


脆弱性和生存回归模型#
注意
此 notebook 使用的库不是 PyMC 的依赖项,因此需要专门安装才能运行此 notebook。打开下面的下拉菜单以获取更多指导。
额外的依赖项安装说明
为了运行此 notebook(本地或在 binder 上),您不仅需要安装可用的 PyMC 以及所有可选依赖项,还需要安装一些额外的依赖项。有关安装 PyMC 本身的建议,请参阅 安装
您可以使用您偏好的包管理器安装这些依赖项,我们提供 pip 和 conda 命令的示例,如下所示。
$ pip install lifelines
请注意,如果您想(或需要)从 notebook 内部而不是命令行安装软件包,您可以通过运行 pip 命令的变体来安装软件包
import sys
!{sys.executable} -m pip install lifelines
您不应运行 !pip install,因为它可能会将软件包安装在不同的环境中,即使已安装,也无法从 Jupyter notebook 中使用。
另一种选择是使用 conda 代替
$ conda install lifelines
当使用 conda 安装 scientific python 包时,我们建议使用 conda forge
import os
import arviz as az
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import pymc as pm
import pytensor.tensor as pt
from lifelines import KaplanMeierFitter
from matplotlib import cm
from matplotlib.lines import Line2D
from scipy.stats import fisk, weibull_min
%config InlineBackend.figure_format = 'retina' # high resolution figures
az.style.use("arviz-darkgrid")
rng = np.random.default_rng(42)
生存分析的完整通用性和应用范围被医学术语的加载语义所掩盖。它被人们在日历和里程碑中追踪生命时,对自身关注的持续焦虑所蒙蔽。但广义上的生存分析不是关于你,甚至不一定关于生存。
需要额外的抽象步骤才能从医学背景转向看到 time-to-event 数据无处不在!每个有隐式时钟的任务,每个有终点线的目标,每个欠下死亡之债的收割者——这些都是 time-to-event 数据的来源。
我们将演示传统上在医学环境中部署的基于生存的回归分析概念如何有效地应用于人力资源数据和业务流程分析。特别是,我们将研究员工生命周期数据中员工流失的时间问题,并将这种现象建模为今年早些时候记录的员工调查响应的函数。
生存回归模型#
这里的重点是框架的通用性。我们描述的是时间内状态转换的轨迹。在任何地方,速度或效率都很重要,了解 time-to-event 轨迹的输入非常重要。这就是生存分析的好处——清晰表达的模型,量化了人口统计特征和治疗效果(在速度方面)对状态转换概率的影响。生与死之间的移动,雇佣和解雇,生病和治愈,订阅到流失。这些状态转换都可以使用生存回归模型进行透明且引人注目的建模。
我们将看到关于 time-to-event 数据的两种回归建模方法:(1)Cox 比例风险方法和(2)加速失效时间模型。这两种模型都使分析师能够组合和评估不同协变量对生存时间结果的影响,但每种模型的方式略有不同。
我们还将展示生存建模的分层变体,称为脆弱性建模,我们使用回归估计生存函数,但允许包含个体或群体特定的“脆弱性”项。这些是对个体生存曲线的估计程序应用的乘法因子,使我们能够捕捉人群中一些无法解释的异质性。此外,我们将展示如何表达分层方法来估计基线风险。在整个过程中,我们将借鉴 Collett [2014] 中的讨论。
数据探索#
人员分析本质上是关于理解业务中的效率和风险——生存分析非常适合阐明这些双重关注点。我们的示例数据来自 Keith McNulty 的 人员分析回归建模手册 McKnulty [2020] 中讨论的一个人力资源主题案例。
该数据描述了对工作满意度问题和受访者寻求其他就业意向的调查回复。此外,该数据还包含受访者的广泛“人口统计”信息,以及关键的指标,表明他们是否在公司 离职 以及在调查后的哪个 月 份,我们仍然有他们在公司的记录。我们希望了解随时间推移的员工流失概率,作为员工调查回复的函数,以帮助 (a) 管理措手不及的风险,以及 (b) 通过维持适当配备人员的公司来确保效率。
重要的是要注意,这种数据总是删失数据,因为它总是在某个时间点提取。因此,对于某些人,我们没有看到离职事件。他们可能永远不会离开公司——但重要的是,在测量时点,我们根本不知道他们是否会在明天离职……因此,数据在测量时点被有意义地删失。我们的建模策略需要考虑这如何改变所讨论的概率,如 具有截断或删失数据的贝叶斯回归 中所述。
try:
retention_df = pd.read_csv(os.path.join("..", "data", "time_to_attrition.csv"))
except FileNotFoundError:
retention_df = pd.read_csv(pm.get_data("time_to_attrition.csv"))
dummies = pd.concat(
[
pd.get_dummies(retention_df["gender"], drop_first=True),
pd.get_dummies(retention_df["level"], drop_first=True),
pd.get_dummies(retention_df["field"], drop_first=True),
],
axis=1,
).rename({"M": "Male"}, axis=1)
retention_df = pd.concat([retention_df, dummies], axis=1).sort_values("Male").reset_index(drop=True)
retention_df.head()
| 性别 | 领域 | 级别 | 情感 | 意向 | 离职 | 月份 | 男性 | 低 | 中 | 金融 | 健康 | 法律 | 公共/政府 | 销售/市场营销 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 女性 | 教育和培训 | 低 | 8 | 5 | 0 | 12 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 女性 | 教育和培训 | 中 | 8 | 3 | 1 | 11 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 2 | 女性 | 教育和培训 | 低 | 10 | 7 | 1 | 9 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 女性 | 教育和培训 | 高 | 8 | 2 | 0 | 12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 女性 | 教育和培训 | 低 | 8 | 8 | 0 | 12 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
我们为下面回归模型中使用的一些分类变量添加了虚拟编码。我们删除了第一个编码类,因为这避免了估计过程中的识别问题。此外,这意味着为每个指标变量估计的系数都具有相对于删除的“参考”类的解释。
首先,我们将查看在我们数据上估计的生存函数的简单 Kaplan Meier 表示。生存函数量化了在给定时间之前事件尚未发生的概率,即特定月份之前员工流失的概率。自然,不同类型的风险概况会导致不同的生存函数。回归模型(如典型的)有助于解析风险的性质,而风险概况过于复杂而难以清晰表达。
kmf = KaplanMeierFitter()
kmf.fit(retention_df["month"], event_observed=retention_df["left"])
kmf_hi = KaplanMeierFitter()
kmf_hi.fit(
retention_df[retention_df["sentiment"] == 10]["month"],
event_observed=retention_df[retention_df["sentiment"] == 10]["left"],
)
kmf_mid = KaplanMeierFitter()
kmf_mid.fit(
retention_df[retention_df["sentiment"] == 5]["month"],
event_observed=retention_df[retention_df["sentiment"] == 5]["left"],
)
kmf_low = KaplanMeierFitter()
kmf_low.fit(
retention_df[retention_df["sentiment"] == 2]["month"],
event_observed=retention_df[retention_df["sentiment"] == 2]["left"],
)
fig, axs = plt.subplots(1, 2, figsize=(20, 15))
axs = axs.flatten()
ax = axs[0]
for i in retention_df.sample(30).index[0:30]:
temp = retention_df[retention_df.index == i]
event = temp["left"].max() == 1
level = temp["level"].unique()
duration = temp["month"].max()
color = np.where(level == "High", "red", np.where(level == "Medium", "slateblue", "grey"))
ax.hlines(i, 0, duration, color=color)
if event:
ax.scatter(duration, i, color=color)
ax.set_title("Assorted Time to Attrition \n by Level", fontsize=20)
ax.set_yticklabels([])
from matplotlib.lines import Line2D
custom_lines = [
Line2D([0], [0], color="red", lw=4),
Line2D([0], [0], color="slateblue", lw=4),
Line2D([0], [0], color="grey", lw=4),
]
ax.legend(custom_lines, ["High Sentiment", "Medium Sentiment", "Low Sentiment"])
kmf_hi.plot_survival_function(ax=axs[1], label="KM estimate for High Sentiment", color="red")
kmf_mid.plot_survival_function(
ax=axs[1], label="KM estimate for Medium Sentiment", color="slateblue"
)
kmf_low.plot_survival_function(ax=axs[1], label="KM estimate for Low Sentiment", color="grey")
kmf.plot_survival_function(
ax=axs[1], label="Overall KM estimate", color="cyan", at_risk_counts=True
)
axs[1].set_xlabel("Time in Months")
axs[1].set_title("Kaplan Meier Fits by Level", fontsize=20);
/Users/nathanielforde/mambaforge/envs/pymc_examples_new/lib/python3.9/site-packages/lifelines/plotting.py:964: UserWarning: The figure layout has changed to tight
plt.tight_layout()
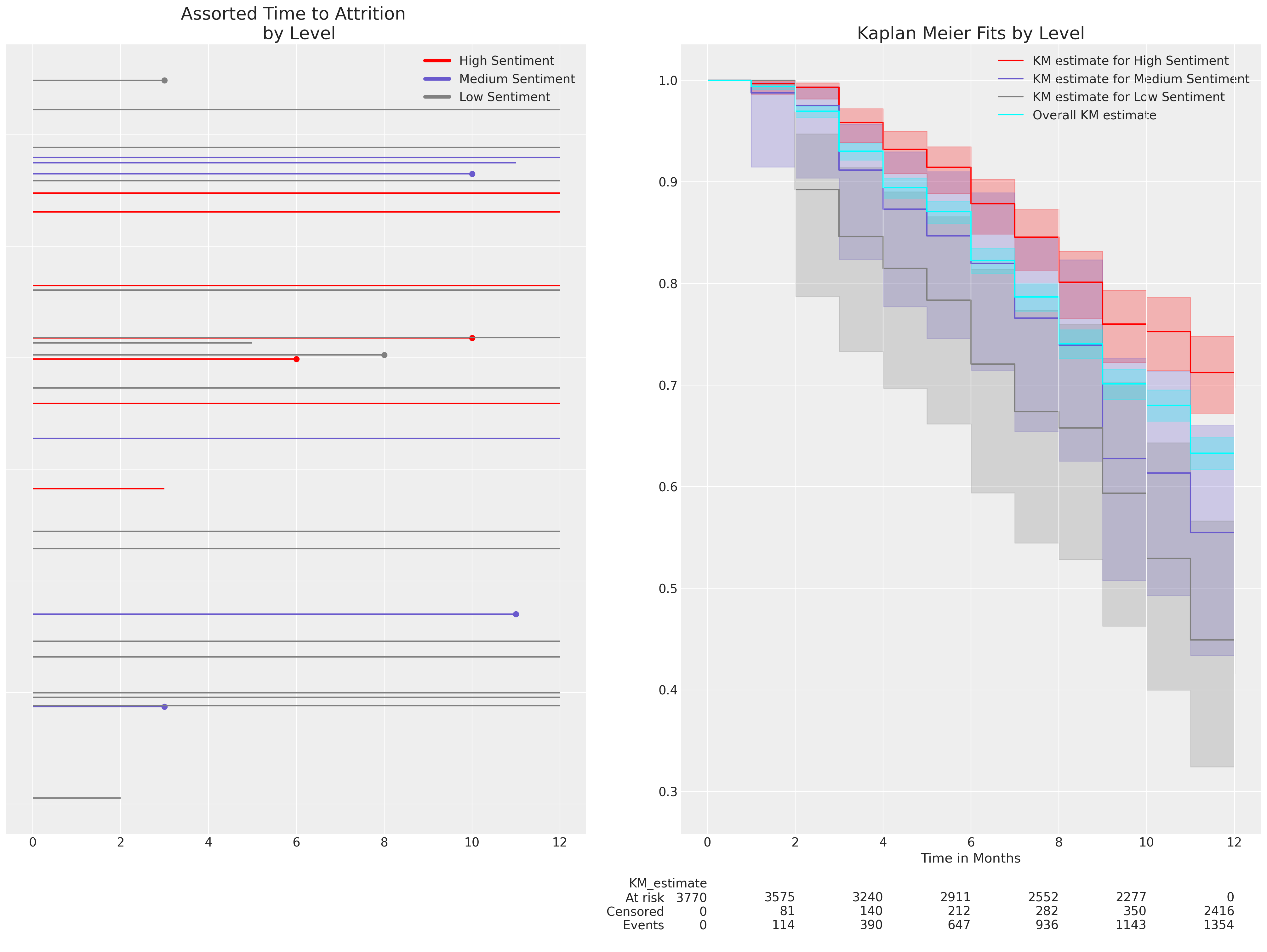
在这里,我们使用了 sentiment 变量级别内的 Kaplan Meier 非参数估计来显示在 12 个月期间的预期流失水平如何被试验期开始时参与者表达的 sentiment 水平修改。这只是生存曲线的探索性数据分析,但我们想了解概率模型如何恢复此类生存曲线,以及概率模型的适当解释是什么。情感越低,流失发生得越快。
生存回归的数据准备#
Cox 比例风险回归模型背后的思想,粗略地说,是认真对待风险的时间成分。我们想象在时间间隔内存在潜在的基线风险发生率。Michael Betancourt 询问 我们将风险视为“一些刺激性资源的积累”,它先于事件的发生。在失效建模中,可以将其想象成零星增加的磨损。在人力资源动态的背景下,可以将其想象成工作环境中日益增加的挫败感。在哲学中,可以将其视为对索瑞斯悖论的阐述;随着沙子堆得越来越高,机会如何随时间变化,以便我们将个体颗粒的集合识别为一堆?这个术语通常表示为
它在 Cox 回归中与个体案例的线性协变量表示相乘组合
并表示预测变量设置为其基线/参考水平时,每个时间点的基线风险。也就是说,回归模型中任何协变量 \(X_{i}\) 超过 0 的任何单位增加都会改变基线风险。在我们的案例中,我们正在查看每月条目的粒度数据。因此,我们需要了解年度调查日期后未来 12 个月内员工流失的风险如何变化,以及每个个体的协变量概况如何改变基线风险。
这些模型可以使用 Austin Rochford 在 贝叶斯生存分析 中概述的贝叶斯估计方法进行估计。在下文中,我们以他的示例为基础。首先,我们指定风险的时间维度,在我们的案例中,我们有一年内的一个月的时间间隔——代表自调查回复日期以来的时间。
intervals = np.arange(12)
intervals
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
然后,我们将数据排列成一个结构,以显示数据集中的每个人是否以及何时经历了员工流失事件。这里的列是每个月的指标,行代表数据集中的每个人。这些值显示 1 表示员工在该月离开了公司,0 表示否则。
n_employees = retention_df.shape[0]
n_intervals = len(intervals)
last_period = np.floor((retention_df.month - 0.01) / 1).astype(int)
employees = np.arange(n_employees)
quit = np.zeros((n_employees, n_intervals))
quit[employees, last_period] = retention_df["left"]
pd.DataFrame(quit)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 3765 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3766 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3767 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3768 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3769 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
3770 行 × 12 列
如 可靠性统计和预测校准 中所述,风险函数、累积密度函数和事件时间分布的生存函数都密切相关。特别是,这些中的每一个都可以相对于任何给定时间序列中处于风险中的一组个体来描述。随着人们经历员工流失事件,处于风险中的个体池会随时间变化。这会改变随时间推移的条件风险——对隐含的生存函数产生连锁影响。为了在我们的估计策略中考虑到这一点,我们需要配置我们的数据以标记谁处于风险之中以及何时处于风险之中。
exposure = np.greater_equal.outer(retention_df.month.to_numpy(), intervals) * 1
exposure[employees, last_period] = retention_df.month - intervals[last_period]
pd.DataFrame(exposure)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 4 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 3765 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3766 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 |
| 3767 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3768 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3769 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
3770 行 × 12 列
在此数据结构中,0 表示员工已经辞职,并且在该时间点不再存在于“风险”池中。而在此结构中,1 表示池在风险池中,应使用该池来计算该时间间隔的瞬时风险。
有了这些结构,我们现在可以估计我们的模型了。按照 Austin Rochford 的示例,我们再次使用泊松技巧来估计比例风险模型。这可能有点令人惊讶,因为 Cox 比例风险模型通常被宣传为半参数模型,由于基线风险分量的分段性质,需要使用部分似然进行估计。
诀窍是看到事件计数的泊松回归和 CoxPH 回归通过确定事件发生率的参数联系起来。在预测计数的情况下,我们需要一个潜在的事件风险,该风险通过每个时间间隔的偏移量索引到时间。这确保了泊松回归的似然项与 Cox 比例风险回归中考虑的似然项足够相似,以至于我们可以用一个代替另一个。换句话说,可以使用泊松似然将 Cox 比例风险模型估计为 GLM,其中我们为时间间隔上的每个点指定“偏移量”或截距修改。使用 Wilkinson 表示法,我们可以写成
类似于
我们使用上面定义的结构和 PyMC 估计它,如下所示
拟合具有固定效应的基本 Cox 模型#
我们将设置一个模型工厂函数,以拟合具有不同协变量规范的基本 Cox 比例风险模型。我们想评估测量离职意向的模型和不测量离职意向的模型之间模型含义的差异。
preds = [
"sentiment",
"Male",
"Low",
"Medium",
"Finance",
"Health",
"Law",
"Public/Government",
"Sales/Marketing",
]
preds2 = [
"sentiment",
"intention",
"Male",
"Low",
"Medium",
"Finance",
"Health",
"Law",
"Public/Government",
"Sales/Marketing",
]
def make_coxph(preds):
coords = {"intervals": intervals, "preds": preds, "individuals": range(len(retention_df))}
with pm.Model(coords=coords) as base_model:
X_data = pm.MutableData("X_data_obs", retention_df[preds], dims=("individuals", "preds"))
lambda0 = pm.Gamma("lambda0", 0.01, 0.01, dims="intervals")
beta = pm.Normal("beta", 0, sigma=1, dims="preds")
lambda_ = pm.Deterministic(
"lambda_",
pt.outer(pt.exp(pm.math.dot(beta, X_data.T)), lambda0),
dims=("individuals", "intervals"),
)
mu = pm.Deterministic("mu", exposure * lambda_, dims=("individuals", "intervals"))
obs = pm.Poisson("obs", mu, observed=quit, dims=("individuals", "intervals"))
base_idata = pm.sample(
target_accept=0.95, random_seed=100, idata_kwargs={"log_likelihood": True}
)
return base_idata, base_model
base_idata, base_model = make_coxph(preds)
base_intention_idata, base_intention_model = make_coxph(preds2)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [lambda0, beta]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 62 seconds.
