


变分推断:贝叶斯神经网络#
机器学习的当前趋势#
概率编程、深度学习和“大数据”是机器学习中最重要的主题。在 PP 内部,许多创新都集中在使用变分推断来扩展规模。在此示例中,我将展示如何在 PyMC 中使用变分推断来拟合一个简单的贝叶斯神经网络。我还将讨论桥接概率编程和深度学习如何为未来的研究开辟非常有趣的途径。
大规模概率编程#
概率编程允许非常灵活地创建自定义概率模型,并且主要关注从数据中进行推断和学习。该方法本质上是贝叶斯的,因此我们可以指定先验来告知和约束我们的模型,并以后验分布的形式获得不确定性估计。使用MCMC 抽样算法,我们可以从这个后验中抽取样本,以非常灵活地估计这些模型。PyMC、NumPyro 和 Stan 是当前构建和估计这些模型的先进工具。然而,抽样的一个主要缺点是它通常很慢,特别是对于高维模型和大型数据集。这就是为什么最近开发了变分推断算法,这些算法几乎与 MCMC 一样灵活,但速度更快。这些算法不是从后验中抽取样本,而是将分布(例如正态分布)拟合到后验,从而将抽样问题转化为优化问题。自动微分变分推断 [Kucukelbir et al., 2015] 已在多个概率编程包中实现,包括 PyMC、NumPyro 和 Stan。
不幸的是,当涉及到传统的 ML 问题(如分类或(非线性)回归)时,概率编程通常在准确性和可扩展性方面逊色于 集成学习(例如 随机森林 或 梯度提升回归树)等更算法化的方法。
深度学习#
现在正处于第三次复兴的神经网络通过几乎在任何对象识别基准测试中占据主导地位、在 Atari 游戏中大放异彩 [Mnih et al., 2013] 以及在围棋中击败世界冠军李世石 [D. Silver, 2016] 而反复成为头条新闻。从统计学的角度来看,神经网络是非常好的非线性函数逼近器和表示学习器。虽然主要以分类而闻名,但它们已扩展到与自动编码器 [Kingma 和 Welling, 2014] 进行的无监督学习以及各种其他有趣的方式(例如 循环网络 或 MDN 来估计多模态分布)。它们为什么如此有效?没有人真正知道,因为统计特性仍未完全理解。
深度学习中很大一部分创新是训练这些极其复杂模型的能力。这建立在几个支柱之上
速度:促进 GPU 的使用可以实现更快的处理速度。
软件:PyTorch 和 TensorFlow 等框架允许灵活创建抽象模型,然后可以对其进行优化并编译到 CPU 或 GPU。
学习算法:对数据子集进行训练——随机梯度下降——使我们能够在海量数据上训练这些模型。像 dropout 这样的技术可以避免过拟合。
架构:许多创新来自更改输入层(如卷积神经网络)或输出层(如 MDN)。
桥接深度学习和概率编程#
一方面,我们有概率编程,它使我们能够以非常规范和易于理解的方式构建相当小且集中的模型,以深入了解我们的数据;另一方面,我们有深度学习,它使用许多启发式方法来训练庞大而高度复杂的模型,这些模型在预测方面非常出色。变分推断的最新创新使概率编程能够扩展模型复杂性和数据规模。因此,我们正处于能够结合这两种方法以期在机器学习中解锁新创新的风口浪尖。有关更多动机,另请参阅 Dustin Tran 的 博客文章。
虽然这将使概率编程能够应用于更广泛的有趣问题,但我认为这种桥接也为深度学习的创新带来了巨大的希望。一些想法是
预测中的不确定性:正如我们将在下面看到的,贝叶斯神经网络会告知我们其预测中的不确定性。我认为不确定性是机器学习中一个被低估的概念,因为它对于实际应用显然很重要。但它也可能在训练中很有用。例如,我们可以专门针对模型最不确定的样本进行训练。
