bin {n}" for n in range(len(c2))])
ax[1, 1].set(title="Study 2", xlabel="c2", ylabel="bin count")
# format axes
ax[0, 0].set(xlim=(-11, 5), xlabel="$x$", ylabel="observed frequency", title="Sample 1")
ax[1, 0].set(xlim=(-11, 5), xlabel="$x$", ylabel="observed frequency", title="Sample 2");
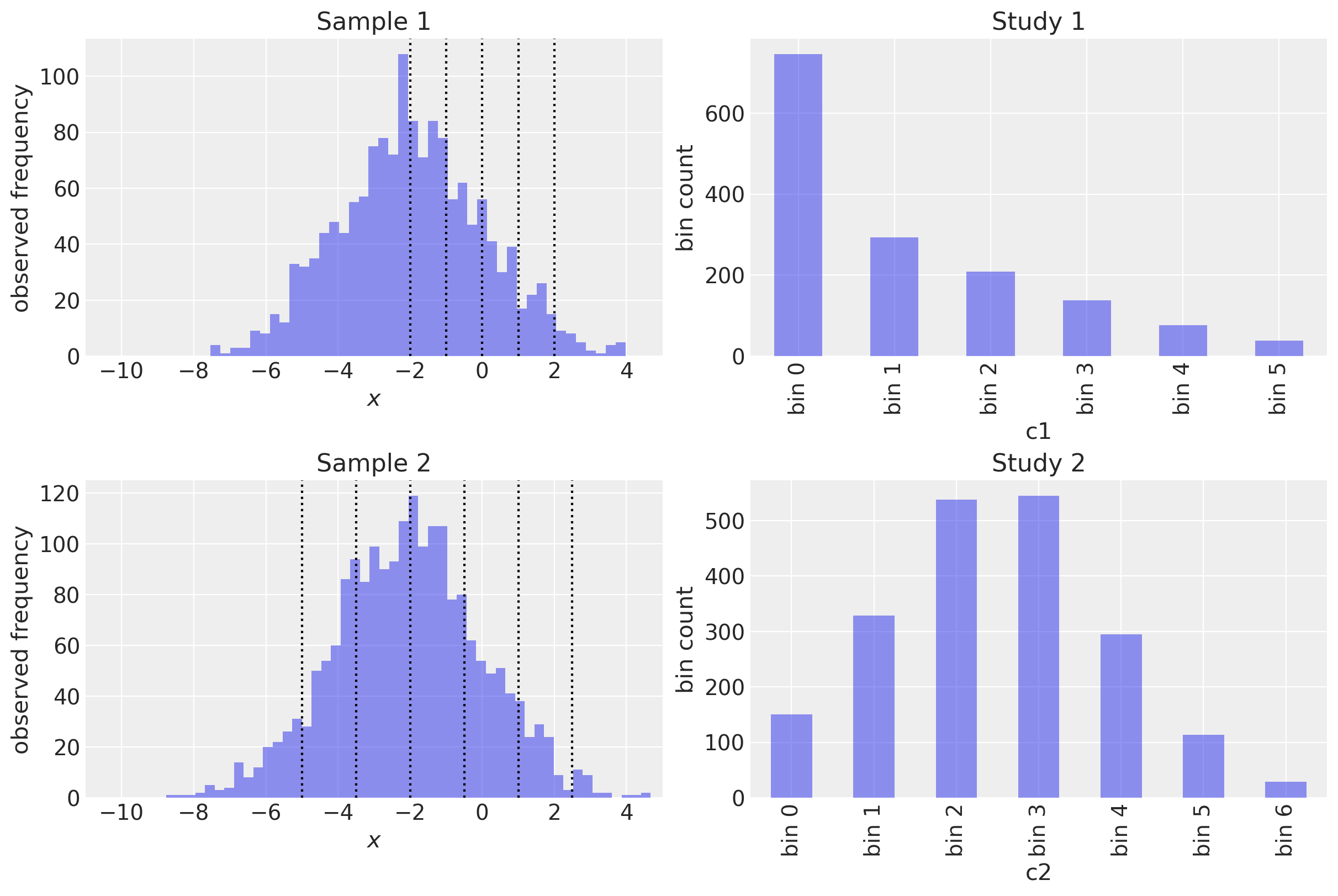
每个箱子都与计数配对。如您在上面看到的,c1 和 c2 的分箱方式不同。一个有 6 个箱子,另一个有 7 个。c1 基本上省略了高斯分布的一半。
概括来说,在实际情况下,我们可能会访问切点和箱子计数,但不能访问底层数据 x1 或 x2。
示例 1:使用一组箱子进行高斯参数估计#
我们将首先研究当我们仅使用一组箱子来估计 mu 和 sigma 参数时会发生什么。
模型规范#
with pm.Model() as model1:
sigma = pm.HalfNormal("sigma")
mu = pm.Normal("mu")
probs1 = pm.math.exp(pm.logcdf(pm.Normal.dist(mu=mu, sigma=sigma), d1))
probs1 = pt.extra_ops.diff(pm.math.concatenate([[0], probs1, [1]]))
pm.Multinomial("counts1", p=probs1, n=c1.sum(), observed=c1.values)
pm.model_to_graphviz(model1)

with model1:
trace1 = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [sigma, mu]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 13 seconds.
模型检查#
我们首先从后验预测检查开始。给定后验值,我们应该能够生成看起来与我们观察到的数据接近的观察结果。
with model1:
ppc = pm.sample_posterior_predictive(trace1)
我们可以通过图形方式执行此操作。
fig, ax = plt.subplots(figsize=(12, 4))
# Plot observed bin counts
c1.plot(kind="bar", ax=ax, alpha=0.5)
# Plot posterior predictive
ppc.posterior_predictive.plot.scatter(x="counts1_dim_0", y="counts1", color="k", alpha=0.2)
# Formatting
ax.set_xticklabels([f"bin {n}" for n in range(len(c1))])
ax.set_title("Six bin discretization of N(-2, 2)")
Text(0.5, 1.0, 'Six bin discretization of N(-2, 2)')
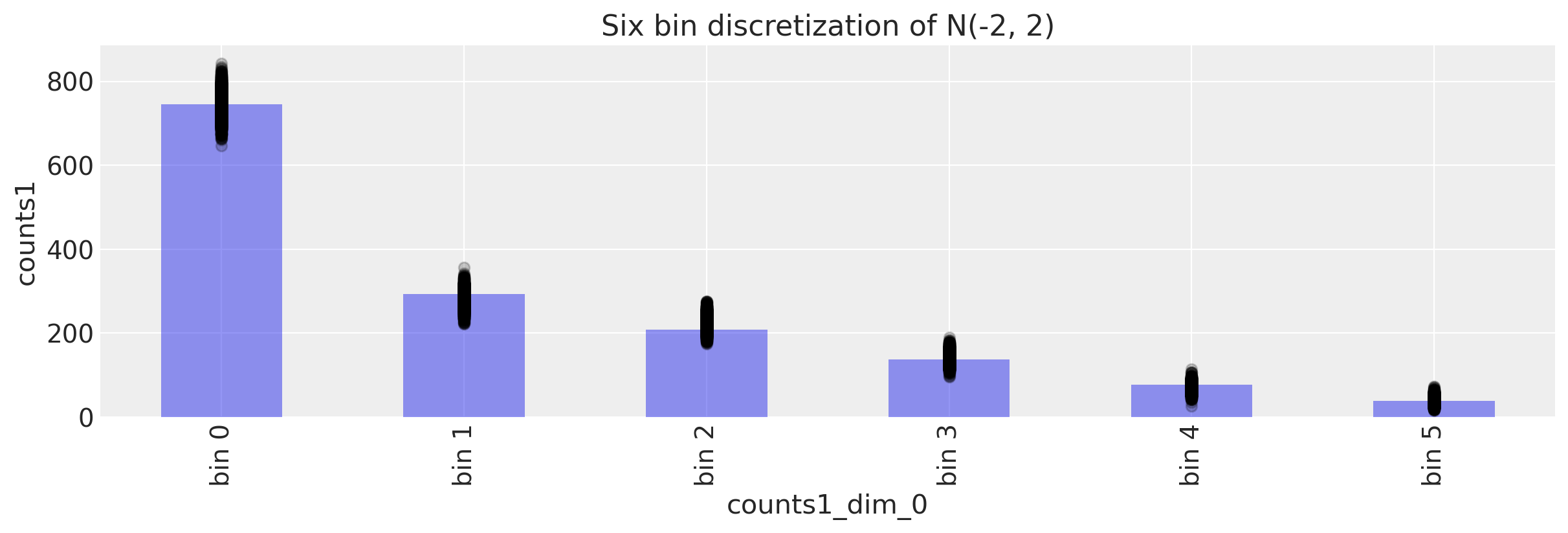
看起来数字在正确的范围内。数字顺序正确,我们还正确识别了正确的比例。
我们还可以通过多种方式以编程方式访问我们的后验预测
ppc.posterior_predictive.counts1.values
array([[[714, 284, 228, 137, 74, 63],
[753, 279, 228, 138, 66, 36],
[734, 304, 222, 141, 60, 39],
...,
[746, 274, 234, 127, 67, 52],
[719, 290, 237, 150, 67, 37],
[706, 285, 229, 143, 97, 40]],
[[773, 263, 211, 149, 61, 43],
[752, 253, 233, 153, 75, 34],
[703, 294, 214, 148, 87, 54],
...,
[686, 317, 257, 128, 66, 46],
[758, 276, 240, 121, 66, 39],
[755, 258, 221, 151, 62, 53]],
[[796, 255, 181, 140, 74, 54],
[764, 267, 224, 120, 83, 42],
[794, 267, 196, 142, 65, 36],
...,
[767, 263, 220, 129, 78, 43],
[774, 278, 229, 125, 62, 32],
[724, 289, 234, 153, 67, 33]],
[[758, 284, 228, 126, 58, 46],