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [lambda0, beta]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 72 seconds.
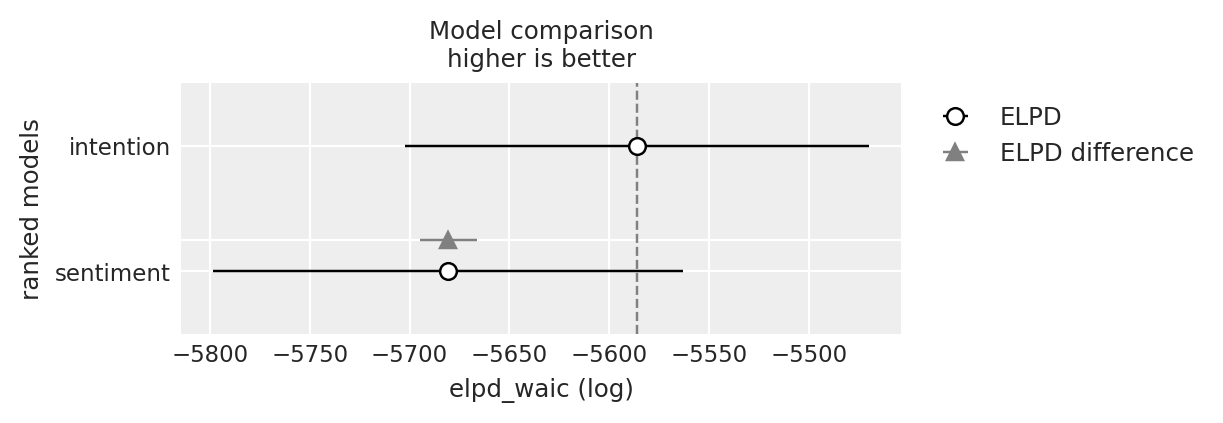
compare = az.compare({"sentiment": base_idata, "intention": base_intention_idata}, ic="waic")
compare
| 排名 | elpd_waic | p_waic | elpd_diff | 权重 | 标准差 | 差分标准差 | 警告 | 比例 | |
|---|---|---|---|---|---|---|---|---|---|
| 意向 | 0 | -5586.085248 | 21.327895 | 0.000000 | 0.996278 | 115.944586 | 0.000000 | False | 对数 |
| 情感 | 1 | -5680.561115 | 20.101640 | 94.475867 | 0.003722 | 117.596277 | 14.181559 | False | 对数 |
az.plot_compare(compare);
pm.model_to_graphviz(base_model)

我们可以在这里看到模型的结构,虽然与典型的回归模型略有不同,但包含了所有相同的元素。观察到的变量以加权和组合,并向前馈送到修改结果。在我们的案例中,结果是风险——或特定时间点的条件风险。正是这些估计的集合构成了我们对该期间风险演变性质的看法。那么,一个显而易见的问题是,预测变量如何促进风险的演变。
第二个问题是,风险的逐实例视图如何转化为随时间推移的生存概率视图?我们如何才能在基于风险的视角和基于生存的视角之间移动?
解释模型系数#
我们将首先关注我们两个模型中输入变量的不同含义。beta 参数估计记录在对数风险率的尺度上。首先查看 intention 预测变量(衡量调查参与者离职意向的分数)如何改变在未能包含此变量的模型中获得的参数估计的幅度和符号。这是一个简单但深刻的提醒,要确保我们衡量正确的事物,并且输入模型的特征/变量构成关于数据生成过程的故事,无论我们是否注意。
m = (
az.summary(base_idata, var_names=["beta"])
.reset_index()[["index", "mean"]]
.rename({"mean": "expected_hr"}, axis=1)
)
m1 = (
az.summary(base_intention_idata, var_names=["beta"])
.reset_index()[["index", "mean"]]
.rename({"mean": "expected_intention_hr"}, axis=1)
)
m = m.merge(m1, left_on="index", right_on="index", how="outer")
m["exp(expected_hr)"] = np.exp(m["expected_hr"])
m["exp(expected_intention_hr)"] = np.exp(m["expected_intention_hr"])
m
| 索引 | 预期风险比 | 预期意向风险比 | exp(预期风险比) | exp(预期意向风险比) | |
|---|---|---|---|---|---|
| 0 | beta[情感] | -0.110 | -0.029 | 0.895834 | 0.971416 |
| 1 | beta[男性] | -0.037 | 0.015 | 0.963676 | 1.015113 |
| 2 | beta[低] | 0.137 | 0.155 | 1.146828 | 1.167658 |
| 3 | beta[中] | 0.161 | 0.107 | 1.174685 | 1.112934 |
| 4 | beta[金融] | 0.207 | 0.234 | 1.229983 | 1.263644 |
| 5 | beta[健康] | 0.249 | 0.236 | 1.282742 | 1.266174 |
| 6 | beta[法律] | 0.091 | 0.073 | 1.095269 | 1.075731 |
| 7 | beta[公共/政府] | 0.102 | 0.120 | 1.107383 | 1.127497 |
| 8 | beta[销售/市场营销] | 0.075 | 0.100 | 1.077884 | 1.105171 |
| 9 | beta[意向] | NaN | 0.189 | NaN | 1.208041 |
每个单独的模型系数都记录了输入变量单位增加对对数风险比的影响的估计。请注意我们如何将系数取幂以将其返回到风险比的尺度。对于具有系数 \(\beta\) 的预测变量 \(X\),解释如下
如果 \(exp(\beta)\) > 1:X 的增加与事件发生的风险(风险)增加有关。
如果 \(exp(\beta)\) < 1:X 的增加与事件发生的风险(较低风险)降低有关。
如果 \(exp(\beta)\) = 1:X 对风险率没有影响。
因此,在我们的案例中,我们可以看到在金融或健康领域工作似乎会导致事件发生的风险比基线风险增加约 25%。有趣的是,我们可以看到包含 intention 预测变量似乎很重要,因为 intention 指标的单位增加会以类似的方式移动刻度盘——而意向是 0-10 的尺度。
这些不是随时间变化的——它们一次性进入加权和,从而修改基线风险。这就是比例风险假设——虽然基线风险会随时间变化,但由不同协变量水平引起的风险差异在整个时间内保持不变。Cox 模型之所以受欢迎,是因为它允许我们估计每个时间点的变化风险,并将人口统计预测变量的影响在整个期间内相乘。比例风险假设并非总是成立,我们将在下面看到一些调整,可以帮助处理违反比例风险假设的情况。
fig, ax = plt.subplots(figsize=(20, 6))
ax.plot(base_idata["posterior"]["lambda0"].mean(("draw", "chain")), color="black")
az.plot_hdi(
range(12),
base_idata["posterior"]["lambda0"],
color="lightblue",
ax=ax,
hdi_prob=0.99,
fill_kwargs={"label": "Baseline Hazard 99%", "alpha": 0.3},
smooth=False,
)
az.plot_hdi(
range(12),
base_idata["posterior"]["lambda0"],
color="lightblue",
ax=ax,
hdi_prob=0.50,
fill_kwargs={"label": "Baseline Hazard 50%", "alpha": 0.8},
smooth=False,
)
ax.legend()
ax.set_xlabel("Time")
ax.set_title("Expected Baseline Hazard", fontsize=20);
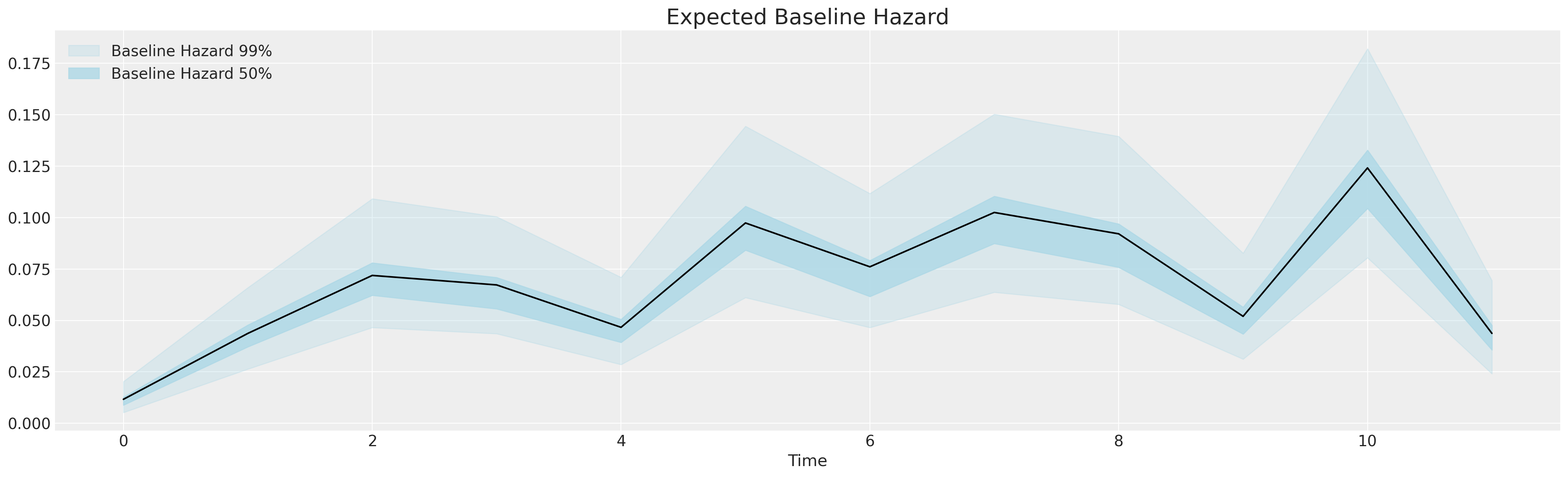
这是基线刺激——不断增长、零星变化的风险,刺激员工流失的发生。我们构建回归模型,其中包含大量控制变量和治疗指标,以评估它们对随时间推移改变基线风险有何影响(如果有)。生存回归建模是分析人口统计学和行为特征对随时间推移的风险影响的透明工具。请注意年度周期结束时的急剧增加。
预测 CoxPH 回归的边际效应#
我们可以通过推导样本/虚构数据的边际效应,使这些解释更具体一些。现在我们定义生存和累积风险度量之间作为基线风险函数的函数关系。
def cum_hazard(hazard):
"""Takes arviz.InferenceData object applies
cumulative sum along baseline hazard"""
return hazard.cumsum(dim="intervals")
def survival(hazard):
"""Takes arviz.InferenceData object transforms
cumulative hazard into survival function"""
return np.exp(-cum_hazard(hazard))
def get_mean(trace):
"""Takes arviz.InferenceData object marginalises
over the chain and draw"""
return trace.mean(("draw", "chain"))
累积风险平滑了基线风险函数的跳跃性,使我们更清楚地了解了随时间推移风险增加的程度。这(反过来)转化为我们的生存函数,该函数很好地表达了 0-1 尺度上的风险。接下来,我们设置一个函数,以导出每个个体的生存和累积风险函数,这些函数以其风险概况为条件。
def extract_individual_hazard(idata, i, retention_df, intention=False):
beta = idata.posterior["beta"]
if intention:
intention_posterior = beta.sel(preds="intention")
else:
intention_posterior = 0
hazard_base_m1 = idata["posterior"]["lambda0"]
full_hazard_idata = hazard_base_m1 * np.exp(
beta.sel(preds="sentiment") * retention_df.iloc[i]["sentiment"]
+ np.where(intention, intention_posterior * retention_df.iloc[i]["intention"], 0)
+ beta.sel(preds="Male") * retention_df.iloc[i]["Male"]
+ beta.sel(preds="Low") * retention_df.iloc[i]["Low"]
+ beta.sel(preds="Medium") * retention_df.iloc[i]["Medium"]
+ beta.sel(preds="Finance") * retention_df.iloc[i]["Finance"]
+ beta.sel(preds="Health") * retention_df.iloc[i]["Health"]
+ beta.sel(preds="Law") * retention_df.iloc[i]["Law"]
+ beta.sel(preds="Public/Government") * retention_df.iloc[i]["Public/Government"]
+ beta.sel(preds="Sales/Marketing") * retention_df.iloc[i]["Sales/Marketing"]
)
cum_haz_idata = cum_hazard(full_hazard_idata)
survival_idata = survival(full_hazard_idata)
return full_hazard_idata, cum_haz_idata, survival_idata, hazard_base_m1
def plot_individuals(retention_df, idata, individuals=[1, 300, 700], intention=False):
fig, axs = plt.subplots(1, 2, figsize=(20, 7))
axs = axs.flatten()
colors = ["slateblue", "magenta", "darkgreen"]
for i, c in zip(individuals, colors):
haz_idata, cum_haz_idata, survival_idata, base_hazard = extract_individual_hazard(
idata, i, retention_df, intention
)
axs[0].plot(get_mean(survival_idata), label=f"individual_{i}", color=c)
az.plot_hdi(range(12), survival_idata, ax=axs[0], fill_kwargs={"color": c})
axs[1].plot(get_mean(cum_haz_idata), label=f"individual_{i}", color=c)
az.plot_hdi(range(12), cum_haz_idata, ax=axs[1], fill_kwargs={"color": c})
axs[0].set_title("Individual Survival Functions", fontsize=20)
axs[1].set_title("Individual Cumulative Hazard Functions", fontsize=20)
az.plot_hdi(
range(12),
survival(base_hazard),
color="lightblue",
ax=axs[0],
fill_kwargs={"label": "Baseline Survival"},
)
axs[0].plot(
get_mean(survival(base_hazard)),
color="black",
linestyle="--",
label="Expected Baseline Survival",
)
az.plot_hdi(
range(12),
cum_hazard(base_hazard),
color="lightblue",
ax=axs[1],
fill_kwargs={"label": "Baseline Hazard"},
)
axs[1].plot(
get_mean(cum_hazard(base_hazard)),
color="black",
linestyle="--",
label="Expected Baseline Hazard",
)
axs[0].legend()
axs[0].set_ylabel("Probability of Survival")
axs[1].set_ylabel("Cumulative Hazard Risk")
axs[0].set_xlabel("Time")
axs[1].set_xlabel("Time")
axs[1].legend()
