


贝叶斯因子和边际似然#
import arviz as az
import numpy as np
import pymc as pm
from matplotlib import pyplot as plt
from matplotlib.ticker import FormatStrFormatter
from scipy.special import betaln
from scipy.stats import beta
print(f"Running on PyMC v{pm.__version__}")
Running on PyMC v5.0.0
az.style.use("arviz-darkgrid")
比较模型的“贝叶斯方法”是计算每个模型的边际似然 \(p(y \mid M_k)\),即 观测数据 \(y\) 在给定模型 \(M_k\) 的条件下的概率。这个量,边际似然,只是贝叶斯定理的归一化常数。如果我们写出贝叶斯定理并明确所有推断都依赖于模型这一事实,我们就可以看到这一点。
其中
\(y\) 是数据
\(\theta\) 是参数
\(M_k\) 是 K 个竞争模型中的一个模型
通常,在进行推断时,我们不需要计算这个归一化常数,因此在实践中,我们经常计算后验,直到一个常数因子,即
然而,对于模型比较和模型平均,边际似然是一个重要的量。虽然,这不是执行这些任务的唯一方法,您可以阅读关于使用替代方法进行模型平均和模型选择的资料,此处、那里 和 其他地方。实际上,与使用边际似然相比,这些替代方法通常是更好的选择。
贝叶斯模型选择#
如果我们的主要目标是从一组模型中选择一个最佳模型,我们可以直接选择具有最大 \(p(y \mid M_k)\) 的模型。如果所有模型都被假定具有相同的先验概率,这完全没问题。否则,我们必须考虑到并非所有模型在先验上都同样可能,并计算
有时,主要目标不仅仅是保留一个模型,而是比较模型以确定哪些模型更可能以及可能性有多大。这可以使用贝叶斯因子来实现
即,两个模型的边际似然之间的比率。BF 越大,分子中的模型(在本例中为 \(M_0\))就越好。为了方便解释 BF,Harold Jeffreys 提出了一个用于解释贝叶斯因子的尺度,具有支持或强度的级别。这只是一种将数字转化为文字的方式。
1-3:轶事
3-10:中等
10-30:强
30-100:非常强
\(>\) 100:极端
请注意,如果您得到的数字低于 1,那么支持的是分母中的模型,这些情况的表格也可用。当然,您也可以只取上表中的值的倒数,或者取 BF 值的倒数,您就可以了。
非常重要的是要记住,这些规则只是惯例,充其量只是简单的指南。结果应始终放在我们问题的背景下,并应附有足够的细节,以便其他人可以自行评估他们是否同意我们的结论。在粒子物理学、法庭或疏散城镇以防止数百人死亡的情况下,提出主张所需的证据是不一样的。
贝叶斯模型平均#
模型平均不是从一组候选模型中选择一个单一模型,而是通过平均候选模型来获得一个元模型。这种方法的贝叶斯版本通过其边际后验概率来加权每个模型。
如果先验是正确的,并且正确的模型是我们集合中的 \(M_k\) 模型之一,这是平均模型的最佳方法。否则,贝叶斯模型平均将渐近地选择比较模型集中最接近 Kullback-Leibler 散度 的那个单一模型。
查看此 示例,作为执行模型平均的另一种方式。
一些评论#
现在我们将简要讨论关于边际似然的一些关键事实
优点
奥卡姆剃刀包含在内:具有更多参数的模型比具有更少参数的模型具有更大的惩罚。直观的原因是参数数量越多,先验相对于似然的分散就越大。
缺点
计算边际似然通常是一项艰巨的任务,因为它是在高维参数空间上对高度可变函数进行积分。一般来说,这个积分需要使用或多或少复杂的方法进行数值求解。