表示中的不确定性:我们还可以获得权重的不确定性估计,这可以告知我们网络学习表示的稳定性。
使用先验进行正则化:权重通常使用 L2 正则化来避免过拟合,这自然而然地成为权重系数的高斯先验。然而,我们可以想象各种其他先验,例如 spike-and-slab 以强制稀疏性(这更像是使用 L1 范数)。
使用知情先验进行迁移学习:如果我们想在新对象识别数据集上训练网络,我们可以通过放置以从其他预训练网络(如 GoogLeNet [Szegedy et al., 2014])检索的权重为中心的知情先验来引导学习。
分层神经网络:概率编程中一种非常强大的方法是分层建模,它允许将子组中学习到的内容汇集到总体中(参见 PyMC3 中的分层线性回归)。应用于神经网络,在分层数据集中,我们可以训练各个神经网络以专注于子组,同时仍然了解总体表示。例如,想象一个训练用于对汽车图片中的汽车模型进行分类的网络。我们可以训练一个分层神经网络,其中一个子神经网络经过训练,仅用于区分来自单个制造商的模型。直觉是,来自特定制造商的所有汽车都具有某些相似性,因此训练专门针对品牌的各个网络是有意义的。然而,由于各个网络在更高层连接,它们仍然会与其他专业子网络共享有关对所有品牌有用的特征的信息。有趣的是,网络的不同层可以由层次结构的不同级别告知——例如,提取视觉线的早期层在所有子网络中可能是相同的,而高阶表示将是不同的。分层模型将从数据中学习到这一切。
其他混合架构:我们可以更自由地构建各种神经网络。例如,贝叶斯非参数方法可用于灵活地调整隐藏层的大小和形状,以在训练期间将网络架构最佳地扩展到手头的问题。目前,这需要昂贵的超参数优化和大量的部落知识。
PyMC 中的贝叶斯神经网络#
生成数据#
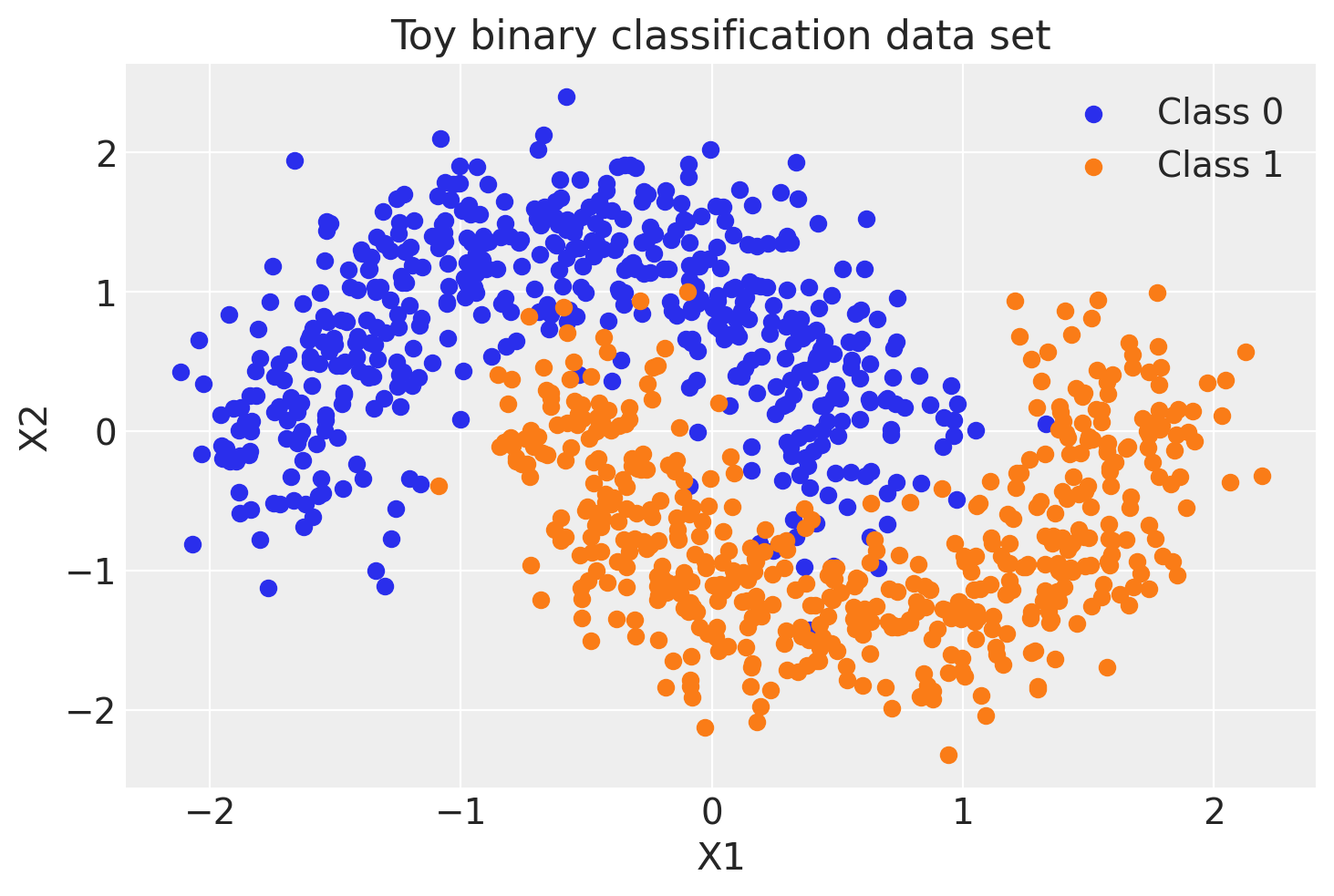
首先,让我们生成一些玩具数据——一个简单的二元分类问题,它是线性不可分的。
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pymc as pm
import pytensor
import seaborn as sns
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import scale
%config InlineBackend.figure_format = 'retina'
floatX = pytensor.config.floatX
RANDOM_SEED = 9927
rng = np.random.default_rng(RANDOM_SEED)
az.style.use("arviz-darkgrid")
X, Y = make_moons(noise=0.2, random_state=0, n_samples=1000)
X = scale(X)
X = X.astype(floatX)
Y = Y.astype(floatX)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.5)
fig, ax = plt.subplots()
ax.scatter(X[Y == 0, 0], X[Y == 0, 1], color="C0", label="Class 0")