#### Next set up test-data input to explore the relationship between levels of the variables.
test_df = pd.DataFrame(np.zeros((3, 15)), columns=retention_df.columns)
test_df["sentiment"] = [1, 5, 10]
test_df["intention"] = [1, 5, 10]
test_df["Medium"] = [0, 0, 0]
test_df["Finance"] = [0, 0, 0]
test_df["M"] = [1, 1, 1]
test_df
| 性别 | 领域 | 级别 | 情感 | 意向 | 离职 | 月份 | 男性 | 低 | 中 | 金融 | 健康 | 法律 | 公共/政府 | 销售/市场营销 | 男 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 1 | 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 1 |
| 1 | 0.0 | 0.0 | 0.0 | 5 | 5 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 1 |
| 2 | 0.0 | 0.0 | 0.0 | 10 | 10 | 0.0 | 0.0 | 0.0 | 0.0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 1 |
意向模型#
如果我们在配备评估它的模型中绘制 intention 变量增加引起的边际效应,我们会看到个体预测生存曲线的急剧划分,这由上面 intention 变量的系数表中看到的显着且实质性的参数估计所暗示。
plot_individuals(test_df, base_intention_idata, [0, 1, 2], intention=True)
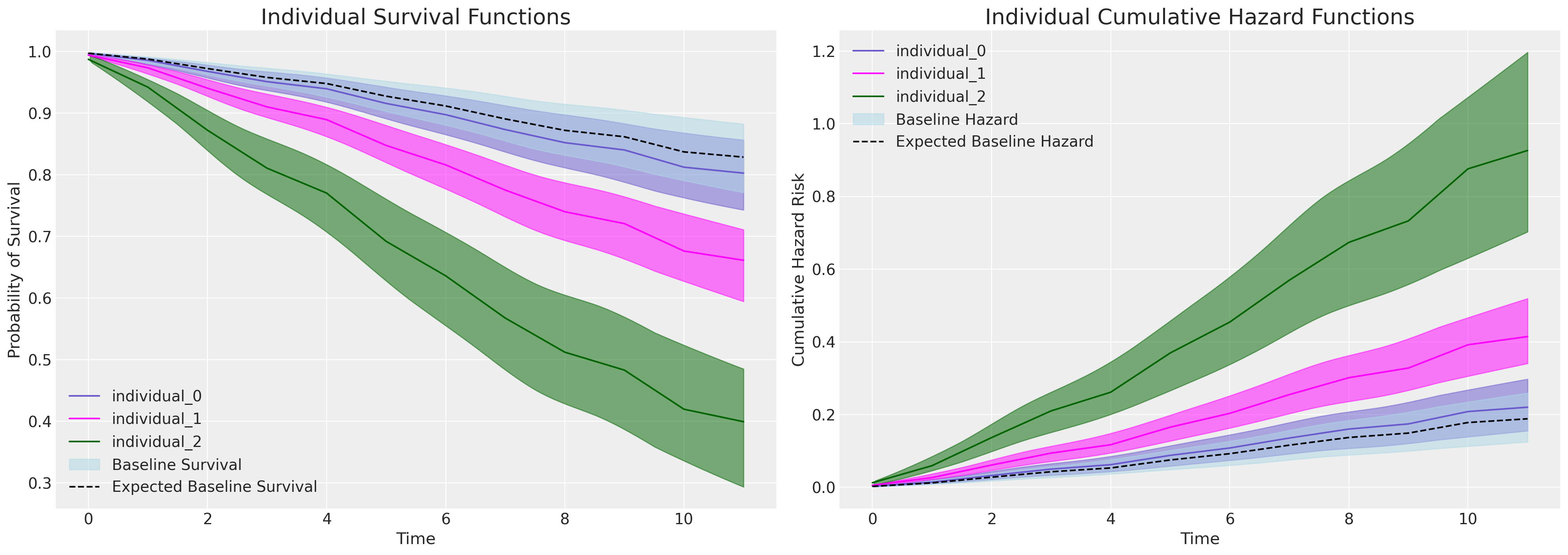
此处重点关注右侧的图。基线累积风险以蓝色表示,其中每个后续曲线表示 intention 指标得分增加的个体的累积风险,即风险增加。这种模式在左侧的图中是倒置的——相反,我们看到对于那些 intention 值高的个体,生存概率如何随时间推移而更急剧地下降。
情感模型#
如果我们对无法解释意向的模型进行相同的测试,则大部分权重都落在调查参与者记录的情感之间指定的差异上。在这里,我们也看到了生存曲线的分离,但效果远不那么明显。
plot_individuals(test_df, base_idata, [0, 1, 2], intention=False)
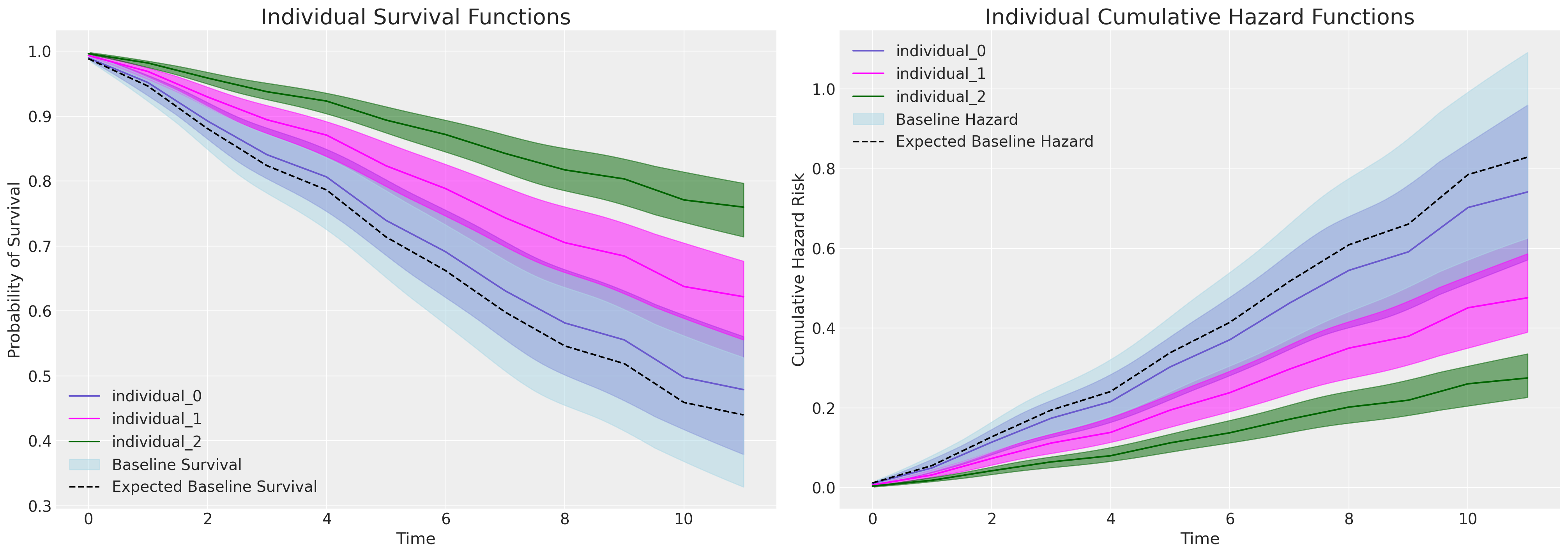
这里要注意的一个主要观察结果是,每个模型中的基线风险完成了多少工作。在可以解释 intention 指标影响的模型中,基线风险较低。表明基线风险必须做更多的工作。测试数据和输入规范的其他组合可用于以此方式试验 CoxPh 模型的条件含义。
为个人特征做出预测#
使用边际效应分析来更好地理解特定变量的影响固然很好,但是我们如何使用它来预测我们调查的员工池中的可能轨迹?在这里,我们只是将模型重新应用于我们观察到的数据集,其中每个参与者在某种意义上都以我们模型的可观察输入为特征。
我们可以使用这些特征来预测我们当前或未来员工群体的生存曲线,并在必要时进行干预,以减轻这些和类似的员工风险概况的隐含流失风险。
def create_predictions(retention_df, idata, intention=False):
cum_haz = {}
surv = {}
for i in range(len(retention_df)):
haz_idata, cum_haz_idata, survival_idata, base_hazard = extract_individual_hazard(
idata, i, retention_df, intention=intention
)
cum_haz[i] = get_mean(cum_haz_idata)
surv[i] = get_mean(survival_idata)
cum_haz = pd.DataFrame(cum_haz)
surv = pd.DataFrame(surv)
return cum_haz, surv
cum_haz_df, surv_df = create_predictions(retention_df, base_idata, intention=False)
surv_df
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 3760 | 3761 | 3762 | 3763 | 3764 | 3765 | 3766 | 3767 | 3768 | 3769 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.994518 | 0.994380 | 0.995593 | 0.995206 | 0.994518 | 0.994583 | 0.994518 | 0.990579 | 0.992487 | 0.992931 | ... | 0.992586 | 0.993310 | 0.988610 | 0.995757 | 0.995011 | 0.992717 | 0.993964 | 0.993364 | 0.993472 | 0.994148 |
| 1 | 0.974209 | 0.973561 | 0.979227 | 0.977416 | 0.974209 | 0.974516 | 0.974209 | 0.956012 | 0.964789 | 0.966834 | ... | 0.965227 | 0.968581 | 0.946990 | 0.979984 | 0.976493 | 0.965843 | 0.971611 | 0.968831 | 0.969341 | 0.972481 |
| 2 | 0.941695 | 0.940254 | 0.952883 | 0.948839 | 0.941695 | 0.942373 | 0.941695 | 0.901768 | 0.920887 | 0.925422 | ... | 0.921831 | 0.929225 | 0.882325 | 0.954570 | 0.946789 | 0.923202 | 0.935920 | 0.929808 | 0.930906 | 0.937853 |
| 3 | 0.912256 | 0.910122 | 0.928877 | 0.922866 | 0.912256 | 0.913260 | 0.912256 | 0.853823 | 0.881618 | 0.888305 | ... | 0.883002 | 0.893866 | 0.825868 | 0.931396 | 0.919829 | 0.885028 | 0.903721 | 0.894759 | 0.896340 | 0.906584 |
| 4 | 0.892383 | 0.889804 | 0.912586 | 0.905277 | 0.892383 | 0.893598 | 0.892383 | 0.822082 | 0.855371 | 0.863449 | ... | 0.857049 | 0.870148 | 0.788869 | 0.915657 | 0.901596 | 0.859485 | 0.882054 | 0.871244 | 0.873125 | 0.885513 |
| 5 | 0.852282 | 0.848839 | 0.879493 | 0.869634 | 0.852282 | 0.853915 | 0.852282 | 0.759607 | 0.803079 | 0.813822 | ... | 0.805304 | 0.822650 | 0.716938 | 0.883650 | 0.864693 | 0.808524 | 0.838480 | 0.824164 | 0.826588 | 0.843096 |
| 6 | 0.822221 | 0.818154 | 0.854484 | 0.842780 | 0.822221 | 0.824154 | 0.822221 | 0.714154 | 0.764475 | 0.777070 | ... | 0.767064 | 0.787359 | 0.665387 | 0.859430 | 0.836926 | 0.770838 | 0.805941 | 0.789185 | 0.791977 | 0.811387 |
| 7 | 0.783397 | 0.778581 | 0.821918 | 0.807920 | 0.783397 | 0.785703 | 0.783397 | 0.657223 | 0.715395 | 0.730204 | ... | 0.718425 | 0.742221 | 0.601809 | 0.827853 | 0.800941 | 0.722843 | 0.764111 | 0.744436 | 0.747639 | 0.770556 |
| 8 | 0.750084 | 0.744669 | 0.793722 | 0.777839 | 0.750084 | 0.752690 | 0.750084 | 0.609981 | 0.673991 | 0.690544 | ... | 0.677365 | 0.703892 | 0.549930 | 0.800474 | 0.769951 | 0.682285 | 0.728390 | 0.706434 | 0.709932 | 0.735632 |
| 9 | 0.731908 | 0.726186 | 0.778234 | 0.761359 | 0.731908 | 0.734672 | 0.731908 | 0.584842 | 0.651689 | 0.669128 | ... | 0.655238 | 0.683145 | 0.522666 | 0.785421 | 0.752995 | 0.660411 | 0.708973 | 0.685863 | 0.689499 | 0.716627 |
| 10 | 0.690271 | 0.683889 | 0.742464 | 0.723420 | 0.690271 | 0.693378 | 0.690271 | 0.528948 | 0.601379 | 0.620680 | ... | 0.605290 | 0.636053 | 0.462957 | 0.750615 | 0.714028 | 0.610981 | 0.664683 | 0.639185 | 0.643059 | 0.673210 |
| 11 | 0.676189 | 0.669604 | 0.730273 | 0.710527 | 0.676189 | 0.679408 | 0.676189 | 0.510585 | 0.584615 | 0.604485 | ... | 0.588636 | 0.620269 | 0.443621 | 0.738737 | 0.700803 | 0.594481 | 0.649766 | 0.623532 | 0.627471 | 0.658565 |
12 行 × 3770 列
样本生存曲线及其边际预期生存轨迹。#
我们现在绘制这些个体风险概况,并边缘化预测的生存曲线。
cm_subsection = np.linspace(0, 1, 120)
colors_m = [cm.Purples(x) for x in cm_subsection]
colors = [cm.spring(x) for x in cm_subsection]
fig, axs = plt.subplots(1, 2, figsize=(20, 7))
axs = axs.flatten()
cum_haz_df.plot(legend=False, color=colors, alpha=0.05, ax=axs[1])
axs[1].plot(cum_haz_df.mean(axis=1), color="black", linewidth=4)
axs[1].set_title(
"Individual Cumulative Hazard \n & Marginal Expected Cumulative Hazard", fontsize=20
)
surv_df.plot(legend=False, color=colors_m, alpha=0.05, ax=axs[0])