[743, 274, 227, 145, 69, 42],
[755, 299, 212, 119, 71, 44],
...,
[718, 302, 240, 135, 68, 37],
[722, 286, 217, 155, 78, 42],
[767, 285, 201, 156, 67, 24]]])
让我们取平均值并将其与观察到的计数进行比较
ppc.posterior_predictive.counts1.mean(dim=["chain", "draw"]).values
array([744.51325, 281.33575, 223.45975, 141.09875, 70.2235 , 39.369 ])
c1.values
array([746, 293, 208, 138, 77, 38])
恢复参数#
更重要的问题是我们是否已恢复分布的参数。回想一下,我们使用 mu = -2 和 sigma = 2 来生成数据。
az.plot_posterior(trace1, var_names=["mu", "sigma"], ref_val=[true_mu, true_sigma]);
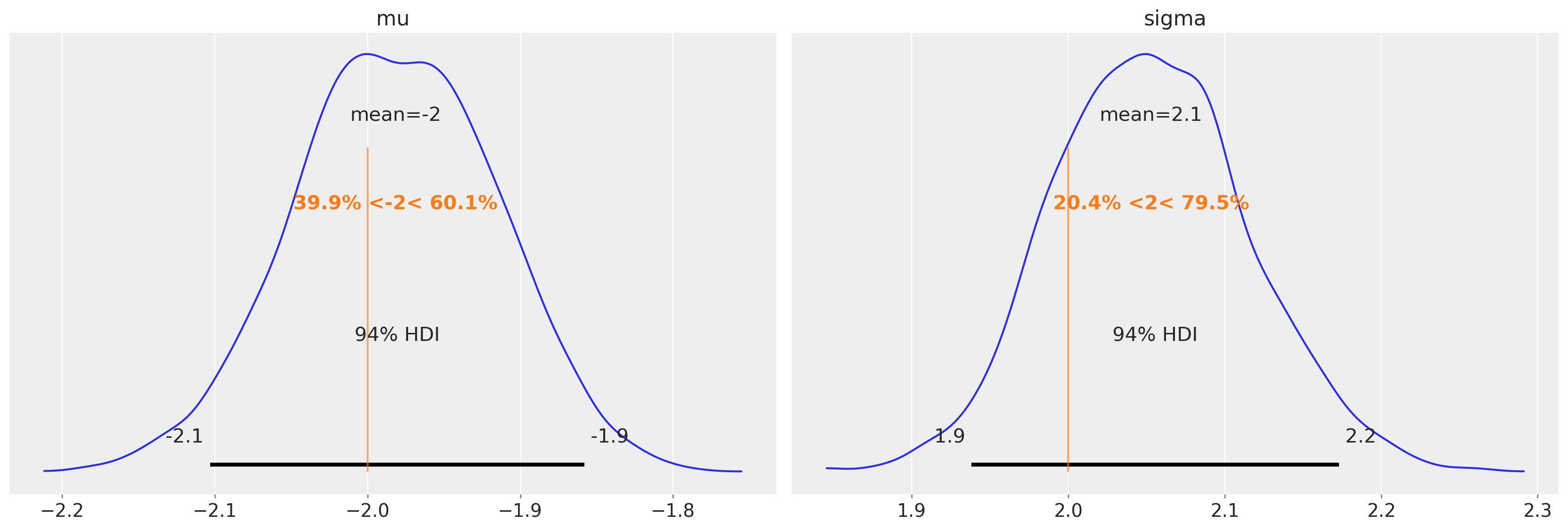
非常好!我们可以访问后验平均估计值(存储为 xarray 类型),如下所示。MCMC 样本以 2D 矩阵的形式返回,其中一个维度用于 MCMC 链 (chain),另一个维度用于样本编号 (draw)。我们可以使用 .mean(dim=["draw", "chain"]) 计算总体后验平均值。
trace1.posterior["mu"].mean(dim=["draw", "chain"]).values
array(-1.98161385)
trace1.posterior["sigma"].mean(dim=["draw", "chain"]).values
array(2.05300289)
示例 2:使用另一组箱子进行参数估计#
在上面,我们使用了一组分箱数据。让我们看看当我们换成另一组数据时会发生什么。
模型规范#
与上面一样,这是模型规范。
with pm.Model() as model2:
sigma = pm.HalfNormal("sigma")
mu = pm.Normal("mu")
probs2 = pm.math.exp(pm.logcdf(pm.Normal.dist(mu=mu, sigma=sigma), d2))
probs2 = pt.extra_ops.diff(pm.math.concatenate([[0], probs2, [1]]))
pm.Multinomial("counts2", p=probs2, n=c2.sum(), observed=c2.values)
with model2:
trace2 = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [sigma, mu]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 11 seconds.
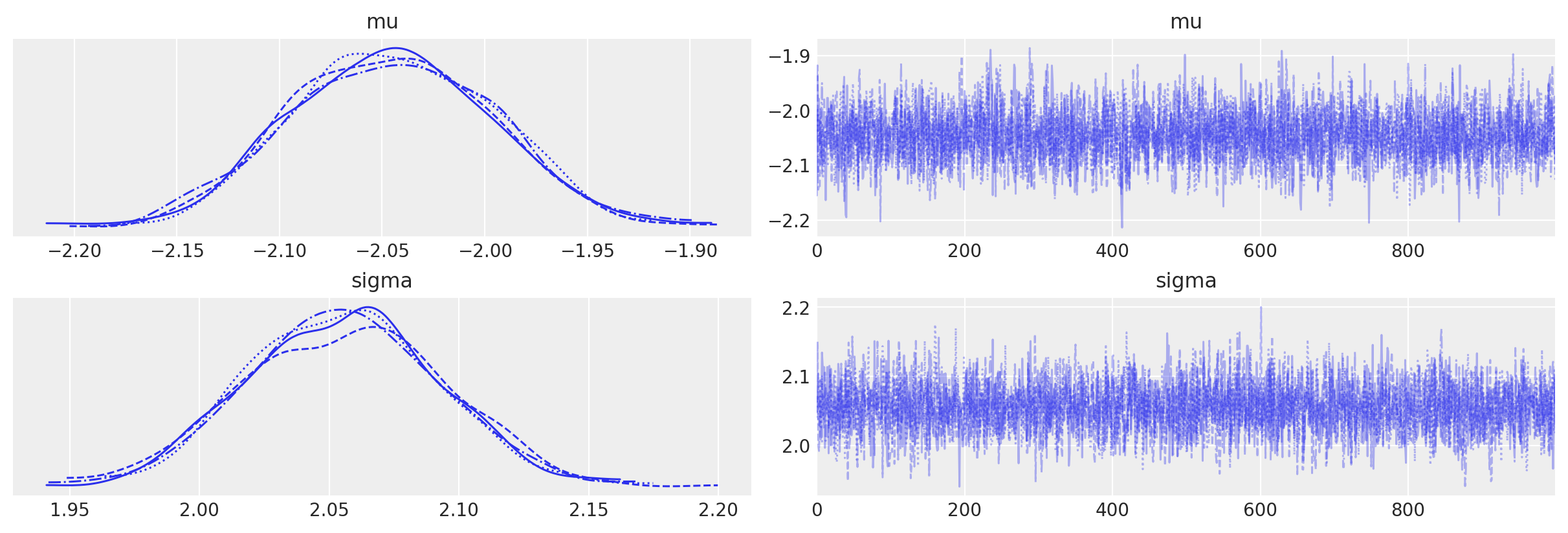
az.plot_trace(trace2);
后验预测检查#
让我们运行 PPC 检查以确保我们生成的数据与我们观察到的数据相似。
with model2:
ppc = pm.sample_posterior_predictive(trace2)
我们计算平均箱子后验预测箱子计数,在样本上取平均值。
ppc.posterior_predictive.counts2.mean(dim=["chain", "draw"]).values
array([150.6875 , 328.46925, 537.65775, 530.53625, 313.99 , 111.5935 ,
27.06575])
c2.values
array([150, 329, 538, 545, 295, 114, 29])
看起来很匹配。但始终明智的做法是将事物可视化。
fig, ax = plt.subplots(figsize=(12, 4))
# Plot observed bin counts
c2.plot(kind="bar", ax=ax, alpha=0.5)
# Plot posterior predictive
ppc.posterior_predictive.plot.scatter(x="counts2_dim_0", y="counts2", color="k", alpha=0.2)
# Formatting
ax.set_xticklabels([f"bin {n}" for n in range(len(c2))])
ax.set_title("Seven bin discretization of N(-2, 2)")
Text(0.5, 1.0, 'Seven bin discretization of N(-2, 2)')
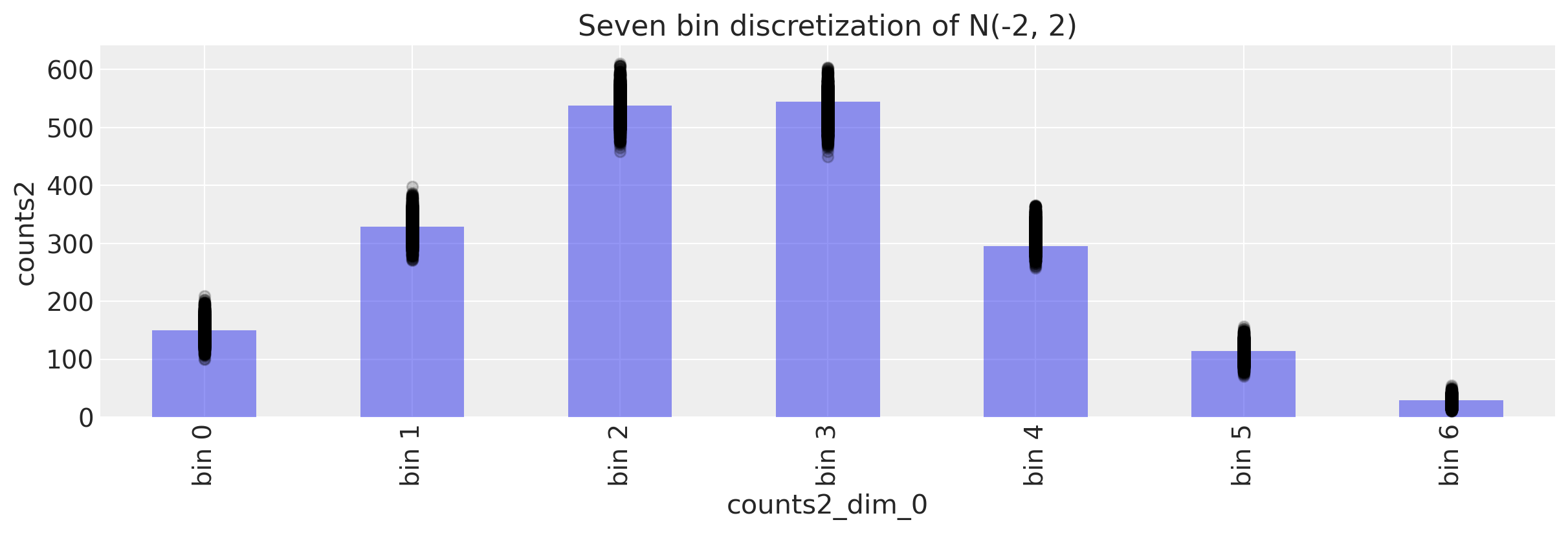
不错!