ax.scatter(X[Y == 1, 0], X[Y == 1, 1], color="C1", label="Class 1")
sns.despine()
ax.legend()
ax.set(xlabel="X1", ylabel="X2", title="Toy binary classification data set");
模型规范#
神经网络非常简单。基本单元是感知器,它只不过是逻辑回归。我们并行使用许多这些,然后将它们堆叠起来以获得隐藏层。这里我们将使用 2 个隐藏层,每个隐藏层有 5 个神经元,这对于如此简单的问题来说已经足够了。
def construct_nn(batch_size=50):
n_hidden = 5
# Initialize random weights between each layer
init_1 = rng.standard_normal(size=(X_train.shape[1], n_hidden)).astype(floatX)
init_2 = rng.standard_normal(size=(n_hidden, n_hidden)).astype(floatX)
init_out = rng.standard_normal(size=n_hidden).astype(floatX)
coords = {
"hidden_layer_1": np.arange(n_hidden),
"hidden_layer_2": np.arange(n_hidden),
"train_cols": np.arange(X_train.shape[1]),
"obs_id": np.arange(X_train.shape[0]),
}
with pm.Model(coords=coords) as neural_network:
# Define data variables using minibatches
X_data = pm.Data("X_data", X_train, dims=("obs_id", "train_cols"))
Y_data = pm.Data("Y_data", Y_train, dims="obs_id")
# Define minibatch variables
ann_input, ann_output = pm.Minibatch(X_data, Y_data, batch_size=batch_size)
# Weights from input to hidden layer
weights_in_1 = pm.Normal(
"w_in_1", 0, sigma=1, initval=init_1, dims=("train_cols", "hidden_layer_1")
)
# Weights from 1st to 2nd layer
weights_1_2 = pm.Normal(
"w_1_2", 0, sigma=1, initval=init_2, dims=("hidden_layer_1", "hidden_layer_2")
)
# Weights from hidden layer to output
weights_2_out = pm.Normal("w_2_out", 0, sigma=1, initval=init_out, dims="hidden_layer_2")