axs[0].plot(surv_df.mean(axis=1), color="black", linewidth=4)
axs[0].set_title("Individual Survival Curves \n & Marginal Expected Survival Curve", fontsize=20)
axs[0].annotate(
f"Expected Attrition by 6 months: {100*np.round(1-surv_df.mean(axis=1).iloc[6], 2)}%",
(2, 0.5),
fontsize=14,
fontweight="bold",
);
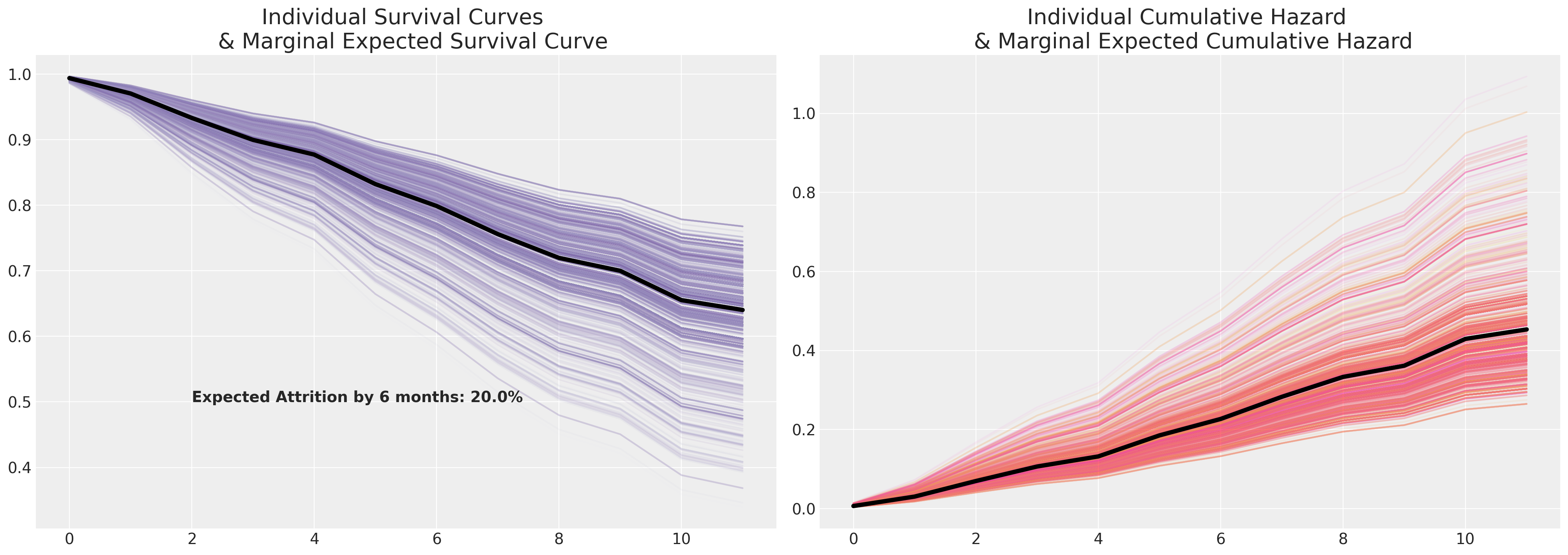
这里的边际生存曲线是一个摘要统计量,就像在更简单的情况下测量平均值一样。它具有您的样本数据(您样本中的个体)的特征,因此,只要您乐于说您的样本数据与您的人群中不同特征的风险成比例地具有代表性,您就应该仅将其视为指示性或可概括的度量。生存建模不能替代健全的实验设计,但它可以用于分析实验数据。
在人力资源背景下,我们可能对管理培训计划影响下的员工流失时间指标感兴趣,或者在软件开发团队采用敏捷实践或新工具时,对生产代码的交付周期感兴趣。了解影响效率的政策是好的,了解政策影响效率的速度更好。
加速失效时间模型#
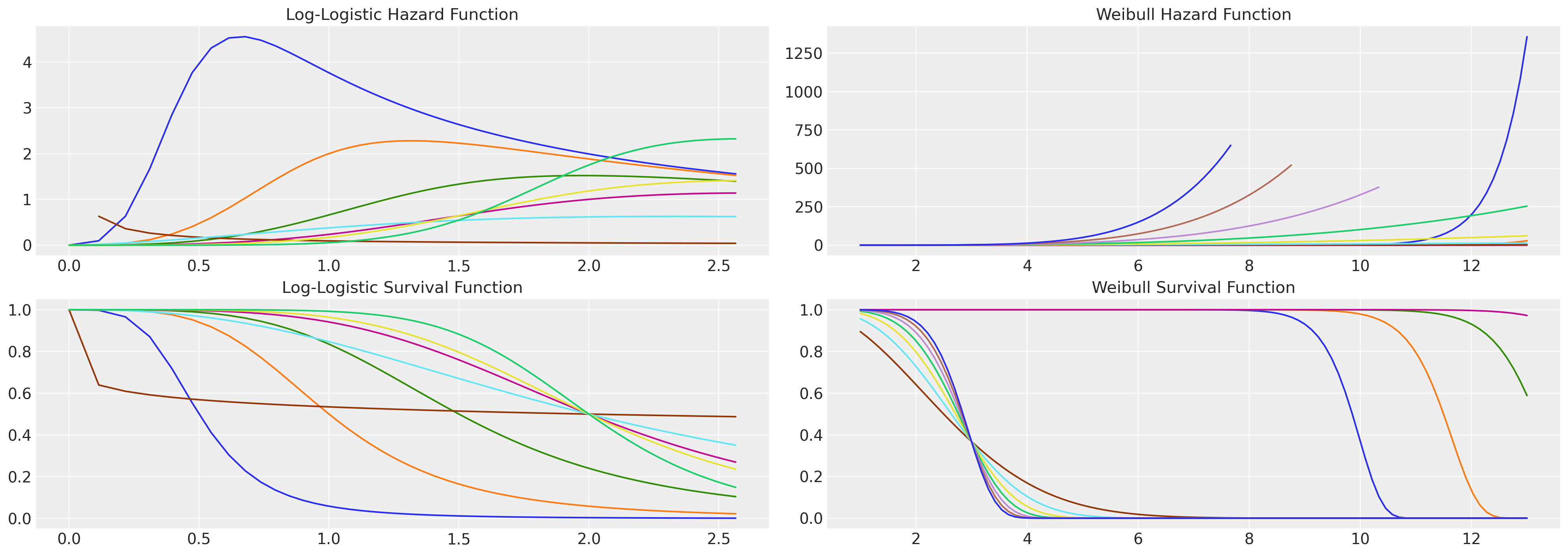
接下来,我们将研究一类基于回归的参数化生存模型,称为加速失效时间模型(AFT)。这些回归模型旨在借助一个或多个规范统计分布来描述感兴趣的生存函数,这些分布可以用一组位置和尺度参数简洁地表征,例如,韦布尔分布、对数logistic分布和对数正态分布等等。这些分布族的一个优点是,我们可以在不必显式参数化时间间隔的情况下,获得更灵活的风险函数。
例如,请参阅此处,了解对数logistic分布如何表现出非单调风险函数,而韦布尔风险函数必然是单调的。如果您的案例理论允许事件发生风险的上升和下降,这是一个重要的观察结果。
fig, axs = plt.subplots(2, 2, figsize=(20, 7))
axs = axs.flatten()
def make_loglog_haz(alpha, beta):
## This is the Log Logistic distribution
dist = fisk(c=alpha, scale=beta)
t = np.log(np.linspace(1, 13, 100)) # Time values
pdf_values = dist.pdf(t)
sf_values = dist.sf(t)
haz_values = pdf_values / sf_values
axs[0].plot(t, haz_values)
axs[2].plot(t, sf_values)
def make_weibull_haz(alpha, beta):
dist = weibull_min(c=alpha, scale=beta)
t = np.linspace(1, 13, 100) # Time values
pdf_values = dist.pdf(t)
sf_values = dist.sf(t)
haz_values = pdf_values / sf_values
axs[1].plot(t, haz_values)
axs[3].plot(t, sf_values)
[make_loglog_haz(4, b) for b in np.linspace(0.5, 2, 4)]
[make_loglog_haz(a, 2) for a in np.linspace(0.2, 7, 4)]
[make_weibull_haz(25, b) for b in np.linspace(10, 15, 4)]
[make_weibull_haz(a, 3) for a in np.linspace(2, 7, 7)]
axs[0].set_title("Log-Logistic Hazard Function", fontsize=15)
axs[2].set_title("Log-Logistic Survival Function", fontsize=15)
axs[1].set_title("Weibull Hazard Function", fontsize=15)
axs[3].set_title("Weibull Survival Function", fontsize=15);
AFT模型将解释变量纳入回归模型中,使其在时间尺度上呈倍增效应,从而影响个体沿时间轴前进的速度。因此,该模型可以直接解释为由朝向感兴趣事件的进展速度参数化。AFT模型的生存函数通常指定为
其中 \(S_{0}\) 是基线生存函数,但该模型通常以对数线性形式表示
其中,我们有基线生存函数 \(S_{0} = P(exp(\mu + \sigma\epsilon_{i}) \geq t)\),它被额外的协变量修改。这些细节对于估计策略非常重要,但它们显示了风险的影响如何像在CoxPH模型中一样在此处分解。协变量的影响在对数尺度上是累加的,以影响由个体风险概况引起的加速因子。
下面我们将估计两个AFT模型:韦布尔模型和对数logistic模型。最终,我们只是拟合一个删失的参数分布,但我们允许每个分布的参数之一被指定为解释变量的线性函数。因此,对数似然项只是
其中 \(f\) 是分布的概率密度函数,\(S\) 是生存函数,\(c\) 是表示观测是否被删失的指示函数 - 意味着它取值于 \(\{0, 1\}\),具体取决于个体是否被删失。 \(f\) 和 \(S\) 都由参数向量 \(\mathbf{\theta}\) 参数化。对于对数logistic模型,我们通过将时间变量转换为对数尺度并拟合具有参数 \(\mu, s\) 的logistic似然来估计它。结果参数拟合可以调整以恢复对数logistic生存函数,我们将在下面展示。对于韦布尔模型,参数分别表示为 \(\alpha, \beta\)。
coords = {
"intervals": intervals,
"preds": [
"sentiment",
"intention",
"Male",
"Low",
"Medium",
"Finance",
"Health",
"Law",
"Public/Government",
"Sales/Marketing",
],
}
X = retention_df[
[
"sentiment",
"intention",
"Male",
"Low",
"Medium",
"Finance",
"Health",
"Law",
"Public/Government",
"Sales/Marketing",
]
].copy()
y = retention_df["month"].values
cens = retention_df.left.values == 0.0
def logistic_sf(y, μ, s):
return 1.0 - pm.math.sigmoid((y - μ) / s)
def weibull_lccdf(x, alpha, beta):
"""Log complementary cdf of Weibull distribution."""
return -((x / beta) ** alpha)
def make_aft(y, weibull=True):
with pm.Model(coords=coords, check_bounds=False) as aft_model:
X_data = pm.MutableData("X_data_obs", X)
beta = pm.Normal("beta", 0.0, 1, dims="preds")
mu = pm.Normal("mu", 0, 1)
if weibull:
s = pm.HalfNormal("s", 5.0)
eta = pm.Deterministic("eta", pm.math.dot(beta, X_data.T))
reg = pm.Deterministic("reg", pt.exp(-(mu + eta) / s))
y_obs = pm.Weibull("y_obs", beta=reg[~cens], alpha=s, observed=y[~cens])
y_cens = pm.Potential("y_cens", weibull_lccdf(y[cens], alpha=s, beta=reg[cens]))
else:
s = pm.HalfNormal("s", 5.0)
eta = pm.Deterministic("eta", pm.math.dot(beta, X_data.T))
reg = pm.Deterministic("reg", mu + eta)
y_obs = pm.Logistic("y_obs", mu=reg[~cens], s=s, observed=y[~cens])
y_cens = pm.Potential("y_cens", logistic_sf(y[cens], reg[cens], s=s))
idata = pm.sample_prior_predictive()
idata.extend(
pm.sample(target_accept=0.95, random_seed=100, idata_kwargs={"log_likelihood": True})
)
idata.extend(pm.sample_posterior_predictive(idata))
return idata, aft_model
weibull_idata, weibull_aft = make_aft(y)
## Log y to ensure we're estimating a log-logistic random variable
loglogistic_idata, loglogistic_aft = make_aft(np.log(y), weibull=False)
/var/folders/__/ng_3_9pn1f11ftyml_qr69vh0000gn/T/ipykernel_48265/3743381411.py:63: UserWarning: The effect of Potentials on other parameters is ignored during prior predictive sampling. This is likely to lead to invalid or biased predictive samples.
idata = pm.sample_prior_predictive()
Sampling: [beta, mu, s, y_obs]
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta, mu, s]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 91 seconds.
/var/folders/__/ng_3_9pn1f11ftyml_qr69vh0000gn/T/ipykernel_48265/3743381411.py:67: UserWarning: The effect of Potentials on other parameters is ignored during posterior predictive sampling. This is likely to lead to invalid or biased predictive samples.
idata.extend(pm.sample_posterior_predictive(idata))
Sampling: [y_obs]
/var/folders/__/ng_3_9pn1f11ftyml_qr69vh0000gn/T/ipykernel_48265/3743381411.py:63: UserWarning: The effect of Potentials on other parameters is ignored during prior predictive sampling. This is likely to lead to invalid or biased predictive samples.
idata = pm.sample_prior_predictive()
Sampling: [beta, mu, s, y_obs]
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta, mu, s]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 67 seconds.