不足
边际似然敏感地依赖于每个模型中参数的指定先验 \(p(\theta_k \mid M_k)\)。
请注意,优点和不足是相关的。使用边际似然来比较模型是一个好主意,因为复杂模型的惩罚已经包含在内(从而防止我们过度拟合),同时,先验的变化会影响边际似然的计算。乍一看,这听起来有点傻;我们已经知道先验会影响计算(否则我们可以简单地避免它们),但这里的重点是敏感地这个词。我们说的是先验的变化,这将使 \(\theta\) 的推断或多或少保持不变,但可能会对边际似然的值产生重大影响。
计算贝叶斯因子#
除了某些受限模型外,边际似然通常不可用闭式解。因此,已经设计了许多方法来计算边际似然和导出的贝叶斯因子,其中一些方法非常简单且 幼稚,以至于在实践中效果非常差。大多数有用的方法最初是在统计力学领域提出的。这种联系的解释是,边际似然类似于统计物理学中的一个中心量,称为配分函数,而配分函数又与另一个非常重要的量自由能密切相关。统计力学和贝叶斯推断之间的许多联系在 此处 进行了总结。
使用分层模型#
贝叶斯因子的计算可以构建为分层模型,其中高层参数是分配给每个模型的索引,并从类别分布中采样。换句话说,我们同时对两个(或更多)竞争模型执行推断,我们使用一个离散的虚拟变量在模型之间跳转。我们花费在采样每个模型上的时间量与 \(p(M_k \mid y)\) 成正比。
以这种方式计算贝叶斯因子时,一些常见的问题是,如果一个模型比另一个模型更好,根据定义,我们将花费更多时间从该模型中采样,而不是从另一个模型中采样。这可能导致不准确,因为我们将对不太可能的模型进行欠采样。另一个问题是,即使在参数未用于拟合该模型时,参数的值也会更新。也就是说,当选择模型 0 时,模型 1 中的参数会更新,但由于它们不用于解释数据,因此它们仅受到先验的限制。如果先验过于模糊,则当我们选择模型 1 时,参数值可能与先前接受的值相差太远,因此步骤被拒绝。因此,我们最终遇到了采样问题。
如果我们发现这些问题,我们可以尝试通过对我们的模型进行两项修改来改进采样
理想情况下,如果两个模型被同等访问,我们可以更好地采样两个模型,因此我们可以调整每个模型的先验,以有利于不太有利的模型,而不利于最有利的模型。这不会影响贝叶斯因子的计算,因为我们必须将先验包含在计算中。
使用伪先验,正如 Kruschke 和其他人建议的那样。这个想法很简单:如果问题是参数在它们所属的模型未被选择时不受限制地漂移,那么一种解决方案是尝试人为地限制它们,但仅在不使用时!您可以在 Kruschke 在他的书中使用过的模型中找到使用伪先验的示例,并且 移植 到 Python/PyMC3。
如果您想了解更多关于这种计算边际似然的方法,请参阅 《Doing Bayesian Data Analysis》第 12 章。本章还讨论了如何使用贝叶斯因子作为经典假设检验的贝叶斯替代方法。
解析方法#
对于某些模型,如 beta-二项模型(又名抛硬币模型),我们可以解析地计算边际似然。如果我们把这个模型写成
边际似然将是
其中
\(B\) 是 beta 函数,不要与 \(Beta\) 分布混淆
\(n\) 是试验次数
\(h\) 是成功次数
由于我们只关心两个不同模型下(对于相同数据)边际似然的相对值,我们可以省略二项式系数 \(\binom {n}{h}\),因此我们可以写成
这个表达式已在下面的单元格中编码,但有一个转折。我们将使用 betaln 函数而不是 beta 函数,这样做是为了防止下溢。
def beta_binom(prior, y):
"""
Compute the marginal likelihood, analytically, for a beta-binomial model.
