


通用 API 快速入门#
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pymc as pm
import pytensor.tensor as pt
/home/xian/anaconda3/envs/pymc-dev-py39/lib/python3.9/site-packages/pkg_resources/__init__.py:123: PkgResourcesDeprecationWarning: main is an invalid version and will not be supported in a future release
warnings.warn(
RANDOM_SEED = 8927
rng = np.random.default_rng(RANDOM_SEED)
az.style.use("arviz-darkgrid")
1. 模型创建#
PyMC 中的模型以 Model 类为中心。它引用所有随机变量 (RV),并计算模型 logp 及其梯度。通常,您会将其实例化为 with 上下文的一部分
with pm.Model() as model:
# Model definition
pass
我们将在下面进一步讨论 RV,但让我们创建一个简单的模型来探索 Model 类。
model.basic_RVs
[mu ~ N(0, 1), obs ~ N(mu, 1)]
model.free_RVs
[mu ~ N(0, 1)]
model.observed_RVs
[obs ~ N(mu, 1)]
model.compile_logp()({"mu": 0})
array(-143.03962875)
值得强调我们对 logp 所做的设计选择。正如您在上面看到的,logp 是通过参数调用的,所以它是模型实例的方法。更准确地说,它基于模型的当前状态或作为参数提供给 logp 的状态(请参见下面的示例)将函数放在一起。
出于各种原因,我们假设 Model 实例不是静态的。如果您需要在内部循环中使用 logp 并且它需要是静态的,只需使用类似 logp = model.logp 的东西。这是一个下面的示例 – 请注意缓存效果和加速
%timeit model.compile_logp()({"mu": 0.1})
logp = model.compile_logp()
%timeit logp({"mu": 0.1})
83 ms ± 7.1 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
18 µs ± 276 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
2. 概率分布#
每个概率程序都由观测到的和未观测到的随机变量 (RV) 组成。观测到的 RV 通过似然分布定义,而未观测到的 RV 通过先验分布定义。在 PyMC 模块中,概率分布的结构如下所示
pymc:api_distributions_continuous
pymc:api_distributions_discrete
pymc:api_distributions_multivariate
pymc:api_distributions_mixture
pymc:api_distributions_timeseries
pymc:api_distributions_censored
pymc:api_distributions_simulator
未观测到的随机变量#
每个未观测到的 RV 都有以下调用签名:名称 (str)、参数关键字参数。因此,可以在模型上下文中定义正态先验,如下所示
with pm.Model():
x = pm.Normal("x", mu=0, sigma=1)
与模型一样,我们可以评估其 logp
pm.logp(x, 0).eval()
array(-0.91893853)
观测到的随机变量#
观测到的 RV 的定义方式与未观测到的 RV 相同,但需要将数据传递到 observed 关键字参数中
with pm.Model():
obs = pm.Normal("x", mu=0, sigma=1, observed=rng.standard_normal(100))
observed 支持列表、numpy.ndarray 和 pytensor 数据结构。
确定性变换#
PyMC 允许您以各种方式自由地对 RV 进行代数运算
with pm.Model():
x = pm.Normal("x", mu=0, sigma=1)
y = pm.Gamma("y", alpha=1, beta=1)
plus_2 = x + 2
summed = x + y
squared = x**2
sined = pm.math.sin(x)
尽管这些转换可以无缝工作,但它们的结果不会自动存储。因此,如果您想跟踪转换后的变量,则必须使用 pm.Deterministic
with pm.Model():
x = pm.Normal("x", mu=0, sigma=1)