/var/folders/__/ng_3_9pn1f11ftyml_qr69vh0000gn/T/ipykernel_48265/3743381411.py:67: UserWarning: The effect of Potentials on other parameters is ignored during posterior predictive sampling. This is likely to lead to invalid or biased predictive samples.
idata.extend(pm.sample_posterior_predictive(idata))
Sampling: [y_obs]
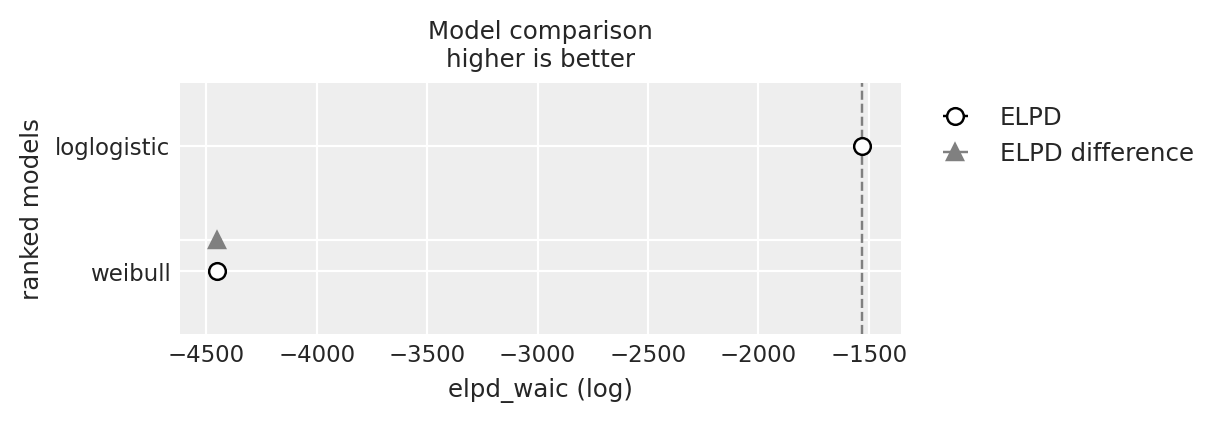
compare = az.compare({"weibull": weibull_idata, "loglogistic": loglogistic_idata}, ic="waic")
compare
| 排名 | elpd_waic | p_waic | elpd_diff | 权重 | 标准差 | 差分标准差 | 警告 | 比例 | |
|---|---|---|---|---|---|---|---|---|---|
| loglogistic | 0 | -1529.708134 | 12.302538 | 0.000000 | 1.0 | 28.919768 | 0.000000 | False | 对数 |
| 威布尔 | 1 | -4449.052088 | 7.357847 | 2919.343954 | 0.0 | 14.245419 | 20.929315 | False | 对数 |
az.plot_compare(compare);
从AFT模型推导个体生存预测#
从上面我们可以看到回归方程是如何计算的,以及如何作为 \(\beta\) 项进入韦布尔似然,以及作为 \(\mu\) 参数进入logistic分布。在这两种情况下,\(s\) 参数仍然可以自由地确定分布的形状。回想一下上面,回归方程作为时间点序列 \(t\) 的分母进入生存函数
因此,加权和越小,个体风险概况引起的加速因子就越大。
Weibull#
每个个体案例的估计参数拟合可以直接输入到韦布尔生存函数中作为 \(\beta\) 项,以恢复预测的轨迹。
fig, axs = plt.subplots(1, 2, figsize=(20, 7))
axs = axs.flatten()
#### Using the fact that we've already stored expected value for the regression equation
reg = az.summary(weibull_idata, var_names=["reg"])["mean"]
t = np.arange(1, 13, 1)
s = az.summary(weibull_idata, var_names=["s"])["mean"][0]
axs[0].hist(reg, bins=30, ec="black", color="slateblue")
axs[0].set_title(
"Histogram of Acceleration Factors in the individual Weibull fits \n across our sample"
)
axs[1].plot(
t,
weibull_min.sf(t, s, scale=reg.iloc[0]),
label=r"Individual 1 - $\beta$: " + f"{reg.iloc[0]}," + r"$\alpha$: " + f"{s}",
)
axs[1].plot(
t,
weibull_min.sf(t, s, scale=reg.iloc[1000]),
label=r"Individual 1000 - $\beta$: " + f"{reg.iloc[1000]}," + r"$\alpha$: " + f"{s}",
)
axs[1].set_title("Comparing Impact of Individual Factor \n on Survival Function")
axs[1].legend();
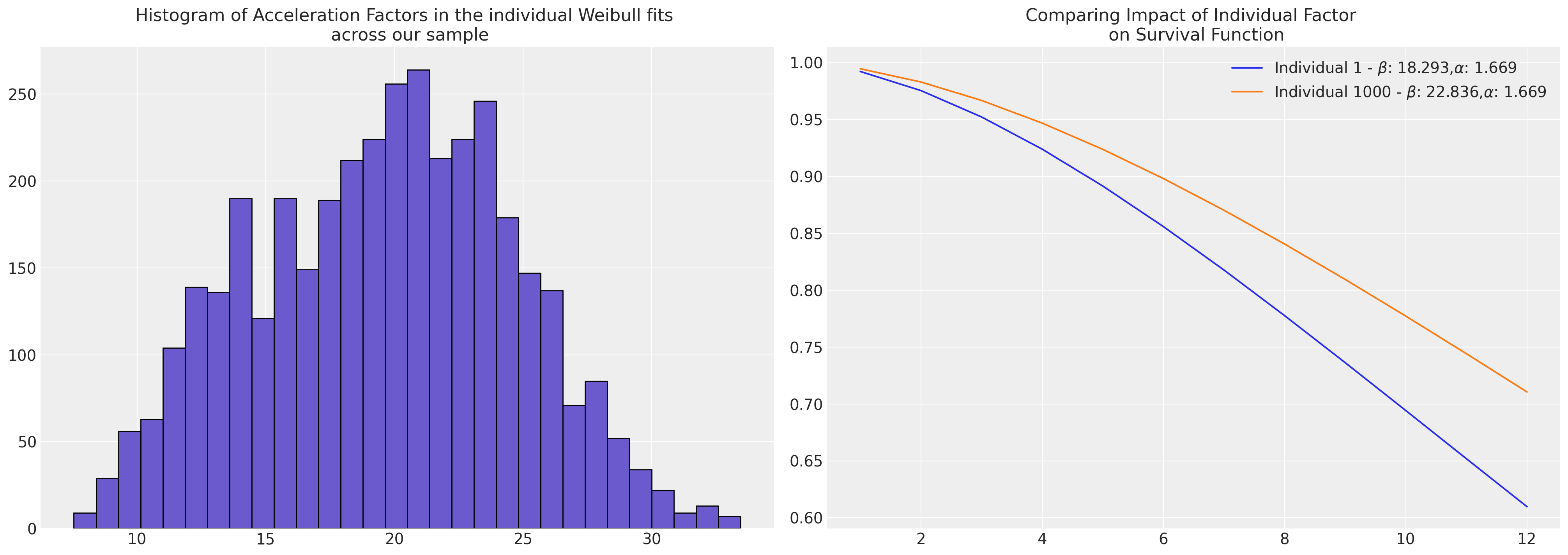
diff = reg.iloc[1000] - reg.iloc[0]
pchange = np.round(100 * (diff / reg.iloc[1000]), 2)
print(
f"In this case we could think of the relative change in acceleration \n factor between the individuals as representing a {pchange}% increase"
)
In this case we could think of the relative change in acceleration
factor between the individuals as representing a 19.89% increase
reg = az.summary(weibull_idata, var_names=["reg"])["mean"]
s = az.summary(weibull_idata, var_names=["s"])["mean"][0]
t = np.arange(1, 13, 1)
weibull_predicted_surv = pd.DataFrame(
[weibull_min.sf(t, s, scale=reg.iloc[i]) for i in range(len(reg))]
).T
weibull_predicted_surv
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 3760 | 3761 | 3762 | 3763 | 3764 | 3765 | 3766 | 3767 | 3768 | 3769 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.992210 | 0.995004 | 0.989394 | 0.996205 | 0.985931 | 0.986630 | 0.993607 | 0.991524 | 0.984801 | 0.988076 | ... | 0.992000 | 0.992905 | 0.977054 | 0.994145 | 0.994967 | 0.992228 | 0.995732 | 0.992615 | 0.992552 | 0.994143 |
| 1 | 0.975437 | 0.984199 | 0.966660 | 0.987982 | 0.955944 | 0.958101 | 0.979811 | 0.973296 | 0.952463 | 0.962572 | ... | 0.974782 | 0.977613 | 0.928841 | 0.981499 | 0.984083 | 0.975495 | 0.986491 | 0.976704 | 0.976508 | 0.981495 |
| 2 | 0.952249 | 0.969150 | 0.935465 | 0.976494 | 0.915172 | 0.919238 | 0.960668 | 0.948141 | 0.908627 | 0.927698 | ... | 0.950991 | 0.956432 | 0.864823 | 0.963927 | 0.968926 | 0.952360 | 0.973597 | 0.954684 | 0.954306 | 0.963919 |
| 3 | 0.923963 | 0.950613 | 0.897784 | 0.962283 | 0.866516 | 0.872748 | 0.937201 | 0.917528 | 0.856522 | 0.885767 | ... | 0.921990 | 0.930531 | 0.790779 | 0.942347 | 0.950258 | 0.924136 | 0.957673 | 0.927784 | 0.927191 | 0.942334 |
| 4 | 0.891571 | 0.929133 | 0.855147 | 0.945732 | 0.812266 | 0.820757 | 0.910170 | 0.882575 | 0.798705 | 0.838585 | ... | 0.888810 | 0.900784 | 0.711300 | 0.917431 | 0.928629 | 0.891814 | 0.939163 | 0.896928 | 0.896095 | 0.917413 |
| 5 | 0.855910 | 0.905157 | 0.808853 | 0.927149 | 0.754364 | 0.765074 | 0.880204 | 0.844222 | 0.737341 | 0.787690 | ... | 0.852318 | 0.867922 | 0.630133 | 0.889738 | 0.904492 | 0.856226 | 0.918430 | 0.862888 | 0.861802 | 0.889714 |
| 6 | 0.817716 | 0.879077 | 0.760043 | 0.906799 | 0.694484 | 0.707264 | 0.847860 | 0.803302 | 0.674283 | 0.734421 | ... | 0.813280 | 0.832589 | 0.550282 | 0.859756 | 0.878241 | 0.818106 | 0.895785 | 0.826349 | 0.825004 | 0.859726 |
| 7 | 0.777649 | 0.851242 | 0.709724 | 0.884919 | 0.634065 | 0.648678 | 0.813636 | 0.760557 | 0.611100 | 0.679952 | ... | 0.772381 | 0.795365 | 0.474048 | 0.827927 | 0.850231 | 0.778112 | 0.871508 | 0.787922 | 0.786320 | 0.827891 |
| 8 | 0.736306 | 0.821975 | 0.658781 | 0.861727 | 0.574315 | 0.590467 | 0.777988 | 0.716655 | 0.549097 | 0.625299 | ... | 0.730239 | 0.756774 | 0.403088 | 0.794653 | 0.820786 | 0.736840 | 0.845856 | 0.748163 | 0.746311 | 0.794610 |
| 9 | 0.694224 | 0.791570 | 0.607985 | 0.837421 | 0.516233 | 0.533589 | 0.741330 | 0.672191 | 0.489322 | 0.571326 | ... | 0.687409 | 0.717293 | 0.338483 | 0.760301 | 0.790206 | 0.694824 | 0.819065 | 0.707573 | 0.705486 | 0.760253 |
| 10 | 0.651884 | 0.760303 | 0.557996 | 0.812190 | 0.460610 | 0.478819 | 0.704042 | 0.627695 | 0.432587 | 0.518759 | ... | 0.644388 | 0.677354 | 0.280813 | 0.725212 | 0.758767 | 0.652545 | 0.791357 | 0.666605 | 0.664300 | 0.725158 |
| 11 | 0.609713 | 0.728426 | 0.509367 | 0.786208 | 0.408051 | 0.426760 | 0.666467 | 0.583629 | 0.379484 | 0.468183 | ... | 0.601614 | 0.637342 | 0.230254 | 0.689694 | 0.726725 | 0.610428 | 0.762937 | 0.625662 | 0.623161 | 0.689635 |
12 行 × 3770 列
Log Logistic#
对于Logistic拟合,我们已经推导出了需要转换的参数估计,以恢复我们旨在估计的对数logistic生存曲线。
reg = az.summary(loglogistic_idata, var_names=["reg"])["mean"]
s = az.summary(loglogistic_idata, var_names=["s"])["mean"][0]
temp = retention_df
t = np.log(np.arange(1, 13, 1))
## Transforming to the Log-Logistic scale
alpha = np.round((1 / s), 3)
beta = np.round(np.exp(reg) ** s, 3)
fig, axs = plt.subplots(1, 2, figsize=(20, 7))
axs = axs.flatten()
axs[0].hist(reg, bins=30, ec="black", color="slateblue")
axs[0].set_title("Histogram of beta terms in the individual Log Logistic fits")
axs[1].plot(
np.exp(t),
fisk.sf(t, c=alpha, scale=beta.iloc[0]),
label=r"$\beta$: " + f"{beta.iloc[0]}," + r"$\alpha$: " + f"{alpha}",
)
axs[1].plot(
np.exp(t),
fisk.sf(t, c=alpha, scale=beta.iloc[1000]),
label=r"$\beta$: " + f"{beta.iloc[1000]}," + r"$\alpha$: " + f"{alpha}",
)
axs[1].set_title("Comparing Impact of Individual Factor \n on Survival Function")
axs[1].legend();
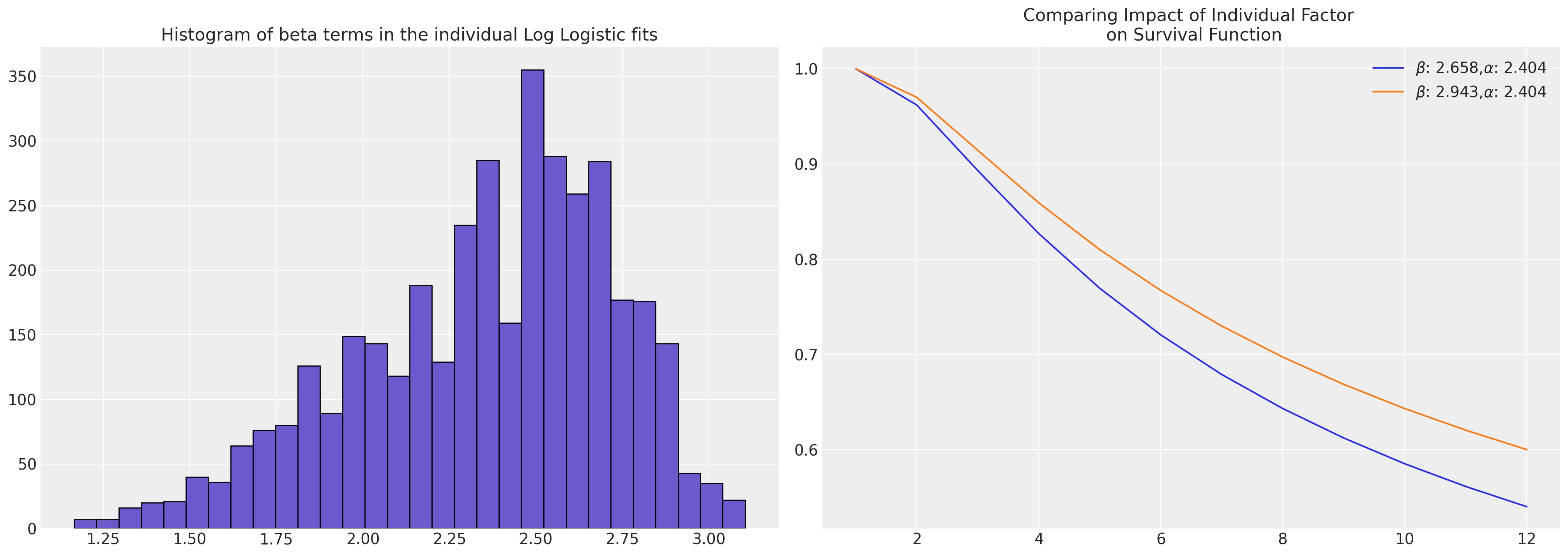
diff = beta.iloc[1000] - beta.iloc[0]
pchange = np.round(100 * (diff / beta.iloc[1000]), 2)
print(
f"In this case we could think of the relative change in acceleration \n factor between the individuals as representing a {pchange}% increase"
)
In this case we could think of the relative change in acceleration
factor between the individuals as representing a 9.68% increase
loglogistic_predicted_surv = pd.DataFrame(
[fisk.sf(t, c=alpha, scale=beta.iloc[i]) for i in range(len(reg))]
).T
loglogistic_predicted_surv
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 3760 | 3761 | 3762 | 3763 | 3764 | 3765 | 3766 | 3767 | 3768 | 3769 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | ... | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 | 1.000000 |