# Build neural-network using tanh activation function
act_1 = pm.math.tanh(pm.math.dot(ann_input, weights_in_1))
act_2 = pm.math.tanh(pm.math.dot(act_1, weights_1_2))
act_out = pm.math.sigmoid(pm.math.dot(act_2, weights_2_out))
# Binary classification -> Bernoulli likelihood
out = pm.Bernoulli(
"out",
act_out,
observed=ann_output,
total_size=X_train.shape[0], # IMPORTANT for minibatches
)
return neural_network
# Create the neural network model
neural_network = construct_nn()
还不错。Normal 先验有助于正则化权重。通常我们会向输入添加一个常数 b,但我在这里省略了它以保持代码更简洁。
变分推断:扩展模型复杂度#
我们现在可以像 pymc.NUTS 一样运行 MCMC 采样器,它在这种情况下效果很好,但正如已经提到的,当我们扩展模型以获得具有更多层的更深层架构时,这将变得非常缓慢。
相反,我们将使用 pymc.ADVI 变分推断算法。这要快得多,并且可以更好地扩展。请注意,这是一种平均场近似,因此我们忽略了后验中的相关性。
小批量 ADVI#
虽然这个模拟数据集足够小,可以一次性拟合所有数据,但它无法扩展到像 ImageNet 这样大的数据集。在上面的模型中,我们设置了小批量,这将允许扩展到更大的数据集。此外,对小批量数据进行训练(随机梯度下降)可以避免局部最小值,并可以加快收敛速度。
%%time
with neural_network:
approx = pm.fit(n=30_000)
Finished [100%]: Average Loss = 12.793
CPU times: user 6.77 s, sys: 240 ms, total: 7.01 s
Wall time: 8.12 s
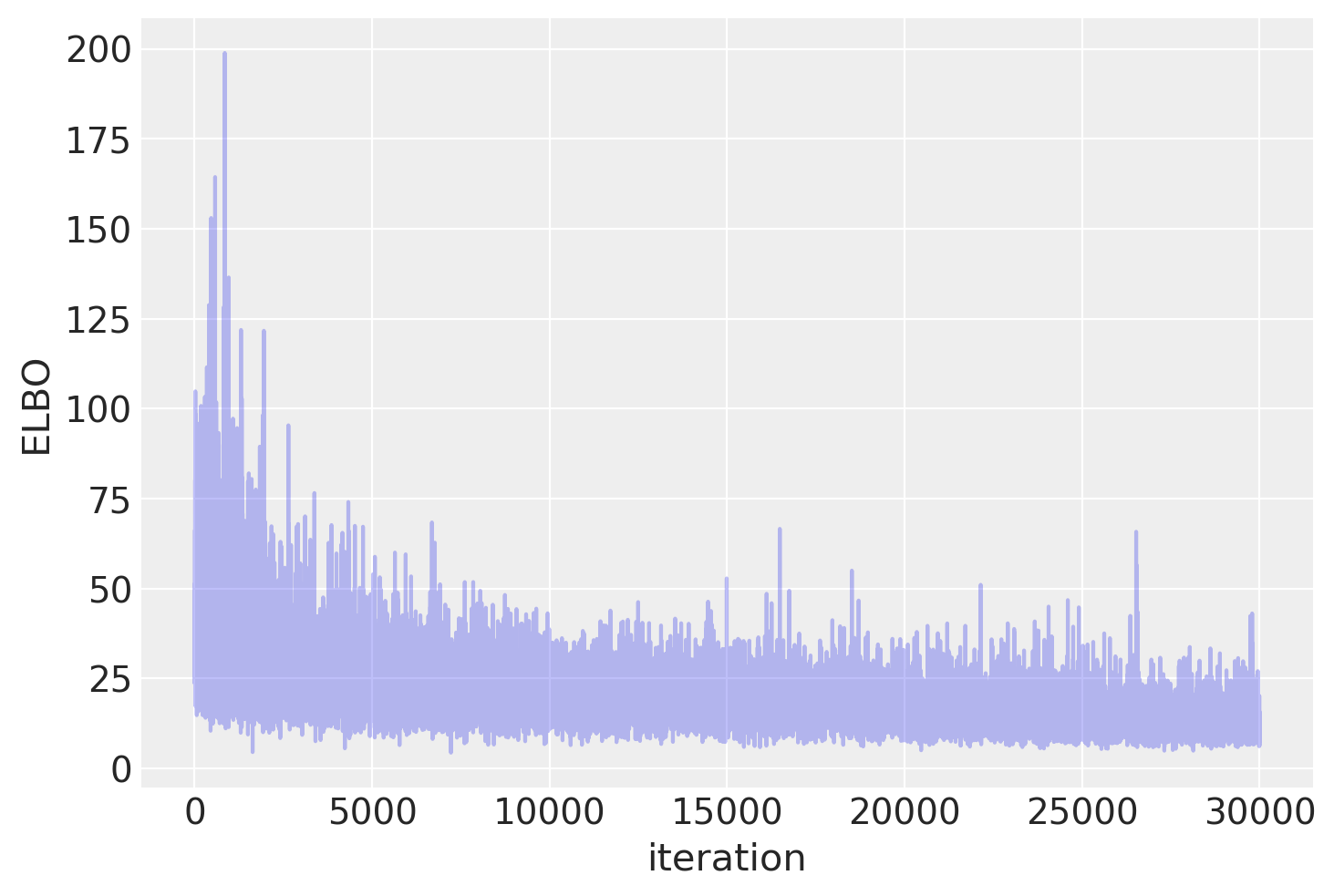
绘制目标函数 (ELBO),我们可以看到优化迭代地改进了拟合。
plt.plot(approx.hist, alpha=0.3)
plt.ylabel("ELBO")
plt.xlabel("iteration");
trace = approx.sample(draws=5000)
现在我们已经训练了我们的模型,让我们使用后验预测检查 (PPC) 对保留集进行预测。我们可以使用 pymc.sample_posterior_predictive() 从后验(从变分估计中采样)生成新数据(在本例中为类预测)。
为了预测整个测试集(而不仅仅是小批量),我们需要创建一个新的模型对象来删除小批量。请注意,我们正在使用我们拟合的 trace 从后验预测分布中采样,使用来自原始模型的后验估计。这里没有新的推断,我们只是使用相同的模型和相同的后验估计来生成预测。Flat 分布只是一个占位符,使模型能够工作;实际值是从后验中采样的。