prior : tuple
tuple of alpha and beta parameter for the prior (beta distribution)
y : array
array with "1" and "0" corresponding to the success and fails respectively
"""
alpha, beta = prior
h = np.sum(y)
n = len(y)
p_y = np.exp(betaln(alpha + h, beta + n - h) - betaln(alpha, beta))
return p_y
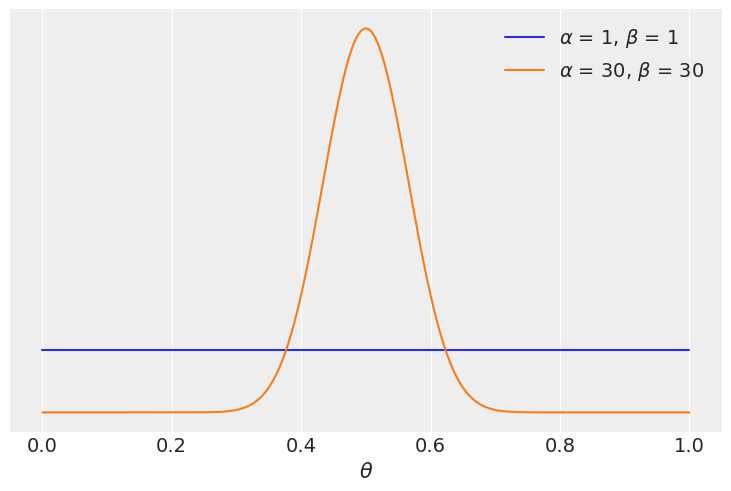
本例的数据包括 100 次“抛硬币”,并且观察到相同数量的“正面”和“反面”。我们将比较两个模型,一个具有均匀先验,另一个具有围绕 \(\theta = 0.5\) 的更集中的先验
y = np.repeat([1, 0], [50, 50]) # 50 "heads" and 50 "tails"
priors = ((1, 1), (30, 30))
for a, b in priors:
distri = beta(a, b)
x = np.linspace(0, 1, 300)
x_pdf = distri.pdf(x)
plt.plot(x, x_pdf, label=rf"$\alpha$ = {a:d}, $\beta$ = {b:d}")
plt.yticks([])
plt.xlabel("$\\theta$")
plt.legend()
以下单元格返回贝叶斯因子
BF = beta_binom(priors[1], y) / beta_binom(priors[0], y)
print(round(BF))
5
我们看到具有更集中的先验 \(\text{beta}(30, 30)\) 的模型比具有更广泛的先验 \(\text{beta}(1, 1)\) 的模型具有 \(\approx 5\) 倍的支持。除了精确的数值之外,这不应该令人惊讶,因为最受欢迎模型的先验集中在 \(\theta = 0.5\) 附近,并且数据 \(y\) 具有相等数量的正面和反面,与 \(\theta\) 在 0.5 附近的值一致。
序贯蒙特卡洛#
序贯蒙特卡洛 采样器是一种基本通过一系列从先验到后验的连续退火序列来进展的方法。这个过程的一个很好的副产品是我们得到了边际似然的估计。实际上,出于数值原因,返回的值是对数边际似然(这有助于避免下溢)。
models = []
idatas = []
for alpha, beta in priors:
with pm.Model() as model:
a = pm.Beta("a", alpha, beta)
yl = pm.Bernoulli("yl", a, observed=y)
idata = pm.sample_smc(random_seed=42)
models.append(model)
idatas.append(idata)
Initializing SMC sampler...
Sampling 4 chains in 4 jobs
/home/oriol/bin/miniconda3/envs/releases/lib/python3.10/site-packages/arviz/data/base.py:221: UserWarning: More chains (4) than draws (3). Passed array should have shape (chains, draws, *shape)
warnings.warn(
Initializing SMC sampler...
Sampling 4 chains in 4 jobs
/home/oriol/bin/miniconda3/envs/releases/lib/python3.10/site-packages/arviz/data/base.py:221: UserWarning: More chains (4) than draws (1). Passed array should have shape (chains, draws, *shape)
warnings.warn(
5.0
正如我们从前面的单元格中看到的那样,SMC 给出的答案与解析计算基本相同!
注意:在上面的单元格中,我们计算了一个差值(而不是除法),因为我们是在对数尺度上,出于同样的原因,我们在返回结果之前取指数。最后,我们计算均值的原因是,我们每个链获得一个对数边际似然值。
使用 SMC 计算(对数)边际似然的优点是,我们可以将其用于更广泛的模型,因为不再需要闭式表达式。我们为这种灵活性付出的代价是更昂贵的计算。请注意,SMC(使用 PyMC 中实现的独立 Metropolis 核)不如基于梯度的采样器(如 NUTS)高效或稳健。随着问题维度的增加,对后验和边际似然的更准确估计将需要更大数量的 draws,rank-plots 可以帮助诊断 SMC 的采样问题。
贝叶斯因子和推断#
到目前为止,我们已经使用贝叶斯因子来判断哪个模型似乎更擅长解释数据,我们得到其中一个模型比另一个模型好 \(\approx 5\) 倍。
但是我们从这些模型中得到的后验呢?它们有多大的不同?
