


使用 HSGP 的婴儿出生建模#
本笔记本提供了一个使用希尔伯特空间高斯过程 (HSGP) 技术的示例,该技术在 [Solin 和 Särkkä,2020] 中介绍,用于时间序列建模。这项技术已被证明可以成功加速具有高斯过程组件的模型。
为了说明主要概念,我们使用了经典的生日示例数据集(参见 [Gelman等人,2013] [第 21 章] 和 此处 获取有关数据来源的评论),并重现了优秀案例研究 [Vehtari,2022] 中提出的模型之一,作者是 Aki Vehtari(您可以在 此存储库 中找到 Stan 代码)。在他的阐述中,作者提出了一个广泛的迭代方法,用于分析 1969-1988 年美国每天的相对出生人数,使用 HSGP 用于各种组件:长期趋势、季节性、每周、一年中的某天和特殊的浮动日变化。由于此资源非常详细并给出了许多相关解释,我们不重现整个过程,而是专注于重现中间模型之一。即,具有缓慢趋势、年度季节性趋势和星期几分量的模型(原始案例研究中的模型 3)。重现比最终模型更简单的模型的原因是使其成为愿意了解此技术的用户的入门笔记本。我们将提供一个后续示例,其中我们实现包含所有组件的最终模型。
在本笔记本中,我们不想深入探讨数学细节,而是专注于实现以及如何在 PyMC 模型中使用 PyMC 的 HSGP 和 HSGPPeriodic API。此类提供了一种在 PyMC 模型中使用 HSGP 的便捷方法。用户需要输入某些参数来控制近似中的项数和定义域。当然,理解这些参数的作用很重要,因此让我们简要介绍一下近似的主要思想和最相关的参数
近似的主要思想#
回想一下,核(与协方差函数相关联)是高斯过程的主要成分,因为它编码了点之间相似性(和平滑度)的度量(参见 均值和协方差函数)。希尔伯特空间近似的思想是将此类核分解为正交基的线性组合,以便在用此展开式替换核时,我们可以根据这些基函数拟合线性模型。从截断展开式中采样将比香草高斯过程公式快得多。关键的观察结果是,近似中的基函数不依赖于高斯过程协方差函数的超参数,从而大大加快了计算速度。
希尔伯特空间来自哪里?事实证明,正交基来自紧集上拉普拉斯算子的谱分解(例如,考虑圆上的傅里叶分解)。换句话说,基函数是平方可积函数空间 \(L^{2}([-L, L])\) 上拉普拉斯算子的特征向量,这是一个希尔伯特空间。回到类 HSGP,两个最重要的参数是
\(m\): 近似中要使用的基向量的数量。
\(L\):定义空间的边界。选择 L,使域 \([-L, L]\) 包含域中的所有点。(请注意,紧集是闭区间 \([-L, L]\) 😉)
还可以使用比例扩展因子 \(c > 0\),用于从高斯过程 \(X\) 的定义域构造 \(L\)。具体而言,\(L\) 可以指定为乘积 \(cS\),其中 \(S = \max|X|\)。
我们推荐论文 [Riutort-Mayol等人,2022],其中对这项技术进行了实践讨论。
注意
您可以在 Numpyro 的文档中找到类似的示例:[示例:高斯过程的希尔伯特空间近似,无日期]。此示例是了解方法内部原理的绝佳资源。
注意
本笔记本基于博文 [Orduz,2024]。
注意
本笔记本使用了非 PyMC 依赖项的库,因此需要专门安装才能运行本笔记本。打开下面的下拉列表以获取额外的指导。
额外依赖项安装说明
为了运行本笔记本(本地或在 binder 上),您不仅需要安装所有可选依赖项的 PyMC 工作版本,还需要安装一些额外的依赖项。有关安装 PyMC 本身的建议,请参阅 安装
您可以使用首选的软件包管理器安装这些依赖项,我们提供了以下 pip 和 conda 命令作为示例。
$ pip install numpyro preliz scikit-learn seaborn tensorflow-probability
请注意,如果您想(或需要)从笔记本内部而不是命令行安装软件包,您可以通过运行 pip 命令的变体来安装软件包
import sys
!{sys.executable} -m pip install numpyro preliz scikit-learn seaborn tensorflow-probability
您不应运行 !pip install,因为它可能会将软件包安装在不同的环境中,即使已安装,也无法从 Jupyter 笔记本中使用。
另一种选择是使用 conda
$ conda install numpyro preliz scikit-learn seaborn tensorflow-probability
当使用 conda 安装科学 python 软件包时,我们建议使用 conda forge
显示代码单元格源
import warnings
from collections.abc import Callable
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import preliz as pz
import pymc as pm
import pytensor.tensor as pt
import seaborn as sns
import xarray as xr
from matplotlib.ticker import MaxNLocator
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import FunctionTransformer, StandardScaler
warnings.filterwarnings("ignore")
az.style.use("arviz-darkgrid")
plt.rcParams["figure.figsize"] = [12, 7]
plt.rcParams["figure.dpi"] = 100