| 1 | 0.961991 | 0.972250 | 0.950902 | 0.977471 | 0.939736 | 0.940788 | 0.967457 | 0.958955 | 0.936014 | 0.939485 | ... | 0.959430 | 0.961925 | 0.916039 | 0.968951 | 0.969927 | 0.960809 | 0.975477 | 0.956383 | 0.961825 | 0.968190 |
| 2 | 0.893214 | 0.920502 | 0.864877 | 0.934806 | 0.837491 | 0.840024 | 0.907619 | 0.885339 | 0.828605 | 0.836887 | ... | 0.886564 | 0.893041 | 0.782878 | 0.911612 | 0.914229 | 0.890136 | 0.929309 | 0.878736 | 0.892781 | 0.909577 |
| 3 | 0.827049 | 0.868761 | 0.785373 | 0.891275 | 0.746596 | 0.750123 | 0.848870 | 0.815305 | 0.734317 | 0.745757 | ... | 0.817124 | 0.826790 | 0.673351 | 0.854996 | 0.859031 | 0.822444 | 0.882569 | 0.805554 | 0.826401 | 0.851869 |
| 4 | 0.769601 | 0.822189 | 0.718789 | 0.851325 | 0.672990 | 0.677099 | 0.796890 | 0.755111 | 0.658774 | 0.672014 | ... | 0.757346 | 0.769280 | 0.590149 | 0.804638 | 0.809763 | 0.763902 | 0.839995 | 0.743183 | 0.768798 | 0.800678 |
| 5 | 0.720729 | 0.781302 | 0.663846 | 0.815635 | 0.613905 | 0.618336 | 0.751941 | 0.704345 | 0.598653 | 0.612855 | ... | 0.706864 | 0.720364 | 0.526625 | 0.760888 | 0.766828 | 0.714270 | 0.802217 | 0.690957 | 0.719817 | 0.756311 |
| 6 | 0.679108 | 0.745520 | 0.618238 | 0.783917 | 0.565951 | 0.570547 | 0.713119 | 0.661429 | 0.550193 | 0.564863 | ... | 0.664139 | 0.678713 | 0.477065 | 0.722952 | 0.729499 | 0.672124 | 0.768845 | 0.647072 | 0.678120 | 0.717917 |
| 7 | 0.643393 | 0.714085 | 0.579939 | 0.755671 | 0.526425 | 0.531093 | 0.679403 | 0.624834 | 0.510473 | 0.525321 | ... | 0.627672 | 0.642978 | 0.437489 | 0.689888 | 0.696890 | 0.636049 | 0.739284 | 0.609840 | 0.642354 | 0.684515 |
| 8 | 0.612462 | 0.686296 | 0.547375 | 0.730397 | 0.493338 | 0.498021 | 0.649896 | 0.593311 | 0.477377 | 0.492230 | ... | 0.596233 | 0.612032 | 0.405209 | 0.660864 | 0.668205 | 0.604872 | 0.712959 | 0.577908 | 0.611387 | 0.655239 |
| 9 | 0.585422 | 0.661562 | 0.519359 | 0.707659 | 0.465244 | 0.469908 | 0.623864 | 0.565882 | 0.449386 | 0.464142 | ... | 0.568859 | 0.584983 | 0.378386 | 0.635191 | 0.642787 | 0.577668 | 0.689376 | 0.550228 | 0.584323 | 0.629379 |
| 10 | 0.561578 | 0.639400 | 0.494993 | 0.687088 | 0.441087 | 0.445710 | 0.600723 | 0.541794 | 0.425398 | 0.439995 | ... | 0.544803 | 0.561133 | 0.355739 | 0.612313 | 0.620101 | 0.553718 | 0.668121 | 0.525999 | 0.560464 | 0.606363 |
| 11 | 0.540383 | 0.619416 | 0.473595 | 0.668376 | 0.420081 | 0.424652 | 0.580005 | 0.520459 | 0.404598 | 0.419003 | ... | 0.523484 | 0.539933 | 0.336352 | 0.591787 | 0.599718 | 0.532459 | 0.648855 | 0.504600 | 0.539258 | 0.585735 |
12 行 × 3770 列
这两个模型都为这两个个体拟合了可比较的估计值。现在我们将看到边际生存函数如何在我们的整个个体样本中进行比较。
fig, ax = plt.subplots(figsize=(20, 7))
ax.plot(
loglogistic_predicted_surv.iloc[:, [1, 300]], label=["LL-Individual 1", "LL-Individual 300"]
)
ax.plot(
loglogistic_predicted_surv.mean(axis=1),
label="LL Marginal Survival Curve",
linestyle="--",
color="black",
linewidth=4.5,
)
ax.plot(weibull_predicted_surv.iloc[:, [1, 300]], label=["W-Individual 1", "W-Individual 300"])
ax.plot(
weibull_predicted_surv.mean(axis=1),
label="W Marginal Survival Curve",
linestyle="dotted",
color="black",
linewidth=4.5,
)
ax.plot(surv_df.iloc[:, [1, 300]], label=["CoxPH-Individual 1", "CoxPH-Individual 300"])
ax.plot(
surv_df.mean(axis=1),
label="CoxPH Marginal Survival Curve",
linestyle="-.",
color="black",
linewidth=4.5,
)
ax.set_title(
"Comparison predicted Individual Survival Curves and \n Marginal (expected) Survival curve across Sample",
fontsize=25,
)
kmf.plot_survival_function(ax=ax, label="Overall KM estimate", color="black")
ax.set_xlabel("Time in Month")
ax.set_ylabel("Probability")
ax.legend();
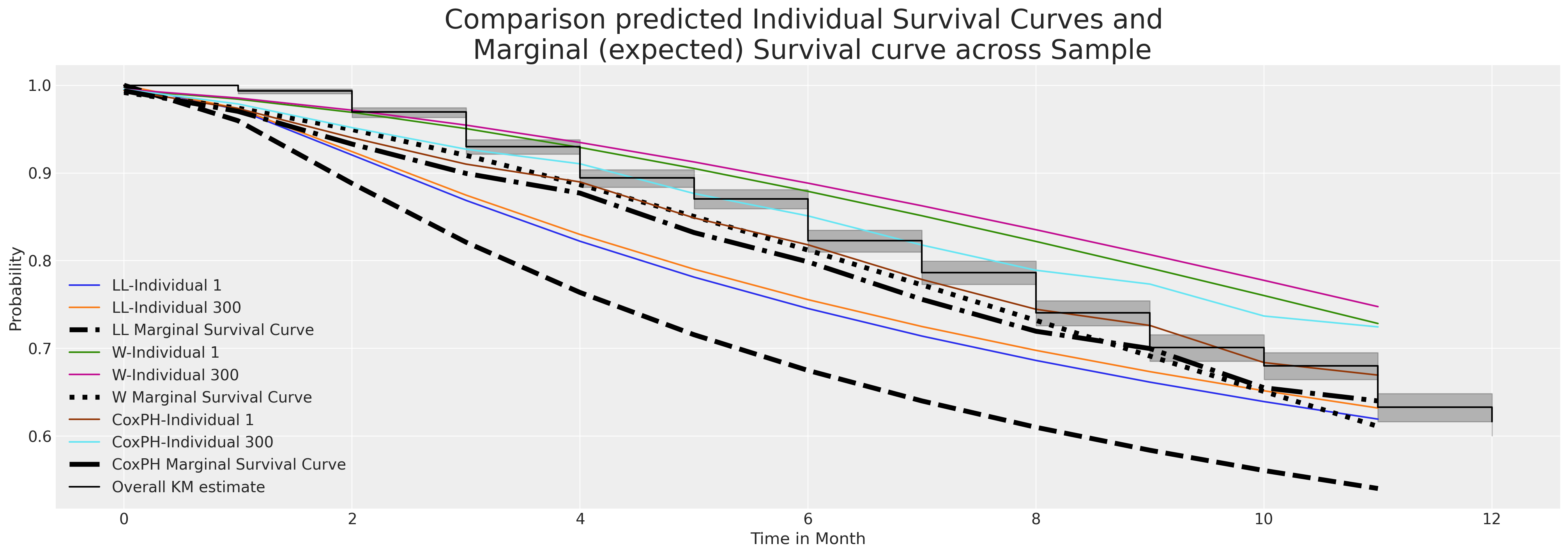
上面我们绘制了每个模型中个体预测生存函数的样本。此外,我们还绘制了通过对数据集中的个体样本进行逐行平均预测的边际生存曲线。这种边际量通常是比较不同时期变化的有用基准。它是一种可以逐年和随时间推移进行比较的度量。
拟合具有个体共享脆弱项的模型#
更广泛地说,贝叶斯回归建模中最引人注目的模式之一是能够融入分层结构。分层生存模型的类似物是个体脆弱性生存模型。但是,“脆弱性”不需要仅在个体层面指定 - 所谓的“共享”脆弱性可以在群体层面部署,例如跨 field。
在上面的CoxPH模型中,我们使用标准回归公式将数据拟合到模型中,其中使用指示变量表示 field 变量的不同级别,这些变量包含在线性组合的加权和中。对于脆弱性模型,我们允许个体或群体脆弱性项作为乘法因子进入我们的模型,该乘法因子高于基线风险与风险的加权人口统计特征的组合。这使我们能够捕获归因于特定个体或特定群体内的异质效应的估计。在我们的上下文中,这些术语旨在解释某些员工对公司的“过度”长期忠诚度,尽管市场上还有其他职位。此外,我们可以对基线风险进行分层,例如按性别,以捕获随时间变化的风险程度,作为其协变量概况的函数。因此,我们的方程现在变为
如下所示,这可以用贝叶斯方式估计。请注意,我们必须为 \(z\) 项设置先验,该项以乘法方式进入方程。为了设置这样的先验,我们推断个体异质性不会导致离职时间加速/减速超过30%,并且我们选择伽马分布作为脆弱性项的先验。
opt_params = pm.find_constrained_prior(
pm.Gamma,
lower=0.80,
upper=1.30,
mass=0.90,
init_guess={"alpha": 1.7, "beta": 1.7},
)
opt_params
/Users/nathanielforde/mambaforge/envs/pymc_examples_new/lib/python3.9/site-packages/pytensor/tensor/rewriting/elemwise.py:685: UserWarning: Optimization Warning: The Op gammainc_der does not provide a C implementation. As well as being potentially slow, this also disables loop fusion.
warn(
/Users/nathanielforde/mambaforge/envs/pymc_examples_new/lib/python3.9/site-packages/pytensor/tensor/rewriting/elemwise.py:685: UserWarning: Optimization Warning: The Op gammainc_der does not provide a C implementation. As well as being potentially slow, this also disables loop fusion.
warn(
{'alpha': 46.22819238464343, 'beta': 44.910852755302585}
fig, ax = plt.subplots(figsize=(20, 6))
ax.hist(
pm.draw(pm.Gamma.dist(alpha=opt_params["alpha"], beta=opt_params["beta"]), 1000),
ec="black",
color="royalblue",
bins=30,
alpha=0.4,
)
ax.set_title("Draws from Gamma constrained around Unity", fontsize=20);

preds = [
"sentiment",
"intention",
"Low",
"Medium",
"Finance",
"Health",
"Law",
"Public/Government",
"Sales/Marketing",
]
preds3 = ["sentiment", "Low", "Medium"]
def make_coxph_frailty(preds, factor):
frailty_idx, frailty_labels = pd.factorize(factor)
df_m = retention_df[retention_df["Male"] == 1]
df_f = retention_df[retention_df["Male"] == 0]
coords = {
"intervals": intervals,
"preds": preds,
"frailty_id": frailty_labels,
"gender": ["Male", "Female"],
"women": df_f.index,
"men": df_m.index,
"obs": range(len(retention_df)),
}
with pm.Model(coords=coords) as frailty_model:
X_data_m = pm.MutableData("X_data_m", df_m[preds], dims=("men", "preds"))
X_data_f = pm.MutableData("X_data_f", df_f[preds], dims=("women", "preds"))
lambda0 = pm.Gamma("lambda0", 0.01, 0.01, dims=("intervals", "gender"))
sigma_frailty = pm.Normal("sigma_frailty", opt_params["alpha"], 1)
mu_frailty = pm.Normal("mu_frailty", opt_params["beta"], 1)
frailty = pm.Gamma("frailty", mu_frailty, sigma_frailty, dims="frailty_id")
beta = pm.Normal("beta", 0, sigma=1, dims="preds")
## Stratified baseline hazards
lambda_m = pm.Deterministic(
"lambda_m",
pt.outer(pt.exp(pm.math.dot(beta, X_data_m.T)), lambda0[:, 0]),
dims=("men", "intervals"),
)
lambda_f = pm.Deterministic(
"lambda_f",
pt.outer(pt.exp(pm.math.dot(beta, X_data_f.T)), lambda0[:, 1]),
dims=("women", "intervals"),
)
lambda_ = pm.Deterministic(
"lambda_",
frailty[frailty_idx, None] * pt.concatenate([lambda_f, lambda_m], axis=0),
dims=("obs", "intervals"),
)
mu = pm.Deterministic("mu", exposure * lambda_, dims=("obs", "intervals"))
obs = pm.Poisson("outcome", mu, observed=quit, dims=("obs", "intervals"))
frailty_idata = pm.sample(random_seed=101)
return frailty_idata, frailty_model
frailty_idata, frailty_model = make_coxph_frailty(preds, range(len(retention_df)))
pm.model_to_graphviz(frailty_model)
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [lambda0, sigma_frailty, mu_frailty, frailty, beta]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 162 seconds.