az.summary(idatas[0], var_names="a", kind="stats").round(2)
| 均值 | 标准差 | hdi_3% | hdi_97% | |
|---|---|---|---|---|
| a | 0.5 | 0.05 | 0.4 | 0.59 |
az.summary(idatas[1], var_names="a", kind="stats").round(2)
| 均值 | 标准差 | hdi_3% | hdi_97% | |
|---|---|---|---|---|
| a | 0.5 | 0.04 | 0.42 | 0.57 |
我们可能会认为结果非常相似,我们对于 \(\theta\) 具有相同的均值,并且 model_0 的后验略宽,正如预期的那样,因为该模型具有更广泛的先验。我们还可以检查后验预测分布,看看它们有多相似。
ppc_0 = pm.sample_posterior_predictive(idatas[0], model=models[0]).posterior_predictive
ppc_1 = pm.sample_posterior_predictive(idatas[1], model=models[1]).posterior_predictive
Sampling: [yl]
Sampling: [yl]
_, ax = plt.subplots(figsize=(9, 6))
bins = np.linspace(0.2, 0.8, 8)
ax = az.plot_dist(
ppc_0["yl"].mean("yl_dim_2"),
label="model_0",
kind="hist",
hist_kwargs={"alpha": 0.5, "bins": bins},
)
ax = az.plot_dist(
ppc_1["yl"].mean("yl_dim_2"),
label="model_1",
color="C1",
kind="hist",
hist_kwargs={"alpha": 0.5, "bins": bins},
ax=ax,
)
ax.legend()
ax.set_xlabel("$\\theta$")
ax.xaxis.set_major_formatter(FormatStrFormatter("%0.1f"))
ax.set_yticks([]);
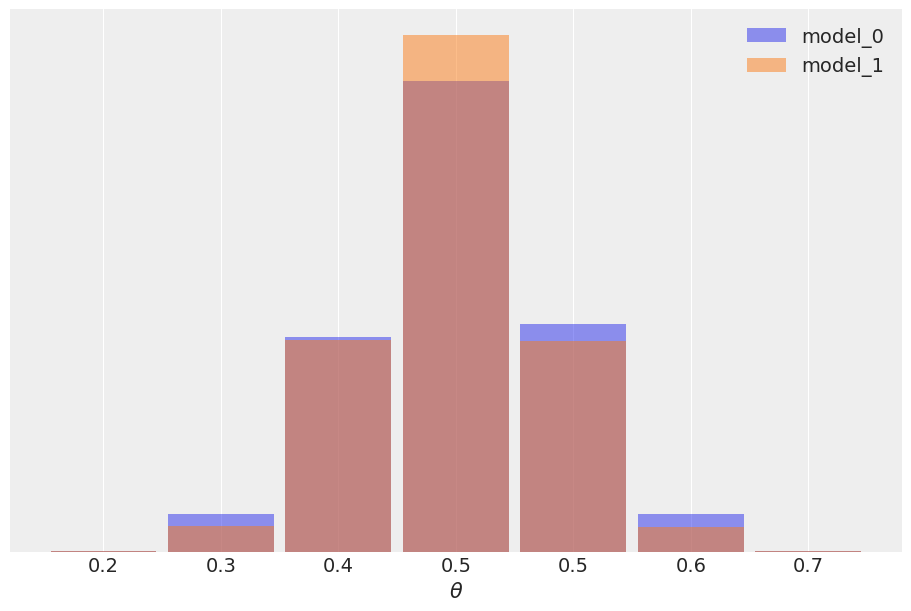
在本例中,观测数据 \(y\) 与 model_1 更一致(因为先验集中在 \(\theta\) 的正确值附近),而不是 model_0 (它为 \(\theta\) 的每个可能值分配相等的概率),并且这种差异由贝叶斯因子捕获。我们可以说贝叶斯因子正在衡量哪个模型作为一个整体更好,包括可能与参数推断无关的先验细节。事实上,在本例中,我们还可以看到,可能有两个不同的模型,具有不同的贝叶斯因子,但仍然获得非常相似的预测。原因是数据信息量足够大,可以减少先验的影响,直到诱导出非常相似的后验。由于预测是从后验计算出来的,我们也会得到非常相似的预测。在大多数比较模型的情况下,我们真正关心的是模型的预测准确性,如果两个模型具有相似的预测准确性,我们将两个模型都视为相似。为了估计预测准确性,我们可以使用 PSIS-LOO-CV (az.loo)、WAIC (az.waic) 或交叉验证等工具。