plus_2 = pm.Deterministic("x plus 2", x + 2)
请注意,plus_2 可以以与上述相同的方式使用,我们只是告诉 PyMC 跟踪此 RV。
RV 列表/更高维度的 RV#
上面我们已经看到了如何创建标量 RV。在许多模型中,我们想要多个 RV。用户有时会尝试创建 RV 列表,如下所示
with pm.Model():
# bad:
x = [pm.Normal(f"x_{i}", mu=0, sigma=1) for i in range(10)]
这可以工作,但速度很慢,不建议使用。相反,我们可以使用 坐标
coords = {"cities": ["Santiago", "Mumbai", "Tokyo"]}
with pm.Model(coords=coords) as model:
# good:
x = pm.Normal("x", mu=0, sigma=1, dims="cities")
x 现在是一个长度为 3 的数组,并且此数组中的 3 个变量中的每一个都与一个标签关联。这将使我们在查看结果时很容易区分这 3 个不同的变量。我们可以索引到这个数组或对其进行线性代数运算
with model:
y = x[0] * x[1] # indexing is supported
x.dot(x.T) # linear algebra is supported
初始化随机变量#
尽管 PyMC 会自动初始化模型,但有时定义 RV 的初始值会很有帮助。这可以通过 initval kwarg 完成
{'x': array([0., 0., 0., 0., 0.])}
{'x': array([-0.36012097, -0.16168135, 1.07485641, -0.08855632, -0.03857412])}
当尝试识别模型规范或初始化问题时,此技术有时很有用。
3. 推断#
定义模型后,我们必须执行推断以近似后验分布。PyMC 支持两大类推断:抽样和变分推断。
3.1 抽样#
MCMC 抽样算法的主要入口点是通过 pm.sample() 函数。默认情况下,此函数尝试自动分配正确的采样器。pm.sample() 返回一个 arviz.InferenceData 对象。InferenceData 对象可以轻松地从文件保存/加载,并且可以携带额外的(元)数据,例如日期/版本和后验预测样本。查看 ArviZ 快速入门 以了解更多信息。
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [mu]
Sampling 2 chains for 1_000 tune and 2_000 draw iterations (2_000 + 4_000 draws total) took 4 seconds.
正如您所看到的,对于仅包含连续变量的模型,PyMC 分配了 NUTS 采样器,即使对于复杂模型,它也非常高效。PyMC 还运行初始调整以找到采样器的良好起始参数。在这里,我们从每条链中的后验中抽取 2000 个样本,并允许采样器在额外的 1500 次迭代中调整其参数。
如果未通过 chains kwarg 设置,则链的数量由可用的 CPU 核心数决定。
idata.posterior.dims
Frozen({'chain': 2, 'draw': 2000})
默认情况下,调整样本会被丢弃。使用 discard_tuned_samples=False,它们可以被保留并最终出现在 InferenceData 对象(即 idata.warmup_posterior)中的单独组中。
您可以使用 chains 和 cores kwargs 控制链的并行运行方式
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (6 chains in 4 jobs)
NUTS: [mu]
Sampling 6 chains for 1_000 tune and 1_000 draw iterations (6_000 + 6_000 draws total) took 7 seconds.
idata.posterior["mu"].shape
(6, 1000)
# get values of a single chain
idata.posterior["mu"].sel(chain=2).shape
(1000,)
3.2 分析抽样结果#
分析抽样结果最常用的图是所谓的迹图
with pm.Model() as model:
mu = pm.Normal("mu", mu=0, sigma=1)
sd = pm.HalfNormal("sd", sigma=1)
obs = pm.Normal("obs", mu=mu, sigma=sd, observed=rng.standard_normal(100))
idata = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [mu, sd]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 4 seconds.