恢复参数#
我们是否恢复了参数?
az.plot_posterior(trace2, var_names=["mu", "sigma"], ref_val=[true_mu, true_sigma]);
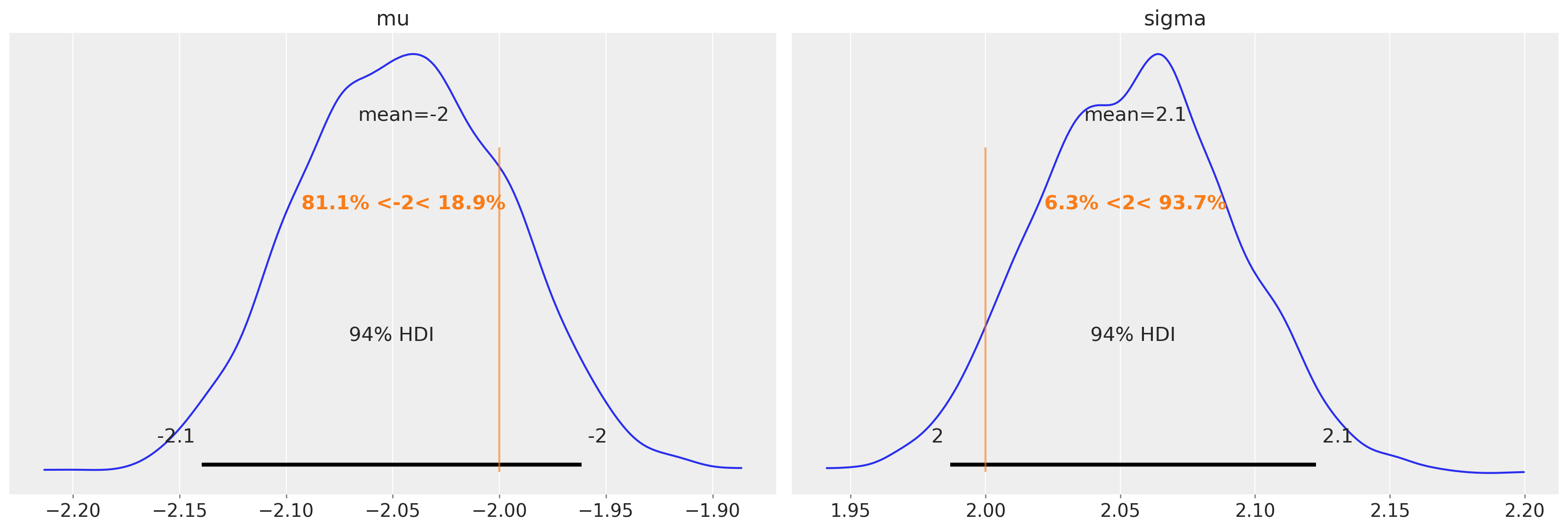
trace2.posterior["mu"].mean(dim=["draw", "chain"]).values
array(-2.04489232)
trace2.posterior["sigma"].mean(dim=["draw", "chain"]).values
array(2.05560527)
示例 3:将两组箱子放在一起进行参数估计#
现在我们需要看看如果我们将两种分箱方式都添加进来会发生什么。
模型规范#
with pm.Model() as model3:
sigma = pm.HalfNormal("sigma")
mu = pm.Normal("mu")
probs1 = pm.math.exp(pm.logcdf(pm.Normal.dist(mu=mu, sigma=sigma), d1))
probs1 = pt.extra_ops.diff(pm.math.concatenate([np.array([0]), probs1, np.array([1])]))
probs1 = pm.Deterministic("normal1_cdf", probs1)
probs2 = pm.math.exp(pm.logcdf(pm.Normal.dist(mu=mu, sigma=sigma), d2))
probs2 = pt.extra_ops.diff(pm.math.concatenate([np.array([0]), probs2, np.array([1])]))
probs2 = pm.Deterministic("normal2_cdf", probs2)
pm.Multinomial("counts1", p=probs1, n=c1.sum(), observed=c1.values)
pm.Multinomial("counts2", p=probs2, n=c2.sum(), observed=c2.values)
pm.model_to_graphviz(model3)

with model3:
trace3 = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [sigma, mu]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 13 seconds.
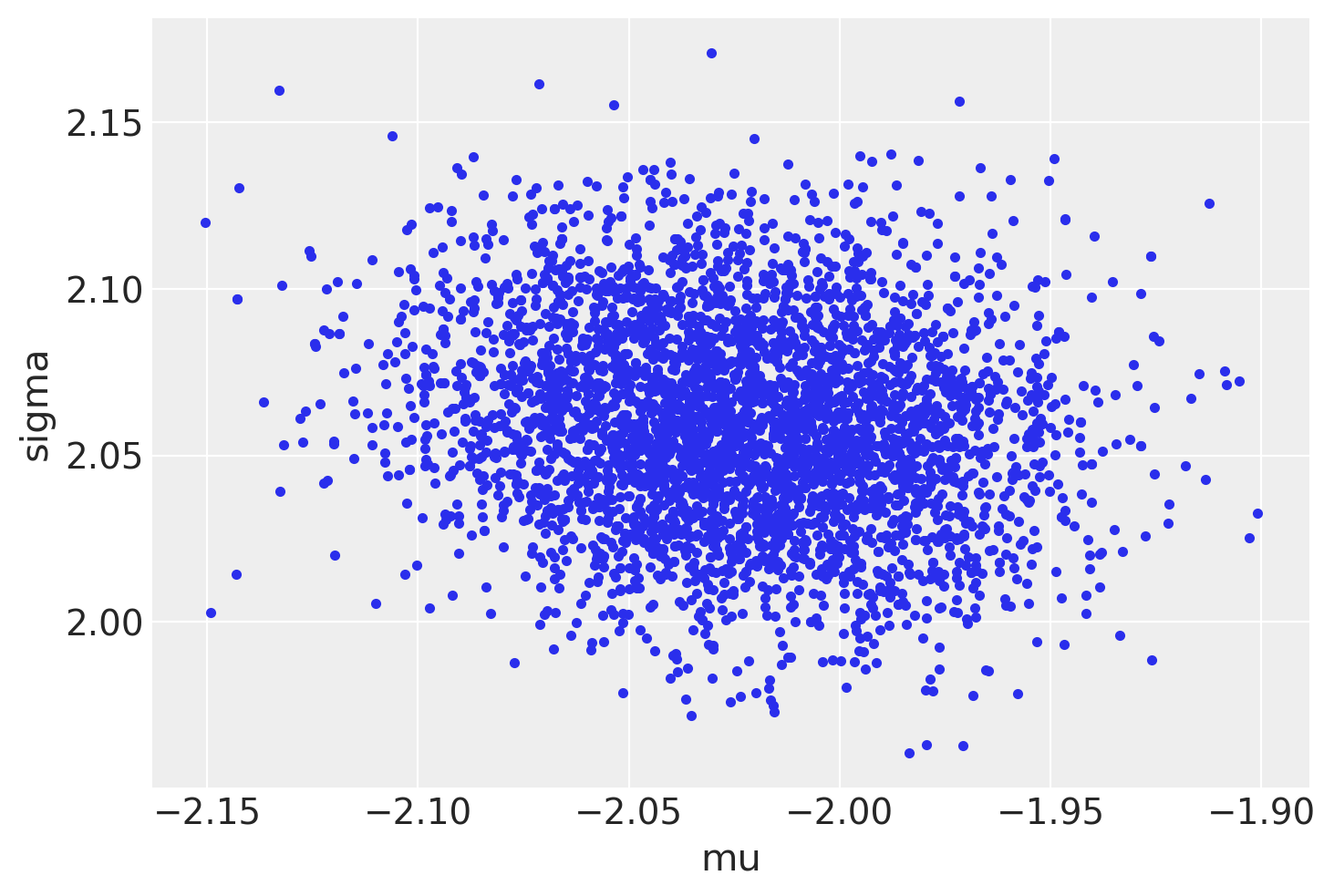
az.plot_pair(trace3, var_names=["mu", "sigma"], divergences=True);
后验预测检查#
with model3:
ppc = pm.sample_posterior_predictive(trace3)
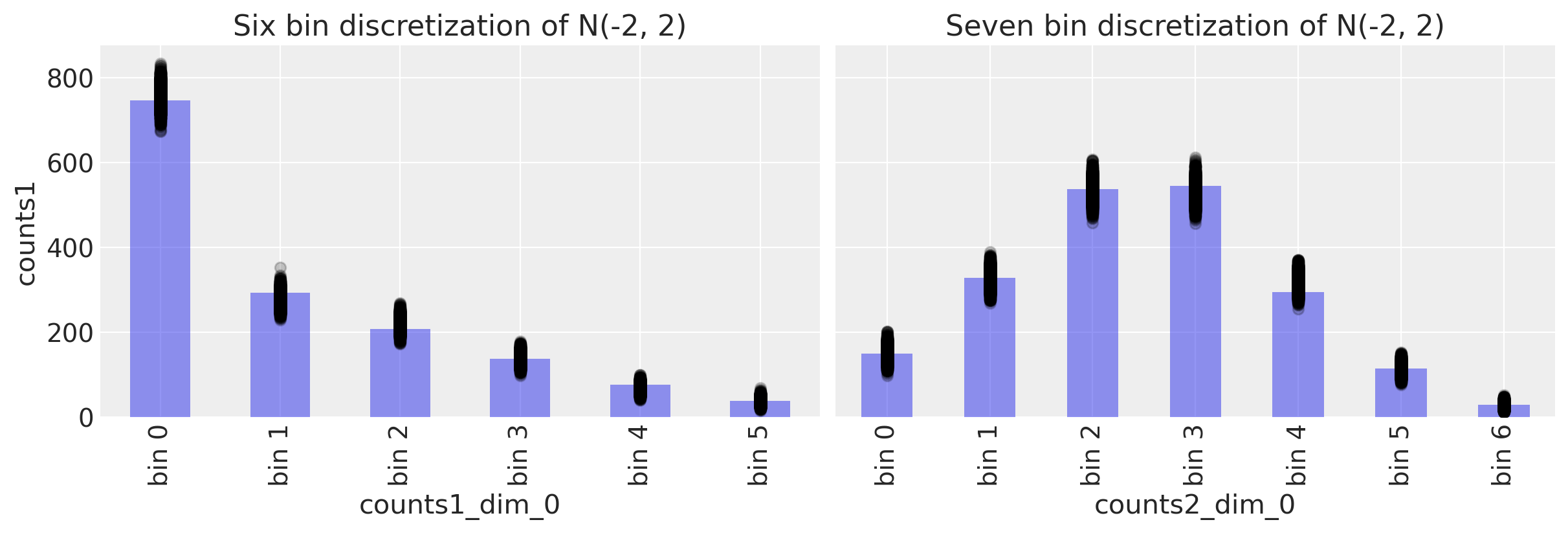
fig, ax = plt.subplots(1, 2, figsize=(12, 4), sharey=True)
# Study 1 ----------------------------------------------------------------
# Plot observed bin counts
c1.plot(kind="bar", ax=ax[0], alpha=0.5)
# Plot posterior predictive
ppc.posterior_predictive.plot.scatter(
x="counts1_dim_0", y="counts1", color="k", alpha=0.2, ax=ax[0]
)
# Formatting
ax[0].set_xticklabels([f"bin {n}" for n in range(len(c1))])
ax[0].set_title("Six bin discretization of N(-2, 2)")
# Study 1 ----------------------------------------------------------------
# Plot observed bin counts
c2.plot(kind="bar", ax=ax[1], alpha=0.5)
# Plot posterior predictive
ppc.posterior_predictive.plot.scatter(
x="counts2_dim_0", y="counts2", color="k", alpha=0.2, ax=ax[1]
)
# Formatting
ax[1].set_xticklabels([f"bin {n}" for n in range(len(c2))])
ax[1].set_title("Seven bin discretization of N(-2, 2)")
Text(0.5, 1.0, 'Seven bin discretization of N(-2, 2)')
恢复参数#
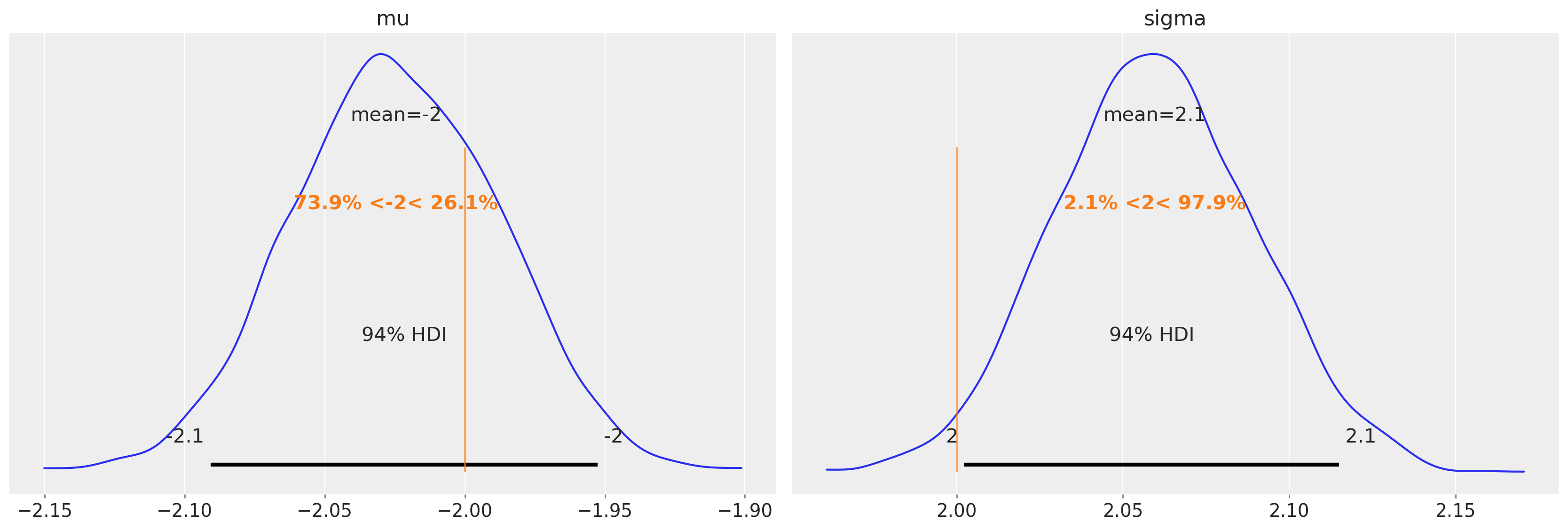
trace3.posterior["mu"].mean(dim=["draw", "chain"]).values
array(-2.02455161)