Savage-Dickey 密度比率#
对于之前的示例,我们比较了两个 beta-二项模型,但有时我们想要做的是将零假设 H_0(或零模型)与备择假设 H_1 进行比较。例如,为了回答问题这个硬币有偏差吗?,我们可以将值 \(\theta = 0.5\) (表示无偏差)与我们让 \(\theta\) 变化的模型的结果进行比较。对于这种类型的比较,零模型嵌套在备择模型中,这意味着零模型是我们正在构建的模型的特定值。在这些情况下,计算贝叶斯因子非常容易,并且不需要任何特殊方法,因为数学运算很方便,所以我们只需要比较在备择模型下在零值(例如 \(\theta = 0.5\))处评估的先验和后验。我们可以从以下表达式中看到这是正确的
只有当 H_0 是 H_1 的特定情况时,才成立。
让我们用 PyMC 和 ArviZ 来做。我们只需要获取模型的后验和先验样本。让我们尝试使用我们之前看到的具有均匀先验的 beta-二项模型。
with pm.Model() as model_uni:
a = pm.Beta("a", 1, 1)
yl = pm.Bernoulli("yl", a, observed=y)
idata_uni = pm.sample(2000, random_seed=42)
idata_uni.extend(pm.sample_prior_predictive(8000))
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [a]
Sampling 4 chains for 1_000 tune and 2_000 draw iterations (4_000 + 8_000 draws total) took 2 seconds.
Sampling: [a, yl]
现在我们调用 ArviZ 的 az.plot_bf 函数
az.plot_bf(idata_uni, var_name="a", ref_val=0.5);
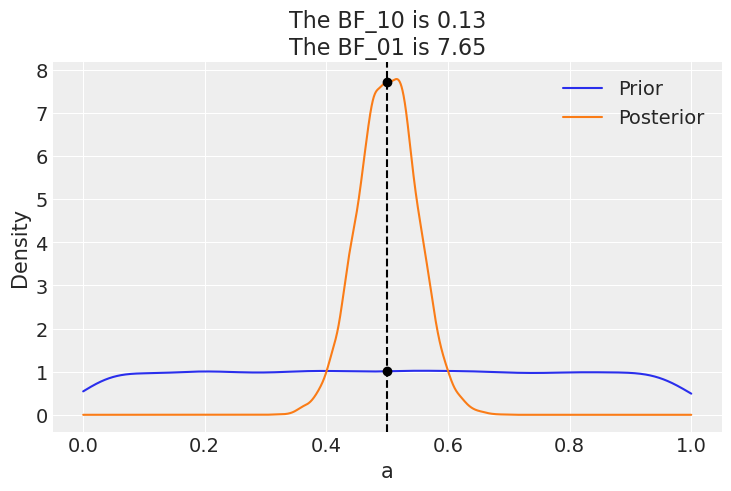
该图显示了先验(蓝色)和后验(橙色)的一个 KDE。两个黑点显示我们在 0.5 处评估两个分布。我们可以看到支持零假设 BF_01 的贝叶斯因子为 \(\approx 8\),我们可以将其解释为支持零假设的中等证据(参见我们之前讨论的 Jeffreys’ 尺度)。
正如我们已经讨论过的,贝叶斯因子正在衡量哪个模型作为一个整体更擅长解释数据。这包括先验,即使先验对后验计算的影响相对较低。当将第二个模型与零假设进行比较时,我们也可以看到先验的这种影响。
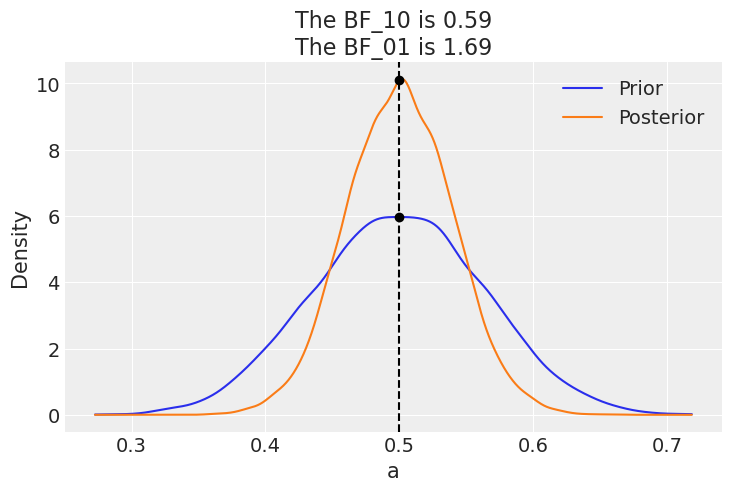
如果我们的模型改为具有先验 beta(30, 30) 的 beta-二项模型,则 BF_01 会更低(在 Jeffreys’ 尺度上为轶事)。这是因为在这个模型下,\(\theta=0.5\) 的值先验上比均匀先验更可能,因此后验和先验会更相似。也就是说,在收集数据后看到后验集中在 0.5 附近并没有太大的意外。
让我们计算一下,亲眼看看。
with pm.Model() as model_conc:
a = pm.Beta("a", 30, 30)
yl = pm.Bernoulli("yl", a, observed=y)