def sample_posterior_predictive(X_test, Y_test, trace, n_hidden=5):
coords = {
"hidden_layer_1": np.arange(n_hidden),
"hidden_layer_2": np.arange(n_hidden),
"train_cols": np.arange(X_test.shape[1]),
"obs_id": np.arange(X_test.shape[0]),
}
with pm.Model(coords=coords):
ann_input = X_test
ann_output = Y_test
weights_in_1 = pm.Flat("w_in_1", dims=("train_cols", "hidden_layer_1"))
weights_1_2 = pm.Flat("w_1_2", dims=("hidden_layer_1", "hidden_layer_2"))
weights_2_out = pm.Flat("w_2_out", dims="hidden_layer_2")
# Build neural-network using tanh activation function
act_1 = pm.math.tanh(pm.math.dot(ann_input, weights_in_1))
act_2 = pm.math.tanh(pm.math.dot(act_1, weights_1_2))
act_out = pm.math.sigmoid(pm.math.dot(act_2, weights_2_out))
# Binary classification -> Bernoulli likelihood
out = pm.Bernoulli("out", act_out, observed=ann_output)
return pm.sample_posterior_predictive(trace)
ppc = sample_posterior_predictive(X_test, Y_test, trace)
Sampling: [out]
我们可以平均每个观测值的预测,以估计类别 1 的潜在概率。
pred = ppc.posterior_predictive["out"].mean(("chain", "draw")) > 0.5
fig, ax = plt.subplots()
ax.scatter(X_test[pred == 0, 0], X_test[pred == 0, 1], color="C0", label="Predicted 0")
ax.scatter(X_test[pred == 1, 0], X_test[pred == 1, 1], color="C1", label="Predicted 1")
sns.despine()
ax.legend()
ax.set(title="Predicted labels in testing set", xlabel="X1", ylabel="X2");
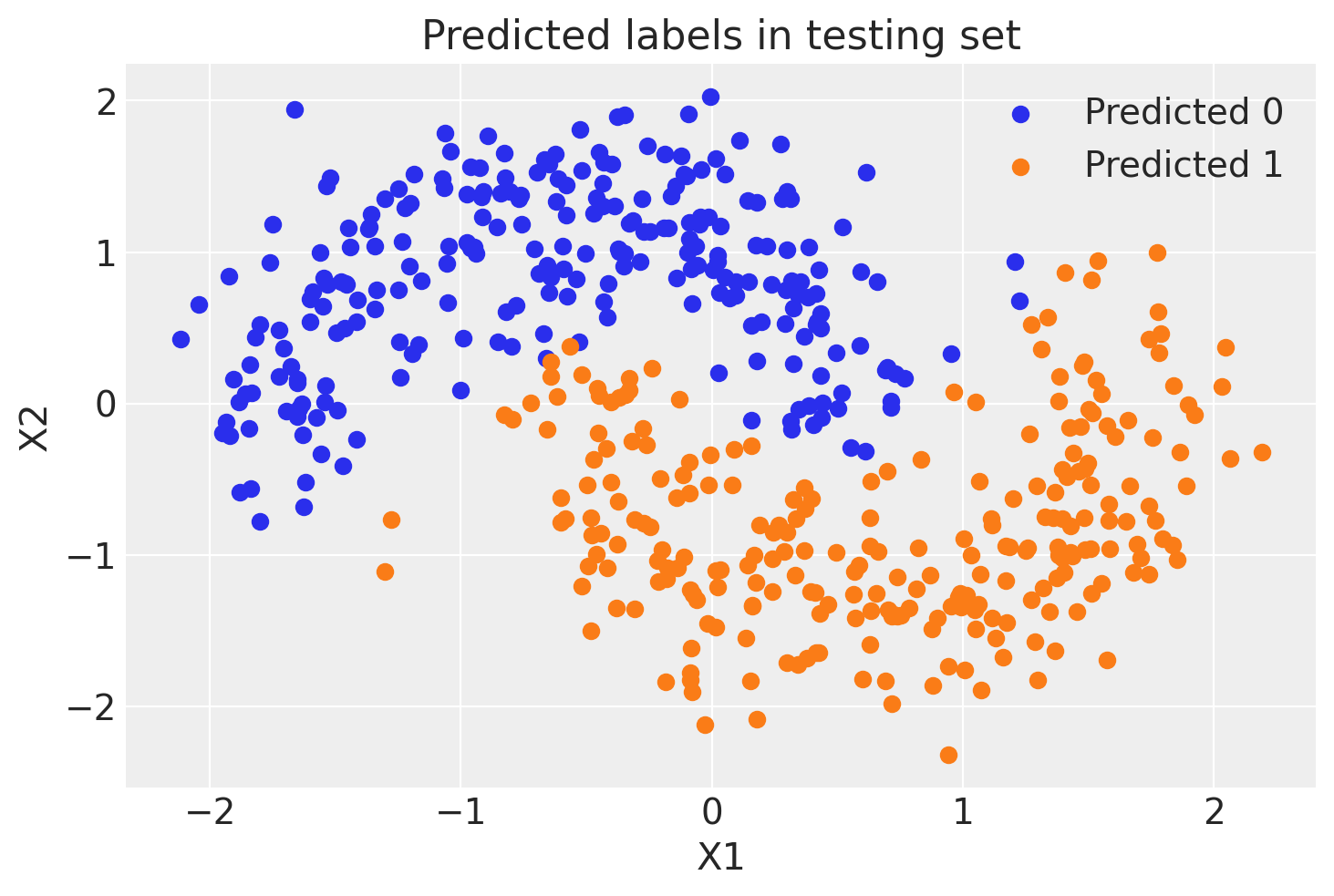
print(f"Accuracy = {(Y_test == pred.values).mean() * 100:.2f}%")
Accuracy = 94.40%
嘿,我们的神经网络做得不错!