plt.rcParams["figure.facecolor"] = "white"
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = "retina"
WARNING (pytensor.tensor.blas): Using NumPy C-API based implementation for BLAS functions.
显示代码单元格源
seed: int = sum(map(ord, "birthdays"))
rng: np.random.Generator = np.random.default_rng(seed=seed)
读取数据#
我们从 贝叶斯工作流书 - 生日 存储库读取数据,作者是 Aki Vehtari。
raw_df = pd.read_csv(
"https://raw.githubusercontent.com/avehtari/casestudies/master/Birthdays/data/births_usa_1969.csv",
)
raw_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7305 entries, 0 to 7304
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 year 7305 non-null int64
1 month 7305 non-null int64
2 day 7305 non-null int64
3 births 7305 non-null int64
4 day_of_year 7305 non-null int64
5 day_of_week 7305 non-null int64
6 id 7305 non-null int64
7 day_of_year2 7305 non-null int64
dtypes: int64(8)
memory usage: 456.7 KB
数据集包含 1969-1988 年期间美国每天的出生人数。除 day_of_year2 外,所有列都是不言自明的,day_of_year2 是一年中的某天(从 1 到 366),闰日为 60,3 月 1 日在非闰年也为 61。
raw_df.head()
| 年份 | 月份 | 日期 | 出生人数 | 一年中的某天 | 星期几 | ID | 一年中的某天 2 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1969 | 1 | 1 | 8486 | 1 | 3 | 1 | 1 |
| 1 | 1969 | 1 | 2 | 9002 | 2 | 4 | 2 | 2 |
| 2 | 1969 | 1 | 3 | 9542 | 3 | 5 | 3 | 3 |
| 3 | 1969 | 1 | 4 | 8960 | 4 | 6 | 4 | 4 |
| 4 | 1969 | 1 | 5 | 8390 | 5 | 7 | 5 | 5 |
EDA 和特征工程#
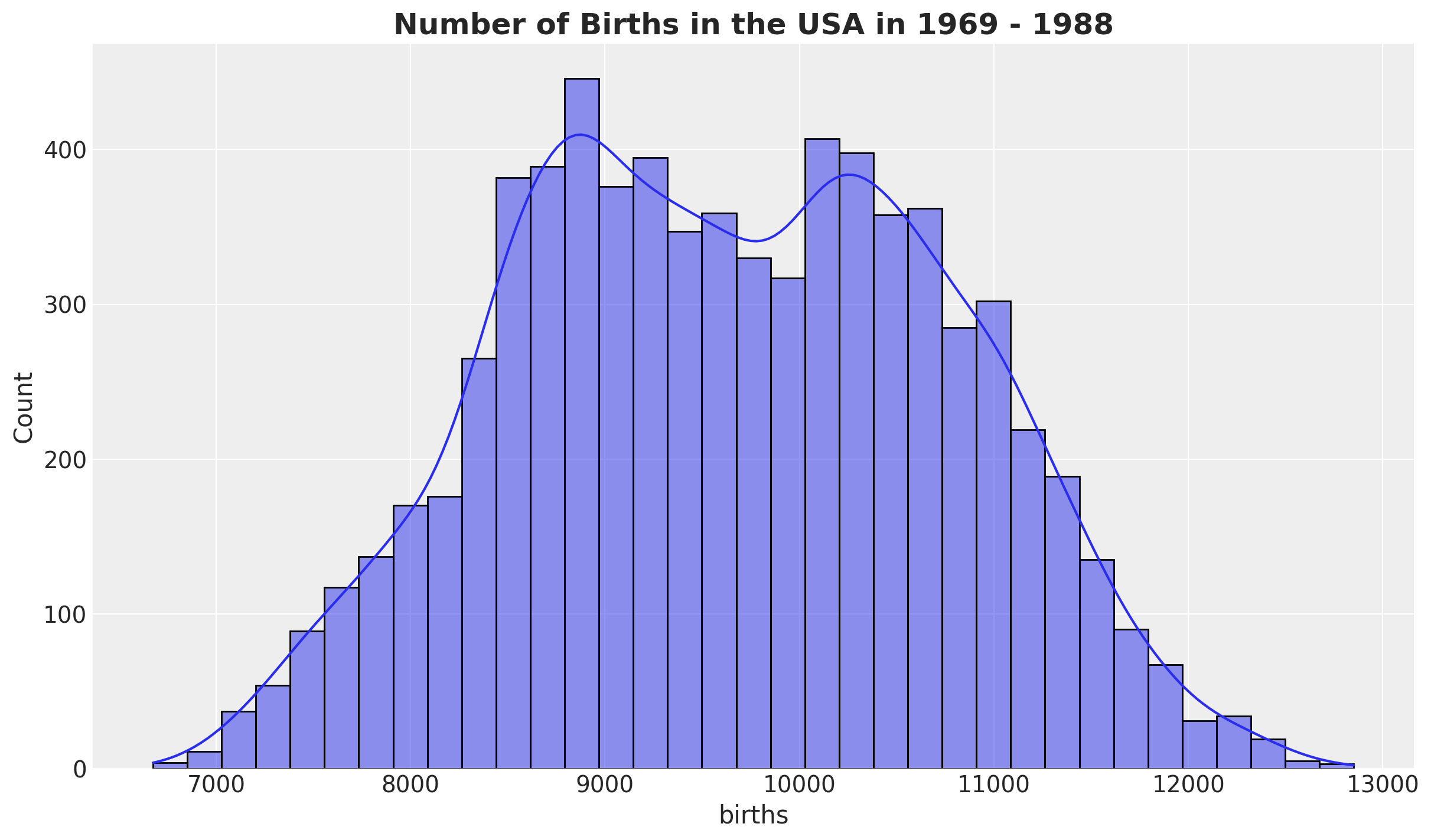
首先,我们研究 births 分布
fig, ax = plt.subplots()
sns.histplot(data=raw_df, x="births", kde=True, ax=ax)
ax.set_title(
label="Number of Births in the USA in 1969 - 1988",
fontsize=18,
fontweight="bold",
);
我们创建了几个特征
date时间戳。births_relative100:相对于 \(100\) 的出生人数。time:数据索引。
data_df = raw_df.copy().assign(
date=lambda x: pd.to_datetime(x[["year", "month", "day"]]),
births_relative100=lambda x: x["births"] / x["births"].mean() * 100,
time=lambda x: x.index,
)
注意
我们缩放数据,使其尽可能接近 Aki 的案例研究。我们不需要缩放数据即可使 HSGP 模型工作。
现在,让我们看一下相对出生人数随时间的变化,这将是我们建模的目标变量。
fig, ax = plt.subplots()
sns.scatterplot(data=data_df, x="date", y="births_relative100", c="C0", s=8, ax=ax)
ax.axhline(100, color="black", linestyle="--", label="mean level")
ax.legend()
ax.set(xlabel="date", ylabel="relative number of births")
ax.set_title(label="Relative Births in the USA in 1969 - 1988", fontsize=18, fontweight="bold");
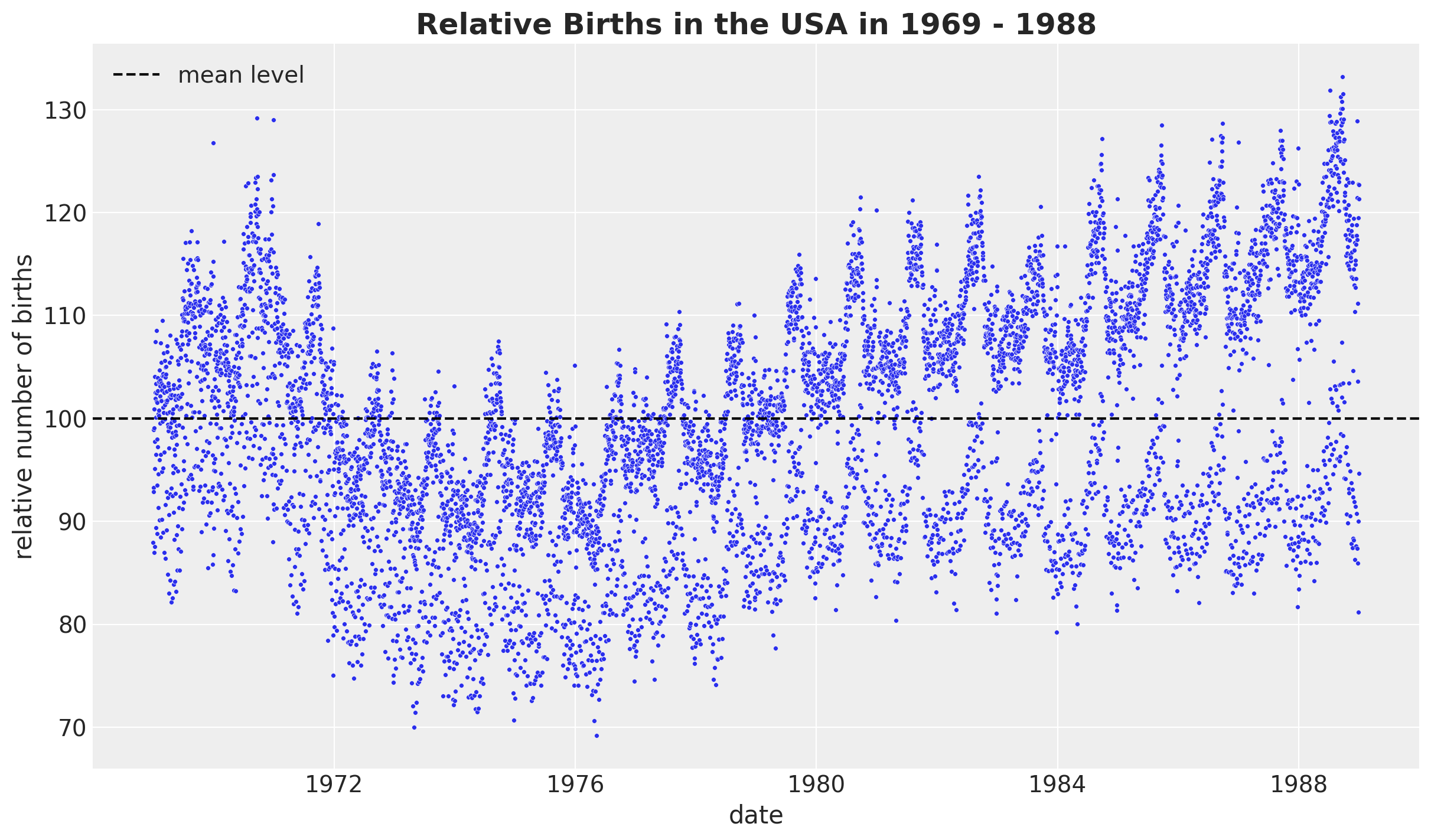
我们看到了明显的长期趋势分量和明显的年度季节性。我们还看到方差如何随时间增长,这被称为 异方差性。
上面的图有很多数据点,我们想确保我们理解不同级别的季节性模式(这可能隐藏在上面的图中)。因此,我们系统地检查各个级别的季节性。
让我们继续按一年中的某天求平均值来查看
fig, ax = plt.subplots()
(