The rhat statistic is larger than 1.01 for some parameters. This indicates problems during sampling. See https://arxiv.org/abs/1903.08008 for details
The effective sample size per chain is smaller than 100 for some parameters. A higher number is needed for reliable rhat and ess computation. See https://arxiv.org/abs/1903.08008 for details

拟合上述模型使我们能够提取关于基线风险的性别特定视图。这种模型规范可以帮助解释比例风险假设的失败,从而可以表达由不同水平的协变量引起的时间变化风险。我们还可以允许跨组的共享脆弱性项,就像这里允许基于工作 field 的组效应的情况一样。然而,通常这与在模型中包含field作为固定效应(就像我们在上面的第一个CoxPH模型中所做的那样)没有太大区别,但在这里我们允许系数估计值来自相同的分布。此分布的方差特征可能具有独立的意义。
此处的方差越大 - 基础模型在捕获观察到的状态转换方面就越差。在思考索瑞斯悖论背景下不断变化的风险时,您可能会认为,个体脆弱性项中的异质性越大,模型规范性越差,我们对所讨论的状态转换的理解就越差 - 导致沙子何时变成堆的语义模糊性,以及员工何时可能离职的更大不确定性。
接下来,我们将拟合一个在 field 分组中具有脆弱性的模型。这些被称为共享脆弱性。
shared_frailty_idata, shared_frailty_model = make_coxph_frailty(preds3, retention_df["field"])
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [lambda0, sigma_frailty, mu_frailty, frailty, beta]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 71 seconds.
pm.model_to_graphviz(shared_frailty_model)

共享脆弱性项和个体脆弱性项之间的比较使我们能够看到,包含更多协变量和个体脆弱性项如何吸收基线风险中的方差并缩小潜在风险的大小。
fig, ax = plt.subplots(figsize=(20, 6))
base_m = shared_frailty_idata["posterior"]["lambda0"].sel(gender="Male")
base_f = shared_frailty_idata["posterior"]["lambda0"].sel(gender="Female")
az.plot_hdi(range(12), base_m, ax=ax, color="lightblue", fill_kwargs={"alpha": 0.5}, smooth=False)
az.plot_hdi(range(12), base_f, ax=ax, color="red", fill_kwargs={"alpha": 0.3}, smooth=False)
get_mean(base_m).plot(ax=ax, color="darkred", label="Male Baseline Hazard Shared Frailty")
get_mean(base_f).plot(ax=ax, color="blue", label="Female Baseline Hazard Shared Frailty")
base_m_i = frailty_idata["posterior"]["lambda0"].sel(gender="Male")
base_f_i = frailty_idata["posterior"]["lambda0"].sel(gender="Female")
az.plot_hdi(range(12), base_m_i, ax=ax, color="cyan", fill_kwargs={"alpha": 0.5}, smooth=False)
az.plot_hdi(range(12), base_f_i, ax=ax, color="magenta", fill_kwargs={"alpha": 0.3}, smooth=False)
get_mean(base_m_i).plot(ax=ax, color="cyan", label="Male Baseline Hazard Individual Frailty")
get_mean(base_f_i).plot(ax=ax, color="magenta", label="Female Baseline Hazard Individual Frailty")
ax.legend()
ax.set_title("Stratified Baseline Hazards");

Let us to pull out and inspect the individual frailty terms
frailty_terms = az.summary(frailty_idata, var_names=["frailty"])
frailty_terms.head()
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| frailty[0] | 0.959 | 0.146 | 0.678 | 1.223 | 0.003 | 0.002 | 2433.0 | 2325.0 | 1.0 |
| frailty[1] | 0.984 | 0.152 | 0.692 | 1.255 | 0.003 | 0.002 | 2352.0 | 2273.0 | 1.0 |
| frailty[2] | 0.980 | 0.145 | 0.699 | 1.243 | 0.003 | 0.002 | 3027.0 | 2771.0 | 1.0 |
| frailty[3] | 0.963 | 0.143 | 0.705 | 1.247 | 0.003 | 0.002 | 2174.0 | 2785.0 | 1.0 |
| frailty[4] | 0.953 | 0.141 | 0.687 | 1.217 | 0.004 | 0.003 | 1508.0 | 2561.0 | 1.0 |
and the shared terms across the groups. Where we can see how working in either Finance or Health seems to drive up the chances of attrition after controlling for other demographic information.
axs = az.plot_posterior(shared_frailty_idata, var_names=["frailty"])
axs = axs.flatten()
for ax in axs:
ax.axvline(1, color="red", label="No change")
ax.legend()
plt.suptitle("Shared Frailty Estimates across the Job Area", fontsize=30);

像这样的共享脆弱性模型在医学试验中很重要,例如,当我们想要衡量实施试验方案的不同机构之间的差异时。但同样在人力资源环境中,我们可能会想象检查不同管理者/团队动态之间的差异脆弱性项。
现在我们将把这个建议放在一边,专注于个体脆弱性模型。
ax = az.plot_forest(
[base_idata, base_intention_idata, weibull_idata, frailty_idata],
model_names=["coxph_sentiment", "coxph_intention", "weibull_sentiment", "frailty_intention"],
var_names=["beta"],
combined=True,
figsize=(20, 15),
r_hat=True,
)
ax[0].set_title("Parameter Estimates: Various Models", fontsize=20);

现在我们可以分离脆弱性估计值,并将它们与我们了解的关于每个个体的人口统计信息进行比较。由于我们在没有意图变量的情况下对数据进行了建模,因此有趣的是,模型如何尝试使用个体脆弱性项来补偿陈述意图的影响。
temp = retention_df.copy()
temp["frailty"] = frailty_terms.reset_index()["mean"]
(
temp.groupby(["Male", "sentiment", "intention"])[["frailty"]]
.mean()
.reset_index()
.pivot(index=["Male", "sentiment"], columns="intention", values="frailty")
.style.background_gradient(cmap="OrRd", axis=None)
.set_precision(3)
)
/var/folders/__/ng_3_9pn1f11ftyml_qr69vh0000gn/T/ipykernel_48265/2005202898.py:4: FutureWarning: this method is deprecated in favour of `Styler.format(precision=..)`
temp.groupby(["Male", "sentiment", "intention"])[["frailty"]]
| 意向 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 男性 | 情感 | ||||||||||
| 0 | 1 | nan | 0.983 | nan | nan | nan | 0.981 | nan | 0.986 | 0.961 | 0.982 |
| 2 | 0.966 | nan | nan | 0.970 | 0.973 | 0.963 | 0.963 | 0.972 | 0.986 | 0.962 | |
| 3 | 0.989 | 0.975 | 0.971 | 0.972 | 0.970 | 0.964 | 0.965 | 0.974 | nan | 0.995 | |
| 4 | 0.972 | 0.971 | 0.985 | 0.970 | 0.975 | 0.968 | 0.970 | 0.965 | 0.973 | nan | |
| 5 | nan | 0.961 | 0.986 | 0.978 | 0.964 | 0.963 | 0.974 | 0.964 | nan | 0.947 | |
| 6 | 0.976 | 0.970 | 0.961 | 0.965 | 0.978 | 0.966 | 0.960 | 0.978 | nan | 0.986 | |
| 7 | 0.972 | 0.969 | 0.969 | 0.973 | 0.969 | 0.972 | 0.969 | 0.969 | 0.968 | 0.965 | |
| 8 | 0.968 | 0.969 | 0.969 | 0.969 | 0.968 | 0.971 | 0.968 | 0.968 | 0.968 | 0.958 | |
| 9 | 0.970 | 0.970 | 0.969 | 0.967 | 0.966 | 0.971 | 0.969 | 0.950 | nan | nan | |
| 10 | 0.967 | 0.971 | 0.968 | 0.971 | 0.970 | 0.970 | 0.974 | 0.953 | 0.960 | nan | |
| 1 | 1 | nan | nan | 0.975 | nan | 0.968 | 0.981 | 0.951 | 0.969 | 0.965 | 0.975 |
| 2 | nan | 0.973 | 0.972 | 0.967 | 0.964 | 0.972 | 0.966 | 0.965 | 0.970 | 0.983 | |
| 3 | 0.962 | nan | 0.989 | 0.967 | 0.965 | 0.969 | 0.955 | 0.968 | 0.960 | 0.981 | |
| 4 | nan | 0.971 | 0.966 | 0.973 | 0.971 | 0.971 | 0.970 | 0.976 | 0.969 | nan | |
| 5 | 0.965 | 0.976 | 0.967 | 0.966 | 0.981 | 0.974 | 0.963 | 0.974 | 0.947 | 0.946 | |
| 6 | 0.972 | 0.968 | 0.964 | 0.969 | 0.970 | 0.961 | 0.968 | 0.964 | 0.979 | 0.972 | |
| 7 | 0.967 | 0.971 | 0.969 | 0.969 | 0.968 | 0.971 | 0.971 | 0.965 | 0.970 | 0.975 | |
| 8 | 0.969 | 0.970 | 0.968 | 0.969 | 0.970 | 0.972 | 0.971 | 0.973 | 0.976 | 0.978 | |
| 9 | 0.970 | 0.970 | 0.968 | 0.969 | 0.970 | 0.964 | 0.964 | 0.973 | 0.974 | nan | |
| 10 | 0.968 | 0.970 | 0.969 | 0.972 | 0.969 | 0.967 | 0.970 | 0.977 | 0.988 | nan |
上面的热图表明,该模型尤其高估了低情绪和低意图得分的影响。脆弱性项通过降低风险项中乘法增加的比率来补偿。存在一种普遍模式,即模型高估了风险,而脆弱性项将其“向下修正”。这有一定的道理,因为看到如此低的情绪与没有辞职意图相结合有点奇怪。这表明受访者的回答可能无法反映他们的深思熟虑的意见。在辞职意图较高的情况下,效果同样明显,这在此背景下也很有意义。
探究Cox脆弱性模型#
和以前一样,我们将需要提取个体预测的生存函数和累积风险函数。这可以类似于上面的分析来完成,但在这里我们包括平均脆弱性项来预测个体风险。
def extract_individual_frailty(i, retention_df, intention=False):
beta = frailty_idata.posterior["beta"]
if intention:
intention_posterior = beta.sel(preds="intention")
else:
intention_posterior = 0
hazard_base_m = frailty_idata["posterior"]["lambda0"].sel(gender="Male")
hazard_base_f = frailty_idata["posterior"]["lambda0"].sel(gender="Female")
frailty = frailty_idata.posterior["frailty"]
if retention_df.iloc[i]["Male"] == 1:
hazard_base = hazard_base_m
else:
hazard_base = hazard_base_f
full_hazard_idata = hazard_base * (
frailty.sel(frailty_id=i).mean().item()
* np.exp(
beta.sel(preds="sentiment") * retention_df.iloc[i]["sentiment"]
+ np.where(intention, intention_posterior * retention_df.iloc[i]["intention"], 0)
+ beta.sel(preds="Low") * retention_df.iloc[i]["Low"]
+ beta.sel(preds="Medium") * retention_df.iloc[i]["Medium"]
+ beta.sel(preds="Finance") * retention_df.iloc[i]["Finance"]
+ beta.sel(preds="Health") * retention_df.iloc[i]["Health"]
+ beta.sel(preds="Law") * retention_df.iloc[i]["Law"]
+ beta.sel(preds="Public/Government") * retention_df.iloc[i]["Public/Government"]
+ beta.sel(preds="Sales/Marketing") * retention_df.iloc[i]["Sales/Marketing"]
)
)
cum_haz_idata = cum_hazard(full_hazard_idata)
survival_idata = survival(full_hazard_idata)
return full_hazard_idata, cum_haz_idata, survival_idata, hazard_base
def plot_individual_frailty(retention_df, individuals=[1, 300, 700], intention=False):
fig, axs = plt.subplots(1, 2, figsize=(20, 7))
axs = axs.flatten()
colors = ["slateblue", "magenta", "darkgreen"]
for i, c in zip(individuals, colors):
haz_idata, cum_haz_idata, survival_idata, base_hazard = extract_individual_frailty(
i, retention_df, intention
)
axs[0].plot(get_mean(survival_idata), label=f"individual_{i}", color=c)
az.plot_hdi(range(12), survival_idata, ax=axs[0], fill_kwargs={"color": c})
axs[1].plot(get_mean(cum_haz_idata), label=f"individual_{i}", color=c)
az.plot_hdi(range(12), cum_haz_idata, ax=axs[1], fill_kwargs={"color": c})
axs[0].set_title("Individual Survival Functions", fontsize=20)
axs[1].set_title("Individual Cumulative Hazard Functions", fontsize=20)
az.plot_hdi(
range(12),
survival(base_hazard),
color="lightblue",
ax=axs[0],
fill_kwargs={"label": "Baseline Survival"},
)
az.plot_hdi(
range(12),
cum_hazard(base_hazard),
color="lightblue",
ax=axs[1],
fill_kwargs={"label": "Baseline Hazard"},
)
axs[0].legend()
axs[1].legend()
plot_individual_frailty(retention_df, [0, 1, 2], intention=True)
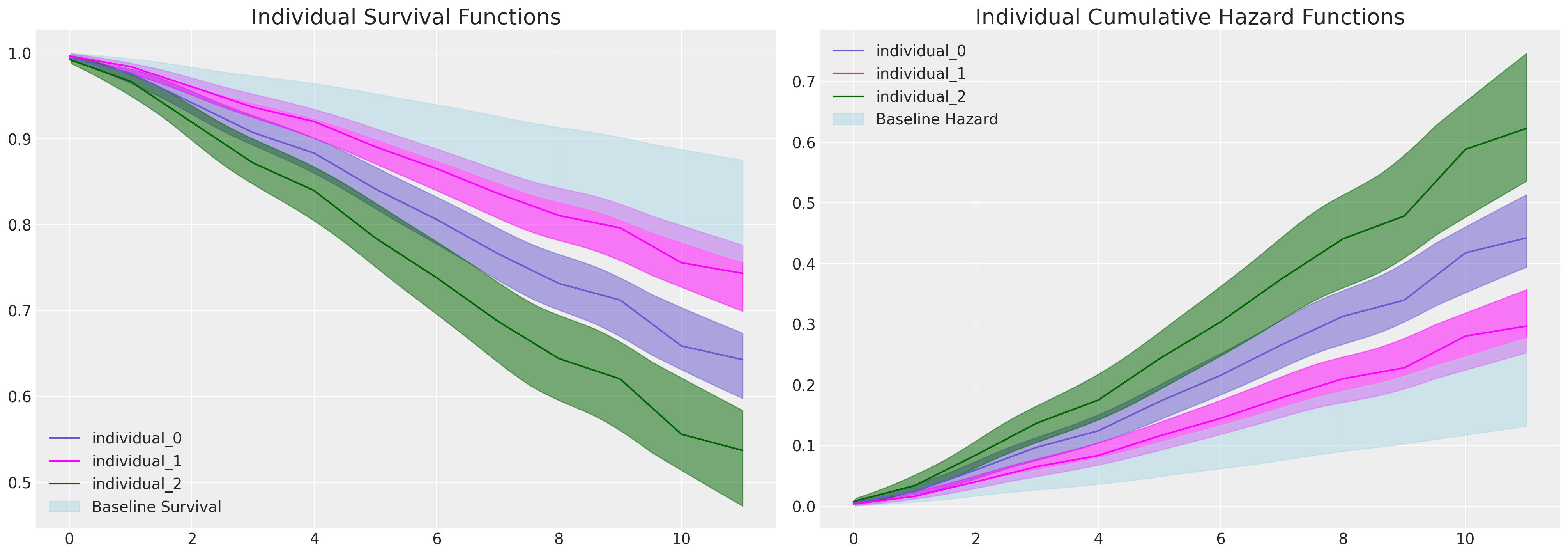
在这些图中,我们看到了每个个体的预测生存函数存在显着差异,这可以通过他们陈述的离职 intention 的度量来解释。我们可以通过检查这三个个体的协变量概况来看到这一点。
retention_df.iloc[0:3, :]