让我们看看分类器学到了什么#
为此,我们在整个输入空间上的网格上评估类别概率预测。
ppc = sample_posterior_predictive(grid_2d, dummy_out, trace)
Sampling: [out]
y_pred = ppc.posterior_predictive["out"]
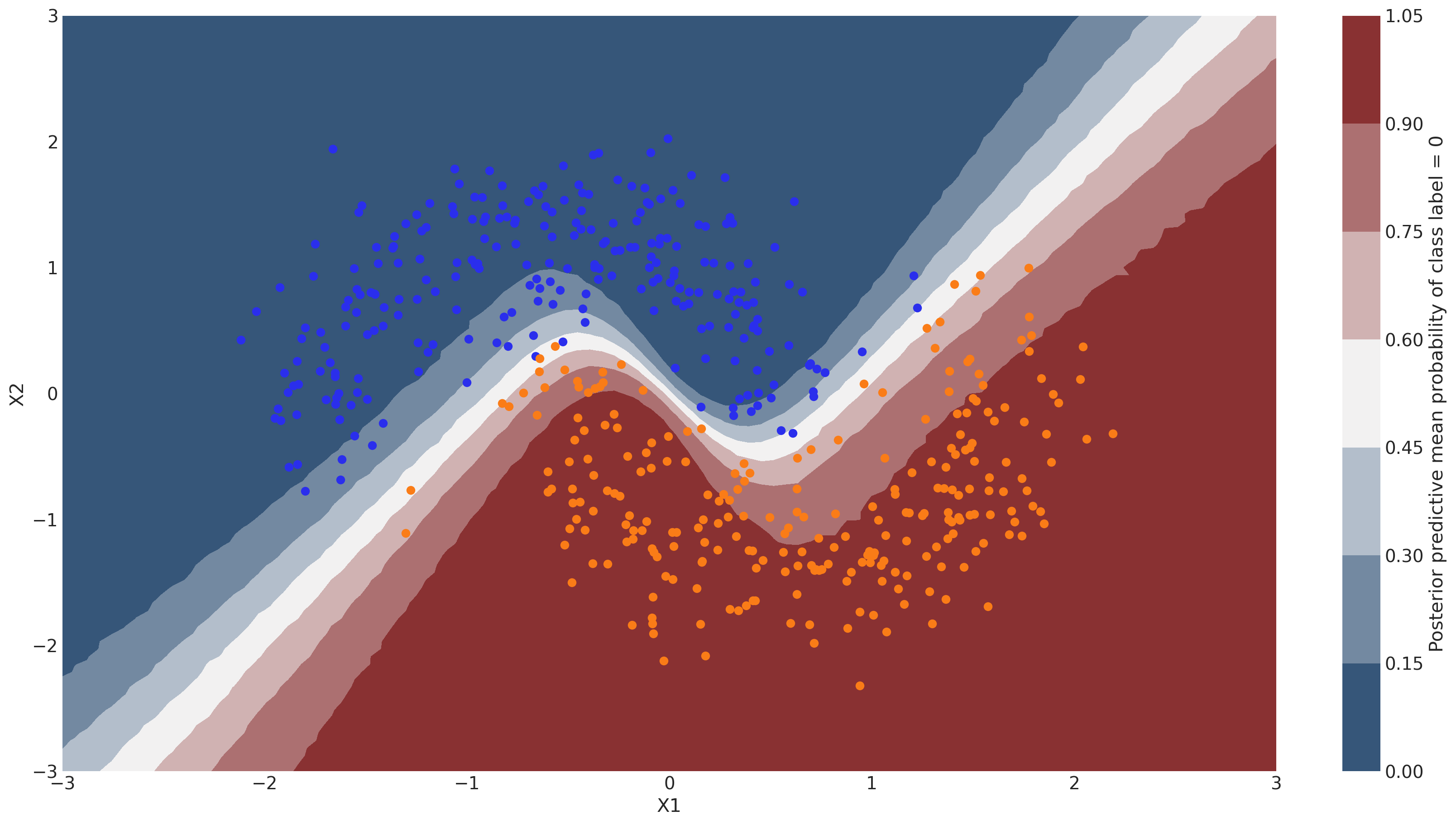
概率曲面#
cmap = sns.diverging_palette(250, 12, s=85, l=25, as_cmap=True)
fig, ax = plt.subplots(figsize=(16, 9))
contour = ax.contourf(
grid[0], grid[1], y_pred.mean(("chain", "draw")).values.reshape(100, 100), cmap=cmap
)
ax.scatter(X_test[pred == 0, 0], X_test[pred == 0, 1], color="C0")
ax.scatter(X_test[pred == 1, 0], X_test[pred == 1, 1], color="C1")
cbar = plt.colorbar(contour, ax=ax)
_ = ax.set(xlim=(-3, 3), ylim=(-3, 3), xlabel="X1", ylabel="X2")
cbar.ax.set_ylabel("Posterior predictive mean probability of class label = 0");
预测值中的不确定性#
请注意,我们可以使用非贝叶斯神经网络完成以上所有操作。每个类别标签的后验预测的平均值应与最大似然预测值相同。但是,我们也可以查看后验预测的标准差,以了解我们预测中的不确定性。这是它的样子
cmap = sns.cubehelix_palette(light=1, as_cmap=True)
fig, ax = plt.subplots(figsize=(16, 9))
contour = ax.contourf(
grid[0], grid[1], y_pred.squeeze().values.std(axis=0).reshape(100, 100), cmap=cmap