trace3.posterior["sigma"].mean(dim=["draw", "chain"]).values
array(2.05959445)
az.plot_posterior(trace3, var_names=["mu", "sigma"], ref_val=[true_mu, true_sigma]);
示例 4:使用连续和分箱度量进行参数估计#
为了完整性,让我们看看如何基于一组连续度量和一组分箱度量来估计人口参数。我们将使用我们已经生成的模拟数据。
模型规范#
with pm.Model() as model4:
sigma = pm.HalfNormal("sigma")
mu = pm.Normal("mu")
# study 1
probs1 = pm.math.exp(pm.logcdf(pm.Normal.dist(mu=mu, sigma=sigma), d1))
probs1 = pt.extra_ops.diff(pm.math.concatenate([np.array([0]), probs1, np.array([1])]))
probs1 = pm.Deterministic("normal1_cdf", probs1)
pm.Multinomial("counts1", p=probs1, n=c1.sum(), observed=c1.values)
# study 2
pm.Normal("y", mu=mu, sigma=sigma, observed=x2)
pm.model_to_graphviz(model4)

with model4:
trace4 = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [sigma, mu]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 12 seconds.
后验预测检查#
with model4:
ppc = pm.sample_posterior_predictive(trace4)
fig, ax = plt.subplots(1, 2, figsize=(12, 4))
# Study 1 ----------------------------------------------------------------
# Plot observed bin counts
c1.plot(kind="bar", ax=ax[0], alpha=0.5)
# Plot posterior predictive
ppc.posterior_predictive.plot.scatter(
x="counts1_dim_0", y="counts1", color="k", alpha=0.2, ax=ax[0]
)
# Formatting
ax[0].set_xticklabels([f"bin {n}" for n in range(len(c1))])
ax[0].set_title("Posterior predictive: Study 1")
# Study 2 ----------------------------------------------------------------
ax[1].hist(ppc.posterior_predictive.y.values.flatten(), 50, density=True, alpha=0.5)
ax[1].set(title="Posterior predictive: Study 2", xlabel="$x$", ylabel="density");
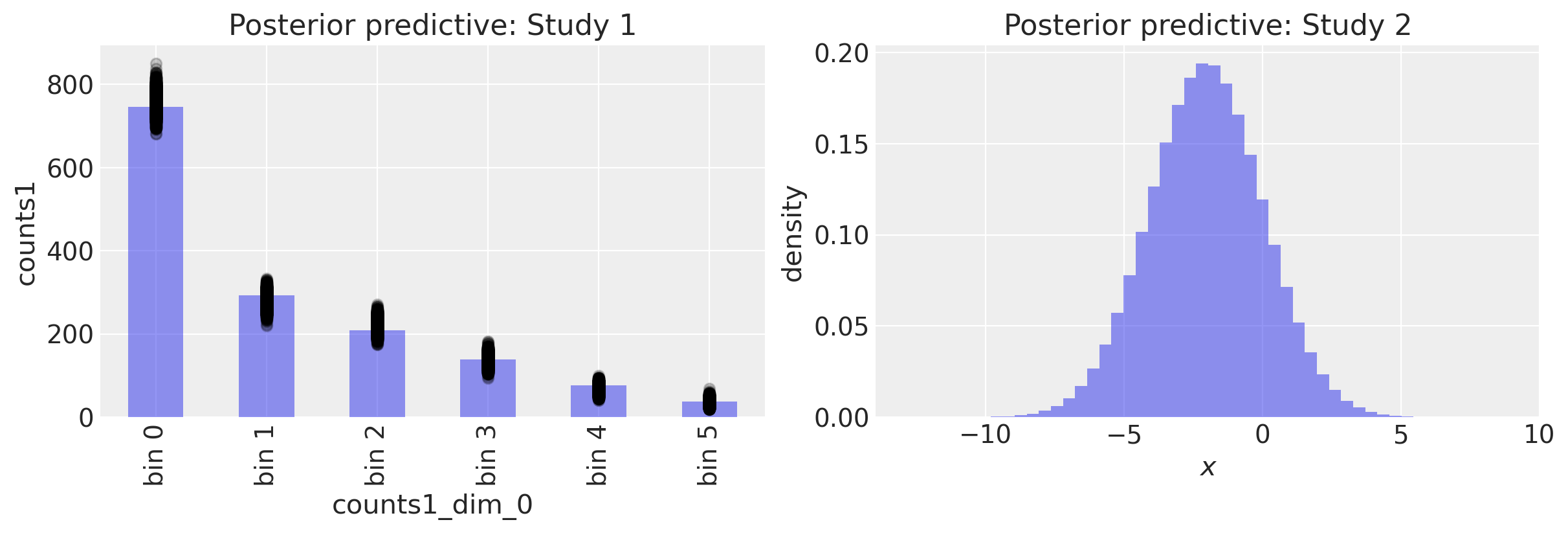
我们可以计算研究 2 的后验预测分布的平均值和标准差,并看到它们接近我们的真实参数。
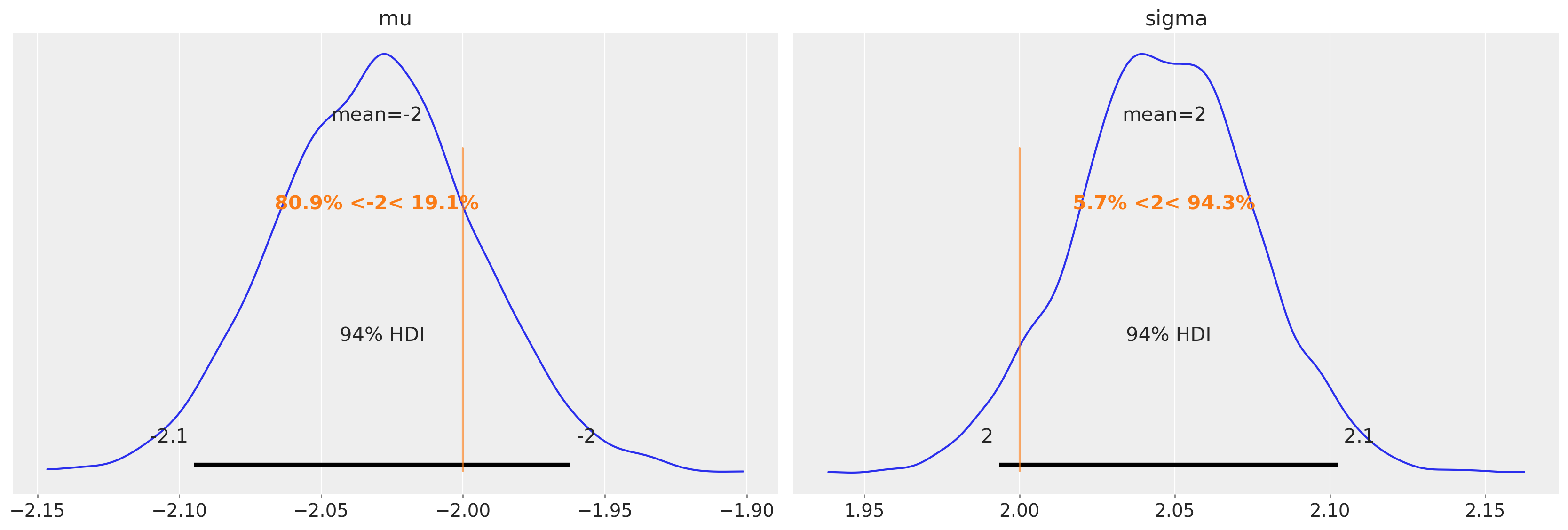
恢复参数#
最后,我们可以检查参数的后验估计值,并看到这里的估计值非常准确。
az.plot_posterior(trace4, var_names=["mu", "sigma"], ref_val=[true_mu, true_sigma]);
示例 5:分层估计#
之前的示例都假设研究 1 和研究 2 的数据是从同一人口中采样的。虽然对于我们的模拟数据来说,这实际上是正确的,但当我们使用真实数据时,我们无法知道这一点。因此,能够提出问题“研究 1 和研究 2 的数据看起来是否来自同一人口?”可能会很有用。
我们可以使用相同的基本方法来做到这一点 - 我们可以像以前一样估计人口级别参数,但现在我们可以添加研究级别参数估计值。这将是我们模型中人口级别参数和观察结果之间的新分层层。
模型规范#
这次,因为我们要进入更复杂的模型,我们将使用 coords 来告诉 PyMC 变量的维度。这会馈送到以后验样本的形式输出,这使得以后处理后验样本以进行统计或可视化目的时更加容易。
with pm.Model(coords=coords) as model5:
# Population level priors
mu_pop_mean = pm.Normal("mu_pop_mean", 0.0, 1.0)
mu_pop_variance = pm.HalfNormal("mu_pop_variance", sigma=1)
sigma_pop_mean = pm.HalfNormal("sigma_pop_mean", sigma=1)
sigma_pop_sigma = pm.HalfNormal("sigma_pop_sigma", sigma=1)