az.plot_trace(idata);
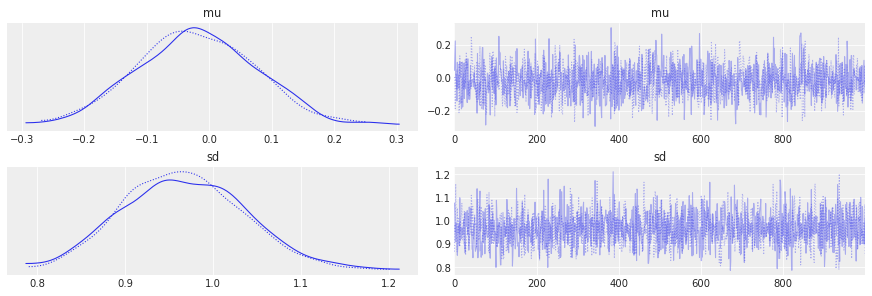
另一个要查看的常用指标是 Gelman-Rubin 统计量,或 R-hat
az.summary(idata)
| 均值 | 标准差 | hdi_3% | hdi_97% | mcse_均值 | mcse_标准差 | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
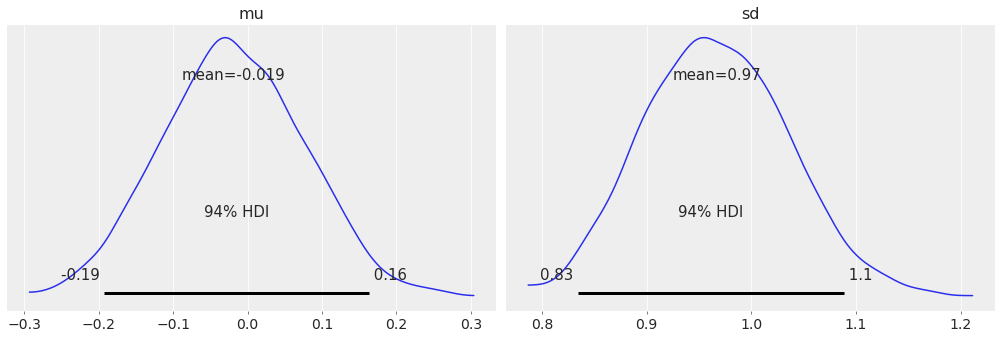
| mu | -0.019 | 0.096 | -0.193 | 0.163 | 0.002 | 0.002 | 1608.0 | 1343.0 | 1.0 |
| 标准差 | 0.967 | 0.069 | 0.835 | 1.089 | 0.002 | 0.001 | 1836.0 | 1406.0 | 1.0 |
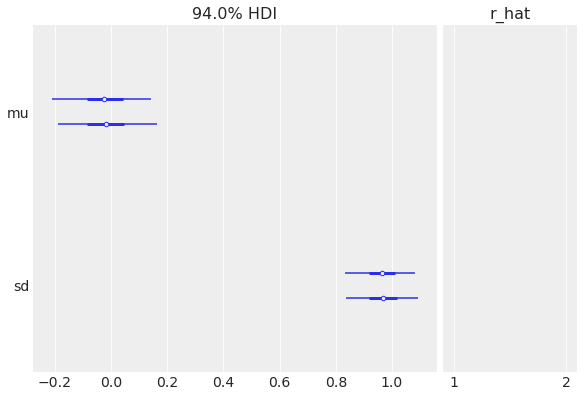
R-hat 也作为 az.plot_forest 的一部分呈现
az.plot_forest(idata, r_hat=True);
最后,对于受 [Kruschke, 2014] 启发的后验图,您可以使用
az.plot_posterior(idata);
对于高维模型,查看所有参数的迹图变得很麻烦。当使用 NUTS 时,我们可以查看能量图来评估收敛问题
with pm.Model(coords={"idx": np.arange(100)}) as model:
x = pm.Normal("x", mu=0, sigma=1, dims="idx")
idata = pm.sample()
az.plot_energy(idata);
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [x]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 5 seconds.