data_df.groupby(["day_of_year2"], as_index=False)
.agg(meanbirths=("births_relative100", "mean"))
.pipe((sns.scatterplot, "data"), x="day_of_year2", y="meanbirths", c="C0", ax=ax)
)
ax.axhline(100, color="black", linestyle="--", label="mean level")
ax.legend()
ax.set(xlabel="day of year", ylabel="relative number of births per day of year")
ax.set_title(
label="Relative Births in the USA in 1969 - 1988\nMean over Day of Year",
fontsize=18,
fontweight="bold",
);
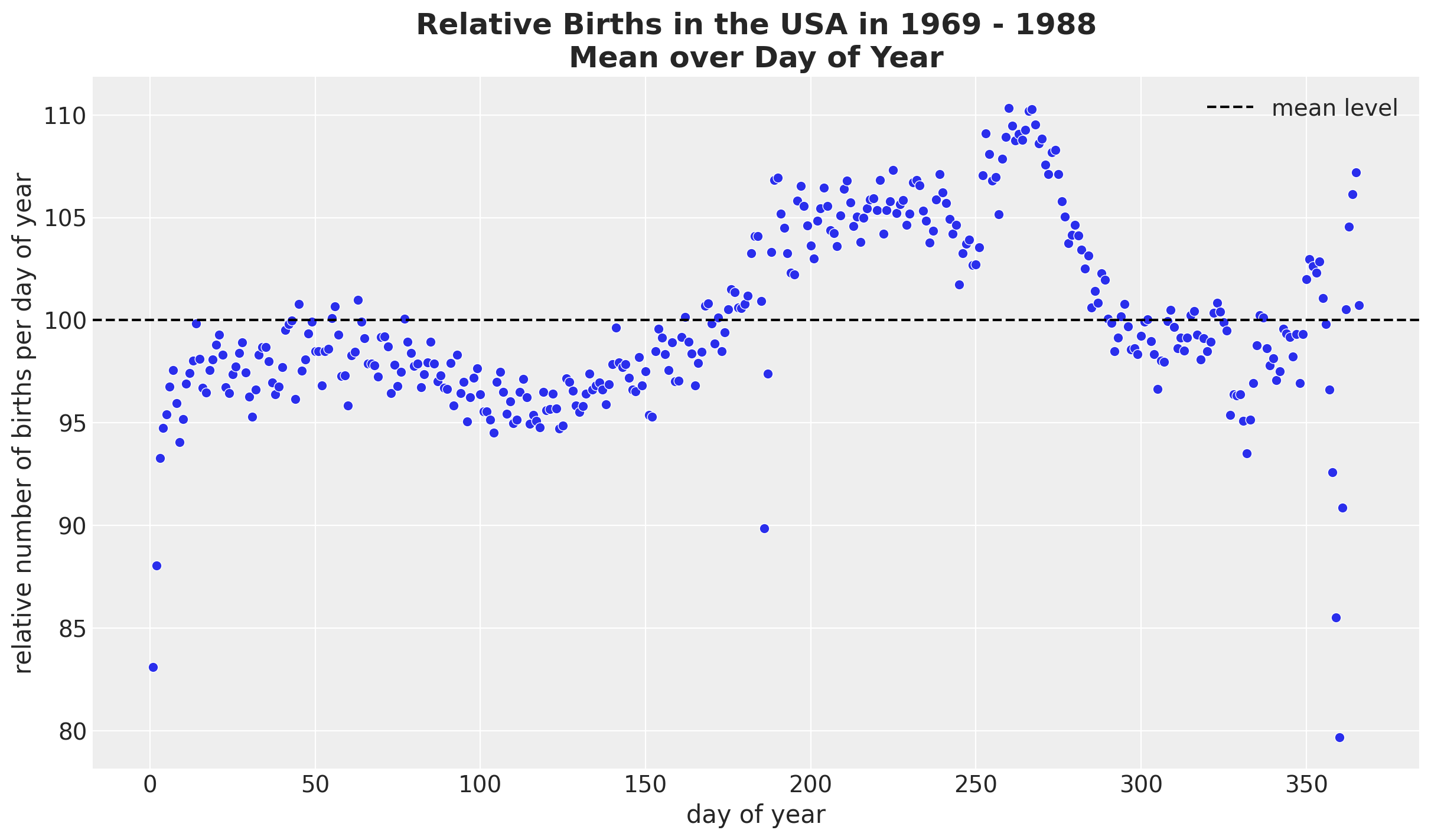
总的来说,我们看到相对平滑的行为,但某些假期(阵亡将士纪念日、感恩节和劳动节)和元旦除外。
接下来,我们按月和年拆分,看看我们是否发现模式随时间变化的任何变化。
fig, ax = plt.subplots()
(
data_df.groupby(["year", "month"], as_index=False)
.agg(meanbirths=("births_relative100", "mean"))
.assign(month=lambda x: pd.Categorical(x["month"]))
.pipe(
(sns.lineplot, "data"),
x="year",
y="meanbirths",
marker="o",
markersize=7,
hue="month",
palette="tab20",
)
)
ax.xaxis.set_major_locator(MaxNLocator(integer=True))
ax.legend(title="month", loc="center left", bbox_to_anchor=(1, 0.5))
ax.set(xlabel="year", ylabel="relative number of births")
ax.set_title(
label="Relative Births in the USA in 1969 - 1988\nMean over Month and Year",
fontsize=18,
fontweight="bold",
);
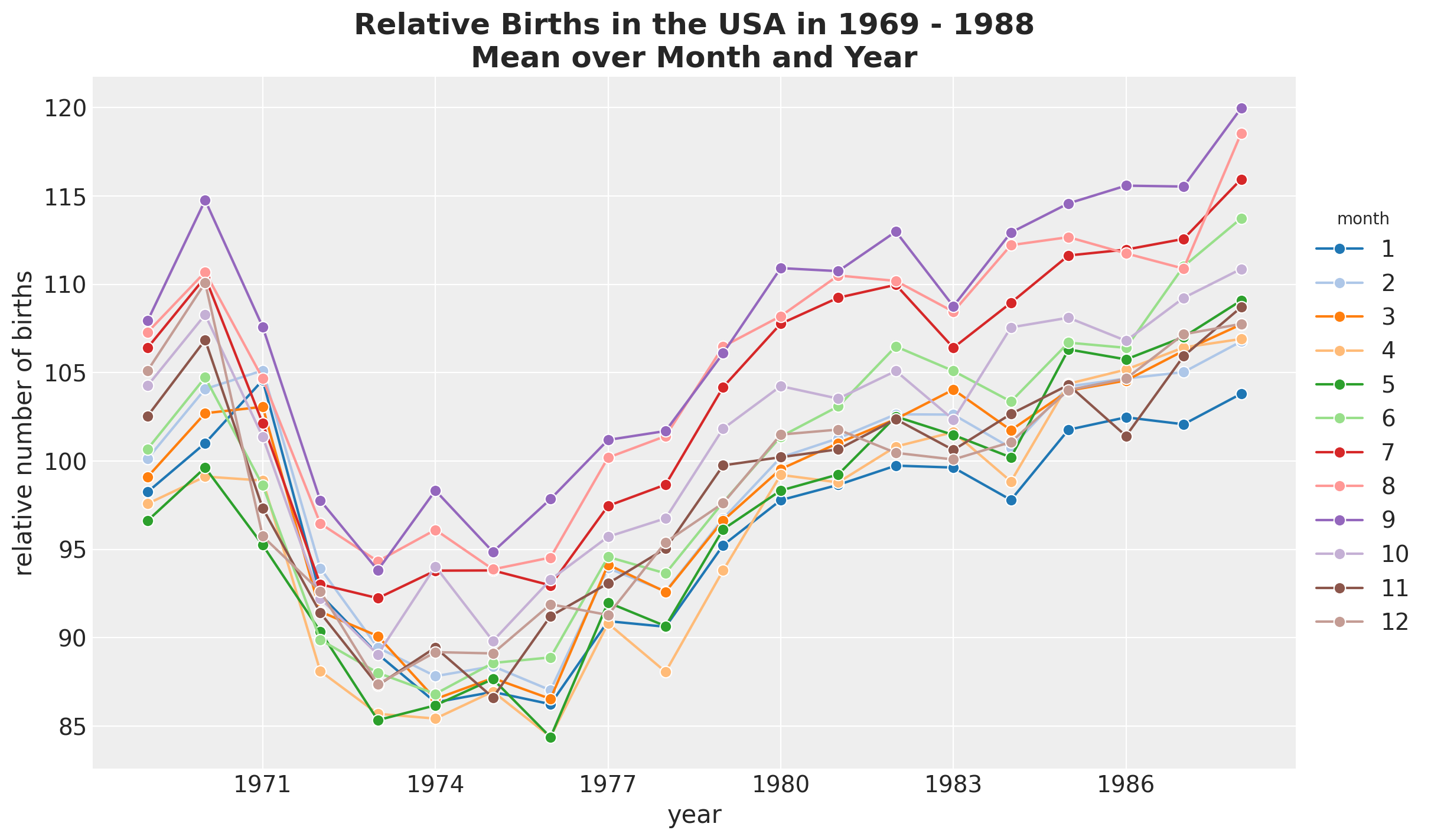
除了全球趋势外,我们没有看到月份之间有任何明显的差异。
我们继续研究每周的季节性。
fig, ax = plt.subplots()
(
sns.lineplot(
data=data_df,
x="day_of_week",
y="births_relative100",
marker="o",
c="C0",
markersize=10,
ax=ax,
)
)
ax.axhline(100, color="black", linestyle="--", label="mean level")
ax.legend()
ax.set(xlabel="day of week", ylabel="relative number of births per day of week")
ax.set_title(
label="Relative Births in the USA in 1969 - 1988\nMean over Day of Week",
fontsize=18,
fontweight="bold",
);
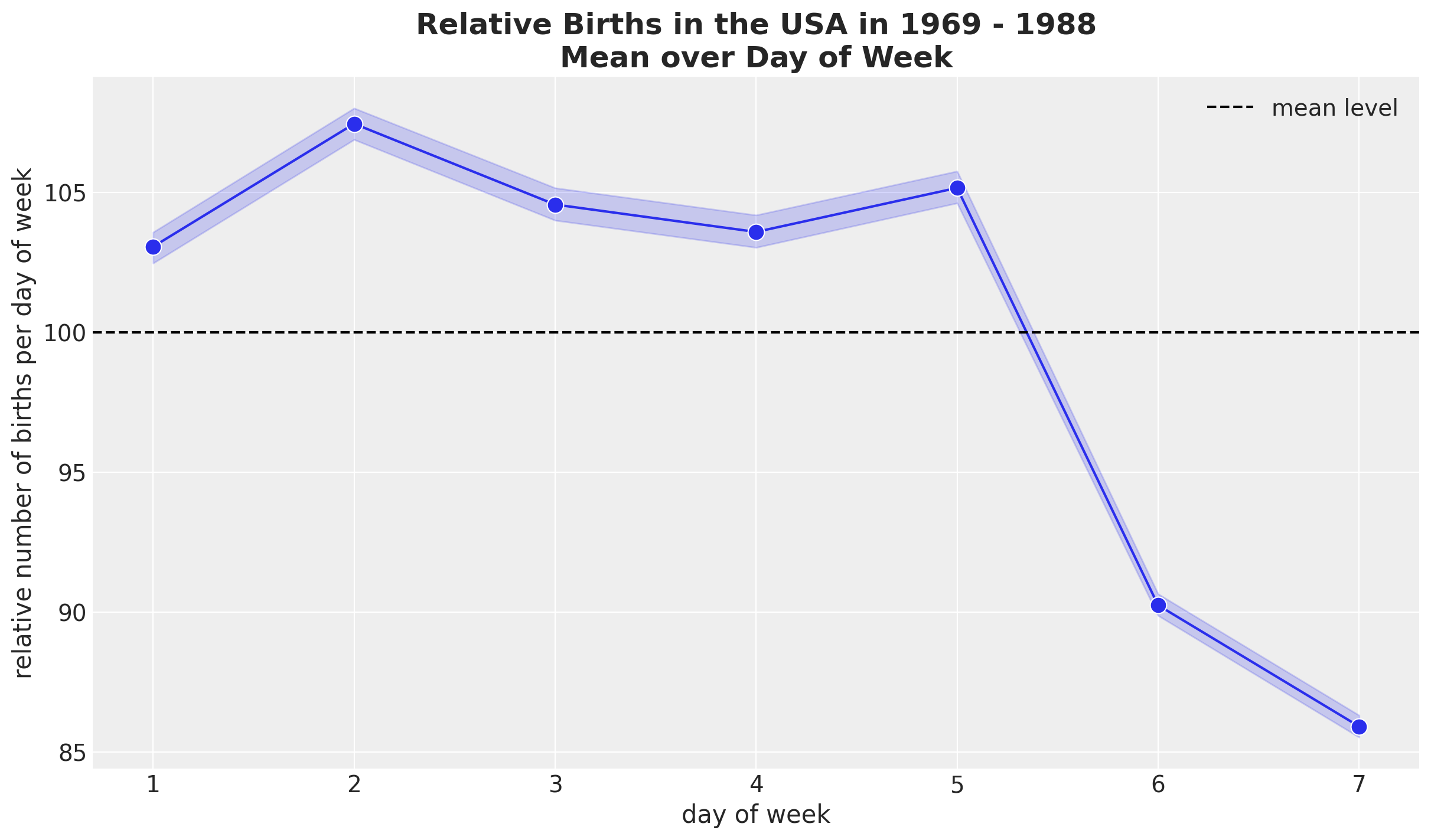
似乎周末的出生人数平均较少。
EDA 摘要
让我们总结一下 EDA 的主要发现
存在明显的非线性长期趋势。
存在明显的平滑年度季节性,直到某些特殊假期和年底下降。
存在明显的每周季节性。
数据预处理#
在更好地了解数据以及我们想要用模型捕获的模式之后,我们可以继续预处理数据。
提取相关特征
n = data_df.shape[0]
time = data_df["time"].to_numpy()
date = data_df["date"].to_numpy()
year = data_df["year"].to_numpy()
day_of_week_idx, day_of_week = data_df["day_of_week"].factorize(sort=True)
day_of_week_no_monday = day_of_week[day_of_week != 1]
day_of_year2_idx, day_of_year2 = data_df["day_of_year2"].factorize(sort=True)
births_relative100 = data_df["births_relative100"].to_numpy()
data_df.head(10)
| 年份 | 月份 | 日期 | 出生人数 | 一年中的某天 | 星期几 | ID | 一年中的某天 2 | 日期 | births_relative100 | 时间 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1969 | 1 | 1 | 8486 | 1 | 3 | 1 | 1 | 1969-01-01 | 87.947483 | 0 |