# Study level priors
mu = pm.Normal("mu", mu=mu_pop_mean, sigma=mu_pop_variance, dims="study")
sigma = pm.TruncatedNormal(
"sigma", mu=sigma_pop_mean, sigma=sigma_pop_sigma, lower=0, dims="study"
)
# Study 1
probs1 = pm.math.exp(pm.logcdf(pm.Normal.dist(mu=mu[0], sigma=sigma[0]), d1))
probs1 = pt.extra_ops.diff(pm.math.concatenate([np.array([0]), probs1, np.array([1])]))
probs1 = pm.Deterministic("normal1_cdf", probs1, dims="bin1")
# Study 2
probs2 = pm.math.exp(pm.logcdf(pm.Normal.dist(mu=mu[1], sigma=sigma[1]), d2))
probs2 = pt.extra_ops.diff(pm.math.concatenate([np.array([0]), probs2, np.array([1])]))
probs2 = pm.Deterministic("normal2_cdf", probs2, dims="bin2")
# Likelihood
pm.Multinomial("counts1", p=probs1, n=c1.sum(), observed=c1.values, dims="bin1")
pm.Multinomial("counts2", p=probs2, n=c2.sum(), observed=c2.values, dims="bin2")
pm.model_to_graphviz(model5)

上面的模型很好,但是按原样运行此模型会导致采样过程中出现数百个发散(您可以从 使用发散诊断有偏推断 笔记本中找到有关发散的更多信息)。虽然我们不会深入探讨此处的原因,但长话短说,高斯居中会将病理引入我们的对数似然空间,从而使 MCMC 采样器难以工作。首先,我们删除了 sigma 的人口级别估计,只保留了研究级别先验。我们使用 Gamma 分布来避免任何零值。其次,使用非中心重新参数化来指定 mu。这并不能完全解决问题,但它确实大大减少了发散的数量。
with pm.Model(coords=coords) as model5:
# Population level priors
mu_pop_mean = pm.Normal("mu_pop_mean", 0.0, 1.0)
mu_pop_variance = pm.HalfNormal("mu_pop_variance", sigma=1)
# Study level priors
x = pm.Normal("x", dims="study")
mu = pm.Deterministic("mu", x * mu_pop_variance + mu_pop_mean, dims="study")
sigma = pm.Gamma("sigma", alpha=2, beta=1, dims="study")
# Study 1
probs1 = pm.math.exp(pm.logcdf(pm.Normal.dist(mu=mu[0], sigma=sigma[0]), d1))
probs1 = pt.extra_ops.diff(pm.math.concatenate([np.array([0]), probs1, np.array([1])]))
probs1 = pm.Deterministic("normal1_cdf", probs1, dims="bin1")
# Study 2
probs2 = pm.math.exp(pm.logcdf(pm.Normal.dist(mu=mu[1], sigma=sigma[1]), d2))
probs2 = pt.extra_ops.diff(pm.math.concatenate([np.array([0]), probs2, np.array([1])]))
probs2 = pm.Deterministic("normal2_cdf", probs2, dims="bin2")
# Likelihood
pm.Multinomial("counts1", p=probs1, n=c1.sum(), observed=c1.values, dims="bin1")
pm.Multinomial("counts2", p=probs2, n=c2.sum(), observed=c2.values, dims="bin2")
pm.model_to_graphviz(model5)

with model5:
trace5 = pm.sample(tune=2000, target_accept=0.99)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [mu_pop_mean, mu_pop_variance, x, sigma]
Sampling 4 chains for 2_000 tune and 1_000 draw iterations (8_000 + 4_000 draws total) took 161 seconds.