)
ax.scatter(X_test[pred == 0, 0], X_test[pred == 0, 1], color="C0")
ax.scatter(X_test[pred == 1, 0], X_test[pred == 1, 1], color="C1")
cbar = plt.colorbar(contour, ax=ax)
_ = ax.set(xlim=(-3, 3), ylim=(-3, 3), xlabel="X1", ylabel="X2")
cbar.ax.set_ylabel("Uncertainty (posterior predictive standard deviation)");

我们可以看到,非常靠近决策边界,我们对预测哪个标签的不确定性最高。您可以想象,将预测与不确定性相关联对于许多应用(如医疗保健)来说至关重要。为了进一步最大化准确性,我们可能希望主要在来自高不确定性区域的样本上训练模型。
为了好玩,我们还可以查看 trace。重点是我们也获得了神经网络权重的不确定性。
az.plot_trace(trace);
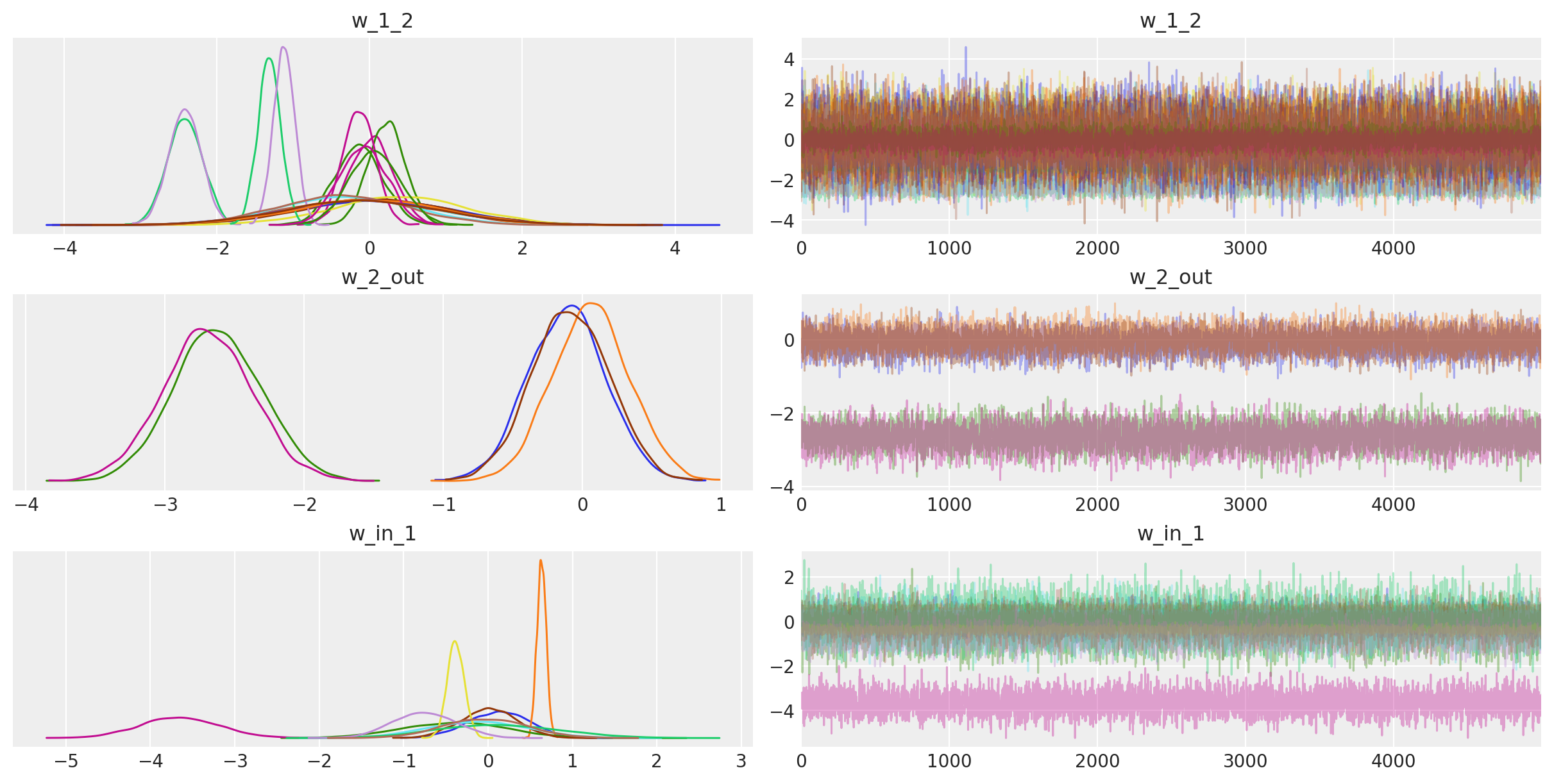
您可能会争辩说,上面的网络并不是真正的深度网络,但请注意,我们可以轻松地扩展它以具有更多层,包括卷积层,以在更具挑战性的数据集上进行训练。
致谢#
Taku Yoshioka 在 PyMC3 中对 ADVI 做了大量工作,包括小批量实现以及从变分后验中采样。我还要感谢 Stan 团队(特别是 Alp Kucukelbir 和 Daniel Lee)推导 ADVI 并教我们了解它。还要感谢 Chris Fonnesbeck、Andrew Campbell、Taku Yoshioka 和 Peadar Coyle 对早期草稿的有用评论。
参考文献#
Alp Kucukelbir、Rajesh Ranganath、Andrew Gelman 和 David M. Blei。Stan 中的自动变分推断。2015 年。arXiv:1506.03431。
Volodymyr Mnih、Koray Kavukcuoglu、David Silver、Alex Graves、Ioannis Antonoglou、Daan Wierstra 和 Martin Riedmiller。使用深度强化学习玩 Atari 游戏。2013 年。arXiv:1312.5602。