| 1 | 1969 | 1 | 2 | 9002 | 2 | 4 | 2 | 2 | 1969-01-02 | 93.295220 | 1 |
| 2 | 1969 | 1 | 3 | 9542 | 3 | 5 | 3 | 3 | 1969-01-03 | 98.891690 | 2 |
| 3 | 1969 | 1 | 4 | 8960 | 4 | 6 | 4 | 4 | 1969-01-04 | 92.859939 | 3 |
| 4 | 1969 | 1 | 5 | 8390 | 5 | 7 | 5 | 5 | 1969-01-05 | 86.952555 | 4 |
| 5 | 1969 | 1 | 6 | 9560 | 6 | 1 | 6 | 6 | 1969-01-06 | 99.078239 | 5 |
| 6 | 1969 | 1 | 7 | 9738 | 7 | 2 | 7 | 7 | 1969-01-07 | 100.923001 | 6 |
| 7 | 1969 | 1 | 8 | 9734 | 8 | 3 | 8 | 8 | 1969-01-08 | 100.881546 | 7 |
| 8 | 1969 | 1 | 9 | 9434 | 9 | 4 | 9 | 9 | 1969-01-09 | 97.772396 | 8 |
| 9 | 1969 | 1 | 10 | 10042 | 10 | 5 | 10 | 10 | 1969-01-10 | 104.073606 | 9 |
我们希望在相对出生人数的归一化对数尺度上工作。这样做的原因是,在一个更容易设置先验(缩放空间)的尺度上工作,并减少异方差性(对数变换)。
# we want to use the scale of the data size to set up the priors.
# we are mainly interested in the standard deviation.
time_pipeline = Pipeline(steps=[("scaler", StandardScaler())])
time_pipeline.fit(time.reshape(-1, 1))
normalized_time = time_pipeline.transform(time.reshape(-1, 1)).flatten()
time_std = time_pipeline["scaler"].scale_.item()
# we first take a log transform and then normalize the data.
births_relative100_pipeline = Pipeline(
steps=[
("log", FunctionTransformer(func=np.log, inverse_func=np.exp)),
("scaler", StandardScaler()),
]
)
births_relative100_pipeline.fit(births_relative100.reshape(-1, 1))
normalized_log_births_relative100 = births_relative100_pipeline.transform(
births_relative100.reshape(-1, 1)
).flatten()
normalized_log_births_relative100_std = births_relative100_pipeline["scaler"].scale_.item()
fig, ax = plt.subplots()
ax.plot(normalized_time, normalized_log_births_relative100, "o", c="C0", markersize=2)
ax.set(xlabel="normalized time", ylabel="relative number of births - Transformed")
ax.set_title(
label="Relative Births in the USA in 1969 - 1988\nTransformed Data",
fontsize=18,
fontweight="bold",
);
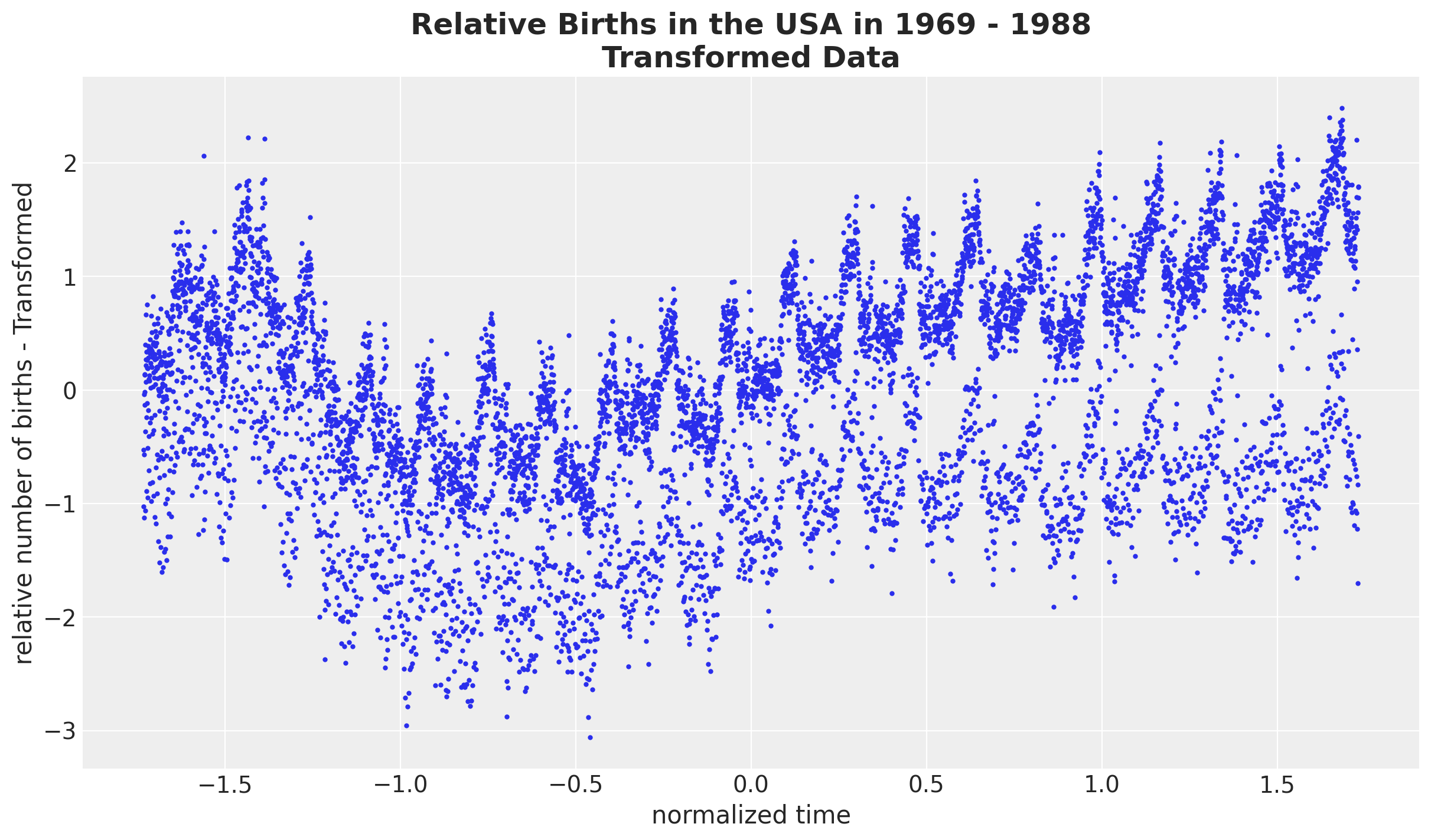
模型规范#
模型组件#
在本示例笔记本中,我们实现了 模型 3: 缓慢趋势 + 年度季节性趋势 + 星期几,如 [Vehtari,2022] 中所述。上面的 EDA 应该帮助我们理解模型以下每个组件背后的动机
全球趋势。 我们使用具有指数二次核的高斯过程。
多年周期性:我们使用具有周期核的高斯过程。请注意,由于我们正在归一化尺度上工作,因此周期应为
period=365.25 / time_std(而不是period=365.25!)。每周季节性:我们对星期几单热编码值使用正态分布。由于数据已标准化,特别是围绕零居中,因此我们不需要添加截距项。此外,我们将星期一的系数设置为零,以避免可识别性问题。
似然:我们使用高斯分布。
对于所有高斯过程组件,我们都使用希尔伯特空间高斯过程 (HSGP) 近似。
先验规范#
大多数先验信息量不大。这里唯一棘手的部分是考虑我们正在相对出生人数数据的归一化对数尺度上工作。例如,对于全球趋势,我们使用具有指数二次核的高斯过程。我们对长度尺度使用以下先验
fig, ax = plt.subplots()
pz.LogNormal(mu=np.log(700 / time_std), sigma=1).plot_pdf(ax=ax)
ax.set(xlim=(None, 4))
ax.set_title(
label="Prior distribution for the global trend Gaussian process",
fontsize=18,
fontweight="bold",
);
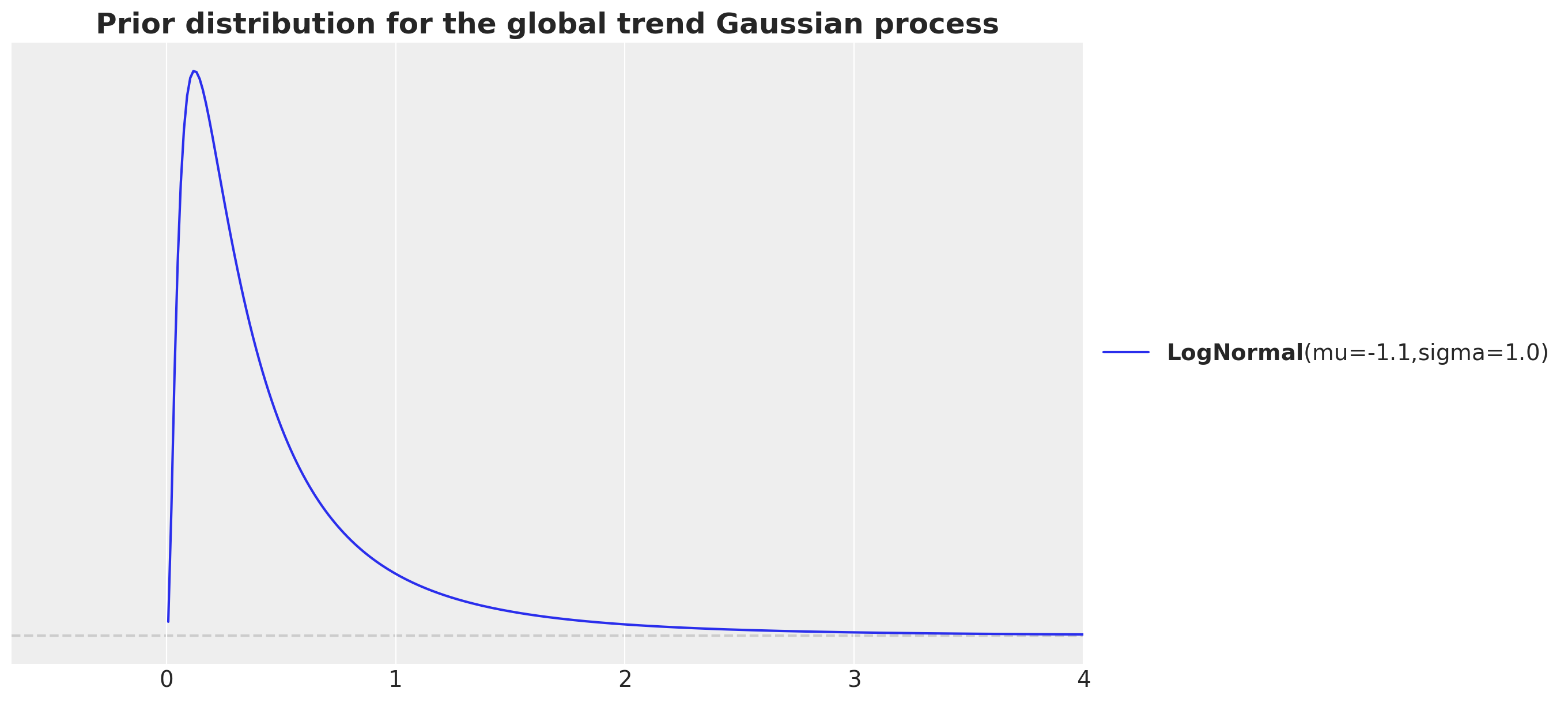