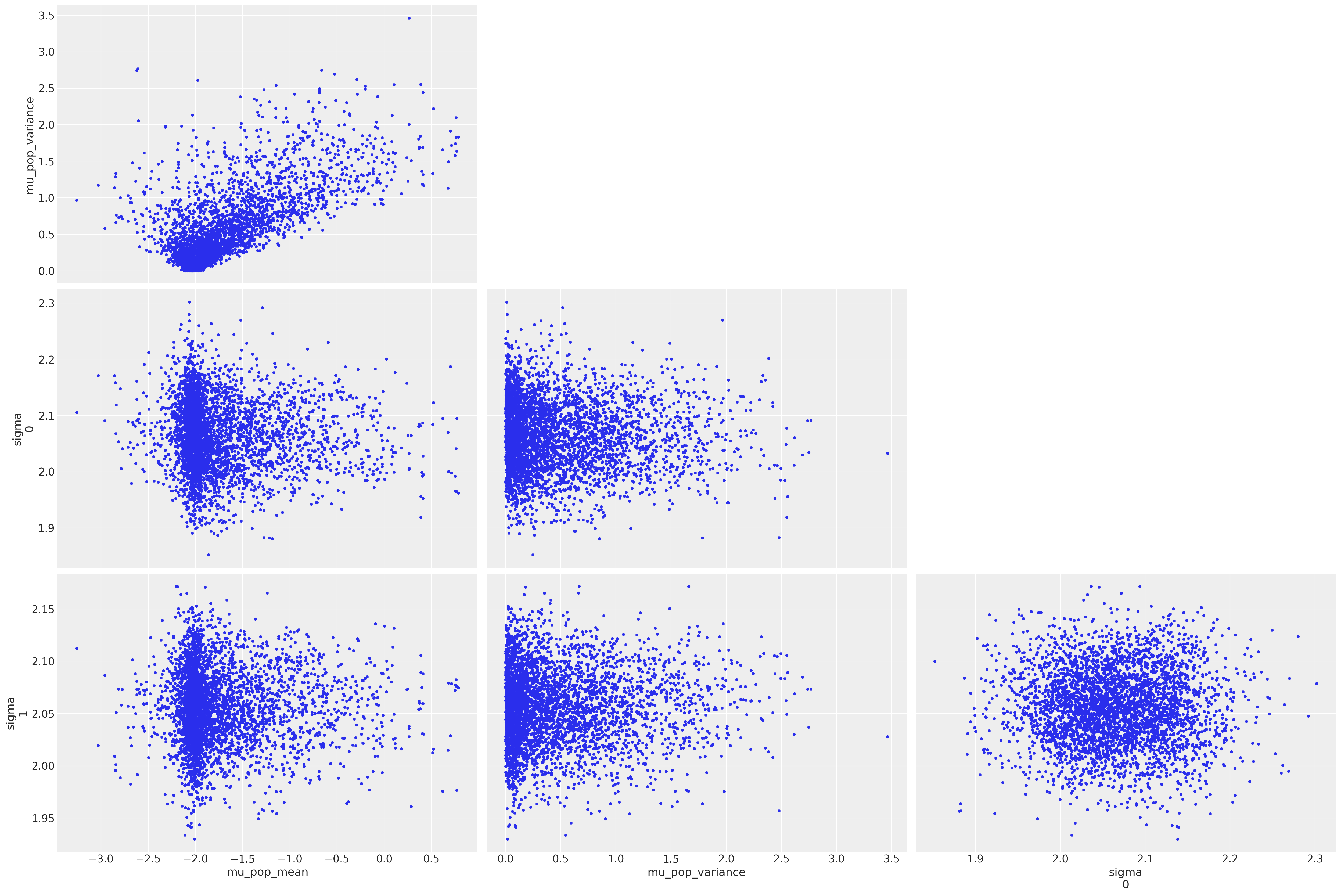
我们可以看到,尽管我们付出了努力,但仍然会得到一些发散。绘制样本并突出显示发散表明(从左上角的子图中),我们的模型正遭受漏斗问题的困扰
az.plot_pair(
trace5, var_names=["mu_pop_mean", "mu_pop_variance", "sigma"], coords=coords, divergences=True
);
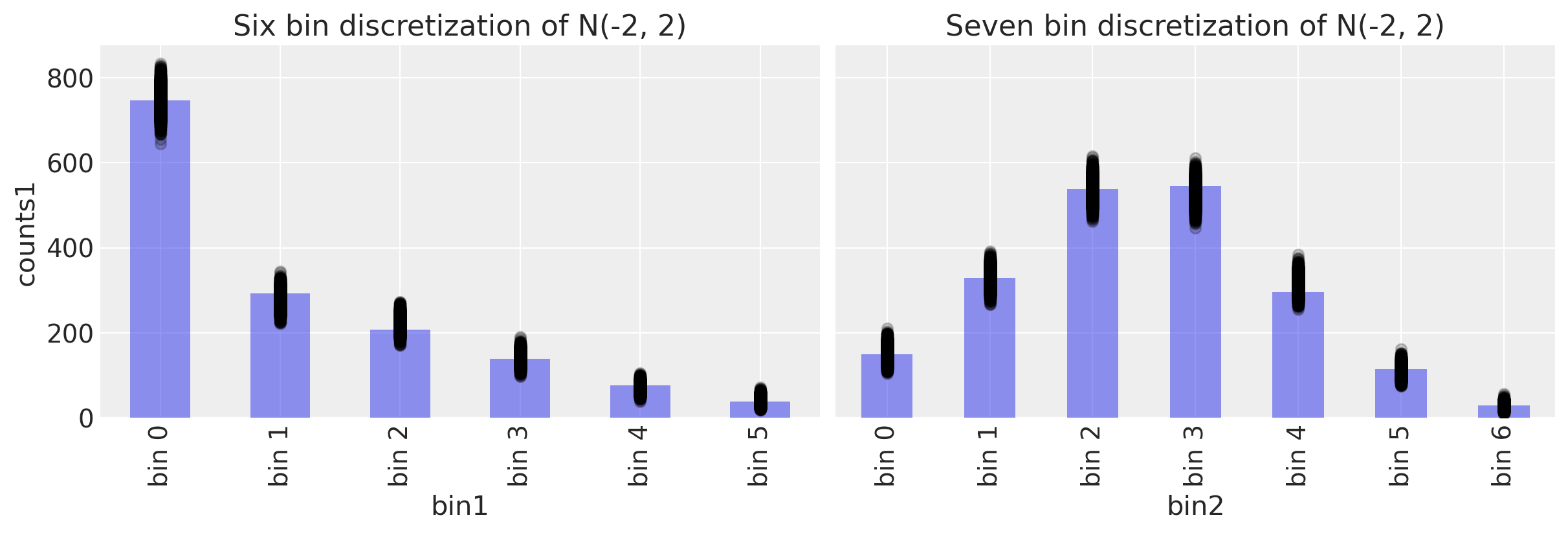
后验预测检查#
with model5:
ppc = pm.sample_posterior_predictive(trace5)
fig, ax = plt.subplots(1, 2, figsize=(12, 4), sharey=True)
# Study 1 ----------------------------------------------------------------
# Plot observed bin counts
c1.plot(kind="bar", ax=ax[0], alpha=0.5)
# Plot posterior predictive
ppc.posterior_predictive.plot.scatter(x="bin1", y="counts1", color="k", alpha=0.2, ax=ax[0])
# Formatting
ax[0].set_xticklabels([f"bin {n}" for n in range(len(c1))])
ax[0].set_title("Six bin discretization of N(-2, 2)")
# Study 1 ----------------------------------------------------------------
# Plot observed bin counts
c2.plot(kind="bar", ax=ax[1], alpha=0.5)
# Plot posterior predictive
ppc.posterior_predictive.plot.scatter(x="bin2", y="counts2", color="k", alpha=0.2, ax=ax[1])
# Formatting
ax[1].set_xticklabels([f"bin {n}" for n in range(len(c2))])
ax[1].set_title("Seven bin discretization of N(-2, 2)")
Text(0.5, 1.0, 'Seven bin discretization of N(-2, 2)')
检查后验#
研究级别均值或标准差是否有差异的证据?
fig, ax = plt.subplots(1, 2, figsize=(10, 3))
diff = trace5.posterior.mu.sel(study=0) - trace5.posterior.mu.sel(study=1)
az.plot_posterior(diff, ref_val=0, ax=ax[0])
ax[0].set(title="difference in study level mean estimates")
diff = trace5.posterior.sigma.sel(study=0) - trace5.posterior.sigma.sel(study=1)
az.plot_posterior(diff, ref_val=0, ax=ax[1])
ax[1].set(title="difference in study level std estimate");
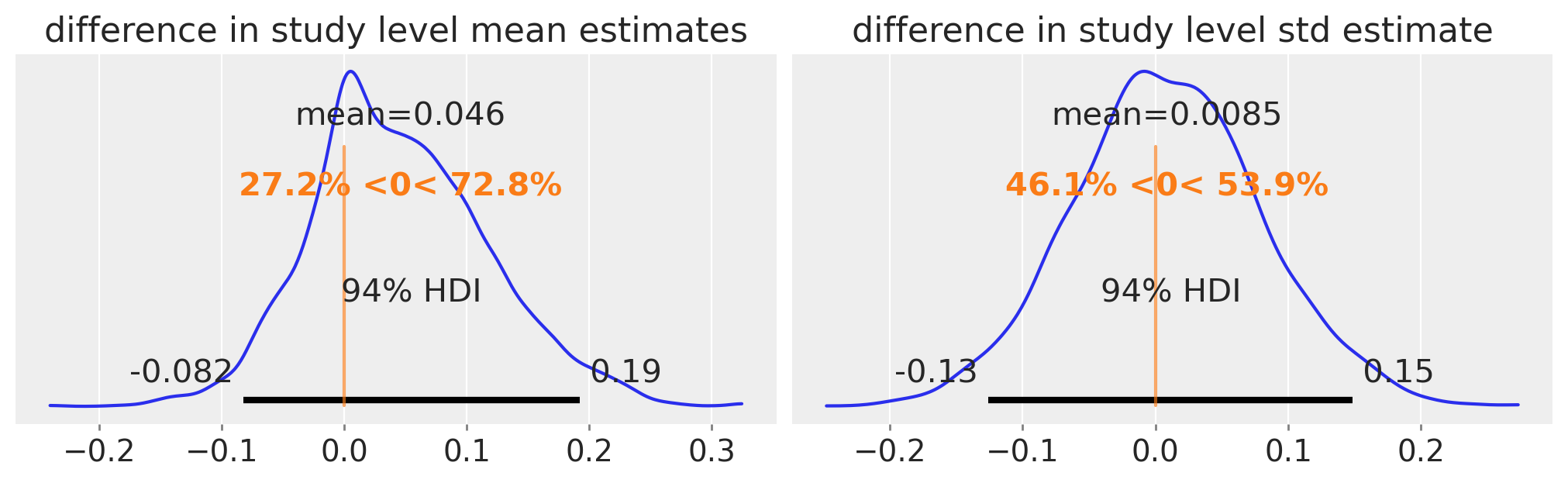
没有令人信服的证据表明人口级别均值和标准差之间存在差异。
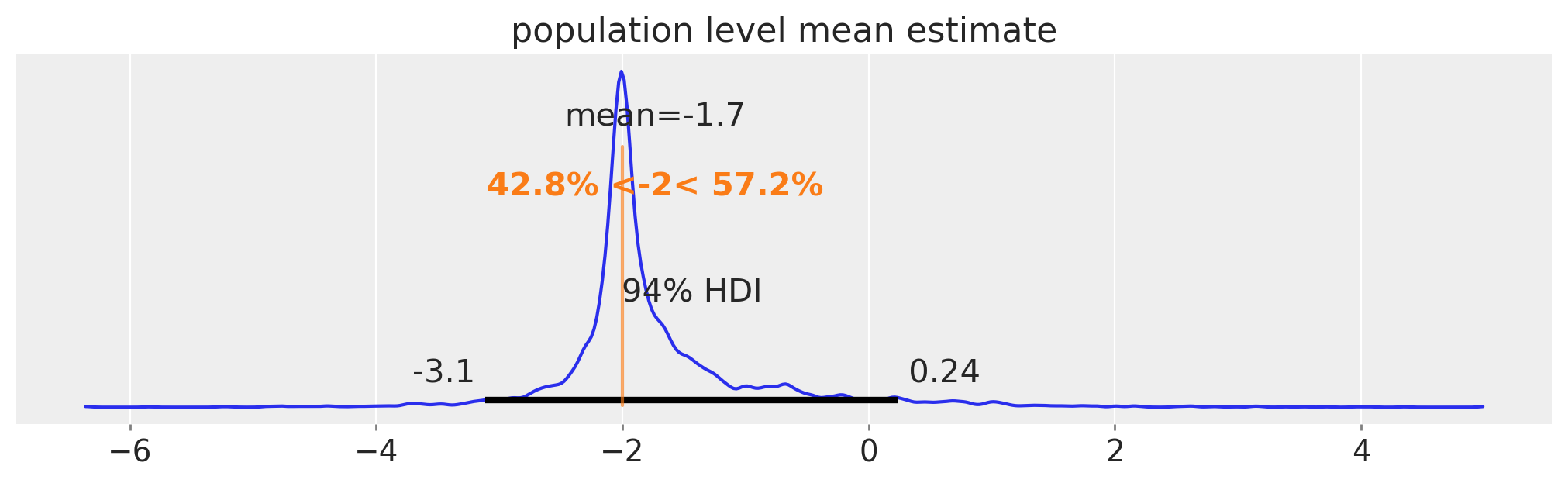
均值参数中的人口级别估计值。在此重新参数化模型中,没有 sigma 的人口级别估计值。
fig, ax = plt.subplots(figsize=(10, 3))
pop_mean = rng.normal(
trace5.posterior.mu_pop_mean.values.flatten(), trace5.posterior.mu_pop_variance.values.flatten()
)
az.plot_posterior(pop_mean, ax=ax, ref_val=true_mu)
ax.set(title="population level mean estimate");
另一种可能的解决方案是从第 1 组和第 2 组独立推断研究级别参数,然后寻找这些参数不同的任何证据。采用这种方法效果很好,没有看到任何发散,尽管这种方法偏离了我们进行人口级别推断的核心目标。我们没有完全完成此示例,而是包含了代码,以防它对任何人的用例有用。
with pm.Model(coords=coords) as model5:
# Study level priors
mu = pm.Normal("mu", dims='study')
sigma = pm.HalfNormal("sigma", dims='study')
# Study 1
probs1 = pm.math.exp(pm.logcdf(pm.Normal.dist(mu=mu[0], sigma=sigma[0]), d1))
probs1 = pt.extra_ops.diff(pm.math.concatenate([np.array([0]), probs1, np.array([1])]))
probs1 = pm.Deterministic("normal1_cdf", probs1, dims='bin1')
# Study 2
probs2 = pm.math.exp(pm.logcdf(pm.Normal.dist(mu=mu[1], sigma=sigma[1]), d2))
probs2 = pt.extra_ops.diff(pm.math.concatenate([np.array([0]), probs2, np.array([1])]))
probs2 = pm.Deterministic("normal2_cdf", probs2, dims='bin2')
# Likelihood
pm.Multinomial("counts1", p=probs1, n=c1.sum(), observed=c1.values, dims='bin1')