C. Maddison 等人。D. Silver、A. Huang。掌握围棋游戏与深度神经网络和树搜索。《自然》,529:484–489,2016 年。网址:https://doi.org/10.1038/nature16961。
Diederik P Kingma 和 Max Welling。自动编码变分贝叶斯。2014 年。arXiv:1312.6114。
Christian Szegedy、Wei Liu、Yangqing Jia、Pierre Sermanet、Scott Reed、Dragomir Anguelov、Dumitru Erhan、Vincent Vanhoucke 和 Andrew Rabinovich。使用卷积进行更深入的研究。2014 年。arXiv:1409.4842。
水印#
%load_ext watermark
%watermark -n -u -v -iv -w -p xarray
Last updated: Tue Feb 11 2025
Python implementation: CPython
Python version : 3.12.8
IPython version : 8.32.0
xarray: 2025.1.2
pytensor : 2.27.1
pymc : 5.20.1
arviz : 0.19.0
numpy : 1.26.4
seaborn : 0.13.2
sklearn : 1.6.1
matplotlib: 3.10.0
Watermark: 2.5.0
许可声明#
此示例库中的所有笔记本均根据 MIT 许可证提供,该许可证允许修改和再分发以用于任何用途,前提是保留版权和许可声明。
引用 PyMC 示例#
要引用此笔记本,请使用 Zenodo 为 pymc-examples 存储库提供的 DOI。
重要提示
许多笔记本改编自其他来源:博客、书籍……在这种情况下,您也应该引用原始来源。
另请记住引用您的代码使用的相关库。
这是一个 BibTeX 引用模板
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
渲染后可能如下所示