动机是我们有大约 \(7.3\)K 个数据点,并且我们想考虑归一化尺度中数据点之间的距离。这就是为什么我们考虑比率 7_000 / time_str。请注意,我们想要捕捉长期趋势,因此我们希望考虑大于数据点距离的长度尺度。我们将量级增加 10 倍,方法是除以 \(10\)。最后,由于 LogNormal 分布具有正支撑,并且是长度尺度的常用选择,因此我们对结果量 700 / time_str 进行对数变换,以确保先验的均值接近此值。
模型实现#
我们现在在 PyMC 中指定模型。
coords = {
"time": time,
"day_of_week_no_monday": day_of_week_no_monday,
"day_of_week": day_of_week,
"day_of_year2": day_of_year2,
}
with pm.Model(coords=coords) as model:
# --- Data Containers ---
normalized_time_data = pm.Data(
name="normalized_time_data", value=normalized_time, mutable=False, dims="time"
)
day_of_week_idx_data = pm.Data(
name="day_of_week_idx_data", value=day_of_week_idx, mutable=False, dims="time"
)
normalized_log_births_relative100_data = pm.Data(
name="log_births_relative100",
value=normalized_log_births_relative100,
mutable=False,
dims="time",
)
# --- Priors ---
# global trend
amplitude_trend = pm.HalfNormal(name="amplitude_trend", sigma=1.0)
ls_trend = pm.LogNormal(name="ls_trend", mu=np.log(700 / time_std), sigma=1)
cov_trend = amplitude_trend * pm.gp.cov.ExpQuad(input_dim=1, ls=ls_trend)
gp_trend = pm.gp.HSGP(m=[20], c=1.5, cov_func=cov_trend)
f_trend = gp_trend.prior(name="f_trend", X=normalized_time_data[:, None], dims="time")
## year periodic
amplitude_year_periodic = pm.HalfNormal(name="amplitude_year_periodic", sigma=1)
ls_year_periodic = pm.LogNormal(name="ls_year_periodic", mu=np.log(7_000 / time_std), sigma=1)
gp_year_periodic = pm.gp.HSGPPeriodic(
m=20,
scale=amplitude_year_periodic,
cov_func=pm.gp.cov.Periodic(input_dim=1, period=365.25 / time_std, ls=ls_year_periodic),
)
f_year_periodic = gp_year_periodic.prior(
name="f_year_periodic", X=normalized_time_data[:, None], dims="time"
)
## day of week
b_day_of_week_no_monday = pm.Normal(
name="b_day_of_week_no_monday", sigma=1, dims="day_of_week_no_monday"
)
b_day_of_week = pm.Deterministic(
name="b_day_of_week",
var=pt.concatenate(([0], b_day_of_week_no_monday)),
dims="day_of_week",
)
# global noise
sigma = pm.HalfNormal(name="sigma", sigma=0.5)
# --- Parametrization ---
mu = pm.Deterministic(
name="mu",
var=f_trend
+ f_year_periodic
+ b_day_of_week[day_of_week_idx_data] * (day_of_week_idx_data > 0),
dims="time",
)
# --- Likelihood ---
pm.Normal(
name="likelihood",
mu=mu,
sigma=sigma,
observed=normalized_log_births_relative100_data,
dims="time",
)
pm.model_to_graphviz(model=model)

提示
在 [Orduz,2024] 中描述了星期几的替代参数化。我们可以使用 ZeroSumNormal 分布通过工作日之间的相对差异进行参数化。我们只需将先验 b_day_of_week 替换为
b_day_of_week = pm.ZeroSumNormal(name="b_day_of_week", sigma=1, dims="day_of_week")
先验预测检查#
我们运行带有先验预测检查的模型,以查看模型是否能够生成与数据相似尺度的数据。
with model:
prior_predictive = pm.sample_prior_predictive(samples=2_000, random_seed=rng)
Sampling: [amplitude_trend, amplitude_year_periodic, b_day_of_week_no_monday, f_trend_hsgp_coeffs_, f_year_periodic_hsgp_coeffs_, likelihood, ls_trend, ls_year_periodic, sigma]