pm.Multinomial("counts2", p=probs2, n=c2.sum(), observed=c2.values, dims='bin2')
示例 6:非正态分布#
理论上,我们使用的方法非常通用。它的依赖项通常是明确指定的
参数分布
该分布支持上的已知切点,用于对我们的数据进行分箱
每个箱子的计数(以及因此的比例)
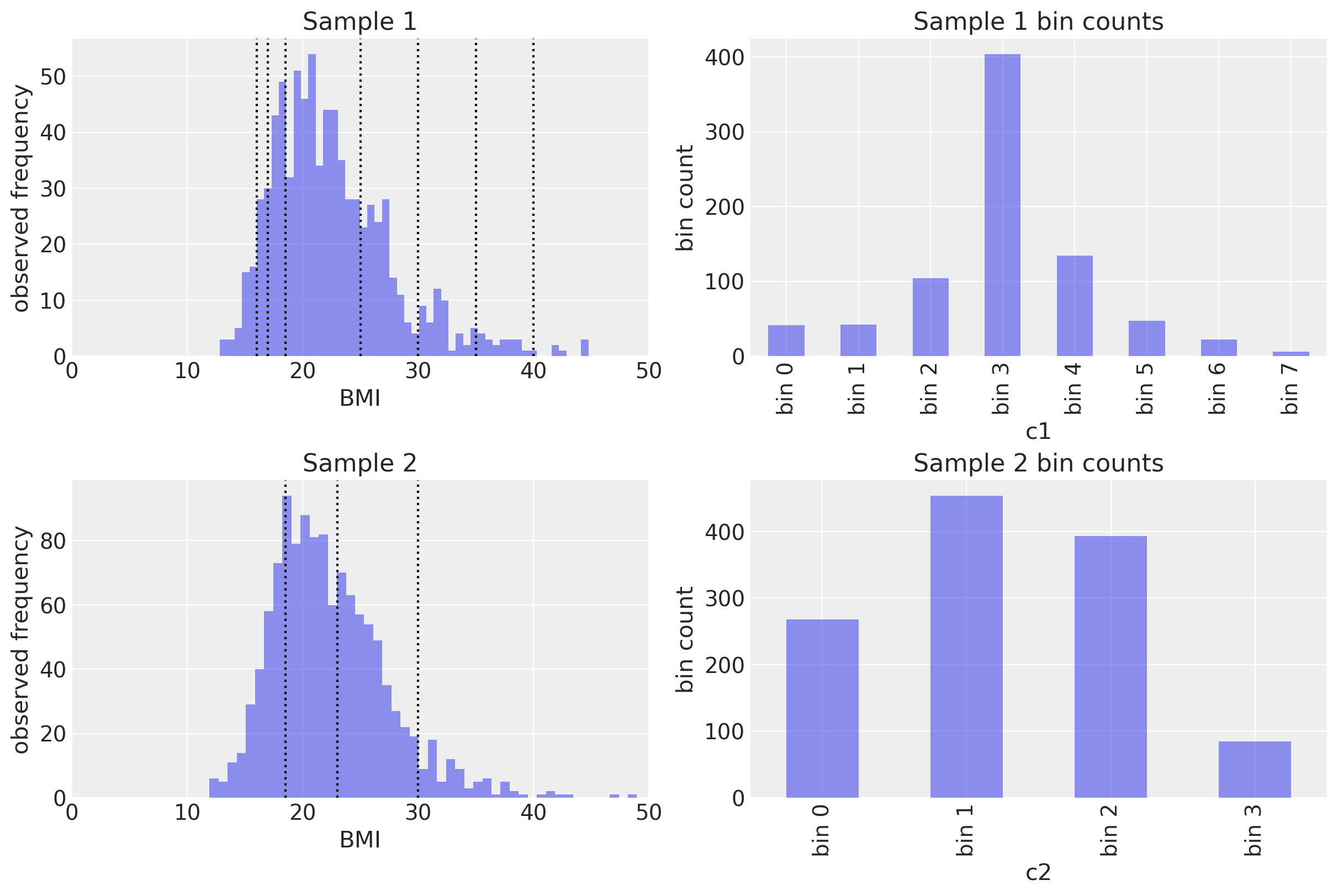
我们现在将凭经验验证是否可以使用相同的方法恢复其他分布的参数。我们将根据 2 项假设(模拟)研究来近似 身体质量指数 (BMI) 的分布。
在第一项研究中,虚构的研究人员使用了一组阈值,这些阈值使他们获得了许多类别的
体重不足(严重消瘦):\(< 16\)
体重不足(中度消瘦):\(16 - 17\)
体重不足(轻度消瘦):\(17 - 18.5\)
正常范围:\(18.5 - 25\)
超重(肥胖前期):\(25 - 30\)
肥胖(I 级):\(30 - 35\)
肥胖(II 级):\(35 - 40\)
肥胖(III 级):\(\ge 40\)
第二组研究人员使用了香港医院管理局推荐的分类方案
体重不足(不健康):\(< 18.5\)
正常范围(健康):\(18.5 - 23\)
超重 I(有风险):\(23 - 25\)
超重 II(中度肥胖):\(25 - 30\)
超重 III(重度肥胖):\(\ge 30\)
我们假设真实的底层 BMI 分布是耿贝尔分布,其 mu 和 beta 参数分别为 20 和 4。
# True underlying BMI distribution
true_mu, true_beta = 20, 4
BMI = pm.Gumbel.dist(mu=true_mu, beta=true_beta)
# Generate two different sets of random samples from the same Gaussian.
x1 = pm.draw(BMI, 800)
x2 = pm.draw(BMI, 1200)
# Calculate bin counts
c1 = data_to_bincounts(x1, d1)
c2 = data_to_bincounts(x2, d2)
fig, ax = plt.subplots(2, 2, figsize=(12, 8))
# First set of measurements ----------------------------------------------
ax[0, 0].hist(x1, 50, alpha=0.5)
for cut in d1:
ax[0, 0].axvline(cut, color="k", ls=":")
# Plot observed bin counts
c1.plot(kind="bar", ax=ax[0, 1], alpha=0.5)
ax[0, 1].set_xticklabels([f"bin {n}" for n in range(len(c1))])
ax[0, 1].set(title="Sample 1 bin counts", xlabel="c1", ylabel="bin count")
# Second set of measuremsnts ---------------------------------------------
ax[1, 0].hist(x2, 50, alpha=0.5)
for cut in d2:
ax[1, 0].axvline(cut, color="k", ls=":")
# Plot observed bin counts
c2.plot(kind="bar", ax=ax[1, 1], alpha=0.5)
ax[1, 1].set_xticklabels([f"bin {n}" for n in range(len(c2))])
ax[1, 1].set(title="Sample 2 bin counts", xlabel="c2", ylabel="bin count")
# format axes ------------------------------------------------------------
ax[0, 0].set(xlim=(0, 50), xlabel="BMI", ylabel="observed frequency", title="Sample 1")
ax[1, 0].set(xlim=(0, 50), xlabel="BMI", ylabel="observed frequency", title="Sample 2");
模型规范#
这是上面示例 3 的变体。唯一的更改是
更新概率分布以匹配我们的目标(耿贝尔分布)
确保我们为我们的目标分布指定先验,这对于我们的领域知识来说是合适的。
with pm.Model() as model6:
mu = pm.Normal("mu", 20, 5)
beta = pm.HalfNormal("beta", 10)
probs1 = pm.math.exp(pm.logcdf(pm.Gumbel.dist(mu=mu, beta=beta), d1))
probs1 = pt.extra_ops.diff(pm.math.concatenate([np.array([0]), probs1, np.array([1])]))
probs1 = pm.Deterministic("gumbel_cdf1", probs1)
probs2 = pm.math.exp(pm.logcdf(pm.Gumbel.dist(mu=mu, beta=beta), d2))
probs2 = pt.extra_ops.diff(pm.math.concatenate([np.array([0]), probs2, np.array([1])]))
probs2 = pm.Deterministic("gumbel_cdf2", probs2)
pm.Multinomial("counts1", p=probs1, n=c1.sum(), observed=c1.values)
pm.Multinomial("counts2", p=probs2, n=c2.sum(), observed=c2.values)
pm.model_to_graphviz(model6)

with model6:
trace6 = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [mu, beta]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 13 seconds.