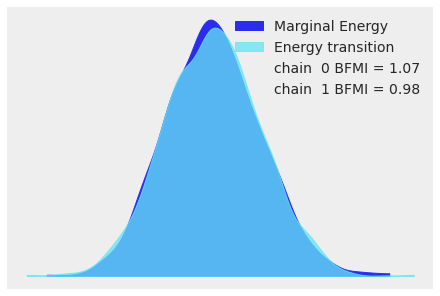
有关采样器统计信息和能量图的更多信息,请参见 采样器统计信息。有关识别采样问题以及如何处理它们的更多信息,请参见 使用发散诊断有偏推断。
3.3 变分推断#
PyMC 支持各种变分推断技术。虽然这些方法速度更快,但它们通常也不太准确,并且可能导致有偏推断。主要入口点是 pymc.fit()。
with pm.Model() as model:
mu = pm.Normal("mu", mu=0, sigma=1)
sd = pm.HalfNormal("sd", sigma=1)
obs = pm.Normal("obs", mu=mu, sigma=sd, observed=rng.standard_normal(100))
approx = pm.fit()
Finished [100%]: Average Loss = 142
返回的 Approximation 对象具有各种功能,例如从近似后验中抽取样本,我们可以像常规抽样运行一样对其进行分析
idata = approx.sample(1000)
az.summary(idata)
arviz - WARNING - Shape validation failed: input_shape: (1, 1000), minimum_shape: (chains=2, draws=4)
| 均值 | 标准差 | hdi_3% | hdi_97% | mcse_均值 | mcse_标准差 | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| mu | -0.023 | 0.169 | -0.338 | 0.296 | 0.005 | 0.004 | 973.0 | 880.0 | NaN |
| 标准差 | 0.989 | 0.158 | 0.694 | 1.262 | 0.005 | 0.004 | 972.0 | 1026.0 | NaN |
variational 子模块在使用哪个 VI 方面提供了很大的灵活性,并遵循面向对象的设计。例如,全秩 ADVI 估计一个完整的协方差矩阵
mu = pm.floatX([0.0, 0.0])
cov = pm.floatX([[1, 0.5], [0.5, 1.0]])
with pm.Model(coords={"idx": np.arange(2)}) as model:
pm.MvNormal("x", mu=mu, cov=cov, dims="idx")
approx = pm.fit(method="fullrank_advi")
Finished [100%]: Average Loss = 0.012772
使用面向对象接口的等效表达式是
with pm.Model(coords={"idx": np.arange(2)}) as model:
pm.MvNormal("x", mu=mu, cov=cov, dims="idx")
approx = pm.FullRankADVI().fit()
Finished [100%]: Average Loss = 0.020531
with pm.Model(coords={"idx": np.arange(2)}) as model:
pm.MvNormal("x", mu=mu, cov=cov, dims="idx")
approx = pm.FullRankADVI().fit()
Finished [100%]: Average Loss = 0.014143
plt.figure()
idata = approx.sample(10000)
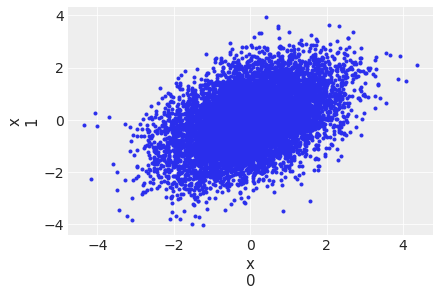
az.plot_pair(idata, var_names="x", coords={"idx": [0, 1]});
<Figure size 432x288 with 0 Axes>
Stein 变分梯度下降 (SVGD) 使用粒子来估计后验
w = pm.floatX([0.2, 0.8])
mu = pm.floatX([-0.3, 0.5])
sd = pm.floatX([0.1, 0.1])
with pm.Model() as model:
pm.NormalMixture("x", w=w, mu=mu, sigma=sd)
approx = pm.fit(method=pm.SVGD(n_particles=200, jitter=1.0))
with pm.Model() as model:
pm.NormalMixture("x", w=[0.2, 0.8], mu=[-0.3, 0.5], sigma=[0.1, 0.1])
plt.figure()
idata = approx.sample(10000)
az.plot_dist(idata.posterior["x"]);
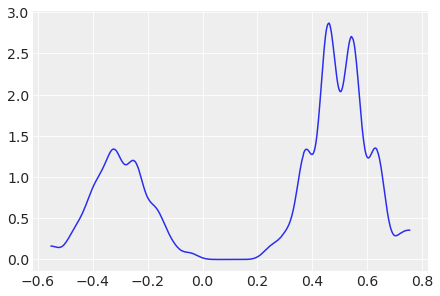
有关变分推断的更多信息,请参见 变分推断。
4. 后验预测抽样#
sample_posterior_predictive() 函数对保留数据和后验预测检查执行预测。
data = rng.standard_normal(100)
with pm.Model() as model:
mu = pm.Normal("mu", mu=0, sigma=1)
sd = pm.HalfNormal("sd", sigma=1)
obs = pm.Normal("obs", mu=mu, sigma=sd, observed=data)
idata = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [mu, sd]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 4 seconds.