fig, ax = plt.subplots()
az.plot_ppc(data=prior_predictive, group="prior", kind="kde", ax=ax)
ax.set_title(label="Prior Predictive", fontsize=18, fontweight="bold");
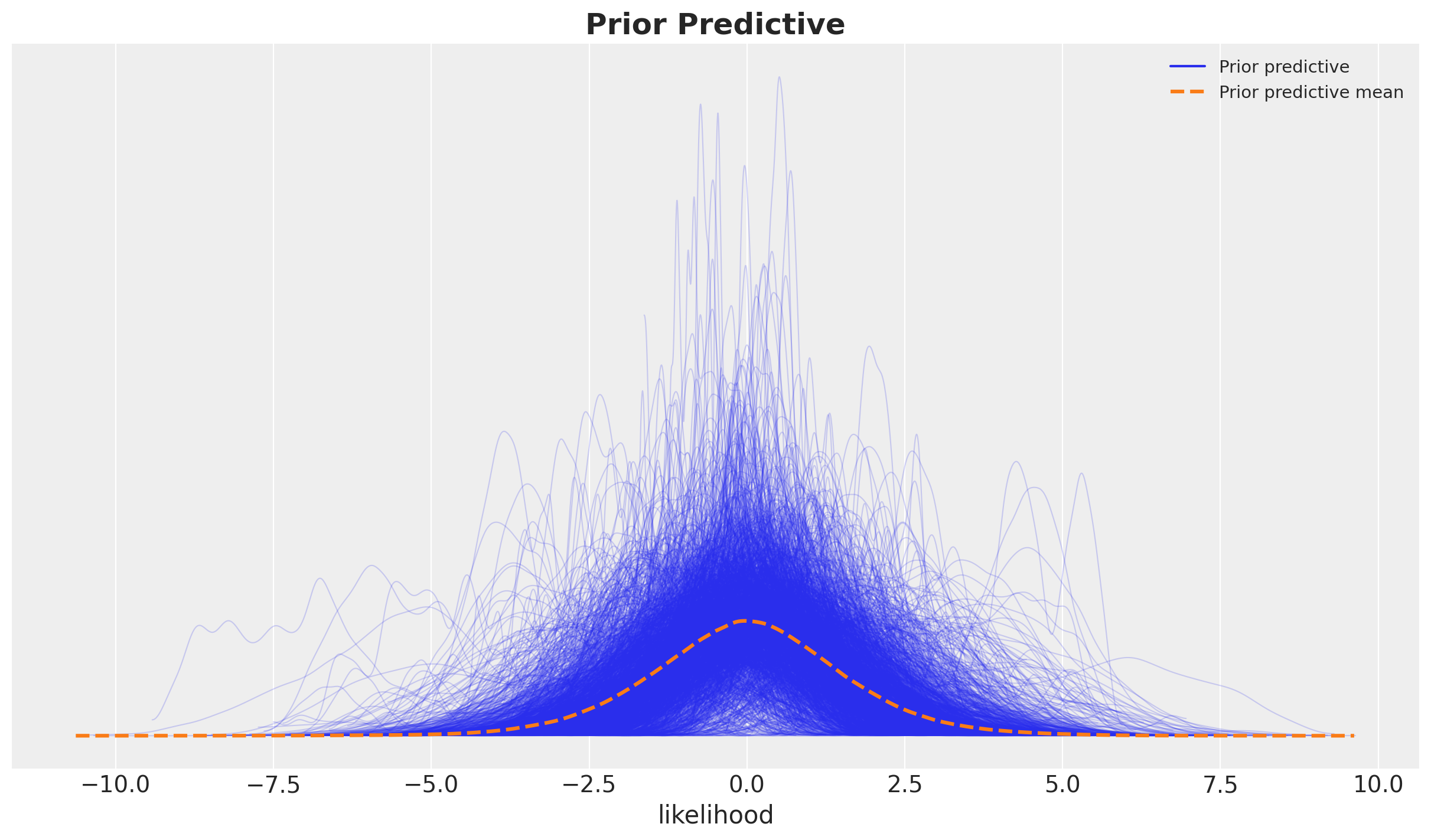
看起来非常合理,因为先验样本在观测数据的合理范围内。
模型拟合和诊断#
我们现在继续使用 NumPyro 采样器拟合模型。在本地运行模型大约需要 \(5\) 分钟(Intel MacBook Pro,\(4\) 核,\(16\) GB RAM)。
with model:
idata = pm.sample(
target_accept=0.9,
draws=2_000,
chains=4,
nuts_sampler="numpyro",
random_seed=rng,
)
idata.extend(pm.sample_posterior_predictive(trace=idata, random_seed=rng))
Sampling: [likelihood]
诊断#
我们没有看到任何发散或非常高的 r-hat 值
idata["sample_stats"]["diverging"].sum().item()
0
var_names = [
"amplitude_trend",
"ls_trend",
"amplitude_year_periodic",
"ls_year_periodic",
"b_day_of_week_no_monday",
"sigma",
]
az.summary(data=idata, var_names=var_names, round_to=3)
| 均值 | 标准差 | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| amplitude_trend | 0.449 | 0.217 | 0.160 | 0.843 | 0.004 | 0.003 | 2285.167 | 3955.338 | 1.002 |
| ls_trend | 0.207 | 0.039 | 0.133 | 0.273 | 0.001 | 0.001 | 2335.080 | 1918.541 | 1.002 |
| amplitude_year_periodic | 0.997 | 0.146 | 0.749 | 1.272 | 0.005 | 0.003 | 852.840 | 1850.789 | 1.003 |
| ls_year_periodic | 0.151 | 0.013 | 0.127 | 0.177 | 0.000 | 0.000 | 1343.954 | 2863.197 | 1.006 |
| b_day_of_week_no_monday[2] | 0.356 | 0.014 | 0.328 | 0.383 | 0.000 | 0.000 | 4972.172 | 5667.910 | 1.000 |
| b_day_of_week_no_monday[3] | 0.125 | 0.014 | 0.099 | 0.152 | 0.000 | 0.000 | 4879.317 | 5806.933 | 1.001 |
| b_day_of_week_no_monday[4] | 0.040 | 0.015 | 0.013 | 0.068 | 0.000 | 0.000 | 4835.465 | 5425.332 | 1.001 |
| b_day_of_week_no_monday[5] | 0.172 | 0.014 | 0.145 | 0.199 | 0.000 | 0.000 | 4841.564 | 6091.857 | 1.000 |
| b_day_of_week_no_monday[6] | -1.108 | 0.014 | -1.135 | -1.081 | 0.000 | 0.000 | 4854.558 | 5582.573 | 1.002 |
| b_day_of_week_no_monday[7] | -1.525 | 0.014 | -1.553 | -1.499 | 0.000 | 0.000 | 4764.057 | 5827.166 | 1.000 |
| sigma | 0.331 | 0.003 | 0.325 | 0.336 | 0.000 | 0.000 | 14065.037 | 5381.733 | 1.001 |
我们还可以查看迹图。
axes = az.plot_trace(
data=idata,
var_names=var_names,
compact=True,
backend_kwargs={"figsize": (15, 12), "layout": "constrained"},
)
plt.gcf().suptitle("Model Trace", fontsize=18, fontweight="bold");
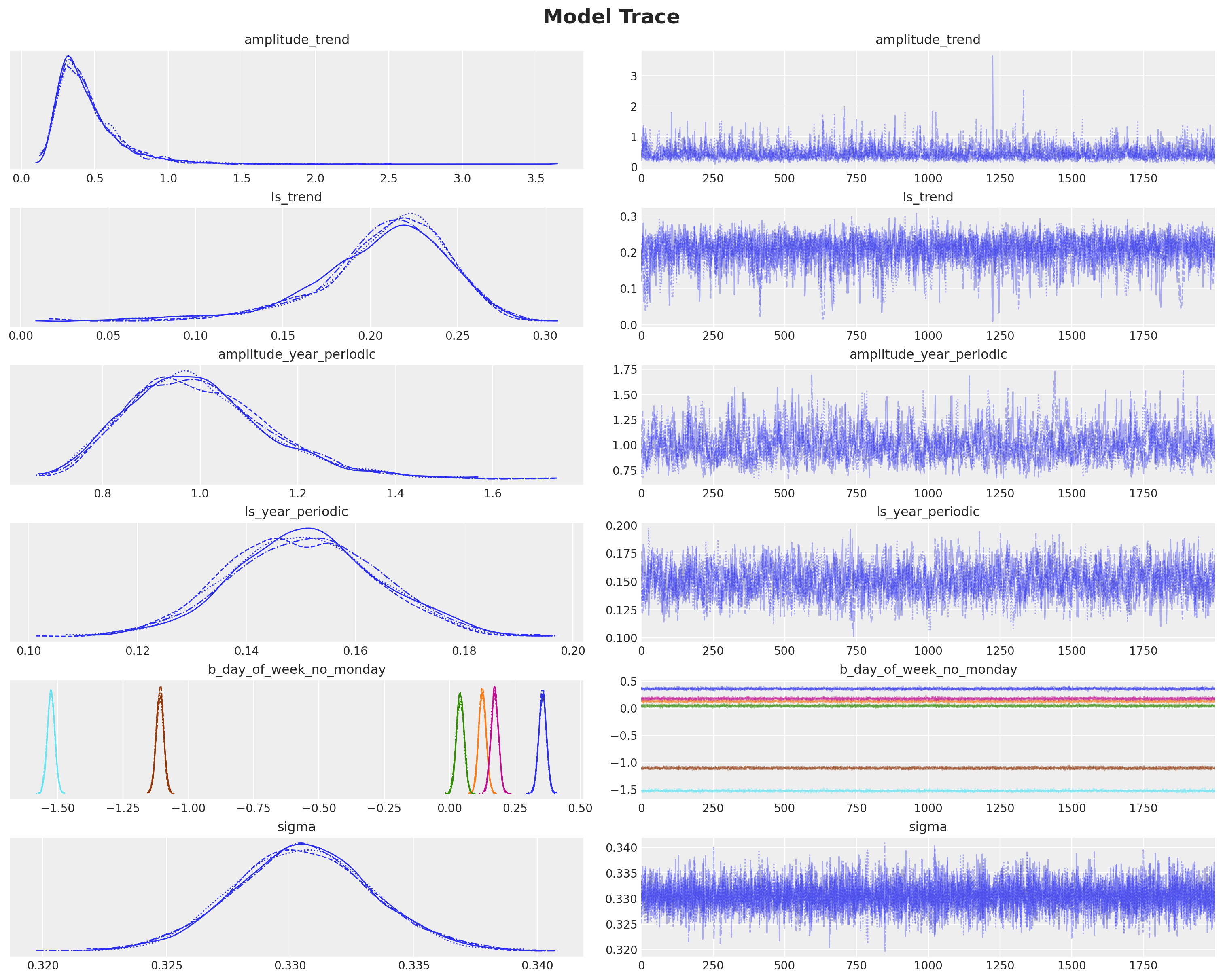
注意
请注意,我们得到了与博文 [Vehtari,2022] 中的 模型 3: 缓慢趋势 + 年度季节性趋势 + 星期几 相同的结果。
后验分布分析#
现在我们想深入研究模型的后验分布及其组件。我们想在原始尺度上执行此操作。因此,第一步是将后验样本转换回原始尺度。为此,我们使用以下实用程序函数(代码并不重要)。
显示代码单元格源
def apply_fn_along_dims(fn: Callable, a: xr.DataArray, dim: str) -> xr.DataArray:
"""Apply a function along a specific dimension.
We need to expand the dimensions of the input array to make it compatible with the
function which we assume acts on a matrix.
"""