The acceptance probability does not match the target. It is 0.8809, but should be close to 0.8. Try to increase the number of tuning steps.
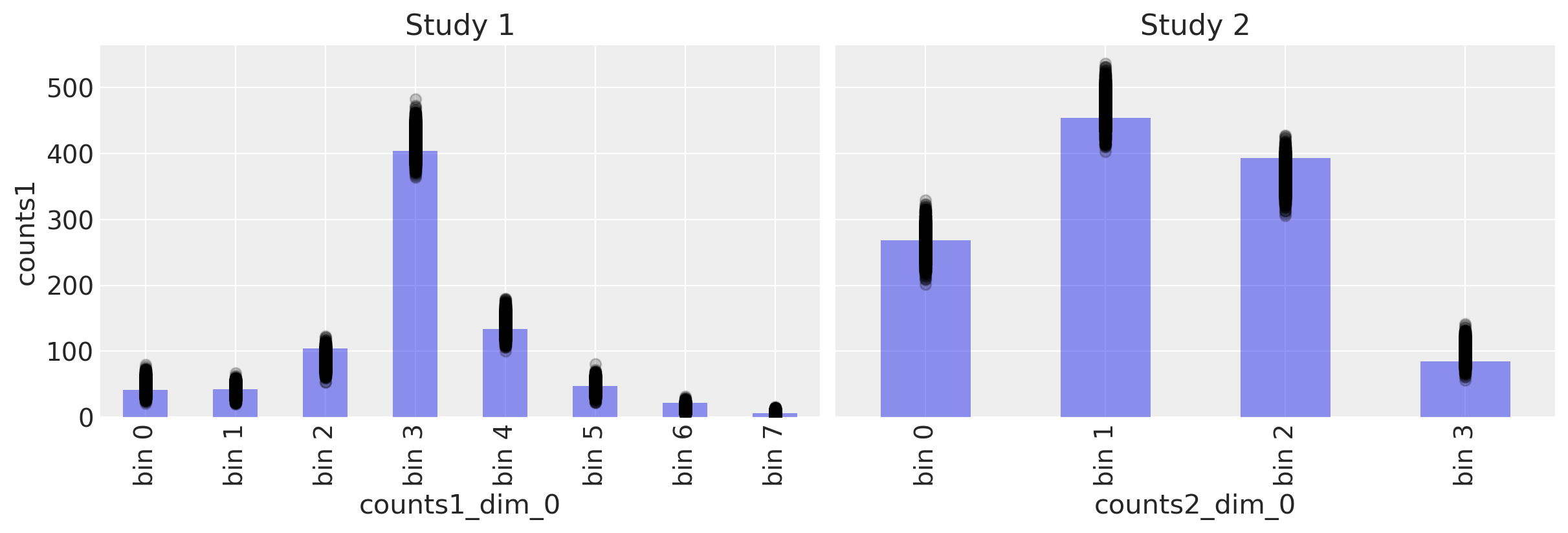
后验预测检查#
with model6:
ppc = pm.sample_posterior_predictive(trace6)
fig, ax = plt.subplots(1, 2, figsize=(12, 4), sharey=True)
# Study 1 ----------------------------------------------------------------
# Plot observed bin counts
c1.plot(kind="bar", ax=ax[0], alpha=0.5)
# Plot posterior predictive
ppc.posterior_predictive.plot.scatter(
x="counts1_dim_0", y="counts1", color="k", alpha=0.2, ax=ax[0]
)
# Formatting
ax[0].set_xticklabels([f"bin {n}" for n in range(len(c1))])
ax[0].set_title("Study 1")
# Study 1 ----------------------------------------------------------------
# Plot observed bin counts
c2.plot(kind="bar", ax=ax[1], alpha=0.5)
# Plot posterior predictive
ppc.posterior_predictive.plot.scatter(
x="counts2_dim_0", y="counts2", color="k", alpha=0.2, ax=ax[1]
)
# Formatting
ax[1].set_xticklabels([f"bin {n}" for n in range(len(c2))])
ax[1].set_title("Study 2")
Text(0.5, 1.0, 'Study 2')
恢复参数#
az.plot_posterior(trace6, var_names=["mu", "beta"], ref_val=[true_mu, true_beta]);
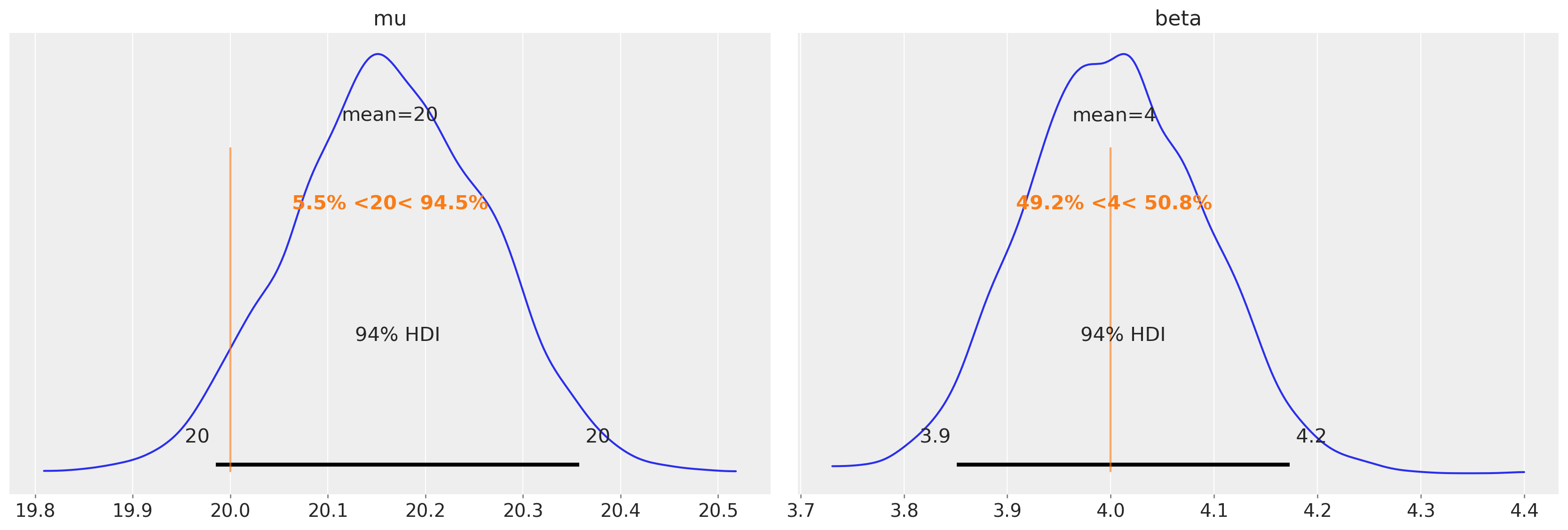
我们可以看到,我们能够很好地恢复已知的底层 BMI 人口参数。
如果我们有兴趣测试研究 1 和研究 2 中的 BMI 分布是否存在任何差异,那么我们可以简单地采用示例 6 中的模型,并像本示例中所做的那样,对其进行调整以使用我们所需的目标分布进行操作。
结论#
如您所见,这种估计高斯分布和非高斯分布的已知参数的方法效果很好。虽然这些示例已应用于合成数据,但进行此类参数恢复研究至关重要。如果我们尝试从计数中恢复人口级别参数,并且在我们知道真实情况时无法做到这一点,那么这将表明该方法不可信。但是,各种参数恢复示例表明,我们实际上可以从分箱数据和不同分箱数据中准确恢复人口级别参数。
此处需要注意的一个关键技术点是,当我们传入观察到的计数时,它们应该完全按照 CDF 顺序排列。此处未显示的是我们打乱计数顺序的实验;在这些实验中,底层分布参数的估计是不正确的。
我们在此处介绍了一系列不同的示例,这些示例清楚地表明,可以轻松地将通用方法调整为面临的特定情况或研究问题。这些方法应该很容易适应新的但相关的数据科学情况。
水印#
%load_ext watermark
%watermark -n -u -v -iv -w -p aeppl,xarray
Last updated: Sat Jun 04 2022
Python implementation: CPython
Python version : 3.10.4
IPython version : 8.3.0
aeppl : 0.0.27
xarray: 2022.3.0
pandas : 1.4.2
seaborn : 0.11.2
matplotlib: 3.5.1
pymc : 4.0.0b6
arviz : 0.12.1
numpy : 1.22.4
pytensor : 2.5.1
Watermark: 2.3.1
许可声明#
本示例库中的所有笔记本均根据 MIT 许可证 提供,该许可证允许修改和再分发以用于任何用途,前提是保留版权和许可声明。
引用 PyMC 示例#
要引用此笔记本,请使用 Zenodo 为 pymc-examples 存储库提供的 DOI。
重要提示
许多笔记本都改编自其他来源:博客、书籍……在这种情况下,您也应该引用原始来源。
另请记住引用您的代码使用的相关库。
这是一个 bibtex 中的引用模板
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
一旦呈现,它可能看起来像