with model:
idata.extend(pm.sample_posterior_predictive(idata))
fig, ax = plt.subplots()
az.plot_ppc(idata, ax=ax)
ax.axvline(data.mean(), ls="--", color="r", label="True mean")
ax.legend(fontsize=10);
/home/xian/anaconda3/envs/pymc-dev-py39/lib/python3.9/site-packages/IPython/core/pylabtools.py:151: UserWarning: Creating legend with loc="best" can be slow with large amounts of data.
fig.canvas.print_figure(bytes_io, **kw)
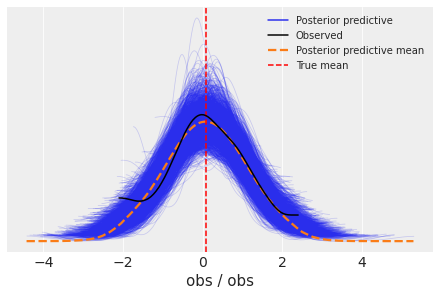
4.1 预测保留数据#
在许多情况下,您想对未见/保留数据进行预测。这在概率机器学习和贝叶斯深度学习中尤其相关。PyMC 包含一个 pm.MutableData 容器来帮助实现此类用途。它是 pytensor.shared 变量的包装器,允许稍后更改数据的值。否则,pm.MutableData 对象可以像任何其他 numpy 数组或张量一样使用。
这种区别非常重要,因为在内部,PyMC 中的所有模型都是巨大的符号表达式。当您将原始数据直接传递到模型中时,您正在授予 PyTensor 权限将此数据视为常量,并在这样做有意义时对其进行优化。如果您稍后需要更改此数据,您可能无法在更大的符号表达式中指向它。使用 pm.MutableData 提供了一种指向符号表达式中的特定位置并更改其中内容的方法。
x = rng.standard_normal(100)
y = x > 0
coords = {"idx": np.arange(100)}
with pm.Model() as model:
# create shared variables that can be changed later on
x_obs = pm.MutableData("x_obs", x, dims="idx")
y_obs = pm.MutableData("y_obs", y, dims="idx")
coeff = pm.Normal("x", mu=0, sigma=1)
logistic = pm.math.sigmoid(coeff * x_obs)
pm.Bernoulli("obs", p=logistic, observed=y_obs, dims="idx")
idata = pm.sample()
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [x]
Sampling 2 chains for 1_000 tune and 1_000 draw iterations (2_000 + 2_000 draws total) took 3 seconds.
现在假设我们要对未见数据进行预测。为此,我们必须更改 x_obs 和 y_obs 的值。从理论上讲,我们不需要设置 y_obs,因为我们想要预测它,但它必须与 x_obs 的形状匹配。
with model:
# change the value and shape of the data
pm.set_data(
{
"x_obs": [-1, 0, 1.0],
# use dummy values with the same shape:
"y_obs": [0, 0, 0],
},
coords={"idx": [1001, 1002, 1003]},
)
idata.extend(pm.sample_posterior_predictive(idata))
idata.posterior_predictive["obs"].mean(dim=["draw", "chain"])
<xarray.DataArray 'obs' (idx: 3)> array([0.0215, 0.488 , 0.982 ]) Coordinates: * idx (idx) int64 1001 1002 1003
参考文献#
John Kruschke. 贝叶斯数据分析实战: R, JAGS, 和 Stan 教程. Academic Press, 2014.
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor,aeppl,xarray
Last updated: Fri Jun 03 2022
Python implementation: CPython
Python version : 3.9.13
IPython version : 8.4.0
pytensor: 2.6.2
aeppl : 0.0.31
xarray: 2022.3.0
arviz : 0.12.1
numpy : 1.22.4
pymc : 4.0.0b6
pytensor : 2.6.2
matplotlib: 3.5.2
Watermark: 2.3.1
许可声明#
本示例库中的所有笔记本均根据 MIT 许可证 提供,该许可证允许修改和再分发以用于任何用途,前提是版权和许可证声明得到保留。
引用 PyMC 示例#
要引用此笔记本,请使用 Zenodo 为 pymc-examples 存储库提供的 DOI。
重要提示
许多笔记本都改编自其他来源:博客、书籍……在这种情况下,您也应该引用原始来源。
另请记住引用您的代码使用的相关库。
这是一个 bibtex 中的引用模板
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
渲染后可能看起来像