return xr.apply_ufunc(
fn,
a.expand_dims(
dim={"_": 1}, axis=-1
), # The auxiliary dimension `_` is used to broadcast the function.
input_core_dims=[[dim, "_"]],
output_core_dims=[[dim, "_"]],
vectorize=True,
).squeeze(dim="_")
模型组件
pp_vars_original_scale = {
var_name: apply_fn_along_dims(
fn=births_relative100_pipeline.inverse_transform,
a=idata["posterior"][var_name],
dim="time",
)
for var_name in ["f_trend", "f_year_periodic"]
}
似然
pp_likelihood_original_scale = apply_fn_along_dims(
fn=births_relative100_pipeline.inverse_transform,
a=idata["posterior_predictive"]["likelihood"],
dim="time",
)
我们首先绘制似然。
显示代码单元格源
fig, ax = plt.subplots(figsize=(15, 9))
sns.scatterplot(data=data_df, x="date", y="births_relative100", c="C0", s=8, label="data", ax=ax)
ax.axhline(100, color="black", linestyle="--", label="mean level")
az.plot_hdi(
x=date,
y=pp_likelihood_original_scale,
hdi_prob=0.94,
color="C1",
fill_kwargs={"alpha": 0.2, "label": r"likelihood $94\%$ HDI"},
smooth=False,
ax=ax,
)
az.plot_hdi(
x=date,
y=pp_likelihood_original_scale,
hdi_prob=0.5,
color="C1",
fill_kwargs={"alpha": 0.6, "label": r"likelihood $50\%$ HDI"},
smooth=False,
ax=ax,
)
ax.legend(loc="upper center", bbox_to_anchor=(0.5, -0.07), ncol=4)
ax.set(xlabel="date", ylabel="relative number of births")
ax.set_title(
label="""Relative Births in the USA in 1969 - 1988
Posterior Predictive (Likelihood)""",
fontsize=18,
fontweight="bold",
);
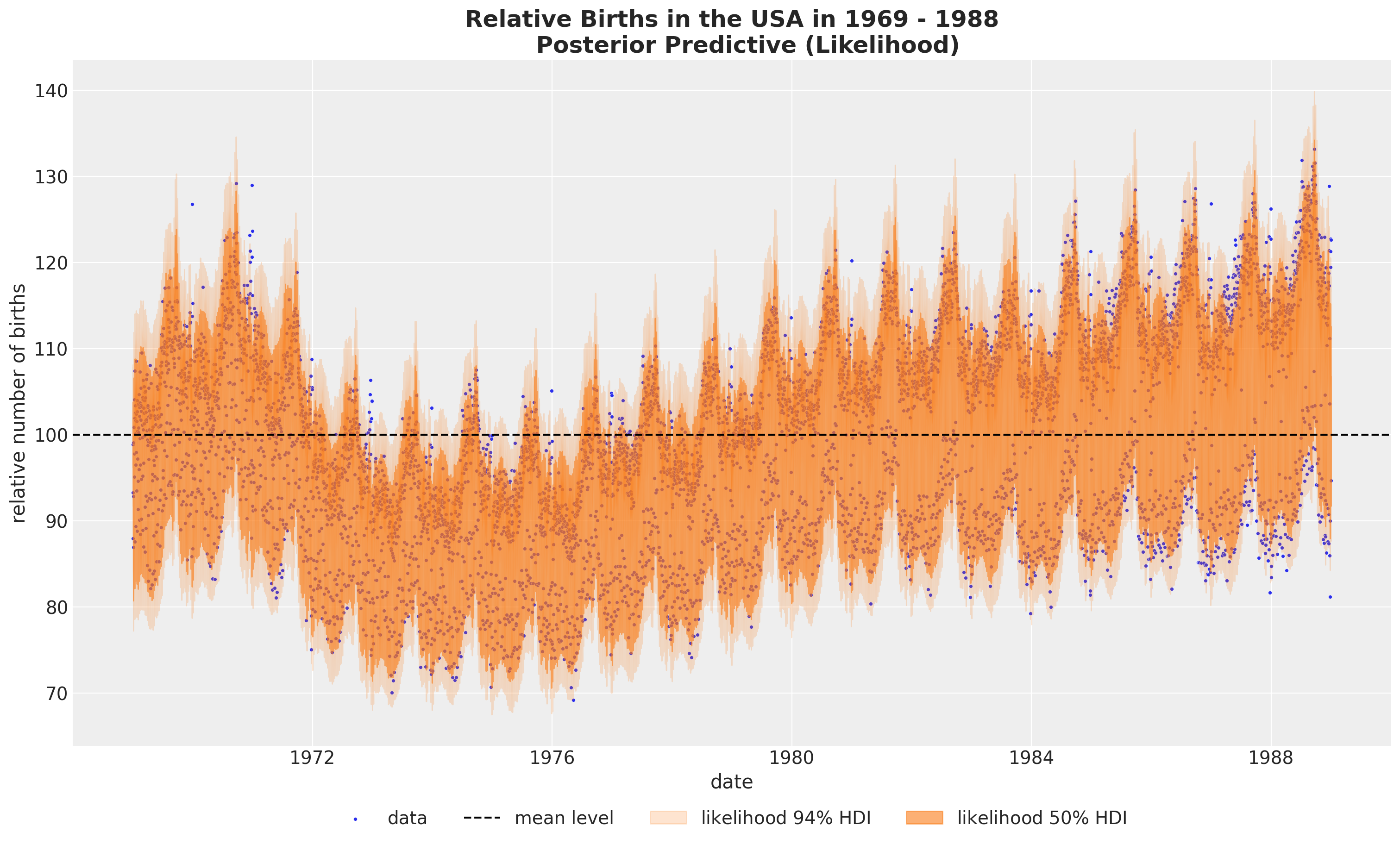
看起来我们正在捕捉全局变化。让我们看一下后验分布图,以更好地了解模型。
fig, ax = plt.subplots()
az.plot_ppc(
data=idata,
num_pp_samples=1_000,
observed_rug=True,
random_seed=seed,
ax=ax,
)
ax.set_title(label="Posterior Predictive", fontsize=18, fontweight="bold");
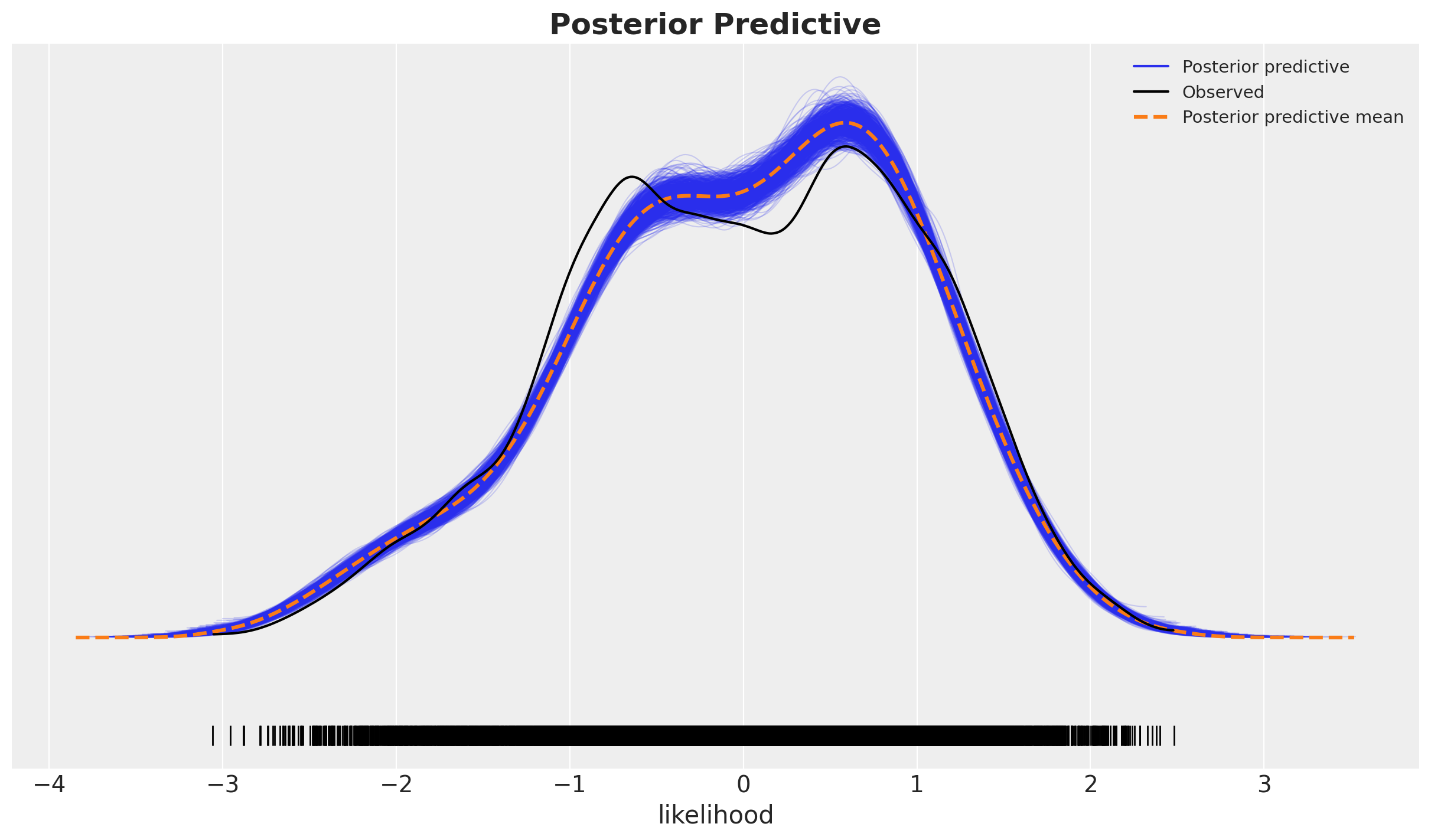
这看起来不太好,因为后验的大部分中黑线和阴影蓝色之间存在相当大的差异,尾部看起来不错。这表明我们可能遗漏了一些协变量。我们将在稍后更复杂的模型中探讨这一点。
为了更好地理解模型拟合,我们需要查看各个组件。
模型组件#
接下来,我们将可视化模型的主要组件中的每一个。我们编写一个实用程序函数来执行此操作。
显示代码单元格源
def plot_component(
component_name: str, color: str, component_label: str
) -> tuple[plt.Figure, plt.Axes]:
fig, ax = plt.subplots(figsize=(15, 9))
sns.scatterplot(
data=data_df, x="date", y="births_relative100", c="C0", s=8, label="data", ax=ax
)
ax.axhline(100, color="black", linestyle="--", label="mean level")
az.plot_hdi(
x=date,
y=pp_vars_original_scale[component_name],
hdi_prob=0.94,
color=color,
fill_kwargs={"alpha": 0.2, "label": rf"{component_label} $94\%$ HDI"},
smooth=False,
ax=ax,
)
az.plot_hdi(
x=date,
y=pp_vars_original_scale[component_name],
hdi_prob=0.5,
color=color,
fill_kwargs={"alpha": 0.6, "label": rf"{component_label} $50\%$ HDI"},
smooth=False,
ax=ax,
)
ax.legend(loc="upper center", bbox_to_anchor=(0.5, -0.07), ncol=4)
ax.set(xlabel="date", ylabel="relative number of births")
ax.set_title(
