how-to 文章
使用 HSGP 的婴儿出生建模
- 2024 年 1 月 24 日
本笔记本提供了一个使用希尔伯特空间高斯过程 (HSGP) 技术的示例,该技术在 [Solin 和 Särkkä,2020 年] 中介绍,用于时间序列建模。这项技术已被证明在加速具有高斯过程组件的模型方面是成功的。
离散变量的自动边缘化
- 2024 年 1 月 20 日
PyMC 非常适合对具有离散潜在变量的模型进行采样。但是,如果您坚持专门使用 NUTS 采样器,则需要以某种方式摆脱离散变量。最好的方法是将它们边缘化,这样您就可以从 Rao-Blackwell 定理中受益,并获得参数的较低方差估计。
Pathfinder 变分推断
- 2023 年 2 月 5 日
Pathfinder [Zhang等人,2021 年] 是一种变分推断算法,可从贝叶斯模型的后验产生样本。它比广泛使用的 ADVI 算法更具优势。在大型问题上,它的扩展性应优于大多数 MCMC 算法,包括动态 HMC(即 NUTS),但代价是对后验的估计存在更多偏差。有关该算法的详细信息,请参阅 arxiv 预印本。
DEMetropolis(Z) 采样器调优
- 2023 年 1 月 18 日
对于连续变量,默认的 PyMC 采样器 (NUTS) 要求计算梯度,PyMC 通过自动微分来实现这一点。但是,在某些情况下,PyMC 模型可能未提供梯度(例如,通过在 PyMC 之外评估数值模型),因此需要替代采样器。 DEMetropolisZ 采样器是无梯度推断的有效选择。 PyMC 中 DEMetropolisZ 的实现基于 ter Braak 和 Vrugt [2008 年],但具有修改后的调优方案。本笔记本比较了采样器的各种调优参数设置,包括 PyMC 中引入的 drop_tune_fraction 参数。
DEMetropolis 和 DEMetropolis(Z) 算法比较
- 2023 年 1 月 18 日
对于连续变量,默认的 PyMC 采样器 (NUTS) 要求计算梯度,PyMC 通过自动微分来实现这一点。但是,在某些情况下,PyMC 模型可能未提供梯度(例如,通过在 PyMC 之外评估数值模型),因此需要替代采样器。差分进化 (DE) Metropolis 采样器是无梯度推断的有效选择。本笔记本比较了 PyMC 中的 DEMetropolis 和 DEMetropolisZ 采样器,以帮助确定哪个是给定问题的更好选择。
贝叶斯生存分析
- 2023 年 1 月 17 日
生存分析 研究事件发生时间的分布。它的应用跨越医学、生物学、工程学和社会科学等多个领域。本教程展示了如何在 Python 中使用 PyMC 拟合和分析贝叶斯生存模型。
在多种方式下使用贝叶斯推断的 ODE Lotka-Volterra
- 2023 年 1 月 16 日
本笔记本的目的是演示如何在有梯度和无梯度的情况下对常微分方程 (ODE) 系统执行贝叶斯推断。比较了不同采样器的准确性和效率。
PyMC 变分推断简介
- 2023 年 1 月 13 日
计算贝叶斯模型后验量的最常用策略是通过抽样,特别是马尔可夫链蒙特卡洛 (MCMC) 算法。虽然抽样算法和相关的计算在性能和效率方面不断提高,但 MCMC 方法的数据规模扩展性仍然很差,并且对于超过几千个观测值的情况变得令人望而却步。变分推断 (VI) 是一种更具可扩展性的抽样替代方案,它将计算后验分布的问题重新定义为优化问题。
经验近似概述
- 2023 年 1 月 13 日
对于大多数模型,我们使用抽样 MCMC 算法,如 Metropolis 或 NUTS。在 PyMC 中,我们习惯于存储 MCMC 样本的轨迹,然后使用它们进行分析。 PyMC 中的变分推断子模块也有类似的概念:经验。这种类型的近似存储 SVGD 采样器的粒子。独立的 SVGD 粒子和 MCMC 样本之间没有区别。 经验充当 MCMC 抽样输出和成熟的 VI 实用程序(如 apply_replacements 或 sample_node)之间的桥梁。有关接口描述,请参阅 variational_api_quickstart。在这里,我们将只关注 Emprical,并概述 经验 近似的特定内容。
使用 PyMC 将强化学习模型拟合到行为数据
- 2022 年 8 月 5 日
强化学习模型通常用于行为研究中,以模拟动物和人类如何学习,在他们需要做出重复选择并随后获得某种形式反馈(例如奖励或惩罚)的情况下。
删失数据模型
- 2022 年 5 月 24 日
关于贝叶斯生存分析的此示例笔记本 涉及删失数据的问题。删失是缺失数据问题的一种形式,其中大于某个阈值的观测值被截断到该阈值,或者小于某个阈值的观测值被截断到该阈值,或者两者兼而有之。这些分别称为右删失、左删失和区间删失。在本示例笔记本中,我们考虑区间删失。
高尔夫推杆的模型构建和扩展
- 2022 年 4 月 2 日
这使用并密切遵循了 Andrew Gelman 的案例研究,该案例研究是用 Stan 编写的。有一些新的可视化效果,我们避免使用不合适的先验,但非常感谢他和 Stan 团队的出色案例研究和软件。
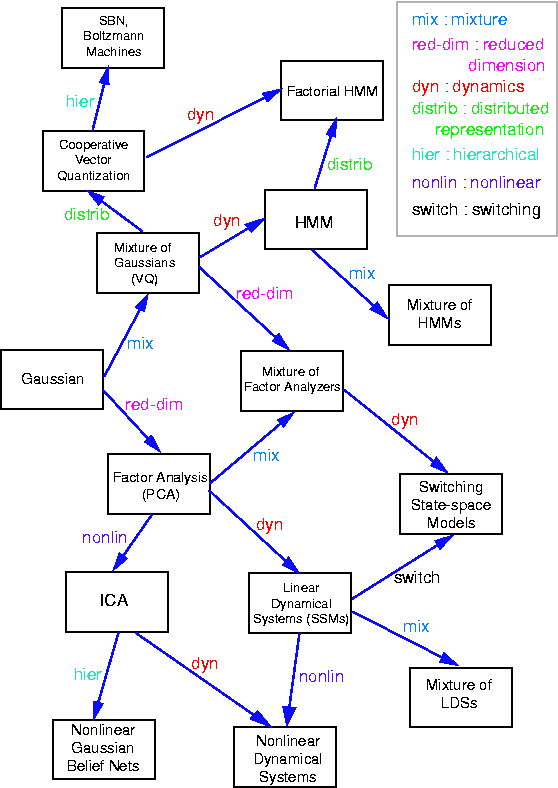
因子分析
- 2022 年 3 月 19 日
因子分析是一种广泛使用的概率模型,用于识别多元数据中的低秩结构,该结构编码在潜在变量中。它与主成分分析非常相关,仅在对这些潜在变量假设的先验分布上有所不同。它也是线性高斯模型的一个很好的例子,因为它可以完全描述为底层高斯变量的线性变换。要了解因子分析与其他模型之间的高级关系,您可以查看 Ghahramani 和 Roweis 最初发布的此图。
{kind=link}
橄榄球预测的分层模型
- 2022 年 3 月 19 日
在本示例中,我们将重现 Baio 和 Blangiardo [2010 年] 中描述的第一个模型,使用 PyMC。然后展示如何从后验预测中抽样,以模拟锦标赛结果,这些结果来自建模的数量得分目标。