| 性别 | 领域 | 级别 | 情感 | 意向 | 离职 | 月份 | 男性 | 低 | 中 | 金融 | 健康 | 法律 | 公共/政府 | 销售/市场营销 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 女性 | 教育和培训 | 低 | 8 | 5 | 0 | 12 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 女性 | 教育和培训 | 中 | 8 | 3 | 1 | 11 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 2 | 女性 | 教育和培训 | 低 | 10 | 7 | 1 | 9 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
def create_predictions(retention_df, intention=False):
cum_haz = {}
surv = {}
for i in range(len(retention_df)):
haz_idata, cum_haz_idata, survival_idata, base_hazard = extract_individual_frailty(
i, retention_df, intention
)
cum_haz[i] = get_mean(cum_haz_idata)
surv[i] = get_mean(survival_idata)
cum_haz = pd.DataFrame(cum_haz)
surv = pd.DataFrame(surv)
return cum_haz, surv
cum_haz_frailty_df, surv_frailty_df = create_predictions(retention_df, intention=True)
surv_frailty_df
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 3760 | 3761 | 3762 | 3763 | 3764 | 3765 | 3766 | 3767 | 3768 | 3769 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.994606 | 0.996375 | 0.992411 | 0.997349 | 0.990543 | 0.990702 | 0.995489 | 0.994179 | 0.989593 | 0.991453 | ... | 0.993628 | 0.994188 | 0.983980 | 0.995030 | 0.995925 | 0.993665 | 0.996433 | 0.994158 | 0.994063 | 0.995216 |
| 1 | 0.976327 | 0.984043 | 0.966826 | 0.988325 | 0.958788 | 0.959467 | 0.980174 | 0.974480 | 0.954712 | 0.962651 | ... | 0.969320 | 0.971975 | 0.924277 | 0.976007 | 0.980310 | 0.969484 | 0.982735 | 0.971909 | 0.971377 | 0.976890 |
| 2 | 0.942033 | 0.960706 | 0.919347 | 0.971156 | 0.900424 | 0.902001 | 0.951311 | 0.937624 | 0.890904 | 0.909467 | ... | 0.932821 | 0.938532 | 0.838909 | 0.947254 | 0.956586 | 0.933182 | 0.961883 | 0.938401 | 0.937252 | 0.949165 |
| 3 | 0.907312 | 0.936786 | 0.872011 | 0.953446 | 0.842969 | 0.845380 | 0.921911 | 0.900423 | 0.828493 | 0.856838 | ... | 0.900804 | 0.909106 | 0.768149 | 0.921832 | 0.935513 | 0.901336 | 0.943293 | 0.908935 | 0.907248 | 0.924625 |
| 4 | 0.883317 | 0.920081 | 0.839730 | 0.941000 | 0.804224 | 0.807162 | 0.901485 | 0.874762 | 0.786641 | 0.821132 | ... | 0.879373 | 0.889368 | 0.722899 | 0.904702 | 0.921262 | 0.880021 | 0.930687 | 0.889181 | 0.887128 | 0.908082 |
| 5 | 0.841648 | 0.890708 | 0.784532 | 0.918977 | 0.738834 | 0.742598 | 0.865795 | 0.830381 | 0.716478 | 0.760581 | ... | 0.832603 | 0.846130 | 0.629919 | 0.866986 | 0.889720 | 0.833480 | 0.902695 | 0.845922 | 0.843086 | 0.871607 |
| 6 | 0.806120 | 0.865288 | 0.738349 | 0.899763 | 0.684982 | 0.689352 | 0.835135 | 0.792668 | 0.659146 | 0.710355 | ... | 0.799519 | 0.815422 | 0.568818 | 0.840028 | 0.867017 | 0.800552 | 0.882474 | 0.815213 | 0.811833 | 0.845499 |
| 7 | 0.766357 | 0.836395 | 0.687650 | 0.877734 | 0.626822 | 0.631774 | 0.800555 | 0.750613 | 0.597743 | 0.655685 | ... | 0.753924 | 0.772917 | 0.490788 | 0.802467 | 0.835171 | 0.755166 | 0.853987 | 0.772734 | 0.768621 | 0.809073 |
| 8 | 0.731486 | 0.810657 | 0.644064 | 0.857939 | 0.577659 | 0.583025 | 0.769986 | 0.713897 | 0.546274 | 0.609121 | ... | 0.714991 | 0.736461 | 0.429643 | 0.769989 | 0.807437 | 0.716402 | 0.829057 | 0.736314 | 0.731583 | 0.777532 |
| 9 | 0.712245 | 0.796290 | 0.620376 | 0.846812 | 0.551281 | 0.556847 | 0.753018 | 0.693707 | 0.518844 | 0.584005 | ... | 0.693743 | 0.716486 | 0.398343 | 0.752098 | 0.792068 | 0.695239 | 0.815195 | 0.716379 | 0.711309 | 0.760135 |
| 10 | 0.658844 | 0.755713 | 0.556014 | 0.815095 | 0.480884 | 0.486882 | 0.705519 | 0.637894 | 0.446305 | 0.516415 | ... | 0.649420 | 0.674652 | 0.337641 | 0.714375 | 0.759462 | 0.651082 | 0.785667 | 0.674635 | 0.668877 | 0.723405 |
| 11 | 0.642894 | 0.743387 | 0.537195 | 0.805370 | 0.460674 | 0.466766 | 0.691211 | 0.621300 | 0.425672 | 0.496850 | ... | 0.633592 | 0.659655 | 0.317438 | 0.700771 | 0.747627 | 0.635315 | 0.774906 | 0.659680 | 0.653684 | 0.710145 |
12 行 × 3770 列
cm_subsection = np.linspace(0, 1, 120)
colors_m = [cm.Purples(x) for x in cm_subsection]
colors = [cm.spring(x) for x in cm_subsection]
fig, axs = plt.subplots(1, 2, figsize=(20, 7))
axs = axs.flatten()
cum_haz_frailty_df.plot(legend=False, color=colors, alpha=0.05, ax=axs[1])
axs[1].plot(cum_haz_frailty_df.mean(axis=1), color="black", linewidth=4)
axs[1].set_title(
"Predicted Individual Cumulative Hazard \n & Expected Cumulative Hazard", fontsize=20
)
surv_frailty_df.plot(legend=False, color=colors_m, alpha=0.05, ax=axs[0])
axs[0].plot(surv_frailty_df.mean(axis=1), color="black", linewidth=4)
axs[0].set_title("Predicted Individual Survival Curves \n & Expected Survival Curve", fontsize=20)
axs[0].annotate(
f"Expected Attrition by 6 months: {np.round(1-surv_frailty_df.mean(axis=1).iloc[6], 3)}",
(2, 0.5),
fontsize=12,
fontweight="bold",
);

请注意,与上面的Cox模型相比,我们额外的脆弱性项导致生存曲线的范围增加。
绘制脆弱性项的影响#
有不同的方法可以对数据进行边际化处理,但我们也可以检查个体的“脆弱性”。在正在进行的政策转变的背景下,这类图和调查最有效。在您想要确定那些亲身经历/正在经历政策转变的个体与那些没有经历政策转变的个体的不同反应率时,它们非常有用。它有助于将注意力集中在受影响最大的员工或研究参与者身上,以弄清楚是什么(如果有的话)驱动了他们的反应,以及是否需要采取预防措施来解决危机。
beta_individual_all = frailty_idata["posterior"]["frailty"]
predicted_all = beta_individual_all.mean(("chain", "draw"))
predicted_all = predicted_all.sortby(predicted_all, ascending=False)
beta_individual = beta_individual_all.sel(frailty_id=range(500))
predicted = beta_individual.mean(("chain", "draw"))
predicted = predicted.sortby(predicted, ascending=False)
ci_lb = beta_individual.quantile(0.025, ("chain", "draw")).sortby(predicted)
ci_ub = beta_individual.quantile(0.975, ("chain", "draw")).sortby(predicted)
hdi = az.hdi(beta_individual, hdi_prob=0.5).sortby(predicted)
hdi2 = az.hdi(beta_individual, hdi_prob=0.8).sortby(predicted)
cm_subsection = np.linspace(0, 1, 500)
colors = [cm.cool(x) for x in cm_subsection]
fig = plt.figure(figsize=(20, 10))
gs = fig.add_gridspec(
2,
2,
height_ratios=(1, 7),
left=0.1,
right=0.9,
bottom=0.1,
top=0.9,
wspace=0.05,
hspace=0.05,
)
# Create the Axes.
ax = fig.add_subplot(gs[1, 0])
ax.set_yticklabels([])
ax_histx = fig.add_subplot(gs[0, 0], sharex=ax)
ax_histx.set_title("Expected Frailty Terms per Individual Risk Profile", fontsize=20)
ax_histx.hist(predicted_all, bins=30, color="slateblue")
ax_histx.set_yticklabels([])
ax_histx.tick_params(labelsize=8)
ax.set_ylabel("Individual Frailty Terms", fontsize=18)
ax.tick_params(labelsize=8)
ax.hlines(
range(len(predicted)),
hdi.sel(hdi="lower").to_array(),
hdi.sel(hdi="higher").to_array(),
color=colors,
label="50% HDI",
linewidth=0.8,
)
ax.hlines(
range(len(predicted)),
hdi2.sel(hdi="lower").to_array(),
hdi2.sel(hdi="higher").to_array(),
color="green",
alpha=0.2,
label="80% HDI",
linewidth=0.8,
)
ax.set_xlabel("Multiplicative Effect of Individual Frailty", fontsize=18)
ax.legend()
ax.fill_betweenx(range(len(predicted)), 0.95, 1.0, alpha=0.4, color="grey")
ax1 = fig.add_subplot(gs[1, 1])
f_index = retention_df[retention_df["gender"] == "F"].index
index = retention_df.index
surv_frailty_df[list(range(len(f_index)))].plot(ax=ax1, legend=False, color="red", alpha=0.8)
surv_frailty_df[list(range(len(f_index), len(index), 1))].plot(
ax=ax1, legend=False, color="royalblue", alpha=0.1
)
ax1_hist = fig.add_subplot(gs[0, 1])
f_index = retention_df[retention_df["gender"] == "F"].index
ax1_hist.hist(
(1 - surv_frailty_df[list(range(len(f_index), len(index), 1))].iloc[6]),
bins=30,
color="royalblue",
ec="black",
alpha=0.8,
)
ax1_hist.hist(
(1 - surv_frailty_df[list(range(len(f_index)))].iloc[6]),
bins=30,
color="red",
ec="black",
alpha=0.8,
)
ax1.set_xlabel("Time", fontsize=18)
ax1_hist.set_title(
"Predicted Distribution of Attrition \n by 6 Months across all risk profiles", fontsize=20
)
ax1.set_ylabel("Survival Function", fontsize=18)
ax.scatter(predicted, range(len(predicted)), color="black", ec="black", s=30)
custom_lines = [Line2D([0], [0], color="red", lw=4), Line2D([0], [0], color="royalblue", lw=4)]
ax1.legend(custom_lines, ["Female", "Male"]);

在这里,我们看到了个体脆弱性项的图以及它们对每个个体预测风险的差异乘法效应的贡献。这是一个强有力的视角,可以了解观察到的协变量为每个个体捕获了多少信息,以及脆弱性项暗示了多少修正调整?
结论#
在本例中,我们已经了解了如何在员工生命周期中对离职时间进行建模 - 我们可能还想知道为该职位招聘替代人员需要多少时间!生存分析的这些应用可以常规地应用于任何存在流程效率问题的行业。我们对随时间推移的风险的理解越深入,我们就越能适应在风险加剧时期构成的威胁。
大致需要平衡两种观点:(i)“精算”需求,即了解生命周期内的预期损失;以及(ii)“诊断”需求,即了解延长或缩短生命周期的 причинные factors。两者最终是互补的,因为每当我们为未来规划时,都需要将影响预期底线的不同风险“定价”。生存回归分析巧妙地结合了这两种观点,使分析师能够理解并采取预防措施来抵消风险增加的时期。
上面我们已经看到了许多用于事件时间数据的不同回归建模策略,但还有更多类型值得探索:具有生存成分的联合纵向模型、具有时变协变量的生存模型、治愈率模型。关于这些生存模型的贝叶斯观点很有用,因为我们经常有来自前几年或实验的详细结果,其中我们的先验为问题增加了有用的视角 - 使我们能够以数字方式编码这些信息,以帮助规范化复杂生存建模的模型拟合。对于像上面这样的脆弱性模型 - 我们已经看到了如何将先验添加到脆弱性项中,以描述未观察到的协变量对个体轨迹的影响。类似地,对基线风险进行分层建模的方法使我们能够仔细表达个体风险的轨迹。这在以人为中心的学科中尤为重要,在这些学科中,我们寻求一次又一次地理解对同一个人进行的重复测量 - 解释我们可以在多大程度上解释个体效应。也就是说,虽然生存分析的框架适用于广泛的领域和问题,但它仍然允许我们建模、预测和推断特定和个体风险的各个方面。
参考文献#
Watermark#
%load_ext watermark
%watermark -n -u -v -iv -w -p pytensor
Last updated: Tue Nov 28 2023
Python implementation: CPython
Python version : 3.9.16
IPython version : 8.11.0
pytensor: 2.11.1
matplotlib: 3.7.1
pymc : 5.3.0
pandas : 1.5.3
arviz : 0.15.1
pytensor : 2.11.1
numpy : 1.23.5
Watermark: 2.3.1
许可声明#
本示例库中的所有笔记本均根据 MIT许可证 提供,该许可证允许修改和重新分发以用于任何用途,前提是保留版权和许可声明。
引用PyMC示例#
要引用此笔记本,请使用Zenodo为pymc-examples存储库提供的DOI。
重要
许多笔记本改编自其他来源:博客、书籍…… 在这种情况下,您也应该引用原始来源。
另请记住引用您的代码使用的相关库。
这是一个bibtex中的引用模板
@incollection{citekey,
author = "<notebook authors, see above>",
title = "<notebook title>",
editor = "PyMC Team",
booktitle = "PyMC examples",
doi = "10.5281/zenodo.5654871"
}
渲染后可能如下所示