label="""Relative Births in the USA in 1969-1988
Posterior Predictive (Global Trend)""",
fontsize=18,
fontweight="bold",
)
return fig, ax
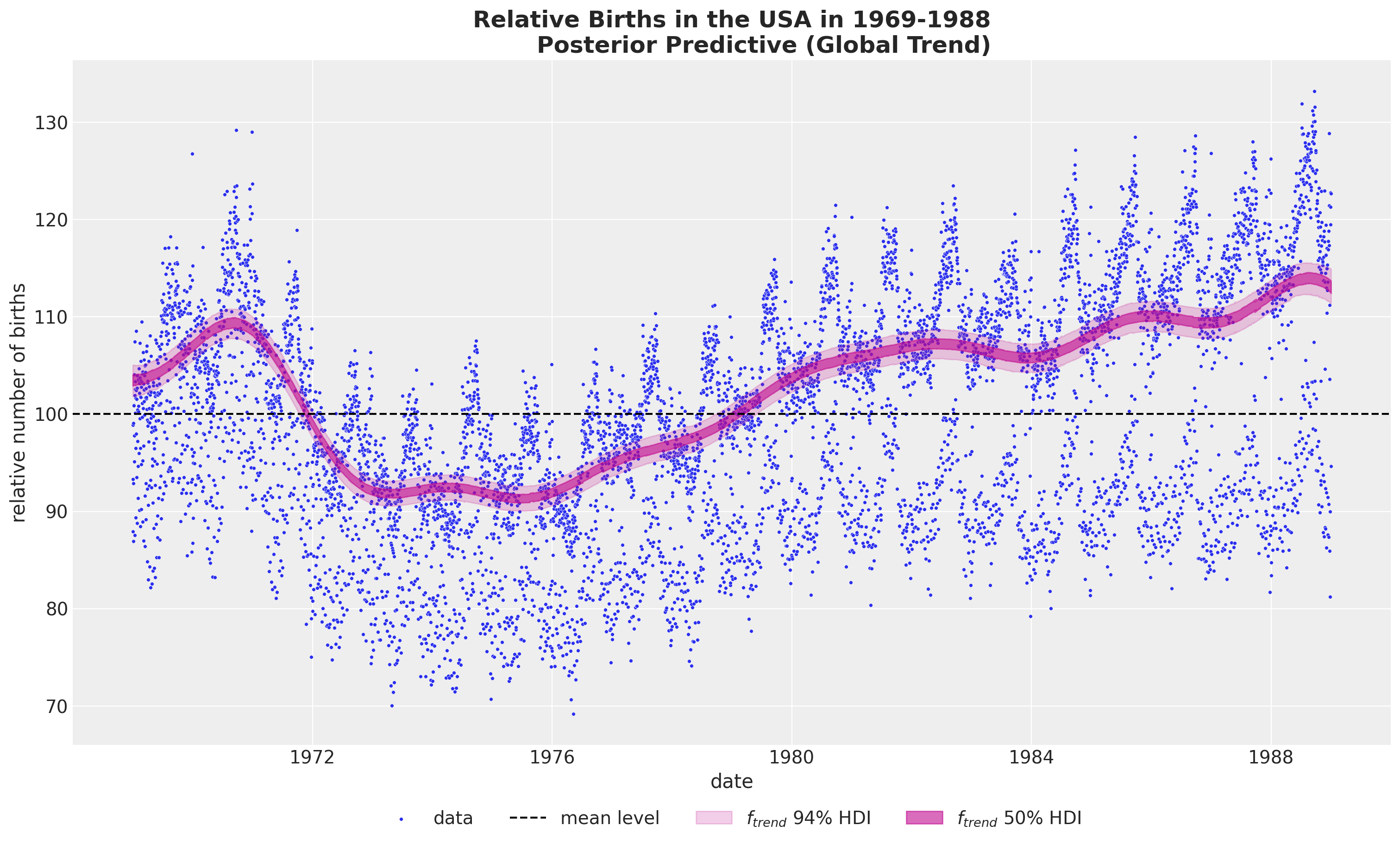
全球趋势#
fig, ax = plot_component(component_name="f_trend", color="C3", component_label="$f_{trend}$")
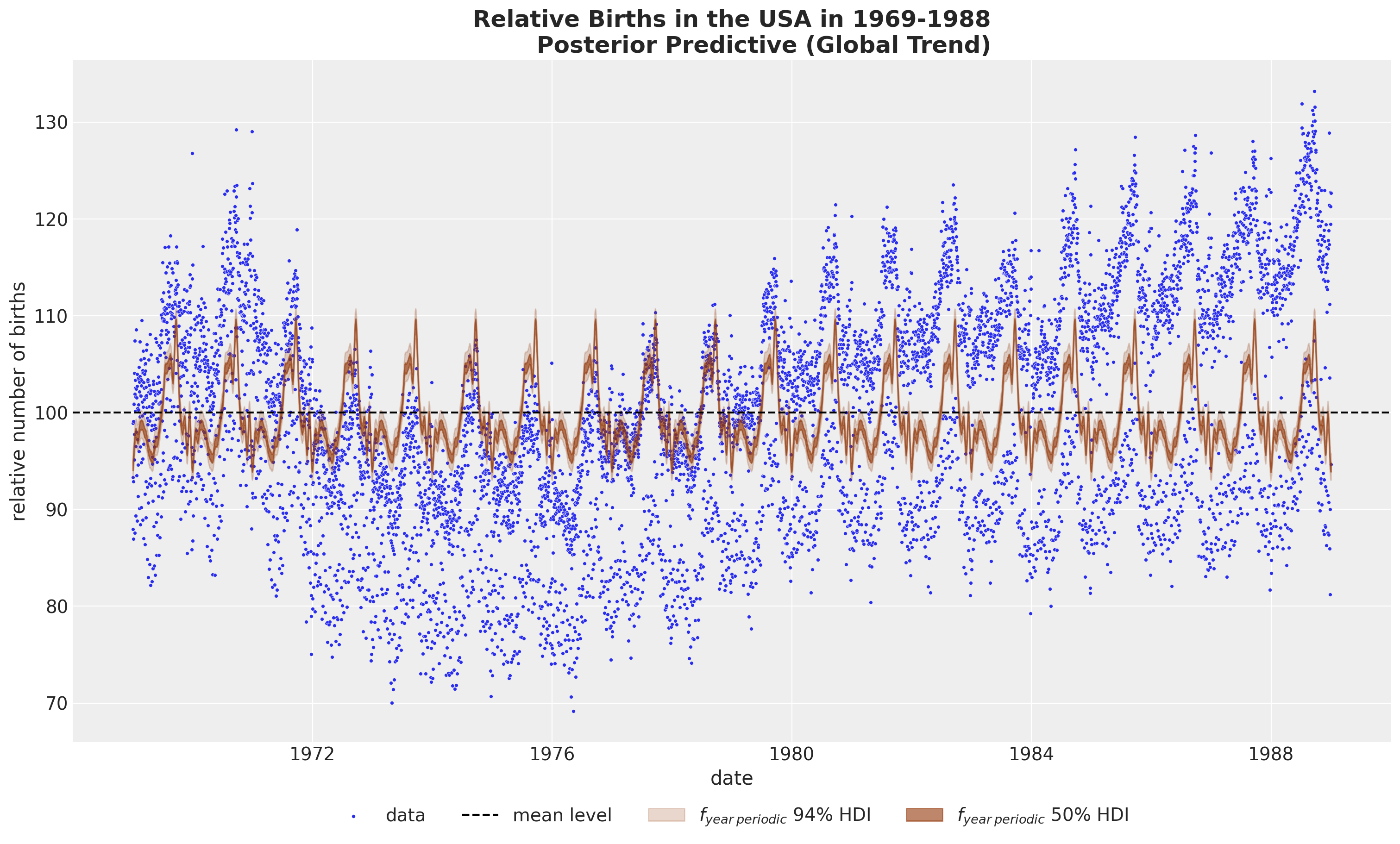
年度周期性#
fig, ax = plot_component(
component_name="f_year_periodic",
color="C4",
component_label=r"$f_{year \: periodic}$",
)
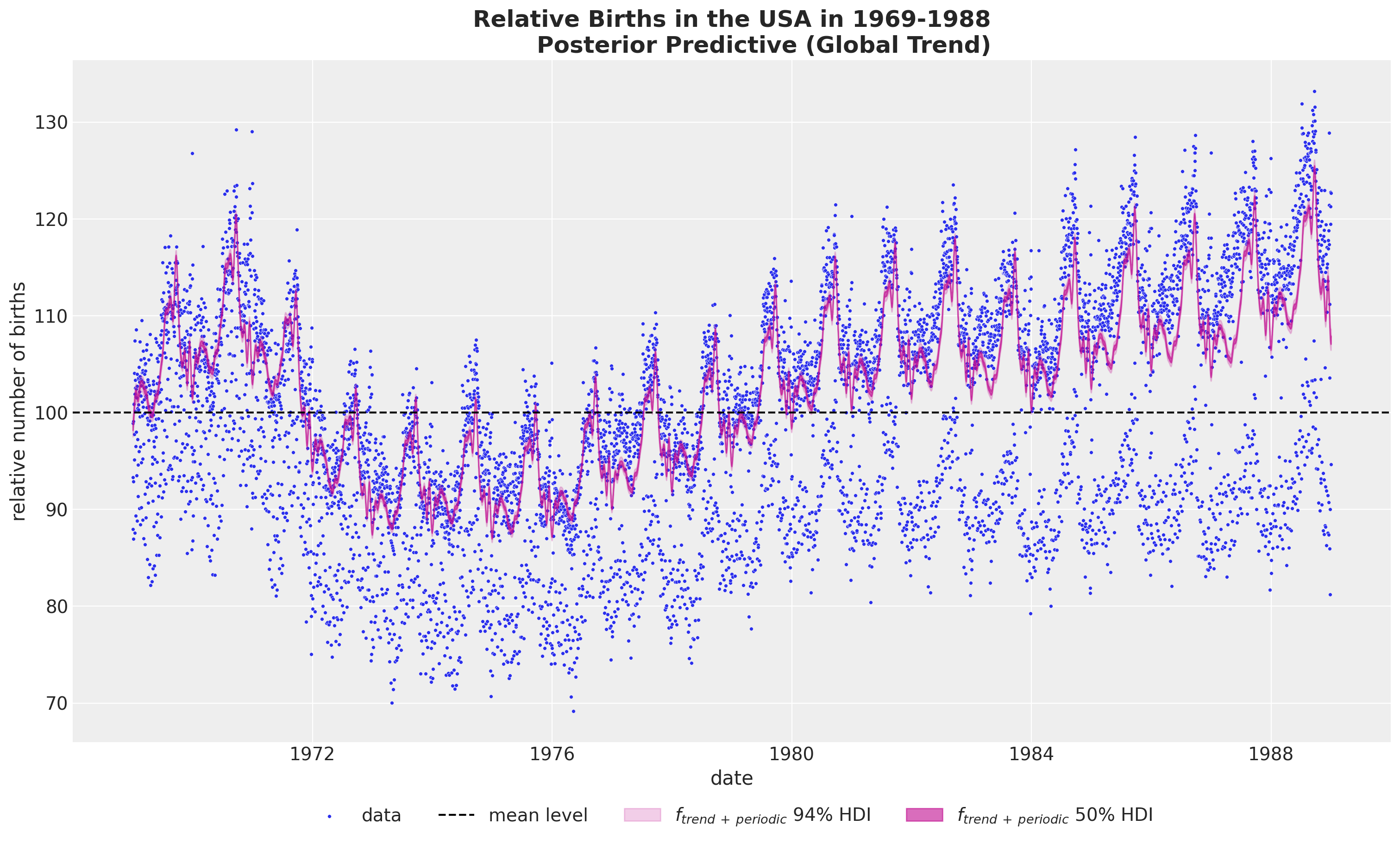
全球趋势加上年度周期性#
如果我们想结合全球趋势和年度周期性,我们不能简单地将原始尺度中的组件相加,因为我们会将均值项添加两次。相反,我们需要先将后验样本相加,然后再进行逆变换(这些操作不可交换!)。
pp_vars_original_scale["f_trend_periodic"] = apply_fn_along_dims(
fn=births_relative100_pipeline.inverse_transform,
a=idata["posterior"]["f_trend"] + idata["posterior"]["f_year_periodic"],
dim="time",
)
fig, ax = plot_component(
component_name="f_trend_periodic",
color="C3",
component_label=r"$f_{trend \: + \: periodic}$",
)
结论#
我们希望您更好地理解 HSGP 以及如何在实践中使用非常方便的 PyMC API。能够策略性地将 GP 折叠到更大的模型中真是太好了。GP 可以“实现”,但 HSGP 使其真正成为可能。原因是每个 GP 组件的复杂度通过近似从 \(\mathcal{O}(n^3)\) 降低到 \(\mathcal{O}(nm + m)\),其中 \(m\) 是近似中使用的基函数的数量。这是一个巨大的加速!
HSGP 局限性
请记住,HSGP 不是万能药。
实际上,这不是一个巨大的限制,因为大多数时候我们都使用平稳协方差和低输入维度。
在未来的笔记本中,我们将展示一个更完整的模型,以便与 Vehtari 的结果进行比较。敬请期待!
致谢#
我要感谢 Alex Andorra 和 Bill Engels 在本笔记本的编写过程中提供的宝贵反馈和建议。
参考文献#
Andrew Gelman、John B. Carlin、Hal S. Stern、David B. Dunson、Aki Vehtari 和 Donald B. Rubin。贝叶斯数据分析。Chapman and Hall/CRC,2013 年。
Arno Solin 和 Simo Särkkä。用于降秩高斯过程回归的希尔伯特空间方法。统计与计算,30(2):419–446, 2020。URL: https://doi.org/10.1007/s11222-019-09886-w,doi:10.1007/s11222-019-09886-w。
Aki Vehtari。《贝叶斯工作流书 - 生日》。2022。URL: https://avehtari.github.io/casestudies/Birthdays/birthdays.html(访问于 2022-03-07)。
Gabriel Riutort-Mayol、Paul-Christian Bürkner、Michael R. Andersen、Arno Solin 和 Aki Vehtari。用于概率编程的实用希尔伯特空间近似贝叶斯高斯过程。统计与计算,33(1):17, 2022。URL: https://doi.org/10.1007/s11222-022-10167-2,doi:10.1007/s11222-022-10167-2。
示例:高斯过程的希尔伯特空间近似。URL: https://num.pyro.org.cn/en/stable/examples/hsgp.html。
Juan Orduz。《使用 hsgp 的时间序列建模:婴儿出生示例》。2024。URL: https://juanitorduz.github.io/birthdays/(访问于 2024-01-02)。
水印#
%load_ext watermark
%watermark -n -u -v -iv -w -p numpyro,pytensor
Last updated: Fri Mar 29 2024
Python implementation: CPython
Python version : 3.11.7
IPython version : 8.20.0
numpyro : 0.14.0
pytensor: 2.19.0
pandas : 2.1.4
preliz : 0.4.1
matplotlib: 3.8.2
pytensor : 2.19.0
pymc : 5.12.0
seaborn : 0.13.2
numpy : 1.26.3
xarray : 2024.2.0
arviz : 0.17.1
Watermark: 2.4.3
许可声明#
本示例库中的所有笔记本均根据 MIT 许可证 提供,该许可证允许修改和重新分发以用于任何用途,前提是保留版权和许可证声明。
引用 PyMC 示例#
要引用本笔记本,请使用 Zenodo 为 pymc-examples 存储库提供的 DOI。
重要提示
许多笔记本改编自其他来源:博客、书籍... 在这种情况下,您也应该引用原始来源。
另请记住引用您的代码使用的相关库。
这是一个 bibtex 中的引用模板
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
呈现后可能看起来像