idata_conc = pm.sample(2000, random_seed=42)
idata_conc.extend(pm.sample_prior_predictive(8000))
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [a]
Sampling 4 chains for 1_000 tune and 2_000 draw iterations (4_000 + 8_000 draws total) took 2 seconds.
Sampling: [a, yl]
az.plot_bf(idata_conc, var_name="a", ref_val=0.5);
由 Osvaldo Martin 于 2017 年 9 月创作 (pymc#2563)
由 Osvaldo Martin 于 2018 年 8 月更新 (pymc#3124)
由 Osvaldo Martin 于 2022 年 5 月更新 (pymc-examples#342)
由 Osvaldo Martin 于 2022 年 11 月更新
由 Reshama Shaikh 于 2023 年 1 月使用 PyMC v5 重新执行
参考文献#
James M. Dickey 和 B. P. Lientz. 加权似然比、关于机会的尖锐假设、马尔可夫链的阶数。数理统计年鉴,41(1):214 – 226, 1970. doi:10.1214/aoms/1177697203。
Eric-Jan Wagenmakers, Tom Lodewyckx, Himanshu Kuriyal, 和 Raoul Grasman. 心理学家的贝叶斯假设检验:关于 Savage–Dickey 方法的教程。认知心理学,60(3):158–189, 2010. URL: https://www.sciencedirect.com/science/article/pii/S0010028509000826, doi:https://doi.org/10.1016/j.cogpsych.2009.12.001。
水印#
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor
Last updated: Sun Jan 15 2023
Python implementation: CPython
Python version : 3.10.8
IPython version : 8.7.0
pytensor: 2.8.10
matplotlib: 3.6.2
numpy : 1.24.0
pymc : 5.0.0
arviz : 0.14.0
Watermark: 2.3.1
许可声明#
本示例库中的所有笔记本均根据 MIT 许可证 提供,该许可证允许修改和再分发用于任何用途,前提是保留版权和许可证声明。
引用 PyMC 示例#
要引用此笔记本,请使用 Zenodo 为 pymc-examples 存储库提供的 DOI。
重要
许多笔记本改编自其他来源:博客、书籍... 在这种情况下,您也应该引用原始来源。
另请记住引用您的代码使用的相关库。
这是一个 bibtex 中的引用模板
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
渲染后可能看起来像